Kafka 详解:全面解析分布式流处理平台
Kafka 详解:全面解析分布式流处理平台
Apache Kafka 是一个分布式流处理平台,主要用于构建实时数据管道和流式应用。它具有高吞吐量、低延迟、高可用性和高可靠性的特点,广泛应用于日志收集、数据流处理、消息系统、实时分析等场景。
📢 Kafka 概述
Apache Kafka 是由 LinkedIn 开发并于 2011 年开源的一个分布式流处理平台,后来捐赠给 Apache 软件基金会。它设计用于高吞吐量、分布式系统,能够处理大规模的实时数据流。
核心概念
- Producer(生产者):负责发布消息到 Kafka 集群的客户端。
- Consumer(消费者):订阅和处理 Kafka 中消息的客户端。
- Broker(代理):Kafka 集群中的一个服务器节点。
- Topic(主题):消息的分类和管理单位,类似于消息队列的队列。
- Partition(分区):Topic 的子单位,用于并行处理和数据分布。
- Replica(副本):分区的副本,用于数据冗余和高可用性。
- Zookeeper:用于管理和协调 Kafka 集群的元数据和状态信息。
更多zookeeper相关知识,请点击:Zookeeper 详解:分布式协调服务的核心概念与实践
📢 Kafka 架构
Kafka 的架构主要包括以下几个部分:
- 生产者:向 Kafka 主题发布消息。
- 消费者:从 Kafka 主题订阅和消费消息。
- 主题和分区:消息被发布到主题中,并分布在多个分区上。
- 代理(Broker):Kafka 集群中的服务器,负责存储消息和处理请求。
- Zookeeper:用于存储集群的元数据、配置和状态信息。
📢 Kafka 数据模型
消息
消息是 Kafka 中最小的数据单位,每条消息包含一个键值对和一些元数据,如时间戳。
主题(Topic)
主题是消息的分类单位。生产者将消息发送到主题,消费者从主题订阅消息。
分区(Partition)
每个主题被划分为多个分区,分区是 Kafka 并行处理和数据分布的基本单位。
副本(Replica)
每个分区有多个副本,以确保高可用性和数据冗余。
Kafka 集群
Kafka 集群由多个 Broker 组成,Broker 之间通过 Zookeeper 进行协调和管理。Zookeeper 负责存储集群的元数据,包括 Broker 信息、主题和分区的元数据等。
Broker
Broker 是 Kafka 集群中的一个节点,负责接收、存储和转发消息。Broker 通过 Zookeeper 协调和管理集群中的分区和副本。
Zookeeper
Zookeeper 是一个分布式协调服务,用于管理和协调 Kafka 集群的元数据和状态信息。Kafka 依赖 Zookeeper 来实现分布式协调、负载均衡和故障恢复。
📢 Kafka 安装与配置
环境准备
- 安装 Java(Kafka 依赖于 Java 运行环境)。
- 下载并安装 Kafka 和 Zookeeper。
配置文件
Kafka 的主要配置文件包括:
- server.properties:Broker 的配置文件。
- zookeeper.properties:Zookeeper 的配置文件。
启动 Kafka 和 Zookeeper
# 启动 Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# 启动 Kafka
bin/kafka-server-start.sh config/server.properties
📢 Kafka 生产者
生产者是向 Kafka 主题发布消息的客户端。生产者通过 Producer API 向 Kafka 发送消息。
生产者配置
主要配置选项包括:
- bootstrap.servers:Kafka 集群的地址。
- key.serializer 和 value.serializer:用于序列化键和值的类。
- acks:消息确认模式。
生产者示例
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class SimpleProducer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("acks", "all");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 10; i++) {producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));}producer.close();}
}
📢 Kafka 消费者
消费者是从 Kafka 主题订阅和消费消息的客户端。消费者通过 Consumer API 读取消息。
消费者配置
主要配置选项包括:
- bootstrap.servers:Kafka 集群的地址。
- group.id:消费者组 ID。
- key.deserializer 和 value.deserializer:用于反序列化键和值的类。
- auto.offset.reset:消费位移的重置策略。
消费者示例
import org.apache.kafka.clients.consumer.*;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class SimpleConsumer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "my-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("auto.offset.reset", "earliest");Consumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("my-topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}}
}
📢 Kafka Topic
创建 Topic
可以使用 Kafka 提供的命令行工具创建 Topic。
bin/kafka-topics.sh --create --topic my-topic --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
查看 Topic 列表
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
删除 Topic
bin/kafka-topics.sh --delete --topic my-topic --bootstrap-server localhost:9092
📢 Kafka 分区和副本
分区
分区是 Kafka 实现并行处理和数据分布的基本单位。每个分区在物理上是一个日志文件,分区内的消息是有序的,但分区之间是无序的。
副本
副本用于数据冗余和高可用性。每个分区有一个 leader 副本和多个 follower 副本。生产者和消费者只能与 leader 副本交互,follower 副本从 leader 副本同步数据。
副本分配策略
Kafka 使用一致性哈希算法将分区分配到不同的 Broker 上,以实现负载均衡和高可用性。
Kafka 数据持久化
Kafka 提供两种主要的数据持久化机制:日志段和索引文件。
日志段
每个分区的消息被分成多个日志段,日志段是顺序写入的。Kafka 通过滚动机制创建新的日志段,并删除旧的日志段。
索引文件
Kafka 为每个日志段创建索引文件,用于快速查找特定的消息偏移量。索引文件包括偏移量索引和时间戳索引。
📢 Kafka 高级功能
事务
Kafka 支持跨分区、跨主题的事务,保证消息的原子性和一致性。
压缩
Kafka 支持消息压缩,以减少网络带宽和存储空间。常见的压缩算法包括 Gzip、Snappy 和 LZ4。
ACL
Kafka 提供访问控制列表(ACL),用于控制用户和客户端对 Kafka 集群的访问权限。
📢 Kafka 调优
Broker 调优
- 调整文件描述符限制:增加 Broker 可用的文件描述符数量。
- 调整 JVM 参数:优化 JVM 的内存分配和垃圾回收策略。
- 调整网络参数:优化 Broker 的网络传输性能。
生产者调优
- 批量发送:启用消息批量发送,以提高吞吐量。
- 压缩:启用消息压缩,以减少网络带宽和存储空间。
消费者调优
- 并行消费:使用多个消费者实例并行消费消息,以提高消费速度。
- 自动提交位移:根据需求配置位移提交策略,平衡性能和数据一致性。
🔥 Kafka 常见问题
消息丢失
- 原因:可能由于网络故障、Broker 宕机或生产者/消费者配置不当。
- 解决:配置合适的 ack 策略、增加副本数量、优化网络和硬件环境。
消息重复
- 原因:可能由于生产者重试、消费者位移提交失败等。
- 解决:使用 Kafka 事务、配置幂等生产者、合理处理消费逻辑。
消息延迟
- 原因:可能由于网络延迟、Broker 负载过高、磁盘 I/O 性能不足等。
- 解决:优化网络和硬件配置、调整 Broker 和客户端参数、使用更高性能的存储设备。
通过这篇详解指南,你可以全面了解 Kafka 的基本原理、架构设计、安装配置、生产者和消费者的使用,以及高级功能和调优技巧。希望这能帮助你更好地使用和掌握 Kafka,构建高效、可靠的流处理系统。
相关文章:

Kafka 详解:全面解析分布式流处理平台
Kafka 详解:全面解析分布式流处理平台 Apache Kafka 是一个分布式流处理平台,主要用于构建实时数据管道和流式应用。它具有高吞吐量、低延迟、高可用性和高可靠性的特点,广泛应用于日志收集、数据流处理、消息系统、实时分析等场景。 &…...
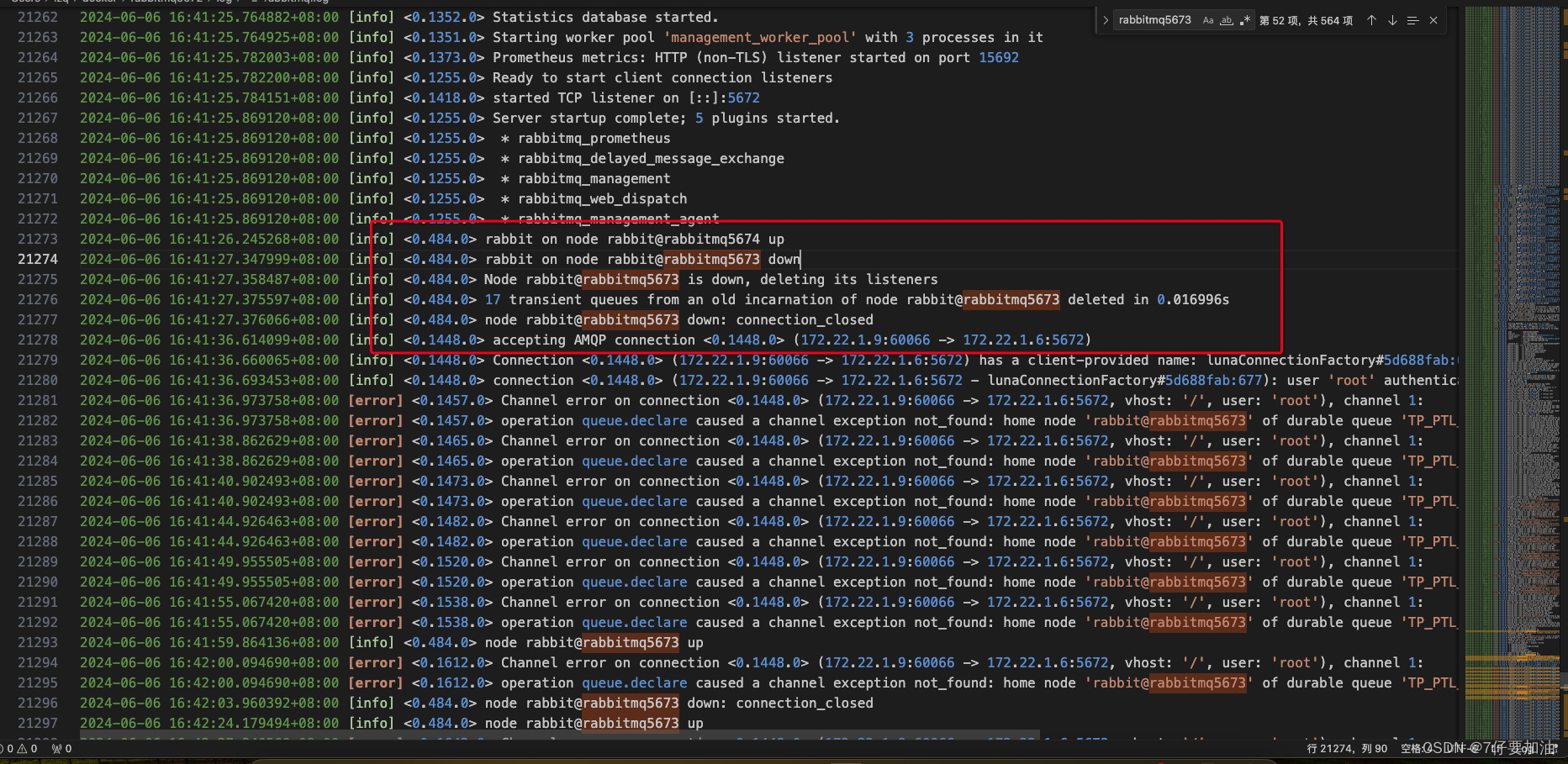
RabbitMQ系列-rabbitmq无法重新加入集群,启动失败的问题
当前存在3个节点:rabbitmq5672、rabbitmq5673、rabbitmq5674 当rabbitmq5673节点掉线之后,重启失败 重启的时候5672节点报错如下: 解决方案 在集群中取消失败节点 rabbitmqctl forget_cluster_node rabbitrabbitmq5673删除失败节点5673的…...

postgresql之翻页优化
列表和翻页是所有应用系统里面必不可少的需求,但是当深度翻页的时候,越深越慢。下面是几种常用方式 准备工作 CREATE UNLOGGED TABLE data (id bigint GENERATED ALWAYS AS IDENTITY,value double precision NOT NULL,created timestamp with time zon…...
小白学Linux | 日志排查
一、windows日志分析 在【运行】对话框中输入【eventvwr】命令,打开【事件查看器】窗 口,查看相关的日志 管理员权限进入PowerShell 使用Get-EventLog Security -InstanceId 4625命令,可获取安全性日志下事 件 ID 为 4625(失败登…...

Spring6
一 概述 1.1、Spring是什么? Spring 是一款主流的 Java EE 轻量级开源框架 ,Spring 由“Spring 之父”Rod Johnson 提出并创立,其目的是用于简化 Java 企业级应用的开发难度和开发周期。Spring的用途不仅限于服务器端的开发。从简单性、可测…...
数字孪生概念、数字孪生技术架构、数字孪生应用场景,深度长文学习
一、数字孪生起源与发展 1.1 数字孪生产生背景 数字孪生的概念最初由Grieves教授于2003年在美国密歇根大学的产品全生命周期管理课程上提出,并被定义为三维模型,包括实体产品、虚拟产品以及二者间的连接,如下图所示: 2011年&…...

云服务对比:阿里云国际站和阿里云国内站有什么区别
阿里云国际站(Alibaba Cloud International)和阿里云国内站(Alibaba Cloud China)在许多方面存在明显区别,这些区别主要体现在服务范围、合规性、定价和支付方式、语言和客服支持、以及备案要求等方面。 首先…...

如何在npm上发布自己的包
如何在npm上发布自己的包 npm创建自己的包 一、一个简单的创建 1、创建npm账号 官网:https://www.npmjs.com/创建账号入口:https://www.npmjs.com/signup 注意:需要进入邮箱验证 2、创建目录及初始化 $ mkdir ufrontend-test $ cd ufron…...
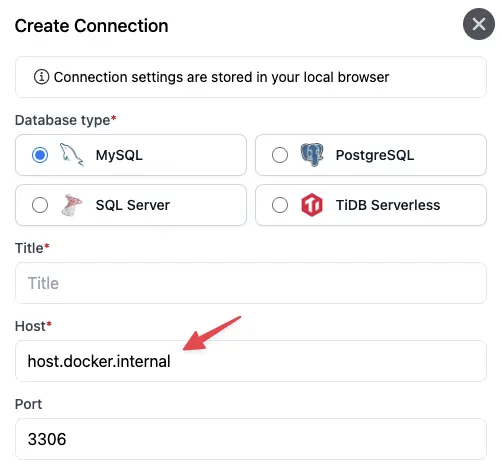
SQL Chat:从SQL到SPEAKL的数据库操作新纪元
引言 SQL Chat是一款创新的、对话式的SQL客户端工具。 它采用自然语言处理技术,让你能够像与人交流一样,通过日常对话的形式对数据库执行查询、修改、创建及删除操作 极大地简化了数据库管理流程,提升了数据交互的直观性和效率。 在这个框…...
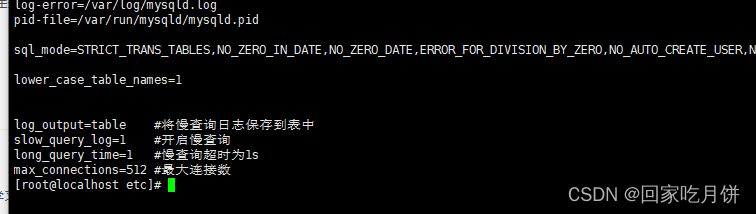
jmeter性能优化之mysql配置
一、连接数据库和grafana 准备:连接好数据库和启动grafana并导入mysql模板 大批量注册、登录、下单等,还有过节像618,双11和数据库交互非常庞大,都会存在数据库的某一张表里面,当用户在登录或者查询某一个界面时&…...

VueRouter3学习笔记
文章目录 1,入门案例2,一些细节高亮效果非当前路由会被销毁 3,嵌套路由4, 传递查询参数5,命名路由6,传递路径参数7,路径参数转props8,查询参数转props9,replace模式10&am…...

「前端+鸿蒙」鸿蒙应用开发-TS函数
在 TypeScript 中,函数是一等公民,这意味着函数可以作为参数传递、作为其他函数的返回值,甚至可以赋值给变量。TypeScript 为 JavaScript 的函数增加了类型系统,使得函数的参数和返回值都具有明确的类型。 TS快速入门-函数 基本函…...
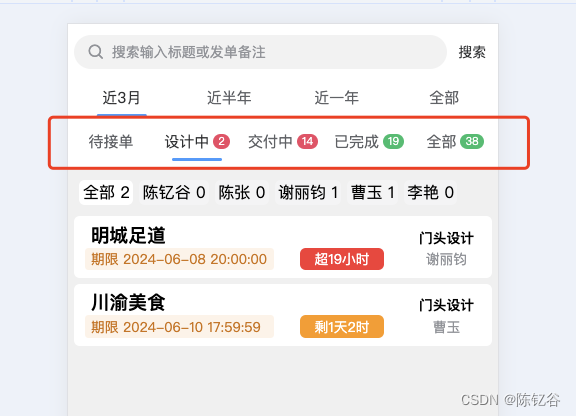
python后端结合uniapp与uview组件tabs,实现自定义导航按钮与小标签颜色控制
实现效果(红框内): 后端api如下: task_api.route(/user/task/states_list, methods[POST, GET]) visitor_token_required def task_states(user):name_list [待接单, 设计中, 交付中, 已完成, 全部]data []color [#F04864, …...

mingw如何制作动态库附python调用
1.mingw和msvc g -fpic HelloWorld.cpp -shared -o test.dllg -L . -ltest .\test.cpp 注意-L后面的.挨不挨着都行,-l不需要-ltest.dll,只需要-ltest 2.dll.cpp extern "C" {__declspec(dllexport) int __stdcall add(int a, int b) {return…...
Vue学习|Vue快速入门、常用指令、生命周期、Ajax、Axios
什么是Vue? Vue 是一套前端框架,免除原生JavaScript中的DOM操作,简化书写 基于MVVM(Model-View-ViewModel)思想,实现数据的双向绑定,将编程的关注点放在数据上。官网:https://v2.cn.vuejs.org/ Vue快速入门 打开页面࿰…...

Python基础教程(八):迭代器与生成器编程
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝Ὁ…...

Oracle10.2.0.1冷备迁移之_数据文件拷贝方式
由于阿里云机房要下架旧服务器,单位未购买整机迁移服务,且业务较老不兼容Oracle11g,所以新购买一台新服务器进行安装Oracle10.2.0.1 ,后续再将数据迁移到新服务器上。 id 数据库版本 操作系统版本 实例名 源库 115.28.242.25…...

智能合约中外部调用漏洞
外部调用 : 在智能合约开发中,调用不受信任的外部合约是一个常见的安全风险点。这是因为,当你调用另一个合约的函数时,你实际上是在执行那个合约的代码,而这可能会引入你未曾预料的行为,包括恶意行为。下面…...
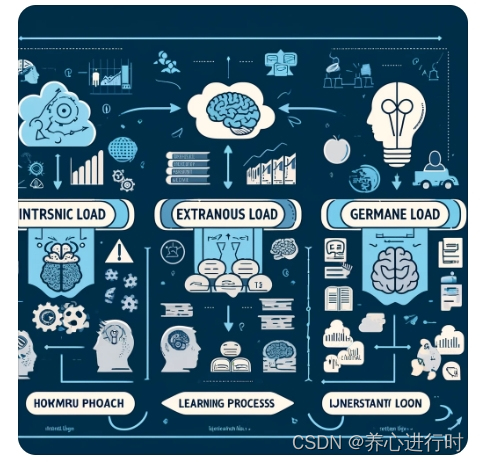
转型AI产品经理(4):“认知负荷”如何应用在Chatbot产品
认知负荷理论主要探讨在学习过程中,人脑处理信息的有限容量以及如何优化信息的呈现方式以促进学习。认知负荷定律认为,学习者的工作记忆容量是有限的,而不同类型的认知任务会对工作记忆产生不同程度的负荷,从而影响学习效果。以下…...
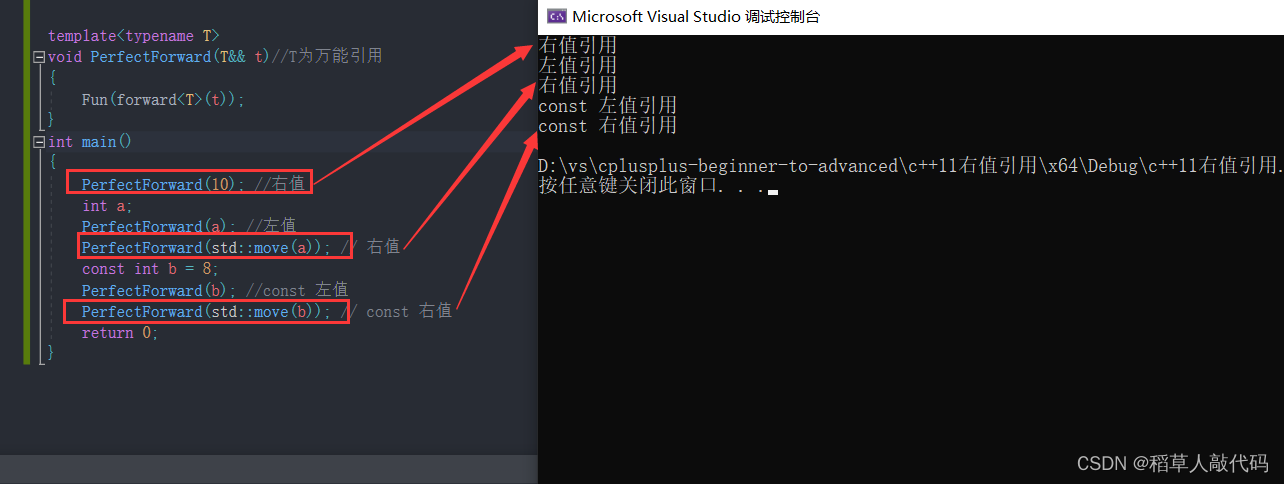
【C++11】常见的c++11新特性(一)
文章目录 1. C11 简介2. 常见的c11特性3.统一的列表初始化3.1initializer_list 4. decltype与auto4.1decltype与auto的区别 5.nullptr6.右值引用和移动语义6.1左值和右值6.1.1左值的特点6.1.2右值的特点6.1.3右值的进一步分类 6.2左值引用和右值引用以及区别6.2.1左值引用6.2.2…...
)
别再为EVE-ng镜像发愁了!手把手教你从官网下载到VMware部署(附国内加速地址)
EVE-ng网络模拟器全流程实战:从镜像获取到高阶配置 第一次接触网络设备模拟的工程师,往往会在EVE-ng的入门阶段遇到各种"拦路虎"——镜像文件找不到可靠的下载源、导入VMware时配置出错、虚拟网络连接异常。这些问题如果得不到解决,…...

BIOS里找不到SSD硬盘?Win10启动失败?可能是ESP引导分区‘隐身’了,手把手教你用PE盘和DiskGenius把它找回来
BIOS里找不到SSD硬盘?Win10启动失败?可能是ESP引导分区‘隐身’了 最近遇到一个奇怪的故障:明明SSD硬盘在PE系统里能正常识别,但BIOS启动项里却死活找不到它。系统反复提示"reboot and select proper boot device"&…...
)
【Sora 2视频集成终极指南】:ChatGPT原生调用、API对接、帧级控制与多模态工作流落地实录(2024官方SDK首曝)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Sora 2视频集成功能详解 ChatGPT Sora 2 并非官方发布的模型名称,而是社区对 OpenAI 视频生成能力演进方向的一种泛称。当前(截至 2024 年中),O…...

服务器运维与DevOps融合:迈向智能化运维的新纪元
在数字化浪潮席卷全球的今天,企业对IT基础设施的依赖程度日益加深,服务器运维作为支撑业务连续性和系统稳定性的核心环节,正面临前所未有的挑战与机遇。传统运维模式依赖人工干预、响应滞后、效率低下,已难以满足现代业务快速迭代…...

高性能服务架构缓存设计:Redis+Caffeine
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...
)
手把手教你用STM32和电位器,临时搭建一个TTL转485调试器(附电路图)
应急调试利器:用STM32和电位器快速搭建TTL转485监听器 在嵌入式开发现场调试时,最让人头疼的莫过于设备串口输出异常却找不到合适的调试工具。上周在客户工厂就遇到了这样的窘境——需要监控设备TTL串口数据,但手边只有RS485转换器和几根杜邦…...
)
ClaudeCode入门08-Git配合(小白入门:不知道怎么写Git提交记录?让AI自动帮你写好)
🎯 本文目标 学会用 Claude Code 自动化 Git 工作流:自动写 Commit Message、管理分支、处理冲突。 😰 Git 新手的痛点 git commit -m "fix" git commit -m "update" git commit -m "修改了一些东西" 不知道 Conventional Commits 是什么 …...

Hive内部表 vs 外部表:选错一次,数据全丢?结合HDFS路径详解核心区别与选型指南
Hive内部表与外部表:数据安全与架构设计的深度抉择 在数据仓库与大数据分析领域,Hive作为构建在Hadoop之上的数据仓库工具,其表类型的选择往往被初学者视为简单的语法差异。然而,当生产环境中TB级的数据因为一个DROP TABLE命令而永…...

ReAct不是格式游戏!揭秘让LLM从“文本生成器”变身“决策引擎”的底层逻辑
文章指出,ReAct常被误解为高级Prompt工程,但核心是闭环执行架构。真正的ReAct强调“决策-执行-反馈”循环,而非固定的Thought/Action/Observation格式。工程代码定义流程,模型生成内容,实现真实工具调用与反馈闭环。文…...

截稿!NeurIPS 2026 投稿微信群成立
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信:CVer2233,助手会拉你进群!扫描下方二维码,加入CVer学术星球!可获得最新顶会/顶刊上…...