音视频开发19 FFmpeg 视频解码- 将 h264 转化成 yuv
视频解码过程

FFmpeg流程
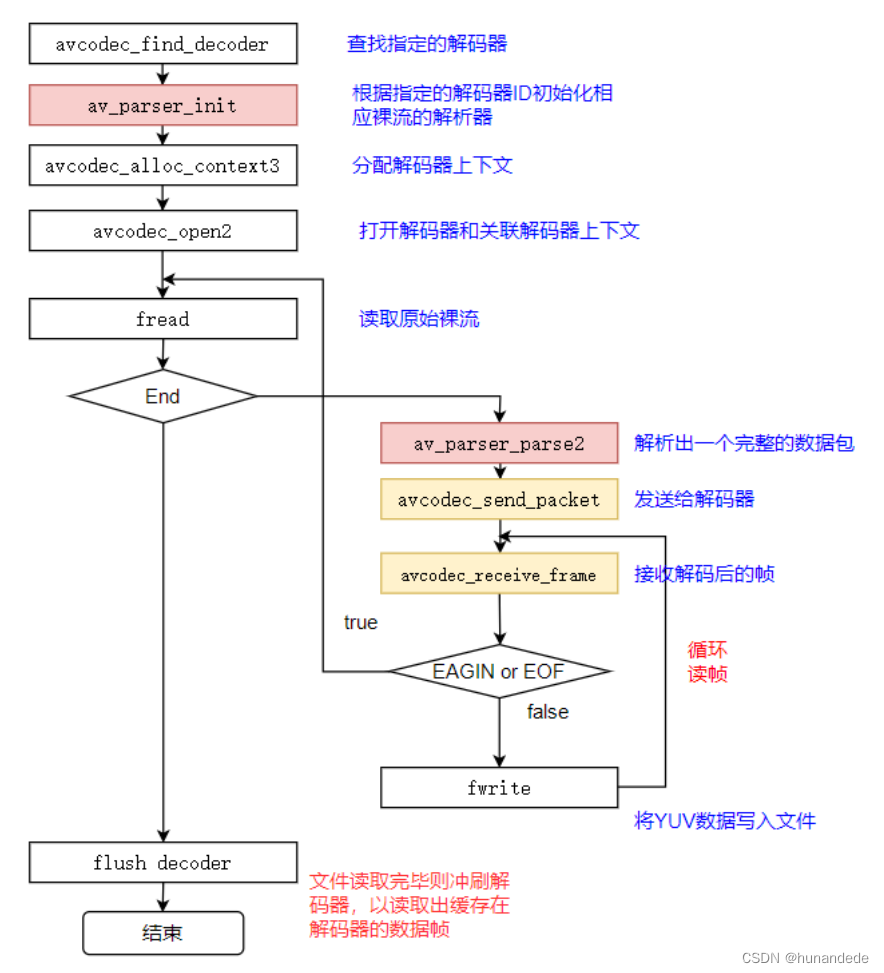
这里的流程是和音频的解码过程一样的,不同的只有在存储YUV数据的时候的形式
存储YUV 数据
如果知道YUV 数据的格式
前提:这里我们打开的h264文件,默认是YUV420P 格式的,
我们可以通过 AVFrame->frame 获得,获得的值如果是视频就 是 AVPixelFormat。
我们可以通过 AVPixelFormat ,知道该视频的编码是啥?
在正常情况下,我们需要判断AVPixelFormat是那种类型,当前代码中并没有判断是因为我们默认使用的YUV420P,那么怎么存储这个YUV420P呢?
首先我们这里要明白,一个AVFrame就是一张图片,假设AVframe 我们存储的是322 * 356 ,322并不是16的整倍数,322/16 = 20......2 也就是说一行会有2个字节的剩余
那么这个剩余的2个字节,怎么办呢?会多给14个字节和剩余的2个字节 结合起来。
因此如果我们用和音频类似的写法: fwrite(frame->data[0], 1, frame->width * frame->height, outfile) 去写,就会有问题,因为要保证这里 width是16的整倍数
这时候就要用到 ffmpeg 的AVFrame给我们提供的 linesize[x]了,
核心代码
// 一般H264默认为 AV_PIX_FMT_YUV420P, 具体怎么强制转为 AV_PIX_FMT_YUV420P 在音视频合成输出的时候讲解// frame->linesize[1] 因为有字节对齐的问题。// 这里先回顾一下 音频的处理方式,在交错模式的时候,使用的 声道数*每个声道有多少个音频样本 * 每个样本占用多少个字节,这是因为音频上 没有字节对齐的问题//字节对齐问题的根本是因为 ,对于一张 322 * 356 的图片来说 ,322并不是16的整倍数,322/16 = 20......2 也就是说一行会有2个字节的剩余//那么这个剩余的2个字节,怎么办呢?会多给14个字节和剩余的2个字节 结合起来。//因此如果我们用和音频类似的写法: fwrite(frame->data[0], 1, frame->width * frame->height, outfile) 去写,就会有问题,因为要保证这里 width是16的整倍数//这时候就要用到 ffmpeg 的AVFrame给我们提供的 linesize[x]了,// uint8_t *data[AV_NUM_DATA_POINTERS]:
// 指向实际的帧数据的指针数组。
// 对于视频帧,这通常是图像平面(如YUV中的Y、U、V平面)。
// 对于音频帧,这通常是音频通道的数据指针。// int linesize[AV_NUM_DATA_POINTERS]:
// 每一行(视频)或每一个音频通道(音频)的大小。
// 对于视频,这通常是图像宽度的字节数。如果图像的宽度 除以 16 有余数,则这个值会凑成16的倍数。
// 对于音频,这通常是这个通道的字节数大小。 在交错模式下: 理论上等于 声道数 * 每个声道有多少个音频样本 * 每个样本占用多少个字节
// 但是,测试发现,在第一个AVFrame包和最后一个 AVframe的时候,linesize[0]的值 比 声道数 * 每个声道有多少个音频样本 * 每个样本占用多少个字节 大于64.//了解了linesize[]的意义,对于一个avframe,就是包含了一帧,就是一张图片,//YUV420P的存储方式是这样的 YYYYYYYYUUVV
// 那么对于 一张 YUV420P (322 * 120)的图片来看,有多少个Y 呢?多少个U,多少个V呢?
// Y的个数为:有 120行,一行一行的存储,每一行的实际大小为322, 但是存储322个Y后,就结束了吗?没有 ,因为有字节对齐问题,因此每次存储完322后,还要跳过14个字节,也就是实际大小为linesize[0],//我们先将Y全部存储完毕。//再存储U,U的个数是多少呢?这里要回头看一下YUV420P存储结构图,这里只是结论:宽高均是Y的一半,因此这里要注意存储U的写法//V的存储和U是一样的。// 正确写法 linesize[]代表每行的字节数量,所以每行的偏移是linesize[],但是真正存储的值 Y 是宽度,for(int j=0; j<frame->height; j++)fwrite(frame->data[0] + j * frame->linesize[0], 1, frame->width, outfile);for(int j=0; j<frame->height/2; j++)fwrite(frame->data[1] + j * frame->linesize[1], 1, frame->width/2, outfile);for(int j=0; j<frame->height/2; j++)fwrite(frame->data[2] + j * frame->linesize[2], 1, frame->width/2, outfile);// 错误写法 用source.200kbps.766x322_10s.h264测试时可以看出该种方法是错误的// 写入y分量
// fwrite(frame->data[0], 1, frame->width * frame->height, outfile);//Y
// // 写入u分量
// fwrite(frame->data[1], 1, (frame->width) *(frame->height)/4,outfile);//U:宽高均是Y的一半
// // 写入v分量
// fwrite(frame->data[2], 1, (frame->width) *(frame->height)/4,outfile);//V:宽高均是Y的一半AVCodecParser说明
avcodec_send_packet
avcodec_receive_frame
所有的代码
/**
* @projectName 07-05-decode_audio
* @brief 解码音频,主要的测试格式aac和mp3
* @author Liao Qingfu
* @date 2020-01-16
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#include <libavutil/frame.h>
#include <libavutil/mem.h>#include <libavcodec/avcodec.h>#define VIDEO_INBUF_SIZE 20480
#define VIDEO_REFILL_THRESH 4096static char err_buf[128] = {0};
static char* av_get_err(int errnum)
{av_strerror(errnum, err_buf, 128);return err_buf;
}static void print_video_format(const AVFrame *frame)
{printf("width: %u\n", frame->width);printf("height: %u\n", frame->height);printf("format: %u\n", frame->format);// 格式需要注意
}static void decode(AVCodecContext *dec_ctx, AVPacket *pkt, AVFrame *frame,FILE *outfile)
{int ret;/* send the packet with the compressed data to the decoder */ret = avcodec_send_packet(dec_ctx, pkt);if(ret == AVERROR(EAGAIN)){fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");}else if (ret < 0){fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",av_get_err(ret), pkt->size);return;}/* read all the output frames (infile general there may be any number of them */while (ret >= 0){// 对于frame, avcodec_receive_frame内部每次都先调用ret = avcodec_receive_frame(dec_ctx, frame);if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)return;else if (ret < 0){fprintf(stderr, "Error during decoding\n");exit(1);}static int s_print_format = 0;if(s_print_format == 0){s_print_format = 1;print_video_format(frame);}printf("video frame data = %f \n", (frame->width) * (frame->height) * 1.5);printf("frame->line[0] = %d \n",frame->linesize[0]);printf("frame->line[1] = %d \n",frame->linesize[1]);printf("frame->line[2] = %d \n",frame->linesize[2]);printf("frame->pkt_size = %d \n",frame->pkt_size);// 一般H264默认为 AV_PIX_FMT_YUV420P, 具体怎么强制转为 AV_PIX_FMT_YUV420P 在音视频合成输出的时候讲解// frame->linesize[1] 因为有字节对齐的问题。// 这里先回顾一下 音频的处理方式,在交错模式的时候,使用的 声道数*每个声道有多少个音频样本 * 每个样本占用多少个字节,这是因为音频上 没有字节对齐的问题//字节对齐问题的根本是因为 ,对于一张 322 * 356 的图片来说 ,322并不是16的整倍数,322/16 = 20......2 也就是说一行会有2个字节的剩余//那么这个剩余的2个字节,怎么办呢?会多给14个字节和剩余的2个字节 结合起来。//因此如果我们用和音频类似的写法: fwrite(frame->data[0], 1, frame->width * frame->height, outfile) 去写,就会有问题,因为要保证这里 width是16的整倍数//这时候就要用到 ffmpeg 的AVFrame给我们提供的 linesize[x]了,// uint8_t *data[AV_NUM_DATA_POINTERS]:
// 指向实际的帧数据的指针数组。
// 对于视频帧,这通常是图像平面(如YUV中的Y、U、V平面)。
// 对于音频帧,这通常是音频通道的数据指针。// int linesize[AV_NUM_DATA_POINTERS]:
// 每一行(视频)或每一个音频通道(音频)的大小。
// 对于视频,这通常是图像宽度的字节数。如果图像的宽度 除以 16 有余数,则这个值会凑成16的倍数。
// 对于音频,这通常是这个通道的字节数大小。 在交错模式下: 理论上等于 声道数 * 每个声道有多少个音频样本 * 每个样本占用多少个字节
// 但是,测试发现,在第一个AVFrame包和最后一个 AVframe的时候,linesize[0]的值 比 声道数 * 每个声道有多少个音频样本 * 每个样本占用多少个字节 大于64.//了解了linesize[]的意义,对于一个avframe,就是包含了一帧,就是一张图片,//YUV420P的存储方式是这样的 YYYYYYYYUUVV
// 那么对于 一张 YUV420P (322 * 120)的图片来看,有多少个Y 呢?多少个U,多少个V呢?
// Y的个数为:有 120行,一行一行的存储,每一行的实际大小为322, 但是存储322个Y后,就结束了吗?没有 ,因为有字节对齐问题,因此每次存储完322后,还要跳过14个字节,也就是实际大小为linesize[0],//我们先将Y全部存储完毕。//再存储U,U的个数是多少呢?这里要回头看一下YUV420P存储结构图,这里只是结论:宽高均是Y的一半,因此这里要注意存储U的写法//V的存储和U是一样的。// 正确写法 linesize[]代表每行的字节数量,所以每行的偏移是linesize[],但是真正存储的值 Y 是宽度,for(int j=0; j<frame->height; j++)fwrite(frame->data[0] + j * frame->linesize[0], 1, frame->width, outfile);for(int j=0; j<frame->height/2; j++)fwrite(frame->data[1] + j * frame->linesize[1], 1, frame->width/2, outfile);for(int j=0; j<frame->height/2; j++)fwrite(frame->data[2] + j * frame->linesize[2], 1, frame->width/2, outfile);// 错误写法 用source.200kbps.766x322_10s.h264测试时可以看出该种方法是错误的// 写入y分量
// fwrite(frame->data[0], 1, frame->width * frame->height, outfile);//Y
// // 写入u分量
// fwrite(frame->data[1], 1, (frame->width) *(frame->height)/4,outfile);//U:宽高均是Y的一半
// // 写入v分量
// fwrite(frame->data[2], 1, (frame->width) *(frame->height)/4,outfile);//V:宽高均是Y的一半}
}
// 注册测试的时候不同分辨率的问题
// 提取H264: ffmpeg -i source.200kbps.768x320_10s.flv -vcodec libx264 -an -f h264 source.200kbps.768x320_10s.h264
// 提取MPEG2: ffmpeg -i source.200kbps.768x320_10s.flv -vcodec mpeg2video -an -f mpeg2video source.200kbps.768x320_10s.mpeg2
// 播放:ffplay -pixel_format yuv420p -video_size 768x320 -framerate 25 source.200kbps.768x320_10s.yuv
int main(int argc, char **argv)
{const char *outfilename;const char *filename;const AVCodec *codec;AVCodecContext *codec_ctx= NULL;AVCodecParserContext *parser = NULL;int len = 0;int ret = 0;FILE *infile = NULL;FILE *outfile = NULL;// AV_INPUT_BUFFER_PADDING_SIZE 在输入比特流结尾的要求附加分配字节的数量上进行解码uint8_t inbuf[VIDEO_INBUF_SIZE + AV_INPUT_BUFFER_PADDING_SIZE];uint8_t *data = NULL;size_t data_size = 0;AVPacket *pkt = NULL;AVFrame *decoded_frame = NULL;// if (argc <= 2)
// {
// fprintf(stderr, "Usage: %s <input file> <output file>\n", argv[0]);
// exit(0);
// }
// filename = argv[1];
// outfilename = argv[2];filename = "D:/AllInformation/qtworkspacenew/07-06-decode_video/source.200kbps.768x320_10s.h264";outfilename = "D:/AllInformation/qtworkspacenew/07-06-decode_video/source.200kbps.768x320_10s.yuv";//我们这里 768x320_10s 是使用的 YUV420p格式,那么一张图片的大小应该为 768*320*1.5 = 368640 bit = 46080 bytes = 45 kb//我们这里计算这个,就是为了查看是否 avframe 的大小.log如下,因为768除以16是没有余数的,因此这里没有字节对齐问题,
// video frame data = 368640.000000
// frame->line[0] = 768
// frame->line[1] = 384
// frame->line[2] = 384// filename = "D:/AllInformation/qtworkspacenew/07-06-decode_video/source.200kbps.766x322_10s.h264";
// outfilename = "D:/AllInformation/qtworkspacenew/07-06-decode_video/source.200kbps.766x322_10s.yuv";//我们这里 766x322_10s 是使用的 YUV420p格式,那么一张图片的大小应该为 766*322*1.5 = 369,978 bit = 46247.25 bytes 约等于 45.16 kb//我们这里计算这个,就是为了查看是否 avframe 的大小 。log如下,说明在766除以16有余数的case下,是有字节对齐的问题存在的,因此在存储这个文件的pcm时候,要注意使用到 linesize[x]// video frame data = 369978.000000
// frame->line[0] = 768
// frame->line[1] = 384
// frame->line[2] = 384printf("aaa\n");pkt = av_packet_alloc();enum AVCodecID video_codec_id = AV_CODEC_ID_H264;if(strstr(filename, "264") != NULL){video_codec_id = AV_CODEC_ID_H264;}else if(strstr(filename, "mpeg2") != NULL){video_codec_id = AV_CODEC_ID_MPEG2VIDEO;}else{printf("default codec id:%d\n", video_codec_id);}// 查找解码器codec = avcodec_find_decoder(video_codec_id); // AV_CODEC_ID_H264if (!codec) {fprintf(stderr, "Codec not found\n");exit(1);}// 获取裸流的解析器 AVCodecParserContext(数据) + AVCodecParser(方法)parser = av_parser_init(codec->id);if (!parser) {fprintf(stderr, "Parser not found\n");exit(1);}// 分配codec上下文codec_ctx = avcodec_alloc_context3(codec);if (!codec_ctx) {fprintf(stderr, "Could not allocate audio codec context\n");exit(1);}// 将解码器和解码器上下文进行关联if (avcodec_open2(codec_ctx, codec, NULL) < 0) {fprintf(stderr, "Could not open codec\n");exit(1);}// 打开输入文件infile = fopen(filename, "rb");if (!infile) {fprintf(stderr, "Could not open %s\n", filename);exit(1);}// 打开输出文件outfile = fopen(outfilename, "wb");if (!outfile) {av_free(codec_ctx);exit(1);}// 读取文件进行解码data = inbuf;data_size = fread(inbuf, 1, VIDEO_INBUF_SIZE, infile);while (data_size > 0){if (!decoded_frame){if (!(decoded_frame = av_frame_alloc())){fprintf(stderr, "Could not allocate audio frame\n");exit(1);}}ret = av_parser_parse2(parser, codec_ctx, &pkt->data, &pkt->size,data, data_size,AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0);if (ret < 0){fprintf(stderr, "Error while parsing\n");exit(1);}data += ret; // 跳过已经解析的数据data_size -= ret; // 对应的缓存大小也做相应减小if (pkt->size)decode(codec_ctx, pkt, decoded_frame, outfile);if (data_size < VIDEO_REFILL_THRESH) // 如果数据少了则再次读取{memmove(inbuf, data, data_size); // 把之前剩的数据拷贝到buffer的起始位置data = inbuf;// 读取数据 长度: VIDEO_INBUF_SIZE - data_sizelen = fread(data + data_size, 1, VIDEO_INBUF_SIZE - data_size, infile);if (len > 0)data_size += len;}}/* 冲刷解码器 */pkt->data = NULL; // 让其进入drain modepkt->size = 0;decode(codec_ctx, pkt, decoded_frame, outfile);fclose(outfile);fclose(infile);avcodec_free_context(&codec_ctx);av_parser_close(parser);av_frame_free(&decoded_frame);av_packet_free(&pkt);printf("main finish, please enter Enter and exit\n");return 0;
}
播放测试:
ffplay -pixel_format yuv420p -video_size 768x320 -framerate 25
source.200kbps.768x320_10s.yuv分离H264或mpeg2video视频格式数据
提取H264:
提取MPEG2:
FFmpeg命令查找-f 后面的格式
相关文章:
音视频开发19 FFmpeg 视频解码- 将 h264 转化成 yuv
视频解码过程 视频解码过程如下图所示: ⼀般解出来的是420p FFmpeg流程 这里的流程是和音频的解码过程一样的,不同的只有在存储YUV数据的时候的形式 存储YUV 数据 如果知道YUV 数据的格式 前提:这里我们打开的h264文件,默认是YU…...
Mysql 常用命令 详细大全【分步详解】
1、启动和停止MySQL服务 // 暂停服务 默认 80 net stop mysql80// 启动服务 net start mysql80// 任意地方启动 mysql 客户端的连接 mysql -u root -p 2、输入密码 3、数据库 4、DDL(Data Definition Language )数据 定义语言, 用来定义数据库对象(数…...
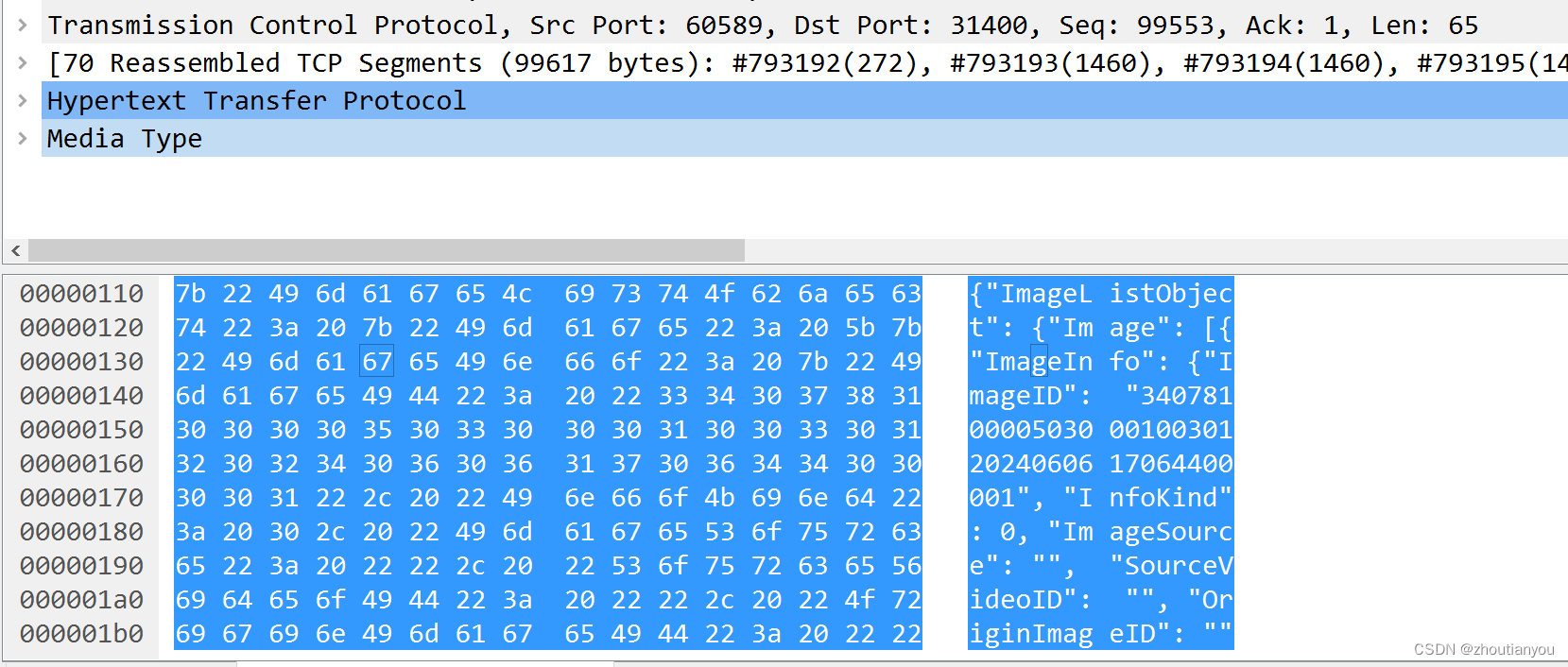
基于百度接口的实时流式语音识别系统
目录 基于百度接口的实时流式语音识别系统 1. 简介 2. 需求分析 3. 系统架构 4. 模块设计 4.1 音频输入模块 4.2 WebSocket通信模块 4.3 音频处理模块 4.4 结果处理模块 5. 接口设计 5.1 WebSocket接口 5.2 音频输入接口 6. 流程图 程序说明文档 1. 安装依赖 2.…...

AIGC作答《2024年高考作文|新课标I卷》能拿多少分?
AIGC作答《2024年高考作文|新课标I卷》能拿多少分? 一、前言二、题目三、作答 一、前言 如火如荼的2024年高考圆满落幕,在如此Happy的时刻,AIGC技术正以其前所未有的热度席卷全球。它不仅改变了我们获取信息的方式,也…...

WHAT - 发布订阅
目录 一、常见实现方案1.1 使用事件发射器(Event Emitter)1.2 自定义事件系统(EventBus)1.3 使用库如 PubSubJS1.4 使用框架内置的状态管理工具Vue.jsReact (使用 Context API 或 Redux) 二、先后关系2.1 缓存事件数据2.2 使用 Re…...
useEffect)
React@16.x(23)useEffect
目录 1,介绍作用介绍 2,注意点2.1,参数1,副作用函数2.1.1,运行时间点2.1.2,返回值2.1.3,闭包的影响2.1.4,严禁出现在代码块中(判断,循环)2.1.5&am…...

算法竞赛一句话解题经典问题分析 ©ntsc 2024
原名:算法竞赛一句话解题&经典问题分析 ©ntsc 2024 处理进度 绿:P1381【~P(今日进度)】蓝:P1099 致CSDN网友: 本文章不定期更新!文章链接: 经典问题分析 基础知识与编程…...

【TensorFlow深度学习】强化学习中的贝尔曼方程及其应用
强化学习中的贝尔曼方程及其应用 强化学习中的贝尔曼方程及其应用:理解与实战演练贝尔曼方程简介应用场景代码实例:使用Python实现贝尔曼方程求解状态价值结语 强化学习中的贝尔曼方程及其应用:理解与实战演练 在强化学习这一复杂而迷人的领…...

牛客 NC129 阶乘末尾0的数量【简单 基础数学 Java/Go/PHP/C++】
题目 题目链接: https://www.nowcoder.com/practice/aa03dff18376454c9d2e359163bf44b8 https://www.lintcode.com/problem/2 思路 Java代码 import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改ÿ…...

【Spring Boot】异常处理
异常处理 1.认识异常处理1.1 异常处理的必要性1.2 异常的分类1.3 如何处理异常1.3.1 捕获异常1.3.2 抛出异常1.3.4 自定义异常 1.4 Spring Boot 默认的异常处理 2.使用控制器通知3.自定义错误处理控制器3.1 自定义一个错误的处理控制器3.2 自定义业务异常类3.2.1 自定义异常类3…...

Laravel学习-自定义辅助函数
因为laravel框架的辅助函数helpers不会进入版本库,被版本库忽略的,只有自己创建一个helpers辅助函数。 可以在任意文件下创建helpers.php文件,建议在app目录下, 然后在composer.json文件中,autoload 中间,…...

LLVM Cpu0 新后端6
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...
GAT1399协议分析(9)--图像上传
一、官方定义 二、wirechark实例 有前面查询的基础,这个接口相对简单很多。 请求: 文本化: POST /VIID/Images HTTP/1.1 Host: 10.0.201.56:31400 User-Agent: python-requests/2.32.3 Accept-Encoding: gzip, deflate Accept: */* Connection: keep-alive content-type:…...

Spring ApplicationContext的getBean方法
Spring ApplicationContext的getBean方法 在Spring框架的ApplicationContext中,getBean(Class<T> requiredType)方法可以接受一个类类型参数,这个参数可以是接口类也可以是实现类。 使用接口类: 如果requiredType是一个接口,…...
—— 自动摘要)
自然语言处理(NLP)—— 自动摘要
自动摘要是一种将长文本信息浓缩为短文本的技术,旨在保留原文的主要信息和意义。 1 自动摘要的第一种方法 它的第一种方法是基于理解的,受认知科学和人工智能的启发。 在这个方法中,我们首先建立文本的语义表示,这可以理解为文本…...

Spring RestClient报错:400 Bad Request : [no body]
我项目采用微服务架构,所以各服务之间通过Spring RestClient远程调用,本来一直工作得好好的,昨天突然发现远程调用一直报错,错误详情如下: org.springframework.web.client.HttpClientErrorException$BadRequest: 400…...
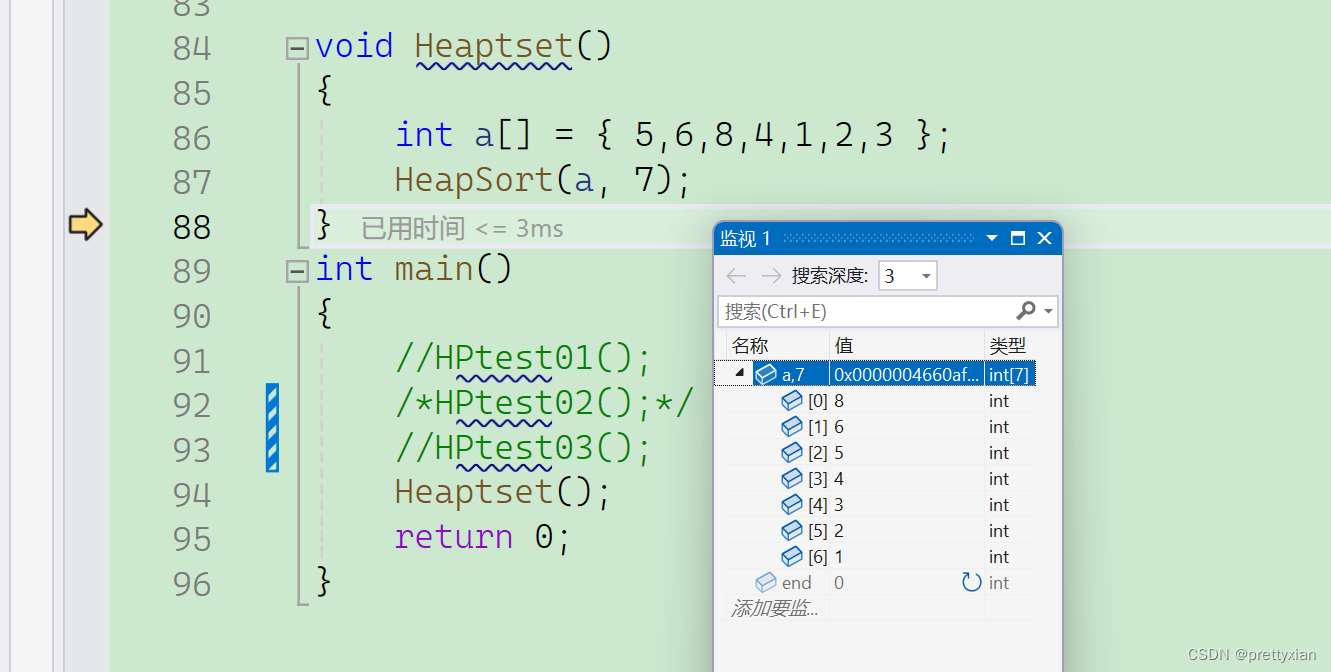
【数据结构】 -- 堆 (堆排序)(TOP-K问题)
引入 要学习堆,首先要先简单的了解一下二叉树,二叉树是一种常见的树形数据结构,每个节点最多有两个子节点,通常称为左子节点和右子节点。它具有以下特点: 根节点(Root):树的顶部节…...

C#面:XML与 HTML 的主要区别是什么
C# XML与HTML有以下几个主要区别: 用途不同:XML(eXtensible Markup Language)是一种用于存储和传输数据的标记语言,它的主要目的是描述数据的结构和内容。HTML(HyperText Markup Language)是一…...

java并发-如何保证线程按照顺序执行?
【readme】 使用只有单个线程的线程池(最简单)Thread.join() 可重入锁 ReentrantLock Condition 条件变量(多个) ; 原理如下: 任务1执行前在锁1上阻塞;执行完成后在锁2上唤醒;任务…...

PyCharm中 Fitten Code插件的使用说明一
一. 简介 Fitten Code插件是是一款由非十大模型驱动的 AI 编程助手,它可以自动生成代码,提升开发效率,帮您调试 Bug,节省您的时间,另外还可以对话聊天,解决您编程碰到的问题。 前一篇文章学习了 PyCharm…...
:make与makefile)
第9课:Linux开发工具(四):make与makefile
第9课:Linux开发工具(四):make与makefile 一、为什么我们需要 Makefile? 1.1 IDE 背后的秘密 在使用 Visual Studio 等 IDE 时,我们只需按下 F5 或点击"编译"按钮,程序就会自动完成编…...

告别硬件依赖:用Proteus玩转STM32F1,从CubeMX生成代码到仿真调试的避坑实践
零硬件玩转STM32F103:Proteus仿真全流程与LL库高效开发指南 从真实硬件到虚拟仿真的思维转换 嵌入式开发者的传统认知里,调试灯闪烁必须连接实物开发板——直到他们遇到Proteus。这款电路仿真软件让STM32F103系列芯片在虚拟环境中完美运行,配…...

OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格 对于正在使用 OpenClaw 这类兼容 OpenAI 协议客户端的开发者或团队而言&a…...

034、LVGL默认主题与自定义主题
LVGL默认主题与自定义主题 一次UI“变脸”引发的血案 上周调试一块基于STM32F429的智能家居面板,LVGL版本8.3.5。客户要求界面风格从“科技蓝”改成“暖木色”,我心想不就是改个颜色主题嘛,简单。结果改完lv_conf.h里的LV_THEME_DEFAULT_COLOR_PRIMARY,编译下载,屏幕一亮…...

如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持 对于使用 Hermes Agent 构建复杂应用的开发者而言,其强大的自…...

回流平台深耕闲置翡翠流通,以数字化服务激活珠宝产业新动能
据中国珠宝玉石首饰行业协会数据,我国珠宝玉石首饰产业市场规模持续扩大,翡翠玉石作为第二大珠宝消费品类,市场存量可观。与此同时,发达国家二手高端消费品交易占整个高端消费品市场的20%至30%,我国目前占比约5%&#…...

教育机构搭建AI辅助教学系统时如何通过Taotoken统一接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育机构搭建AI辅助教学系统时如何通过Taotoken统一接口 构建一个服务于师生的AI辅助教学系统,通常需要集成多种能力&a…...

AMD Ryzen嵌入式处理器在COM Express模块上的高性能应用与设计实践
1. 项目概述:当COM Express遇上AMD Ryzen,一次嵌入式设计的性能跃迁 在嵌入式系统设计领域,COM Express(Computer-On-Module Express)模块因其标准化、高集成度和易于扩展的特性,一直是构建紧凑型、高性能嵌…...
)
STM32CubeMX配置I2C驱动ADS1115,从零开始实现高精度电压采集(附完整工程源码)
STM32CubeMX配置I2C驱动ADS1115:从零实现工业级电压采集系统 在嵌入式开发中,高精度模拟信号采集一直是工程师面临的挑战。当我们需要测量微弱电压信号或实现多通道同步采集时,STM32内置ADC往往难以满足精度要求。本文将手把手教你使用STM32C…...
)
Kicad 5.99版本下,这4个插件让PCB设计效率翻倍(附保姆级安装教程)
KiCad 5.99版本效率革命:4款必备插件全解析与实战指南 刚接触KiCad的工程师常会遇到这样的困境:手动布线耗时费力、生产文件导出步骤繁琐、BOM表整理令人头疼。这些问题在中小型项目中尤为明显,往往让设计周期延长30%以上。而KiCad 5.99版本作…...