保姆级使用PyTorch训练与评估自己的EVA网络教程

文章目录
- 前言
- 0. 环境搭建&快速开始
- 1. 数据集制作
- 1.1 标签文件制作
- 1.2 数据集划分
- 1.3 数据集信息文件制作
- 2. 修改参数文件
- 3. 训练
- 4. 评估
- 5. 其他教程
前言
项目地址:https://github.com/Fafa-DL/Awesome-Backbones
操作教程:https://www.bilibili.com/video/BV1SY411P7Nd
EVA原论文:点我跳转
如果你以为该仓库仅支持训练一个模型那就大错特错了,我在项目地址放了目前支持的42种模型(LeNet5、AlexNet、VGG、DenseNet、ResNet、Wide-ResNet、ResNeXt、SEResNet、SEResNeXt、RegNet、MobileNetV2、MobileNetV3、ShuffleNetV1、ShuffleNetV2、EfficientNet、RepVGG、Res2Net、ConvNeXt、HRNet、ConvMixer、CSPNet、Swin-Transformer、Vision-Transformer、Transformer-in-Transformer、MLP-Mixer、DeiT、Conformer、T2T-ViT、Twins、PoolFormer、VAN、HorNet、EfficientFormer、Swin Transformer V2、MViT V2、MobileViT、DaViT、RepLKNet、BEiT、EVA、MixMIM、EfficientNetV2),使用方式一模一样。且目前满足了大部分图像分类需求,进度快的同学甚至论文已经在审了
0. 环境搭建&快速开始
- 这一步我也在最近录制了视频
最新Windows配置VSCode与Anaconda环境
『图像分类』从零环境搭建&快速开始
- 不想看视频也将文字版放在此处。建议使用Anaconda进行环境管理,创建环境命令如下
conda create -n [name] python=3.6 其中[name]改成自己的环境名,如[name]->torch,conda create -n torch python=3.6
- 我的测试环境如下
torch==1.7.1
torchvision==0.8.2
scipy==1.4.1
numpy==1.19.2
matplotlib==3.2.1
opencv_python==3.4.1.15
tqdm==4.62.3
Pillow==8.4.0
h5py==3.1.0
terminaltables==3.1.0
packaging==21.3
- 首先安装Pytorch。建议版本和我一致,进入Pytorch官网,点击
install previous versions of PyTorch,以1.7.1为例,官网给出的安装如下,选择合适的cuda版本
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 10.2
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2# CUDA 10.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 9.2
pip install torch==1.7.1+cu92 torchvision==0.8.2+cu92 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CPU only
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
- 安装完Pytorch后,再运行
pip install -r requirements.txt
- 下载MobileNetV3-Small权重至datas下
- Awesome-Backbones文件夹下终端输入
python tools/single_test.py datas/cat-dog.png models/mobilenet/mobilenet_v3_small.py --classes-map datas/imageNet1kAnnotation.txt
1. 数据集制作
1.1 标签文件制作
-
将项目代码下载到本地
-
本次演示以花卉数据集为例,目录结构如下:
├─flower_photos
│ ├─daisy
│ │ 100080576_f52e8ee070_n.jpg
│ │ 10140303196_b88d3d6cec.jpg
│ │ ...
│ ├─dandelion
│ │ 10043234166_e6dd915111_n.jpg
│ │ 10200780773_c6051a7d71_n.jpg
│ │ ...
│ ├─roses
│ │ 10090824183_d02c613f10_m.jpg
│ │ 102501987_3cdb8e5394_n.jpg
│ │ ...
│ ├─sunflowers
│ │ 1008566138_6927679c8a.jpg
│ │ 1022552002_2b93faf9e7_n.jpg
│ │ ...
│ └─tulips
│ │ 100930342_92e8746431_n.jpg
│ │ 10094729603_eeca3f2cb6.jpg
│ │ ...
- 在
Awesome-Backbones/datas/中创建标签文件annotations.txt,按行将类别名 索引写入文件;
daisy 0
dandelion 1
roses 2
sunflowers 3
tulips 4

1.2 数据集划分
- 打开
Awesome-Backbones/tools/split_data.py - 修改
原始数据集路径以及划分后的保存路径,强烈建议划分后的保存路径datasets不要改动,在下一步都是默认基于文件夹进行操作
init_dataset = 'A:/flower_photos' # 改为你自己的数据路径
new_dataset = 'A:/Awesome-Backbones/datasets'
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/split_data.py
- 得到划分后的数据集格式如下:
├─...
├─datasets
│ ├─test
│ │ ├─daisy
│ │ ├─dandelion
│ │ ├─roses
│ │ ├─sunflowers
│ │ └─tulips
│ └─train
│ ├─daisy
│ ├─dandelion
│ ├─roses
│ ├─sunflowers
│ └─tulips
├─...
1.3 数据集信息文件制作
- 确保划分后的数据集是在
Awesome-Backbones/datasets下,若不在则在get_annotation.py下修改数据集路径;
datasets_path = '你的数据集路径'
- 在
Awesome-Backbones/下打开终端输入命令:
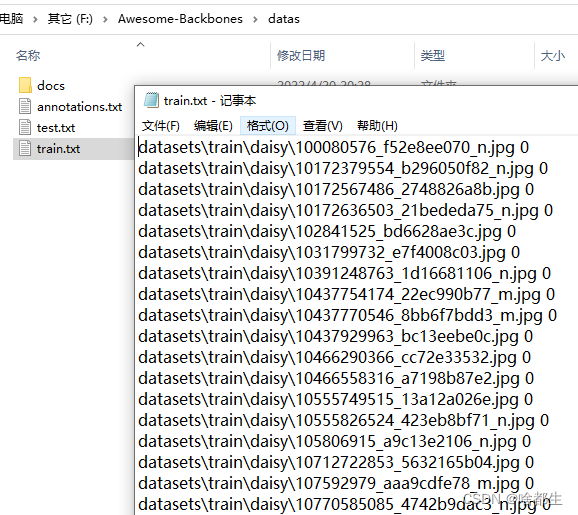
python tools/get_annotation.py
- 在
Awesome-Backbones/datas下得到生成的数据集信息文件train.txt与test.txt
2. 修改参数文件
-
每个模型均对应有各自的配置文件,保存在
Awesome-Backbones/models下 -
由
backbone、neck、head、head.loss构成一个完整模型 -
找到EVA参数配置文件,可以看到
所有支持的类型都在这,且每个模型均提供预训练权重

-
在
model_cfg中修改num_classes为自己数据集类别大小 -
按照自己电脑性能在
data_cfg中修改batch_size与num_workers -
若有预训练权重则可以将
pretrained_weights设置为True并将预训练权重的路径赋值给pretrained_weights -
若需要冻结训练则
freeze_flag设置为True,可选冻结的有backbone, neck, head -
在
optimizer_cfg中修改初始学习率,根据自己batch size调试,若使用了预训练权重,建议学习率调小 -
学习率更新详见
core/optimizers/lr_update.py,同样准备了视频『图像分类』学习率更新策略|优化器 -
更具体配置文件修改可参考配置文件解释,同样准备了视频『图像分类』配置文件补充说明
3. 训练
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下train.txt与test.txt与annotations.txt对应 - 选择想要训练的模型,在
Awesome-Backbones/models/下找到对应配置文件,以eva_g _p14_headless为例 - 按照
配置文件解释修改参数 - 在
Awesome-Backbones路径下打开终端运行
python tools/train.py models/eva/eva_g _p14_headless.py

4. 评估
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下test.txt与annotations.txt对应 - 在
Awesome-Backbones/models/下找到对应配置文件 - 在参数配置文件中
修改权重路径,其余不变
ckpt = '你的训练权重路径'
- 在
Awesome-Backbones路径下打开终端运行
python tools/evaluation.py models/eva/eva_g _p14_headless.py

- 单张图像测试,在
Awesome-Backbones打开终端运行
python tools/single_test.py datasets/test/dandelion/14283011_3e7452c5b2_n.jpg models/eva/eva_g _p14_headless.py

至此完毕,实在没运行起来就去B站看我手把手带大家运行的视频教学吧~
5. 其他教程
除开上述,我还为大家准备了其他一定用到的操作教程,均放在了GitHub项目首页,为了你们方便为也粘贴过来
- 环境搭建
- 数据集准备
- 配置文件解释
- 训练
- 模型评估&批量检测/视频检测
- 计算Flops&Params
- 添加新的模型组件
- 类别激活图可视化
- 学习率策略可视化
有任何更新均会在Github与B站进行通知,记得Star与三连关注噢~
相关文章:
保姆级使用PyTorch训练与评估自己的EVA网络教程
文章目录前言0. 环境搭建&快速开始1. 数据集制作1.1 标签文件制作1.2 数据集划分1.3 数据集信息文件制作2. 修改参数文件3. 训练4. 评估5. 其他教程前言 项目地址:https://github.com/Fafa-DL/Awesome-Backbones 操作教程:https://www.bilibili.co…...

Java--JMH--性能测试--测试软件运行效率/时间--StopWatch
写在前面: 很多时候想要测试代码运行时间,或者比较2个运行的效率。 最简单的方法就是Sytem.currentTimeMillis记录2开始和结束时间来算 但是Java 代码越执行越快,放在后面的方法会有优势,这个原因受留个眼,以后研究。大概有受类加…...
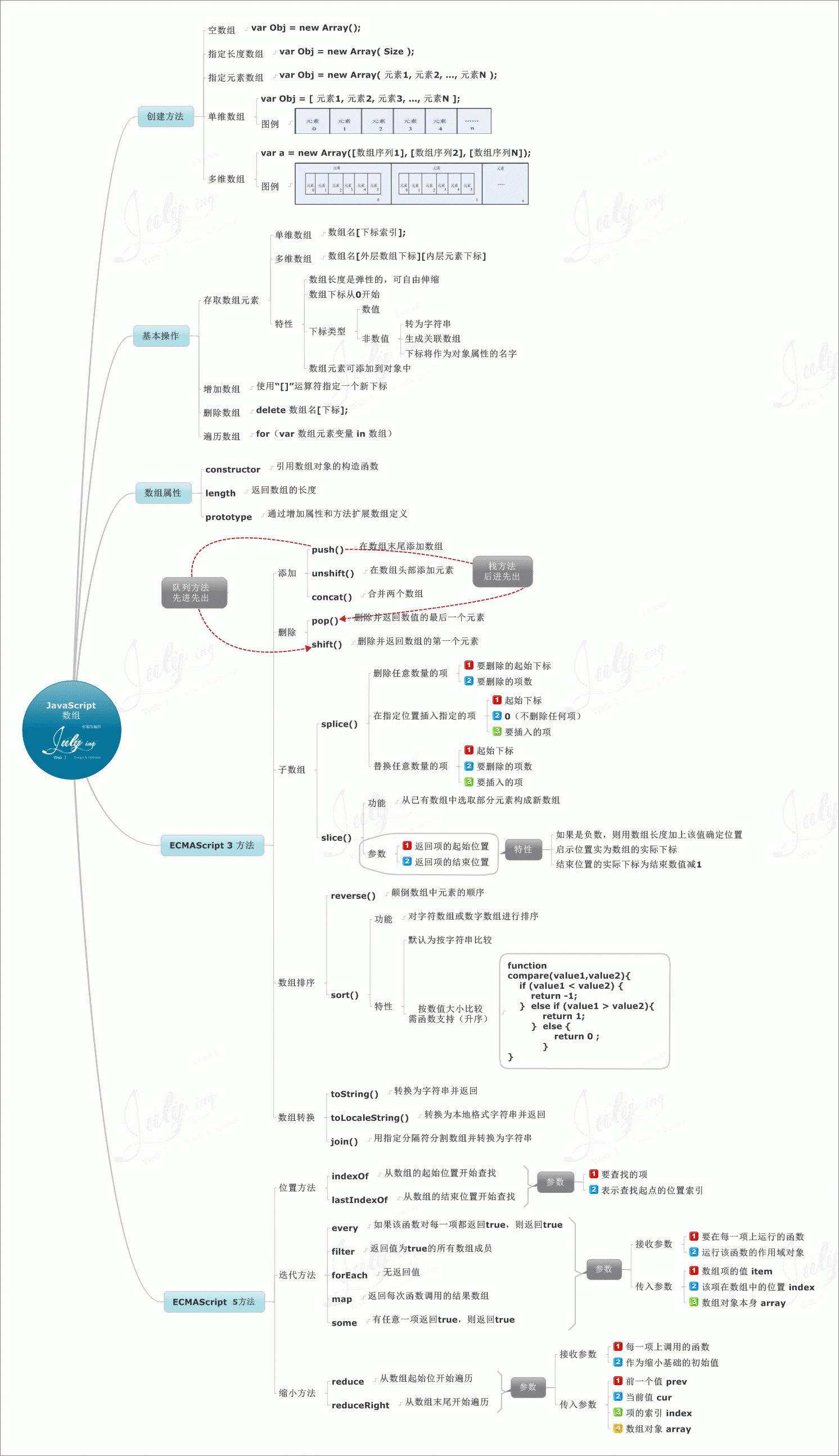
JavaScript Array(数组)对象
数组对象的作用是:使用单独的变量名来存储一系列的值。参数参数 size 是期望的数组元素个数。返回的数组,length 字段将被设为 size 的值。参数 element ...; elementn 是参数列表。当使用这些参数来调用构造函数 Array() 时,新创建的数组的元…...

干货 | 电容在电路35个基本常识
第1个电压源正负端接了一个电容,与电路并联,用于整流电路时,具有很好的滤波作用,当电压交变时,由于电容的充电作用,两端的电压不能突变,就保证了电压的平稳。当用于电池电源时,具有交…...
日读300篇文献的技巧
感觉自己看文章很慢,有时候也抓不住重点。 如果是英文文献的话,可能还要有点难度,毕竟英语渣渣还是需要有中文-》英文的转换过程。 最近在搞毕业论文的时候,发现了一个非常好玩的东西,大大提升了我看文章搞科研&#x…...

C++核心编程
一、内存分区模型概述:C程序在执行时,将内存划分为4个区域程序运行前:代码区:存放函数体的二进制代码,由操作系统管理①共享。共享的目的是对于频繁被执行的程序,在内存中只需有一份代码即可②只读。使其只…...
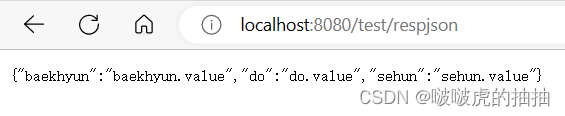
SpringMVC程序开发
目录 SpringMVC 1、MVC定义 2、MVC和SpringMVC之间的关系 学SpringMVC 1、Spring MVC的创建和连接 浏览器获取前端接口和后端程序连接功能实现 2、获取参数 2.1、传递单个参数/多个参数 2.2、传递对象 2.3、传递表单参数 2.4、后端参数重命名 2.5、RequestBody接收J…...

多版本并发控制MVCC
什么是MVCC? MVCC是一种并发控制方法,一般在数据库管理系统中,实现数据库的并发访问。 可以使用乐观锁和悲观锁来实现。 MVCC的作用? 可以在不加锁的情况下解决读写问题,同时还可以解决脏读,幻读&#…...

JavaScript Date(日期)对象
日期对象用于处理日期和时间。在线实例返回当日的日期和时间如何使用 Date() 方法获得当日的日期。getFullYear()使用 getFullYear() 获取年份。getTime()getTime() 返回从 1970 年 1 月 1 日至今的毫秒数。setFullYear()如何使用 setFullYear() 设置具体的日期。toUTCString()…...
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...

代码随想录【Day34】| 1005. K 次取反后最大化的数组和、134. 加油站、135. 分发糖果
1005. K 次取反后最大化的数组和 题目链接 题目描述: 给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。&…...

Java性能调优杀手锏JMH
JMH简介 JMH(Java Microbenchmark Harness)由 OpenJDK/Oracle 里面那群开发了 Java编译器的大牛们所开发,是一个功能强大、灵活的工具,它可以用于检测和评估Java应用程序的性能,主要目的是测量Java应用程序的性能,尤其是在多线程…...
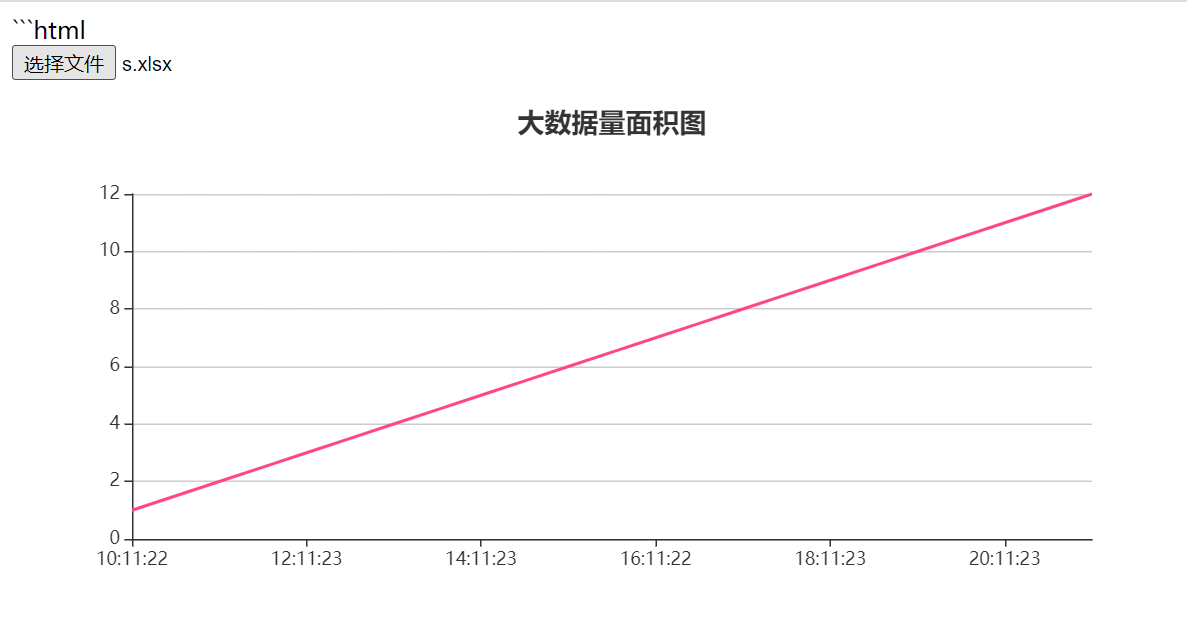
实现excle表上传生成echarts图
代码如下html <!--这是一个网上关于读取Excel最经典的代码--> <!DOCTYPE html> <html><head><meta charset"utf-8"><title>ECharts</title><!-- 引入 echarts.js --><!-- <script src"newjs/js/incubato…...
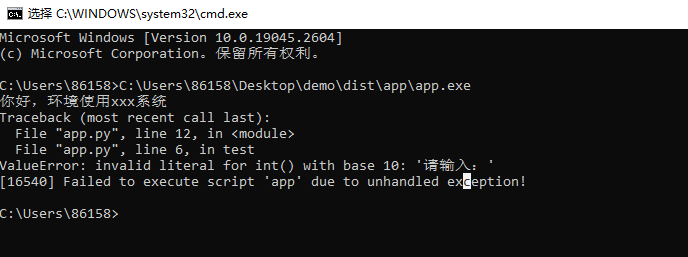
python代码如何打包
网上的文章对小白都不太友好呀,讲得都比较高大上,本文章就用最简单的方式来教会大家如何打包。既然各位已经学习到了python打包了, 深适度应该跟我查不多。 注意事项: 1. 这个插件只能打包 mac 、win系统运行的文件,也…...
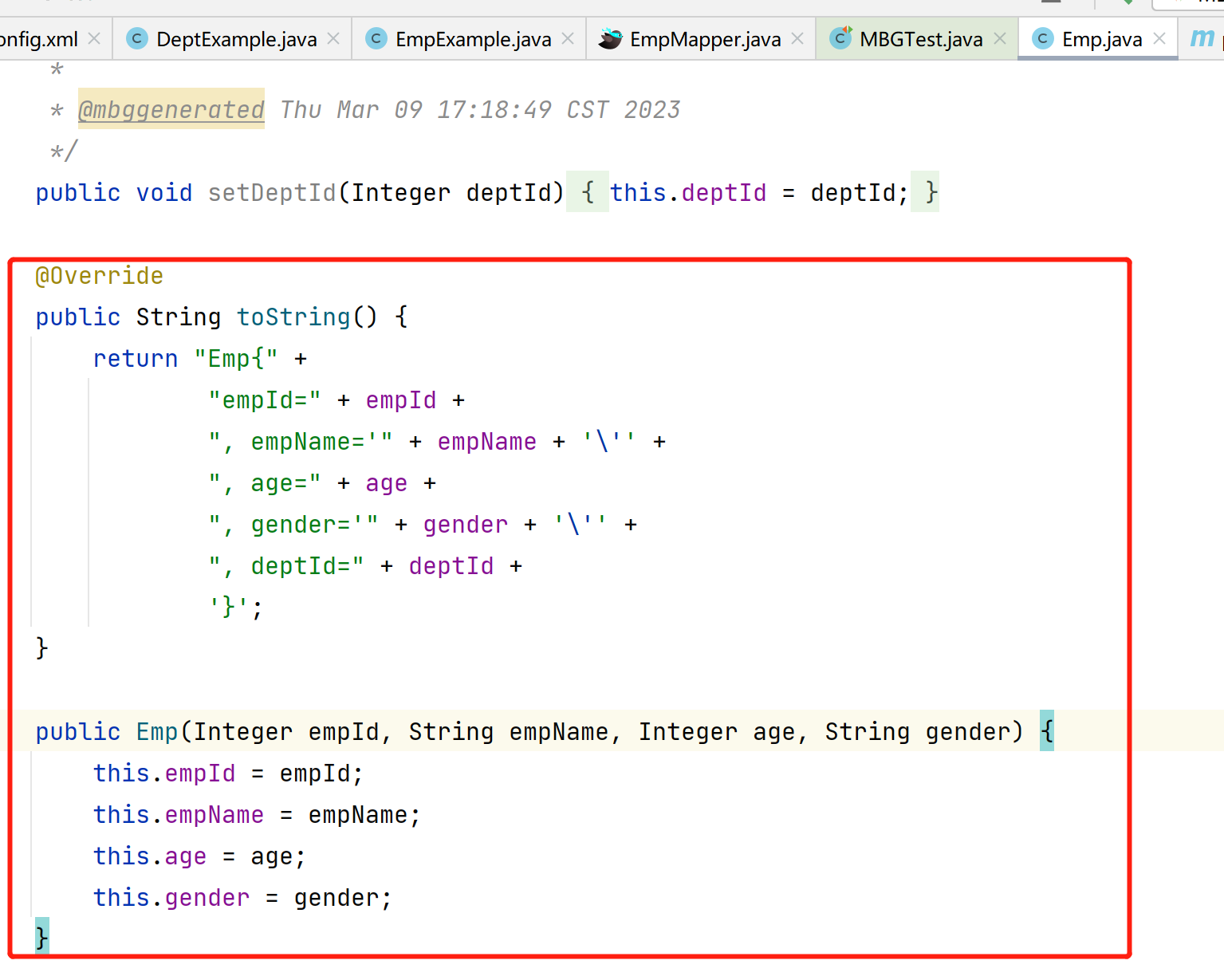
MyBatis学习笔记(十二) —— MyBatis的逆向工程
12、MyBatis的逆向工程 正向工程:先创建Java实体类,由框架负责根据实体类生成数据库表。Hibernate是支持正向工程的。 逆向工程:先创建数据库表,由框架负责根据数据库表,反向生成如下资源: Java实体类Mappe…...
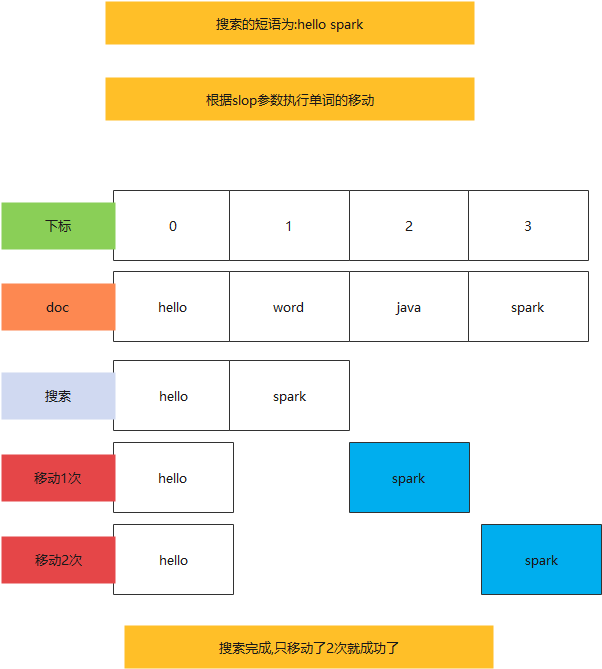
4.Elasticsearch深入了解
4.Elasticsearch深入了解[toc]1.Elasticsearch架构原理Elasticsearch的节点类型在Elasticsearch主要分成两类节点,一类是Master,一类是DataNode。Master节点在Elasticsearch启动时,会选举出来一个Master节点。当某个节点启动后,然…...

【HashSet】| 深度剥析Java SE 源码合集Ⅲ
目录一. 🦁 HashSet介绍1.1 特点1.2 底层实现二. 🦁 结构以及对应方法分析2.1 结构组成2.1.1 源码实现2.1.2 成员变量及构造方法2.2 常用的方法2.2.1 添加add(E e)方法2.2.2 删除remove(Object o)方法三. 最后想说一. 🦁 HashSet介绍 1.1 特…...
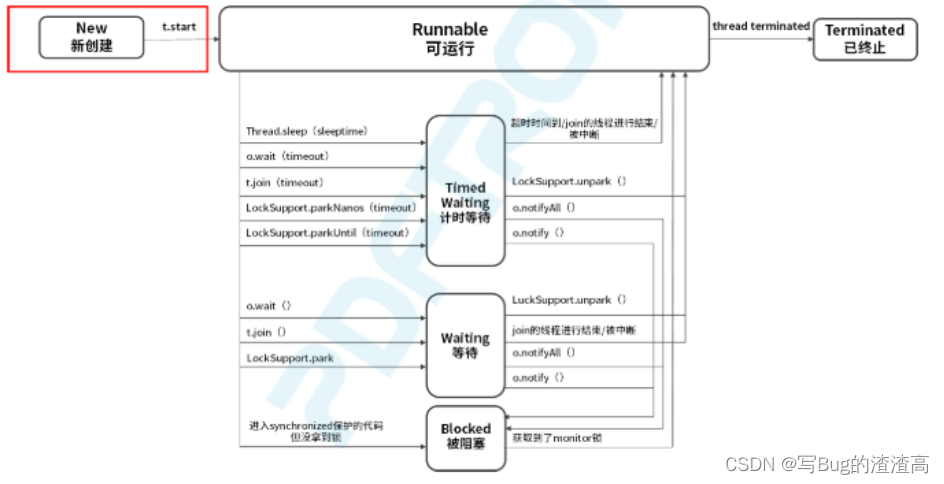
你了解线程的状态转换吗
本文概述: 讲述线程的六种状态. 你可能已经了解了六种状态, 但是你知道 sleep 被唤醒之后, wait ()被 notify 之后进入了什么状态吗? 本文只是开胃小菜, 你看看下一篇文章对你有没有帮助. 一共有六种状态: New 新建状态Runnable 运行状态Blocked 阻塞状态Waiting 等待状态Tim…...
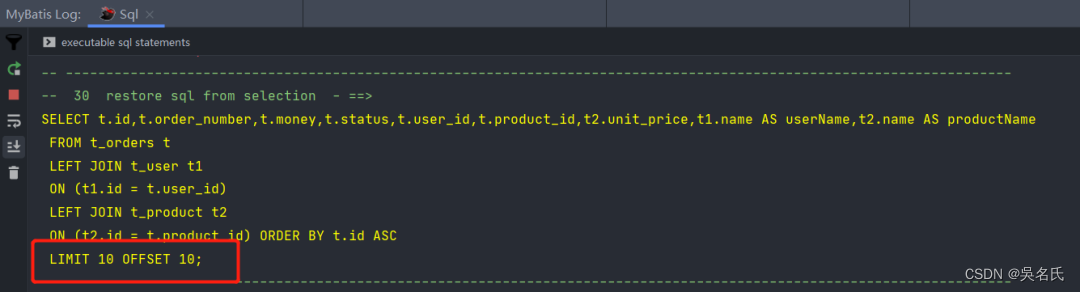
MyBatis-Plus联表查询的短板,该如何解决呢
mybatis-plus作为mybatis的增强工具,它的出现极大的简化了开发中的数据库操作,但是长久以来,它的联表查询能力一直被大家所诟病。一旦遇到left join或right join的左右连接,你还是得老老实实的打开xml文件,手写上一大段…...
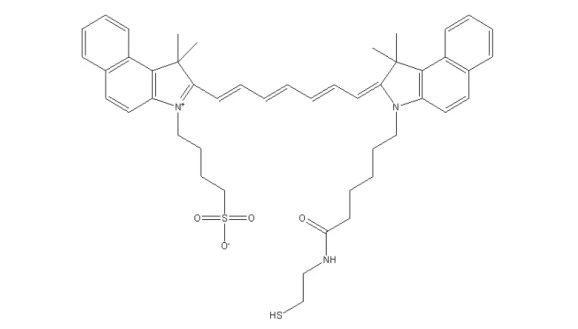
吲哚菁绿-巯基,ICG-SH,科研级别试剂,吲哚菁绿可用于测定心输出量、肝脏功能、肝血流量,和对于眼科血管造影术。
ICG-THIOL,吲哚菁绿-巯基 中文名称:吲哚菁绿-巯基 英文名称:ICG-THIOL 英文别名:ICG-SH 性状:绿色粉末 溶剂:溶于二氯甲烷等其他常规有机溶剂 稳定性:冷藏保存,避免反复冻融。 存储条件&…...

CMOS闩锁效应原理与防护设计实践
1. 闩锁效应基础原理剖析闩锁效应(Latch-up)是CMOS集成电路设计中最为棘手的可靠性问题之一。这种现象本质上是由芯片内部寄生形成的PNP-NPN晶体管对构成的晶闸管结构(SCR)被意外触发导致的。当特定条件满足时,这些寄生元件会形成正反馈回路,导致电源与地…...

语言启蒙到底要不要背单词
语言启蒙阶段到底要不要背单词?我更愿意把这个问题换一种问法:这些词是不是能和声音、图像、语境连起来,并且隔几天还能回来一次。 如果只是拿一张词表硬记,入门用户很容易觉得枯燥。可如果完全不接触词汇,后面的听读…...

MobaXterm 全能终端神器:实战指南
写在前面:作为Windows下最全能的远程终端工具,MobaXterm 在 2026 年已迭代至 v26.0 版本。本文基于最新版,从工具选型对比、核心功能实战到效率提升技巧,带你真正掌握这款"瑞士军刀"。文末附赠快捷键大全和安全配置清单…...

企业内网虚拟机如何通过Taotoken安全接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网虚拟机如何通过Taotoken安全接入多模型API 在许多企业的技术架构中,开发与测试环境常部署于内网虚拟机中。这些…...

基于Ollama与Stable Diffusion的Discord AI机器人本地部署指南
1. 项目概述:一个能聊能画的Discord AI机器人 最近在折腾一个挺有意思的玩意儿:一个部署在自己电脑上的Discord机器人,它不仅能像ChatGPT一样跟你聊天,还能根据你的描述生成图片。这个项目的核心,是把两个当下很火的开…...

数字永生:将意识上传云端的技术与伦理极限
——一个软件测试从业者的技术解构与风险分析各位同行,当你看到“数字永生”这四个字时,脑海里浮现的是什么?是马斯克口中2045年即将实现的意识上传,还是《黑镜》里那些被困在虚拟牢笼中的数字灵魂?作为一个每天与需求…...

Midjourney咖啡印相为何总偏灰?揭秘RGB→Lab→咖啡染料光谱响应的3层色彩断层及校正算法
更多请点击: https://intelliparadigm.com 第一章:Midjourney咖啡印相为何总偏灰?揭秘RGB→Lab→咖啡染料光谱响应的3层色彩断层及校正算法 咖啡印相(Coffee Cyanotype)作为一种新兴的生物友好型物理输出工艺…...

如何在Windows上快速安装安卓应用:APK Installer终极指南
如何在Windows上快速安装安卓应用:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想要在Windows电脑上运行安卓应用&…...

开源工具LMAO:通过浏览器自动化免费调用ChatGPT与Copilot API
1. 项目概述与核心价值如果你和我一样,是个喜欢折腾各种AI工具,但又对官方API的付费门槛、调用限制或者复杂的申请流程感到头疼的开发者,那么今天聊的这个项目,你一定会感兴趣。它叫LLM-API-Open,圈内朋友喜欢叫它LMAO…...

怎样3步掌握桌面自动化:智能鼠标键盘录制工具完整攻略
怎样3步掌握桌面自动化:智能鼠标键盘录制工具完整攻略 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo Keymouse…...