【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构
目录
一、引言
二、自动模型类(AutoModel)
2.1 概述
2.2 Model Head(模型头)
2.3 代码示例
三、总结
一、引言
这里的Transformers指的是huggingface开发的大模型库,为huggingface上数以万计的预训练大模型提供预测、训练等服务。
🤗 Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨是让最先进的 NLP 技术人人易用。
🤗 Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
🤗 Transformers 支持三个最热门的深度学习库: Jax, PyTorch 以及 TensorFlow — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。
本文重点介绍自动模型类(AutoModel)。
二、自动模型类(AutoModel)
2.1 概述
AutoModel是Hugging Face的Transformers库中的一个非常实用的类,它属于自动模型选择的机制。这个设计允许用户在不知道具体模型细节的情况下,根据给定的模型名称或模型类型自动加载相应的预训练模型。它减少了代码的重复性,并提高了灵活性,使得开发者可以轻松地切换不同的模型进行实验或应用。
2.2 Model Head(模型头)
Model Head在预训练模型的基础上添加一层或多层的额外网络结构来适应特定的模型任务,方便于开发者快速加载transformers库中的不同类型模型,不用关心模型内部细节。
- ForCausalLM:因果语言模型头,用于decoder类型的任务,主要进行文本生成,生成的每个词依赖于之前生成的所有词。比如GPT、Qwen
- ForMaskedLM:掩码语言模型头,用于encoder类型的任务,主要进行预测文本中被掩盖和被隐藏的词,比如BERT。
- ForSeq2SeqLM:序列到序列模型头,用于encoder-decoder类型的任务,主要处理编码器和解码器共同工作的任务,比如机器翻译或文本摘要。
- ForQuestionAnswering:问答任务模型头,用于问答类型的任务,从给定的文本中抽取答案。通过一个encoder来理解问题和上下文,对答案进行抽取。
- ForSequenceClassification:文本分类模型头,将输入序列映射到一个或多个标签。例如主题分类、情感分类。
- ForTokenClassification:标记分类模型头,用于对标记进行识别的任务。将序列中的每个标记映射到一个提前定义好的标签。如命名实体识别,打标签
- ForMultiplechoice:多项选择任务模型头,包含多个候选答案的输入,预测正确答案的选项。
2.3 代码示例
对于目前常见的LLM,比如GLM、Qwen、Baichuan等,通常使用AutoModelForCausalLM模型头进行加载,比如下面代码中使用AutoModelForCausalLM.from_pretrained加载Qwen2模型。
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
#model_dir = snapshot_download('ZhipuAI/glm-4-9b-chat')
model_dir = snapshot_download('Qwen/Qwen2-7B-Instruct')
import torchdevice = "cuda:2" # the device to load the model ontotokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)prompt = "介绍一下大语言模型"
messages = [{"role": "system", "content": "你是一个智能助理."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)model = AutoModelForCausalLM.from_pretrained(model_dir,device_map="cuda:2",trust_remote_code=True,output_attentions=True
)gen_kwargs = {"max_length": 512, "do_sample": True, "top_k": 1}
with torch.no_grad():outputs = model.generate(**model_inputs, **gen_kwargs)outputs = outputs[:, model_inputs['input_ids'].shape[1]:] #切除system、user等对话前缀print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(model)AutoModelForCausalLM.from_pretrained常见参数:
- model_name_or_path (str): 指定预训练模型的名称或模型文件的路径。例如,"gpt2"、"distilgpt2"或本地模型文件夹的路径。
- config (Optional[PretrainedConfig]): 模型配置对象或其配置的字典。通常不需要手动提供,因为如果未提供,它会根据model_name_or_path自动加载。
- tokenizer (Optional[PreTrainedTokenizer]): 与模型一起使用的分词器。如果提供,可以用于快速预处理文本数据。如果未提供,某些功能可能受限。
- cache_dir (Optional[str]): 用于存储下载的模型文件的缓存目录路径。
- from_tf (bool, default=False): 是否从TensorFlow检查点加载模型。
- force_download (bool, default=False): 是否强制重新下载模型,即使本地已有。
- resume_download (bool, default=False): 是否从上次下载中断的地方继续下载。
- proxies (dict, optional): 如果需要通过代理服务器下载模型,可以提供代理的字典。
- output_loading_info (bool, default=False): 是否返回加载模型时的详细信息。
- local_files_only (bool, default=False): 是否仅从本地文件加载模型,不尝试在线下载。
- low_cpu_mem_usage (bool, default=False): 是否优化模型加载以减少CPU内存使用,这对于大型模型特别有用。
- device_map (Optional[Dict[str, Union[int, str]]]): 用于在多GPU或特定设备上分配模型的字典。在PyTorch 2.0及Transformers的相应版本中更为常见。
- revision (str, optional): 指定模型版本或分支,用于从Hugging Face Hub加载特定版本的模型。
- use_auth_token (Optional[Union[str, bool]]): 如果模型存储在私有仓库中,需要提供访问令牌。
特别有用的一个功能就是输出模型结构,有助于快速理解模型
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2-7B-Instruct')from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_dir)
print(model)Qwen2的模型结构如下
Qwen2ForCausalLM((model): Qwen2Model((embed_tokens): Embedding(152064, 3584)(layers): ModuleList((0-27): 28 x Qwen2DecoderLayer((self_attn): Qwen2SdpaAttention((q_proj): Linear(in_features=3584, out_features=3584, bias=True)(k_proj): Linear(in_features=3584, out_features=512, bias=True)(v_proj): Linear(in_features=3584, out_features=512, bias=True)(o_proj): Linear(in_features=3584, out_features=3584, bias=False)(rotary_emb): Qwen2RotaryEmbedding())(mlp): Qwen2MLP((gate_proj): Linear(in_features=3584, out_features=18944, bias=False)(up_proj): Linear(in_features=3584, out_features=18944, bias=False)(down_proj): Linear(in_features=18944, out_features=3584, bias=False)(act_fn): SiLU())(input_layernorm): Qwen2RMSNorm()(post_attention_layernorm): Qwen2RMSNorm()))(norm): Qwen2RMSNorm())(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)三、总结
本文对使用transformers的AutoModel自动模型类进行介绍,主要用于加载transformers模型库中的大模型,文中详细介绍了应用于不同任务的Model Head(模型头)、使用模型头、输出模型结构等关于AutoModel常用的方法。希望对您有帮助。
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
AI智能体研发之路-模型篇(八):【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
AI智能体研发之路-模型篇(九):【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
《AI—Transformers应用》
【AI大模型】Transformers大模型库(一):Tokenizer
【AI大模型】Transformers大模型库(二):AutoModelForCausalLM
【AI大模型】Transformers大模型库(三):特殊标记(special tokens)
【AI大模型】Transformers大模型库(四):AutoTokenizer
相关文章:

【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构
目录 一、引言 二、自动模型类(AutoModel) 2.1 概述 2.2 Model Head(模型头) 2.3 代码示例 三、总结 一、引言 这里的Transformers指的是huggingface开发的大模型库,为huggingface上数以万计的预…...
,新增表字段,删除表字段,修改存储格式)
Hadoop yixing(移行),新增表字段,删除表字段,修改存储格式
Hadoop yixing(移行),新增表字段,删除表字段,修改存储格式 一、hadoop中修改存储格式,比如从 textfile 转化为 orc 格式,表中的数据的组织形式要重新改变,就要将重新创建新格式的表将原来的数据按照新的格…...
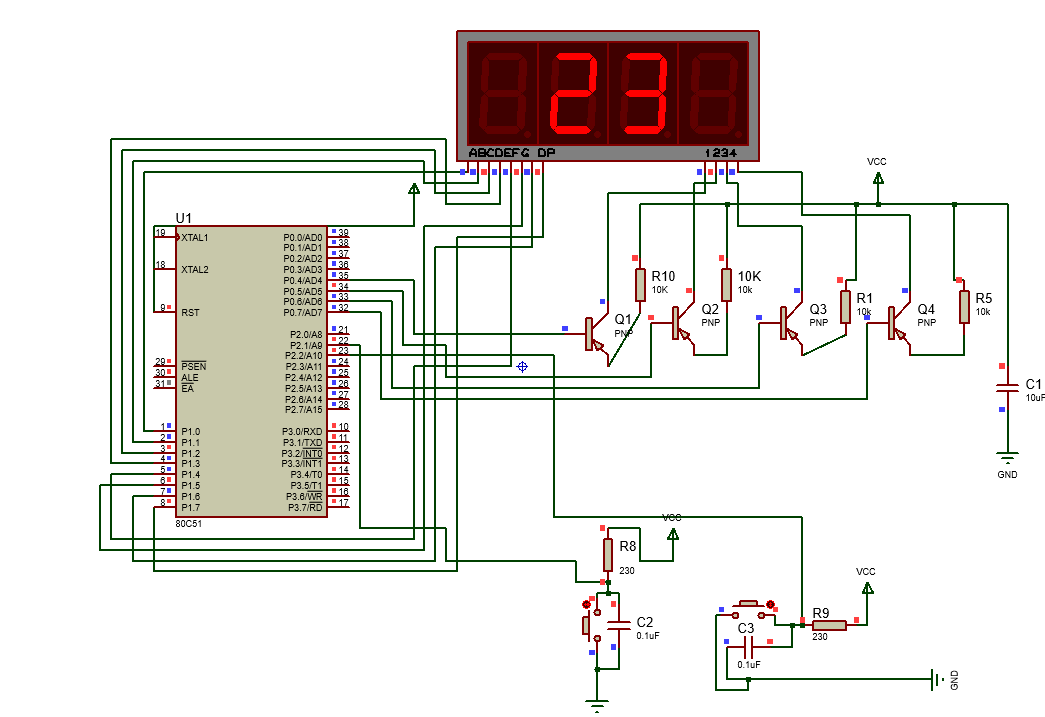
使用汇编和proteus实现仿真数码管显示电路
proteus介绍: proteus是一个十分便捷的用于电路仿真的软件,可以用于实现电路的设计、仿真、调试等。并且可以在对应的代码编辑区域,使用代码实现电路功能的仿真。 汇编语言介绍: 百度百科介绍如下: 汇编语言是培养…...
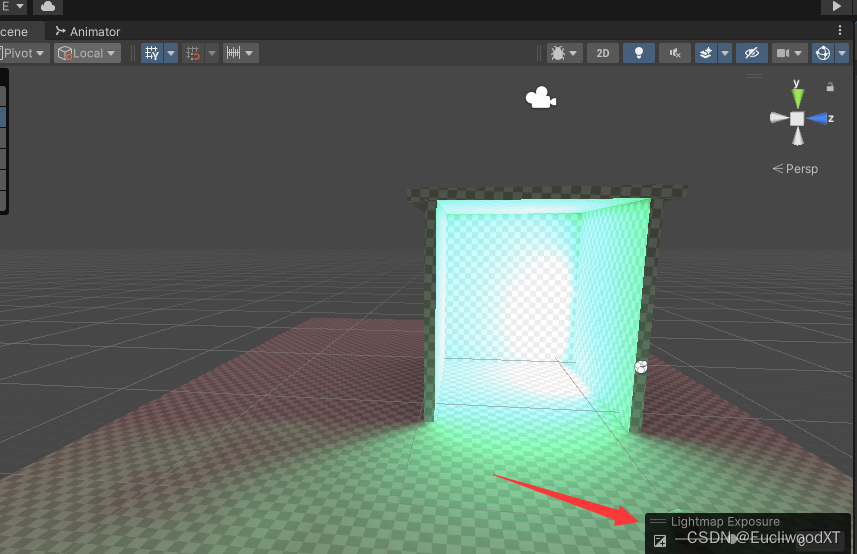
【Unity】官方文档学习-光照系统
目录 1 前言 2 光照介绍 2.1 直接光与间接光 2.2 实时光照与烘焙光照 2.3 全局光照 3 光源 3.1 Directional Light 3.1.1 Color 3.1.2 Mode 3.1.3 Intensity 3.1.4 Indirect Multiplier 3.1.5 Shadow Type 3.1.6 Baked Shadow Angle 3.1.7 Realtime Shadows 3.1…...

1731. 每位经理的下属员工数量
1731. 每位经理的下属员工数量 题目链接:1731. 每位经理的下属员工数量 代码如下: # Write your MySQL query statement below select a.employee_id as employee_id,a.name as name,count(b.employee_id) as reports_count,round(avg(b.age),0) as av…...

特征筛选LASSO回归封装好的代码、数据集和结果
Gitee仓库地址:特征筛选LASSO回归封装好的代码、数据集和结果 README LassoFeatureSelector_main 这个是主函数文件,在实例化LassoFeatureSelector类时,需要传入下面这些参数: input_train_data_path:输入训练集的路…...

Autosar 通讯栈配置-手动配置PDU及Signal-基于ETAS软件
文章目录 前言System配置ISignalSystem SignalPduFrameISignal到System Signal的mapSystem Signal到Pdu的mapPdu到Frame的mapSignal配置Can配置CanHwFilterEcuC配置PduR配置CanIf配置CanIfInitCfgCanIfRxPduCfgCom配置ComIPduComISignalSWC配置Data mappingRTE接口Com配置补充总…...

Web前端工资调整:深入剖析与全面解读
Web前端工资调整:深入剖析与全面解读 在快速发展的互联网行业中,Web前端技术日新月异,而与之紧密相关的工资调整也成为了业内热议的话题。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析Web前端工资调整的原因、趋势、…...

cesium已知两个点 写一个简单具有动画尾迹效果的抛物线
// 定义起点和终点的经纬度和高度 var start { longitude: 111.09683723811149, latitude: 38.92112250636146, elevation: 603.5831692856873 }; var end { longitude: 111.09769465526689, latitude: 38.92815375977821, elevation: 627.0132157062261 }; // 生成更多的中…...
C#中使用Mysql批量新增数据 MySqlBulkCopy
在C#中使用MySqlBulkCopy类来批量复制数据到MySQL数据库,首先需要确保你的项目中已经引用了MySQL Connector。以下是使用MySqlBulkCopy的基本步骤: 1.安装MySQL Connector。 可以通过NuGet安装MySQL Connector: 2.在代码中引用必要的命名空间…...

ARM-V9 RME(Realm Management Extension)系统架构之系统安全能力的架构差异
安全之安全(security)博客目录导读 RME系统中的应用处理单元(PE)之间的架构差异可能会带来潜在的安全风险并增加管理软件的复杂性。例如,通过在ID_AA64MMFR0_EL1.PARange中为每个PE设置不同的值来支持不同的物理范围,可能会妨碍内…...

Ansible——stat模块
目录 参数总结 返回值 基础语法 常见的命令行示例 示例1:检查文件是否存在 示例2:获取文件详细信息 示例3:检查目录是否存在 示例4:获取文件的 MD5 校验和 示例5:获取文件的 MIME 类型 高级使用 示例6&…...

第二十节:带你梳理Vue2:Vue子组件向父组件传参(事件传参)
1. 自定义事件 除了可以处理原生的DOM事件, v-on指令也可以处理组件内部触发的自定义的事件,调用this.$emit()函数就可以触发一个自定义事件 $emit() 触发事件函数接受一个自定义事件的事件名以及其他任何给事件函数传递的参数. 然后就可以在组件上使用v-on来绑定这个自定义事…...

华为od-C卷100分题目 - 10寻找最富裕的小家庭
华为od-C卷100分题目 - 10寻找最富裕的小家庭 题目描述 在一棵树中,每个节点代表一个家庭成员,节点的数字表示其个人的财富值,一个节点及其直接相连的子节点被定义为一个小家庭。 现给你一棵树,请计算出最富裕的小家庭的财富和。…...

本地部署AI大模型 —— Ollama文档中文翻译
写在前面 来自Ollama GitHub项目的README.md 文档。文档中涉及的其它文档未翻译,但是对于本地部署大模型而言足够了。 Ollama 开始使用大模型。 macOS Download Windows 预览版 Download Linux curl -fsSL https://ollama.com/install.sh | sh手动安装说明 …...

【前端技术】 ES6 介绍及常用语法说明
😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~ 🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Mi…...
)
程序员具备的职业素养(个人见解)
程序员应该有什么职业素养? 1. 技术能力 毫无疑问,优秀的技术是程序员的必备。 -扎实的编程基础:熟练掌握至少一门编程语言,并理解基本的数据结构和算法,要做到精通!。 - 广泛的技术知识:了…...

Springboot 开发-- 集成 Activiti 7 流程引擎
引言 Activiti 7是一款遵循BPMN 2.0标准的开源工作流引擎,旨在为企业提供灵活、可扩展的流程管理功能。它支持图形化的流程设计、丰富的API接口、强大的执行引擎和完善的监控报表,帮助企业实现业务流程的自动化、规范化和智能化。本文将为您详细介绍 Ac…...

一些常用的frida脚本
这里整理一些常用的frida脚本,和ghidra 一起食用风味更佳~ Trace RegisterNatives 注意到从java到c的绑定中,可能会在JNI_OnLoad动态的执行RegisterNatives方法来绑定java层的函数到c行数,可以通过这个方法,来吧运行…...
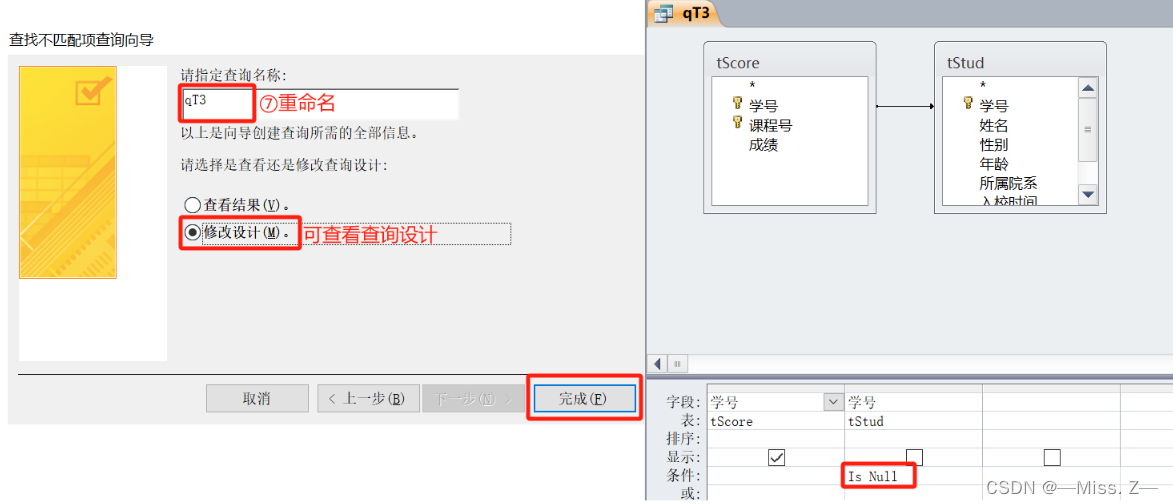
计算机二级Access操作题总结——简单应用
查询设计 创建一个查询,能够在客人每次结账时根据客人的姓名提示统计这个客人已住天数和应交金额,并显示“姓名”、“房间号”、“已住天数”和“应交金额”,所建查询命名为“qT2”。 注:输入姓名时应提示“请输入姓名”。已住天…...

RustClaw:高性能网络代理的Rust实现与架构解析
1. 项目概述:一个Rust实现的Claw库最近在折腾一些网络代理和流量处理的工具链,发现很多核心组件对性能和安全性的要求越来越高。传统的C/C实现虽然快,但内存安全和并发模型上的坑,让开发和维护成本居高不下。就在这个当口…...

如何构建高效的个人游戏串流服务器:Sunshine完整部署指南
如何构建高效的个人游戏串流服务器:Sunshine完整部署指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在当今数字娱乐时代,游戏玩家面临着设备限制与体验…...

EDA工具选型实战:从价格到价值的深度迁移指南
1. 从价格战到价值战:一次EDA工具市场策略的深度复盘十年前,当Altium宣布将其旗舰PCB设计软件Altium Designer的价格下调约75%时,整个电子设计自动化(EDA)圈子都炸开了锅。这无异于在由Cadence、Mentor Graphics&#…...

原生TypeScript待办清单:纯前端架构、观察者模式与拖拽排序实践
1. 项目概述:一个由AI辅助构思的现代化待办清单最近在整理个人项目时,我重新审视了一个之前用TypeScript写的待办清单应用。这个项目的初衷很简单:我需要一个极简、快速、完全由我掌控的待办工具,它不需要登录,数据就存…...

终极UE4SS游戏Mod开发指南:从零开始掌握虚幻引擎脚本系统
终极UE4SS游戏Mod开发指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4S…...

016、气压计原理与高度测量
飞控算法从入门到精通 016 气压计原理与高度测量 一、一次炸机带来的教训 去年夏天,我在一个四轴飞行器上调试定高悬停。气压计用的是MS5611,数据手册翻烂了,滤波算法也上了,地面站里高度曲线看着挺平滑。结果一上天,飞机像喝醉了酒——先是莫名其妙往下掉半米,然后猛…...

ARM GIC中断控制器架构与关键寄存器详解
1. ARM GIC中断控制器架构概述ARM通用中断控制器(GIC)是现代ARM处理器中负责中断管理的核心组件,它实现了复杂的中断分发和处理机制。GIC架构从v2版本发展到现在的v4版本,功能不断增强,支持多核处理、虚拟化扩展和安全隔离等高级特性。GIC主要…...

汽车电子系统如何重构价值:从马力到算力的产业变革
1. 从马力到算力:汽车价值创造的核心迁移十年前,如果你问一个车迷,一辆好车的灵魂是什么,答案多半会指向引擎盖下的那台机器——它的排量、气缸数,以及最终输出的马力。那个时代,机械性能是绝对的王者&…...

Roast:颠覆AI助手模式,打造苏格拉底式思维拷问引擎
1. 项目概述:当AI开始“拷问”你如果你用过市面上那些主流的AI助手,不管是ChatGPT、Claude还是DeepSeek,你大概率有过这样的体验:你抛出一个想法,它总能给你一堆“哇,这个想法太棒了!”、“很有…...

告别TwinCAT:手把手教你用LinuxCNC+IGH搭建开源EtherCAT运动控制平台
告别商业软件束缚:LinuxCNCIGH开源运动控制平台实战指南 在工业自动化和运动控制领域,商业软件长期占据主导地位,但高昂的授权费用和封闭的生态系统让许多工程师和创客望而却步。开源运动控制平台的出现打破了这一局面,为追求灵活…...