spark-3.5.1+Hadoop 3.4.0+Hive4.0 分布式集群 安装配置
Hadoop安装参考:
Hadoop 3.4.0+HBase2.5.8+ZooKeeper3.8.4+Hive4.0+Sqoop 分布式高可用集群部署安装 大数据系列二-CSDN博客
一 下载:
Downloads | Apache Spark
1 下载Maven – Welcome to Apache Maven
# maven安装及配置教程
wget https://dlcdn.apache.org/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz
#
tar zxvf apache-maven-3.8.8-bin.tar.gz
mv apache-maven-3.8.8/ /usr/local/maven
#vi /etc/profile
export MAVEN_HOME=/usr/local/maven
export PATH=$PATH:$MAVEN_HOME/bin
#source /etc/profile
#查看版本
root@slave13 soft]# mvn --version
Apache Maven 3.8.8 (4c87b05d9aedce574290d1acc98575ed5eb6cd39)
Maven home: /usr/local/maven
Java version: 1.8.0_191, vendor: Oracle Corporation, runtime: /usr/local/jdk/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.18.0-348.el8.x86_64", arch: "amd64", family: "unix"2 下载:Scala 2.13.14 | The Scala Programming Language
#解压
tar zxvf scala-2.13.14.tgz
sudo mv scala-2.13.14/ /usr/local/scala
sudo vi /etc/profile
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
#查看版本
scala -version
Scala code runner version 2.13.14 -- Copyright 2002-2024, LAMP/EPFL and Lightbend, Inc.3 安装spark
#解压
tar zxvf spark-3.5.1-bin-hadoop3.tgz
sudo mv spark-3.5.1-bin-hadoop3/ /usr/local/spark/
#配置环境变量(slave12,slave13同样配置)
sudo vi /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
source /etc/profile
#配置环境变量
cd /usr/local/spark/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop/
export SPARK_MASTER_HOST=master11
export SPARK_LIBRARY_PATH=/usr/local/spark/jars
export SPARK_WORKER_MEMORY=2048m
export SPARK_WORKER_CORES=2
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8082
export SPARK_DIST_CLASSPATH=$(/data/hadoop/bin/hadoop classpath)
#修改workers配置文件
cp workers.template workers
vim workers
slave12
slave13
#分发文件到slave12,slave13
scp -r /usr/local/spark/ slave12:/usr/local/
scp -r /usr/local/spark/ slave13:/usr/local/
scp -r /usr/local/scala/ slave12:/usr/local/
scp -r /usr/local/scala/ slave13:/usr/local/二 启动
#master11启动
[root@master11 ~]# /usr/local/spark/sbin/start-all.sh#报错
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/Loggerat java.lang.Class.getDeclaredMethods0(Native Method)at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)at java.lang.Class.privateGetMethodRecursive(Class.java:3048)at java.lang.Class.getMethod0(Class.java:3018)at java.lang.Class.getMethod(Class.java:1784)at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.slf4j.Loggerat java.net.URLClassLoader.findClass(URLClassLoader.java:382)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 7 more
#解决
cd /usr/local/spark/jars/
wget https://repo1.maven.org/maven2/org/slf4j/slf4j-api/1.7.9/slf4j-api-1.7.9.jar
wget https://repo1.maven.org/maven2/org/slf4j/slf4j-nop/1.7.9/slf4j-nop-1.7.9.jar#启动
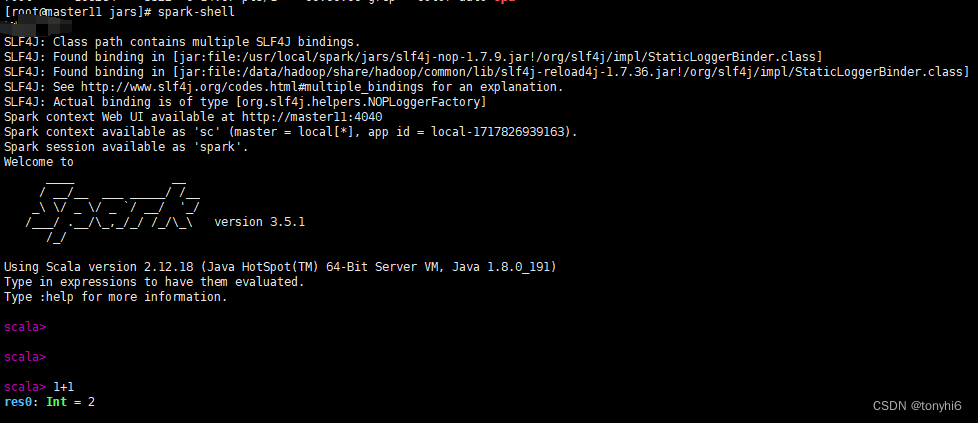
[root@master11 ~]# /usr/local/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master11.out
slave12: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave12.out
slave13: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave13.out
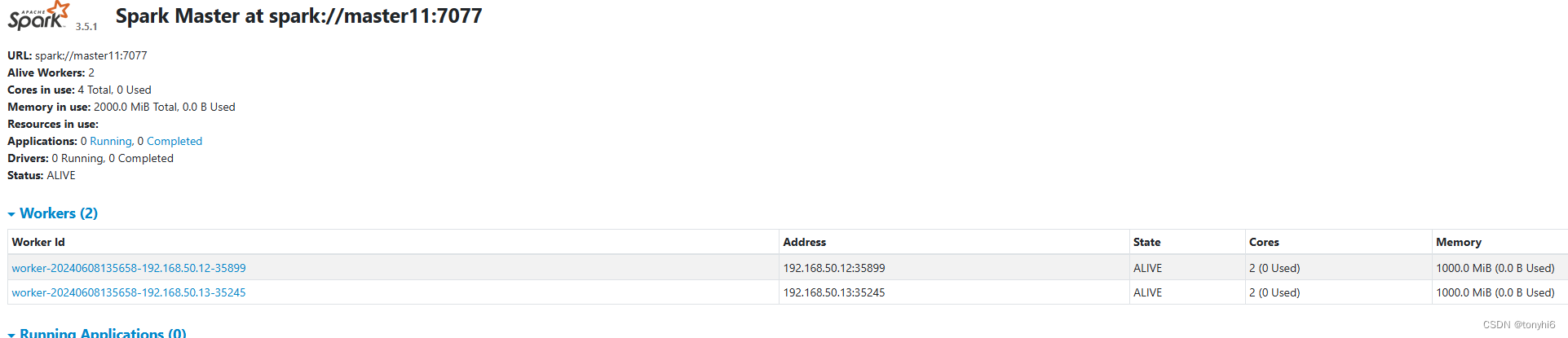
#查看 如下图



三 Spark 与Hive 集成
1 拷贝配置文件和Mysql 驱动
cp /data/hive/conf/hive-site.xml /usr/local/spark/conf/
cp /data/hadoop/etc/hadoop/hdfs-site.xml /usr/local/spark/conf/
cp /data/hadoop/etc/hadoop/core-site.xml /usr/local/spark/conf/
cp /data/hive/lib/mysql-connector-java-8.0.29.jar /usr/local/spark/jars/2 登录hive,创建测试表
hive
create database testdb;
use testdb;
create table test(id int,name string) row format delimited fields terminated by ',';
#创建测试文件
cat /root/test.csv
1,lucy
2,lili
#导入数据
load data local inpath '/root/test.csv' overwrite into table test;3 启动 spark-sql
spark-sql --master spark://master11:7077 --executor-memory 512m --total-executor-cores 2 --driver-class-path /usr/local/spark/jars/mysql-connector-java-8.0.29.jar
spark-sql (default)> show databases;
namespace
default
testdb
Time taken: 2.918 seconds, Fetched 2 row(s)
spark-sql (default)> use testdb;
Response code
Time taken: 0.478 seconds
spark-sql (testdb)> show tables;
namespace tableName isTemporary
test
Time taken: 0.454 seconds, Fetched 1 row(s)
spark-sql (testdb)> select * from test;
id name
1 lcuy
2 lili
Time taken: 4.126 seconds, Fetched 2 row(s)相关文章:
spark-3.5.1+Hadoop 3.4.0+Hive4.0 分布式集群 安装配置
Hadoop安装参考: Hadoop 3.4.0HBase2.5.8ZooKeeper3.8.4Hive4.0Sqoop 分布式高可用集群部署安装 大数据系列二-CSDN博客 一 下载:Downloads | Apache Spark 1 下载Maven – Welcome to Apache Maven # maven安装及配置教程 wget https://dlcdn.apache.org/maven/maven-3/3.8…...

Matlab实现GWO-CNN-LSTM-Mutilhead-Att灰狼算法卷积长短期记忆神经网络融合多头注意力机制预测 SCI顶级优化
数据预处理:准备和清理数据,包括数据的加载、特征提取、归一化等。 GWO (灰狼算法) 的实现:根据灰狼算法的原理和公式,编写 MATLAB 代码来初始化灰狼群体、计算适应度函数、更新位置等。 CNN (卷积神经网络) 的构建:使…...

RTKLIB之RTKPLOT画图工具
开源工具RTKLIB在业内如雷贯耳,其中的RTKPLOT最近正在学习,发现其功能之强大,前所未见,打开了新的思路。 使用思博伦GSS7000卫星导航模拟器,PosApp软件仿真一个载具位置 1,RTKPLOT支持DUT 串口直接输出的NMEA数据并…...

本地部署 RAGFlow
本地部署 RAGFlow 0. RAGFlow 是什么?1. 安装 wsl-ubuntu2. (可选)配置清华大学软件源3. 系统更新和安装构建工具4. 安装 Miniconda35. 安装 CUDA Toolkit6. 安装 git lfs7. 配置 Hugging Face 的缓存路径8. 配置 vm.max_map_count9. 安装 Docker Engine10. 安装 nginx11. 本地…...

php常用数据库操作
文章目录 PHP操作1. mysqli_connect() 连接数据库2. mysqli_close() 关闭数据库3. mysqli_num_rows 查询结果集中的行数4. mysqli_select_db 选择数据库的函数5. mysqli_query 常规的插入查找等6. header( )7.防止 sql 注入 PHP操作 1. mysqli_connect() 连接数据库 2. mysql…...
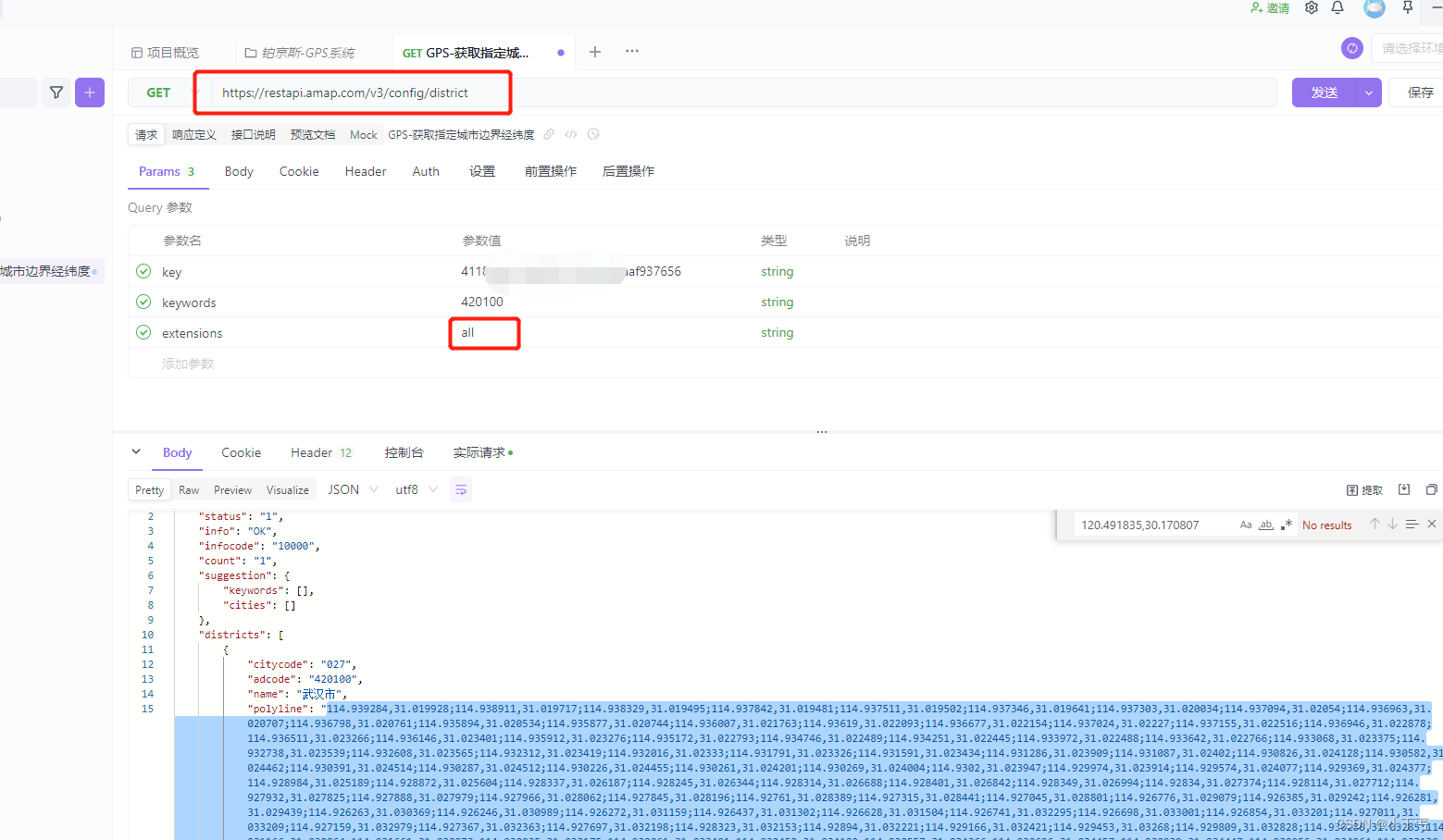
判断经纬度是否在某个城市内
一、从高德获取指定城市边界经纬度信息 通过apifox操作: 二、引入第三方jar包: maven地址:https://mvnrepository.com/ maven依赖: <dependency><groupId>org.locationtech.jts</groupId><artifactId>…...
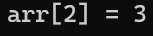
Java——数组排序和查找
一、排序介绍 1、排序的概念 排序是将多个数据按照指定的顺序进行排列的过程。 2、排序的种类 排序可以分为两大类:内部排序和外部排序。 3、内部排序和外部排序 1)内部排序 内部排序是指数据在内存中进行排序,适用于数据量较小的情况…...

Flutter中防抖动和节流策略
什么是防抖和节流? 函数节流(throttle)与 函数防抖(debounce)都是为了限制函数的执行频次,以优化函数触发频率过高导致的响应速度跟不上触发频率,出现延迟,假死或卡顿的现象 是应对频…...

设计模式-中介者(调停者)模式(行为型)
中介者模式 中介者模式是一种行为型模式,又叫调停者模式,它是为了解决多个对象之间,多个类之间通信的复杂性,定义一个中介者对象来封装一些列对象之间的交互,使各个对象之间不同持有对方的引用就可以实现交互…...

HC-05蓝牙模块配置连接和使用
文章目录 1. 前期准备 2. 进入AT模式 3. 电脑串口配置 4. 配置过程 5. 主从机蓝牙连接 6. 蓝牙模块HC-05和电脑连接 1. 前期准备 首先需要准备一个USB转TTL连接器,电脑安装一个串口助手,然后按照下面的连接方式将其相连。 VCCVCCGNDGNDRXDTXDTXD…...

云上小知识:企业选择云服务的小Tips
企业在选择云服务模式时,应综合考虑以下几个关键因素: 1. 业务需求与场景 企业需要根据自身的业务特点和需求来选择合适的云服务模式。例如,如果企业的用户分布广泛,需要跨地域提供服务,那么公有云可能是更好的选择。…...

生成式人工智能 - Stable Diffusion 都使用了哪些技术?
一、Stable Diffusion简述 1、简述 Stable Diffusion在2022年8月开源,是由慕尼黑大学的CompVis研究团队开发的生成式人工神经网络。该项目由初创公司StabilityAI、CompVis和Runway合作开发,并得到了EleutherAI和LAION的支持。截至2022年10月,StabilityAI已筹集了1.01亿美元…...

React的useState的基础使用
import {useState} from react // 1.调用useState添加状态变量 // count 是新增的状态变量 // setCount 修改状态变量的方法 // 2.添加点击事件回调 // userState实现计数实例import {useState} from react// 使用组件 function App() {// 1.调用useState添加状态变量// coun…...
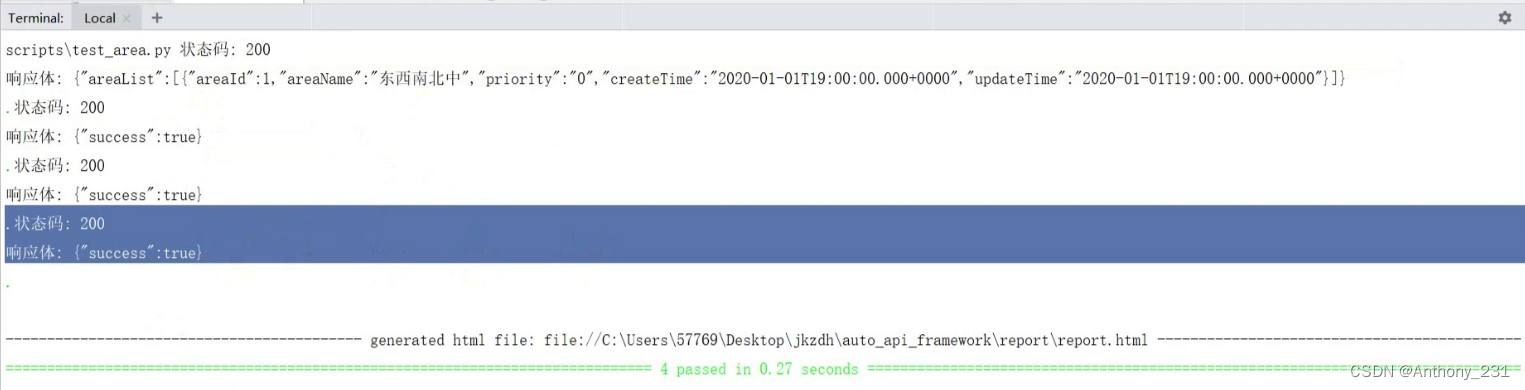
接口自动化Requests+Pytest基础实现
目录 1. 数据库以及数据库操作1.1 概念1.2 分类1.3 作用 2 python操作数据库的相关实现2.1 背景2.2 相关实现 3. pymysql基础3.1 整个流程3.2 案例3.3 Pymysql工具类封装 4 事务4.1 案例4.2 事务概念4.3 事务特征 5. requests库5.1 概念5.2 角色定位5.3 安装5.4 校验5.5 reques…...

深入解析Kafka消息传递的可靠性保证机制
深入解析Kafka消息传递的可靠性保证机制 Kafka在设计上提供了不同层次的消息传递保证,包括at most once(至多一次)、at least once(至少一次)和exactly once(精确一次)。每种保证通过不同的机制…...

jEasyUI 设置排序
jEasyUI 设置排序 jEasyUI 是一个基于 jQuery 的框架,用于轻松构建交互式的 Web 应用程序。它提供了一系列的 UI 组件,如表格(datagrid)、树(tree)、下拉列表(combobox)等,这些组件可以帮助开发者快速实现复杂的界面功能。在本文中,我们将重点讨论如何在 jEasyUI 中…...
)
MySQL之查询性能优化(十二)
查询性能优化 优化COUNT()查询 4.使用近似值 有时候某些业务场景并不要求完全精确的COUNT值,此时可以用近似值来代替。EXPLAIN出来的优化器估算的行数就是一个不错的近似值,执行EXPLAIN并不需要真正地去执行查询,所以成本很低。很多时候&am…...

7-16 二分查找
7-16 二分查找 分数 25 全屏浏览 切换布局 作者 李廷元 单位 中国民用航空飞行学院 请实现有重复数字的有序数组的二分查找。 输出在数组中第一个大于等于查找值的位置,如果数组中不存在这样的数,则输出数组长度加一。 输入格式: 输入第一行有两个…...
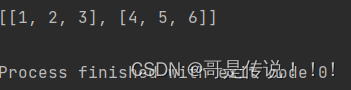
对Java中二维数组的深层认识
首先,在JAVA中,二维数组是一种数组的数组。它可以看作是一个矩阵,通常是由于表示二维数据节后,如表格和网格。 1.声明和初始化二维数组 声明 int[][] arr;初始化 int[][] arrnew int[3][4];或者用花括号嵌套 int[][] arr{{1,…...

C++的STL 中 set.map multiset.multimap 学习使用详细讲解(含配套OJ题练习使用详细解答)
目录 一、set 1.set的介绍 2.set的使用 2.1 set的模板参数列表 2.2 set的构造 2.3 set的迭代器 2.4 set的容量 2.5 set的修改操作 2.6 set的使用举例 二、map 1.map的介绍 2.map的使用 2.1 map的模板参数说明 2.2 map的构造 2.3 map的迭代器 2.4 map的容量与元…...

连接器选型三张“底牌”:电源、高速、射频的隐性代价与系统级权衡
当产品进入量产阶段,连接器往往是“压死骆驼的最后一根稻草”。它不像芯片那样有明确的数据手册边界,也不像PCB那样可归咎于Layout规则。连接器的失效模式高度依赖“配合状态”——插拔了几次?压接用了什么工具?相邻器件发热多少&…...

IP第一次作业
...

K8s网络插件Flannel与Calico:从原理到实战的选型与部署指南
1. Kubernetes网络插件基础认知 刚接触Kubernetes时,最让我头疼的就是容器网络问题。为什么Pod之间需要通信?为什么有的服务跨节点就访问不了?这些问题的答案都藏在CNI(Container Network Interface)插件里。Flannel和…...

5G上行免调度传输:开启无线通信新篇章
5G上行免调度传输:开启无线通信新篇章 在无线通信技术不断演进的浪潮中,5G以其高速率、低时延和大连接等特性,成为推动社会数字化转型的关键力量。其中,上行免调度传输作为5G技术体系中的一个重要环节,正逐步展现出其独…...

从 Classic ABAP 走到 ABAP Cloud,开发习惯、架构边界与 Clean Core 的重新建立
今天还在做 SAP S/4HANA 项目的人,大多已经感受到一个很现实的变化,真正难迁移的,从来不只是几段旧代码,也不只是把 SE80 里的对象搬到一个新工具里,而是整个开发思路要重新校准。以前很多团队习惯把 ABAP 当成一个紧贴业务系统内核的实现层,屏幕逻辑、数据库访问、增强点…...

DISTINCT 带 WHERE 仍全表扫描?两层优化刀法拆解
DISTINCT 带 WHERE 仍全表扫描?两层优化刀法拆解 引言:一个看似多余的 DISTINCT,藏着性能陷阱 几乎每个写过 SQL 的人都用过 DISTINCT。它的语义很简单——去掉重复行。但"简单"不等于"快"。在一个客户的生产环境中&…...

《Java 100 天进阶之路》第1篇:编程语言类型有哪些?我心中的TOP1编程语言,什么是Java跨平台性?
第1篇:编程语言类型有哪些?我心中的TOP1编程语言,什么是Java跨平台性? 一、核心知识点 编程语言的三大类型:机器语言、汇编语言、高级语言Java为什么是“一次编写,到处运行”(跨平台原理&…...

鸿蒙与 H5 通信使用的方法及原理
鸿蒙(HarmonyOS)与 H5 的通信主要通过 Web 组件(WebView) 实现,支持多种机制以满足不同场景需求。一、通信方法1. runJavaScript() 方法(原生 → H5)鸿蒙原生侧通过 WebviewControl…...

英文论文降AIGC教程:2026最新实测3款工具与逻辑重塑避坑指南
赶稿季来临,英文长稿的AI率到底该怎么降?不少同学愁的头都要秃了,不要再一个词一个词的扣了,这不仅慢,还会把好好的学术英语改得支离破碎。 坦率的讲,真正聪明的降ai,绝对不是机械替换…...

【STM32F407 DSP实战】矩阵运算基础:从初始化到加减法与求逆的嵌入式实现
1. 为什么要在STM32F407上实现矩阵运算 在嵌入式开发中,矩阵运算可以说是无处不在。从简单的PID控制到复杂的图像处理算法,都离不开矩阵这个基础数据结构。就拿我最近做的一个四轴飞行器项目来说,姿态解算部分就需要频繁地进行矩阵乘法、求逆…...