面试题------>MySQL!!!
一、连接查询
①:左连接left join (小表在左,大表在右)
②:右连接right join(小表在右,大表在左)
二、聚合函数
SQL 中提供的聚合函数可以用来统计、求和、求最值等等
COUNT:统计行数量
SUM:获取单个列的合计值
AVG:计算某个列的平均值
MAX:计算列的最大值
MIN:计算列的最小值
三、SQL 关键字
①分页:limit
SELECT * FROM student3 LIMIT 100,6; 查询学生表中数据,跳过100条,从第101条开始显示,取6 条
②倒序:order by ... desc
select * from user order by id desc limit 0 6
③分组:group by
SELECT sex , count(*) FROM student GROUP BY sex
④去重:distinct
select DISTINCT NAME FROM student3;
四、 SQL Select 语句完整的执行顺序
查询中用到的关键词主要包含如下展示,并且他们的顺序依次为
form...left join...on...where...group by...having..select...avg()/sum()...order by...asc/desc...limit...
from: 需要从哪个数据表检索数据
where: 过滤表中数据的条件
group by: 如何将上面过滤出的数据分组算结果
order by : 按照什么样的顺序来查看返回的数据
五、 数据库三范式(掌握)
第一范式:
1NF 原子性,列或者字段不能再分,要求属性具有原子性,不可再分解;
第二范式:
2NF主要是解决行的冗余。
1.每一行数据有唯一的主键
2. 非主键字段必须依赖于主键字段
第三范式:
3NF主要是解决 列 的冗余。
非主键字段不依赖于其它非主键字段
我们有时候并不会严格的遵守第三范式,例如我们在设计订单明细表的时候,我们冗余了商品的名称和图片,因为我们通过商品id再去查询商品表会给基础表造成压力,所以我们冗余了两个字段。
六、存储引擎 :MyISAM 存储引擎 与 InnoDB 引擎区别
①. 事务支持:MyLISAM不支持事务,InnoDB支持事务。
②. 锁定机制(锁的粒度):MyISAM 表级锁 ; InnoDB 支持行级锁。
③. 外键支持:MyISAM 不支持外键约束;而 InnoDB 支持外键约束。(一般不用外键,我们在使用外键过程中,删除的时候需要)
④. 并发性能: InnoDB 支持行级锁定和事务处理,InnoDB 的并发性能更高。
七、数据库事务(必会)
1.事务特性ACID
原子性:即不可分割性,事务要么全部被执行,要么就全部不被执行。
一致性:事务必须使数据库从一个一致性状态变换到另一个一致性状态,即一个事务执行之前和执行之后都必须处于一致性状态。拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还是5000,这就是事务的一致性。
隔离性:即一个事务执行之前和执行之后都必须处于一致性状态。
持久性:事务一旦结束,数据就持久到数据库
如何保持事务特性:
-
redo log, 持久性,当数据库对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,那么这个时候buffer pool中的数据页就与磁盘上的数据页内容不一致,称buffer pool的数据页为dirty page脏数据,如果这个时候发生非正常的DB服务重启,那么这些数据还在内存,并没有同步到磁盘文件中,也就是会发生数据丢失,如果这个时候,能够在有一个文件,当buffer pool中的data page变更结束后,把相应修改记录记录到这个文件(注意,记录日志是顺序IO),那么当DB服务发生crash的情况,恢复DB的时候,也可以根据这个文件的记录内容,重新写到到磁盘文件,这样数据就保持一致。
-
undo log,一致性,原子性。 undo日志用于存放数据被修改前的值,如果修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。另外InnoDB MVCC事务特性也是基于undo日志实现的。undo日志分为insert undo log(insert语句产生的日志,事务提交后直接删除)和update undo log(delete和update语句产生的日志,由于该undo log可能提供MVVC机制使用,所以不能再事务提交时删除)
2.隔离级别
读未提交:脏读
脏读:所谓的脏读,其实就是读到了别的事务回滚前的脏数据。当前事务读到的数据是别的事务想要修改但是没有修改成功的数据。
A读了B回滚前的数据。
读已提交:不可重复读,针对update和delete
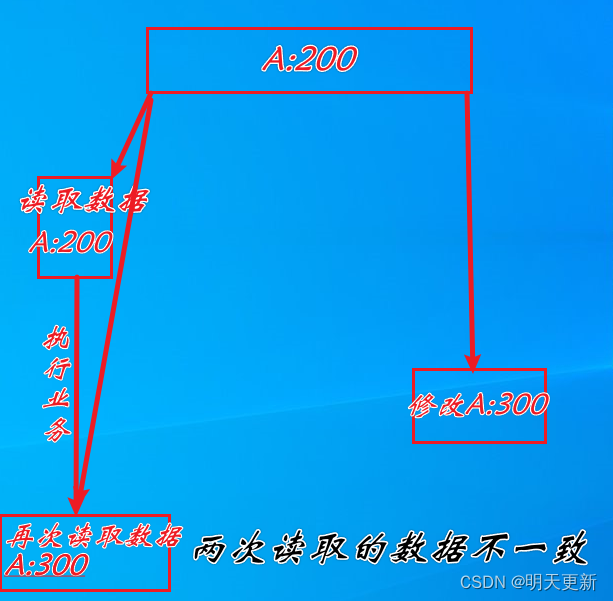
可重复读:幻读,针对insert

解决方法:采用多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。·
串行化:一个一个来,有效解决脏读,不可重复读,幻读,就是效率很低。
八、索引的优点和缺点(空间换时间)
优点:加快查询效率
缺点:占用内存空间,增删改的效率较低(删除数据的时候还需要删索引的相关数据,故效率低)
九、索引的分类
①:普通索引:值可以重复
②:唯一索引:唯一,允许有一个空值
③:主键索引:不为空,只能有一个
④:联合索引:(手机号和密码),(订单id和status)
⑤:全文索引:虽然MySQL支持全文索引但我们并没有采用,我们采用ES做搜索引擎。
十、B树与B+树的主要区别
存储数据的位置:
B树: 数据既存储在所有节点中(叶子节点和非叶子节点都有数据)
B+树: 所有的数据记录都存储在叶子节点中,非叶子节点仅包含索引信息。叶子节点包含了完整的数据和索引键。
叶子节点之间的链接:
B树: 叶子节点之间没有链接。
B+树: 叶子节点之间通过指针相互链接,形成一个链表或循环链表,这使得范围查询和遍历变得高效。
十一、MySql Explain优化命令使用
truncate table student // 自增id 从 0 开始
delete from student // 自增id 会保留 , 108
区别:
1:自增id
2:delete 可以恢复
truncate 无法恢复
通过MySQL的慢日志和skyworking进行记录所有较慢的sql语句,我们的运维通过xxl-job每天早上八点定时发送邮件,我们查看邮件看是否有自己所在组的慢日志的语句。在通过explain命令对我们的sql语句进行分析,通过查看type字段看我们的sql处于什么阶段,然后进行优化。
1、type 列(重点)
"type"列用于表示访问表时所采用的访问类型。
下面是常见的"type"值及其含义:
-
system: 表示只有一行的表,通常是系统表。 -
const: 表示通过索引只能匹配到一行数据。 explain select * from student where id = 1688
-
eq_ref: 表示使用了等值连接(例如,使用主键或唯一索引连接表)。explain SELECT * FROM student s1 JOIN student s2 ON s1.id = s2.id WHERE s1.age = 25;
-
ref: 表示使用了非唯一索引进行查找,并返回匹配的多行或一行数据。 explain select * from student where name = '张68'
-
range: 表示使用了索引进行范围查找,例如使用比较符(>, <, BETWEEN)或IN操作符。 explain select * from student where age < 1688
-
index: 表示全索引扫描,也就是说用了某一个索引的全部, 通常发生在查询使用索引覆盖的情况下。explain select count(*) from student ;explain select sum(age) from student
-
all: 表示全表扫描,即没有使用索引,需要遍历整个表进行查询。 explain select * from student
2、如何避免索引失效
①:避免使用范围条件查询(如果查询的结果数大于总数的三分之一,索引就会失效)
②:避免使用函数运算会造成索引失效(使用函数运算,在没计算出来结果之前无法确定结果)
③:字符串不加引号会造成索引失效(不加引号比较的是ASI码,加引号比较的是字符串常量)
④:尽量使用索引覆盖
索引覆盖:通过索引就能找到你想要的信息,就可以避免再次查询
回表:通过索引不能够完全查询到你要找到的信息,需要回表再查询一次
⑤:or关键字连接(or前后的列都需要有索引才会走索引,只要有一个没有使用索引,索引就是失效)
⑥:使用!=(底层就是使用函数运算,索引就会失效)
⑦:like '%张' (最左匹配原则,先%就是全表查询,先‘张’就是根据索引查询)
十二、数据库锁
1、行锁和表锁
①:粒度划分:行锁,表锁,库锁
②:行锁和表锁的区别:
表锁:开销小,加锁快,不会出现死锁,锁的粒度大,锁冲突的概率大,并发低
行锁:开销大,加锁慢,会出现死锁,粒度小,锁冲突的概率小,高并发
2、优化索引
2.1、索引设计原则:
-
对查询频次较高, 且数据量比较大的表, 建立索引.
- 索引字段的选择, 最佳候选列应当从 where 子句的条件中提取, 如果 where 子句中的组合比较多, 那么应当挑选最常用, 过滤效果最好的列的组合
-
使用唯一索引, 区分度越高, 使用索引的效率越高,能建唯一索引就建唯一索引,或者普通索引
-
索引并非越多越好, 如果该表赠,删,改操作较多, 慎重选择建立索引, 过多索引会降低表维护效率. 不是越多越好
-
使用短索引, 提高索引访问时的 I/O 效率, 因此也相应提升了 Mysql 查询效率.
-
如果 where 后有多个条件经常被用到, 建议建立复合索引, 复合索引需要遵循最左前缀法则, N 个列组合而成的复合索引, 相当于创建了 N 个索引.
3、聚簇索引和非聚簇索引
索引存储的都是key - value形式,主键索引存储的索引(key)物理表的地址(value)
非聚簇索引,key存储的是索引,value存储的是主键索引,需要再回表。
聚簇索引:我们以往使用的索引中只有主键索引是聚簇索引。主键索引是跟物理表直接连接。
非聚簇索引:除了主键索引外的都是非聚簇索引,依赖于主键索引,根据主键索引连接物理表,再进行回表。
十三、索引下推
在传统的查询语句中,当我们的查询条件有多个时,通常会将拥有的数据查出来后再进行回表操作,拿到符合的条件再比对剩下的查询条件,这会浪费大量资源,但在开启索引下推后,我们可以直接在第一次查询索引时附带上其余条件,从而减少回表的次数,增加查询效率,但索引吓退时只能附带一些简单查询规则,后续可能会慢慢优化。mysql6.5之后才有索引下推。
相关文章:
面试题------>MySQL!!!
一、连接查询 ①:左连接left join (小表在左,大表在右) ②:右连接right join(小表在右,大表在左) 二、聚合函数 SQL 中提供的聚合函数可以用来统计、求和、求最值等等 COUNT&…...

英伟达:史上最牛一笔天使投资
200万美元的天使投资,让刚成立就面临倒闭风险的英伟达由危转安,并由此缔造了一个2.8万亿美元的市值神话。 这是全球风投史上浓墨重彩的一笔。 前不久,黄仁勋在母校斯坦福大学的演讲中,提到了人生中的第一笔融资——1993年&#x…...

PDF分页处理:技术与实践
引言 在数字化办公和学习中,PDF文件因其便携性和格式稳定性而广受欢迎。然而,处理大型PDF文件时,我们经常需要将其拆分成单独的页面,以便于管理和分享。本文将探讨如何使用Python编程语言和一些流行的库来实现PDF文件的分页处理。…...
数据可视化——pyecharts库绘图
目录 官方文档 使用说明: 点击基本图表 可以点击你想要的图表 安装: 一些例图: 柱状图: 效果: 折线图: 效果: 环形图: 效果: 南丁格尔图(玫瑰图&am…...

Python的return和yield,哪个是你的菜?
目录 1、return基础介绍 📚 1.1 return用途:数据返回 1.2 return执行:函数终止 1.3 return深入:无返回值情况 2、yield核心概念 🍇 2.1 yield与迭代器 2.2 生成器函数构建 2.3 yield的暂停与续行特性 3、retur…...
)
持续总结中!2024年面试必问 20 道分布式、微服务面试题(七)
上一篇地址:持续总结中!2024年面试必问 20 道分布式、微服务面试题(六)-CSDN博客 十三、请解释什么是服务网格(Service Mesh)? 服务网格(Service Mesh)是一种用于处理服…...

AJAX 跨域
这里写目录标题 同源策略JSONPJSONP 是怎么工作的JSONP 的使用原生JSONP实践CORS 同源策略 同源: 协议、域名、端口号 必须完全相同、 当然网页的URL和AJAX请求的目标资源的URL两者之间的协议、域名、端口号必须完全相同。 AJAX是默认遵循同源策略的,不…...

3 数据类型、运算符与表达式-3.1 C语言的数据类型和3.2 常量与变量
数据类型 基本类型 整型字符型实型(浮点型) 单精度型双精度型 枚举类型 构造类型 数组类型结构体类型共用体类型 指针类型空类型 #include <stdio.h> #include <string.h> #include <stdbool.h> // 包含布尔类型定义 // 常量和符号常量 #define PRICE 30//…...
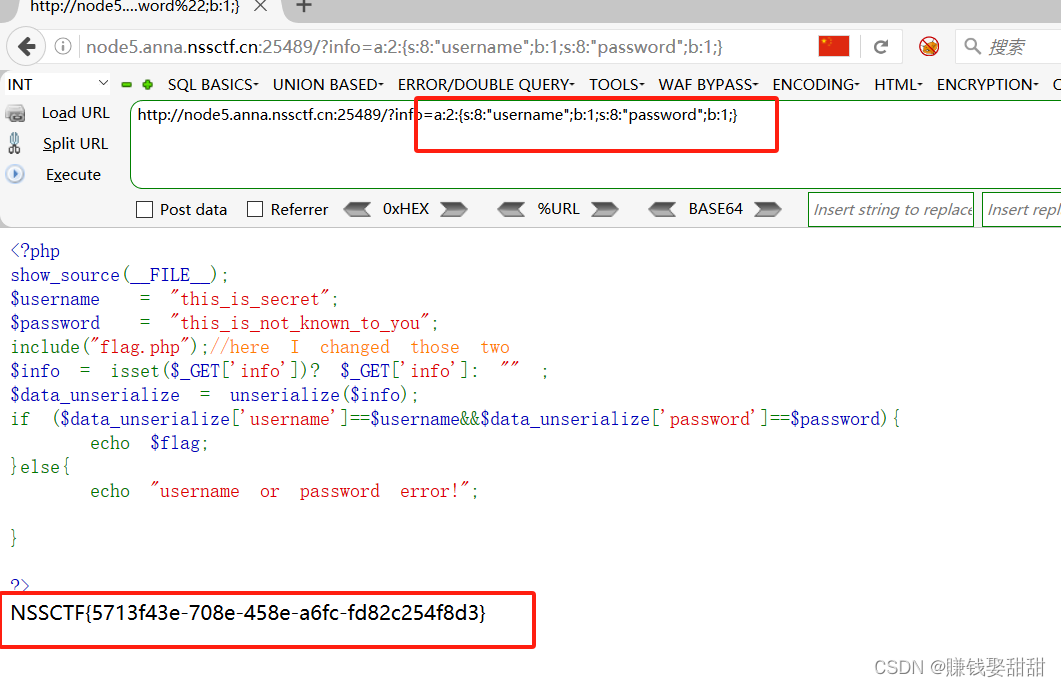
NSSCTF-Web题目5
目录 [SWPUCTF 2021 新生赛]error 1、题目 2、知识点 3、思路 [LitCTF 2023]作业管理系统 1、题目 2、知识点 3、思路 [HUBUCTF 2022 新生赛]checkin 1、题目 2、知识点 3、思路 [SWPUCTF 2021 新生赛]error 1、题目 2、知识点 数据库注入、报错注入 3、思路 首先…...

cnvd_2015_07557-redis未授权访问rce漏洞复现-vulfocus复现
1.复现环境与工具 环境是在vulfocus上面 工具:GitHub - vulhub/redis-rogue-getshell: redis 4.x/5.x master/slave getshell module 参考攻击使用方式与原理:https://vulhub.org/#/environments/redis/4-unacc/ 2.复现 需要一个外网的服务器做&…...

免费,C++蓝桥杯等级考试真题--第7级(含答案解析和代码)
C蓝桥杯等级考试真题--第7级 答案:D 解析:步骤如下: 首先,--a 操作会使 a 的值减1,因此 a 变为 3。判断 a > b 即 3 > 3,此时表达式为假,因为 --a 后 a 并不大于 b。因此,程…...

python为什么要字符串格式化
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。相对于老版的%格式方法,它有很多优点。 1.在%方法中%s只能替代字符串类型,而在format中不需要理会数据类型; 2.单个参数可以…...
go语言后端开发学习(三)——基于validator包实现接口校验
前言 在我们开发模块的时候,有一个问题是我们必须要去考虑的,它就是如何进行入参校验,在gin框架的博客中我就介绍过一些常见的参数校验,大家可以参考gin框架学习笔记(四) ——参数绑定与参数验证,而这个其实也不是能够完全应对我…...
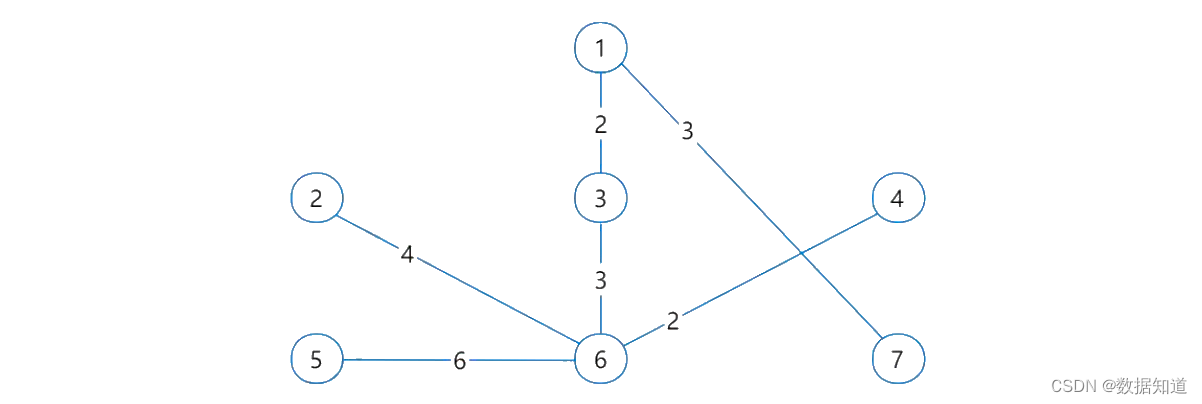
系统架构设计师【补充知识】: 应用数学 (核心总结)
一、 图论之最小生成树 (1)定义: 在连通的带权图的所有生成树中,权值和最小的那棵生成树(包含图中所有顶点的树),称作最小生成树。 (2)针对问题: 带权图的最短路径问题。 (3)最小生成树的解法有普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法,我…...
栅格数据格式)
【ArcGIS微课1000例】0118:一文讲清楚tif(geotiff)栅格数据格式
文章目录 一、Tiff概述二、GeoTiff概述1. ovr文件2. tfw文件3. xml文件4. dbf文件一、Tiff概述 TIFF(Tagged Image File Format)是一种常见的图像文件格式,它被广泛用于存储和传输各种类型的图像数据。下面是对TIFF格式数据的介绍: 图像存储:TIFF格式可以存储多通道的位…...

调用第三方API --------------Python篇
在项目开发过程中,可能需要调用第三方的一些API或者公司提供的数据接口来得到相应的数据或者实现对应的功能。 因此API的调用和数据接口的访问都是做数据分析的一个常用操作,如何快速实现API和数据接口的调用,网上一般提供很多语言版本&#…...
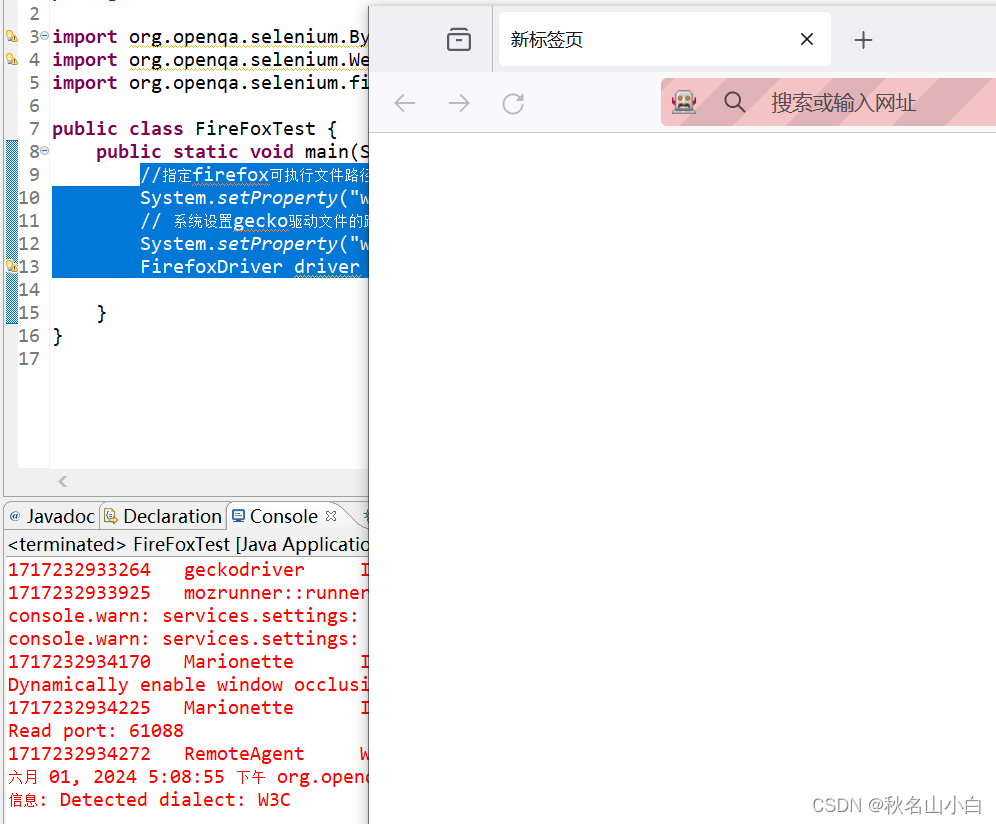
Web自动化测试-掌握selenium工具用法,使用WebDriver测试Chrome/FireFox网页(Java
目录 一、在Eclipse中构建Maven项目 1.全局配置Maven 2.配置JDK路径 3.创建Maven项目 4.引入selenium-java依赖 二、Chrome自动化脚本编写 1.创建一个ChromeTest类 2.测试ChromeDriver 3.下载chromedriver驱动 4.在脚本中通过System.setProperty方法指定chromedriver的…...

maven多模块项目搭建
文章目录 创建方式创建父项目创建子模块 目录结构示例父模块模块A模块B(并在模块B中引入模块A) 注意事项 创建方式 创建父项目 #创建文件夹后,进入目录,执行以下命令 PS D:\demo> mvn archetype:generate #将输出很多模板&am…...

PostgreSQL的视图pg_tables
PostgreSQL的视图pg_tables pg_tables 是 PostgreSQL 中的一个系统视图,用于显示当前数据库中所有用户定义的表的信息。这个视图提供了关于表的名称、所属模式(schema)、所有者以及表类型等详细信息。 pg_tables 视图的主要列 列名类型描述…...

Stable diffusion采样器详解
在我们使用SD web UI的过程中,有很多采样器可以选择,那么什么是采样器?它们是如何工作的?它们之间有什么区别?你应该使用哪一个?这篇文章将会给你想要的答案。 什么是采样? Stable Diffusion模…...
与事务ID:那些年我们追丢的TLP)
068、PCIE标签(Tag)与事务ID:那些年我们追丢的TLP
068、PCIE标签(Tag)与事务ID:那些年我们追丢的TLP 从一次深夜调试说起 上个月帮同事看一个诡异的PCIE问题:DMA传输偶尔丢包,概率大概万分之三。逻辑分析仪抓到的TLP序列一切正常,但设备端就是偶尔收不到某个内存写请求。熬到凌晨三点,突然注意到一个细节——两个不同方…...
)
从暗房到云端:一位古籍修复师用Midjourney蓝晒法重制《天工开物》插图的72小时实录(含失败21次原始日志)
更多请点击: https://intelliparadigm.com 第一章:从暗房到云端:一场古籍图像的跨时空显影 在胶片时代,古籍修复师需在幽暗的暗房中,借助红光灯与显影液,一帧一帧唤醒沉睡于纸背的墨痕;而今&am…...

标书高效制作:Word 排版快捷键 + AI 工具组合工作流
在招投标文档制作中,Word 排版、格式调整、段落对齐、目录生成等重复操作,往往占用大量时间。熟练使用快捷键可以显著提升编辑速度,而结合 AI 辅助工具,则能从流程层面实现效率升级。本文分享一套安全、合规、无营销的纯办公实践方…...

Photoshop图层批量导出终极指南:告别手动操作,提升10倍工作效率
Photoshop图层批量导出终极指南:告别手动操作,提升10倍工作效率 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ad…...

如何将Scrapeless MCP服务器集成到ZeroClaw中:逐步指南
关键要点: 一个TOML块将云浏览器连接到本地Rust代理。 ZeroClaw是一个单一二进制AI代理运行时,它与LLM提供者通信,监听30多个频道,并通过工具进行操作。只需在~/.zeroclaw/config.toml中添加四行[mcp]块即可添加Scrapeless MCP服…...

情感演绎有多强?顶伯实测愤怒、喜悦、悲伤等 9 种语气
🎭 微软 TTS 的情感演绎有多强?顶伯实测愤怒、喜悦、悲伤等 9 种语气🎯 引言:语音合成的情感革命在人工智能语音合成领域,情感表达一直是技术难点。微软 TTS(文本转语音)通过深度学习模型&#…...

欧姆龙G9SP安全控制系统中,如何通过NB触摸屏实现远程复位与状态监控?
欧姆龙G9SP安全控制系统与NB触摸屏的深度集成:远程复位与状态监控实战指南 在工业自动化领域,安全控制系统的可靠性与操作便捷性同样重要。欧姆龙G9SP作为专业的安全控制器,与NB系列触摸屏的协同工作,能够为生产线提供既安全又高…...

承压含水层中变流量抽水试验井流动力学模型与参数反演方法【附算法】
✨ 长期致力于变流量、抽水试验、参数反演、井损、粒子群优化算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)线性衰减变流量抽水试验理论模型与半…...

终极OpenHTMLtoPDF教程:5分钟构建专业PDF生成器
终极OpenHTMLtoPDF教程:5分钟构建专业PDF生成器 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF/UA)!…...

PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程
PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, al…...