LLM大语言模型(十六):最新开源 GLM4-9B 本地部署,带不动,根本带不动
目录
前言
本机环境
GLM4代码库下载
模型文件下载:文件很大
修改为从本地模型文件启动
启动模型cli对话demo
慢,巨慢,一个字一个字的蹦
GPU资源使用情况
GLM3资源使用情况对比

前言
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。
除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。
本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。
我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 GLM-4-9B-Chat-1M 模型和基于 GLM-4-9B 的多模态模型 GLM-4V-9B。GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
本机环境
OS:Windows
CPU:AMD Ryzen 5 3600X 6-Core Processor
Mem:32GB
GPU:RTX 4060Ti 16G
GLM4代码库下载
参考:LLM大语言模型(一):ChatGLM3-6B本地部署_llm3 部署-CSDN博客
# 下载代码库
https://github.com/THUDM/GLM-4.git模型文件下载:文件很大
建议从modelscope下载模型,这样就不用担心网络问题了。
模型链接如下:
glm-4-9b-chat汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。![]() https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/files
https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/files
git lfs install # 以安装则忽略
git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git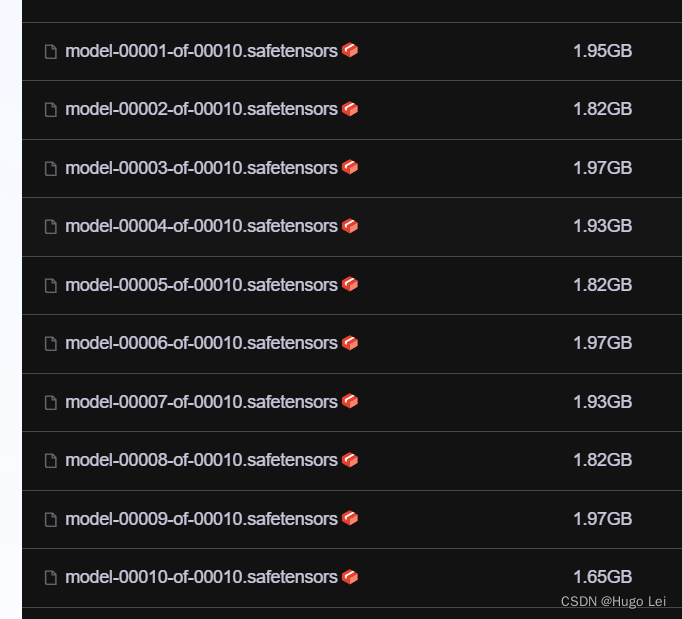
做好心理准备:接近20G(我的带宽只有300Mbps~~)
修改为从本地模型文件启动
修改此文件basic_demo/trans_cli_demo.py
修改这一行:
MODEL_PATH = os.environ.get('MODEL_PATH', 'D:\github\glm-4-9b-chat') 该为你下载的模型文件夹
"""
This script creates a CLI demo with transformers backend for the glm-4-9b model,
allowing users to interact with the model through a command-line interface.Usage:
- Run the script to start the CLI demo.
- Interact with the model by typing questions and receiving responses.Note: The script includes a modification to handle markdown to plain text conversion,
ensuring that the CLI interface displays formatted text correctly.
"""import os
import torch
from threading import Thread
from typing import Union
from pathlib import Path
from peft import AutoPeftModelForCausalLM, PeftModelForCausalLM
from transformers import (AutoModelForCausalLM,AutoTokenizer,PreTrainedModel,PreTrainedTokenizer,PreTrainedTokenizerFast,StoppingCriteria,StoppingCriteriaList,TextIteratorStreamer
)ModelType = Union[PreTrainedModel, PeftModelForCausalLM]
TokenizerType = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]# 改为你下载的模型文件夹
MODEL_PATH = os.environ.get('MODEL_PATH', 'D:\github\glm-4-9b-chat')def load_model_and_tokenizer(model_dir: Union[str, Path], trust_remote_code: bool = True
) -> tuple[ModelType, TokenizerType]:model_dir = Path(model_dir).expanduser().resolve()if (model_dir / 'adapter_config.json').exists():model = AutoPeftModelForCausalLM.from_pretrained(model_dir, trust_remote_code=trust_remote_code, device_map='auto')tokenizer_dir = model.peft_config['default'].base_model_name_or_pathelse:model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=trust_remote_code, device_map='auto')tokenizer_dir = model_dirtokenizer = AutoTokenizer.from_pretrained(tokenizer_dir, trust_remote_code=trust_remote_code, encode_special_tokens=True, use_fast=False)return model, tokenizermodel, tokenizer = load_model_and_tokenizer(MODEL_PATH, trust_remote_code=True)class StopOnTokens(StoppingCriteria):def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:stop_ids = model.config.eos_token_idfor stop_id in stop_ids:if input_ids[0][-1] == stop_id:return Truereturn Falseif __name__ == "__main__":history = []max_length = 8192top_p = 0.8temperature = 0.6stop = StopOnTokens()print("Welcome to the GLM-4-9B CLI chat. Type your messages below.")while True:user_input = input("\nYou: ")if user_input.lower() in ["exit", "quit"]:breakhistory.append([user_input, ""])messages = []for idx, (user_msg, model_msg) in enumerate(history):if idx == len(history) - 1 and not model_msg:messages.append({"role": "user", "content": user_msg})breakif user_msg:messages.append({"role": "user", "content": user_msg})if model_msg:messages.append({"role": "assistant", "content": model_msg})model_inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_tensors="pt").to(model.device)streamer = TextIteratorStreamer(tokenizer=tokenizer,timeout=60,skip_prompt=True,skip_special_tokens=True)generate_kwargs = {"input_ids": model_inputs,"streamer": streamer,"max_new_tokens": max_length,"do_sample": True,"top_p": top_p,"temperature": temperature,"stopping_criteria": StoppingCriteriaList([stop]),"repetition_penalty": 1.2,"eos_token_id": model.config.eos_token_id,}t = Thread(target=model.generate, kwargs=generate_kwargs)t.start()print("GLM-4:", end="", flush=True)for new_token in streamer:if new_token:print(new_token, end="", flush=True)history[-1][1] += new_tokenhistory[-1][1] = history[-1][1].strip()
启动模型cli对话demo
运行该py文件即可,效果如下:
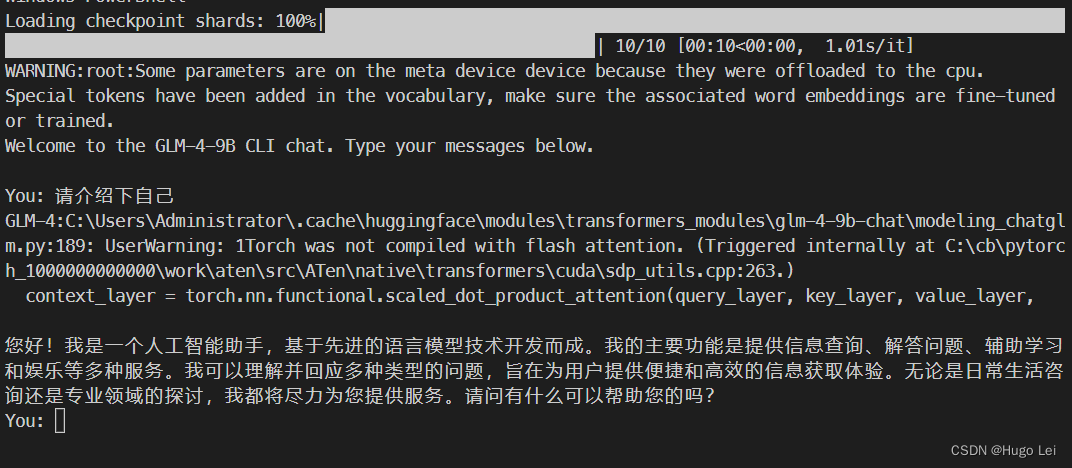
模型运行时会报个warning:
C:\Users\Administrator\.cache\huggingface\modules\transformers_modules\glm-4-9b-chat\modeling_chatglm.pm.py:189: UserWarning: 1Torch was not compiled with flash attention. (Triggered internally at C:\cb\pytorc000h_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:263.)
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
不过也没影响运行。
慢,巨慢,一个字一个字的蹦
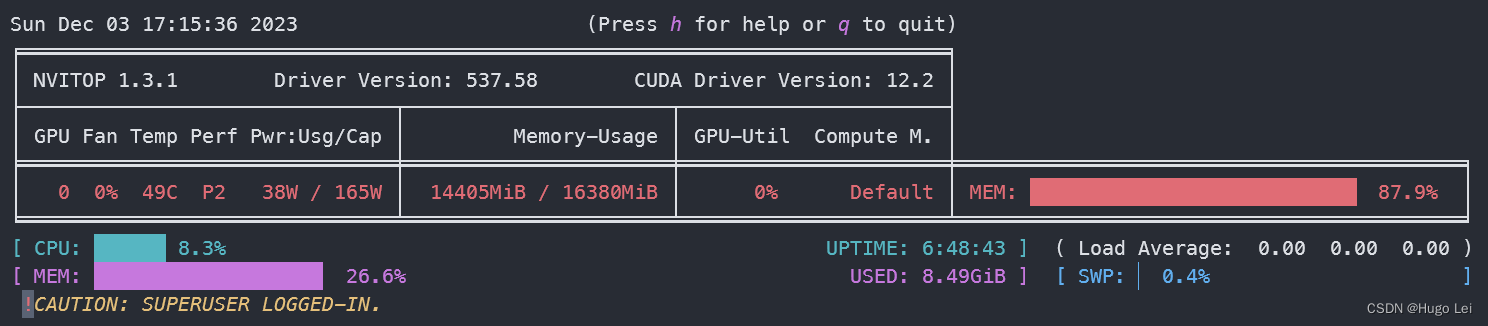
GPU资源使用情况
- 16G显存,使用率90%+
- 内存使用16G,50%

GLM3资源使用情况对比
相关文章:
LLM大语言模型(十六):最新开源 GLM4-9B 本地部署,带不动,根本带不动
目录 前言 本机环境 GLM4代码库下载 模型文件下载:文件很大 修改为从本地模型文件启动 启动模型cli对话demo 慢,巨慢,一个字一个字的蹦 GPU资源使用情况 GLM3资源使用情况对比 前言 GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 …...

【JVM】JVM 的内存区域
Java虚拟机(JVM)在执行Java程序时,将其运行时数据划分到若干不同的内存区域。这些内存区域的管理对Java应用程序的性能和稳定性有着重要影响。JVM的内存区域主要包括以下几部分: 方法区(Method Area)&#…...

intel新CPU性能提升68%!却在内存上违反祖训
前几天的台北电脑展「Computex」,各家都拿出了看家本领。 老朋友 AMD 在会展上发布了最新的锐龙 9000 系列和自己家移动处理器 HX AI 系列,IPC 和能效都取得了不错的进步。 当然隔壁蓝厂 intel 也没闲着,当即就掏出了下一代的低功耗移动端处…...
stm32MP135裸机编程:修改官方GPIO例程在DDR中点亮第一颗LED灯
0 参考资料 轻松使用STM32MP13x - 如MCU般在cortex A核上裸跑应用程序.pdf 正点原子stm32mp135开发板&原理图 STM32Cube_FW_MP13_V1.1.0 STM32CubeIDE v1.151 需要修改那些地方 1.1 修改LED引脚 本例使用开发板的PI3引脚链接的LED作为我们点亮的第一颗LED灯,…...
探索乡村振兴新模式:发挥科技创新在乡村振兴中的引领作用,构建智慧农业体系,助力美丽乡村建设
随着科技的不断进步,乡村振兴工作正迎来前所未有的发展机遇。科技创新作为推动社会发展的重要力量,在乡村振兴中发挥着越来越重要的引领作用。本文旨在探讨如何发挥科技创新在乡村振兴中的引领作用,通过构建智慧农业体系,助力美丽…...
机器学习笔记:focal loss
1 介绍 Focal Loss 是一种在类别不平衡的情况下改善模型性能的损失函数最初在 2017 年的论文《Focal Loss for Dense Object Detection》中提出这种损失函数主要用于解决在有挑战性的对象检测任务中,易分类的负样本占据主导地位的问题,从而导致模型难以…...

Python编程:解锁超能力,开挂人生!
在当今数字化时代,编程技能变得日益重要,而Python作为一门功能强大且易于学习的编程语言,已经成为许多人的首选。掌握Python,确实可以让你在技术领域如鱼得水,仿佛拥有了超能力一般。 Python的简易语法和丰富的库资源…...

TSINGSEE青犀视频:城市道路积水智能监管,智慧城市的守护者
随着城市化进程的加快,城市道路网络日益复杂,尤其在夏季,由于暴雨频发,道路积水问题成为影响城市交通和市民生活的重要因素之一。传统的道路积水监测方式往往依赖于人工巡逻和简单的监控设备,这些方法存在效率低下、响…...

几款免费又好用的项目管理工具(甘特图)
选择甘特图工具时,我们不仅要考虑工具的基本功能,还要考虑其易用性、团队协作能力、定制性以及与其他软件的集成能力。以下是几款好用的甘特图工具及它们的优点和不足,帮助你来选择适合自己的工具: 1、进度猫 特点: 任…...

落地台灯什么牌子的比较好?五款适合学生使用的大路灯分享
以往只知道养孩子难,但到底有多难,心里确实没有个切实的预期,但随着我家孩子越长越大,我才知道原来想要把孩子的身心健康照顾好到底是有多难!吃、穿、住、行无一不要精心挑选,就是为了能给他营造一个更好的…...

(免费领源码)基于 node.js#vue#mysql的网上游戏商城35112-计算机毕业设计项目选题推荐
摘 要 本论文主要论述了如何使用node.js语言开发一个基于vue的网上游戏商城,本系统将严格按照软件开发流程进行各个阶段的工作,本系统采用的数据库是Mysql,使用node.js的koa技术技术构建的一个管理系统,实现了本系统的全部功能。在…...

[2024-06]-[大模型]-[Ollama] 0-相关命令
常用的ollama命令[持续更新中] ollama更新: curl https://ollama.ai/install.sh |sh带着flash attention启动: OLLAMA_FLASH_ATTENTION1 ollama serve停止ollama服务: sudo systemctl stop ollama note:目前遇到sudo systemctl …...

Image组件无法设置长按事件
最近对image 设置长按事件,通过api发现有个长按事件 LongPressGesture,但是使用了长按没反应,于是看文档,文档描述如下: 当组件默认支持可拖拽时,如Text、TextInput、TextArea、HyperLink、Image和RichEd…...
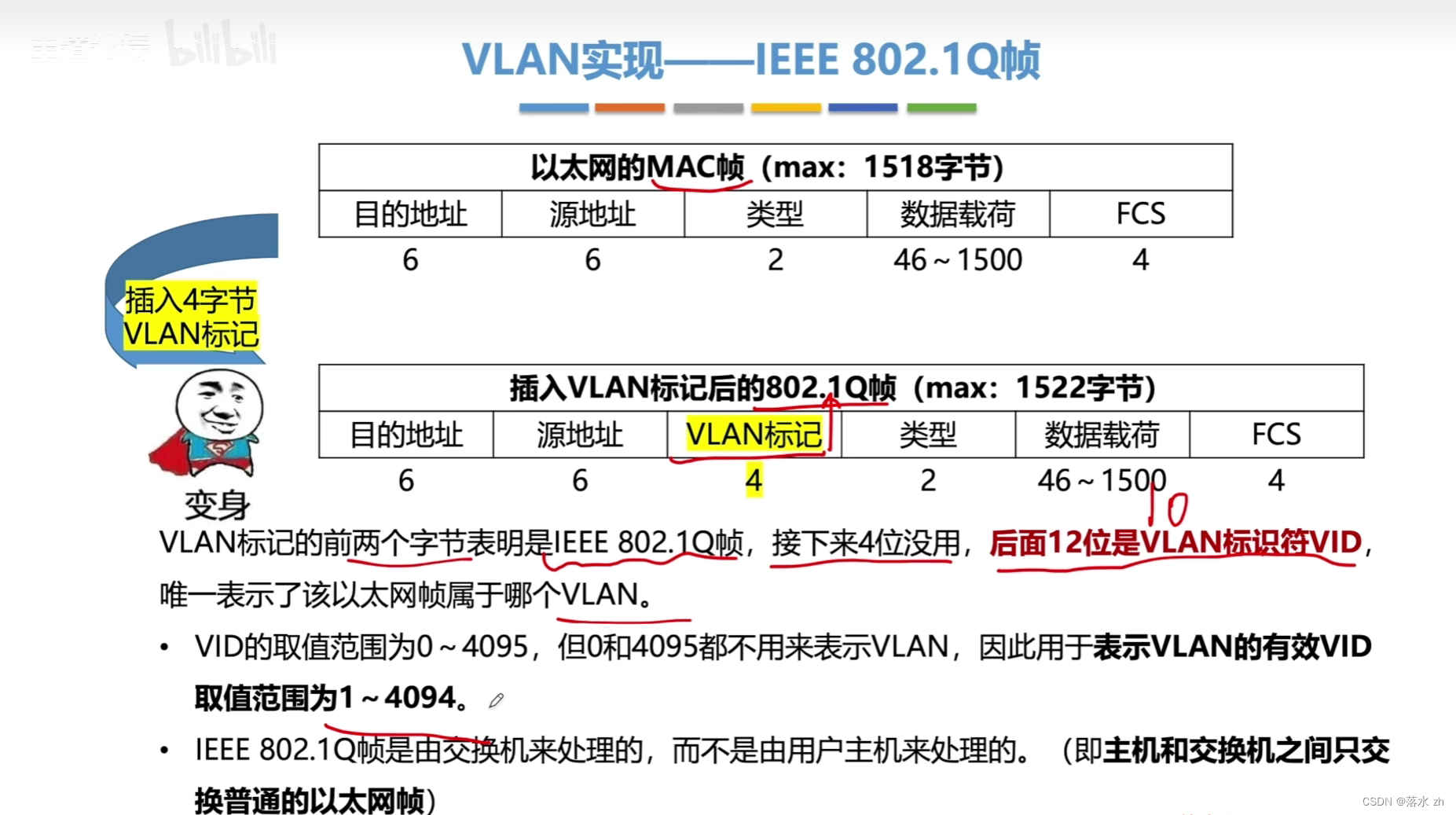
计算机网络 —— 数据链路层(VLAN)
计算机网络 —— 数据链路层(VLAN) 什么是VLAN为什么要有VLANVLAN如何实现IEEE 802.1Q 我们今天来看VLAN: 什么是VLAN VLAN(Virtual Local Area Network,虚拟局域网)是一种网络技术,它将一个物…...

Redis基本操作介绍
1. 安装与启动 安装:Redis支持多种操作系统,包括Linux、Windows等。从Redis官网下载相应的安装包,并按照系统要求进行安装。启动: Linux系统:在终端中,进入Redis的安装目录,运行redis-server命…...

Unity3d使用3D WebView for Windows and macOS打开全景网页(720云)操作问题记录
问题描述 使用Unity3d内嵌网页的形式打开720云中的全景图这个功能,使用的是3D WebView for Windows and macOS插件,720云的全景图在浏览器上的操作是滑动鼠标滚轮推远/拉近全景图,鼠标左键拖拽网页可以旋转全景图内容。网页的打开过程是正常…...
把文件从一台linux机器上传到另一台linux机器上
文章目录 1,第一种情况1.1 先测试2台机器是否可以互相通信1.2 对整个文件夹里面的所有内容进行传输的命令1.3 检查结果 2,第二种情况2.1,单个文件传输的命令 1,第一种情况 我这里有2台linux机器, 机器A:19…...

WT32-ETH01作为TCP Server进行通讯
目录 模块简介WT32-ETH01作为TCP Server设置W5500作为TCP Client设置连接并进行通讯总结 模块简介 WT32-ETH01网关主要功能特点: 采用双核Xtensa⑧32-bit LX6 MCU.集成SPI flash 32Mbit\ SRAM 520KB 支持TCP Server. TCP Client, UDP Server. UDP Client工作模式 支持串口、wi…...

mvn install -DskipTests
mvn install -DskipTests mvn install -DskipTests 不用做测试的打包代码...
Lua搭建网站后台教程
本文讲解如何使用二进制发布包和FastWeb网站管理工具搭建站点 FastWeb网站管理工具 使用该工具可快速在Windows平台部署。支持官方或三方模块的自动安装、日志调试、版本更新等。 1、下载最新版本压缩包 2、解压到任意目录(建议英文) 3、运行 ①点击 [设置]->[安装] 部…...

解放原神玩家生产力的开源工具箱:Snap.Hutao如何用本地化数据处理重塑游戏体验
解放原神玩家生产力的开源工具箱:Snap.Hutao如何用本地化数据处理重塑游戏体验 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitH…...
)
485温湿度传感器Modbus通信避坑指南:从波特率匹配到报文解析(以4800波特率为例)
485温湿度传感器Modbus通信实战:从硬件对接到数据解析全流程 工业现场的数据采集往往从一串看似简单的十六进制代码开始。当您第一次将485温湿度传感器接入系统时,可能会遇到这样的场景:硬件连接无误,指示灯正常闪烁,但…...

图表数据提取神器:WebPlotDigitizer让科研图表重获新生
图表数据提取神器:WebPlotDigitizer让科研图表重获新生 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 你是否曾面对论文中…...

NHSE动物森友会存档编辑器完整指南:打造梦想岛屿的终极工具
NHSE动物森友会存档编辑器完整指南:打造梦想岛屿的终极工具 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》中收集稀有物品而烦恼吗࿱…...

MoviePilot连接TMDB异常的终极诊断指南:5步快速排查与完整解决方案
MoviePilot连接TMDB异常的终极诊断指南:5步快速排查与完整解决方案 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为NAS媒体库自动化管理工具,其核心功能依赖TheMov…...

ncmdump终极指南:3步快速解锁网易云音乐NCM加密文件的完整免费解决方案
ncmdump终极指南:3步快速解锁网易云音乐NCM加密文件的完整免费解决方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?ncmdump这款强大的NCM解密工…...

基于视觉大模型的GUI自动化:从原理到实践
1. 项目概述:当GUI自动化遇见视觉大模型 最近在折腾自动化测试和RPA(机器人流程自动化)的时候,我遇到了一个老生常谈但又极其棘手的问题:如何稳定、高效地识别和操作那些没有标准控件标识的图形界面元素?传…...

ARM ETMv4跟踪寄存器架构与调试实践
1. ARM ETMv4 跟踪寄存器架构概述ARM嵌入式跟踪宏单元(ETM)是处理器调试架构中的关键组件,ETMv4作为其第四代架构,提供了更强大的指令和数据跟踪能力。与传统的断点调试不同,ETM采用实时跟踪技术,能够在不中断处理器运行的情况下&…...

S7-1500 PLC做高速数据采集?一个32位微秒时间戳的完整实现与避坑指南
S7-1500 PLC微秒级时间戳工程实践:从硬件同步到数据拼接的完整方案 在工业自动化领域,毫秒级响应已是基础要求,而微秒级精度正成为高端装备的标配。当一台数控机床以8000转/分钟的速度运行时,每个刀具接触工件的瞬间都需被精确记录…...

子网掩码实战:从原理到网络规划的深度解析
1. 子网掩码的核心原理 第一次接触子网掩码时,我也被那一串数字搞得晕头转向。直到有次公司网络改造,亲眼看到老工程师用子网划分解决了IP地址不足的问题,才真正明白它的价值。简单来说,子网掩码就像邮局的邮政编码系统 - 它告诉网…...