手写kNN算法的实现-用欧几里德空间来度量距离
kNN的算法思路:找K个离预测点最近的点,然后让它们进行投票决定预测点的类型。
- step 1: kNN存储样本点的特征数据和标签数据
- step 2: 计算预测点到所有样本点的距离,关于这个距离,我们用欧几里德距离来度量(其实还有很多其他的,比如曼哈顿距离等),并进行排序,拿出前k个样本点。
- step 3: 统计前k个样本点的类别,以最多的那个类型作为预测结果。
欧几里德距离:
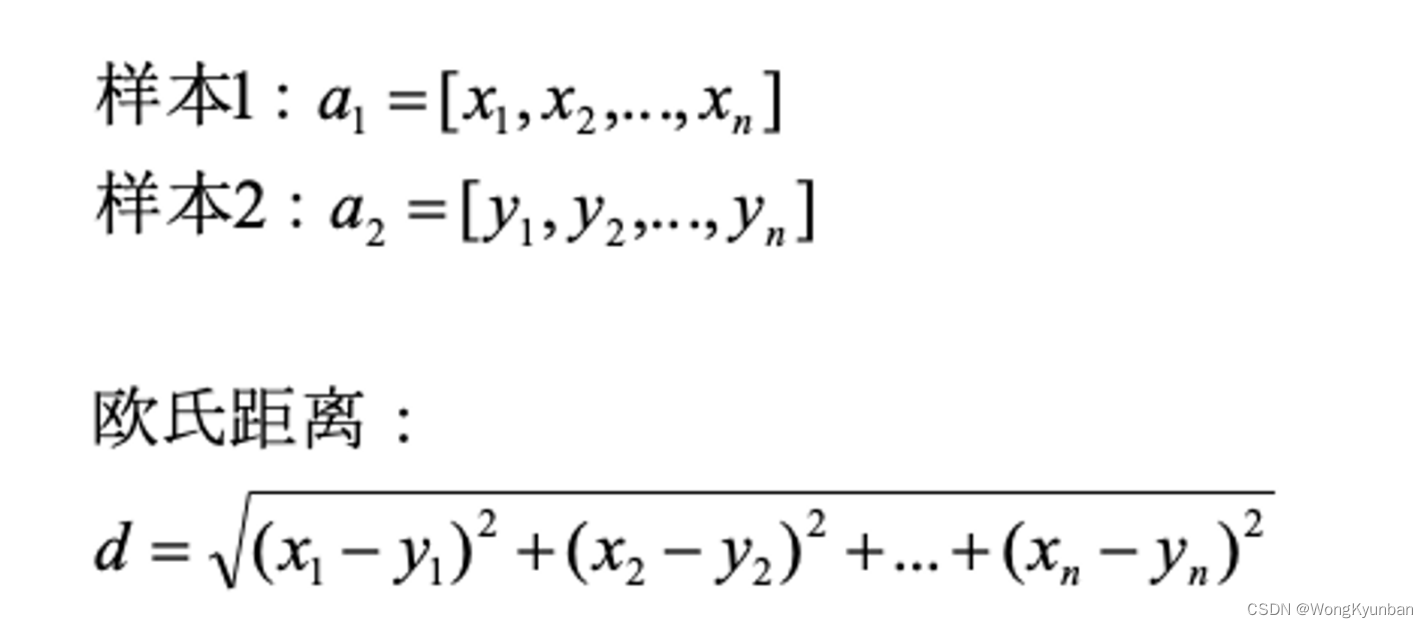
上代码:
import numpy as np
# 用于统计
from collections import Counterclass MyKnn:# 初始化投票的数量,neighbors表示我们要找的点的数量,用于投票决定预测点的类型def __init__(self,neighbors):self.k = neighbors# 因为kNN是一个惰性机器性学习模型,只在预测阶段才会用到的训练数据,不存在训练阶段。或者说在所谓的训练阶段,只是为了存储样本数据。# X为特征集# Y为对应的标签集def fit(self,X,Y):self.X = np.array(X)self.Y = np.array(Y)# 如果特征集不是矩阵阵列或则标签集不是一维数组,都直接抛异常。if self.X.ndim != 2 or self.Y.ndim != 1:raise Exception("dimensions are wrong!")# 如果标签的数量不竺于特征集的行数也直接抛异常if self.X.shape[0] != self.Y.shape[0]:raise Exception("input labels are not correct!")def predict(self,X_pre):# 这是要预测的点pre = np.array(X_pre)# 判断测试点的矩阵是不是和样本点的矩阵一样的,不是直接抛异常if self.X.ndim != pre.ndim:raise Exception("input dimensions are wrong!")# 我们用rs数组来存储预测结果rs = []for p in pre:# 用temp临时数组来存储预测点到所有样本点的欧几里德距离temp = []for a in self.X:# 取出每一个样本点来与预测点计算欧几里德距离# np.sqrt(((p - a) ** 2).sum(-1)) 算出距离,先求出每预测点到样本点的差值,再平方,再将所有平方后的值加在一起,最后对加起来的结果进行开方,得到欧几里德距离。并临时存储在temp数组里temp.append(np.sqrt(((p - a) ** 2).sum(-1)))temp = np.array(temp)# 对所有距离进行排序,用np.argsort排序时,结果对识破距离的下标,而不是具体的值,因为我们并不关心具体的值,我们只要前k个点。用np.argsort排序完,取出前k个点的indices(就是下标)neighbors_indices = np.argsort(temp)[:self.k]# 通过前k个点的下标,取出相应的标签,然后用Counter进行统计(这个就是计票环节)ss = np.take(self.Y,neighbors_indices)# 我们开始计票,取出票数第一的标签值。# e.g: Counter(ss) -> {2: 4, 1: 1} 表示标签值为2的得4示,标签为1的得1票# most_common(1) -> [(2, 4)] , 所以most_common(1)[0][0]的值就是 2found = Counter(ss).most_common(1)[0][0]# 预测结果存储到rs数组中rs.append(found)return rs
欧几里德距离的计算:

测试上面的kNN算法:
# 用鸢尾花数据集来验证我们上面写的算法
from sklearn.datasets import load_iris
# 使用train_test_split对数据集进行拆分,一部分用于训练,一部分用于测试验证
from sklearn.model_selection import train_test_split
# 1.生成一个kNN模型
myknn = MyKnn(5)
# 2.准备数据集:特征集X_train和标签集y_train
X_train,y_train = load_iris(return_X_y=True)
# 留出30%的数据集用于验证测试
X_train,X_test,y_train,y_test = train_test_split(X_train,y_train,test_size=0.3)
# 3.训练模型
myknn.fit(X_train,y_train)
# 4.预测,acc就是预测结果
acc = myknn.predict(X_test)
# 计算准确率
(acc == y_test).mean()
acc == y_test 得到的结果是
array([ True, True, True, True, True, True, True, True, True,True, True, True, True, True, True, True, True, True,True, True, True, True, True, True, True, True, True,True, True, True, True, True, True, True, True, True,False, True, True, True, True, True, True, True, True])
True 是1,False是0,准确率就是:
正确的个数 / 总数 = 准确率
用余弦相似度实现kNN算法
相关文章:
手写kNN算法的实现-用欧几里德空间来度量距离
kNN的算法思路:找K个离预测点最近的点,然后让它们进行投票决定预测点的类型。 step 1: kNN存储样本点的特征数据和标签数据step 2: 计算预测点到所有样本点的距离,关于这个距离,我们用欧几里德距离来度量(其实还有很多…...
IGraph使用实例——线性代数计算(blas)
1 概述 在图论中,BLAS(Basic Linear Algebra Subprograms)并不直接应用于图论的计算,而是作为一套线性代数计算中通用的基本运算操作函数集合,用于进行向量和矩阵的基本运算。然而,这些基本运算在图论的相…...

【MySQL】(基础篇五) —— 排序检索数据
排序检索数据 本章将讲授如何使用SELECT语句的ORDER BY子句,根据需要排序检索出的数据。 排序数据 还是使用上一节中的例子,查询employees表中的last_name字段 SELECT last_name FROM employees;输出结果: 发现其输出并没有特定的顺序。其实…...

C++ C_style string overview and basic Input funcitons
write in advance 最近在做题,遇到一个简单的将console的输入输出到文件中的简单题目,没有写出来。悔恨当初没有踏实地总结string 相关的 I/O 以及与文件的操作。这篇文章旨在记录基础的字符I/O, 简单常用的文件I/O操作函数。 当然,你会说C…...

VS2022+Qt雕刻机单片机马达串口上位机控制系统
程序示例精选 VS2022Qt雕刻机单片机马达串口上位机控制系统 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《VS2022Qt雕刻机单片机马达串口上位机控制系统》编写代码,代码整洁&a…...

Android Ble低功耗蓝牙开发
一、新建项目 在Android Studio中新建一个项目,如下图所示: 选择No Activity,然后点击Next 点击Finish,完成项目创建。 1、配置build.gradle 在android{}闭包中添加viewBinding,用于获取控件 buildFeatures {viewB…...

Visual Studio的快捷按键
Visual Studio的快捷按键对于提高编程效率至关重要。以下是一些常用的Visual Studio快捷按键,并按照功能进行分类和归纳: 1. 文件操作 Ctrl O:打开文件Ctrl S:保存文件Ctrl Shift S:全部保存Ctrl N:…...
【WEB系列】过滤器Filter
Filter,过滤器,属于Servlet规范,并不是Spring独有的。其作用从命名上也可以看出一二,拦截一个请求,做一些业务逻辑操作,然后可以决定请求是否可以继续往下分发,落到其他的Filter或者对应的Servl…...
[书生·浦语大模型实战营]——LMDeploy 量化部署 LLM 实践
1.基础作业 1.1配置 LMDeploy 运行环境 创建开发机 创建新的开发机,选择镜像Cuda12.2-conda;选择10% A100*1GPU;点击“立即创建”。注意请不要选择Cuda11.7-conda的镜像,新版本的lmdeploy会出现兼容性问题。其他和之前一样&…...

TiDB-从0到1-配置篇
TiDB从0到1系列 TiDB-从0到1-体系结构TiDB-从0到1-分布式存储TiDB-从0到1-分布式事务TiDB-从0到1-MVCCTiDB-从0到1-部署篇TiDB-从0到1-配置篇 一、系统配置 TiDB的配置分为系统配置和集群配置两种。 其中系统配置对应TiDB Server(不包含TiKV和PD的参数࿰…...

微信小程序按钮设计与交互:打造极致用户体验
微信小程序作为一种流行的应用形式,其界面设计和交互体验对于用户吸引力和留存率至关重要。其中,按钮作为用户与小程序进行交互的主要方式之一,其设计和实现直接影响到用户体验的质量。在本文中,我们将探讨微信小程序按钮的设计与…...

ES6中如何使用class和extends关键字实现继承?
在ES6中,可以使用class关键字来定义类,使用extends关键字来实现继承。下面是一个示例: // 父类 class Parent {constructor(name) {this.name name;}sayHello() {console.log(Hello, my name is ${this.name});} }// 子类 class Child ex…...
Linux:基本指令
文章目录 ls指令pwd指令cd指令touch指令mkdir指令rmdir指令 && rm指令cp指令man指令echo指令输出重定向追加重定向 cat指令输入重定向 mv指令which指令alias指令more && less指令head && tail指令事件相关的指令date显示时间戳 cal指令find指令grep指令…...

商业C++静态代码检测工具PC-lint Plus 、 polysace和sonarqube对比
商业C静态代码检测工具PC-lint Plus 、 polysace和sonarqube对比 特性/工具PC-lint PlusPolyspaceSonarQube主要功能高精度静态代码分析、编码标准检查高级静态分析和形式验证、优化嵌入式系统综合性代码质量管理、静态分析、技术债务管理集成方式可集成到IDE和构建系统与开发…...

邬家桥公园
文|随意的风 原文地址 我游览过现存规模最大、保存最完整的皇家园林颐和园,瞻仰过拥有世界上最大祭天建筑群的天坛公园,那都是多年前的事情了。 邬家桥公园相比颐和园、天坛公园,气势雄伟倒谈不上。它没有西湖的水平如镜ÿ…...

Flutter 中的 RenderObjectToWidgetAdapter 小部件:全面指南
Flutter 中的 RenderObjectToWidgetAdapter 小部件:全面指南 Flutter 是一个功能强大的 UI 框架,由 Google 开发,允许开发者使用 Dart 语言构建跨平台的移动、Web 和桌面应用。在 Flutter 的渲染体系中,RenderObjectToWidgetAdap…...
SNAT与DNAT
一、SNAT策略概述 1、SNAT 策略的典型应用环境 局域网主机共享单个公网IP地址接入Internet(私有IP不能在Internet中正常路由) 局域共享上网 2、 SNAT 策略的原理 修改数据包的源地址 把从内网 --> 外网的数据的源内网地址转换成公网源地址 3、SN…...

MySql八股文知识点总结,一篇文章让mysql成为面试加分项
MySql八股文知识点总结(自检) 1.前言 参与了几次中大厂的面试,你会发现一面时对于八股文的考察也具有侧重点(MySQLRedis > 网络 > 系统 >设计模式 > java集合 >spring) 本文的目标就是通过这一篇文章让你能在面…...
Python 很好用的爬虫框架:Scrapy:
了解Scrapy 爬虫框架的工作流程: 在scrapy中, 具体工作流程是这样的: 首先第一步 当爬虫引擎<engine>启动后, 引擎会到 spider 中获取 start_url<起始url> 然后将其封装为一个request对象, 交给调度器<…...

C/C++|关于 namespace 在C++中的代码组织
命名空间(namespace)在C中用于组织代码,避免命名冲突,并提供更好的代码结构和可读性。下面详细解释命名空间在C多文件编写中的各种作用和表达。 基本概念 命名空间是一个声明区域,用于组织代码,防止不同部…...
)
从网页地图卡顿说起:深入理解瓦片加载与前端性能优化(Leaflet/Mapbox实战)
从网页地图卡顿说起:深入理解瓦片加载与前端性能优化(Leaflet/Mapbox实战) 当用户在地图应用中频繁缩放拖拽却遭遇卡顿、白屏时,体验会瞬间崩塌。作为前端开发者,我们该如何从底层机制入手解决这些问题?本文…...

3PEAK思瑞浦 TP2262-TSR TSSOP8 运算放大器
特性 供电电压:3V至36V 低供电电流:每通道最大1000A差分输入电压范围至电源轨,可作为比较器工作 输入轨至-Vs,轨到轨输出快速响应:3.5MHz带宽,15V/us斜率,100ns过载恢复时间 低失调电压:-25C时最大2mV-2.5 mV在-40C至85C(最大) -3…...

Cursor-Learner:基于编辑器历史数据,自动生成个性化AI编程助手Prompt
1. 项目概述:一个帮你“诊断”编程习惯的智能助手 如果你和我一样,每天都在和 Cursor 或 WindSurf 这类 AI 驱动的代码编辑器打交道,那你肯定也遇到过这样的困惑:为什么有时候 AI 助手能精准地理解你的意图,写出漂亮的…...
)
Tarjan算法:从DFS序到强连通分量的寻路指南(附C++实战与缩点技巧)
1. 从迷宫探索到强连通王国:Tarjan算法的生活隐喻 想象你正在探索一座巨大的迷宫,手里拿着粉笔和记事本。每走到一个新的岔路口,你就在墙上标记数字(第一个到的路口标1,第二个标2...),这就是DFS…...

CSS 混合模式完全指南
CSS 混合模式完全指南 引言 CSS 混合模式(Blend Modes)是一种强大的视觉效果工具,它允许你控制多个元素或图层如何混合在一起。本文将深入探讨各种混合模式的用法和高级技巧。 混合模式类型 基础混合模式 模式效果描述normal默认模式…...

5步快速搭建微信机器人:WeixinBot完整使用指南
5步快速搭建微信机器人:WeixinBot完整使用指南 【免费下载链接】WeixinBot 网页版微信API,包含终端版微信及微信机器人 项目地址: https://gitcode.com/gh_mirrors/we/WeixinBot 在当今自动化办公和智能交互的时代,拥有一个能够自动处…...

CentOS 7.9离线部署OnlyOffice踩坑全记录:从依赖包下载到SELinux配置的保姆级避坑指南
CentOS 7.9离线部署OnlyOffice全流程实战:从依赖包下载到SELinux配置的深度排错手册 在企业级生产环境中,离线部署文档协作平台往往面临比常规安装更复杂的挑战。本文将以CentOS 7.9为例,详细拆解OnlyOffice在完全离线环境下的部署全流程&…...
)
别再为手眼标定头疼了!用Matlab+机器人工具箱搞定Eye-in-Hand/Eye-to-Hand(附完整代码)
机器人视觉实战:从零实现手眼标定与平面九点标定 在工业自动化领域,机器人视觉系统的精度直接影响着抓取、装配等关键任务的可靠性。许多工程师在理论阶段能够理解手眼标定的数学原理,但一到实际代码实现环节就陷入困境——数据格式如何准备…...

CANN/ge 图引擎资源释放
aclgrphBuildFinalize 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率,减少模型内存占用。 GE 提供对 PyTorch、Tens…...

路由55555555
LSW2:先进入vlan,再添加mac地址,mac地址在主机处复制(此时只添加PC1还有PC2的mac地址就好了)给G0/0/1接口配置不带标签的vlan 启动mac 地址:LSW3:设置网关,看是否能够通...