【内存管理】页表映射
页表的一些术语
现在Linux内核中支持四级页表的映射,我们先看下内核中关于页表的一些术语:
-
全局目录项,PGD(Page Global Directory)
-
上级目录项,PUD(Page Upper Directory)
-
中间目录项,PMD(Page Middle Directory)
-
页表项,(Page Table)
大家在看内核代码时会经常看的以上术语,但在ARM的芯片手册中并没有用到这些术语,而是使用L1,L2,L3页表这种术语。
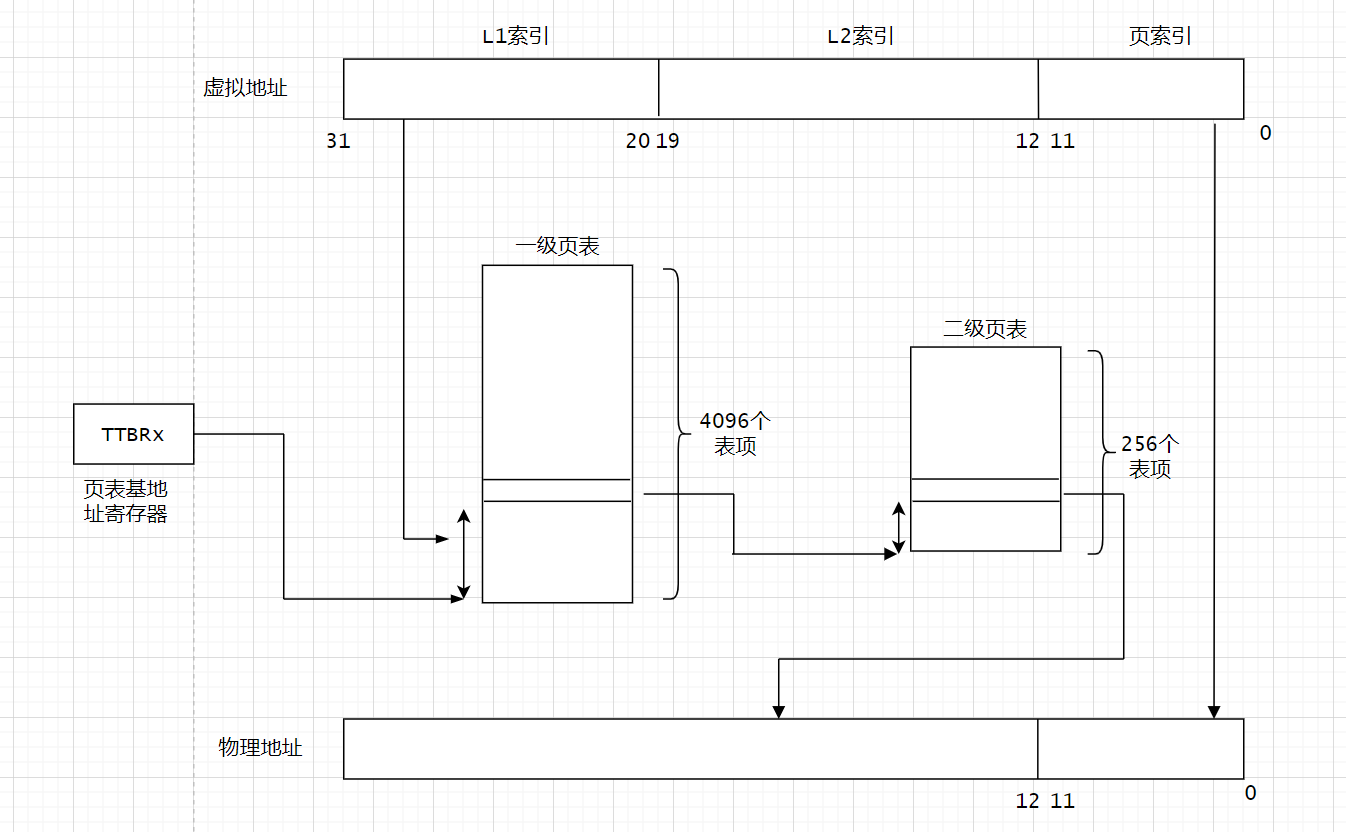
ARM32 虚拟地址到物理地址的转换
虚拟地址的32个bit位可以分为3个域,最高12bit位20~31位称为L1索引,叫做PGD,页面目录。中间的8个bit位叫做L2索引,在Linux内核中叫做PT,页表。最低的12位叫做页索引。
在ARM处理器中,TTBRx寄存器存放着页表基地址,我们这里的一级页表有4096个页表项。每个表项中存放着二级表项的基地址。我们可以通过虚拟地址的L1索引访问一级页表,访问一级页表相当于数组访问。
二级页表通常是动态分配的,可以通过虚拟地址的中间8bit位L2索引访问二级页表,在L2索引中存放着最终物理地址的高20bit位,然后和虚拟地址的低12bit位就组成了最终的物理地址。以上就是虚拟地址转换为物理地址的过程。
MMU访问页表是硬件实现的,但页表的创建和填充需要Linux内核来填充。通常,一级页表和二级页表存放在主存储器中。
ARM32 一级页表的页表项
下面这张图来自ARMV7的手册。

一级页表项这里有三种情况:一种是无效的,第二种是一级页表的表项。第三种是段映射的页表项。
-
bit 0 ~ bit 1:用来表示这个页表项是一级页表还是段映射的表项。
-
PXN:PL1 表示是否可以执行这段代码,为0表示可执行,1表示不可执行。
-
NS:none-security bit,用于安全扩展。
-
Domain:Domain域,指明所属的域,Linux中只使用了3个域。
-
bit31:bit10:指向二级页表基地址。
二级页表的表项

-
bit0:禁止执行标志。1表示禁止执行,0表示可执行
-
bit1:区分是大页还是小页
-
C/B bit:内存区域属性
-
TEX[2:0]:内存区域属性
-
AP[0:1] :访问权限
-
S:是否可共享
-
nG:用于TLB
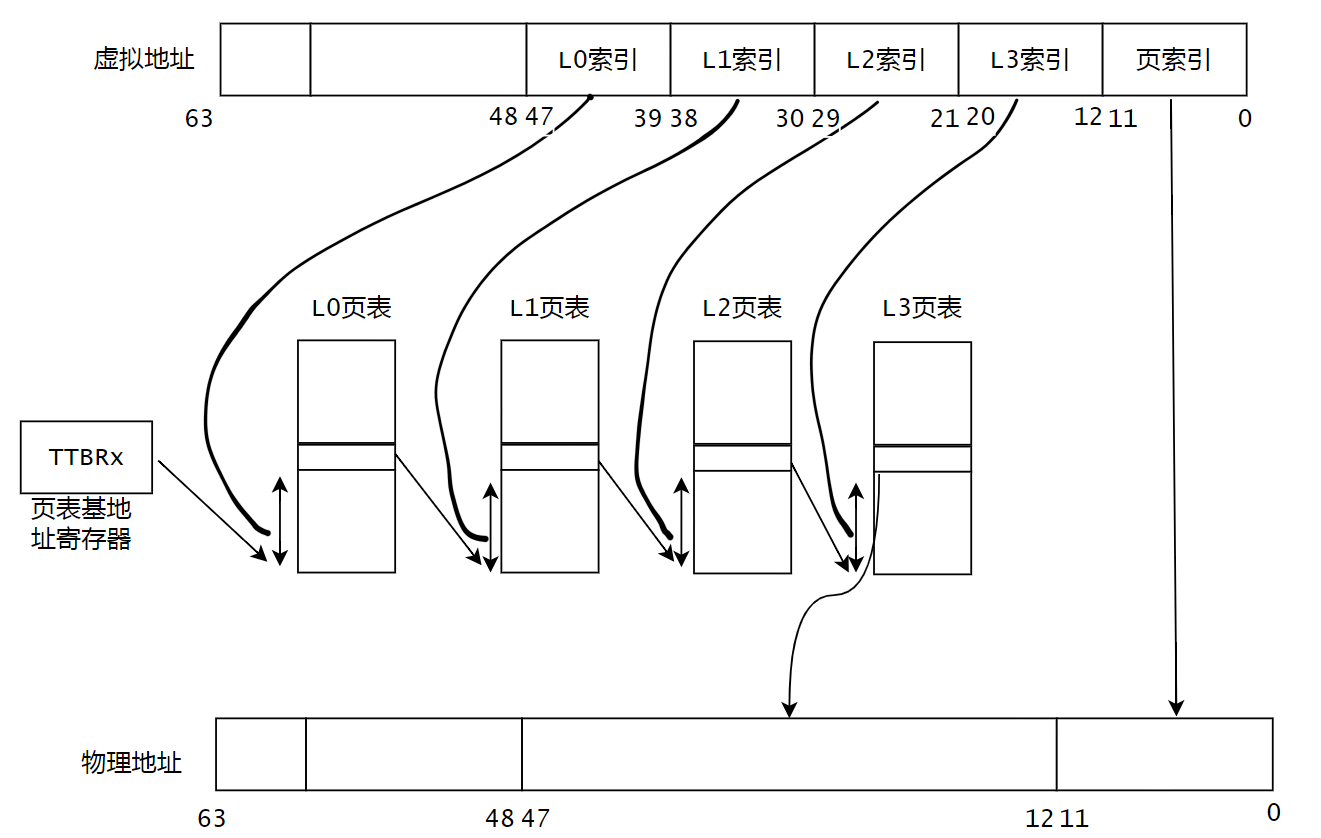
ARM64 页表
ARM体系结构从ARMV8-A开始就支持64bit位,最大支持48根地址线。那为什么不支持64根地址线呢?主要原因是48根地址线时已支持最大访问空间为256TB(内核空间和用户空间分别256TB)满足了大部分应用的需求。而且,64根地址线时,芯片的设计复杂度会急剧增加。ARMV8-A架构中,支持4KB,16KB和64KB的页,支持3级或者4级映射。
下面我们以4KB大小页+4级映射介绍下虚拟地址到物理地址的映射过程。
-
0~11 :页索引
-
bit 63 :页表基地址选择位,ARMV8架构中有2两个页表基地址,一个用于用户空间,一个用户内核空间。
-
39~47:L0索引
-
30~38:L1索引
-
21~29:L2索引
-
12~20:L3 索引
假设页表基地址为TTBRx,访问页表基地址就能访问到L0页表的基地址,可以使用L0索引的值作为offset去访问L0页表。
L0的页表项包含了下一级L1页表的基地址,同样的,可以使用L1索引的值作为offset去访问L2页表。以此类推。
最后通过L3的页表项可以得到物理地址的bit12 ~ 47位,这个时候再将虚拟地址的页索引位对应到物理地址的0~11就是完整的物理地址。
Linux内核关于页表的函数
Linux内核中页表操作的宏定义
Linux内核中封装了很多宏来处理页表
#define pgd_offset_k(addr) pgd_offset(&init_mm,addr) //由虚拟地址来获取内核页表的PGD页表的相应的页表项
#define pgd_offset(mm,addr) ((mm)->pgd + pgd_index(addr)) //由虚拟地址来获取用户进程的页表中相应的PGD表项
pgd_index(addr) //由虚拟地址找到PGD页表的索引
pte_index(addr) //由虚拟地址找到PT页表的索引
pte_offset_kernel(pmd,addr) //查找内核页表中对应的PT页表的表项
判断页表项的状态
#define pte_none(pte) (!pte_val(pte)) //pte是否存在
#define pte_present(pte) (pte_isset((pte), L_PTE_PRESENT)) //present比特位
#define pte_valid(pte) (pte_isset((pte), L_PTE_VALID)) //pte是否有效
#define pte_accessible(mm, pte) (mm_tlb_flush_pending(mm) ? pte_present(pte) : pte_valid(pte))
#define pte_write(pte) (pte_isclear((pte), L_PTE_RDONLY)) //pte是否可写
#define pte_dirty(pte) (pte_isset((pte), L_PTE_DIRTY)) //pte是否有脏数据
#define pte_young(pte) (pte_isset((pte), L_PTE_YOUNG)) //
#define pte_exec(pte) (pte_isclear((pte), L_PTE_XN))
修改页表
mk_pte() //创建的相应的页表项
pte_mkdirty() // 设置dirty标志位
pte_mkold() // 清除Accessed标志位
pte_mkclean() //清除dirty标志位
pte_mkwrite()// 设置读写标志位
pte_wrprotect() //清除读写标志位
pte_mkyoung()//设置Accessed标志位
set_pte_at()// 设置页表项到硬件中
例子1 内核页表的映射
前面我们介绍了很多关于内核的宏,函数,下面我们通过实际的例子学习如何使用这些宏
系统初始化时需要把kernel image区域和线性映射区建立页表映射,这个时候依次调用start_kernel() --> setup_arch() --> paging_init() --> map_lowmem() --> create_mapping()去创建内核页表。我们可以研究下内核是如何建立内核页表的映射。
/** Create the page directory entries and any necessary* page tables for the mapping specified by `md'. We* are able to cope here with varying sizes and address* offsets, and we take full advantage of sections and* supersections.*/
static void __init create_mapping(struct map_desc *md)
{if (md->virtual != vectors_base() && md->virtual < TASK_SIZE) {pr_warn("BUG: not creating mapping for 0x%08llx at 0x%08lx in user region\n",(long long)__pfn_to_phys((u64)md->pfn), md->virtual);return;}if (md->type == MT_DEVICE &&md->virtual >= PAGE_OFFSET && md->virtual < FIXADDR_START &&(md->virtual < VMALLOC_START || md->virtual >= VMALLOC_END)) {pr_warn("BUG: mapping for 0x%08llx at 0x%08lx out of vmalloc space\n",(long long)__pfn_to_phys((u64)md->pfn), md->virtual);}__create_mapping(&init_mm, md, early_alloc, false);
}
首先会检查映射的虚拟地址是否在内核向量表的基址以上,并且小于用户空间的TASK_SIZE。TASK_SIZE通常被定义为0xC0000000(3GB),表示用户空间的虚拟地址范围从0到3GB。对于64位体系结构,TASK_SIZE通常被定义为0x00007fffffffffff(128TB)。
接着会检查映射的类型是否为设备类型,并且虚拟地址在页偏移以上且低于FIXADDR_START,且不在VMALLOC_START和VMALLOC_END之间(即不在vmalloc空间中)。
最后会调用__create_mapping函数创建映射。传入初始内存管理结构体init_mm、映射描述结构体md、早期内存分配函数early_alloc,以及false标志。
/** Create a mapping for the given map descriptor, md. The function* __create_mapping is used for both kernel and user mode mappings.** @mm: the mm structure where the mapping will be created* @md: the map descriptor with the details of the mapping* @alloc: a pointer to a function used to allocate pages for the mapping* @ng: a boolean flag indicating if the mapping is non-global*/
static void __init __create_mapping(struct mm_struct *mm, struct map_desc *md,void *(*alloc)(unsigned long sz),bool ng)
{unsigned long addr, length, end;phys_addr_t phys;const struct mem_type *type;pgd_t *pgd;type = &mem_types[md->type];#ifndef CONFIG_ARM_LPAE----------------------(1)/** Catch 36-bit addresses*/if (md->pfn >= 0x100000) {create_36bit_mapping(mm, md, type, ng);return;}
#endifaddr = md->virtual & PAGE_MASK;----------------------(2)phys = __pfn_to_phys(md->pfn);length = PAGE_ALIGN(md->length + (md->virtual & ~PAGE_MASK));/** Check if the mapping can be made using pages.* If not, print a warning and ignore the request.*/if (type->prot_l1 == 0 && ((addr | phys | length) & ~SECTION_MASK)) {----------------------(3)pr_warn("BUG: map for 0x%08llx at 0x%08lx can not be mapped using pages, ignoring.\n",(long long)__pfn_to_phys(md->pfn), addr);return;}pgd = pgd_offset(mm, addr);end = addr + length;----------------------(4)do {unsigned long next = pgd_addr_end(addr, end);----------------------(5)/** Allocate a page directory entry for this range.* Initialize it with the appropriate page table* and make the mapping.*/alloc_init_p4d(pgd, addr, next, phys, type, alloc, ng);----------------------(6)/** Update the phys value with the end of the last mapped* page so that the next range can be allocated properly.*/phys += next - addr;addr = next;----------------------(7)} while (pgd++, addr != end);
}
__create_mapping完成中创建映射的功能,根据给定的映射描述结构体,将虚拟地址与物理地址进行映射。
(1) 系统没有启用ARM LPAE(Large Physical Address Extension),并且物理页帧号大于等于0x100000,调用create_36bit_mapping函数进行处理,然后返回。
在早期阶段,地址总线也是32位的,即4G的内存地址空间。随着应用程序越来越丰富,占用的内存总量很容易就超过了4G。但由于编程模型和地址总线的限制,是无法使用超过4G的物理地址的。所以PAE/LPAE这种大内存地址方案应运而生。
PAE/LAPE方案其它很简单,编程视角依然还是32位(4G)的地址空间,这层是虚拟地址空间。而计算机地址总线却使用超过32位的,比如X86的就使用36位(64G)的地址总线,ARM使用的是48位(64G)的地址总线。中间是通过保护模式(X86架构)或者MMU机制(ARM架构)提供的分页技术(paging)实现32位虚拟地址访问超过4G的物理内存空间。这项技术的关键是分页技术中的页表项使用超过4字节的映射表 (ARM在LPAE模式下,页表项是8字节),因为使用超过4字节映射表,就可以指示超过4G的内存空间。
(2) 获取虚拟地址的起始地址,因为地址映射的最小单位是page,因此这里进行mapping的虚拟地址需要对齐到page size,同样的,长度也需要对齐到page size。
(3) 首先检查映射类型的prot_l1字段是否为0。prot_l1表示第一级页表(Level 1 Page Table)的保护位。如果prot_l1为0,表示无法使用页面进行映射。如果地址、物理地址和长度与SECTION_MASK存在非零位,表示页面映射要求地址和长度并未按页面大小对齐。
(4)设置了页全局目录(pgd)的初始偏移,并将结束地址(end)设置为起始地址(addr)加上长度(length)。
(5)然后,使用pgd_addr_end函数计算下一个地址(next),该地址是当前地址和结束地址之间的较小值。
(6)调用alloc_init_p4d函数,为当前范围内的地址分配一个页目录项,初始化它的页表,并进行映射。该函数使用给定的参数pgd、addr、next、phys、type、alloc和ng来执行这些操作。
(7)更新phys的值,使其加上当前范围内映射的页面数,以便正确分配下一个范围的地址。最后,在循环的末尾,递增pgd的值,并检查是否达到了结束地址。如果没有达到,继续循环处理下一个地址范围。
例子2 进程页表的映射
remap_pfn_range函数对于写过Linux驱动的人都不陌生,很多驱动程序的mmap函数都会调用到该函数,该函数实现了物理空间到用户进程的映射。
比如我们在用户空间读写SOC的寄存器时,ARM中的寄存器通常都是memory map形式的,在用户空间都要读写ARM空间的寄存器,通常都要操作/dev/mem设备来实现,最后都会调用到remap_pfn_range来实现。
-
VMA:准备要映射的进程地址空间的VMA的数据结构
-
addr:要映射到 用户空间的起始地址
-
pfn:准备要映射的物理内存的页帧号
-
size:表示要映射的大小
-
prot:表示要映射的属性
接下来我们从页表的角度看下函数的实现
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot)
{pgd_t *pgd;unsigned long next;unsigned long end = addr + PAGE_ALIGN(size);struct mm_struct *mm = vma->vm_mm;//从VMA获取当前进程的mm_struct结构unsigned long remap_pfn = pfn;int err;if (WARN_ON_ONCE(!PAGE_ALIGNED(addr)))return -EINVAL;if (is_cow_mapping(vma->vm_flags)) {if (addr != vma->vm_start || end != vma->vm_end)return -EINVAL;vma->vm_pgoff = pfn;}err = track_pfn_remap(vma, &prot, remap_pfn, addr, PAGE_ALIGN(size));if (err)return -EINVAL;vma->vm_flags |= VM_IO | VM_PFNMAP | VM_DONTEXPAND | VM_DONTDUMP;//设置vm_flags,remap_pfn_range直接使用物理内存。Linux内核对物理页面分为两类:normal mapping,special mapping。special mapping就是内核不希望该页面参与到内核的页面回收等活动中。BUG_ON(addr >= end);pfn -= addr >> PAGE_SHIFT;pgd = pgd_offset(mm, addr);//找到页表项flush_cache_range(vma, addr, end);//以PGD_SIZE为步长遍历页表do {next = pgd_addr_end(addr, end);//获取下一个PGD页表项的管辖的地址范围的起始地址err = remap_p4d_range(mm, pgd, addr, next,pfn + (addr >> PAGE_SHIFT), prot);//继续遍历下一级页表if (err)break;} while (pgd++, addr = next, addr != end);if (err)untrack_pfn(vma, remap_pfn, PAGE_ALIGN(size));return err;
}
遍历PUD页表
static inline int remap_pud_range(struct mm_struct *mm, p4d_t *p4d,unsigned long addr, unsigned long end,unsigned long pfn, pgprot_t prot)
{pud_t *pud;unsigned long next;int err;pfn -= addr >> PAGE_SHIFT;pud = pud_alloc(mm, p4d, addr);//找到pud页表项。对于二级页表来说,PUD指向PGDif (!pud)return -ENOMEM;//以PUD_SIZE为步长遍历页表do {next = pud_addr_end(addr, end);//获取下一个PUD页表项的管辖的地址范围的起始地址err = remap_pmd_range(mm, pud, addr, next,pfn + (addr >> PAGE_SHIFT), prot);//继续遍历下一级页表if (err)return err;} while (pud++, addr = next, addr != end);return 0;
}
Linux内核中实现了4级页表,对于ARM32来说,它是如何跳过中间两级页表的呢?大家可以看下以下两个宏的实现
/* Find an entry in the second-level page table.. */
#ifndef pmd_offset
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long address)
{return (pmd_t *)pud_page_vaddr(*pud) + pmd_index(address);
}
#define pmd_offset pmd_offset
#endif
接收指向页上级目录项的指针 pud 和线性地址 addr 作为参数。这个宏产生目录项 addr 在页中间目录中的偏移地址。在两级或三级分页系统中,它产生 pud ,即页全局目录项的地址。
#ifndef pud_offset
static inline pud_t *pud_offset(p4d_t *p4d, unsigned long address)
{return (pud_t *)p4d_page_vaddr(*p4d) + pud_index(address);
}
#define pud_offset pud_offset
#endif
参数为指向页全局目录项的指针 pgd 和线性地址 addr 。这个宏产生页上级目录中目录项 addr 对应的线性地址。在两级或三级分页系统中,该宏产生 pgd ,即一个页全局目录项的地址。
遍历PMD页表
remap_pmd_range函数和remap_pud_range类似。
static inline int ioremap_pmd_range(pud_t *pud, unsigned long addr,unsigned long end, phys_addr_t phys_addr, pgprot_t prot,pgtbl_mod_mask *mask)
{pmd_t *pmd;unsigned long next;pmd = pmd_alloc_track(&init_mm, pud, addr, mask);//找到对应的pmd页表项,对于二级页表来说,pmd指向pudif (!pmd)return -ENOMEM;//以PMD_SIZE为步长遍历页表do {next = pmd_addr_end(addr, end);//获取下一个PMD页表项的管辖的地址范围的起始地址if (ioremap_try_huge_pmd(pmd, addr, next, phys_addr, prot)) {*mask |= PGTBL_PMD_MODIFIED;continue;}//继续遍历下一级页表if (ioremap_pte_range(pmd, addr, next, phys_addr, prot, mask))return -ENOMEM;} while (pmd++, phys_addr += (next - addr), addr = next, addr != end);return 0;
}
遍历PT页表
/** maps a range of physical memory into the requested pages. the old* mappings are removed. any references to nonexistent pages results* in null mappings (currently treated as "copy-on-access")*/
static int remap_pte_range(struct mm_struct *mm, pmd_t *pmd,unsigned long addr, unsigned long end,unsigned long pfn, pgprot_t prot)
{pte_t *pte, *mapped_pte;spinlock_t *ptl;int err = 0;mapped_pte = pte = pte_alloc_map_lock(mm, pmd, addr, &ptl);//寻找相应的pte页表项。注意这里需要申请一个spinlock锁用来保护修改pte页表if (!pte)return -ENOMEM;arch_enter_lazy_mmu_mode();//以PAGE_SIZE为步长遍历PT页表do {BUG_ON(!pte_none(*pte));if (!pfn_modify_allowed(pfn, prot)) {err = -EACCES;break;}/**pte_none()判断这个pte是否存在*pfn_pte()由页帧号pfn得到pte*pte_mkspecial()设置软件的PTE_SPECIAL标志位(三级页表才会用该标志位)*set_pte_at() 把pte设置到硬件页表中*/set_pte_at(mm, addr, pte, pte_mkspecial(pfn_pte(pfn, prot)));pfn++;} while (pte++, addr += PAGE_SIZE, addr != end);arch_leave_lazy_mmu_mode();pte_unmap_unlock(mapped_pte, ptl);//PT页表设置完成后,需要把spinlock 释放return err;
}
缺页中断do_anonymous_page
在缺页中断处理中,匿名页面的触发条件为下面的两个条件,当满足这两个条件的时候就会调用do_anonymous_page函数来处理匿名映射缺页异常,代码实现在mm/memory.c文件中
- 发生缺页的地址所在页表项不存在
- 是匿名页,即是vma->vm_ops为空,即vm_operations函数指针为空
我们知道在进程的
task_struct结构中包含了一个mm_struct结构的指针,mm_struct用来描述一个进程的虚拟地址空间。进程的mm_struct则包含装入的可执行映像信息以及进程的页目录指针pgd。该结构还包含有指向 ~vm_area_struct ~结构的几个指针,每个vm_area_struct代表进程的一个虚拟地址区间。vm_area_struct结构含有指向vm_operations_struct结构的一个指针,vm_operations_struct描述了在这个区间的操作。vm_operations结构中包含的是函数指针;其中,open、close 分别用于虚拟区间的打开、关闭,而nopage 用于当虚存页面不在物理内存而引起的“缺页异常”时所应该调用的函数
/** We enter with non-exclusive mmap_lock (to exclude vma changes,* but allow concurrent faults), and pte mapped but not yet locked.* We return with mmap_lock still held, but pte unmapped and unlocked.*/
static vm_fault_t do_anonymous_page(struct vm_fault *vmf)
{struct vm_area_struct *vma = vmf->vma;struct page *page;vm_fault_t ret = 0;pte_t entry;/* File mapping without ->vm_ops ? */if (vma->vm_flags & VM_SHARED)-----------------(1)return VM_FAULT_SIGBUS;/** Use pte_alloc() instead of pte_alloc_map(). We can't run* pte_offset_map() on pmds where a huge pmd might be created* from a different thread.** pte_alloc_map() is safe to use under mmap_write_lock(mm) or when* parallel threads are excluded by other means.** Here we only have mmap_read_lock(mm).*/if (pte_alloc(vma->vm_mm, vmf->pmd))-----------------(2)return VM_FAULT_OOM;/* See the comment in pte_alloc_one_map() */if (unlikely(pmd_trans_unstable(vmf->pmd)))return 0;/* Use the zero-page for reads */if (!(vmf->flags & FAULT_FLAG_WRITE) &&!mm_forbids_zeropage(vma->vm_mm)) {-----------------(3)entry = pte_mkspecial(pfn_pte(my_zero_pfn(vmf->address),-----------------(4)vma->vm_page_prot));vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,-----------------(5)vmf->address, &vmf->ptl);if (!pte_none(*vmf->pte)) {-----------------(6)update_mmu_tlb(vma, vmf->address, vmf->pte);goto unlock;}ret = check_stable_address_space(vma->vm_mm);-----------------(7)if (ret)goto unlock;/* Deliver the page fault to userland, check inside PT lock */if (userfaultfd_missing(vma)) {-----------------(8)pte_unmap_unlock(vmf->pte, vmf->ptl);return handle_userfault(vmf, VM_UFFD_MISSING);}goto setpte;}/* Allocate our own private page. */if (unlikely(anon_vma_prepare(vma)))-----------------(9)goto oom;page = alloc_zeroed_user_highpage_movable(vma, vmf->address);-----------------(10)if (!page)goto oom;if (mem_cgroup_charge(page, vma->vm_mm, GFP_KERNEL))-----------------(11)goto oom_free_page;cgroup_throttle_swaprate(page, GFP_KERNEL);/** The memory barrier inside __SetPageUptodate makes sure that* preceding stores to the page contents become visible before* the set_pte_at() write.*/__SetPageUptodate(page);-----------------(12)entry = mk_pte(page, vma->vm_page_prot);-----------------(13)entry = pte_sw_mkyoung(entry);if (vma->vm_flags & VM_WRITE)entry = pte_mkwrite(pte_mkdirty(entry));-----------------(14)vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,&vmf->ptl);-----------------(15)if (!pte_none(*vmf->pte)) {update_mmu_cache(vma, vmf->address, vmf->pte);-----------------(16)goto release;}ret = check_stable_address_space(vma->vm_mm);-----------------(17)if (ret)goto release;/* Deliver the page fault to userland, check inside PT lock */if (userfaultfd_missing(vma)) {pte_unmap_unlock(vmf->pte, vmf->ptl);put_page(page);return handle_userfault(vmf, VM_UFFD_MISSING);}inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);-----------------(18)page_add_new_anon_rmap(page, vma, vmf->address, false);-----------------(19)lru_cache_add_inactive_or_unevictable(page, vma);-----------------(20)
setpte:set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);-----------------(21)/* No need to invalidate - it was non-present before */update_mmu_cache(vma, vmf->address, vmf->pte);-----------------(22)
unlock:pte_unmap_unlock(vmf->pte, vmf->ptl);return ret;
release:put_page(page);goto unlock;
oom_free_page:put_page(page);
oom:return VM_FAULT_OOM;
}
- 如果是共享则意味着之前以及通过mmap方式在其他进程申请过物理内存,vma应该存在对应物理内存映射,不应该再发生page fault
- 调用pte_alloc函数来为页面表表项(PTE)分配内存,并传递vma->vm_mm和vmf->pmd作为参数
- 如果页面错误不是写操作且内存管理子系统允许使用零页,则映射到零页面
- 生成一个特殊页表项,映射到专有的0页,一页大小
- 据pmd,address找到pte表对应的一个表项,并且lock住
- 如果页表项不为空,则调用
update_mmu_tlb函数更新内存管理单元(MMU)的转换查找缓冲(TLB)并且跳unlock。 - 检查地址空间的稳定性。
- 如果发现
userfaultfd缺失,则解除映射并解锁页面表项(PTE) - 对vma进行预处理,主要是创建anon_vma和anon_vma_chain,为后续反向映射做准备
- 从高端内存区的伙伴系统中获取一个页,这个页会清0
- 申请内存成功之后,将新申请的page加入到mcgroup管理
- 设置此页的PG_uptodate标志,表示此页是最新的
- 将页面和页面保护位(
vma->vm_page_prot)组合成一个 PTE 条目。 - 如果vma区是可写的,则给页表项添加允许写标志。将 PTE 条目的
Dirty位和Young位设置为1。 - 锁定
pte条目,防止同时更新和更多虚拟内存对物理内存映射 - pte条目存在的话,让mmu更新页表项,应该会清除tlb
- 检查给定的内存是否从用户拷贝过来的。如果从用户拷贝过来的内存不稳定,不用处理。
- 增加
mm_struct中匿名页的统计计数 - 对这个新页进行反向映射,主要工作是:设置此页的
_mapcount= 0,说明此页正在使用,但是是非共享的(>0是共享)。设置page->mapping最低位为1,page->mapping指向此vma->anon_vma,page->index存放此page在vma中的第几页。 - 通过判断,将页加入到活动lru缓存或者不能换出页的lru链表
- 将上面配置好的页表项写入页表
- 更新mmu的cache
do_anonymous_page首先判断一下匿名页是否是共享的,如果是共享的匿名映射,但是虚拟内存区域没有提供虚拟内存操作集合
就返回错误;然后判断一下pte页表是否存在,如果直接页表不存在,那么分配页表;
接下来判读缺页异常是由读操作触发的还是写操作触发的,如果是读操作触发的,生成特殊的页表项,映射到专用的零页,设置页表项后返回;如果是写操作触发的,需要初始化vma中的anon_vma_chain和anon_vma,分配物理页用于匿名映射,调用mk_pte函数生成页表项,设置页表项的脏标志位和写权限,设置页表项后返回。
小结
从以上的分析中,我们可以学习到关于常用的页表的宏的使用方法。Linux内核就是这样,你不光可以看到某个函数的实现,还可以看到某个函数的调用过程。所以,大家对某个函数有疑问的时候,可以顺着这样的思路去学习。
ARM32页表和Linux页表那些奇葩的地方
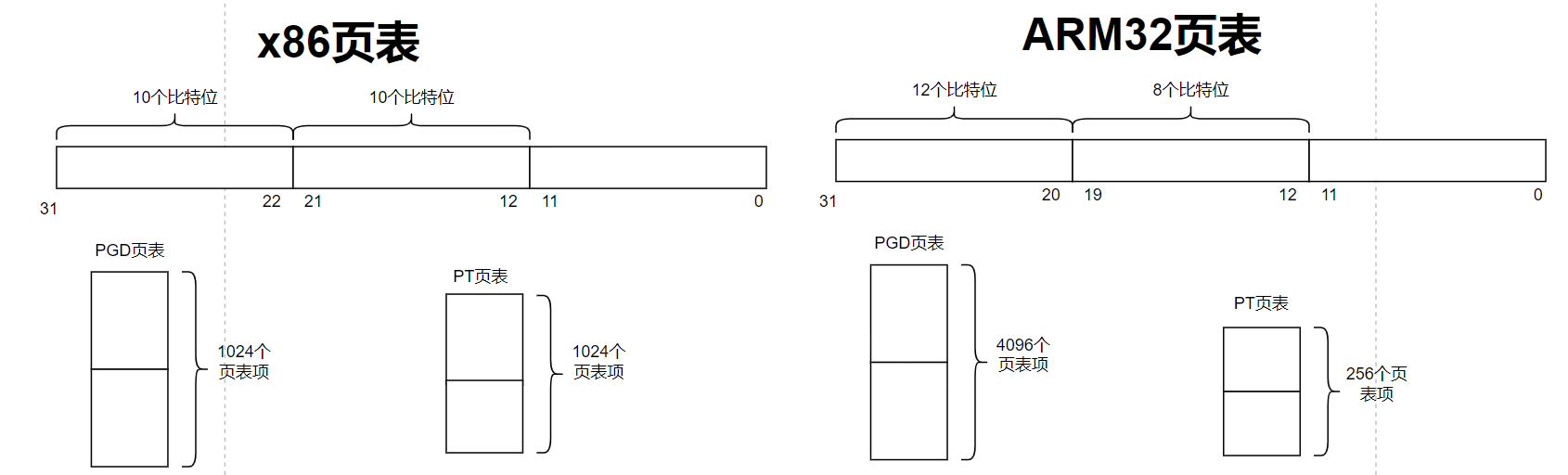
ARM32硬件页表中PGD页目录项PGD是从20位开始的,但是为何头文件定义是从21位开始?
历史原因:Linux最初是基于x86的体系结构设计的,因此Linux内核很多的头文件的定义都是基于x86的,特别是关于PTE页表项里面的很多比特位的定义。因此ARM在移植到Linux时只能参考x86版本的Linux内核的实现。
X86的PGD是从bit22 ~ bit31,总共10bit位,1024页表项。PT页表从bit12 ~ bit 21 ,总共 10 bit位,1024页表项。
ARM的PGD是从bit20 ~ bit31,总共12bit, 4096页表项。PT域从bit12 ~ bit 19,总共8bit,2556页表项。
X86和ARM页表最大的差异在于PTE页表内容的不同。
Linux内核版本的PTE比特位的定义
/** "Linux" PTE definitions for LPAE.** These bits overlap with the hardware bits but the naming is preserved for* consistency with the classic page table format.*/
#define L_PTE_VALID (_AT(pteval_t, 1) << 0) /* Valid */
#define L_PTE_PRESENT (_AT(pteval_t, 3) << 0) /* Present */
#define L_PTE_USER (_AT(pteval_t, 1) << 6) /* AP[1] */
#define L_PTE_SHARED (_AT(pteval_t, 3) << 8) /* SH[1:0], inner shareable */
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 10) /* AF */
#define L_PTE_XN (_AT(pteval_t, 1) << 54) /* XN */
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 55)
#define L_PTE_SPECIAL (_AT(pteval_t, 1) << 56)
#define L_PTE_NONE (_AT(pteval_t, 1) << 57) /* PROT_NONE */
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 58) /* READ ONLY */#define L_PMD_SECT_VALID (_AT(pmdval_t, 1) << 0)
#define L_PMD_SECT_DIRTY (_AT(pmdval_t, 1) << 55)
#define L_PMD_SECT_NONE (_AT(pmdval_t, 1) << 57)
#define L_PMD_SECT_RDONLY (_AT(pteval_t, 1) << 58)
ARM32的PTE比特位的定义
/** - extended small page/tiny page*/
#define PTE_EXT_XN (_AT(pteval_t, 1) << 0) /* v6 */
#define PTE_EXT_AP_MASK (_AT(pteval_t, 3) << 4)
#define PTE_EXT_AP0 (_AT(pteval_t, 1) << 4)
#define PTE_EXT_AP1 (_AT(pteval_t, 2) << 4)
#define PTE_EXT_AP_UNO_SRO (_AT(pteval_t, 0) << 4)
#define PTE_EXT_AP_UNO_SRW (PTE_EXT_AP0)
#define PTE_EXT_AP_URO_SRW (PTE_EXT_AP1)
#define PTE_EXT_AP_URW_SRW (PTE_EXT_AP1|PTE_EXT_AP0)
#define PTE_EXT_TEX(x) (_AT(pteval_t, (x)) << 6) /* v5 */
#define PTE_EXT_APX (_AT(pteval_t, 1) << 9) /* v6 */
#define PTE_EXT_COHERENT (_AT(pteval_t, 1) << 9) /* XScale3 */
#define PTE_EXT_SHARED (_AT(pteval_t, 1) << 10) /* v6 */
#define PTE_EXT_NG (_AT(pteval_t, 1) << 11) /* v6 */
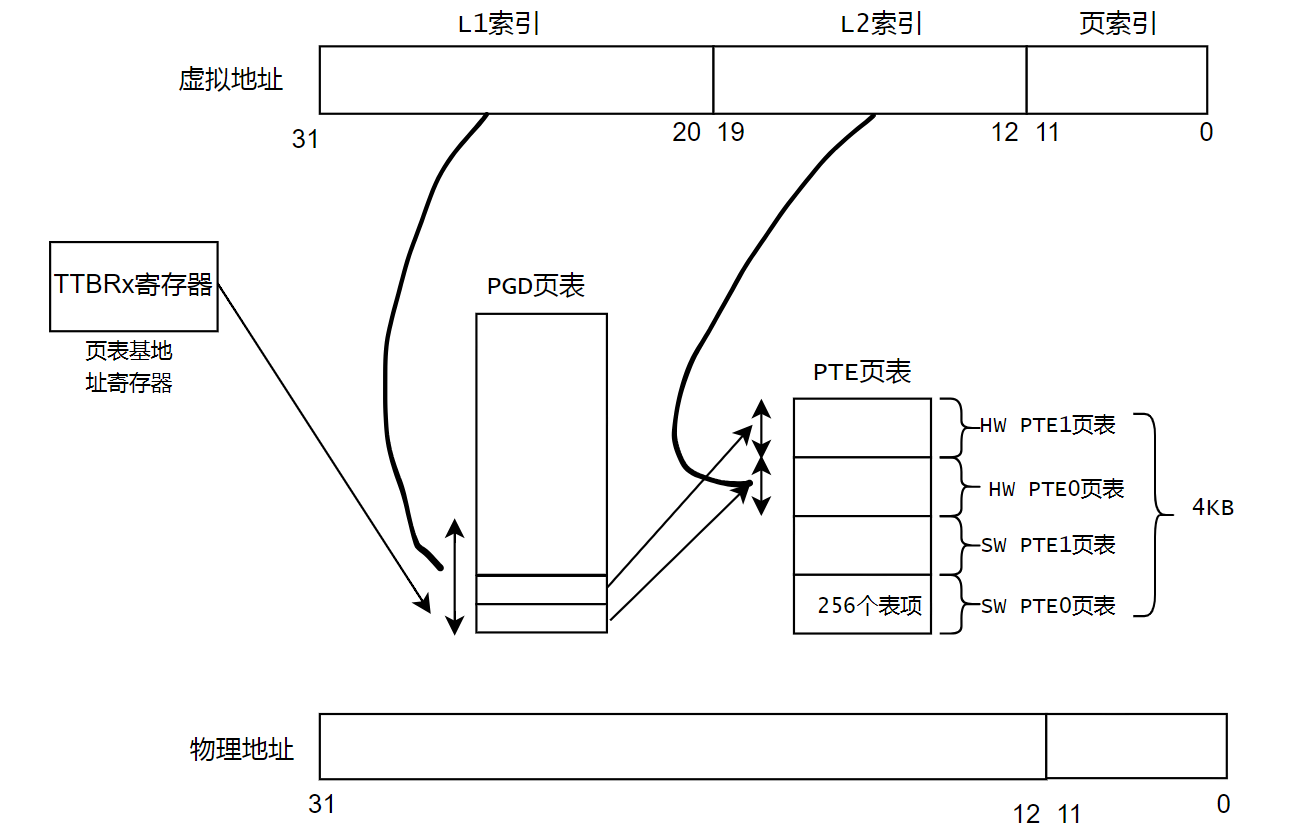
那X86和ARM的页表差距这么大,软件怎么设计呢?Linux内核的内存管理已经适配了X86的页表项,我们可以通过软件适配的办法来解决这个问题。因此,ARM公司在移植该方案时提出了两套页表的方案。一套页表是为了迎合ARM硬件的真实页表,另一套页表是为了迎合Linux真实的页表。
对于PTE页表来说,一下子就多出了一套页表,一套页表256表项,每个表项占用4字节。为了软件实现的方便,软件会把两个页表合并成一个页表。4套页表正好占用256 * 4 * 4 = 4K的空间。因此,Linux实现的时候,就分配了一个page 来存放这些页表。
这一套方案的话,相当于每个PGD页表项有8字节,包含指向两套PTE页表项的entry。每4个字节指向一个物理的二级页表。
本文参考
奔跑吧Linux内核
http://www.wowotech.net/memory_management/mem_init_3.html
http://blog.chinaunix.net/uid-628190-id-5821835.html
https://blog.csdn.net/zhoutaopower/article/details/88940727
https://blog.csdn.net/zhoutaopower/article/details/88940727
https://zhuanlan.zhihu.com/p/543076384
https://blog.csdn.net/huyugv_830913/article/details/5884628
https://zhuanlan.zhihu.com/p/452139283
https://www.cnblogs.com/arnoldlu/p/8335508.html
https://www.cnblogs.com/tolimit/p/5398552.html
https://blog.csdn.net/weixin_42419952/article/details/124392825
https://blog.csdn.net/sinat_22338935/article/details/128899811
https://zhuanlan.zhihu.com/p/377905409
https://www.cnblogs.com/pwl999/p/15534986.html
相关文章:
【内存管理】页表映射
页表的一些术语 现在Linux内核中支持四级页表的映射,我们先看下内核中关于页表的一些术语: 全局目录项,PGD(Page Global Directory) 上级目录项,PUD(Page Upper Directory) 中间目…...
Cloudpods 强大的多云管理平台部署
简介 Cloudpods 是一款简单、可靠的企业IaaS资源管理软件。帮助未云化企业全面云化IDC物理资源,提升企业IT管理效率。 Cloudpods 帮助客户在一个地方管理所有云计算资源。统一管理异构IT基础设施资源,极大简化多云架构复杂度和难度,帮助企业…...

深度学习的可微渲染
深度学习的可微渲染 可微渲染(Differentiable Rendering)是深度学习领域的一个重要概念,它将传统的计算机图形学与深度学习结合起来,通过使渲染过程可微分(differentiable),以便于在深度学习模…...

CAS Server Restful接口实现后台认证
背景 对于一些比较复杂定制化登录页的情况下,之前提到过可以自定义修改使用CAS Server提供的登录页这种操作已经明显跟不上复杂定制场景了,所以CAS Server也提供了支持Restful接口,支持服务端后台登陆,对于复杂登陆场景时&#x…...
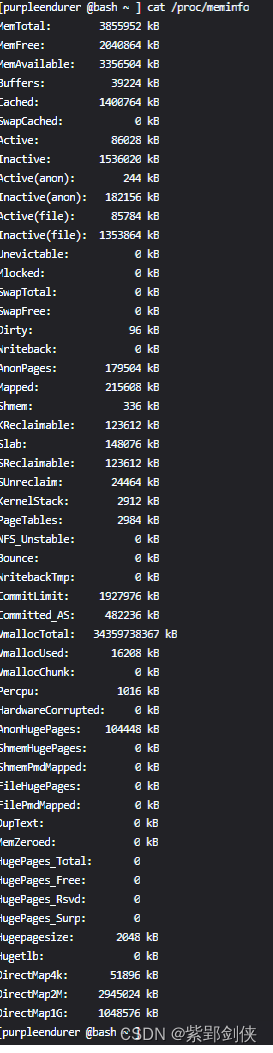
Linux shell编程学习笔记58:cat /proc/mem 获取系统内存信息
0 前言 在开展系统安全检查的过程中,除了收集cpu信息,我们还需要收集内存信息。在Linux中,获取内存信息的命令很多,这里我们着重研究 cat /proc/mem命令。 1 cat /proc/mem命令 /proc/meminfo 文件提供了有关系统内存的使用情况…...

【InternLM实战营第二期笔记】07:OpenCompass :是骡子是马,拉出来溜溜
文章目录 课程实操 课程 评测的意义是什么呢?我最近也在想。看到这节开头的内容后忽然有个顿悟:如果大模型最终也会变成一种基础工具(类比软件),稳定或可预期的效果需要先于用户感知构建出来,评测 case 就…...
matlab演示银河系转动动画
代码 function GalaxyRotationSimulation()% 参数设置num_stars 1000; % 恒星数量galaxy_radius 1; % 银河系半径rotation_speed 0.05; % 旋转速度% 生成银河系中的恒星分布theta 2 * pi * rand(num_stars, 1); % 角度r galaxy_radius * sqrt(rand(num_stars, 1)); % 半径…...

备战 清华大学 上机编程考试-冲刺前50%,倒数第5天
T1:多项式求和 小K最近刚刚习得了一种非常酷炫的多项式求和技巧,可以对某几类特殊的多项式进行运算。非常不幸的是,小K发现老师在布置作业时抄错了数据,导致一道题并不能用刚学的方法来解,于是希望你能帮忙写一个程序…...

leetCode127. 单词接龙
leetCode127. 单词接龙 // bfs 剪枝 class Solution { public:int ladderLength(string beginWord, string endWord, vector<string>& wordList) {// 1.将所有的单词放在set字段中unordered_set<string> s;for (auto & ele : wordList) s.insert(ele);//…...

进程概念(二)
目录 进程优先级基本概念查看系统进程PRI and NIPRI vs NI修改进程优先级的命令renice修改优先级进程其他概念 环境变量基本概念查看环境变量方法常见环境变量PATHHOMESHELL 查看环境变量环境变量相关的命令 环境变量特征命令行参数main函数中的俩个参数 argc argvmain函数的第…...

java程序100道01—20
1.用循环的嵌套,输出输出如下图形 * * * * * * * * * * * * * * * * * * * * * * * * * package Exercises.One_Hundred; public class Demo01 {public static void main(String[] args) {for(int i1;i<5;i){for(int j1;j<2*i-1;j){Sys…...

让GNSSRTK不再难【第二天-第7部分2】
状态更新计算过程: 计算卡尔曼增益: 根据预测的误差协方差矩阵 P k − P_k^- Pk− 和观测噪声协方差矩阵 R R R 计算卡尔曼增益 K k K_k Kk: K k P k − H T ( H P k − H T R ) − 1 K_k P_k^- H^T (H P_k^- H^T R)^{-1} KkPk…...

计算引擎:Flink核心概念
Apache Flink 是一个流处理框架,擅长处理实时数据流和批处理任务。Flink 提供了强大的功能来处理和分析大量数据。以下是 Flink 的核心概念: 1. DataStream 和 DataSet API DataStream API: 用于处理无界数据流,即不断生成和流动的数据。例如,传感器数据、日志等。DataSet…...
技术前沿 |【大模型InstructBLIP进行指令微调】
大模型InstructBLIP进行指令微调 一、引言二、InstructBLIP模型介绍三、指令微调训练通用视觉语言模型的应用潜力四、InstructBLIP的指令微调训练步骤五、实验结果与讨论六、结论与展望 一、引言 随着人工智能技术的快速发展,视觉语言模型(Vision-Langu…...

CSS-布局-flex
CSS3 新增了弹性盒子模型( Flexible Box 或 FlexBox ),是一种新的用于在 HTML 页面实现布局的方式。使得 HTML 页面适应不同尺寸的屏幕和不同的设备时,元素是可预测地运行。 基本概念 容器:使用 display:flex 或 display:inline-flex 声明的…...

「C系列」C 数组
文章目录 一、C 数组1. 声明数组2. 初始化数组3. 访问数组元素4. 数组越界5. 多维数组 二、C 操作数组的方法有哪些三、C 数组-应用场景1. 存储固定数量的数据2. 实现算法(如排序)3. 处理数据集合 四、相关链接 一、C 数组 在C语言中,数组是…...

Python框架scrapy有什么天赋异禀
Scrapy框架与一般的爬虫代码之间有几个显著的区别,这些差异主要体现在设计模式、代码结构、执行效率以及可扩展性等方面。下面是一些关键的不同点: 结构化与模块化: Scrapy:提供了高度结构化的框架,包括定义好的Spider…...

【ROS2大白话】四、ROS2非常简单的传参方式
系列文章目录 【ROS2大白话】一、ROS2 humble及cartorgrapher安装 【ROS2大白话】二、turtlebot3安装 【ROS2大白话】三、给turtlebot3安装realsense深度相机 【ROS2大白话】四、ROS2非常简单的传参方式 文章目录 系列文章目录前言一、launch文件传参的demo1. 编写launch.py文…...

浅谈mysql 的批量delete 和 使用in条件批量删除问题
在考虑这两个DELETE语句的性能时,我们需要考虑数据库如何执行这些查询以及它们背后可能涉及的索引和数据结构。 1.执行多个单独的DELETE语句: DELETE FROM a WHERE b 1 AND c 1; ... DELETE FROM a WHERE b 1000 AND c 1000; 这种方法的优点是每…...

【Spring Boot】过滤敏感词的两种实现
文章目录 项目场景前置知识前缀树 实现方式解决方案一:读取敏感词文件生成前缀树构建敏感词过滤器1. 导入敏感词文件 src/main/resources/sensitive_words.txt2. 构建敏感词过滤器 SensitiveFilter3. 测试与使用 解决方案二:使用第三方插件 houbb/sensit…...

基于FET6254-C多核异构处理器的智能运动控制系统设计与实践
1. 项目概述:当运动控制遇上嵌入式智能最近在做一个智能运动控制的项目,从传统的PLC方案转向了更灵活、更智能的嵌入式平台。选型过程中,飞凌嵌入式的FET6254-C核心板进入了我的视野,经过一番深度评估和实际测试,它确实…...

企业微信多账号协同管理方案:矩阵如何统一管理?
账号越来越多、运营越来越乱?通过企业微信 API,实现多账号统一管理与自动化调度。很多私域团队在业务增长后,都会开始运营多个企业微信账号。 但账号一多,人工切换、消息管理、客户分配都会变得非常混乱。QiWe 开放平台通过标准化…...

Horos:免费开源医学影像软件,3D医疗图像处理的终极指南
Horos:免费开源医学影像软件,3D医疗图像处理的终极指南 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos…...

从动态规划到最优策略:基于模型的强化学习核心算法剖析
1. 从动态规划到强化学习的桥梁 动态规划(Dynamic Programming,DP)是解决序列决策问题的经典方法,而强化学习(Reinforcement Learning,RL)则可以看作是在未知环境下的动态规划。我第一次接触这个…...

别再手动整理了!用这个油猴脚本,5分钟搞定百度网盘群文件目录导出
百度网盘群文件目录导出神器:油猴脚本极简操作指南 1. 为什么需要群文件目录导出工具 百度网盘作为国内主流的云存储服务,群组文件共享功能被广泛用于团队协作、资源分发等场景。但官方界面存在一个明显的痛点:当群文件数量达到数百甚至上千时…...

Ubuntu 22.04 下配置 Arduino IDE 2.x:从安装到第三方库的完整避坑指南
1. 准备工作:下载Arduino IDE 2.x 在Ubuntu 22.04上配置Arduino开发环境,第一步自然是获取官方IDE。我推荐直接从Arduino官网下载最新版本,避免使用老旧软件包带来的兼容性问题。打开浏览器访问arduino.cc/en/software,你会看到两…...

Codex 上下文提供详解与操作指南
1. 文档目标 这份文档解决的是一个非常实际的问题: 怎么给 Codex 足够完整的上下文什么信息是必须给的,什么信息是可选但高价值的怎样让 Codex 在一次任务里快速进入正确状态怎样避免“我已经说了很多,但结果还是不对”怎样把上下文提供方式变…...

智能定时任务管理:用自然语言替代Crontab,TickGPTick项目实践
1. 项目概述:一个能“听懂”你需求的定时任务管理器最近在折腾一个自动化脚本项目时,我又一次陷入了“定时任务”的泥潭。相信很多开发者都有同感:写个脚本容易,但想让它定时、可靠、有状态地跑起来,总得和 crontab、s…...
)
别再死记硬背了!用Python脚本帮你自动生成CANopen PDO映射表(附源码)
用Python自动化生成CANopen PDO映射表的工程实践 每次面对密密麻麻的CANopen设备描述文件时,你是否也经历过这样的场景:深夜加班核对PDO映射参数,反复翻阅数百页的EDS文档,稍不留神就会把0x1800错配成0x1801。这种低效的手工操作不…...

量化交易自动化框架设计:从API客户端到策略回测的工程实践
1. 项目概述与核心价值最近在量化交易和自动化策略开发的圈子里,一个名为cbonoz/kalshi-skill的项目引起了我的注意。乍一看,这像是一个针对特定交易平台 Kalshi 的技能或工具包。对于不熟悉的朋友,Kalshi 是一个新兴的事件合约交易平台&…...