Pytorch 实现目标检测二(Pytorch 24)
一 实例操作目标检测
下面通过一个具体的例子来说明锚框标签。我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个 元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的(x, y)轴坐标(范围介于0和1之间)。我 们还构建了五个锚框,用左上角和右下角的坐标进行标记:A0, . . . , A4(索引从0开始)。然后我们在图像中 绘制这些真实边界框和锚框。
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],[0.57, 0.3, 0.92, 0.9]])
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4'])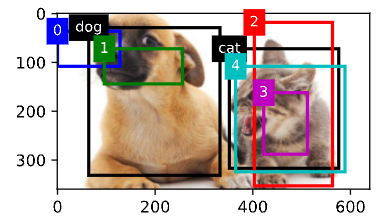
使用上面定义的multibox_target函数,我们可以根据狗和猫的真实边界框,标注这些锚框的分类和偏移量。 在这个例子中,背景、狗和猫的类索引分别为0、1和2。下面我们为锚框和真实边界框样本添加一个维度。
labels = multibox_target(anchors.unsqueeze(dim=0),ground_truth.unsqueeze(dim=0))返回的结果中有三个元素,都是张量格式。第三个元素包含标记的输入锚框的类别。
1.1 使用非极大值抑制预测边界框
在预测时,我们先为图像生成多个锚框,再为这些锚框一一预测类别和偏移量。一个预测好的边界框则根据 其中某个带有预测偏移量的锚框而生成。下面我们实现了offset_inverse函数,该函数将锚框和偏移量预测 作为输入,并应用逆偏移变换来返回预测的边界框坐标。
def offset_inverse(anchors, offset_preds):anc = d2l.box_corner_to_center(anchors)pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)predicted_bbox = d2l.box_center_to_corner(pred_bbox)return predicted_bbox当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。为了简化输出,我 们可以使用非极大值抑制(non‐maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
以下是非极大值抑制的工作原理。对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。假设最大的预测概率为p,则该概率所对应的类别B即为预测的类别。具体来说,我们将p称为预测边界框B的置信度(confidence)。在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表L。然后 我们通过以下步骤操作排序列表L。
- 从L中 选取置信度最高的预测边界框B1作为基准,然后将所有与B1的IoU超过预定阈值ϵ的非基准预测 边界框从L中移除。这时,L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。 简而言之,那些具有非极大值置信度的边界框被抑制了。
- 从L中选取置信度第二高的预测边界框B2作为又一个基准,然后将所有与B2的IoU大于ϵ的非基准预测 边界框从L中移除。
- 重复上述过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预测边界框的IoU都小于阈值ϵ;因此,没有一对边界框过于相似。
- 输出列表L中的所有预测边界框。
以下nms函数按降序对置信度进行排序并返回其索引。
#@save
def nms(boxes, scores, iou_threshold):B = torch.argsort(scores, dim=-1, descending=True)keep = []while B.numel() > 0:i = B[0]keep.append(i)if B.numel() == 1:break iou = box_iou(boxes[i, :].reshape(-1, 4), boxes[B[1:], :].reshape(-1, 4)).reshape(-1)inds = torch.nonzero(iou <= iou_threshold).reshape(-1)B = B[inds + 1]return torch.tensor(keep, device=boxes.device)我们定义以下multibox_detection函数来 将非极大值抑制应用于预测边界框。这里的实现有点复杂,请不要 担心。我们将在实现之后,马上用一个具体的例子来展示它是如何工作的。
#@save
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,pos_threshold=0.009999999):device, batch_size = cls_probs.device, cls_probs.shape[0]anchors = anchors.squeeze(0)num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]out = []for i in range(batch_size):cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)conf, class_id = torch.max(cls_prob[1:], 0)predicted_bb = offset_inverse(anchors, offset_pred)keep = nms(predicted_bb, conf, nms_threshold)all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)combined = torch.cat((keep, all_idx))uniques, counts = combined.unique(return_counts=True)non_keep = uniques[counts == 1]all_id_sorted = torch.cat((keep, non_keep))class_id[non_keep] = -1class_id = class_id[all_id_sorted]conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]below_min_idx = (conf < pos_threshold)class_id[below_min_idx] = -1conf[below_min_idx] = 1 - conf[below_min_idx]pred_info = torch.cat((class_id.unsqueeze(1),conf.unsqueeze(1), predicted_bb), dim=1)out.append(pred_info)return torch.stack(out)现在让我们将上述算法应用到一个带有四个锚框的具体示例中。为简单起见,我们假设预测的偏移量都是零, 这意味着预测的边界框即是锚框。对于背景、狗和猫其中的每个类,我们还定义了它的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率[0.9, 0.8, 0.7, 0.1], # 狗的预测概率[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率我们可以在图像上绘制这些预测边界框和置信度。
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])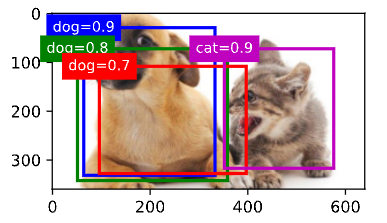
现在我们可以调用multibox_detection函数来 执行非极大值抑制,其中阈值设置为0.5。请注意,我们在示例 的张量输入中添加了维度。
我们可以看到返回结果的形状是(批量大小,锚框的数量,6)。最内层维度中的六个元素提供了同一预测 边界框的输出信息。第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值‐1表示背景或在非极大 值抑制中被移除了。第二个元素是预测的边界框的置信度。其余四个元素分别是预测边界框左上角和右下角 的(x, y)轴坐标(范围介于0和1之间)。
output = multibox_detection(cls_probs.unsqueeze(dim=0),offset_preds.unsqueeze(dim=0),anchors.unsqueeze(dim=0),nms_threshold=0.5)
output
删除‐1类别(背景)的预测边界框后,我们可以 输出由非极大值抑制保存的最终预测边界框。
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():if i[0] == -1:continue label = ('dog=', 'cat=')[int(i[0])] + str(i[1])show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)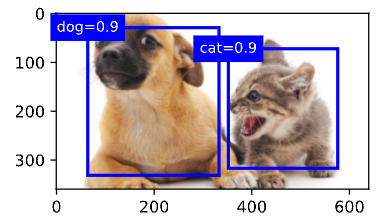
实践中,在执行非极大值抑制前,我们甚至 可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
小结:
- 我们 以图像的每个像素为中心生成不同形状的锚框。
- 交并比(IoU)也被称为杰卡德系数,用于衡量两个边界框的相似性。它是相交面积与相并面积的比率。
- 在训练集中,我们需要给每个锚框两种类型的标签。一个是与锚框中目标检测的类别,另一个是锚框真实相对于边界框的偏移量。
- 预测期间可以使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。
二 多尺度目标检测
我们以输入图像的每个像素为中心,生成了多个锚框。基本而言,这些锚框代表了图像不同区域 的样本。然而,如果为每个像素都生成的锚框,我们最终可能会得到太多需要计算的锚框。想象一个 561×728的 输入图像,如果以每个像素为中心生成五个形状不同的锚框,就需要在图像上标记和预测超过200万个锚框 (561 × 728 × 5)。
减少图像上的锚框数量并不困难。比如,我们可以在输入图像中均匀采样一小部分像素,并以它们为中心生 成锚框。此外,在不同尺度下,我们可以生成不同数量和不同大小的锚框。直观地说,比起较大的目标,较小的目标在图像上出现的可能性更多样。例如,1 × 1、1 × 2和2 × 2的目标可以分别以4、2和1种可能的方式 出现在2 × 2图像上。因此,当使用较小的锚框检测较小的物体时,我们可以采样更多的区域,而对于较大的 物体,我们可以采样较少的区域。
为了演示如何在多个尺度下生成锚框,让我们先读取一张图像。
%matplotlib inline
import torch
from d2l import torch as d2limg = d2l.plt.imread('../img/catdog.jpg')
img.shape # (360, 640, 3)display_anchors函数定义如下。我们 在特征图(fmap)上生成锚框(anchors),每个单位(像素)作为锚框的中心。由于锚框中的(x, y)轴坐标值(anchors)已经被除以特征图(fmap)的宽度和高度,因此这些值介 于0和1之间,表示特征图中锚框的相对位置。
由于锚框(anchors)的中心分布于特征图(fmap)上的所有单位,因此这些中心必须根据其相对空间位置在任何输入图像上均匀分布。更具体地说,给定特征图的宽度和高度fmap_w和fmap_h,以下函数将均匀地对任 何输入图像中fmap_h行和fmap_w列中的像素进行采样。以这些均匀采样的像素为中心,将会生成大小为s(假 设列表s的长度为1)且宽高比(ratios)不同的锚框。
def display_anchors(fmap_w, fmap_h, s):d2l.set_figsize()fmap = torch.zeros((1, 10, fmap_h, fmap_w))anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])bbox_scale = torch.tensor((w, h, w, h))d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0] * bbox_scale)首先,让我们考虑探测小目标。为了在显示时更容易分辨,在这里具有不同中心的锚框不会重叠:锚框的尺 度设置为0.15,特征图的高度和宽度设置为4。我们可以看到,图像上4行和4列的锚框的中心是均匀分布的。
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])
然后,我们将特征图的高度和宽度减小一半,然后使用较大的锚框来检测较大的目标。当尺度设置为0.4时, 一些锚框将彼此重叠。
display_anchors(fmap_w=2, fmap_h=2, s=[0.4])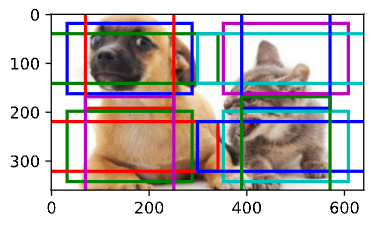
最后,我们进一步将特征图的高度和宽度减小一半,然后将锚框的尺度增加到0.8。此时,锚框的中心即是图 像的中心。
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])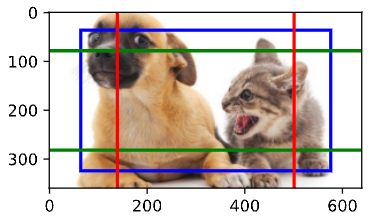
小结:
- 在多个尺度下,我们 可以生成不同尺寸的锚框来检测不同尺寸的目标。
- 通过定义特征图的形状,我们 可以决定任何图像上均匀采样的锚框的中心。
- 我们 使用输入图像在某个感受野区域内的信息,来预测输入图像上与该区域位置相近的锚框类别和偏 移量。
- 我们可以通过深入学习,在 多个层次上的图像分层表示进行多尺度目标检测。
相关文章:
Pytorch 实现目标检测二(Pytorch 24)
一 实例操作目标检测 下面通过一个具体的例子来说明锚框标签。我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个 元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的(x, y)轴坐标(范围…...
进行高效列表操作)
如何使用Python中的列表解析(list comprehension)进行高效列表操作
Python中的列表解析(list comprehension)是一种创建列表的简洁方法,它可以在单行代码中执行复杂的循环和条件逻辑。列表解析提供了一种快速且易于阅读的方式来生成新的列表。 以下是一些使用列表解析进行高效列表操作的示例: 1.…...

java使用websocket遇到的问题
java使用websocket的bug 1 websocket连接正常但是收不到服务端发出的消息java的websocket并发的时候导致连接断开(看着连接是正常的,但是实际上已经断开) 1 websocket连接正常但是收不到服务端发出的消息 java的websocket并发的时候导致连接断…...

[Cloud Networking] Layer 2
文章目录 1. 什么是Mac Address?2. 如何查找MAC地址?3. 二层数据交换4. [Layer 2 Protocol](https://blog.csdn.net/settingsun1225/article/details/139552315) 1. 什么是Mac Address? MAC 地址是计算机的唯一48位硬件编码,嵌入到网卡中。 MAC地址也…...
)
[240609] qwen2 发布,在 Ollama 已可用 | 采用语言模型构建通用 AGI(2020年8月)
目录 qwen2 发布,在 Ollama 已可用Qwen2 模型概览 (基于 Ollama 网站信息)一、模型介绍二、模型参数三、支持语言 (除英语和中文外)四、模型性能五、许可证六、数据支撑: 采用语言模型构建通用 AGI qwen2 发布,在 Ollama 已可用 Qwen2 模型概览 (基于 O…...
)
赶紧收藏!2024 年最常见 20道分布式、微服务面试题(五)
上一篇地址:赶紧收藏!2024 年最常见 20道分布式、微服务面试题(四)-CSDN博客 九、在分布式系统中,如何保证数据一致性? 在分布式系统中保证数据一致性是一个复杂的问题,因为分布式系统由多个独…...

为什么Kubernetes(K8S)弃用Docker:深度解析与未来展望
为什么Kubernetes弃用Docker:深度解析与未来展望 🚀 为什么Kubernetes弃用Docker:深度解析与未来展望摘要引言正文内容(详细介绍)什么是 Kubernetes?什么是 Docker?Kubernetes 和 Docker 的关系…...
软件游戏提示msvcp120.dll丢失的解决方法,总结多种靠谱的解决方法
在电脑使用过程中,我们可能会遇到一些错误提示,其中之一就是“找不到msvcp120.dll”。那么,msvcp120.dll是什么?它对电脑有什么影响?有哪些解决方法?本文将从以下几个方面进行探讨。 一,了解msv…...
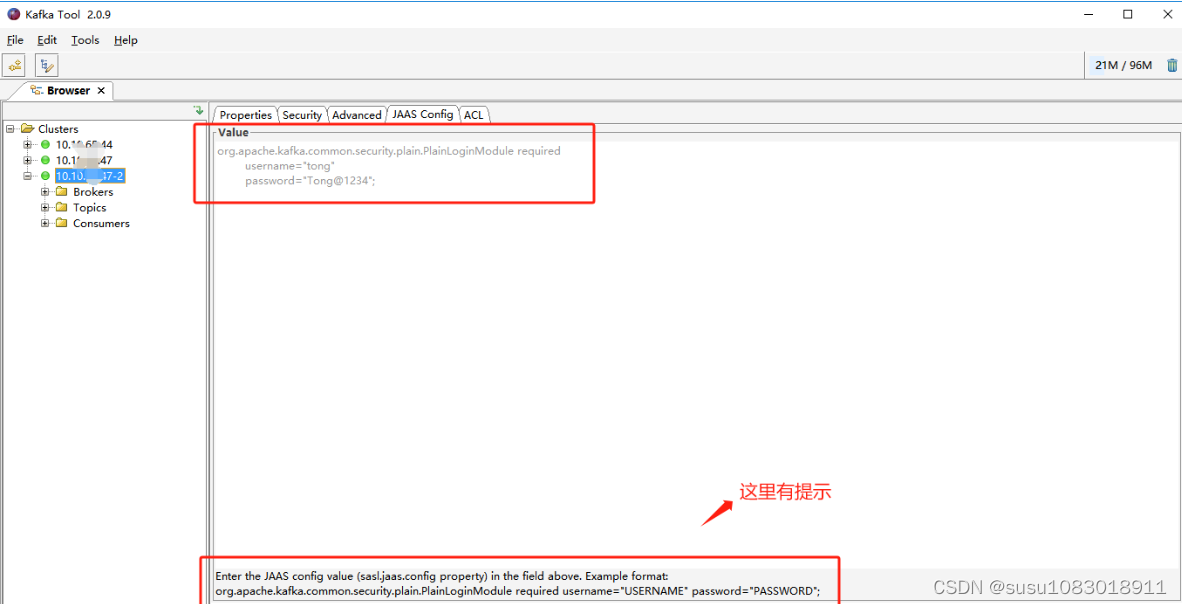
使用kafka tools工具连接带有用户名密码的kafka
使用kafka tools工具连接带有用户名密码的kafka 创建kafka连接,配置zookeeper 在Security选择Type类型为SASL Plaintext 在Advanced页面添加如下图红框框住的内容 在JAAS_Config加上如下配置 需要加的配置: org.apache.kafka.common.security.plain.Pla…...

[个人感悟] Java基础问题应该考察哪些问题?
前言 “一切代码无非是数据结构和算法流程的结合体.” 忘了最初是在何处看见这句话了, 这句话, 对于Java基础的考察也是一样. 正如这句话所说, 我们对于基础的考察主要考察, 数据结构, 集合类型结构, 异常类型, 已经代码的调用和语法关键字. 其中数据结构和集合类型结构是重点…...
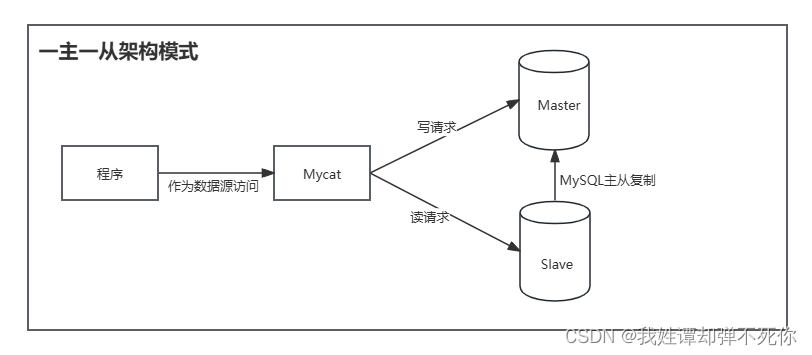
MySQL-主从复制
1、主从复制的理解 在工作用常见Redis作为缓存与MySQL一起使用。当有请求时,首先会从缓存中进行查找,如果存在就直接取出,否则访问数据库,这样 提升了读取的效率,也减少了对后台数据库的访问压力。Redis的缓存架构时高…...

开发没有尽头,尽力既是完美
最近遇到了一些难题,开发系统总有一些地方没有考虑周全,偏偏用户使用的时候“完美复现”了这个隐藏的Bug...... 讲道理创业一年之久为了生存,我一直都有在做复盘,复盘的核心就是:如何提升营收、把控开发质量࿰…...

【手推公式】如何求SDE的解(附录B)
【手推公式】如何求SDE的解(附录B) 核心思路:不直接求VE和VP的SDE的解xt,而是求xt的期望和方差,从而写出x0到xt的条件分布形式(附录B) 论文:Score-Based Generative Modeling throug…...
STM32F103单片机工程移植到航顺单片机HK32F103注意事项
一、简介 作为国内MCU厂商中前三阵营之一的航顺芯片,建立了世界首创超低功耗7nA物联网、万物互联核心处理器浩瀚天际10X系列平台,接受代理商/设计企业/方案商定制低于自主研发十倍以上成本,接近零风险自主品牌产品,芯片设计完成只…...

Llama模型家族之Stanford NLP ReFT源代码探索 (四)Pyvene论文学习
LlaMA 3 系列博客 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (三) 基于 LlaMA…...

rapidjson 打包过程插入对象
开发过程中遇到一种情况,在打包过程中插入一个字符串(里面是json对象), 官方文档 没看到相关例子,不知道是不是自己粗心没找到。方法RawValue其实是一个通用打包方法,一般情况我们都调用的是String()、Int(…...
NVeloDocx一个基于NVelocity的word模版引擎
NVeloDocx是一个基于NVelocity的Word模版引擎,目前主要是用于E6低代码开发平台供用户轻松制作各种Word报告模版。 有以下优点: 1、完全的NVelocity语法; 2、直接在Word中写NVelocity脚本,使用非常非常方便; 3、完全兼…...
【JavaEE】Spring IoCDI详解
一.基本概念 1.Ioc基本概念 Ioc: Inversion of Control (控制反转), 也就是说 Spring 是⼀个"控制反转"的容器. 什么是控制反转呢? 也就是控制权反转. 什么的控制权发发了反转? 获得依赖对象的过程被反转了也就是说, 当需要某个对象时, 传统开发模式中需要自己通…...

Bean的作用域
singleton : 单例,IOC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。 prototype : 原型,每次获取都会创建一个新的 bean 实例。也就是说,连续 getBean() 两次,得到的是不同…...
卡尔曼滤波器例子
卡尔曼滤波器 卡尔曼滤波器(Kalman Filter)是一种用于线性系统状态估计的递归算法,可以有效地融合传感器数据和系统模型来估计系统的状态。它在机器人学中广泛应用,尤其是位置和速度等状态的估计。通过卡尔曼滤波器,可以有效地估计机器人在二维平面内的真实位置,并减小测…...

【STM32CubeMX实战】基于NRF24L01与HAL库构建稳定无线通信链路
1. NRF24L01无线模块基础认知 第一次接触NRF24L01这个火柴盒大小的模块时,我完全没想到它能在2.4GHz频段实现2Mbps的高速通信。这个由Nordic公司出品的射频芯片,特别适合嵌入式系统的无线通信需求。它的工作电压范围在1.9V到3.6V之间,实测在3…...
)
从DSB到SSB:用MATLAB图解通信中的‘频谱减肥’术(单边带调制原理可视化)
从DSB到SSB:用MATLAB图解通信中的‘频谱减肥’术 想象一下,你正在参加一场热闹的派对,房间里挤满了人,大家都在高声交谈。突然,主持人宣布要节省空间,要求所有人只能站在房间的左侧或右侧——这就是单边带调…...

手把手教你调试STM32F103的UART4 DMA:从CubeMX配置到逻辑分析仪抓包分析
STM32F103 UART4 DMA调试实战:从CubeMX配置到逻辑分析仪波形解析 在嵌入式开发中,UART通信是最基础也最常用的外设之一。当通信数据量大或实时性要求高时,直接使用中断方式处理每个字节会显著增加CPU负担。DMA(直接内存访问&#…...

2026厦门国际智能交通运输产业博览会开幕:海外需求与国内先进技术的双向奔赴
2026年5月13日,为期三天的2026厦门国际智能交通运输产业博览会(CITSE 2026,以下简称“智交会”)隆重开幕。本届智交会由中国智能交通协会联合厦门会展集团股份有限公司共同举办,以“聚焦产业创新变革,赋能出…...

Hermes Agent框架对接Taotoken聚合API的详细配置步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent框架对接Taotoken聚合API的详细配置步骤指南 1. 准备工作 在开始配置之前,你需要准备好两样东西…...

电源扰动测试与功率分析仪应用实践
1. 电源扰动测试的核心价值与行业需求在电力电子产品的研发验证阶段,电源扰动测试是评估设备可靠性的关键环节。我曾在某工业电源模块项目中,因忽视电源扰动测试导致产品在东南亚市场出现大规模故障——当地电网电压频繁跌落至170V,使得我们的…...

Rust数据库实战:Rusqlite SQLite深度解析
Rust数据库实战:Rusqlite SQLite深度解析 引言 在Rust开发中,SQLite是构建轻量级数据库应用的核心技术。作为一名从Python转向Rust的后端开发者,我深刻体会到Rusqlite在SQLite操作方面的优势。Rusqlite是Rust生态中最流行的SQLite客户端库&am…...

终极Java数据结构指南:从链表到红黑树的实现与原理
终极Java数据结构指南:从链表到红黑树的实现与原理 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向编写Java核心内容。如果本仓…...

卡梅德生物技术快报|骆驼纳米抗体:从原核表达、高通量测序到分子对接全流程实现
1. 问题背景(技术痛点)靶向结合分子开发中,传统抗体制备存在:分子量大,扩散与穿透效率有限;文库构建与淘选周期长,难以规模化;原核表达与纯化体系不稳定,批次差异大&…...

AI驱动数字营销平台架构解析:从工作流引擎到品牌个性化
1. 项目概述:一个AI驱动的数字营销代理平台最近在GitHub上看到一个挺有意思的项目,叫windagency/valora.ai。乍一看这个仓库名,可能很多人会有点懵,这到底是做什么的?是AI工具,还是营销平台?作为…...