YOLOv8改进 | 卷积模块 | 在主干网络中添加/替换蛇形卷积Dynamic Snake Convolution
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
蛇形动态卷积是一种新型的卷积操作,旨在提高对细长和弯曲的管状结构的特征提取能力。它通过自适应地调整卷积核的权重,使得网络能够更加关注管状结构的局部特征,如血管的分叉和弯曲部分。这种卷积操作的设计灵感来源于蛇形曲线,它能够在不同尺度上捕捉到管状结构的细节信息,从而提高准确性。通过在卷积过程中引入这种动态性,DSCNet能够更有效地处理管状结构的复杂性和变异性,为后续的特征融合提供更精细的信息。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLOv8改进——更新各种有效涨点方法——点击即可跳转
目录
1.原理
2. 蛇形动态卷积的代码实现
2.1 将蛇形动态卷积添加到YOLOv8中
2.2 更改init.py文件
2.3 添加yaml文件
2.4 在task.py中进行注册
2.5 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1.原理

官方论文:Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation——点击即可跳转
代码实现:官方代码仓库——点击即可跳转
动态蛇形卷积(Dynamic Snake Convolution)的设计灵感来源于蛇形的形状,用于改善对目标形状和边界的敏感性。能够帮助神经网络更好地捕捉目标的形状信息,特别是对于复杂的或不规则形状的目标。通过引入动态的、可变形的卷积核来实现这一目标。这种可变形的卷积核能够根据目标的形状和边界信息进行调整,从而更好地适应目标的特定形状。
传统的卷积操作在处理目标形状变化较大的情况下可能存在一定的局限性,而动态蛇形卷积则能够通过自适应性地调整卷积核的形状和大小,更有效地捕获目标的特征。
这种模块的应用通常能够增强目标检测模型对不同尺度、形状和姿态的目标的感知能力,从而提高目标检测的准确性和鲁棒性。虽然这只是目标检测中的一种模块,但它代表了在深度学习领域中不断创新和改进的努力,以提高模型对复杂场景的理解能力。
蛇形动态卷积(Snake-like Dynamic Convolution)是一种卷积神经网络中的技术,旨在提升卷积操作的灵活性和适应性,以便更好地捕捉和表征图像中的复杂结构。以下是蛇形动态卷积的基本原理和其核心概念的详细讲解:
1. 卷积操作的基本概念
在传统的卷积神经网络(CNN)中,卷积层使用固定形状的滤波器(卷积核)在图像上滑动,执行点积运算,从而提取局部特征。这些滤波器的参数在训练过程中被学习,并在整个输入图像上重复使用。
2. 动态卷积的引入
传统卷积的局限性在于,固定形状和参数的卷积核可能无法适应图像中复杂和多样的局部结构。为了解决这一问题,动态卷积应运而生。动态卷积的核心思想是,根据输入数据动态调整卷积核的参数,使其更加适应局部特征。
3. 蛇形动态卷积的具体机制
蛇形动态卷积是动态卷积的一种特殊形式,其名称源于卷积核的形状和应用方式。其主要特点如下:
a. 蛇形核形状
蛇形动态卷积核的形状不是固定的矩形或方形,而是类似于蛇形路径。这样设计的目的是为了能够更灵活地捕捉图像中的曲线和非直线结构。这种核形状可以更好地适应图像中的复杂边缘和纹理。
b. 动态调整权重
蛇形动态卷积的权重不是固定的,而是根据输入数据动态生成的。通常使用一个生成网络(如小型卷积网络或注意力机制)来根据当前输入生成适应性的权重。这些权重在卷积操作时被应用,从而使得卷积核在不同位置具有不同的特性。
c. 多尺度特征提取
蛇形动态卷积可以通过不同尺度的卷积核捕捉图像中的多尺度特征。通过结合不同尺度的特征,可以更全面地描述图像中的结构信息。
4. 蛇形动态卷积的优势
-
更强的特征表达能力:通过动态调整卷积核的形状和权重,蛇形动态卷积可以更好地适应图像中的多样性和复杂性,从而提取更加丰富和准确的特征。
-
灵活性和适应性:这种卷积方式能够根据输入的变化动态调整自身,从而在处理不同类型的图像和任务时具有更好的适应性。
-
提升模型性能:在实际应用中,蛇形动态卷积常常能够提升图像分类、目标检测和语义分割等任务的性能。
蛇形动态卷积是一种创新的卷积操作方式,通过引入动态权重调整和灵活的核形状,能够更好地捕捉图像中的复杂结构特征。这种方法在许多计算机视觉任务中展示了其优越性和潜力。
2. 蛇形动态卷积的代码实现
2.1 将蛇形动态卷积添加到YOLOv8中
关键步骤一:将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/conv.py中,并在该文件的__all__中添加“DySnakeConv”
class DySnakeConv(nn.Module):def __init__(self, inc, ouc, k=3, act=True) -> None:super().__init__()self.conv_0 = Conv(inc, ouc, k, act=act)self.conv_x = DSConv(inc, ouc, 0, k)self.conv_y = DSConv(inc, ouc, 1, k)self.conv_1x1 = Conv(ouc * 3, ouc, 1, act=act)def forward(self, x):return self.conv_1x1(torch.cat([self.conv_0(x), self.conv_x(x), self.conv_y(x)], dim=1))class DSConv(nn.Module):def __init__(self, in_ch, out_ch, morph, kernel_size=3, if_offset=True, extend_scope=1):"""The Dynamic Snake Convolution:param in_ch: input channel:param out_ch: output channel:param kernel_size: the size of kernel:param extend_scope: the range to expand (default 1 for this method):param morph: the morphology of the convolution kernel is mainly divided into two typesalong the x-axis (0) and the y-axis (1) (see the paper for details):param if_offset: whether deformation is required, if it is False, it is the standard convolution kernel"""super(DSConv, self).__init__()# use the <offset_conv> to learn the deformable offsetself.offset_conv = nn.Conv2d(in_ch, 2 * kernel_size, 3, padding=1)self.bn = nn.BatchNorm2d(2 * kernel_size)self.kernel_size = kernel_size# two types of the DSConv (along x-axis and y-axis)self.dsc_conv_x = nn.Conv2d(in_ch,out_ch,kernel_size=(kernel_size, 1),stride=(kernel_size, 1),padding=0,)self.dsc_conv_y = nn.Conv2d(in_ch,out_ch,kernel_size=(1, kernel_size),stride=(1, kernel_size),padding=0,)self.gn = nn.GroupNorm(out_ch // 4, out_ch)self.act = Conv.default_actself.extend_scope = extend_scopeself.morph = morphself.if_offset = if_offsetdef forward(self, f):offset = self.offset_conv(f)offset = self.bn(offset)# We need a range of deformation between -1 and 1 to mimic the snake's swingoffset = torch.tanh(offset)input_shape = f.shapedsc = DSC(input_shape, self.kernel_size, self.extend_scope, self.morph)deformed_feature = dsc.deform_conv(f, offset, self.if_offset)if self.morph == 0:x = self.dsc_conv_x(deformed_feature.type(f.dtype))x = self.gn(x)x = self.act(x)return xelse:x = self.dsc_conv_y(deformed_feature.type(f.dtype))x = self.gn(x)x = self.act(x)return x# Core code, for ease of understanding, we mark the dimensions of input and output next to the code
class DSC(object):def __init__(self, input_shape, kernel_size, extend_scope, morph):self.num_points = kernel_sizeself.width = input_shape[2]self.height = input_shape[3]self.morph = morphself.extend_scope = extend_scope # offset (-1 ~ 1) * extend_scope# define feature map shape"""B: Batch size C: Channel W: Width H: Height"""self.num_batch = input_shape[0]self.num_channels = input_shape[1]"""input: offset [B,2*K,W,H] K: Kernel size (2*K: 2D image, deformation contains <x_offset> and <y_offset>)output_x: [B,1,W,K*H] coordinate mapoutput_y: [B,1,K*W,H] coordinate map"""def _coordinate_map_3D(self, offset, if_offset):device = offset.device# offsety_offset, x_offset = torch.split(offset, self.num_points, dim=1)y_center = torch.arange(0, self.width).repeat([self.height])y_center = y_center.reshape(self.height, self.width)y_center = y_center.permute(1, 0)y_center = y_center.reshape([-1, self.width, self.height])y_center = y_center.repeat([self.num_points, 1, 1]).float()y_center = y_center.unsqueeze(0)x_center = torch.arange(0, self.height).repeat([self.width])x_center = x_center.reshape(self.width, self.height)x_center = x_center.permute(0, 1)x_center = x_center.reshape([-1, self.width, self.height])x_center = x_center.repeat([self.num_points, 1, 1]).float()x_center = x_center.unsqueeze(0)if self.morph == 0:"""Initialize the kernel and flatten the kernely: only need 0x: -num_points//2 ~ num_points//2 (Determined by the kernel size)!!! The related PPT will be submitted later, and the PPT will contain the whole changes of each step"""y = torch.linspace(0, 0, 1)x = torch.linspace(-int(self.num_points // 2),int(self.num_points // 2),int(self.num_points),)y, x = torch.meshgrid(y, x)y_spread = y.reshape(-1, 1)x_spread = x.reshape(-1, 1)y_grid = y_spread.repeat([1, self.width * self.height])y_grid = y_grid.reshape([self.num_points, self.width, self.height])y_grid = y_grid.unsqueeze(0) # [B*K*K, W,H]x_grid = x_spread.repeat([1, self.width * self.height])x_grid = x_grid.reshape([self.num_points, self.width, self.height])x_grid = x_grid.unsqueeze(0) # [B*K*K, W,H]y_new = y_center + y_gridx_new = x_center + x_gridy_new = y_new.repeat(self.num_batch, 1, 1, 1).to(device)x_new = x_new.repeat(self.num_batch, 1, 1, 1).to(device)y_offset_new = y_offset.detach().clone()if if_offset:y_offset = y_offset.permute(1, 0, 2, 3)y_offset_new = y_offset_new.permute(1, 0, 2, 3)center = int(self.num_points // 2)# The center position remains unchanged and the rest of the positions begin to swing# This part is quite simple. The main idea is that "offset is an iterative process"y_offset_new[center] = 0for index in range(1, center):y_offset_new[center + index] = (y_offset_new[center + index - 1] + y_offset[center + index])y_offset_new[center - index] = (y_offset_new[center - index + 1] + y_offset[center - index])y_offset_new = y_offset_new.permute(1, 0, 2, 3).to(device)y_new = y_new.add(y_offset_new.mul(self.extend_scope))y_new = y_new.reshape([self.num_batch, self.num_points, 1, self.width, self.height])y_new = y_new.permute(0, 3, 1, 4, 2)y_new = y_new.reshape([self.num_batch, self.num_points * self.width, 1 * self.height])x_new = x_new.reshape([self.num_batch, self.num_points, 1, self.width, self.height])x_new = x_new.permute(0, 3, 1, 4, 2)x_new = x_new.reshape([self.num_batch, self.num_points * self.width, 1 * self.height])return y_new, x_newelse:"""Initialize the kernel and flatten the kernely: -num_points//2 ~ num_points//2 (Determined by the kernel size)x: only need 0"""y = torch.linspace(-int(self.num_points // 2),int(self.num_points // 2),int(self.num_points),)x = torch.linspace(0, 0, 1)y, x = torch.meshgrid(y, x)y_spread = y.reshape(-1, 1)x_spread = x.reshape(-1, 1)y_grid = y_spread.repeat([1, self.width * self.height])y_grid = y_grid.reshape([self.num_points, self.width, self.height])y_grid = y_grid.unsqueeze(0)x_grid = x_spread.repeat([1, self.width * self.height])x_grid = x_grid.reshape([self.num_points, self.width, self.height])x_grid = x_grid.unsqueeze(0)y_new = y_center + y_gridx_new = x_center + x_gridy_new = y_new.repeat(self.num_batch, 1, 1, 1)x_new = x_new.repeat(self.num_batch, 1, 1, 1)y_new = y_new.to(device)x_new = x_new.to(device)x_offset_new = x_offset.detach().clone()if if_offset:x_offset = x_offset.permute(1, 0, 2, 3)x_offset_new = x_offset_new.permute(1, 0, 2, 3)center = int(self.num_points // 2)x_offset_new[center] = 0for index in range(1, center):x_offset_new[center + index] = (x_offset_new[center + index - 1] + x_offset[center + index])x_offset_new[center - index] = (x_offset_new[center - index + 1] + x_offset[center - index])x_offset_new = x_offset_new.permute(1, 0, 2, 3).to(device)x_new = x_new.add(x_offset_new.mul(self.extend_scope))y_new = y_new.reshape([self.num_batch, 1, self.num_points, self.width, self.height])y_new = y_new.permute(0, 3, 1, 4, 2)y_new = y_new.reshape([self.num_batch, 1 * self.width, self.num_points * self.height])x_new = x_new.reshape([self.num_batch, 1, self.num_points, self.width, self.height])x_new = x_new.permute(0, 3, 1, 4, 2)x_new = x_new.reshape([self.num_batch, 1 * self.width, self.num_points * self.height])return y_new, x_new"""input: input feature map [N,C,D,W,H];coordinate map [N,K*D,K*W,K*H] output: [N,1,K*D,K*W,K*H] deformed feature map"""def _bilinear_interpolate_3D(self, input_feature, y, x):device = input_feature.devicey = y.reshape([-1]).float()x = x.reshape([-1]).float()zero = torch.zeros([]).int()max_y = self.width - 1max_x = self.height - 1# find 8 grid locationsy0 = torch.floor(y).int()y1 = y0 + 1x0 = torch.floor(x).int()x1 = x0 + 1# clip out coordinates exceeding feature map volumey0 = torch.clamp(y0, zero, max_y)y1 = torch.clamp(y1, zero, max_y)x0 = torch.clamp(x0, zero, max_x)x1 = torch.clamp(x1, zero, max_x)input_feature_flat = input_feature.flatten()input_feature_flat = input_feature_flat.reshape(self.num_batch, self.num_channels, self.width, self.height)input_feature_flat = input_feature_flat.permute(0, 2, 3, 1)input_feature_flat = input_feature_flat.reshape(-1, self.num_channels)dimension = self.height * self.widthbase = torch.arange(self.num_batch) * dimensionbase = base.reshape([-1, 1]).float()repeat = torch.ones([self.num_points * self.width * self.height]).unsqueeze(0)repeat = repeat.float()base = torch.matmul(base, repeat)base = base.reshape([-1])base = base.to(device)base_y0 = base + y0 * self.heightbase_y1 = base + y1 * self.height# top rectangle of the neighbourhood volumeindex_a0 = base_y0 - base + x0index_c0 = base_y0 - base + x1# bottom rectangle of the neighbourhood volumeindex_a1 = base_y1 - base + x0index_c1 = base_y1 - base + x1# get 8 grid valuesvalue_a0 = input_feature_flat[index_a0.type(torch.int64)].to(device)value_c0 = input_feature_flat[index_c0.type(torch.int64)].to(device)value_a1 = input_feature_flat[index_a1.type(torch.int64)].to(device)value_c1 = input_feature_flat[index_c1.type(torch.int64)].to(device)# find 8 grid locationsy0 = torch.floor(y).int()y1 = y0 + 1x0 = torch.floor(x).int()x1 = x0 + 1# clip out coordinates exceeding feature map volumey0 = torch.clamp(y0, zero, max_y + 1)y1 = torch.clamp(y1, zero, max_y + 1)x0 = torch.clamp(x0, zero, max_x + 1)x1 = torch.clamp(x1, zero, max_x + 1)x0_float = x0.float()x1_float = x1.float()y0_float = y0.float()y1_float = y1.float()vol_a0 = ((y1_float - y) * (x1_float - x)).unsqueeze(-1).to(device)vol_c0 = ((y1_float - y) * (x - x0_float)).unsqueeze(-1).to(device)vol_a1 = ((y - y0_float) * (x1_float - x)).unsqueeze(-1).to(device)vol_c1 = ((y - y0_float) * (x - x0_float)).unsqueeze(-1).to(device)outputs = (value_a0 * vol_a0 + value_c0 * vol_c0 + value_a1 * vol_a1 +value_c1 * vol_c1)if self.morph == 0:outputs = outputs.reshape([self.num_batch,self.num_points * self.width,1 * self.height,self.num_channels,])outputs = outputs.permute(0, 3, 1, 2)else:outputs = outputs.reshape([self.num_batch,1 * self.width,self.num_points * self.height,self.num_channels,])outputs = outputs.permute(0, 3, 1, 2)return outputsdef deform_conv(self, input, offset, if_offset):y, x = self._coordinate_map_3D(offset, if_offset)deformed_feature = self._bilinear_interpolate_3D(input, y, x)return deformed_feature蛇形动态卷积的主要处理流程包括以下几个关键步骤:
1. 输入图像或特征图
首先,将输入图像或上一级网络输出的特征图输入到蛇形动态卷积层中。
2. 特征生成网络
特征生成网络用于根据输入数据生成卷积核的权重。这个网络通常是一个小型的卷积网络或注意力机制,具体步骤如下:
-
提取特征:通过若干卷积层提取输入特征图的高维特征。
-
生成权重:使用特定的机制(如全连接层或注意力模块)生成卷积核的权重。这些权重是动态的,即根据当前输入数据生成,并随每个输入样本而变化。
3. 生成蛇形卷积核
根据特征生成网络输出的权重,生成蛇形卷积核。蛇形卷积核的形状和大小可能会根据任务需求进行调整,常见的做法包括:
-
核形状设计:定义卷积核的具体形状,使其呈现出类似蛇形的路径。
-
权重赋值:使用生成的权重对蛇形卷积核进行赋值。
4. 执行卷积操作
使用生成的蛇形卷积核对输入图像或特征图执行卷积操作。具体过程如下:
-
滑动窗口:卷积核在输入图像或特征图上以滑动窗口的方式移动,覆盖每一个局部区域。
-
点积运算:对于每一个局部区域,卷积核的权重与输入特征进行点积运算,生成新的特征值。
5. 输出特征图
卷积操作生成的输出特征图将被传递到下一层网络。这个特征图包含了经过蛇形动态卷积处理后的信息,更好地反映了输入图像的局部结构和复杂特征。
2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数

然后在下面的__all__中声明函数

2.3 添加yaml文件
关键步骤三:在/ultralytics/ultralytics/cfg/models/v8下面新建文件yolov8_DySnakeConv.yaml文件,粘贴下面的内容
*注:由于DySnakeConv并不改变图像大小,没有步长设置为2的过程。所以选择添加一层,通道数设置和输入一样,卷积核大小就为3。YOLOv8的ymal中没有不改变图像大小的conv,所以是无法替换的。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, DySnakeConv, [512,3]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)温馨提示:本文只是对yolov8l基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv8n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv8s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv8l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv8m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv8x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.4 在task.py中进行注册
关键步骤四:在parse_model函数中进行注册,添加DySnakeConv,

2.5 执行程序
关键步骤五:在ultralytics文件中新建train.py,将model的参数路径设置为yolov8_DySnakeConv.yaml的路径即可
建议大家写绝对路径,确保一定能找到
from ultralytics import YOLO# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v8/yolov8_SimRepCSP.yaml') # build from YAML and transfer weights# Train the model
model.train(device = [3], batch=16)🚀运行程序,如果出现下面的内容则说明添加成功🚀
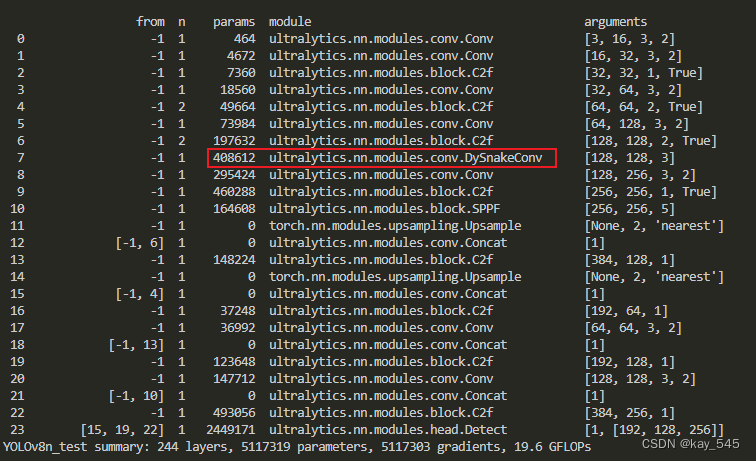
3. 完整代码分享
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的YOLOv8nGFLOPs
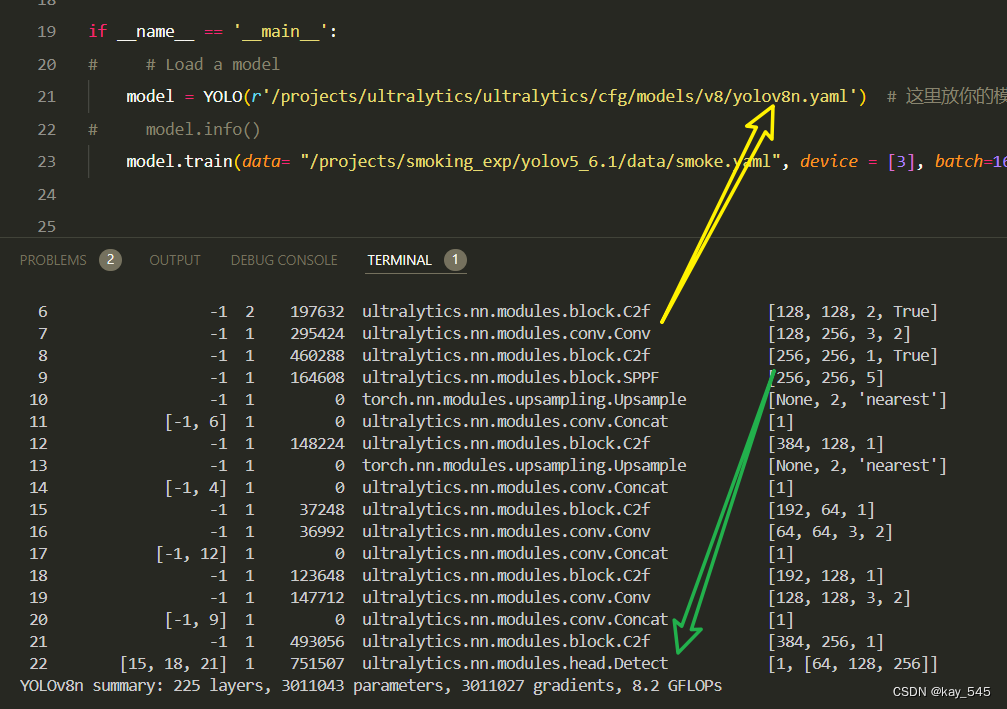
改进后的GFLOPs

5. 进阶
与c2f结合和添加不同位置的蛇形动态卷积
6. 总结
动态蛇形卷积通过引入灵活的、类似蛇形路径的卷积核和动态权重生成机制,提升卷积操作的适应性和特征表达能力。具体而言,它利用一个特征生成网络,根据输入图像或特征图动态生成卷积核的权重,并将这些权重赋予预定义的蛇形路径卷积核,以适应输入的局部结构。在卷积操作中,这些动态生成的卷积核能够更灵活地捕捉和表征图像中的复杂和多样化的特征,从而增强卷积神经网络在图像处理任务中的性能。
相关文章:
YOLOv8改进 | 卷积模块 | 在主干网络中添加/替换蛇形卷积Dynamic Snake Convolution
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 蛇形动态卷积是一种新型的卷积操作,旨在提高对细长和弯曲的管状结构的特征提取能力。它通过自适应地调整卷积核的权重࿰…...
)
深入解析力扣183题:从不订购的客户(LEFT JOIN与子查询方法详解)
关注微信公众号 数据分析螺丝钉 免费领取价值万元的python/java/商业分析/数据结构与算法学习资料 在本篇文章中,我们将详细解读力扣第183题“从不订购的客户”。通过学习本篇文章,读者将掌握如何使用SQL语句来解决这一问题,并了解相关的复杂…...

牛客NC32 求平方根【简单 二分 Java/Go/C++】
题目 题目链接: https://www.nowcoder.com/practice/09fbfb16140b40499951f55113f2166c 思路 Java代码 import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** para…...

王道408数据结构CH3_栈、队列
概述 3.栈、队列和数组 3.1 栈 3.1.1 基本操作 3.1.2 顺序栈 #define Maxsize 50typedef struct{ElemType data[Maxsize];int top; }SqStack;3.1.3 链式栈 typedef struct LinkNode{ElemType data;struct LinkNode *next; }*LiStack;3.2 队列 3.2.1 基本操作 3.2.2 顺序存储…...

Angular 由一个bug说起之六:字体预加载
浏览器在加载一个页面时,会解析网页中的html和css,并开始加载字体文件。字体文件可以通过css中的font-face规则指定,并使用url()函数指定字体文件的路径。 比如下面这样: css font-face {font-family: MyFont;src: url(path/to/font.woff2…...

并查集进阶版
过关代码如下 #define _CRT_SECURE_NO_WARNINGS #include<bits/stdc.h> #include<unordered_set> using namespace std;int n, m; vector<int> edg[400005]; int a[400005], be[400005]; // a的作用就是存放要摧毁 int k; int fa[400005]; int daan[400005]…...
贪心(不相交的开区间、区间选点、带前导的拼接最小数问题)
目录 1.简单贪心 2.区间贪心 不相交的开区间 1.如何删除? 2.如何比较大小 区间选点问题 3.拼接最小数 1.简单贪心 比如:给你一堆数,你来构成最大的几位数 2.区间贪心 不相交的开区间 思路: 首先,如果有两个…...

[力扣题解] 617. 合并二叉树
题目:617. 合并二叉树 思路 递归法遍历,随便一种遍历方式都可以,以前序遍历为例; 代码 class Solution { public:TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {if(root1 NULL){return root2;}if(root2 NULL){r…...
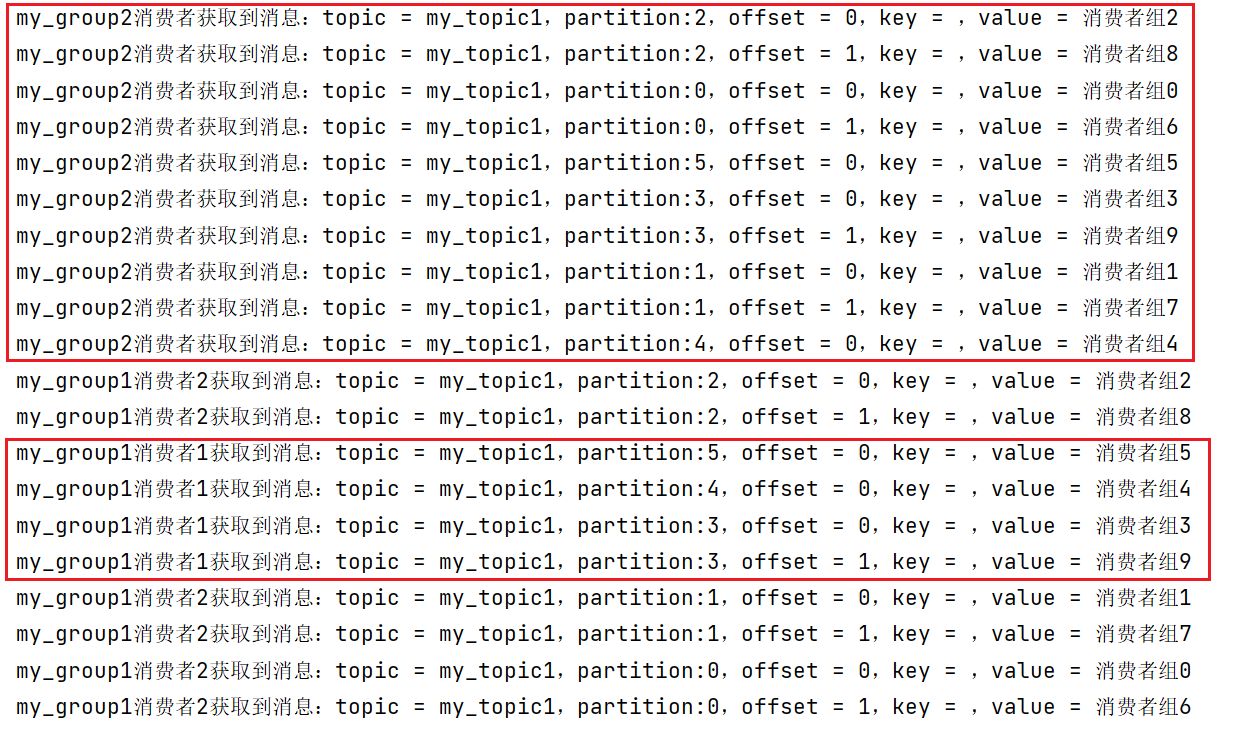
kafka-消费者组(SpringBoot整合Kafka)
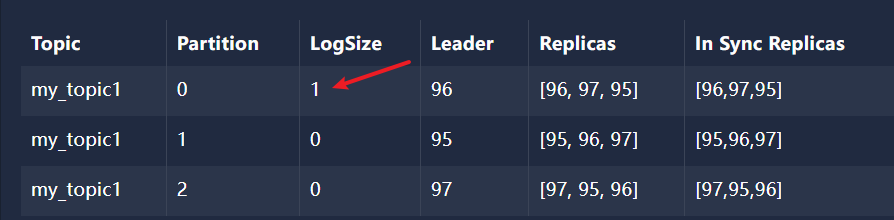
文章目录 1、消费者组1.1、使用 efak 创建 主题 my_topic1 并建立6个分区并给每个分区建立3个副本1.2、创建生产者发送消息1.3、application.yml配置1.4、创建消费者监听器1.5、创建SpringBoot启动类1.6、屏蔽 kafka debug 日志 logback.xml1.7、引入spring-kafka依赖1.8、消费…...

Redisson知识
使用Redission获取锁 RLock lock redisson.getLock("my-lock"); 一、Redisson使用不指定锁过期时间的方式加锁: lock.lock(); 特点: 1.使用Redisson加的锁,具有自动续期机制,如果业务运行时间较长,运行…...

0103__【C/C++ 单线程性能分析工具 Gprof】 GNU的C/C++ 性能分析工具 Gprof 使用全面指南
【C/C 单线程性能分析工具 Gprof】 GNU的C/C 性能分析工具 Gprof 使用全面指南-CSDN博客...
如何把几个pdf文件合成在一个pdf文件
PDF合并,作为一种常见的文件处理方式,无论是在学术研究、工作汇报还是日常生活中,都有着广泛的应用。本文将详细介绍PDF合并的多种方法,帮助读者轻松掌握这一技能。 打开 “轻云处理pdf官网” 的网站,然后上传pdf。 pd…...

Stream与MLC测试CPU内存DDR5的原理与方法详解
在高性能计算和服务器领域,内存性能是决定整体系统性能的关键因素之一,特别是随着DDR5内存的普及,其更高的带宽和更低的延迟特性使得内存性能测试变得更加重要。本文将详细介绍使用Stream和MLC两种工具对CPU内存DDR5进行性能测试的原理和实施…...
linux业务代码性能优化点
planning优化的一些改动----------> 减少值传递,多用引用来传递 <---------- // ----------> 减少值传递,多用引用来传递 <---------- // 例1: class A{}; std::vector<A> v; // for(auto elem : v) {} // 不建议ÿ…...

Shell脚本学习_字符串变量
目录 1.Shell字符串变量:格式介绍 2.Shell字符串变量:拼接 3.Shell字符串变量:字符串截取 4.Shell索引数组变量:定义-获取-拼接-删除 1.Shell字符串变量:格式介绍 1、目标: 能够使用字符串的三种方式 …...
spring-kafka-生产者服务搭建测试(SpringBoot整合Kafka)
文章目录 1、生产者服务搭建1.1、引入spring-kafka依赖1.2、application.yml配置----v1版1.3、使用Java代码创建主题分区副本1.4、发送消息 1、生产者服务搭建 1.1、引入spring-kafka依赖 <?xml version"1.0" encoding"UTF-8"?> <project xml…...
JVM学习-内存泄漏
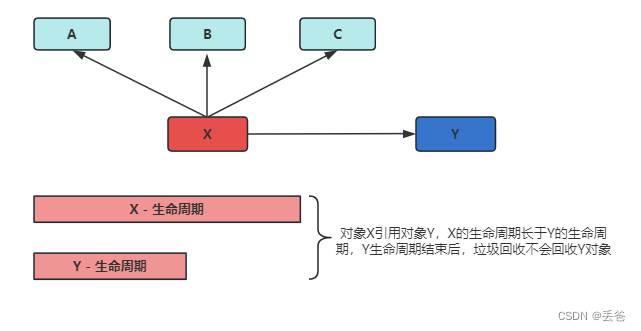
内存泄漏的理解和分类 可达性分析算法来判断对象是否是不再使用的对象,本质都是判断一上对象是否还被引用,对于这种情况下,由于代码的实现不同就会出现很多内存泄漏问题(让JVM误以为此对象还在引用,无法回收,造成内存泄…...
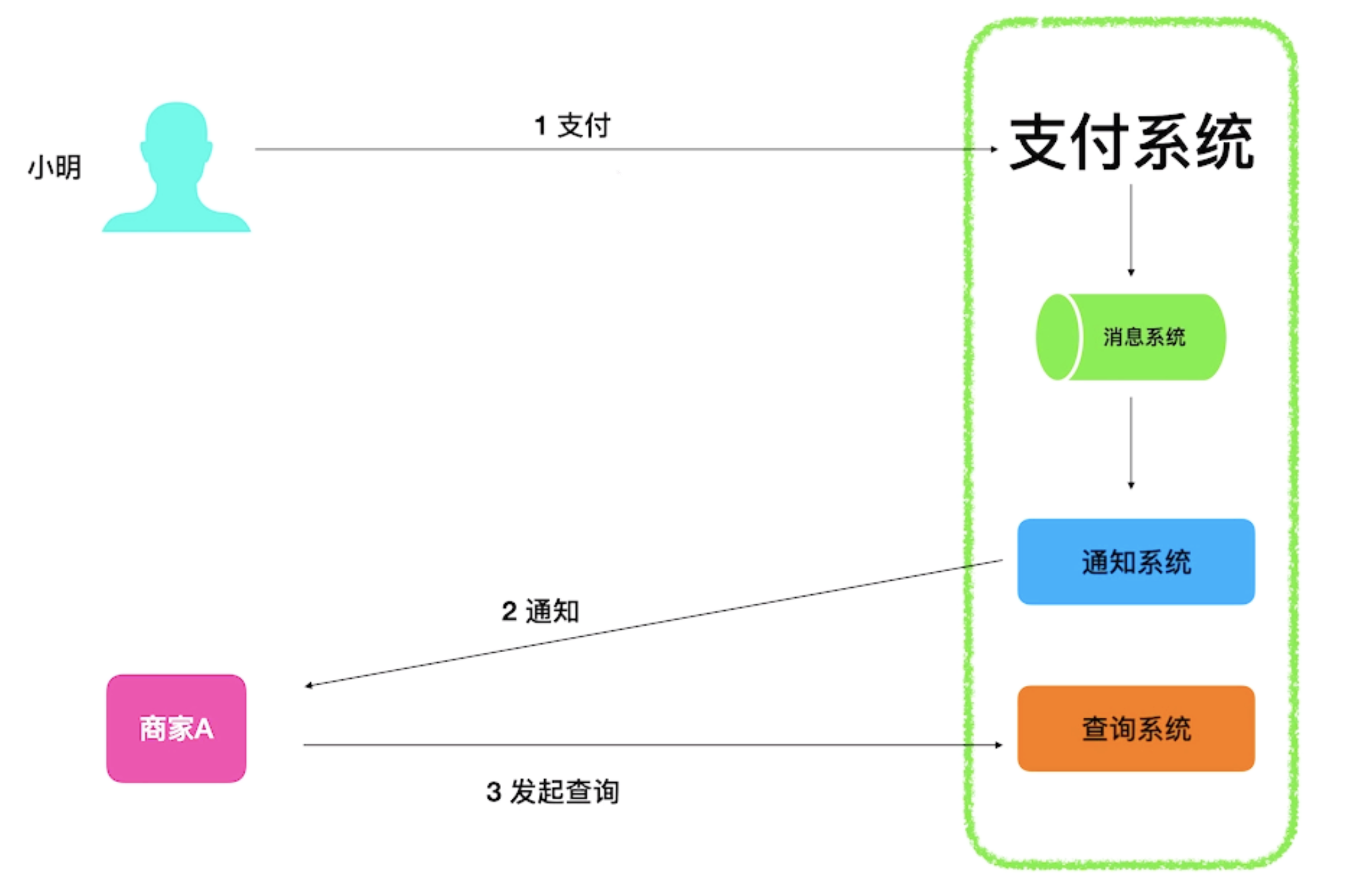
Go微服务: 分布式之通过本地消息实现最终一致性和最大努力通知方案
通过本地消息实现最终一致性 1 )概述 我们的业务场景是可以允许我们一段时间有不一致的消息的状态的,并没有说必须特别高的这个消息的一致性比如说在TCC这个架构中,如果采用了消息的最终一致性,整体架构设计要轻松好多即便我们库…...
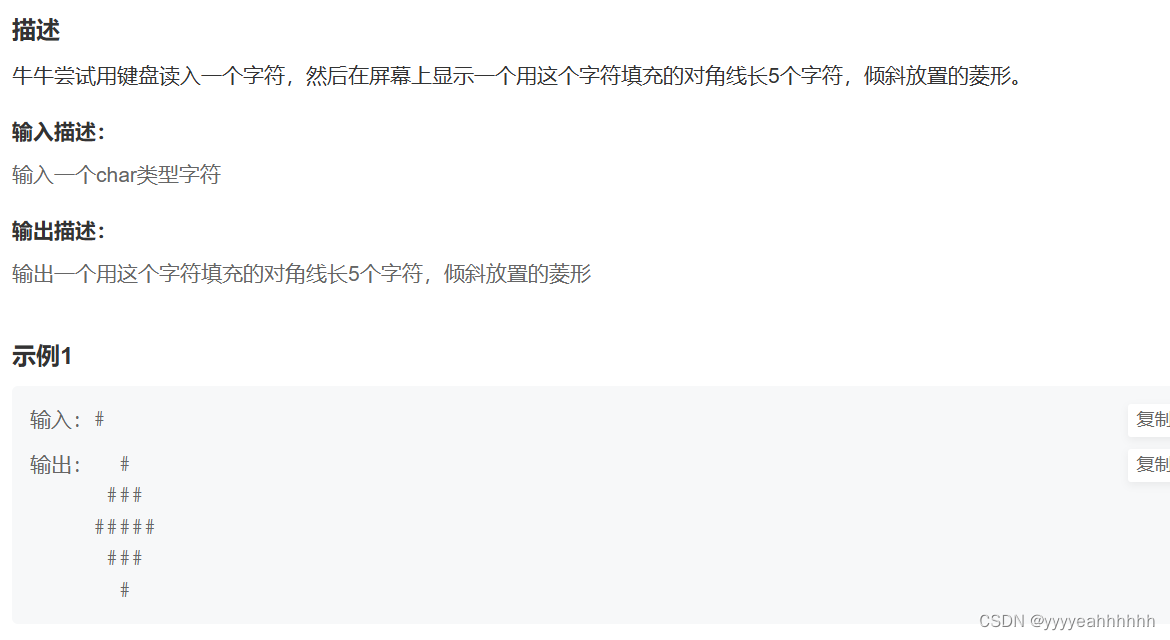
BC C language
题目汇总 No.1 打印有规律的字符(牛牛的字符菱形) 代码展示 #include<stdio.h> int main() {char ch0;scanf("%c",&ch);for(int i0;i<5;i){for(int j0;j<5;j){if((i0||i4)&&j2)printf("%c", ch);else if ((i 1||i3) &&…...

算法训练营第四十九天 | LeetCode 139单词拆分
LeetCode 139 单词拆分 基本还是完全背包的思路,不过用了三重循环,第三重循环是用于判断当前字符串尾部指定长度字符是否和列表中某一字符串相同,是的话可以将当前dp[j]或上当前下标减去该单词长度后的下标值。 代码如下: clas…...

自动驾驶人机交接:DMS与安全验证如何破解控制权转移困局
1. 自动驾驶人机交接的核心困境与行业分野最近几年,自动驾驶(AV)和高级驾驶辅助系统(ADAS)无疑是汽车科技领域最炙手可热的话题。无论是传统车企的“新四化”转型,还是科技公司的颠覆性入局,大家…...

VCF 9.1 新特性:安装器与 Fleet Depot 支持 HTTP 无认证离线软件源
VMware Cloud Foundation(VCF)9.0 推出了统一软件仓库(Software Depot),支持连接博通在线源或企业内部离线源。但在 9.0 中,离线源默认必须使用 HTTPS 基础认证,即使关闭 HTTPS 也依然需要认证,对纯内网环境很不友好。在 VCF 9.1…...

从怀疑到真香!2026年我亲测十多款语音识别转文字app只留这一个
开完2小时讨论会,你要花3小时逐句整理纪要?采访了3个受访者,你戴耳机听一天录音,还漏了一半核心观点?做方言访谈,转出来的文字驴唇不对马嘴,你还要返工重听? 这些磨人的痛点…...

Encaustic不是滤镜!揭秘热蜡媒介物理特性如何反向重构MJ提示词结构:材料科学×AIGC的跨学科实践
更多请点击: https://intelliparadigm.com 第一章:Encaustic不是滤镜!——热蜡媒介的本质祛魅 Encaustic(热蜡绘画)常被误认为是数字图像处理中的一种“复古滤镜”,实则是一种拥有两千多年历史的实体绘画媒…...
)
别再只盯着原理图了!用Python+OpenCV动手模拟激光三角测距(斜射/直射对比)
用PythonOpenCV模拟激光三角测距:斜射与直射的实战对比 激光三角测距技术听起来高大上,但真正理解它的精髓往往需要跳出公式推导的泥潭。作为一名长期在工业检测领域摸爬滚打的技术人员,我发现用代码模拟物理过程是最有效的学习方式。本文将…...

别再只会用Broadside了!手把手教你用Endfire阵列搞定智能音箱的远场拾音
智能音箱远场拾音实战:从Broadside到Endfire的工程进阶指南 当你的智能音箱在厨房油烟机轰鸣时依然能清晰识别"播放爵士乐"指令,或是会议设备在开放式办公室准确捕捉三米外的发言——这背后往往是Endfire阵列的精密调校在发挥作用。作为嵌入式…...

一、NodeMCU-32S核心功能与上手场景解析
1. NodeMCU-32S开发板的核心特性解析 第一次拿到NodeMCU-32S这块开发板时,我就被它小巧的尺寸和丰富的接口吸引了。作为基于ESP32芯片设计的开发板,它最大的亮点就是双核处理器和Wi-Fi/蓝牙双模无线功能。这两个特性让它在物联网项目中特别吃香ÿ…...

英雄联盟Akari助手:5大核心功能提升你的游戏体验终极指南
英雄联盟Akari助手:5大核心功能提升你的游戏体验终极指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否厌倦了在英雄联盟对…...

终极指南:如何5分钟搞定B站字幕提取与格式转换
终极指南:如何5分钟搞定B站字幕提取与格式转换 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 你是否曾为保存B站视频中的精彩内容而烦恼?…...

一屏融汇虚实 一擎驱动孪生:云边端协同架构赋能,打造城市园区港口通用数字孪生底座
一屏融汇虚实 一擎驱动孪生副标题:云边端协同架构赋能,打造城市园区港口通用数字孪生底座前言随着数字孪生向全域覆盖、多场景复用、高并发承载、实时性联动纵深发展,行业普遍面临场景割裂、架构分散、算力错配、底座不通用等痛点。城市、园区…...