LLVM Cpu0 新后端10
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
LLVM 后端实践笔记
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?pwd=vd6s 提取码: vd6s
一、第一节 汇编器
独立汇编器可以理解为依赖于 LLVM 后端提供的接口实现的一个独立软件,因为 LLVM 和 gcc 在这个地方的实现逻辑不一样。
在 gcc 中,编译器和汇编器是两个独立的工具,编译器,也就是 cc,只能生成汇编代码,而汇编器 as,才用来将汇编代码翻译为二进制目标代码,gcc 驱动软件 gcc 将这些工具按顺序驱动起来(还包括预处理器、链接器等),最终实现从 C 语言到二进制目标代码的功能。但是,这样的设计有个缺点,每个工具都需要先对输入文件做 parse,然后再输出时写入文件,反复多次的磁盘读写一定程度影响了编译的效率。
而在 LLVM 中,编译器后端本身就可以将中间代码(对应 gcc 中 cc 的中间表示)翻译成二进制目标文件,而不需要发射汇编代码到文件中,再重新 parse 汇编文件。当然它也可以通过配置命令行参数指定将中间代码翻译成汇编代码,方便展示底层程序逻辑。
但我们目前已经实现的这些功能,却无法支持输入汇编代码,输出二进制目标文件,虽然通常情况下已经不再需要手工编写汇编代码,但在特殊情况下,比如引导程序、调试特殊功能、需要优化性能等场合下,还是需要编写汇编代码,所以一个汇编器依然是很重要的。
显然,我们之前的章节已经把和指令相关的汇编表示都在 TableGen 中实现了,这一节中,最核心的就是实现一个汇编器的 parser,并将其注册到 LLVM 后端框架中,并使能汇编功能。并且,汇编器的核心功能在 LLVM 中也已经实现了,原理其实就是一个语法制导的翻译,我们要做的只是重写其中部分和后端架构相关的接口。
我还实现了一个额外的特性。当我们仅使用汇编器时,编译器占用的寄存器 $sw,就可以被释放出来当做普通寄存器用了,所以我们重新定义一下 GPROut 这个寄存器类别,并将 Cpu0.td 拆分成两份,将它拆分为 Cpu0Asm.td 和 Cpu0Other.td,前者会在调用汇编器时被使用到,而后者保持和之前一样的设计。
因为 $sw 寄存器是编译器用来记录状态的,如果只编写汇编代码,我们认为程序员有义务去维护这个寄存器中的值什么时候是有效的,进而程序员就可以在认为这个寄存器中值无效时,把它当做普通寄存器来使用。我们的标量寄存器有很多,多这样一个寄存器的意义并不是很大,这里依然这么做,其实是想展示一下 TableGen 机制的灵活性。
在 Cpu0 的后端代码路径下,新建一个子目录 AsmParser,在这个路径下新建 Cpu0AsmParser.cpp 用来实现绝大多数功能。
1.1 修改前的效果
llvm-mc -triple=cpu0 -filetype=obj test.s -o test.o
提示我们当前的汇编器不支持cpu0架构。llvm-mc是llvm的汇编器,能够将汇编文件.s编成目标文件.o。
1.2 修改
1.2.1 AsmParser/Cpu0AsmParser.cpp
作为一个独立的功能模块,使能它的 DEBUG 信息名称为 cpu0-asm-parser,声明一些新的 class: Cpu0AsmParser 作为核心类,用来处理所有汇编 parser 的工作,我们稍后介绍;Cpu0AssemblerOptions 这个类用来做汇编器参数的管理;Cpu0Operand 类用来解析指令操作数,因为指令操作数可能有各种不同的类型,所以将这部分单独抽出来实现。
Cpu0AsmParser 类继承了基类 MCTargetAsmParser,并重写了部分接口,而有关于汇编 parser 的详细逻辑可以参考 AsmParser.cpp 中的实现。两个比较重要的重写函数:ParseInstruction() 和MatchAndEmitInstruction()。汇编器在做 parser 时,要先做 Parse,然后再对符合语法规范的指令做指令匹配,前者的关键函数就是ParseInstruction(),后者的关键函数就是MatchAndEmitInstruction()。
在 ParseInstruction() 中,根据传入的词法记号,解析指令助记符存入 Operands 容器中,然后在后边依次解析每个操作数,也存入 Operands 中。对于不满足语法规范的输入,比如操作数之间缺逗号等这种问题,直接报错并退出。在解析操作数时,调用了 ParseOperand() 接口,这也是一个很重要的接口,专用来解析操作数,我们也重写了这个接口以适应我们的类型,尤其是地址运算符。ParseInstruction() 执行完毕后会返回到 AsmParser.cpp 中的 parseStatement 方法中,并在做一些分析后,再调用到 MatchAndEmitInstruction() 方法。
在 MatchAndEmitInstruction() 函数中,将 Operands 容器对象传入。首先调用 MatchInstructionImpl 函数,这个函数是 TableGen 参考我们的指令 td 文件生成的 Cpu0GenAsmMatcher.inc 文件自动生成的。匹配之后如果成功了,还需要做额外的处理,如果这个是伪指令,需要汇编器展开,这种指令我们设计了几条,在之后会提到,这种指令需要调用 expandInstruction() 函数来展开,后者根据对应指令调用对应的展开函数,如果不是伪指令,就调用 EmitInstruction() 接口来发射编码,这个函数与我们前边章节设计指令输出的接口是同一个,也就是说在汇编 parser 之后的代码,是复用了之前的代码。匹配如果失败了,则做简单处理并返回,这里我们只实现了几种简单的情况,如果你的后端有一些 TableGen 支持不了的指令形式,也可以在这里做额外的处理,不过还是尽量去依赖 TableGen 的匹配表为好。
在 ParseOperand() 函数中,将前边 parse 出来的 Operands 容器对象传入。首先调用 MatchOperandParserImpl() 函数来 parse 操作数,这个函数也是 Cpu0GenAsmMatcher.inc 文件中定义好的。如果这个函数 parse 成功,就返回, 否则继续在下边完成一些自定义的 parse 动作,在一个 switch 分支中,根据词法 token 的类型来分别处理。其中,对于 Token,可能是一个寄存器,调用 tryParseRegisterOperand() 函数来处理,如果没有解析成功,则按照标识符处理;对于标识符、加减运算符和数字等 Token 的情况,统一调用 parseExpression() 来处理;对于百分号 Token,表示可能是一个重定位信息,比如 %hi($r1),则调用 parseRelocOperand() 函数来处理。
其他函数就不一一说明了,其中包括很多在 parse 操作数时,不同的操作数下的特殊处理,还有伪指令的展开动作,重定位操作数的格式解析以及生成重定位表达式,寄存器、立即数的 parse,还有汇编宏指令的解析(比如 .macro, .cpload 这一类)。
在最后,这些代码都实现完毕后,需要调用 RegisterMCAsmParser 接口将汇编 parser 注册到 LLVM 中,这个步骤写入到 LLVMInitializeCpu0AsmParser() 函数中。
1.2.2 Cpu0RegisterInfoGPROutForAsm.td
在这个文件中,我们定义的 GPROut 类别是支持完整的 CPURegs 的。
1.2.3 Cpu0RegisterInfoGPROutForOther.td
在这个文件中,我们定义的 GPROut 类别不包含 $sw 寄存器。
1.2.4 Cpu0Asm.td
由 Cpu0.td 拆分出来的文件,和 Cpu0Other.td 对应。
1.2.5 Cpu0Other.td
由 Cpu0.td 拆分出来的文件,和 Cpu0Asm.td 对应。
1.2.6 Cpu0.td
删掉 Target.td、Cpu0RegisterInfo.td 文件的包含。添加汇编器 parser 在 td 中的定义,并注册到 Cpu0 的属性中。这些都是常规操作。
1.2.7 Cpu0InstrFormats.td
增加针对伪指令的描述性 class,继承自 Cpu0Pseudo 类。
1.2.8 Cpu0InstrInfo.td
增加 Operand 操作数 class 中 ParserMatchClass 和 ParserMethod 属性的描述,只有这样,td 中的操作数才会支持汇编 parse。
定义伪指令 LoadImm32Reg, LoadAddr32Reg, LoadAddr32Imm,这几个指令会在 Cpu0AsmParser.cpp 中实现对应的展开函数 expandLoadImm(), expandLoadAddressImm 和 expandLoadAddressReg,这些函数统一放到 expandInstruction() 中管理,后者在 MatchAndEmitInstruction() 函数中被调用。
1.2.9 Cpu0RegisterInfo.td
将 GPROut 的定义移动到 Cpu0RegisterInfoGPROutForAsm.td 和 Cpu0RegisterInfoGPROutForOther.td 中。
1.3 修改后效果
用上述命令能正确生成.o文件,我们还可以使用之前适配的反汇编器进行反汇编查看。
相关文章:
LLVM Cpu0 新后端10
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...
)
k8s面试题大全,保姆级的攻略哦(二)
目录 三十六、pod的定义中有个command和args参数,这两个参数不会和docker镜像的entrypointc冲突吗? 三十七、标签及标签选择器是什么,如何使用? 三十八、service是如何与pod关联的? 三十九、service的域名解析格式…...
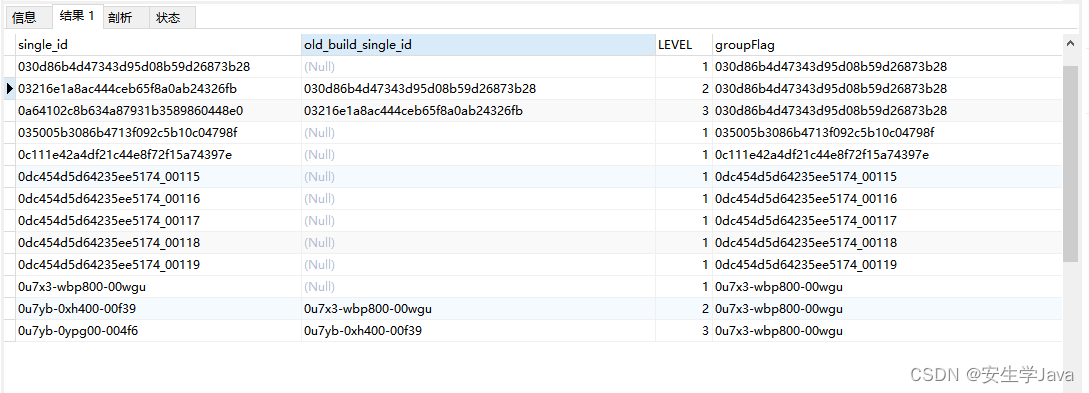
Mysql:通过一张表里的父子级,递归查询并且分组分级
递归函数WITH RECURSIVE语法 WITH RECURSIVE cte_name (column_list) AS (SELECT initial_query_resultUNION [ALL]SELECT recursive_queryFROM cte_nameWHERE condition ) SELECT * FROM cte_name; WITH RECURSIVE 关键字:表示要使用递归查询的方式处理数据。 c…...
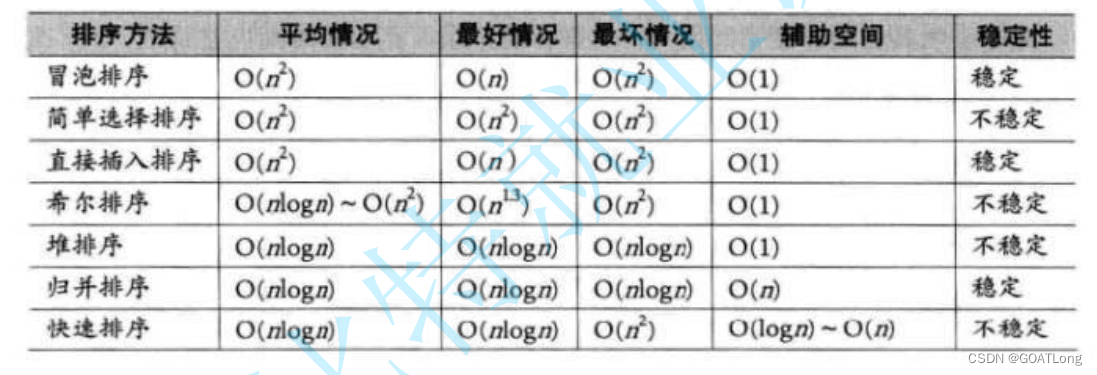
数据结构之排序算法
目录 1. 插入排序 1.1.1 直接插入排序代码实现 1.1.2 直接插入排序的特性总结 1.2.1 希尔排序的实现 1.2.2 希尔排序的特性总结 2. 选择排序 2.1.1 选择排序 2.1.2 选择排序特性 2.2.1 堆排序 2.2.2 堆排序特性 3. 交换排序 3.1.1 冒泡排序 3.1.2 冒泡排序的特性 …...

移动安全赋能化工能源行业智慧转型
随着我国能源化工企业的不断发展,化工厂中经常存在火灾爆炸的危险,特别是生产场所,约有80%以上生产场所区域存在爆炸性物质。而目前我国化工危险场所移动通信设备的普及率高,但是对移动通信设备的安全防护却有所忽视,包…...

今天是放假带娃的一天
端午节放假第一天 早上5点半宝宝就咔咔乱叫了,几乎每天都这个点醒,准时的很,估计他是个勤奋的娃吧,要早起锻炼婴语,哈哈 醒来后做饭、洗锅、洗宝宝的衣服、给他吃D3,喂200ml奶粉、给他洗澡、哄睡࿰…...

linux Ubuntu安装samba服务器与SSH远程登录
目录 1,下载安装包 2,添加服务器 3,修改服务器配置 3.1 备份配置文件 3.2 修改配置 4,开启samba服务器 5,开关电脑与服务器设置 6, SSH远程登录 1,下载samba服务器安装包 sudo apt in…...

纳什均衡:博弈论中的运作方式、示例以及囚徒困境
文章目录 一、说明二、什么是纳什均衡?2.1 基本概念2.2 关键要点 三、理解纳什均衡四、纳什均衡与主导策略五、纳什均衡的例子六、囚徒困境七、如何原理和应用7.1 博弈论中的纳什均衡是什么?7.2 如何找到纳什均衡?7.3 为什么纳什均衡很重要&a…...

Linux之进程信号详解【上】
🌎 Linux信号详解 文章目录: Linux信号详解 信号入门 技术应用角度的信号 信号及信号的产生 信号的概念 信号的处理方式 信号的产生方式 键盘产生信号 系统调用产生信号 软件…...

【Spring Cloud】Eureka详细介绍及底层原理解析
目录 底层原理详解 1. 服务注册与发现 2. 心跳机制 3. 服务剔除与自我保护机制 Eureka Server 核心组件 Eureka Client 核心组件 使用场景 结语 Eureka 是 Netflix 开源的一款服务发现框架,用于构建分布式系统中的服务注册与发现。 它包含两个核心组件&…...
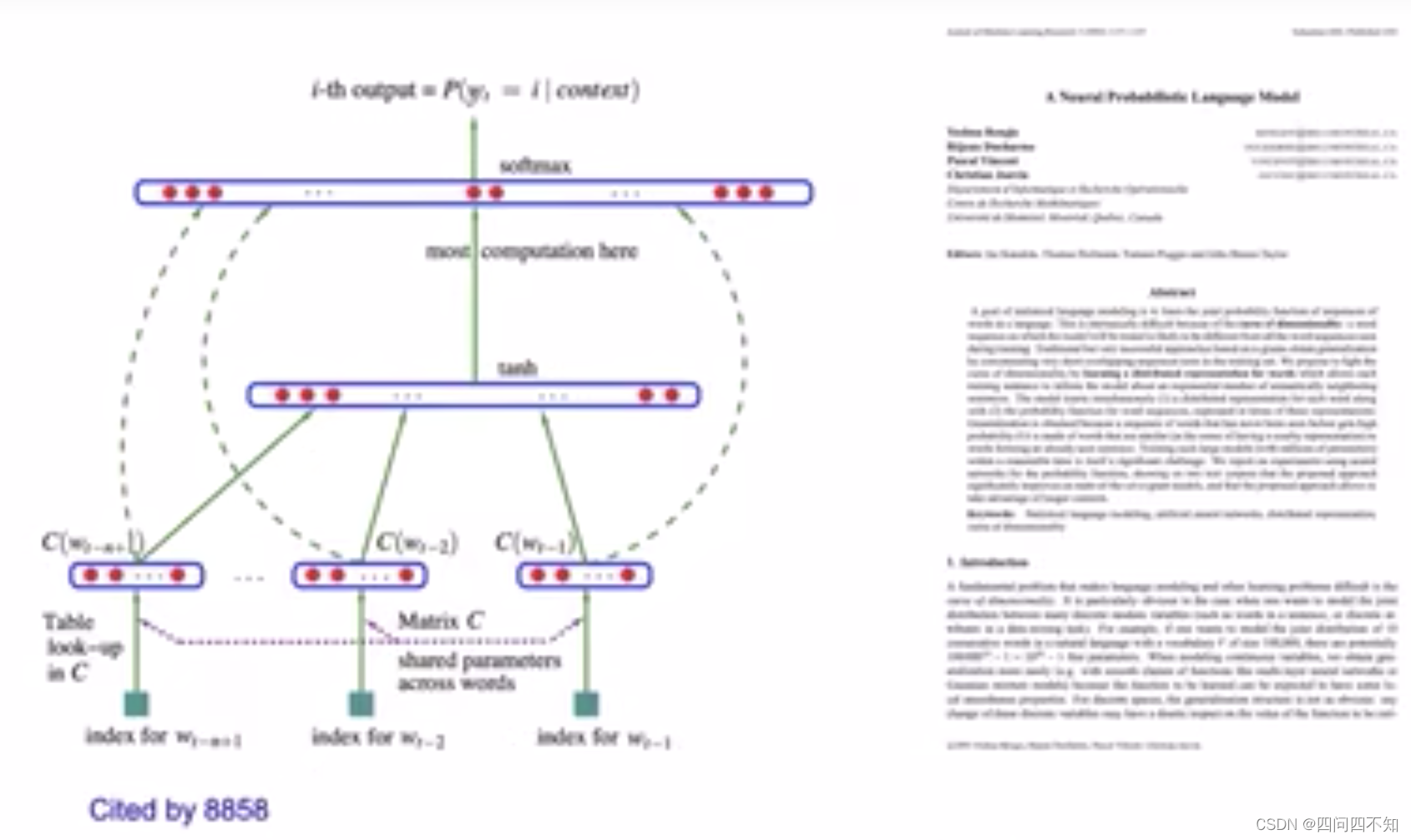
【清华大学】《自然语言处理》(刘知远)课程笔记 ——NLP Basics
自然语言处理基础(Natural Language Processing Basics, NLP Basics) 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言…...

代码随想录 | Day17 | 二叉树:二叉树的最大深度最小深度
代码随想录 | Day17 | 二叉树:二叉树的最大深度&&最小深度 主要学习内容: 利用前序后序层序求解二叉树深度问题 其中穿插回溯法 104.二叉树的最大深度 104. 二叉树的最大深度 - 力扣(LeetCode) 递归遍历 后序遍历 …...

【Linux】Socket编程基础
文章目录 字节序字节序转化函数 套接字socket通用结构体通信类型名空间套接字函数socket():创建套接字bind()函数:绑定服务器套接字与其地址、端口listen()函数:侦听客户连接connect():连接服务器套接字accept()函数:服…...
关于stm32的软件复位
使用软件复位的目的: 软件复位并不会擦除存储器中的数据,它只是将处理器恢复到复位状态,即中断使能位被清除,系统寄存器被重置,但RAM和Flash存储器中的数据保持不变。 STM32软件复位(基于库文件V3.5) ,对…...

规范系统运维:系统性能监控与优化的重要性与实践
在当今这个高度信息化的时代,企业的IT系统运维工作显得尤为关键。其中,系统性能监控和优化是运维工作中不可或缺的一环。本文旨在探讨规范系统运维中系统性能监控与优化的重要性,并分享一些实践经验和策略。 一、系统性能监控与优化的重要性…...

用python编撰一个电脑清理程序
自制一个电脑清理程序,有啥用呢?在电脑不装有清理软件的时候,可以解决自己电脑内存不足的情况。 1、设想需要删除指定文件夹中的临时文件和缓存文件。以下是代码。 import os import shutil def clean_folder(folder_path): for root,…...

2024年【天津市安全员C证】免费试题及天津市安全员C证试题及解析
题库来源:安全生产模拟考试一点通公众号小程序 天津市安全员C证免费试题是安全生产模拟考试一点通生成的,天津市安全员C证证模拟考试题库是根据天津市安全员C证最新版教材汇编出天津市安全员C证仿真模拟考试。2024年【天津市安全员C证】免费试题及天津市…...
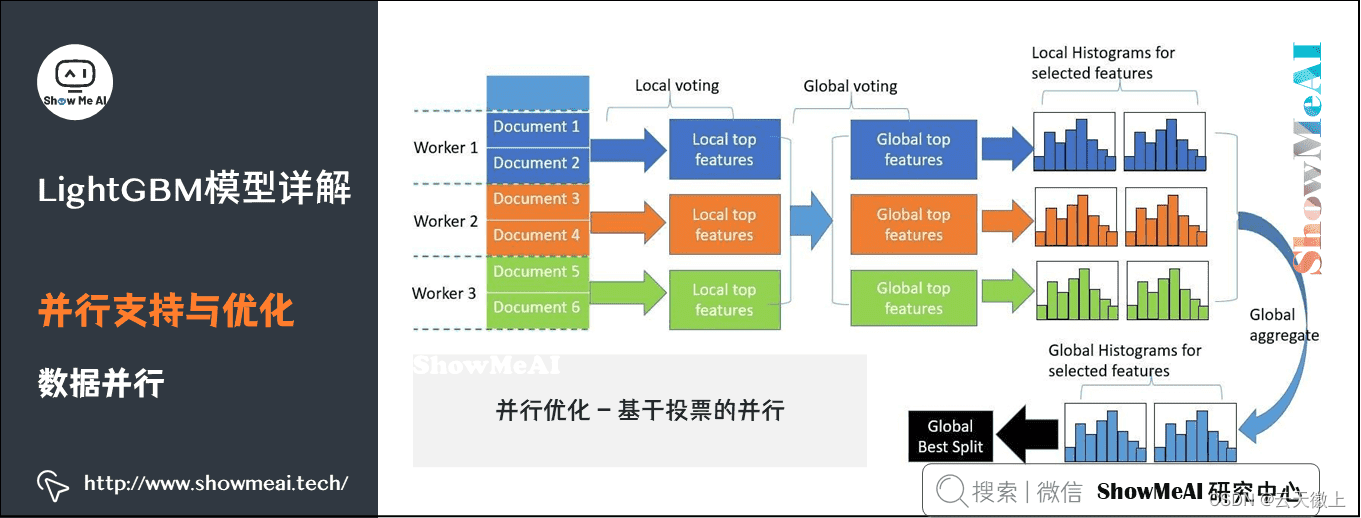
【Python数据挖掘实战案例】机器学习LightGBM算法原理、特点、应用---基于鸢尾花iris数据集分类实战
一、引言 1、简要介绍数据挖掘的重要性和应用 在数字化时代,数据已经成为企业和社会决策的重要依据。数据挖掘作为一门交叉学科,结合了统计学、机器学习、数据库技术和可视化等多个领域的知识,旨在从海量数据中提取有价值的信息,…...
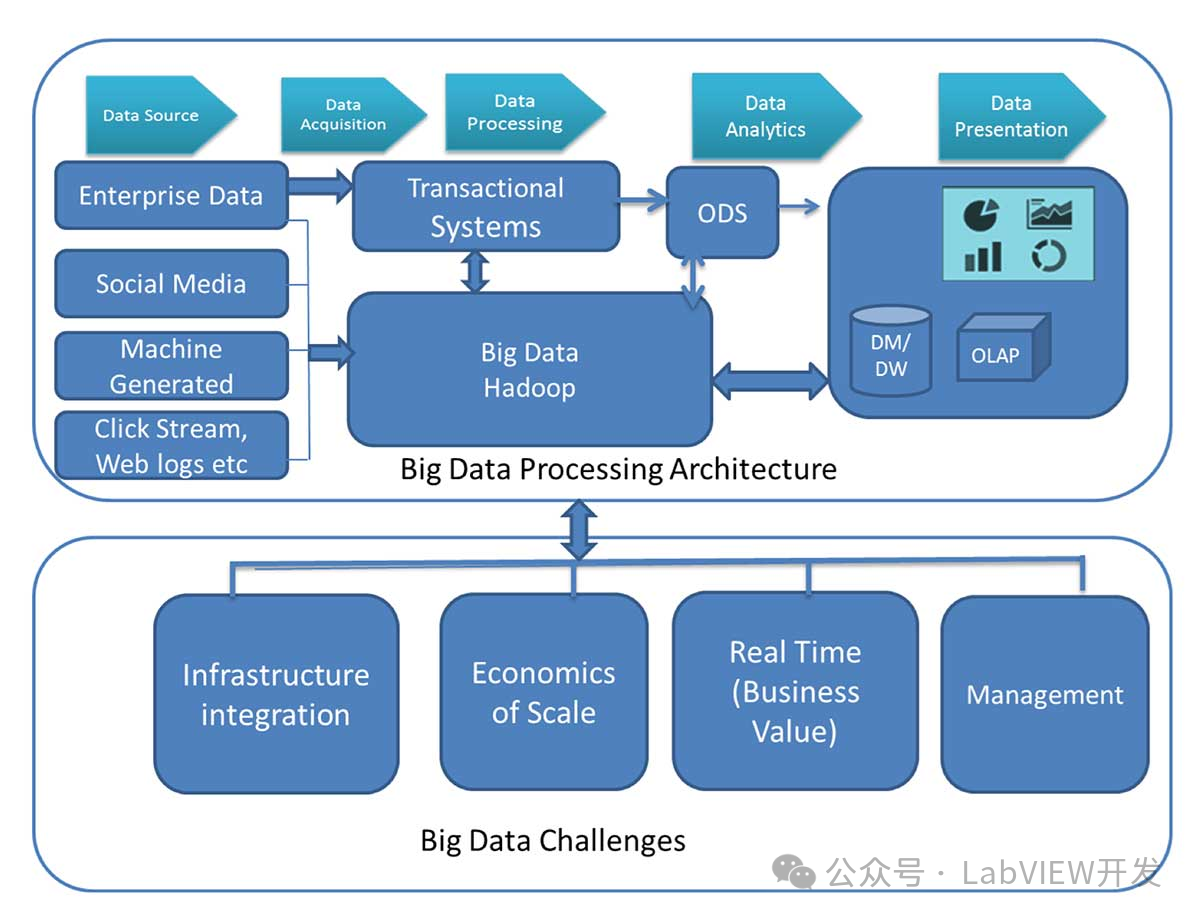
使用LabVIEW进行大数据数组操作的优化方法
针对大数据量数组操作,传统的内存处理方法可能导致内存不足。通过LabVIEW的图像批处理技术,可以有效地进行大数据数组操作,包括分块处理、并行处理和内存优化等。这种方法能显著提高处理效率和系统稳定性。 图像批处理的优势 内存优化&#…...
【Linux】(五)—— SSH远程登录和XShell使用
SSH Linux中的SSH(Secure Shell)是一个强大的网络协议,用于在不安全的网络环境中提供安全的远程登录和资料拷贝等其他网络服务。以下是有关Linux中SSH的关键点和操作指南: SSH的基础概念 安全性:SSH通过对所有传输的…...

AI辅助构建复古像素风Hacker News聚合器:全栈开发实战
1. 项目概述:一个AI驱动的复古风Hacker News聚合器最近在逛Hacker News的时候,我总感觉“Show HN”板块里那些有趣的个人项目像流星一样,刷一下就过去了,想回头再找特别费劲。作为一个喜欢折腾的开发者,我就在想&#…...

汽车软件平台演进:从AUTOSAR到Hypervisor,如何重塑开发与商业模式
1. 汽车软件平台现状:从“硬骨头”到“乐高积木”的演进干了十几年汽车电子,我亲眼看着车里的代码从几万行膨胀到上亿行。十年前,我们还在为某个ECU(电子控制单元)里塞进一个简单的网络协议栈而通宵调试;现…...

终端里的编程副驾:DeepSeek-TUI-项目深度拆解,实测与原理分析
刷 GitHub Trending 又看到一个挺有意思的东西:DeepSeek-TUI。说白了,就是把 DeepSeek V4 这个编程大模型,直接塞进了你的终端里。 这玩意儿不是简单的 CLI 包装。我跑了一下 curl 看 README,发现他们搞了个完整的 TUI(…...

横空出世!IDEA最强MyBatis插件来了,功能很全!
最近更新了IDEA 2026.1这个版本,发现之前使用的MyBaitsX这个插件没有兼容,启动就报错!于是就改用了MyBatisCodeHelper-Pro这个插件,体验了一把,提示很全,还有方便的MyBaits日志转SQL面板,这里分…...

QMCDecode:解锁QQ音乐加密文件,让音乐真正属于你
QMCDecode:解锁QQ音乐加密文件,让音乐真正属于你 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,…...

我写的C语言代码笔记
单链表:#include <stdio.h> #include <stdlib.h>//实现初始化,头插,尾插,删除,输出等单链表的基本操作 typedef struct Node {int data;struct Node* next; }Node;//初始化 Node* intList() {Node* list …...

5分钟Git指南
Git——一个版本控制系统 了解Git当你建立了一个Git版本库,那么存放.git(也就是版本库)的文件夹就被称为工作区,.git内部有一个暂存区,一个叫做master的分支,一个HEAD指针能够指向分支中不同版本的文件&…...

Python自动化红头文件生成:ReportLab与Jinja2技术实践
1. 项目概述:一个自动化的红头文件生成工具 最近在整理一些行政和项目文档时,经常需要处理格式要求极为严格的“红头文件”。这类文件通常用于正式通知、公告或批复,其版头、字体、字号、间距乃至印章位置都有近乎刻板的规定。手动在Word里调…...
)
从文献检索到论文写作:Perplexity与Zotero构建AI-native科研流水线(实测单篇综述效率提升3.8倍)
更多请点击: https://intelliparadigm.com 第一章:从文献检索到论文写作:Perplexity与Zotero构建AI-native科研流水线(实测单篇综述效率提升3.8倍) 在AI-native科研范式下,传统文献管理与写作流程正被重构…...

GitHub企业版MCP服务器:为AI助手集成私有化GitHub工作流
1. 项目概述:一个为开发者定制的GitHub企业版MCP服务器如果你是一名重度依赖GitHub Enterprise进行团队协作的开发者,并且正在探索如何将AI助手(比如Claude、Cursor等)无缝集成到你的日常开发工作流中,那么你很可能已经…...