机器学习常见知识点 1:Baggin集成学习技术和随机森林
文章目录
- 1、集成学习
- a.Bagging
- Bagging的工作原理
- 1. 自助采样(Bootstrap Sampling)
- 2. 训练多个基学习器
- 3. 聚合预测
- Bagging的优点
- Bagging的缺点
- 应用场景
- b.Boosting
- 2、决策树
- 3、随机森林
- 随机森林的核心概念
- 1. 集成学习
- 2. 决策树
- 构建随机森林的步骤
- 1. 自助采样(Bootstrap sampling)
- 2. 训练多个决策树
- 3. 聚合预测
- 随机森林的随机性的两个体现
- 随机森林的优势
记忆名词:
Bagging、自助采样
随机森林、基模型、集成学习、特征随机性
1、集成学习
集成学习是一种机器学习范式,它通过构建并组合多个学习器来提高预测性能。集成学习中最主要和最常用的两种技术是 Bagging 和 Boosting。不过,除了这两种,还有另一种较为常见的集成方法称为 Stacking。下面对这三种主要的集成学习技术的区别进行简要介绍:
主要区别:
- Bagging:独立并行地训练每个基模型,并且每个模型都得到同等的权重。目标是减少方差,提高稳定性。这些基学习器通常是同一种类型的机器学习算法,如决策树是Bagging中最常用的基学习器。
- Boosting:顺序训练每个基模型,每个模型学习前一个模型的残差。目标是减少偏差,提高预测的准确性。
- Stacking:利用不同模型的多样性,通过一个高层模型来整合各个基模型的输出。目标是利用不同模型的优势,提高整体性能。
在实际应用中,选择哪一种集成技术取决于特定任务的需求、数据特性以及所追求的性能指标。
a.Bagging
Bagging(自助聚合) 是一种集成学习技术,用于提高机器学习算法的稳定性和准确性,尤其是对于决策树模型。全称为“Bootstrap Aggregating”,Bagging通过组合多个模型的预测结果来减少方差,通常能有效防止过拟合。
Bagging的工作原理
1. 自助采样(Bootstrap Sampling)
Bagging的核心是自助采样,这是一种随机采样技术。从原始数据集中随机选择样本,允许重复,即同一个样本可以被选中多次。这样,每次采样都能生成一个大小等于原数据集的新数据集,但由于有放回的采样方式,这些新数据集彼此之间会有所不同。
- 相当于对每个基模型都有一个原数据集大小的数据集,这个数据集是在原数据集中有放回地随机抽取的。每个基模型对原数据集有不同视角,减少了过拟合的现象。
2. 训练多个基学习器
使用自助采样得到的每个独立的数据子集训练一个基学习器。这些基学习器通常是同一种类型的机器学习算法,如决策树是Bagging中最常用的基学习器。
3. 聚合预测
当所有的基学习器都被训练完成后,它们的预测将被组合起来形成最终的预测结果。对于分类问题,最常用的聚合方法是投票机制(多数投票);对于回归问题,则通常采用平均预测。
Bagging的优点
- 减少方差:通过在不同的数据子集上训练,并聚合多个模型的预测,Bagging能显著减少预测的方差,增强模型的泛化能力。
- 避免过拟合:相较于单个模型,Bagging的集成方法能更好地避免过拟合问题。
- 并行化:由于每个基模型的训练是独立的,Bagging方法非常适合并行处理,提高训练效率。
Bagging的缺点
- 增加计算负担:需要训练多个基学习器,对计算资源的需求较高。
- 模型解释性降低:虽然单个决策树等基学习器容易理解,但整个Bagging模型由于涉及多个基学习器,因此整体解释性不如单个模型。
应用场景
Bagging是随机森林的基础,也可以用于其他类型的模型。除了决策树外,它也可以用于神经网络、线性回归等多种机器学习算法中,尤其是那些倾向于对训练数据过拟合的算法。
总之,Bagging是一个强大的集成技术,能有效提升模型在各种数据集上的表现,尤其是在处理那些具有高方差的复杂数据集时。
b.Boosting
将在讲述XGB和LGB时进行解释。
2、决策树
看纯文字的话,决策树这块是最难理解的,因此可以结合其他资料
花哩花哩:【五分钟机器学习】可视化的决策过程:决策树 Decision Tree
机器学习常见知识点 2:决策树
3、随机森林
哔哩哔哩:【五分钟机器学习】随机森林(RandomForest):看我以弱搏强
随机森林是一种流行且强大的机器学习方法,用于分类和回归任务。它属于集成学习领域,具体来说是基于决策树的Bagging(自助聚合)技术。随机森林通过构建多个决策树并结合它们的预测结果来提高整体模型的准确性和鲁棒性。
- 根据自助聚合集成学习方法(Bagging),随机森林就相当于是Bagging方法中,基模型是决策树的Bagging方法。不过值得注意的是,随机森林对决策树实现的不同之处
随机森林的核心概念
1. 集成学习
随机森林基于集成学习原理,即将多个学习器结合起来,以期望得到比单一模型更好的预测效果。集成方法通常比单一模型更稳健,因为它们汇集了多个模型的决策,从而减少了过拟合的风险。
2. 决策树
随机森林的基本构件是决策树,这是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,而每个叶节点代表一种类别(在分类问题中)或一个连续值(在回归问题中)。决策树容易理解和实现,但单独使用时容易过拟合。
构建随机森林的步骤
先设置超参数,即多少棵树,分几层
1. 自助采样(Bootstrap sampling)
随机森林中的每个决策树都是通过从原始训练数据集中进行随机有放回抽样(即自助采样)来构建的子集。这意味着同一数据点可以在同一个树的训练数据中多次出现。
2. 训练多个决策树
使用自助采样得到的每个子集训练一个决策树。在构建这些决策树时,随机森林引入了另一个随机性层次:在每个分裂点,不是查看所有特征以找到最佳分裂,而是随机选择特征的一个子集,并基于这个子集找到最佳分裂。这一策略被称为特征随机性(feature bagging)。
3. 聚合预测
一旦所有决策树都被训练完成,它们的预测将被组合起来形成模型的最终输出。在分类任务中,这通常通过多数投票机制完成(即森林中的大多数树选择的类别成为最终预测)。在回归任务中,通常取所有树的预测输出的平均值。
随机森林的随机性的两个体现
- 自助采样(数据级的随机性):自助采样来为每棵树生成不同的训练子集。
- 特征随机性(特征级的随机性):在进行每次分裂时,不是从所有特征中选择最优分裂特征,而是从随机选定的特征子集中选择最优分裂特征。
随机森林的优势
- 准确性高:通过结合多个决策树的预测,随机森林通常能达到很高的准确率。
- 对于过拟合的鲁棒性:相对于单个决策树,随机森林更不容易过拟合。
- 可用于特征选择:随机森林能够提供关于特征重要性的洞见,这对于理解数据中哪些特征是影响结果的关键因素非常有用。
- 灵活性:能处理分类和回归任务,同时不需要特征缩放,可以很好地处理二元特征、连续特征以及缺失数据。
随机森林是一种基于决策树的Bagging集成学习技术,一般情况下它通过自助采样为每颗决策树选择样本空间,在训练每颗决策树的时候,它也具有随机性,即它随机选择特征子空间,在这个特征子空间里使用基尼不准度的方法选取最优特征进行决策树节点分裂。
- 总的来说随机森林的随机性体现在两个方面,第一个是在样本空间的选择上,第二个是在决策树分裂时特征空间的选择上
扩展一下:
袋外误差(OOB)估计:由于自助采样,某些实例可能不会被包括在某棵树的训练集中。这些袋外实例可以用作验证集,提供模型性能的无偏估计。
相关文章:

机器学习常见知识点 1:Baggin集成学习技术和随机森林
文章目录 1、集成学习a.BaggingBagging的工作原理1. 自助采样(Bootstrap Sampling)2. 训练多个基学习器3. 聚合预测 Bagging的优点Bagging的缺点应用场景 b.Boosting 2、决策树3、随机森林随机森林的核心概念1. 集成学习2. 决策树 构建随机森林的步骤1. …...

容器(Docker)安装
centos安装Docker sudo yum remove docker* sudo yum install -y yum-utils#配置docker的yum地址 sudo yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo#安装指定版本 - 可以根据实际安装版本 sudo yum install -y docke…...

前端JS必用工具【js-tool-big-box】学习,获取当前浏览器向上滚动还是向下滚动,获取当前距离顶部和底部的距离
这一小节,我们说一下 js-tool-big-box 添加的最新工具方法,在日常前端开发工作中,如果网页很长,我们就需要获取当前浏览器是在向上滚动,还是向下滚动。如果向上滚动,滚动到0的时候呢,需要做一些…...

【python】flask 框架
python flask 框架 flask是一个轻量级的python后端框架 (Django, tornado, flask) 官网:欢迎来到 Flask 的世界 — Flask中文文档(3.0.x) 安装:pip install Flask -i https://pypi.douban.com 常识: http,默认端口号为80; https,默认端口号…...

Word中插入Mathtype右编号,调整公式与编号的位置
当你已经将mathtype内置于word后,可以使用右编号快速插入公式 但是往往会出现公式和编号出现的位置或之间的距离不合适 比如我在双栏下插入公式,会发现插入的公式与编号是适用于单栏的 解决办法: 开始->样式->MTDisplayLquation -&g…...
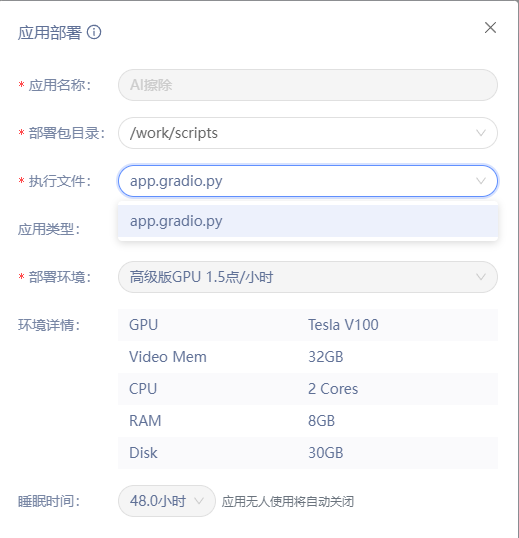
基于【Lama Cleaner】一键秒去水印,轻松移除不想要的内容!
一、项目背景 革命性的AI图像编辑技术,让您的图片焕然一新!无论水印、logo、不想要的人物或物体,都能被神奇地移除,只留下纯净的画面。操作简单,效果出众,给你全新的视觉体验。开启图像编辑新纪元,尽在掌控! 利用去水印开源工具Lama Cleaner对照片中"杂质"进行去除…...

VMware Workstation Ubuntu server 24 (Linux) 磁盘扩容 挂载硬盘
1 Ubuntu server 关机,新增加磁盘 2 启动ubuntu虚拟机,分区和挂载磁盘 sudo fdisk /dev/sdb #查看磁盘UUID sudo blkid #创建挂载目录 sudo mkdir /mnt/data # sudo vi /etc/fstab /dev/disk/by-uuid/0b440ed0-b28b-4756-beeb-10c585e3d101 /mnt/data ext4 defaults 0 1 #加…...
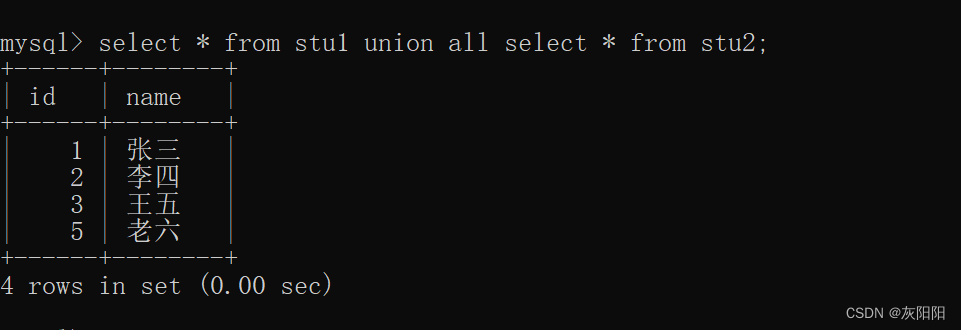
表的设计与查询
目录 一、表的设计 1.第一范式(一对一) 定义: 示例: 2.第二范式(一对多) 定义: 要求: 示例: 3.第三范式(多对多) 定义: 要求…...

【react】如何合理使用useEffect
useEffect 是 React Hooks API 的一部分,它允许你在函数组件中执行副作用操作,比如数据获取、订阅或者手动更改 DOM。合理使用 useEffect 可以帮助你管理组件的生命周期行为,同时避免不必要的渲染和性能问题。以下是一些关于如何合理使用 useEffect 的建议: 明确依赖项: 当…...

计算机专业英语Computer English
计算机专业英语 Computer English 高等学校计算机英语教材 Contents 目录 Part One Computer hardware and software 计算机硬件和软件----------盖金曙 生家峰 Unit 1 the History of Computers计算机的历史 Unit 2 Computer System计算机系统 Unit 3 Di…...
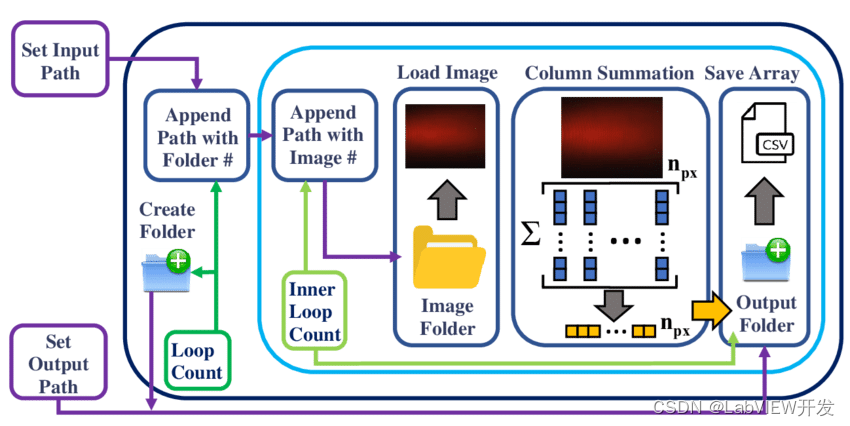
目前比较好用的LabVIEW架构及其选择
LabVIEW提供了多种架构供开发者选择,以满足不同类型项目的需求。选择合适的架构不仅可以提高开发效率,还能确保项目的稳定性和可维护性。本文将介绍几种常用的LabVIEW架构,并根据不同项目需求和个人习惯提供选择建议。 常用LabVIEW架构 1. …...

CSS之块浮动
在盒子模型的基础上就可以对网页进行设计 不知道盒子模型的可以看前面关于盒子模型的内容 而普通的网页设计具有一定的原始规律,这个原始规律就是文档流 文档流 标签在网页二维平面内默认的一种排序方式,块级标签不管怎么设置都会占一行,而同一行不能放置两个块级标签 行级…...
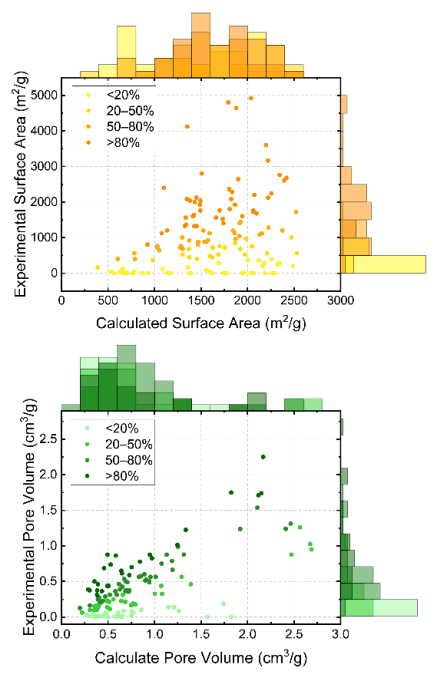
探索GPT-4V在学术领域的应用——无需编程即可阅读和理解科学论文
1. 概述 论文地址:https://arxiv.org/pdf/2312.05468.pdf 随着人工智能潜力的不断扩大,人工智能(AI)在化学领域的应用也在迅速发展。特别是大规模语言模型的出现,极大地扩展了人工智能在化学研究中的作用。由于这些模…...

耐用充电宝有哪些?优质充电宝到底选哪个?良心推荐!
在电量即生产力的现今时代,如何为移动设备寻找一位最佳的伴侣呢?一款耐用、优质的充电宝无疑是你的不二之选。今天我们将带您揭开市场隐藏的一面,揭示哪些充电宝品牌真正代表了耐用与品质的标杆。让我们一起深入了解并选购最适合自己的充电宝…...

何为屎山代码?
在编程界,有一种代码被称为"屎山代码"。这并非指某种编程语言或方法,而是对那些庞大而复杂的项目的一种形象称呼。屎山代码,也被称为"祖传代码",是历史遗留问题,是前人留给我们的"宝藏"…...

基于esp8266_点灯blinker_智能家居
文章目录 一 实现思路1 项目简介2 项目构成3 代码实现4 外壳部分 二 效果展示UI图片 一 实现思路 摘要:esp8266,mixly,点灯blinker,物联网,智能家居,3donecut 1 项目简介 1 项目效果 通过手机blinker app…...

Web前端开发交流群:深度探索、实践与创新的集结地
Web前端开发交流群:深度探索、实践与创新的集结地 在数字时代的浪潮中,Web前端开发扮演着举足轻重的角色。为了促进前端技术的交流与发展,Web前端开发交流群应运而生,成为众多开发者学习、分享、创新的集结地。本文将从四个方面、…...
苹果AI一夜颠覆所有,Siri史诗级进化,内挂GPT-4o
苹果AI一夜颠覆所有,Siri史诗级进化,内挂GPT-4o 刚刚,苹果AI,正式交卷! 今天,苹果构建了一个全新AI帝国——个人化智能系统Apple Intelligence诞生,智能助手Siri迎来诞生13年以来的史诗级进化…...
)
量子计算的奥秘与魅力:开启未来科技的钥匙(详解)
目录 一、量子计算的基本概念 二、量子计算的基本原理 1.量子叠加态与相位态 一、概念 二、量子叠加态 定义与原理 特性与影响 应用领域 三、量子相位态 定义与原理 特性与影响 应用领域 2.量子门操作 一、概念 二、量子门操作的基本概念 三、常见的量子门操作…...

redis 主从同步时,是同步主节点的缓存积压区的数据,还是同步主节点的aof文件
Redis 的主从同步(replication)是同步主节点的数据到从节点上,但它既不是直接同步 AOF 文件,也不是同步缓存积压区。 当一个 Redis 从节点启动并连接到主节点时,会发生以下步骤: 同步数据集:从…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...

Lovable电商网站搭建,为什么92%的初创团队在第3周就遭遇性能雪崩?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署。其核心基于 Vue 3(Composition API&a…...