CI/CD实战面试宝典:从构建到高可用性的全面解析
实战部署与配置
请描述你设计和实现的一个CI/CD pipeline的完整流程,包括构建、测试、部署各个阶段。
我设计的CI/CD pipeline通常包括以下几个阶段:
- 代码提交:开发人员将代码提交到Git仓库,触发CI/CD流程。
- 代码检查:运行静态代码分析工具(如SonarQube),检查代码质量和潜在问题。
- 构建:使用构建工具(如Maven、Gradle)编译代码,打包生成可部署的工件(如Docker镜像)。
- 单元测试:运行单元测试,确保代码的基本功能正确。
- 集成测试:在隔离环境中运行集成测试,验证不同模块之间的交互。
- 部署到测试环境:将构建通过的工件部署到测试环境。
- 端到端测试:运行端到端测试,模拟用户操作,验证应用的整体功能和性能。
- 部署到预生产环境:通过测试后,部署到预生产环境进行最终验证。
- 手动批准:在部署到生产环境前需要手动批准,以确保一切准备就绪。
- 部署到生产环境:将工件部署到生产环境,并进行监控以确保应用稳定运行。
在你的pipeline中,如何处理不同环境(如开发、测试、生产)的配置管理?
我们使用环境变量和配置文件来管理不同环境的配置。在CI/CD pipeline中,我们会根据目标环境动态加载相应的配置文件。比如,可以在部署步骤中使用Kubernetes的ConfigMap和Secret来管理配置,确保每个环境使用不同的配置集。同时,我们会将这些配置文件和环境变量存储在安全的密钥管理系统中(如Vault),以确保敏感信息的安全。
故障排除
你在CI/CD pipeline中遇到过哪些常见的问题?如何进行故障排除和解决?
常见的问题包括构建失败、测试失败、部署失败和环境配置问题。对于这些问题的故障排除:
- 构建失败:检查构建日志,找出错误信息,修复代码或配置。
- 测试失败:分析测试报告,找到失败的测试用例,修复代码或测试脚本。
- 部署失败:检查部署日志和环境配置,确保所有依赖和配置正确。
- 环境配置问题:验证环境变量和配置文件,确保它们与目标环境匹配。
请描述一次CI/CD失败的实例,你是如何诊断并解决这个问题的?
有一次,我们在部署到测试环境时遇到了失败,问题出在数据库连接配置上。首先,我查看了部署日志,发现应用无法连接到数据库。接着,我检查了配置文件,发现数据库的URL配置有误。修正配置后,我重新部署,但问题依然存在。最后,我检查了Kubernetes中的ConfigMap和Secret,发现其中一个环境变量的值被错误地覆盖了。修正这个问题后,重新部署应用,问题得以解决。
进阶自动化
你如何在CI/CD pipeline中实现零停机时间的部署?
实现零停机时间的部署可以使用滚动更新、蓝绿部署或金丝雀发布等策略。在Kubernetes中,滚动更新是最常见的方法。我们可以配置Deployment的更新策略,逐步替换旧的Pod,每次只替换一部分,确保在更新过程中总有Pod在服务。蓝绿部署则是同时运行两套环境(蓝色和绿色),在新版本部署完成并验证通过后,切换流量到新环境。金丝雀发布则是将新版本发布给一小部分用户,逐步增加发布范围,确保在出现问题时能快速回滚。
请解释一下你如何在pipeline中实现自动化回滚(rollback)策略。
我们会在CI/CD pipeline中配置自动化回滚策略,确保在出现问题时能快速恢复到稳定版本。具体方法包括:
- 健康检查:在部署后运行健康检查,验证新版本的状态。如果健康检查失败,自动触发回滚。
- 监控和告警:通过监控工具(如Prometheus、Grafana)监控关键指标,一旦发现异常,自动触发回滚。
- 版本管理:在每次部署前备份当前版本,出现问题时自动恢复到上一个稳定版本。
部署策略
请描述你在Kubernetes中使用过的多种部署策略及其实现方式。
在Kubernetes中,我使用过的部署策略包括滚动更新、蓝绿部署和金丝雀发布。
- 滚动更新:配置Deployment的更新策略,逐步替换旧的Pod,确保在更新过程中总有Pod在服务。
- 蓝绿部署:同时运行两套环境(蓝色和绿色),在新版本部署完成并验证通过后,切换流量到新环境。可以通过Service和Ingress进行流量切换。
- 金丝雀发布:将新版本发布给一小部分用户,逐步增加发布范围,确保在出现问题时能快速回滚。可以通过创建多个Deployment和Service来实现流量控制。
你如何在CI/CD中实现并管理Kubernetes的配置漂移?
我们使用GitOps方法来管理Kubernetes的配置漂移。所有Kubernetes配置文件(如Deployment、Service等)都存储在Git仓库中,通过ArgoCD或Flux等工具监控Git仓库的变化,并自动将变更应用到Kubernetes集群。这样,所有配置变更都有版本控制,任何配置漂移都可以通过查看Git历史记录来追溯和恢复。此外,通过定期审计和监控工具,确保集群状态与配置一致,及时发现和纠正配置漂移。
性能与监控
请描述你在CI/CD pipeline中使用过的性能监控和日志记录工具。
在CI/CD pipeline中,我使用过Prometheus和Grafana进行性能监控,使用ELK Stack(Elasticsearch、Logstash、Kibana)进行日志记录。Prometheus负责采集和存储性能数据,Grafana用于可视化展示和告警配置。ELK Stack用于收集和分析日志,帮助我们排查问题和优化性能。
你如何监控CI/CD pipeline的性能,并在性能下降时进行优化?
我们通过监控工具(如Prometheus和Grafana)实时监控CI/CD pipeline的性能指标,包括构建时间、测试时间、部署时间等。当发现性能下降时,我们会分析监控数据,找出瓶颈。常见的优化措施包括并行执行任务、缓存依赖、增量构建和优化测试。通过这些方法,我们可以提高CI/CD pipeline的效率和稳定性。
资源管理
你如何在CI/CD pipeline中有效管理和优化资源使用?
在CI/CD pipeline中,我们会优化计算资源和存储资源的使用。具体方法包括:
- 并行执行任务:利用多核CPU并行执行独立任务,提高资源利用率。
- 缓存依赖:缓存构建过程中的依赖包和构件,减少重复下载和构建的资源消耗。
- 优化测试:优先运行关键测试,减少非关键测试的频率,降低测试资源的消耗。
- 自动伸缩:使用Kubernetes的自动伸缩功能,根据负载动态调整资源分配。
请描述一次你在CI/CD中遇到的资源瓶颈及其解决方法。
我们曾在CI/CD中遇到过构建时间过长的问题,主要瓶颈在于依赖下载和构建资源不足。为了解决这个问题,我们配置了CI工具缓存依赖包,减少每次构建下载依赖的时间。同时,我们调整了CI服务器的资源配置,增加了CPU和内存,确保构建过程有足够的资源。此外,我们还将构建任务拆分为多个并行执行的步骤,利用多核CPU提升构建速度。
安全与合规
你如何在CI/CD pipeline中实施安全最佳实践?
在CI/CD pipeline中,我们会集成代码扫描和容器镜像扫描工具(如SonarQube、Trivy、Clair),在构建阶段检查代码和镜像中的已知漏洞和安全问题。我们还会使用静态代码分析工具检查代码质量和潜在的安全风险。所有敏感信息(如API密钥、数据库密码)都存储在安全的密钥管理系统中(如Vault),并通过环境变量或配置文件在运行时动态加载。
请描述你如何在CI/CD中实现合规性,确保符合企业或行业标准?
我们会在CI/CD pipeline中集成合规检查工具,确保代码和配置符合企业或行业标准。具体措施包括:
- 代码审计:使用静态代码分析工具检查代码质量和安全性。
- 配置审计:使用工具检查Kubernetes配置是否符合最佳实践和安全标准。
- 日志记录和监控:记录和监控所有CI/CD活动,确保操作可追溯,满足合规性要求。
- **定
期审计**:定期进行安全和合规性审计,及时发现和修复问题。
访问控制
你如何在CI/CD中管理和控制不同角色的访问权限?
我们使用基于角色的访问控制(RBAC)来管理和控制不同角色的访问权限。在CI/CD工具中配置不同角色和权限,确保只有授权人员可以执行特定操作。对于敏感操作(如部署到生产环境),我们会配置多因素认证和手动审批流程,增加安全性。
请解释一下如何在CI/CD pipeline中保护敏感数据。
我们通过密钥管理系统(如Vault、Kubernetes Secrets)保护敏感数据。在CI/CD pipeline中,通过环境变量或配置文件动态加载敏感信息,确保敏感数据在传输和存储过程中加密。我们还会限制对敏感信息的访问权限,确保只有需要的进程或用户可以访问。同时,定期审计和监控访问记录,确保敏感数据的安全。
高可用性与灾难恢复
你如何确保CI/CD系统的高可用性?
为了确保CI/CD系统的高可用性,我们会采取以下措施:
- 分布式架构:使用分布式CI/CD工具(如Jenkins集群、GitLab Runner集群)避免单点故障。
- 自动伸缩:根据负载动态调整CI/CD资源,确保高峰期有足够的处理能力。
- 定期备份:定期备份CI/CD系统的配置和数据,确保在故障时可以快速恢复。
- 监控和告警:使用监控工具(如Prometheus、Grafana)实时监控CI/CD系统状态,设置告警,及时处理异常。
请描述你在CI/CD中实现高可用性和故障转移的经验。
在实现高可用性和故障转移时,我们使用分布式CI/CD工具,配置多实例运行,确保即使一个实例故障,其他实例仍能继续工作。我们还配置了自动伸缩,根据负载动态调整资源,确保系统始终有足够的处理能力。通过定期备份和监控系统状态,我们可以在故障发生时快速恢复,并及时处理异常,确保CI/CD系统的稳定运行。
灾难恢复
请描述你设计和实现的CI/CD灾难恢复策略。
我们设计的CI/CD灾难恢复策略包括定期备份、异地备份和故障演练。定期备份CI/CD系统的配置和数据,确保在故障时可以快速恢复。将备份数据存储在异地,确保即使本地数据丢失,也能从异地备份中恢复。定期进行灾难恢复演练,验证恢复流程的有效性,确保团队熟悉恢复步骤。
你在CI/CD中有过真实的灾难恢复演练经验吗?请详细描述一次演练过程。
有的。我们定期进行灾难恢复演练。一次演练的过程如下:
- 计划演练:确定演练的目标和范围,通知相关团队成员。
- 模拟故障:故意引发某个组件的故障,比如停止Jenkins主节点。
- 执行恢复:根据灾难恢复计划,恢复Jenkins主节点的备份数据,并启动新的实例。
- 验证恢复:检查CI/CD系统的状态,确保所有服务正常运行,所有数据完好无损。
- 总结和改进:记录演练过程中的问题和改进建议,更新灾难恢复计划。
综合实战案例
请描述一次你从零开始设计并实现CI/CD系统的完整案例。
有一次,我们需要为一个新的项目设计并实现CI/CD系统。首先,我们选择了GitLab作为版本控制系统,Jenkins作为CI工具,ArgoCD作为Kubernetes的CD工具。接着,我们在GitLab中创建项目仓库,并配置分支策略。然后,安装和配置Jenkins,创建Job,配置构建触发器,编写Jenkinsfile定义构建、测试、打包和部署的步骤。在Jenkins中配置测试任务,集成单元测试、集成测试和端到端测试。最后,安装和配置ArgoCD,将应用配置存储在Git仓库,通过GitOps实现自动化部署。通过这些步骤,我们搭建了一个完整的CI/CD pipeline,实现了代码的自动化构建、测试和部署,提高了开发和运维效率。
你如何衡量CI/CD系统的成功?有哪些关键指标(KPIs)?
衡量CI/CD系统的成功,可以通过以下关键指标(KPIs):
- 构建时间:从代码提交到构建完成的时间,越短越好。
- 测试通过率:自动化测试的通过率,越高越好。
- 部署频率:代码部署到生产环境的频率,越高越好。
- 失败率:构建、测试和部署失败的次数,越低越好。
- 恢复时间:从发现问题到修复并重新部署的时间,越短越好。
持续改进
你如何持续改进现有的CI/CD pipeline?
我们通过定期审查和反馈机制持续改进现有的CI/CD pipeline。定期审查CI/CD pipeline的性能和效率,分析瓶颈和问题。根据团队反馈和最佳实践,优化构建、测试和部署流程。引入新的工具和技术,提升自动化水平和安全性。定期进行灾难恢复演练和安全审计,确保CI/CD系统的稳定性和安全性。
请描述一次你在CI/CD系统中进行重大改进的经验和效果。
有一次,我们发现CI/CD pipeline的构建时间过长,影响了开发效率。经过分析,我们决定引入并行构建和依赖缓存。首先,我们将构建任务拆分为多个并行执行的步骤,利用多核CPU提升构建速度。然后,我们配置了CI工具缓存依赖包,减少每次构建下载依赖的时间。经过这些改进,构建时间减少了约50%,开发效率显著提升,团队对CI/CD系统的满意度也大大提高。
相关文章:

CI/CD实战面试宝典:从构建到高可用性的全面解析
实战部署与配置 请描述你设计和实现的一个CI/CD pipeline的完整流程,包括构建、测试、部署各个阶段。 我设计的CI/CD pipeline通常包括以下几个阶段: 代码提交:开发人员将代码提交到Git仓库,触发CI/CD流程。代码检查࿱…...
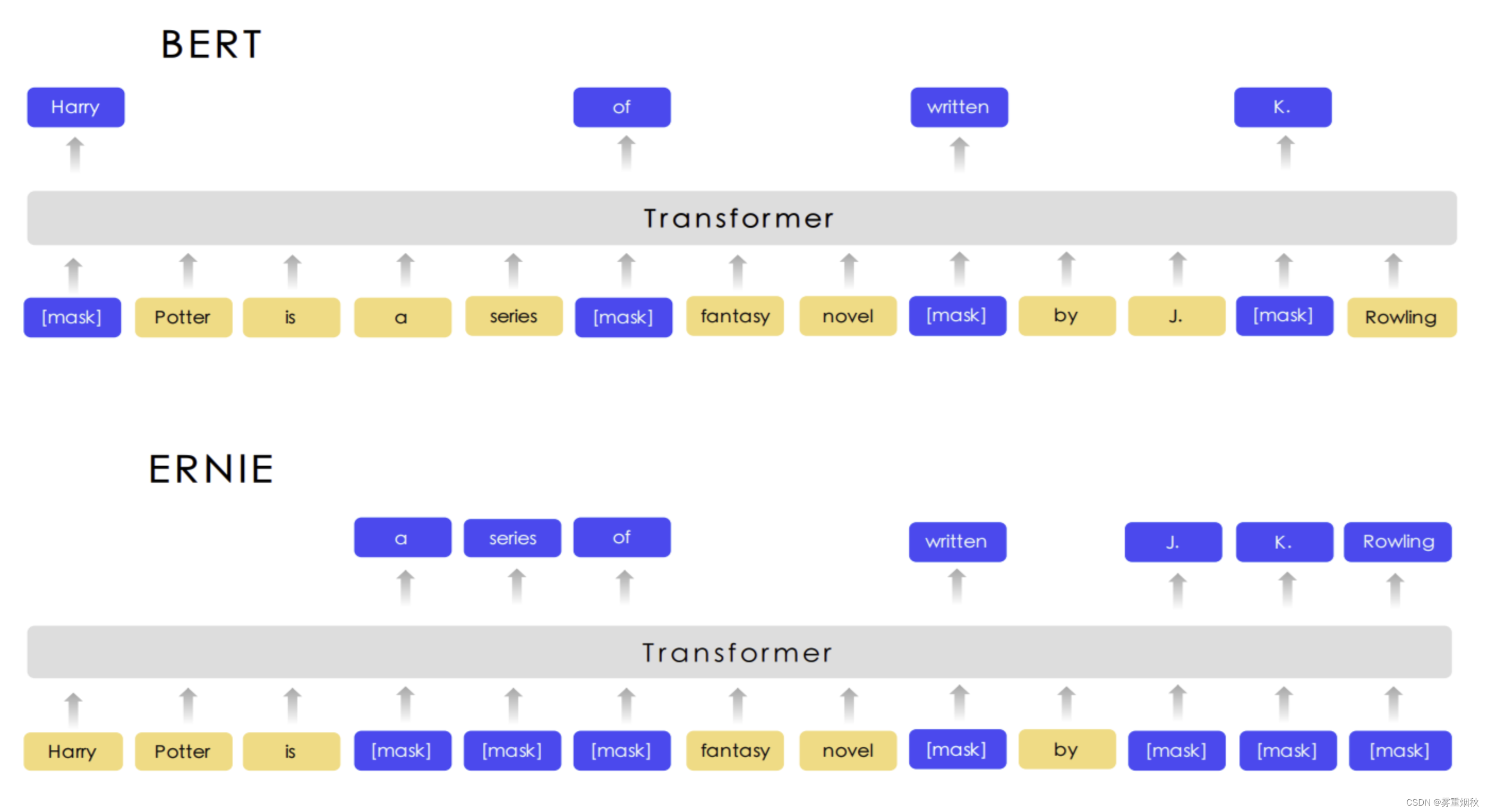
NLP实战入门——文本分类任务(TextRNN,TextCNN,TextRNN_Att,TextRCNN,FastText,DPCNN,BERT,ERNIE)
本文参考自https://github.com/649453932/Chinese-Text-Classification-Pytorch?tabreadme-ov-file,https://github.com/leerumor/nlp_tutorial?tabreadme-ov-file,https://zhuanlan.zhihu.com/p/73176084,是为了进行NLP的一些典型模型的总…...
MySQL: 表的增删改查(基础)
文章目录 1. 注释2. 新增(Create)3. 查询(Retrieve)3.1 全列查询3.2 指定列查询3.3 查询字段为表达式3.4 别名3.5 去重: distinct3.6 排序: order by3.7条件查询3.8 分页查询 4. 修改 (update)5. 删除(delete)6. 内容重点总结 1. 注释 注释:在SQL中可以使用“–空格…...
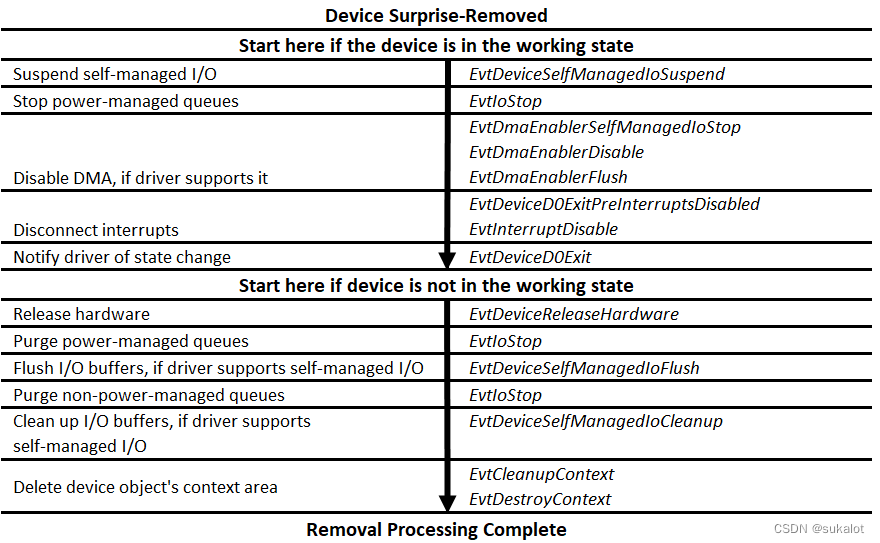
WDF驱动开发-PNP和电源管理(三)
对于PNP设备来说,理解它们的启动和删除顺序,以及意外移除顺序非常重要,在早期,经常有拔插U盘导致windows重启的例子,这就是意外移除带来的问题。 功能或Filter驱动程序的启动顺序 下图显示了框架调用 WDF (KMDF 和 U…...

Redis集群和高可用性:保障Redis服务的稳定性
I. 引言 A. 对Redis的简单介绍和其在现代Web应用中的角色 Redis(REmote DIctionary Server)是一个开源的、基于内存的键值数据库,它支持多种数据结构,如字符串、哈希、列表、集合、有序集合等。由于Redis的高性能和丰富的数据类型,使其在现代Web应用中广泛使用。例如,它…...
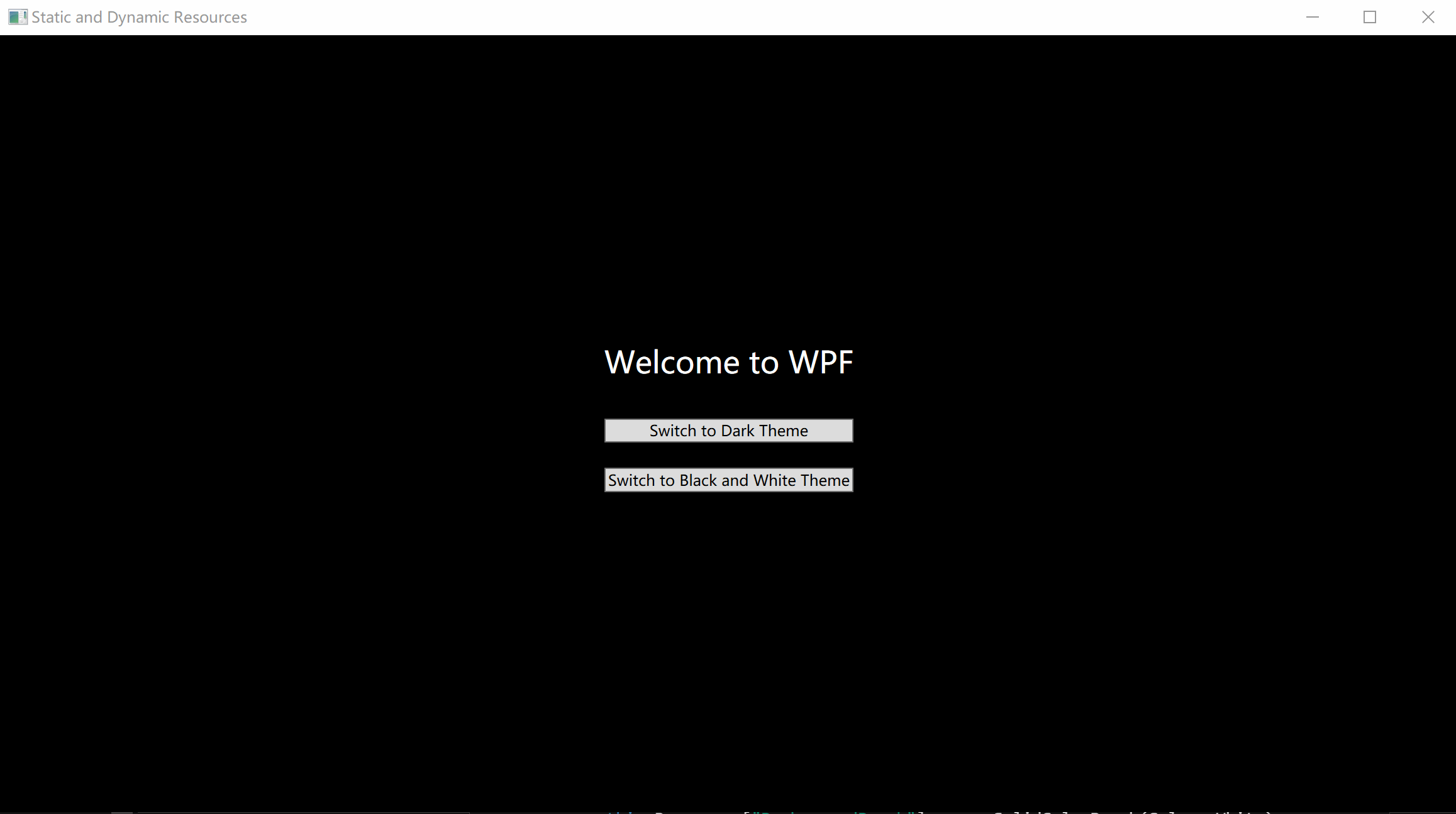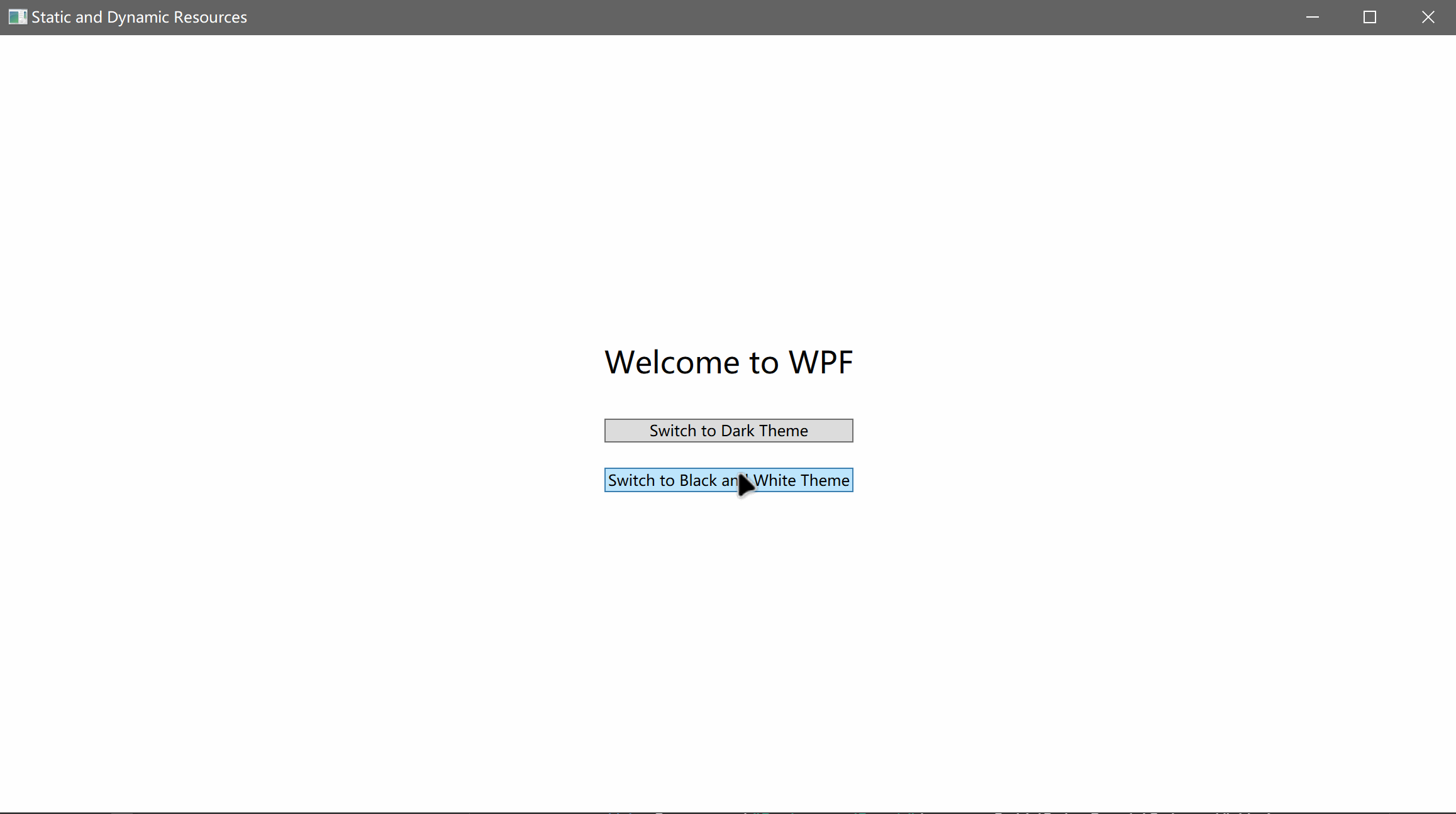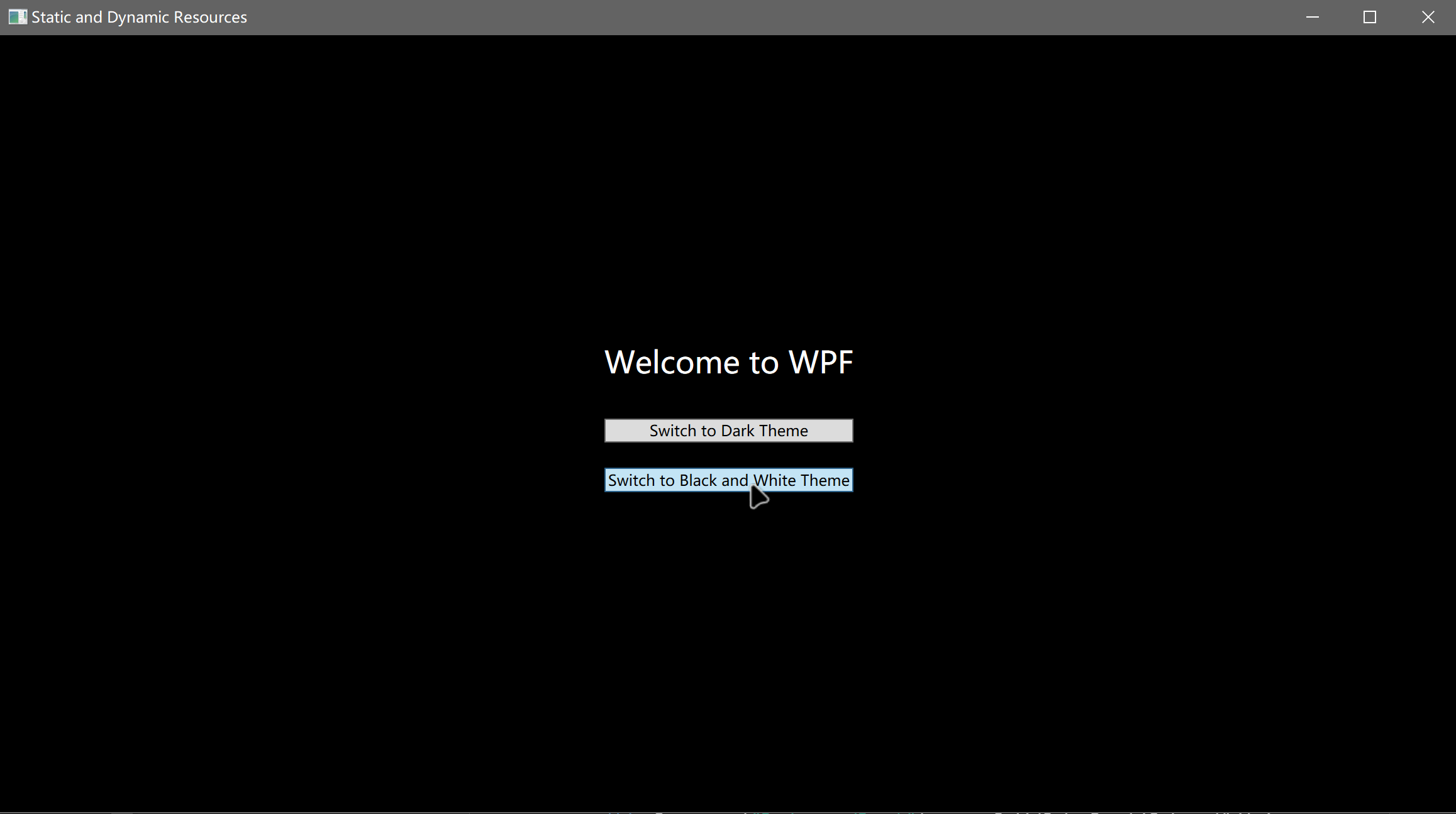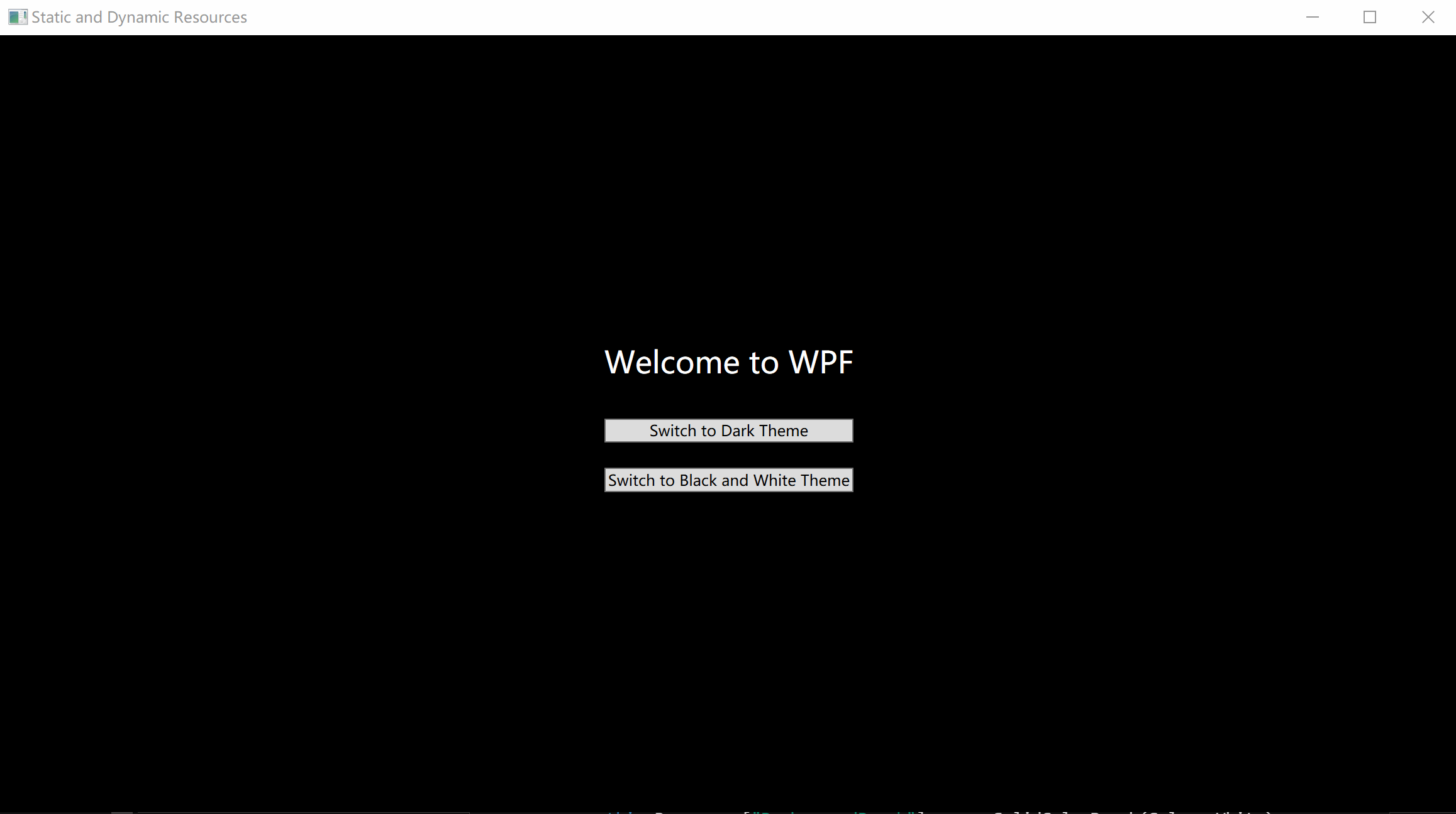
C# WPF入门学习主线篇(二十一)—— 静态资源和动态资源
C# WPF入门学习主线篇(二十一)—— 静态资源和动态资源 欢迎来到C# WPF入门学习系列的第二十一篇。在上一章中,我们介绍了WPF中的资源和样式。本篇文章将深入探讨静态资源(StaticResource)和动态资源(Dynam…...
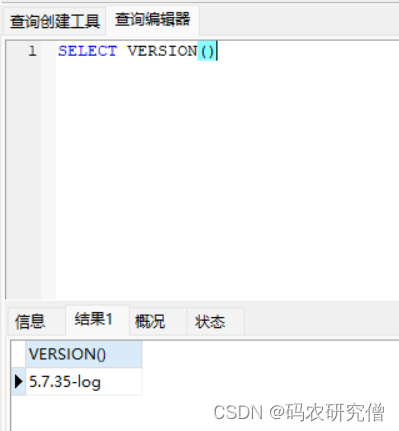
出现 Navicat 和 Cmd 下SQL 版本 | 查询不一致的解决方法
目录 1. 问题所示1.1 查询表格不一致1.2 版本不一致2. 原理分析3. 解决方法1. 问题所示 命令行和数据库使用工具出现不一致的情况,分别有如下情况 1.1 查询表格不一致 使用工具查询当地表格: 使用命令行查询当地表格: 1.2 版本不一致 在cmd命令下mysql --version 查询…...
31、matlab卷积运算:卷积运算、二维卷积、N维卷积
1、conv 卷积和多项式乘法 语法 语法1:w conv(u,v) 返回向量 u 和 v 的卷积。 语法2:w conv(u,v,shape) 返回如 shape 指定的卷积的分段。 参数 u,v — 输入向量 shape — 卷积的分段 full (默认) | same | valid full:全卷积 ‘same…...

C++青少年简明教程:文件
C青少年简明教程:文件 文件是指存储在计算机文件系统中的数据集合。文件可以包含各种类型的信息,例如文本、图像、音频视频等。在 C中,文件是一种数据流,可以用于读取或写入数据。C提供了一系列的文件操作函数,用于实现…...
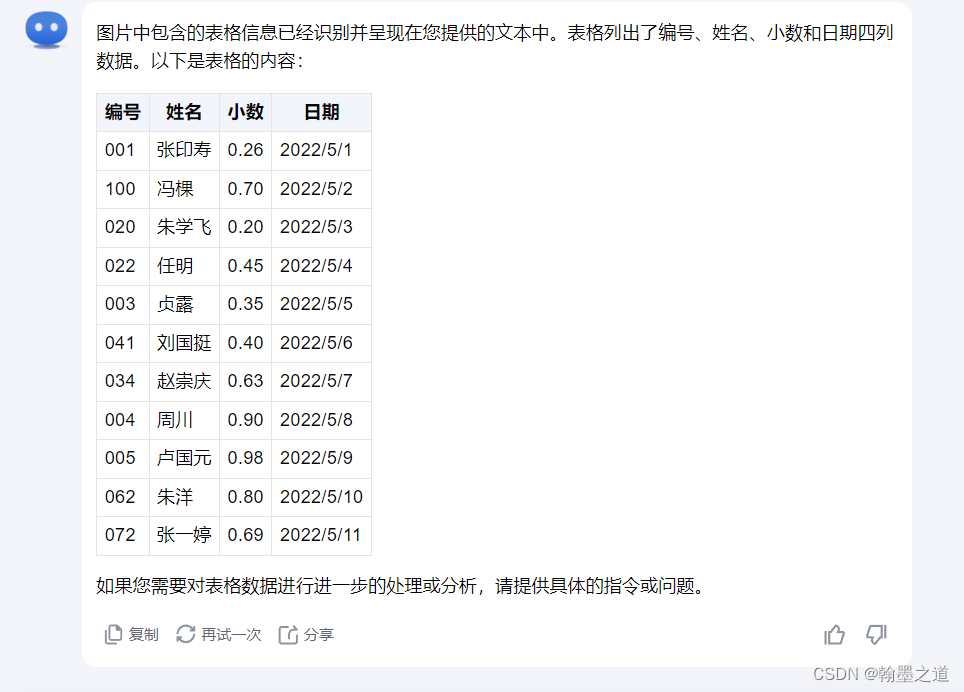
Kimichat使用案例010:快速识别出图片中的表格保存到Excel
文章目录 一、介绍二、图片信息三、输入内容四、输出内容五、markdown提示词六、markdown输出一、介绍 如果有一张图片格式的表格,想要快速复制到Excel表格中,那么一般要借助于OCR工具。之前试过不少在线OCR工具,识别效果差强人意。其实,kimichat就可以非常好的完成这个任务…...
]C语言指针探秘)
[大师C语言(第二十四篇)]C语言指针探秘
引言 在C语言的学习和应用中,指针无疑是最重要、最难以掌握的概念之一。它为C语言提供了强大的功能和灵活性,同时也带来了不少的复杂性。本文将深入探讨C语言指针背后的技术,帮助你更好地理解和应用指针。 第一部分:指针的基本概…...

Docker命令总结
文章目录 Docker命令总结Docker环境Docker容器生命周期Docker容器运维Docker容器rootfsDocker镜像仓库Docker本地镜像管理Docker容器资源Docker系统日志 Docker命令总结 docker命令非常多,这里主要分为8类总结 Docker环境 可以查看Docker版本和自身的详细信息 d…...

把chatgpt当实习生,进行matlab gui程序编程
最近朋友有个项目需要整点matlab代码,无奈自己对matlab这种工科的软件完全是外行,无奈只有求助gpt这种AI助手了。大神们告诉我们,chatgpt等的助手已经是大学实习生水平啦,通过多轮指令交互就可以让他帮你完成工作啦!所…...
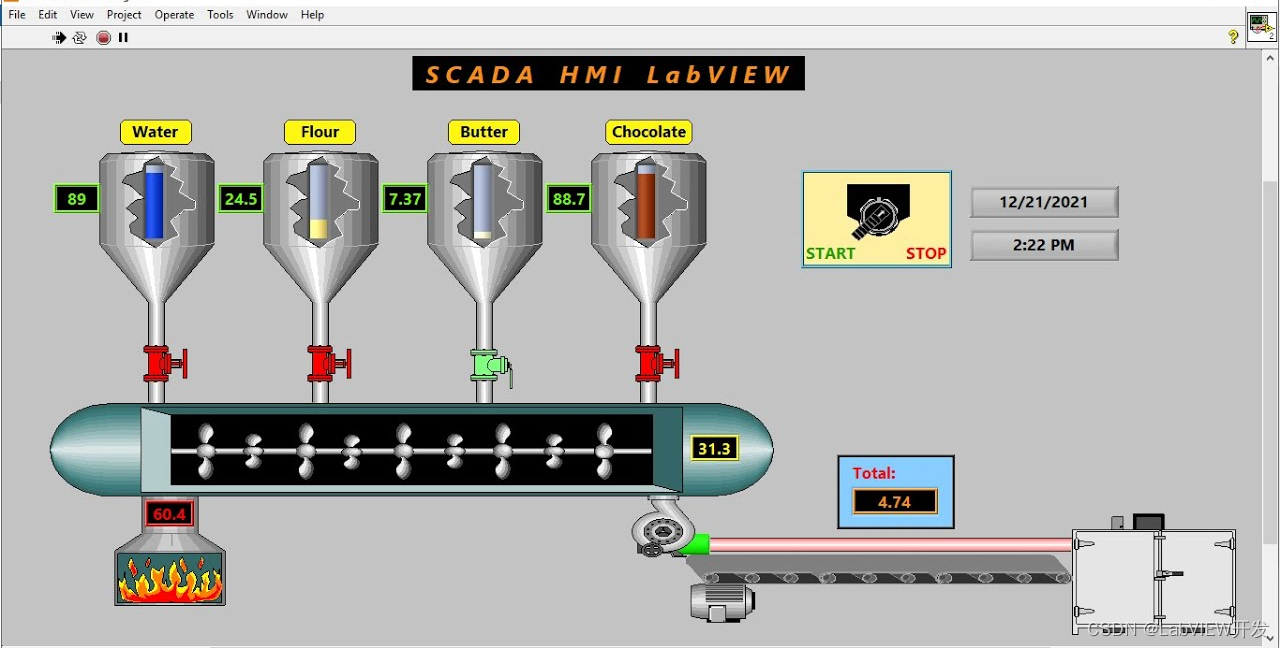
LabVIEW 与组态软件在自动化系统中的应用比较与选择
LabVIEW 确实在非标单机设备、测试和测量系统中有着广泛的应用,特别是在科研、教育、实验室和小型自动化设备中表现突出。然而,LabVIEW 也具备一定的扩展能力,可以用于更复杂和大型的自动化系统。以下是对 LabVIEW 与组态软件在不同应用场景中…...

html--万年历
<!DOCTYPE html> <html lang"zh_CN"><head><meta http-equiv"Content-Type" content"text/html; charsetUTF-8" /><meta charset"utf-8" /><title>万年历</title><link rel"styles…...
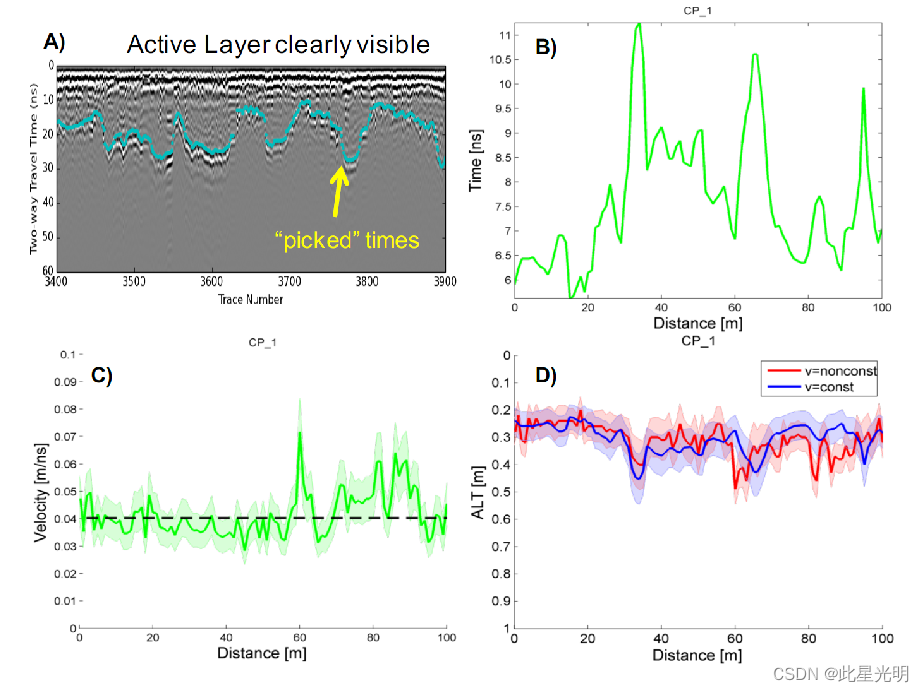
2013年 阿拉斯加巴罗活动层厚度和土壤含水量
Pre-ABoVE: Active Layer Thickness and Soil Water Content, Barrow, Alaska, 2013 ABoVE前:阿拉斯加巴罗活动层厚度和土壤含水量,2013年 简介 文件修订日期:2018-01-10 数据集版本:1 摘要 该数据集提供了 2013 年 8 月在…...

超详解——python数字和运算——小白篇
目录 1.位运算 2. 常用内置函数/模块 math模块: random模块: decimal模块: 3.内置函数: 总结: 1.位运算 位运算是对整数在内存中的二进制表示进行操作。Python支持以下常见的位运算符: 按位与&…...
LabVIEW图像采集处理项目中相机选择与应用
在LabVIEW图像采集处理项目中,选择合适的相机是确保项目成功的关键。本文将详细探讨相机选择时需要关注的参数、黑白相机与彩色相机的区别及其适用场合,帮助工程师和开发者做出明智的选择。 相机选择时需要关注的参数 1. 分辨率 定义:分辨率…...
Java——IO流(一)-(2/9):File类的常用方法(判断文件类型、获取文件信息、创建删除文件、遍历文件夹)
目录 常用方法1:判断文件类型、获取文件信息 方法 实例演示 常用方法2:创建文件、删除文件 方法 实例演示 常用方法3:遍历文件夹 方法 实例演示 常用方法1:判断文件类型、获取文件信息 方法 File提供的判断文件类型、获…...

电子设计入门教程硬件篇之集成电路IC(二)
前言:本文为手把手教学的电子设计入门教程硬件类的博客,该博客侧重针对电子设计中的硬件电路进行介绍。本篇博客将根据电子设计实战中的情况去详细讲解集成电路IC,这些集成电路IC包括:逻辑门芯片、运算放大器与电子零件。电子设计…...

构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增
构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增 【免费下载链接】obsidian-template Starter templates for Obsidian 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-template 在信息过载的时代,知识工作者面临的核心挑战…...
了!手把手教你用Python复现最近邻和双线性插值(附完整代码))
别再只会用cv2.resize()了!手把手教你用Python复现最近邻和双线性插值(附完整代码)
从零实现图像缩放:深入理解最近邻与双线性插值的数学本质 当你在Jupyter Notebook里轻松敲下cv2.resize(img, (300,300))时,有没有想过这个看似简单的操作背后隐藏着怎样的数学魔法?今天我们将撕开OpenCV的封装外壳,用纯Python和N…...

ThunderAI:开源本地AI助手桌面应用部署与核心架构解析
1. 项目概述:一个开源的AI助手桌面应用 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“ThunderAI”。这名字听起来就挺带劲,对吧?点进去一看,是个用Python写的桌面应用程序,核心功能是把几个…...

为OpenClaw配置Taotoken实现高效AI智能体工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken实现高效AI智能体工作流 OpenClaw 是一个流行的开源AI智能体框架,它允许开发者快速构建和编排复…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

动态架构跳跃:让视觉语言大模型高效适配垂直领域任务
1. 项目概述:从“大而全”到“快而准”的模型进化之路 在视觉语言预训练模型(Vision-Language Pre-trained Models, VLPMs)如CLIP、ALIGN等席卷多模态领域的今天,一个核心的工程与学术困境日益凸显:这些动辄数十亿参数…...

不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力
不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力 很多公司一遇到系统卡顿。 第一反应特别统一: 加机器。CPU 不够? 加。 QPS 扛不住? 扩容。 数据库慢? 上集群。 结果最后: 服务器越来越多。 成本越来越高。 系统还是越来越慢。 最离谱的是: 有…...
)
华为eNSP模拟企业网:用VRRP+MSTP搞定500人公司的网络冗余与隔离(附排错记录)
华为eNSP实战:构建500人企业级网络的高可用架构 当一家企业发展到500人规模时,网络架构的稳定性和可靠性就成为业务连续性的关键保障。作为网络工程师,我们经常面临这样的挑战:如何在有限的预算下,设计出既满足部门隔离…...

xhs签名验证机制详解:如何绕过小红书反爬虫系统的终极指南
xhs签名验证机制详解:如何绕过小红书反爬虫系统的终极指南 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 在小红书数据爬取领域,xhs签名验证机制是开…...

5个简单步骤:用DXVK在Linux上流畅运行Windows游戏
5个简单步骤:用DXVK在Linux上流畅运行Windows游戏 【免费下载链接】dxvk Vulkan-based implementation of D3D8, 9, 10 and 11 for Linux / Wine 项目地址: https://gitcode.com/gh_mirrors/dx/dxvk 你是否曾经想在Linux系统上玩Windows游戏,却被…...