C++ 贪心算法——跳跃游戏、划分字母区间

一:跳跃游戏
55. 跳跃游戏
题目描述:给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1,然后从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论你怎么跳,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 ,所以永远不可能到达最后一个下标。
提示:
* 1 <= nums.length <= 10⁴
* 0 <= nums[i] <= 10⁵
解题思路:
这道题最关键的地方就是不要去想在当前位置,我应该跳到哪里去,而是只需要记录当前能到达的最远位置,就可以了,遍历一遍给定的数组,若发现遍历到的当前位置i大于最远可达距离,则说明无法到达,直接返回false,若数组遍历完了,没有返回false,说明遍历到每一个i处时,均小于当时的最远距离,即均可达,返回true。
参考程序:
class Solution {
public:bool canJump(vector<int>& nums) {int k = 0;for (int i = 0; i < nums.size(); i++) {if (i > k) return false;k = max(k, i + nums[i]);}return true;}
};

二:跳跃游戏 II
45. 跳跃游戏 II
题目描述:给定一个长度为 n 的 0 索引整数数组 nums ,初始位置为 nums[0] 。每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
0 <= j <= nums[i]i + j < n
返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1] 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:2
解释:跳到最后一个位置的最小跳跃次数是 2。
从下标为 0 跳跃下标为 1 的位置,跳 1 步,然后再跳 3 步到达数组的最后一个位置。
示例 2:
输入:nums = [2,3,0,1,4]
输出:2
提示:
* 1 <= nums.length <= 10⁴
* 0 <= nums[i] <= 1000
* 题目保证可以到达 nums[n-1]
解题思路:
这道题最关键的地方同样是不要去想在当前位置,我应该跳到哪里去。而且根据每次跳跃所能到达的最远距离,将给定数组划分为很多区间,遍历当前区间中所有值,得到的最远距离,作为下一个区间的右界限,划分的区间数-1即为所需的最少跳跃次数。这么说可能有点懵,下面举一个例子,大家就明白了
例如,对于[2,3,1,1,4,2,1,1,3],起始的时候,只能从索引为0的2处起跳,
则[2,3,1,1,4,2,1,1,3] 划分为 [2] [3,1,1,4,2,1,1,3]
从索引为0的2处起跳,其最远可以到达的索引为2的1处,按最远可到达的区域,划分数组
[2] [3,1,1,4,2,1,1,3] 划分为 [2] [3,1] [1,4,2,1,1,3]
遍历新得到的区间[3,1],记录最远距离,若从3处起跳,最远可到达索引为4的4处,若从1处起跳,则只能到达4前面索引为3的1处,所以当前区间[3,1]起跳,最远可到达索引为4的4处,因此
[2] [3,1] [1,4,2,1,1,3] 划分为 [2] [3,1] [1,4] [2,1,1,3]
同理,遍历新得到的区间[1,4],记录最远距离,若从1处起跳,最远可到达索引为4的4处,若从4处起跳,则最远可以到达后面索引为8的3处,所以当前区间[3,1]起跳,最远可到达索引为8的3处,因此
已经超过或恰好到达最后一个元素,不需要继续划分了,即
起始位置: [2]
第一次跳跃,新的可达区域 [3,1]
第二次跳跃,新的可达区域 [1,4]
第三次跳跃,新的可达区域 [2,1,1,3]
上面过程中遍历当前区间,记录从当前区间起跳可到达的最远距离的过程对应下面程序中的
maxPos = max(nums[i] + i, maxPos);
上面每个区间的右界限,即对应下面程序中的end变量,当遍历完当前区间后,遍历当前区间时得到的最远可达距离maxPos,即为下一个区间的右界限,即end = maxPos;
参考程序:
class Solution {
public:int jump(vector<int>& nums){int ans = 0,end = 0,maxPos = 0;for (int i = 0; i < nums.size() - 1; i++){maxPos = max(nums[i] + i, maxPos);if (i == end){ end = maxPos; ans++;} }return ans;}};

三、划分字母区间
763. 划分字母区间
题目描述:给你一个字符串 s。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s。返回一个表示每个字符片段长度的数组。
示例1:
- 输入:
s = "ababcbacadefegdehijhklij" - 输出:
[9,7,8] - 解释:
划分结果为"ababcbaca", "defegde", "hijhklij"。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 这样的划分是错误的,因为划分的片段数较少。
示例2:
- 输入:
s = "eccbbdbec" - 输出:
[10]
注意:
1 <= s.length <= 500s仅由小写英文字母组成
解决思路一:
①、首先,遍历一遍给定的字符串s,记录每个字母出现的次数,存放在变量int zm[26]中。
②、然后,进行第二遍遍历,在每轮迭代中,将当前字符放入map中, map的键选取为字母映射编号(0~25),值选取为当前出现次数。并进行判断,若map中当前字符出现的次数与第一次遍历时存放在数组zm中的次数相等,说明该字符已经全部出现了,将其从map表中删除。若map表为空,则说明,遍历到当前位置处,前面出现的所有字符,后面均不再出现,可以在此处进行切割,将个数累计变量进行存储(也就是我们所要输出的长度),然后将累计量清零,继续进行下一轮迭代,直至第二遍遍历结束。
上述思路的参考程序如下:
class Solution {
public:vector<int> partitionLabels(string s) {int zm[26]={0}; unordered_map<int,int> map; vector<int> ans; int iter=0;for(int i=0;i<s.size();i++){ zm[s[i]-'a']++;} //第一遍遍历,统计各个字母出现次数for(int i=0;i<s.size();i++) //第二遍遍历,统计切割段数{ map[s[i]-'a']++; // 键选取为字母映射编号(0~25),值选取为当前出现次数auto it = map.begin();while (it != map.end()) {if (it->second == zm[it->first]) it = map.erase(it); else break;}iter++;if(map.empty()) {ans.push_back(iter); iter=0;} //当map为空时,说明当前已经出现过的元素,已经全部出现了}return ans;}
};

上述方案的时间复杂度较低,属于时间最优的算法之一,但由于使用了额外的map表,空间复杂度比较高,下面介绍一种改进方案,不再需要使用额外的map表,从而降低空间复杂度。
解决思路二:
①、首先,同样是遍历一遍给定的字符串s,所不同的是,记录的是每个字符最后出现的位置,存放在int hash[27]中。
②、然后,进行第二遍遍历,最远边界right初始化为0,左边界left初始化为0,在每轮迭代中,对最远边界进行更新,若当前字符i的最远边界大于right,则对right进行更新。在每轮迭代中,会进行判断,若当前字符i处于最远边界right处,则说明,到达了前面出现的所有字符的最远边界处,前面出现的所有字符,后面均不再出现,可以在此处进行切割。right-left+1,即为当前片段的长度,压入结果队列中。并将left更新为i + 1。继续进行下一轮迭代,直至第二遍遍历结束。
上述思路的参考程序如下:
class Solution {
public:vector<int> partitionLabels(string S) {int hash[27] = {0}; // i为字符,hash[i]为字符出现的最后位置for (int i = 0; i < S.size(); i++) { // 统计每一个字符最后出现的位置hash[S[i] - 'a'] = i;}vector<int> result;int left = 0;int right = 0;for (int i = 0; i < S.size(); i++) {right = max(right, hash[S[i] - 'a']); // 找到字符出现的最远边界if (i == right) {result.push_back(right - left + 1);left = i + 1;}}return result;}
}

上述方案的时间复杂度同样较低,属于时间最优的算法之一,且无需使用额外的map表,空间复杂度也得到了有效降低。

相关文章:
C++ 贪心算法——跳跃游戏、划分字母区间
一:跳跃游戏 55. 跳跃游戏 题目描述:给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回 true ࿱…...

汽车数据应用构想(三)
上期说的,用数据去拟合停车信息的应用,那么类似的POI信息相关的场景其实都可以实现。今天讲讲用户使用频率也很高的加油/充电场景。 实际应用中,在加油场景中用户关心的通常还是价格。无论是导航还是各种加油APP/小程序,都已经很…...

体素技术在AI绘画中的革新作用
随着人工智能技术的不断进步,AI绘画已经成为艺术创作和视觉设计领域的一大趋势。在众多推动AI绘画发展的技术中,体素技术以其独特的优势,正在逐渐改变着我们对计算机生成图像的认识。本文旨在探讨体素技术在AI绘画中的应用与影响,…...

Leetcode.866 回文质数
题目链接 Leetcode.866 回文质数 rating : 1938 题目描述 给你一个整数 n n n ,返回大于或等于 n n n 的最小 回文质数。 一个整数如果恰好有两个除数: 1 1 1 和它本身,那么它是 质数 。注意, 1 1 1 不是质数。 例如…...
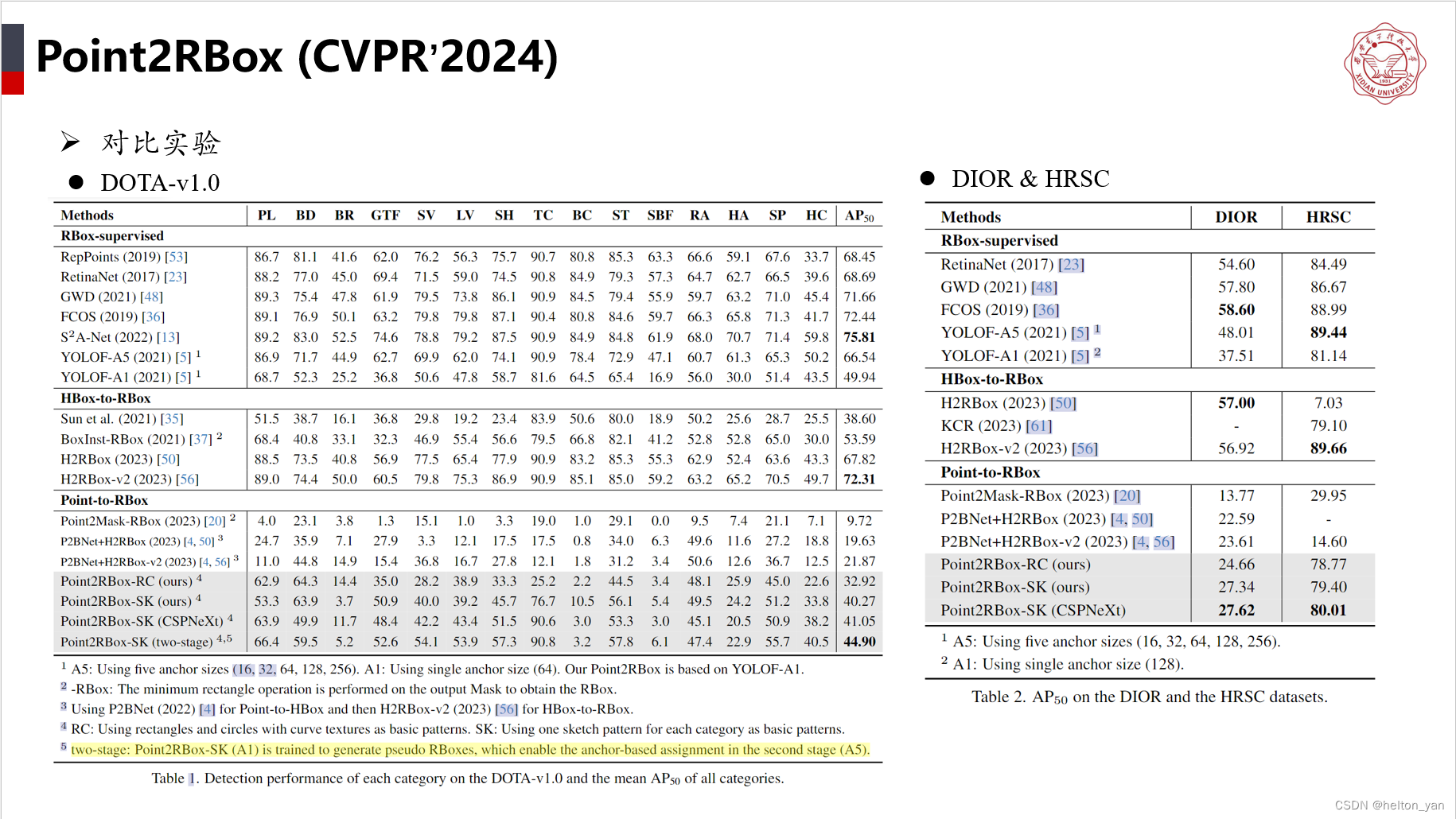
【论文阅读】Point2RBox (CVPR’2024)
paper:https://arxiv.org/abs/2311.14758 code:https://github.com/yuyi1005/point2rbox-mmrotate...

深度学习的点云分割
深度学习的点云分割 点云分割是计算机视觉中的一个重要任务,特别是在三维数据处理和分析中。点云数据是由大量三维点构成的集合,每个点包含空间坐标(x, y, z),有时还包含其他信息如颜色和法向量。点云分割的目标是将点…...

【知识点】c++模板特化
在 C 中,模板特化分为全特化(full specialization)和偏特化(partial specialization)。它们允许程序员为特定类型或类型模式提供不同的实现,以覆盖通用模板的默认行为。 模板全特化 模板全特化是指为某个…...

算法家族之一——二分法
目录 算法算法的打印效果如果算法里的整型“i”为1如果算法里的整型“i”为11 算法的流程图算法的实际应用总结 大家好,我叫 这是我58,现在,请看下面的算法。 算法 #define _CRT_SECURE_NO_WARNINGS 1//<--预处理指令 #include <stdi…...
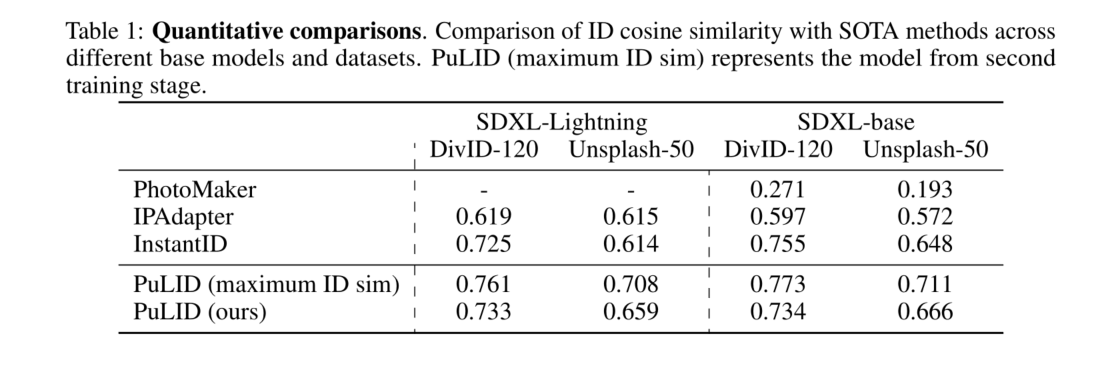
【深度学习】PuLID: Pure and Lightning ID Customization via Contrastive Alignment
论文:https://arxiv.org/abs/2404.16022 代码:https://github.com/ToTheBeginning/PuLID 文章目录 AbstractIntroductionRelated WorkMethods Abstract 我们提出了一种新颖的、无需调整的文本生成图像ID定制方法——Pure and Lightning ID customizatio…...

Elastic 8.14:用于简化分析的 Elasticsearch 查询语言 (ES|QL) 正式发布
作者:来自 Elastic Brian Bergholm 今天,我们很高兴地宣布 Elastic 8.14 正式发布。 什么是新的? 8.14 版本最重要的标题是 ES|QL 的正式发布(GA),它是从头开始设计和专门构建的,可大大简化数据调查。在新的查询引擎的…...

C语言指针与数组的区别
在C语言中,指针和数组虽然在很多情况下可以互换使用,但它们在概念上和行为上存在一些区别。下面详细解释这些区别: ### 数组 1. **固定大小**:数组在声明时必须指定大小,这个大小在编译时确定,之后不能改…...

springboot3一些听课笔记
文章目录 一、错误处理机制1.1 默认1.2 自定义 二、嵌入式容器 一、错误处理机制 1.1 默认 错误处理的自动配置都在ErrorMvcAutoConfiguration中,两大核心机制: ● 1. SpringBoot 会自适应处理错误,响应页面或JSON数据 ● 2. SpringMVC的错…...

【小沐学Python】Python实现Web服务器(CentOS下打包Flask)
文章目录 1、简介2、下载Python3、编译Python4、安装PyInstaller5、打包PyInstaller6、相关问题6.1 ImportError: urllib3 v2 only supports OpenSSL 1.1.1, currently the ssl module is compiled with OpenSSL 1.0.2k-fips 26 Jan 2017. See: https://github.com/urllib3/url…...

Cesium开发环境搭建(一)
1.下载安装Node.js 进入官网地址下载安装包 Node.js — Download Node.js https://cdn.npmmirror.com/binaries/node/ 选择对应你系统的Node.js版本,这里我选择的是Windows系统、64位 安装完成后,WINR,输入node --version,显示…...
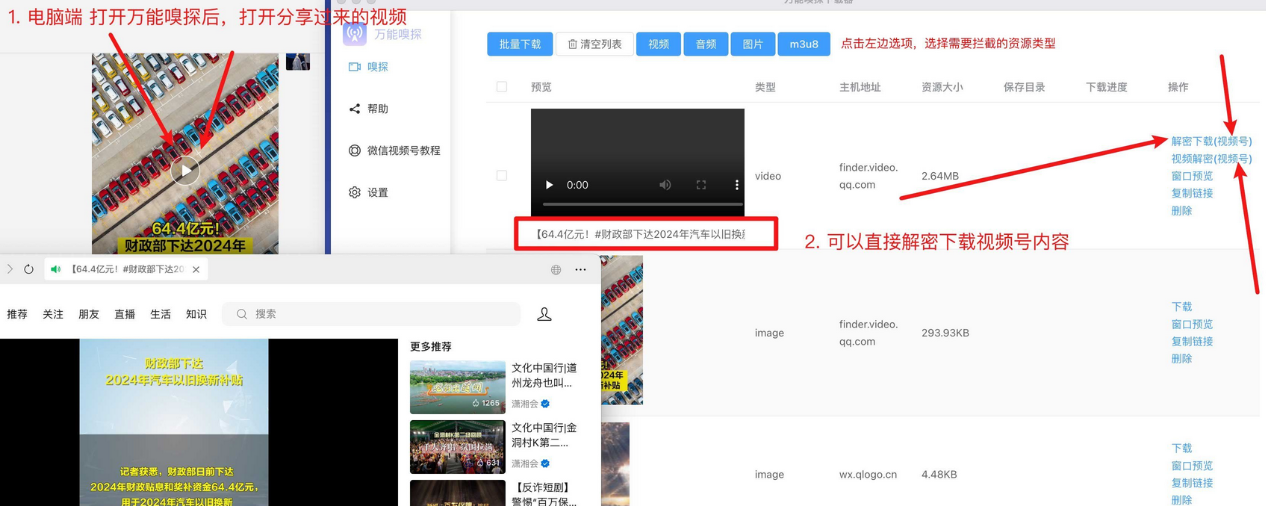
视频、图片、音频资源抓取(支持视频号),免安装,可批量,双端可用!
今天分享一款比较好用资源嗅探软件,这个嗅探工具可以下载视频号,界面干净,可以内容预览和批量下载,看到这里你是不是想用它爬很多不得了的东西。这款软件无需安装,打开即用。同时他支持windows系统和Mac系统,是一款不可…...
FreeRTOS实时系统 在任务中增加数组等相关操作 导致单片机起不来或者挂掉
在调试串口任务中增加如下代码,发现可以用keil进行仿真,但是烧录程序后,调试串口没有打印,状态灯也不闪烁,单片机完全起不来 博主就纳了闷了,究竟是什么原因,这段代码可是公司永流传的老代码了&…...

CentOS 7基础操作08_Linux查找目录和文件
1、which命令——查找用户所执行的命令文件存放的目录 which命令用于查找Linux命令程序并显示所在的具体位置.其搜索范围主要由用户的环境变量PATH决定(可以执行言echo sPATH”命令查看),这个范围也是Linux操作系统在执行命令或程序时的默认搜索路径。 which命令使用要查找的命…...

CI/CD实战面试宝典:从构建到高可用性的全面解析
实战部署与配置 请描述你设计和实现的一个CI/CD pipeline的完整流程,包括构建、测试、部署各个阶段。 我设计的CI/CD pipeline通常包括以下几个阶段: 代码提交:开发人员将代码提交到Git仓库,触发CI/CD流程。代码检查࿱…...
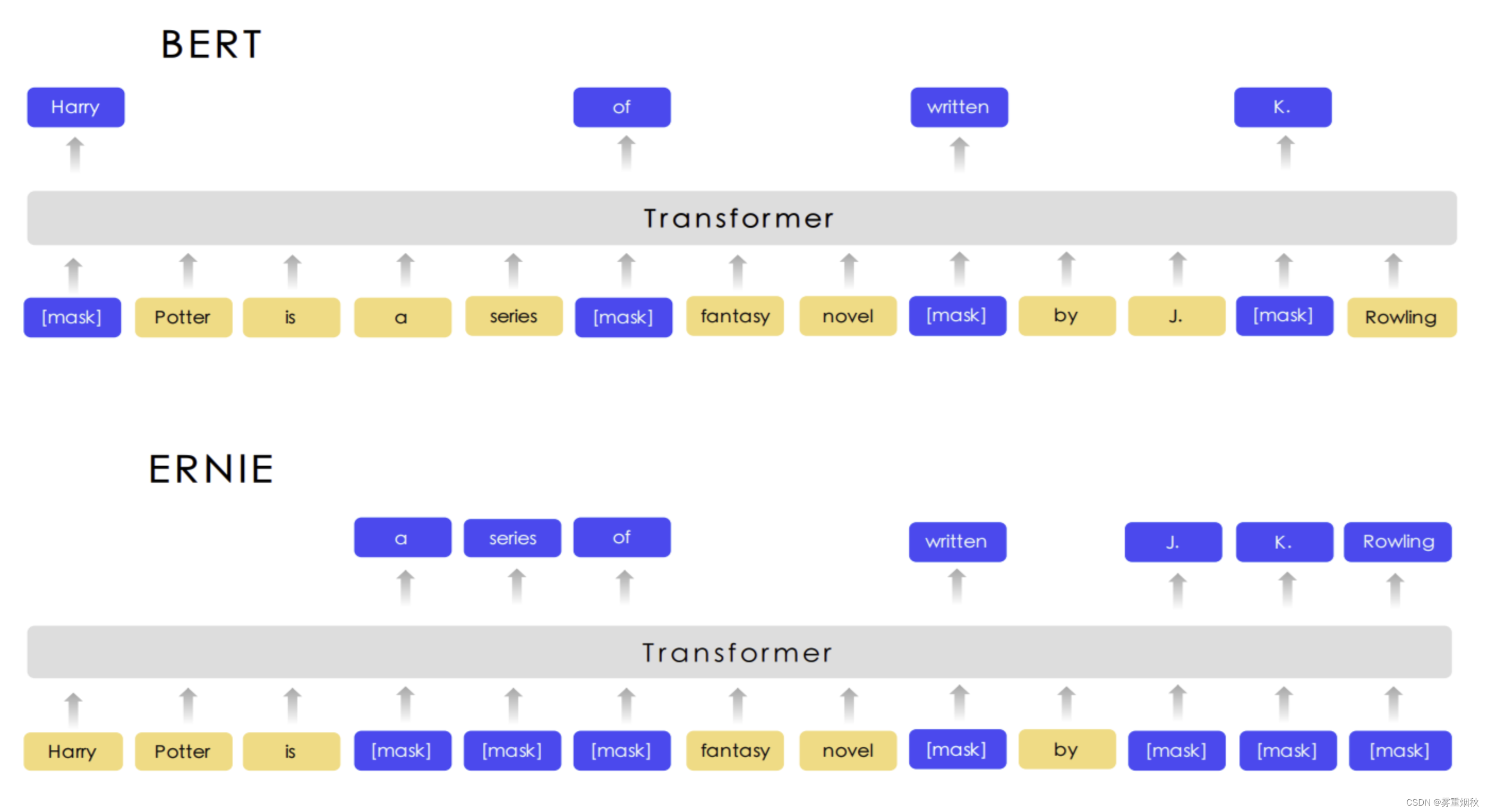
NLP实战入门——文本分类任务(TextRNN,TextCNN,TextRNN_Att,TextRCNN,FastText,DPCNN,BERT,ERNIE)
本文参考自https://github.com/649453932/Chinese-Text-Classification-Pytorch?tabreadme-ov-file,https://github.com/leerumor/nlp_tutorial?tabreadme-ov-file,https://zhuanlan.zhihu.com/p/73176084,是为了进行NLP的一些典型模型的总…...
MySQL: 表的增删改查(基础)
文章目录 1. 注释2. 新增(Create)3. 查询(Retrieve)3.1 全列查询3.2 指定列查询3.3 查询字段为表达式3.4 别名3.5 去重: distinct3.6 排序: order by3.7条件查询3.8 分页查询 4. 修改 (update)5. 删除(delete)6. 内容重点总结 1. 注释 注释:在SQL中可以使用“–空格…...

告别 Origin 内卷|虎贲等考 AI 科研绘图,一键出期刊级学术图
很多做毕业论文、发期刊、做课题的同学和科研人,都卡在同一个难题上:论文写得再好,却栽在科研绘图上。想用专业软件,Origin、Visio、GraphPad 上手难、参数复杂、调试半天出不来一张合格图;用 Excel、PPT 随手做图&…...

AI写测试靠谱吗?深度体验Diffblue Cover后,我总结了这3个真实使用场景和2个坑
AI写测试靠谱吗?深度体验Diffblue Cover后的实战思考 第一次在IntelliJ的插件市场看到Diffblue Cover时,我的反应和大多数Java开发者一样——"这玩意儿真能自动写测试?"作为在金融行业摸爬滚打八年的老码农,我见过太多号…...

三指拖拽革命:在Windows上解锁macOS级触控板体验的终极指南
三指拖拽革命:在Windows上解锁macOS级触控板体验的终极指南 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersD…...

NVIDIA Profile Inspector终极指南:200+隐藏参数解锁显卡性能新高度
NVIDIA Profile Inspector终极指南:200隐藏参数解锁显卡性能新高度 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款功能强大的显卡驱动参数调校工具…...

别再只会用Matplotlib画基础热力图了!这5个高级定制技巧让你的图表更专业
别再只会用Matplotlib画基础热力图了!这5个高级定制技巧让你的图表更专业 热力图是数据可视化中最直观的展示方式之一,但大多数数据分析师止步于基础用法。当你的图表需要出现在学术论文、商业报告或投资人演示中时,默认参数生成的热力图往往…...

3分钟拯救你的B站缓存视频:m4s-converter让珍贵回忆永不消失
3分钟拯救你的B站缓存视频:m4s-converter让珍贵回忆永不消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的困扰…...
)
别再硬怼tabular了!用LaTeX的minipage环境搞定不规则子图排版(附代码对比)
LaTeX排版革命:用minipage环境实现不规则子图的高效布局 在学术写作和技术文档中,图片排版常常成为LaTeX用户的痛点。当遇到需要将不同尺寸的子图组合成一个整体时,传统方法往往陷入复杂的表格嵌套和间距调整的泥潭。本文将介绍一种更优雅的解…...

刘教链|百万美刀的比特币:VanEck的预言与微策略的进化困境
BTC在8万刀附近磨了一周。就在市场踟蹰不前的时候,VanEck抛出一个大胆的预测[1]。一、VanEck的百万预言5月9日,VanEck的投资主管Matthew Sigel说了一番话。他认为比特币会在下一届美国总统任期结束前达到100万美刀[1],算下来大概是2031年前后…...

Musa并行搜索工具:重塑信息检索工作流,提升多源对比效率
1. 项目概述:重新定义你的搜索工作流如果你和我一样,每天的工作都离不开在浏览器里反复横跳——为了一个技术问题,先在 Google 搜一遍,再去 Stack Overflow 看看有没有新答案,接着打开 ChatGPT 问问它的看法࿰…...

光纤偏振测量:从琼斯矢量到庞加莱球,六种工具深度解析与工程实践
1. 从一道周五小测题说起:光纤测量中的偏振态表征上周五,我在整理旧资料时,翻到了EE Times在2015年发布的一篇“周五小测”文章,主题是光纤光学测量。其中第一道题就很有意思,它问的是:“以下哪种工具不能用…...