【博士每天一篇文献-综述】Modularity in Deep Learning A Survey
阅读时间:2023-12-8
1 介绍
年份:2023
作者:孙浩哲,布朗克斯医疗卫生系统
会议: Science and Information Conference
引用量:4
论文主要探讨了深度学习中的模块化(modularity)概念,模块化具有易于理解、解释、扩展、模块组合性和重用等优点。论文探讨了数据、任务和模型模块化在深度学习中的表现,数据模块化指的是观察或创建不同目的的数据组;任务模块化指的是将任务分解为子任务;模型模块化意味着神经网络系统的架构可以分解为可识别的模块。
2 创新点
- 多维度综述:论文从数据、任务和模型三个维度对深度学习中的模块化进行了全面的综述,这种多角度的分析为理解模块化在深度学习中的作用提供了一个全面的视角。
- 模块化定义的讨论:论文对模块化这一概念进行了深入的探讨,并尝试提出一个通用的定义,这有助于统一不同研究者对模块化理解的差异。
- 模块化优势的具体化:详细描述了模块化在深度学习中的各种优势,如易于设计、提高解释性、促进知识迁移和重用、改善泛化和样本效率等,这些优势的具体阐述为模块化的应用提供了明确的指导。
- 模块化原则的实例分析:论文不仅讨论了模块化的理论基础,还结合具体的深度学习子领域,如计算机视觉和自然语言处理,展示了模块化原则的实际应用案例。
- 模块化与深度学习模型的结合:论文探讨了如何将模块化原则与现有的深度学习模型结合,包括对典型模块的分析和模块组合方式的讨论,这有助于推动深度学习模型的创新和发展。
- 模块化在不同学习场景下的应用:论文讨论了模块化在少样本学习、多任务学习、持续学习等不同学习场景下的应用,这有助于理解模块化在解决实际问题中的潜力。
3 相关研究
3.1 思维导图

3.2 数据模块化
数据模块化分为原生数据模块化(intrinsic data modularity)和人为的数据模块化(imposed data modularity)
原生的数据模块化指的是数据集中自然存在的、未经人为引入的模块划分。这种模块化通常是数据固有特性的反映,可能源自数据的生成过程或其内在的结构。例如,在一个图像数据集中,不同的类别可以自然形成模块,因为属于同一类别的图像在特征空间中倾向于彼此接近。固有模块化可以由数据集中的类别标签隐含地定义,它反映了数据样本之间的语义关系,即样本的相似性或差异性。此外,数据集中的固有模块化还可以通过其他元数据特征来识别,如时间、地点、性别等。代表的数据集有ImageNet、Omniglot、OmniPrint、Meta-Album、NORB、Moons Dataset、VQA v2.0、 SpeakingFaces 。
人为的数据模块化是指由人为引入的数据集划分。这种模块化是基于特定目的或为了实现特定的学习目标而人为创建的。例如,在训练深度学习模型时,实践者可能会将整个训练数据集划分为多个小批量(mini-batches),每个小批量作为一个模块进行处理。这种划分有助于减少反向传播过程中的内存需求,使得训练大型深度学习模型成为可能。此外,强加的模块化还可以包括数据增强、特征划分、课程学习中的非均匀小批量采样等,这些都是为了更好地训练学习机器而人为设计的策略。
3.3 任务模块化
子任务分解可以分为两种模式:并行分解和顺序分解。
(1)并行分解
将一个任务分解成可以同时并行处理的子任务。比如,
- 同质分解:当子任务彼此相似时,这种分解被称为同质的。例如,将多类分类问题分解为多个较小的分类问题。
- 参数掩码:使用参数掩码来识别对个别类别负责的参数子集。
- 树状结构:将神经网络分解为树状结构,处理不同子集的类别,确保不同类别的特征不会在网络的后层中共享。
- 模块化二元分类器:将多类分类模型分解为可重用、可替换和可组合的二元分类器模块。
(2)顺序分解
将任务分解为需要按特定顺序依次执行的子任务。 比如,
- 强化学习中的应用:在强化学习中,复杂任务可以分解为一系列子任务或步骤,代理需要按顺序学习完成这些步骤。
- 学习效率:如果学习发生在分解阶段的粒度上,而不是整个任务,强化学习代理将更有效地学习。
- 信用分配:任务的分解允许独立地进行信用分配,失败可以追溯到具体的问题阶段,而不影响其他阶段。
- 实际应用:顺序子任务分解广泛应用于实际应用中,如光学字符识别(OCR)和自然语言处理(NLP)。
- 多语言识别:面对多语言识别任务时,可以分解为脚本识别和特定脚本的识别两个阶段。
- 文本识别:文本识别任务通常包括解耦的文本检测(定位文本的边界框)和文本识别(识别边界框中的文本)两个子任务。
- NLP流程:传统的自然语言处理流程包括句子分割、词标记化、词性标注、词形还原、过滤停用词和依存句法分析等子任务。
3.4 模型模块化
3.4.1 优点
- 设计和实现的便利性:模型模块化允许神经网络由重复的层或块模式组成,简化了模型架构的描述和实现。
- Kolmogorov复杂性:模块化设计减少了模型架构描述的长度,提高了描述的简洁性。
- 硬件和软件优化:标准化的神经网络构建块(如全连接层和卷积层)促进了为快速计算优化的硬件和软件生态系统的发展。
- 专家知识整合:模块化有助于将专家知识整合到模型设计中,提升模型性能。
- 可解释性:模块化允许为每个神经网络模块分配特定子任务,增强了模型的可解释性。
- 选择性模块评估:提供了对不同样本或任务间关系洞察的能力,有助于条件计算的背景下理解模型行为。
- 重用和知识转移:模块化促进了跨任务的模块重用,例如通过微调大型预训练模型来适应下游任务。
- 细粒度重用:研究者关注于更细粒度的模块重用,假设任务共享底层模式,并保留可重用模块的清单。
- 组合泛化:模块化有助于实现组合泛化,即系统地重新组合已知元素以映射新输入到正确输出。
- 知识保留:模块化有助于知识保留,使得知识更新和故障排除更加有针对性。
- 减少梯度干扰和灾难性遗忘:模块化有助于减轻不同任务间的梯度干扰和灾难性遗忘问题。
- 模型扩展:模块化模型可以通过增加或减少模块数量来扩展或缩小模型容量,适应不同大小的数据集。
- 计算成本与模型大小解耦:基于稀疏激活的模块化方法允许增加模型容量而不增加计算成本,因为每次前向传递只评估模型的一小部分。
- 超大型模型示例:如Switch Transformer,展示了通过模块化可以构建具有数万亿参数的超大型模型。
3.4.2 非序列数据模块化
全连接层、卷积层、局部连接层 (类似于卷积层,但移除了参数共享的约束)、低秩局部连接层 (Low-rank locally connected layers)、 群卷积层 (Group convolutional layers)、深度可分离卷积层 (Depthwise separable convolutional layers)、构建块 (多个层组合成一个更高层次的模块,例如ResNet、Inception、ResNeXt和Wide ResNet中的构建块)、Inception模块、 ResNet块。
3.4.3 序列数据模块化
递归神经网络(RNN)、门控循环单元 (GRU)、长短期记忆网络 (LSTM)、自注意力层、多头自注意力、Transformer 块、视觉变换器 (Vision transformers)。
3.5 模块化的组合
3.5.1 静态模块组合
静态组合指模块组合的结构对所有输入样本或任务都是固定不变的。 比如顺序连接、集成组合 (并行方式组织)、Dropout、树形结构组合 (结合了顺序和并行组合,形成树状结构)、有向无环图 (DAG)、合作组合 (每个模块作为独立的神经网络,具有特定功能,与集成组合不同,合作组合中的模块通常是异构的)。
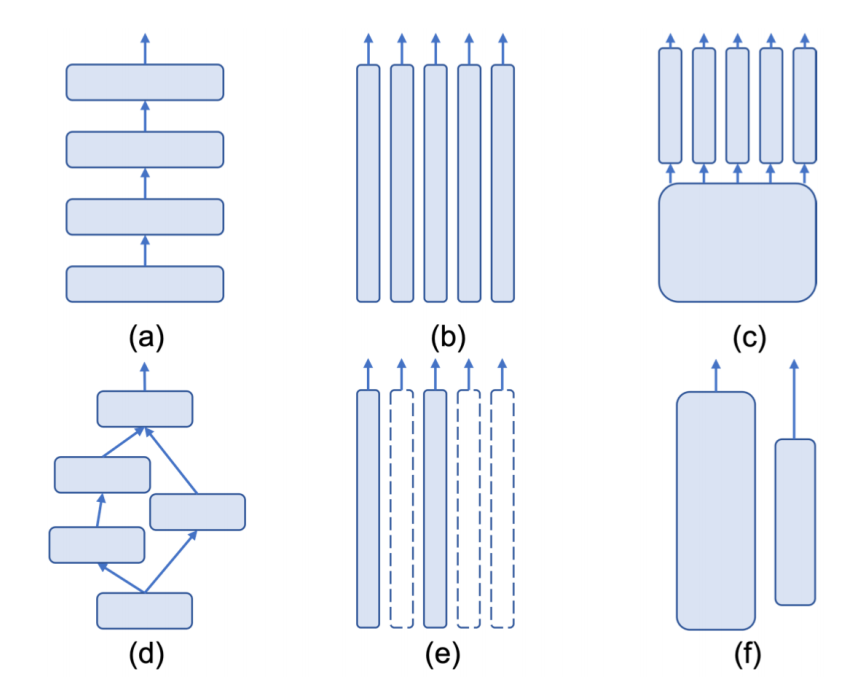
(a) 顺序连接 (b) 集成 © 树形结构组合 (d) 一般有向无环图 (e) 条件组合(f) 合作组合
3.5.2 条件模块组合
条件组合指的是根据每个特定的输入动态地(条件性地、稀疏地或选择性地)激活或使用组合模块。
比如条件计算 (根据输入样本或任务的条件,选择性地激活模块)、专家混合 (由多个独立的神经网络组成,每个模块学习处理整体任务的一个子任务,MoE)、模块崩溃 (训练过程中可能出现的问题,其中一个小模块被频繁选择,导致其他模块被忽视)、批量大小缩小 (条件激活的模块可能会导致处理的批量大小减少,影响硬件效率)、堆叠MoE (Stacked MoE)、层次MoE (Hierarchical MoE)、网络移植(通过直接移植对应新能力的模块来为通用网络添加新能力) 。
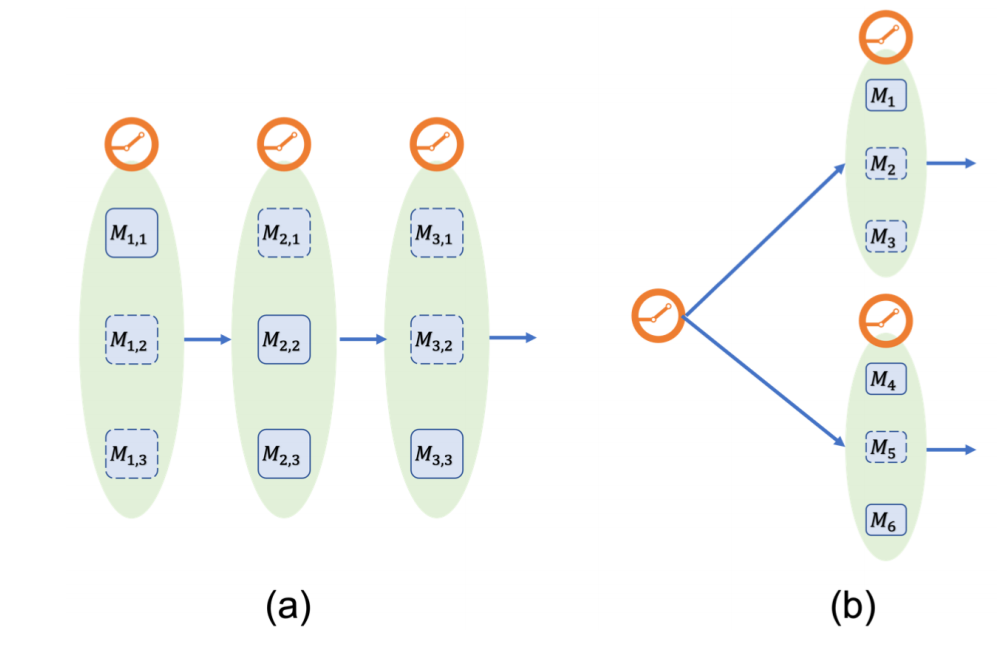
(a) 堆叠MoE (b) 分层MoE
3.6 其他模块化
- 图论中的模块化: 在图论中,模块化是一个用于社区检测的度量,衡量社区内部连接的密度与社区间连接的密度之比。
- 参数聚类: 受到图论中模块化度量的启发,研究了神经网络训练过程中参数聚类模式的出现。
- 结构模块化与功能专业化: 通过三个启发式度量定义了结构模块化,并直观地理解为子网络能够独立完成子任务的程度。
- 结构与功能模块化的关系: 通过设计场景研究了结构模块化(通过模块间稀疏连接强制实现)是否导致模块的功能专业化。
- 超网络的模块化: 将模块化用于描述超网络学习每个输入实例不同函数的能力。
- 解耦表示的模块化: 解耦表示旨在逆转数据生成过程,将数据的潜在因素恢复到学习到的表示中,其中模块化表示是解耦表示的一个理想属性。
6 思考
作者也在结论中说到,在深度学习中模块化这个概念本身没有一个明确的定义,所以作者将深度学习中所有可以称为模块化概念的方法、模型和结构都列举了出来,并说明了这些结构的优点和特性。启发性较低。
相关文章:
【博士每天一篇文献-综述】Modularity in Deep Learning A Survey
阅读时间:2023-12-8 1 介绍 年份:2023 作者:孙浩哲,布朗克斯医疗卫生系统 会议: Science and Information Conference 引用量:4 论文主要探讨了深度学习中的模块化(modularity)概念…...
Sentinel不使用控制台基于注解限流,热点参数限流
目录 一、maven依赖 二、控制台 三、基于注解限流 四、热点参数限流 五、使用JMeter验证 一、maven依赖 需要注意,使用的版本需要和你的SpringBoot版本匹配!! Spring-Cloud直接添加如下依赖即可,baba已经帮你指定好版本了。…...

HTML做成一个端午节炫酷页面
做成端午节页面之前,先了解一下端午节的由来: 1.起源与历史: 端午节起源于中国,始于春秋战国时期,至今已有2000多年历史。 最初是古代百越地区(长江中下游及以南一带)崇拜龙图腾的部族举行图…...

解决Ubuntu系统/usr/lib/xorg/Xorg占用显卡内存问题原创
在Ubuntu系统中,/usr/lib/xorg/Xorg进程占用显卡内存的问题可能会影响系统性能,特别是在使用GPU进行计算任务时。以下是一些解决方法,可以帮助你减少或解决这个问题: 1. 更新显卡驱动 首先,确保你使用的是最新版本的…...

【Activiti7系列】基于Spring Security的Activiti7工作流管理系统简介及实现(附源码)(下篇)
作者:后端小肥肠 上篇:【Activiti7系列】基于Spring Security的Activiti7工作流管理系统简介及实现(上篇)_spring security activiti7-CSDN博客 目录 1.前言 2. 核心代码 2.1. 流程定义模型管理 2.1.1. 新增流程定义模型数据 …...

解密Spring Boot:深入理解条件装配与条件注解
文章目录 一、条件装配概述1.1 条件装配的基本原理1.2 条件装配的作用 二、常用注解2.1 ConditionalOnClass2.2 ConditionalOnBean2.3 ConditionalOnProperty2.4 ConditionalOnExpression2.5 ConditionalOnMissingBean 三、条件装配的实现原理四、实际案例 一、条件装配概述 1…...
【数据结构与算法】使用数组实现栈:原理、步骤与应用
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 目录 一、引言 🎄栈(Stack)是什么? …...

cell的复用机制和自定义cell
cell的复用机制和自定义cell UITableView 在学习cell之前,我们需要先了解UITableView。UITableView继承于UIScrollView,拥有两个两个相关协议 UITableViewDelegate和UITableViewDataSource,前者用于显示单元格,设置行高以及对单…...
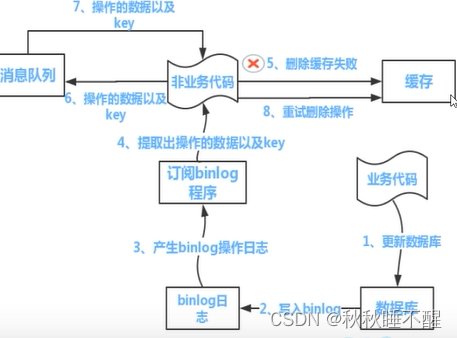
Redis 双写一致原理篇
前言 我们都知道,redis一般的作用是顶在mysql前面做一个"带刀侍卫"的角色,可以缓解mysql的服务压力,但是我们如何保证数据库的数据和redis缓存中的数据的双写一致呢,我们这里先说一遍流程,然后以流程为切入点来谈谈redis和mysql的双写一致性是如何保证的吧 流程 首先…...

《软件定义安全》之四:什么是软件定义安全
第4章 什么是软件定义安全 1.软件定义安全的含义 1.1 软件定义安全的提出 虚拟化、云计算、软件定义架构的出现,对安全体系提出了新的挑战。如果要跟上网络演进的步伐和业务快速创新的速度,安全体系应该朝以下方向演变。 𝟭 安全机制软件…...

将AIRNet集成到yolov8中,实现端到端训练与推理
AIRNet是一个图像修复网络,支持对图像进行去雾、去雨、去噪声的修复。其基于对比的退化编码器(CBDE),将各种退化类型统一到同一嵌入空间;然后,基于退化引导恢复网络(DGRN)将嵌入空间修复为目标图像。可以将AIRNet的输出与yolov8进行端到端集成,实现部署上的简化。 本博…...
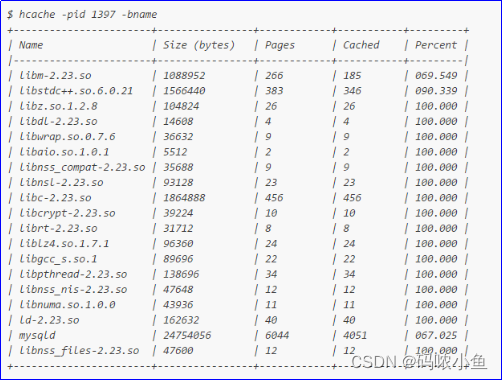
hcache缓存查看工具
1、hcache概述 hcache是基于pcstat的,pcstat可以查看某个文件是否被缓存和根据进程pid来查看都缓存了哪些文件。hcache在其基础上增加了查看整个操作系统Cache和根据使用Cache大小排序的特性。官网:https://github.com/silenceshell/hcache 2、hcache安装 2.1下载…...

Java 数据类型 -- Java 语言的 8 种基本数据类型、字符串与数组
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 004 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...
kafka-生产者事务-数据传递语义事务介绍事务消息发送(SpringBoot整合Kafka)
文章目录 1、kafka数据传递语义2、kafka生产者事务3、事务消息发送3.1、application.yml配置3.2、创建生产者监听器3.3、创建生产者拦截器3.4、发送消息测试3.5、使用Java代码创建主题分区副本3.6、屏蔽 kafka debug 日志 logback.xml3.7、引入spring-kafka依赖3.8、控制台日志…...

免费!GPT-4o发布,实时语音视频丝滑交互
We’re announcing GPT-4o, our new flagship model that can reason across audio, vision, and text in real time. 5月14日凌晨,OpenAI召开了春季发布会,发布会上公布了新一代旗舰型生成式人工智能大模型【GPT-4o】,并表示该模型对所有免费…...
)
DevOps的原理及应用详解(四)
本系列文章简介: 在当今快速变化的商业环境中,企业对于软件交付的速度、质量和安全性要求日益提高。传统的软件开发和运维模式已经难以满足这些需求,因此,DevOps(Development和Operations的组合)应运而生,成为了解决这些问题的有效方法。 DevOps是一种强调软件开发人员(…...

关于选择,关于处事
一个人选择应该选择的是勇敢,选择不应该选择的是无奈。放弃,不该放弃的是懦夫,不放弃应该放弃的是睿智。所以,碰到事的时候要先静,先不管什么事,先静下来,先淡定,先从容。在生活里要…...
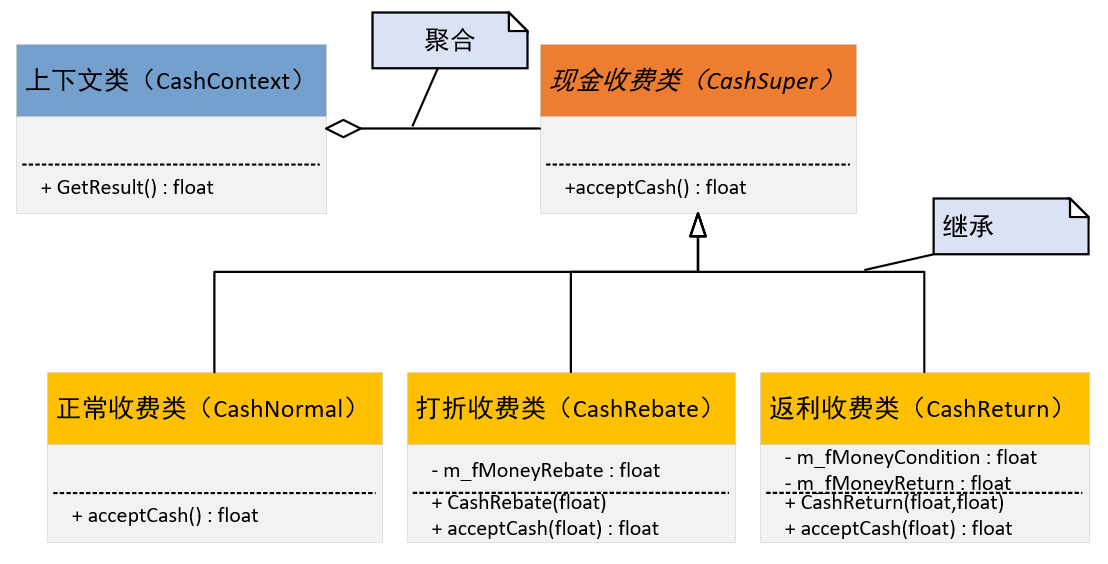
大话设计模式解读02-策略模式
本篇文章,来解读《大话设计模式》的第2章——策略模式。并通过Qt和C代码实现实例代码的功能。 1 策略模式 策略模式作为一种软件设计模式,指对象有某个行为,但是在不同的场景中,该行为有不同的实现算法。 策略模式的特点&#…...

展会邀请 | 龙智即将亮相2024上海国际嵌入式展,带来安全合规、单一可信数据源、可追溯、高效协同的嵌入式开发解决方案
2024年6月12日至14日,备受全球嵌入式系统产业和社群瞩目的2024上海国际嵌入式展(embedded world china 2024)即将盛大开幕,龙智将携行业领先的嵌入式开发解决方案亮相 640展位 。 此次参展,龙智将全面展示专为嵌入式行…...

codeforce round951 div2
A guess the maximum 问题: 翻译一下就是求所有相邻元素中max - 1的最小值 代码: #include <iostream> #include <algorithm>using namespace std;const int N 5e4;int a[N]; int n;void solve() {cin >> n;int ans 0x3f3f3f3f;…...

Python face_recognition 库实战:从环境搭建到人脸特征点检测
1. 环境准备:搭建人脸识别的开发环境 第一次接触人脸识别开发时,最让人头疼的就是环境配置。记得我刚开始用face_recognition库时,光是安装依赖就折腾了大半天。后来才发现,其实只要掌握几个关键步骤,整个过程可以非常…...

Amphenol ICC RJE1Y26610C42401线束组件解析与替代思路
在工业通信、数据交换以及网络设备连接场景中,RJ45以太网线束组件一直是非常核心的连接方案之一。近期不少工程师在项目维护和设备升级过程中,开始关注 Amphenol ICC 推出的 RJE1Y26610C42401 线束组件。 这类型号通常被应用于工业交换机、服务器、网络设…...
)
别再复制粘贴了!手把手教你用Simscape Language从零创建自定义物理模块(附完整代码)
从零构建Simscape自定义物理模块:工程师的深度实践指南 在物理系统建模领域,预置的标准化组件库往往无法满足复杂工程场景的需求。当您面对一个特殊的齿轮传动机构、非线性的液压元件或是定制化的传感器模型时,掌握Simscape Language的自定义…...

从NIST到Interatomic Repository:金属体系L-J势参数高效检索与验证指南
1. 金属模拟中的L-J势参数为何如此重要 我第一次用LAMMPS模拟镁合金拉伸过程时,发现结果和实验数据差了十万八千里。折腾了两周才发现问题出在Lennard-Jones势参数上——当时随便找了个文献值就用,结果模拟出的晶格常数比实际小了15%。这个教训让我明白…...

Sketch MeaXure:3步告别设计标注烦恼的TypeScript重构方案
Sketch MeaXure:3步告别设计标注烦恼的TypeScript重构方案 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure Sketch MeaXure是一款基于TypeScript重构的Sketch设计标注插件,专为解决UI设计师与开发…...

Taotoken为Claude Code用户提供稳定替代方案解决封号与Token不足痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken为Claude Code用户提供稳定替代方案解决封号与Token不足痛点 1. 场景与需求 许多使用Claude Code进行开发的工程师会遇到…...

全球供应链重塑下的半导体与PC板行业:工程师的挑战与韧性构建
1. 从“分裂的联盟”到工程师的十字路口 最近翻看行业旧闻,读到一篇2019年EE Times上Rick Merritt的评论文章,标题叫“State of the Disunion”。文章本身探讨的是当时科技行业在政治与全球化张力下的处境,但最让我印象深刻的,是评…...
)
从选型到调参:伺服电机刚性、惯量比实战避坑指南(以台达/三菱为例)
伺服电机系统实战:从刚性调节到三环控制的深度优化 在工业自动化领域,伺服系统的性能直接决定了设备的精度与效率。去年参与的一个CNC机床改造项目中,我们遇到了一个典型问题:在加工复杂曲面时,机械臂末端总是出现微米…...

CANN/asc-devkit ReduceMax API参考
ReduceMax 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

指标漂移、用户冷启动、LLM幻觉干扰——大模型A/B测试三大盲区全解析,SITS大会实证数据支撑
更多请点击: https://intelliparadigm.com 第一章:指标漂移、用户冷启动、LLM幻觉干扰——大模型A/B测试三大盲区全解析,SITS大会实证数据支撑 在2024年SITS(Scalable Intelligence Testing Summit)大会上,…...