RAG与知识库搭建
Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。通过链接注册并联系客服,可以获得20元代金券(相当于6-7H的免费GPU资源)。欢迎大家体验一下~
0. 简介
自从发现可以利用自有数据来增强大语言模型(LLM)的能力以来,如何将 LLM 的通用知识与个人数据有效结合一直是热门话题。关于使用微调(fine-tuning)还是检索增强生成(RAG)来实现这一目标的讨论持续不断。检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
用一个简单的比喻来说, RAG 对大语言模型(Large Language Model,LLM)的作用,就像开卷考试对学生一样。在开卷考试中,学生可以带着参考资料进场,比如教科书或笔记,用来查找解答问题所需的相关信息。开卷考试的核心在于考察学生的推理能力,而非对具体信息的记忆能力。同样地,在 RAG 中,事实性知识与 LLM 的推理能力相分离,被存储在容易访问和及时更新的外部知识源中,具体分为两种:
- 参数化知识(Parametric knowledge): 模型在训练过程中学习得到的,隐式地储存在神经网络的权重中。
- 非参数化知识(Non-parametric knowledge): 存储在外部知识源,例如向量数据库中。
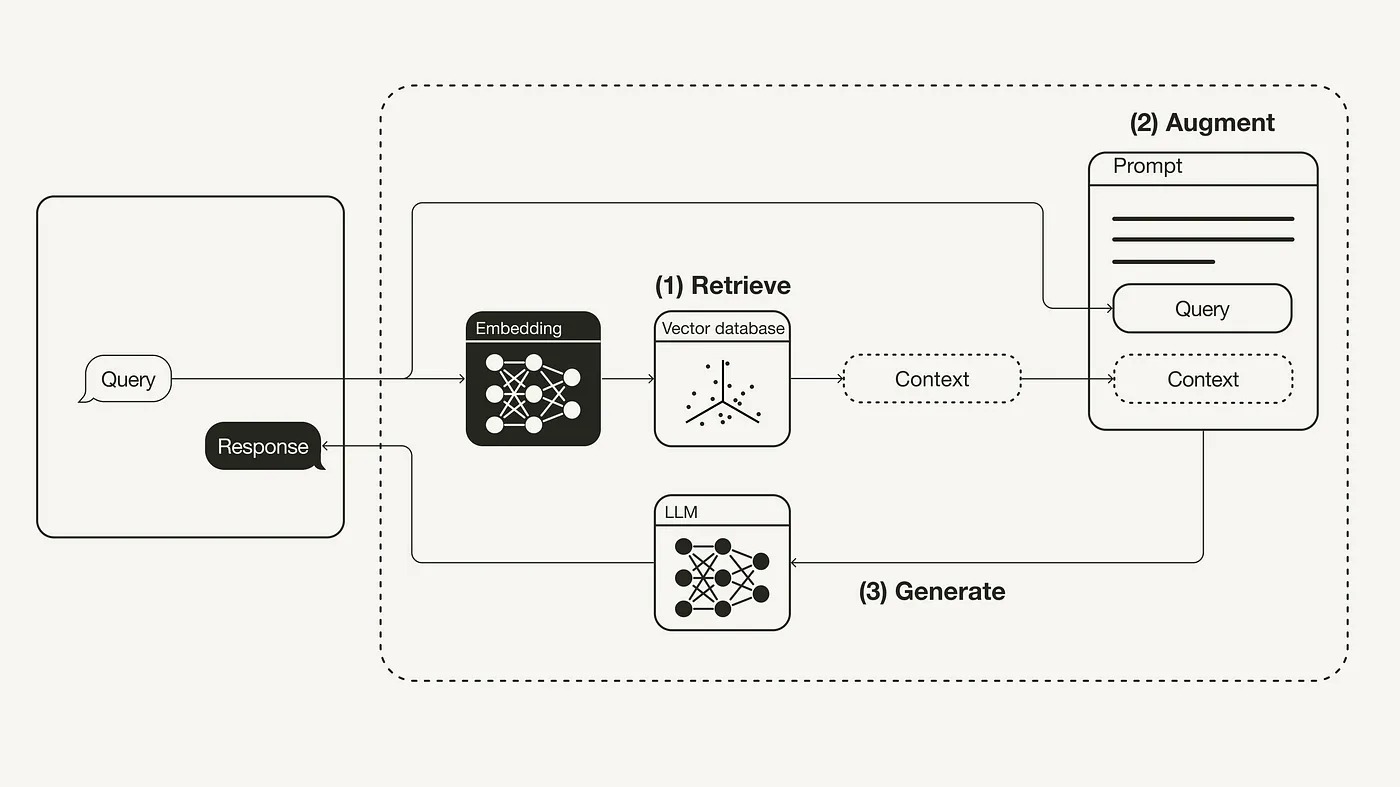
1. 了解LangChain
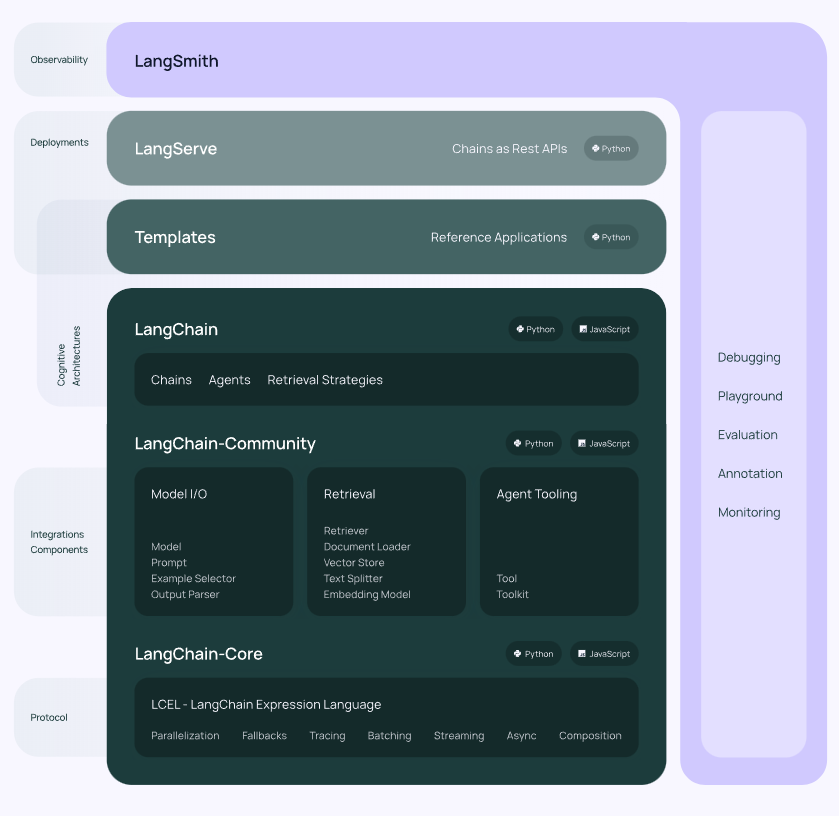
从上图可以看到,LangChain 目前有四层框架:
- 最下层深色部分:LangChain的Python和JavaScript库。包含无数组件的接口和集成,以及将这些组件组合到一起的链(chain)和代理(agent)封装,还有链和代理的具体实现。
- Templates:一组易于部署的参考体系结构,用于各种各样的任务。
- LangServe:用于将LangChain链部署为REST API的库。
- LangSmith:一个开发人员平台,允许您调试、测试、评估和监控基于任何LLM框架构建的链,并与LangChain无缝集成。
2. RAG基础使用
首先,你需要建立一个向量数据库,这个数据库作为一个外部知识源,包含了所有必要的额外信息。填充这个数据库需要遵循以下步骤:
- 收集数据并将其加载进系统
- 将你的文档进行分块处理
- 对分块内容进行嵌入,并存储这些块
首先,你需要收集并加载数据。为了加载数据,你可以利用 LangChain 提供的众多 DocumentLoader 之一。Document 是一个包含文本和元数据的字典。为了加载文本,你会使用 LangChain 的 TextLoader。
import requests
from langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
其次,需要对文档进行分块 — 由于 Document 的原始大小超出了 LLM 处理窗口的限制,因此需要将其切割成更小的片段。LangChain 提供了许多文本分割工具,对于这个简单的示例,你可以使用 CharacterTextSplitter,设置 chunk_size 大约为 500,并且设置 chunk_overlap 为 50,以确保文本块之间的连贯性。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
最后一步是嵌入并存储这些文本块 — 为了实现对文本块的语义搜索,你需要为每个块生成向量嵌入,并将它们存储起来。生成向量嵌入时,你可以使用 OpenAI 的嵌入模型;而存储它们,则可以使用 Weaviate 向量数据库。通过执行 .from_documents() 操作,就可以自动将这些块填充进向量数据库中。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions()
)vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False
)
一旦向量数据库准备好,你就可以将它设定为检索组件,这个组件能够根据用户查询与已嵌入的文本块之间的语义相似度,来检索出额外的上下文信息
retriever = vectorstore.as_retriever()
接下来,你需要准备一个提示模板,以便用额外的上下文信息来增强原始的提示。你可以根据下面显示的示例,轻松地定制这样一个提示模板。
from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)print(prompt)
在 RAG (检索增强生成) 管道的构建过程中,可以通过将检索器、提示模板与大语言模型 (LLM) 相结合来形成一个序列。定义好 RAG 序列之后,就可以开始执行它。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)query = "What did the president say about Justice Breyer"
rag_chain.invoke(query)
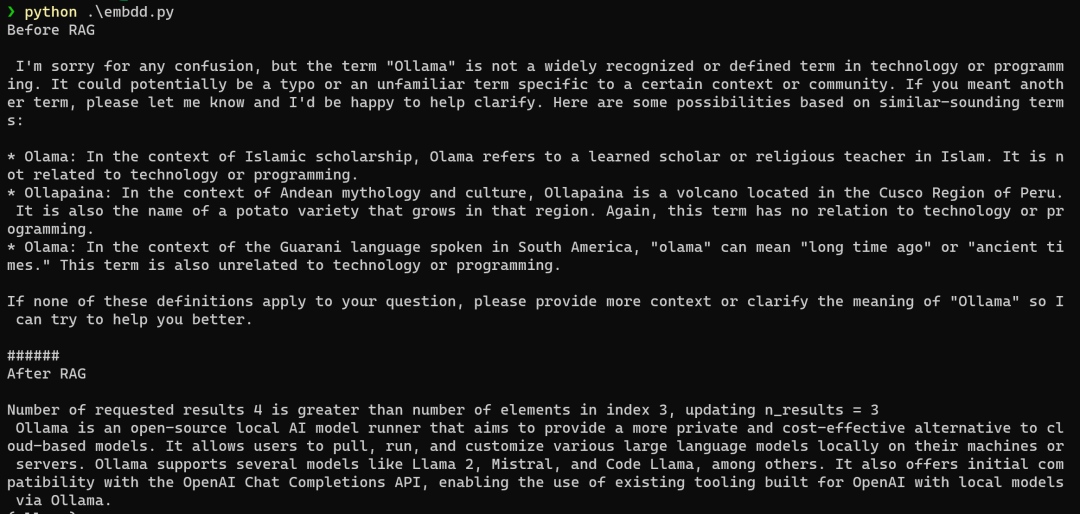
3. ollama替换chatgpt完成联网搜索拆分
此外可以通过ollama检索完成Embedding,给他资料,让他从这些资料从中找到答案来回答问题,就是构建知识库,回答问题
urls = ["https://ollama.com/","https://ollama.com/blog/windows-preview","https://ollama.com/blog/openai-compatibility",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [ item for sublist in docs for item in sublist]
#text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500,chunk_overlap=100)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500, chunk_overlap=100)
docs_splits = text_splitter.split_documents(docs_list)# 2 convert documents to Embeddings and store themvectorstore = Chroma.from_documents(documents=docs_splits,collection_name="rag-chroma",embedding=embeddings.ollama.OllamaEmbeddings(model='nomic-embed-text'),
)retriever =vectorstore.as_retriever()# 4 after RAG
print("\n######\nAfter RAG\n")
after_rag_template ="""Answer the question based only the following context:
{context}
Question:{question}
"""
after_rag_prompt = ChatPromptTemplate.from_template(after_rag_template)
after_rag_chain = ({"context": retriever, "question": RunnablePassthrough()}| after_rag_prompt| model_local| StrOutputParser()
)
print(after_rag_chain.invoke("What is Ollama?"))
通过三个网址,获取数据,将其转化为embedding,存储在向量库中,我们提问时,就能得到我们想要的一个初步答案,比未给语料时效果要好。
使用nomic-embed-text进行嵌入,nomic-embed-text具有更高的上下文长度8k,该模型在短文本和长文本任务上均优于 OpenAI Ada-002 和text-embedding-3-small。
4. 多模态RAG
为了帮助模型识别出"猫"的图像和"猫"这个词是相似的,我们依赖于多模态嵌入。为了简化一下,想象有一个魔盒,能够处理各种输入——图像、音频、文本等。现在,当我们用一张"猫"的图像和文本"猫"来喂养这个盒子时,它施展魔法,生成两个数值向量。当这两个向量被输入机器时,机器会想:"根据这些数值,看起来它们都与’猫’有关。"这正是我们的目标!我们的目标是帮助机器识别"猫"的图像和文本"猫"之间的密切联系。然而,为了验证这个概念,当我们在向量空间中绘制这两个数值向量时,结果发现它们非常接近。这个结果与我们之前观察到的两个文本词"猫"和"狗"在向量空间中的接近度完全一致。这就是多模态的本质。
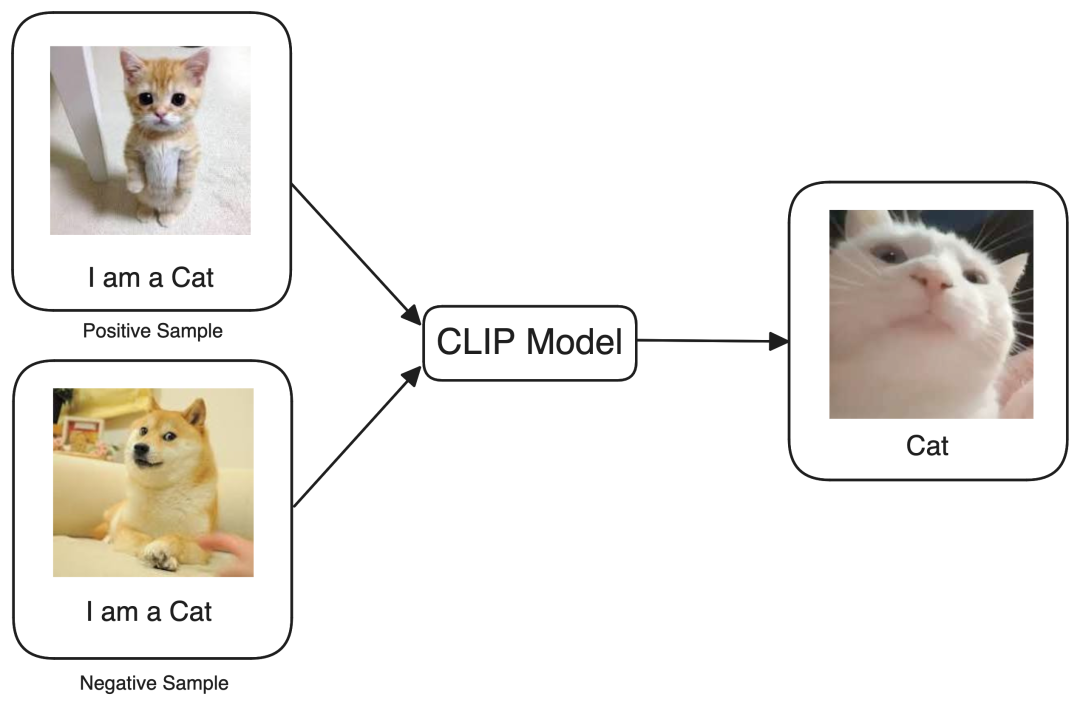
现在我们训练文本-图像模型识别出正样本提供了准确的解释,而负样本具有误导性,应该在训练过程中被忽略。正式来说,这种技术被OpenAI引入的 CLIP[2] (对比语言-图像预训练)所称,作者在大约4亿对从互联网上获取的图像标题对上训练了一个图像-文本模型,每当模型犯错误时,对比损失函数就会增加并惩罚它,以确保模型训练良好。同样的原则也适用于其他模态组合,例如猫的声音与猫这个词是语音-文本模型的正样本,一段猫的视频与描述性文本"这是一只猫"是视频-文本模型的正样本。
…详情请参照古月居
相关文章:
RAG与知识库搭建
Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时&…...
MySQL提权之UDF提权
1、前言 最近遇到udf提权,几经周折终于搞懂了。感觉挺有意思的,渗透思路一下子就被打开了。 2、什么是udf提权 udf 全称为user defined function,意思是用户自定义函数。用户可以对数据库所使用的函数进行一个扩展(windows利用…...

【设计模式】结构型设计模式之 组合模式
介绍 这里的组合模式,与之前的设计模式中的"组合关系"完全是两码事,这里的组合模式主要用来处理结构为树形的数据。 组合模式(Composite Pattern)是一种结构型设计模式,它允许你将对象组合成树状结构来表示…...
我给KTV服务生讲解防抖,他竟然听懂了
端午节三天假期,的最后一天,我和朋友闲来无事,想着去唱会儿歌吧,好久不唱了,于是吃了午饭,石景山就近找了一家KTV,我们团好了卷就过去了。 装修还算不错,很快找到服务生,…...

抽象java入门1.3.1
前言: 本期内容是为了更好补充关于方法(函数)的定义 开始: 函数(function)表示每个输入值对应唯一输出值的一种对应关系。 核心在于:输入值和输出值这两个元素 真的吗? 错&…...
使用Rufus工具制作Ubuntu To Go——很详细
一、准备工作 准备工具: 1、下载Rufus(主角)软件 2、准备一个U盘(制作启动盘,32G足够) 3、准备一个U盘或硬盘(小白128G足够,装Ubuntu系统) 4、下载Ubuntu系统镜像文件 1、下载软件Rufus 先来看…...

Android Jetpack Compose 实现一个电视剧选集界面
文章目录 需求概述效果展示实现思路代码实现总结 需求概述 我们经常能看到爱奇艺或者腾讯视频这类的视频APP在看电视剧的时候都会有一个选集的功能。如下图所示 这个功能其实很简单,就是绘制一些方块,在上面绘制上数字,还有标签啥的。当用户…...

C++多线程并发
文章目录 C多线程并发std::chronoC中的多线程:std::thread主线程等待子线程结束:join主线程分离子线程:detach异步:std::async异步的另一种用法:std::launch::deferredstd::async的底层实现:std::promisest…...
新火种AI|摊上事儿了!13名OpenAI与谷歌员工联合发声:AI失控可能导致人类灭绝...
作者:小岩 编辑:彩云 2024年,OpenAI的CEO Sam Altman就没有清闲过,他似乎一直走在解决麻烦的路上。最近,他的麻烦又来了。 当地时间6月4日,13位来自OpenAI和Google Deep Mind的现任及前任员工联合发布了…...

Web前端后端精通:深度解析与技能进阶
Web前端后端精通:深度解析与技能进阶 在数字时代的浪潮中,Web前端后端技术的精通成为了信息科技领域的核心竞争力。本文将从四个方面、五个方面、六个方面和七个方面深入探讨Web前端后端技术的精髓,带领读者领略这一领域的魅力与挑战。 一、…...
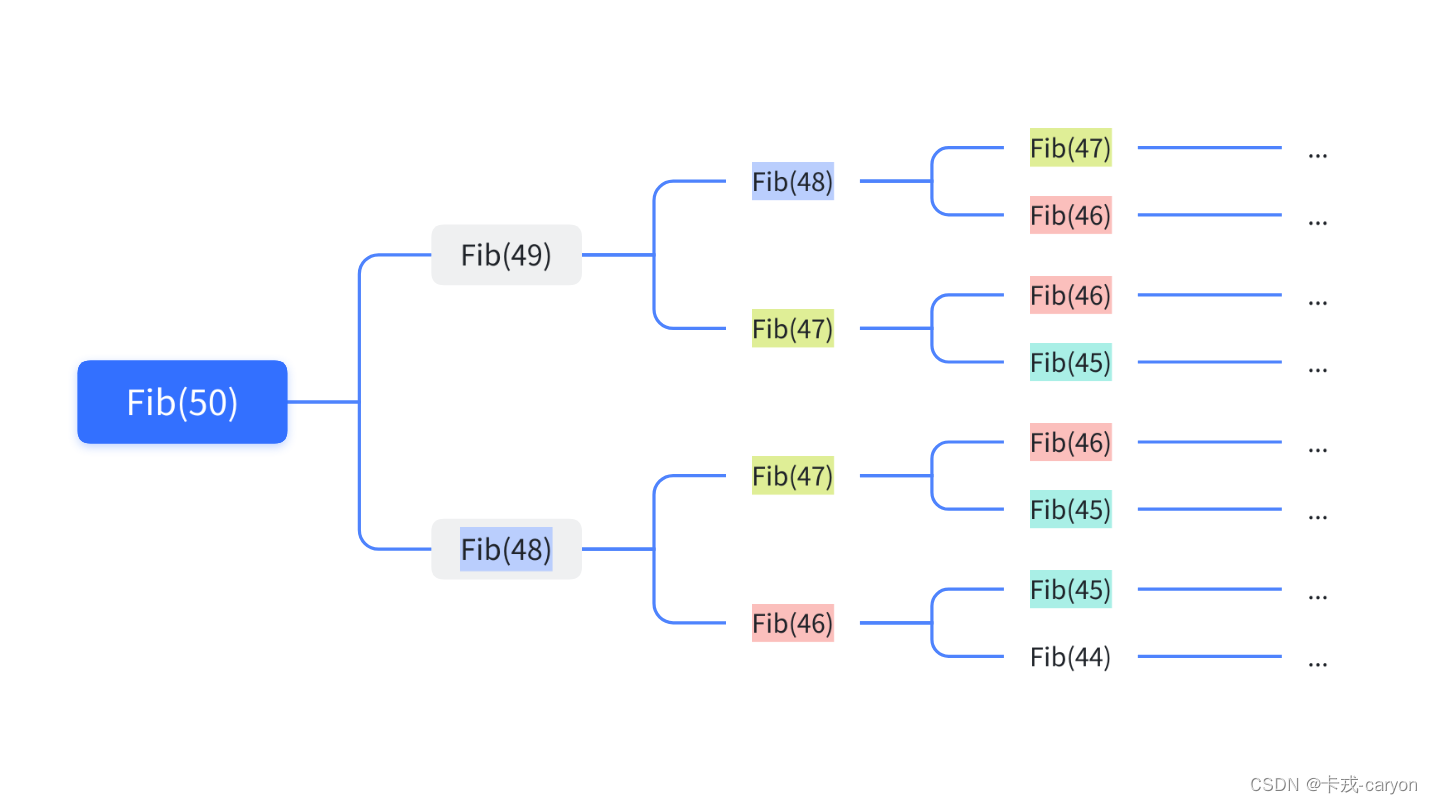
【C语言】09.函数递归
递归其实是⼀种解决问题的方法,在C语言中,递归就是函数自己调用自己。 一、递归的介绍 1.1递归的思想 把⼀个大型复杂问题层层转化为⼀个与原问题相似,但规模较小的子问题来求解;直到子问题不能再被拆分,递归就结束…...
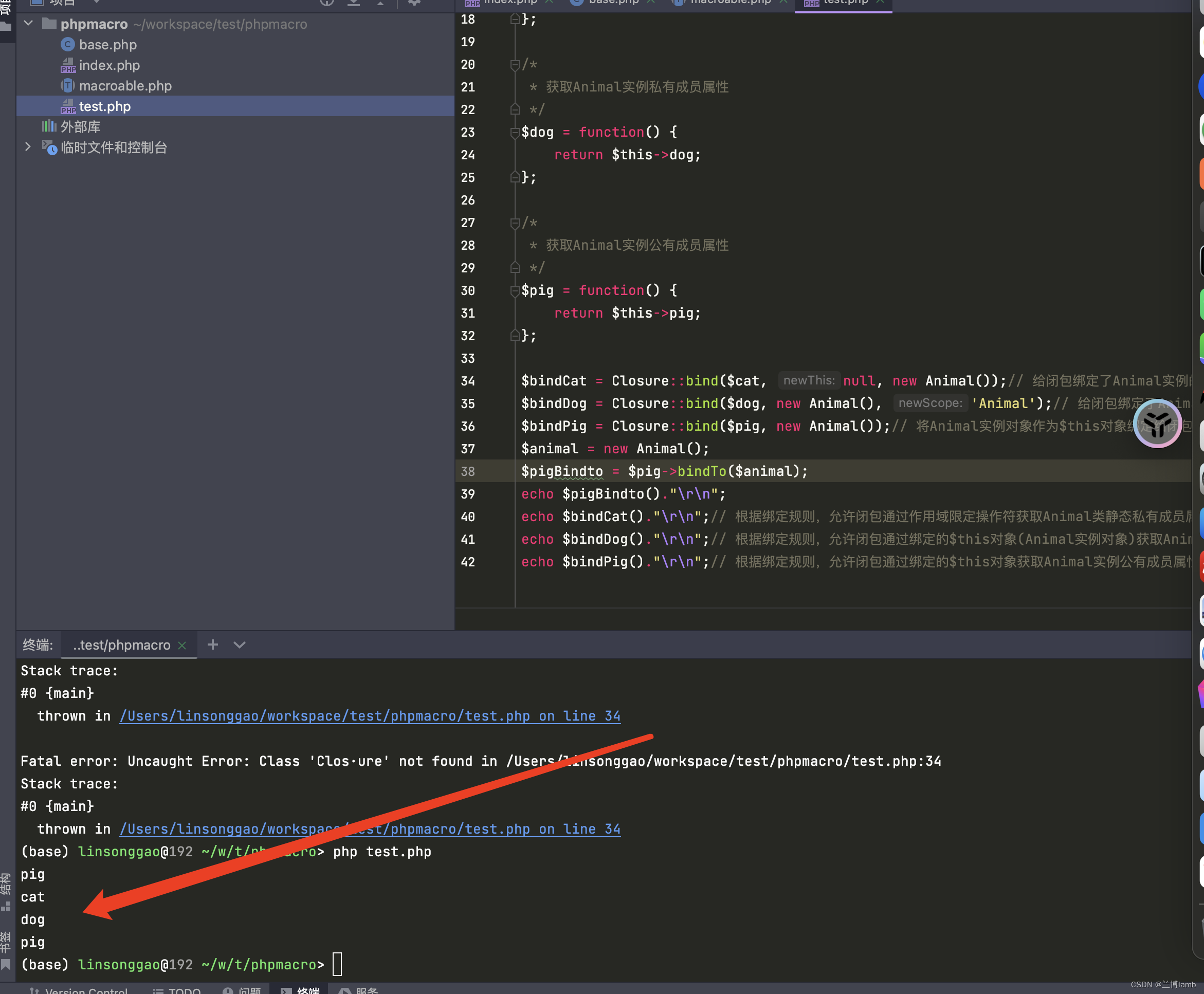
php高级之框架源码、宏扩展原理与开发
在使用框架的时候我们经常会看到如下代码 类的方法不会显示地声明在代码里面,而是通过扩展的形式后续加进去,这么做的好处是可以降低代码的耦合度、保证源码的完整性、团队开发的时候可以分别写自己的服务去扩展类,减少代码冲突等等。我自己…...

(2024,示例记忆,模型记忆,遗忘,差分评估,概率评估)深度学习中的记忆:综述
Memorization in deep learning: A survey 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0 摘要 1 引言 0 摘要 深度神经网络(DNNs)驱动的深度学习ÿ…...
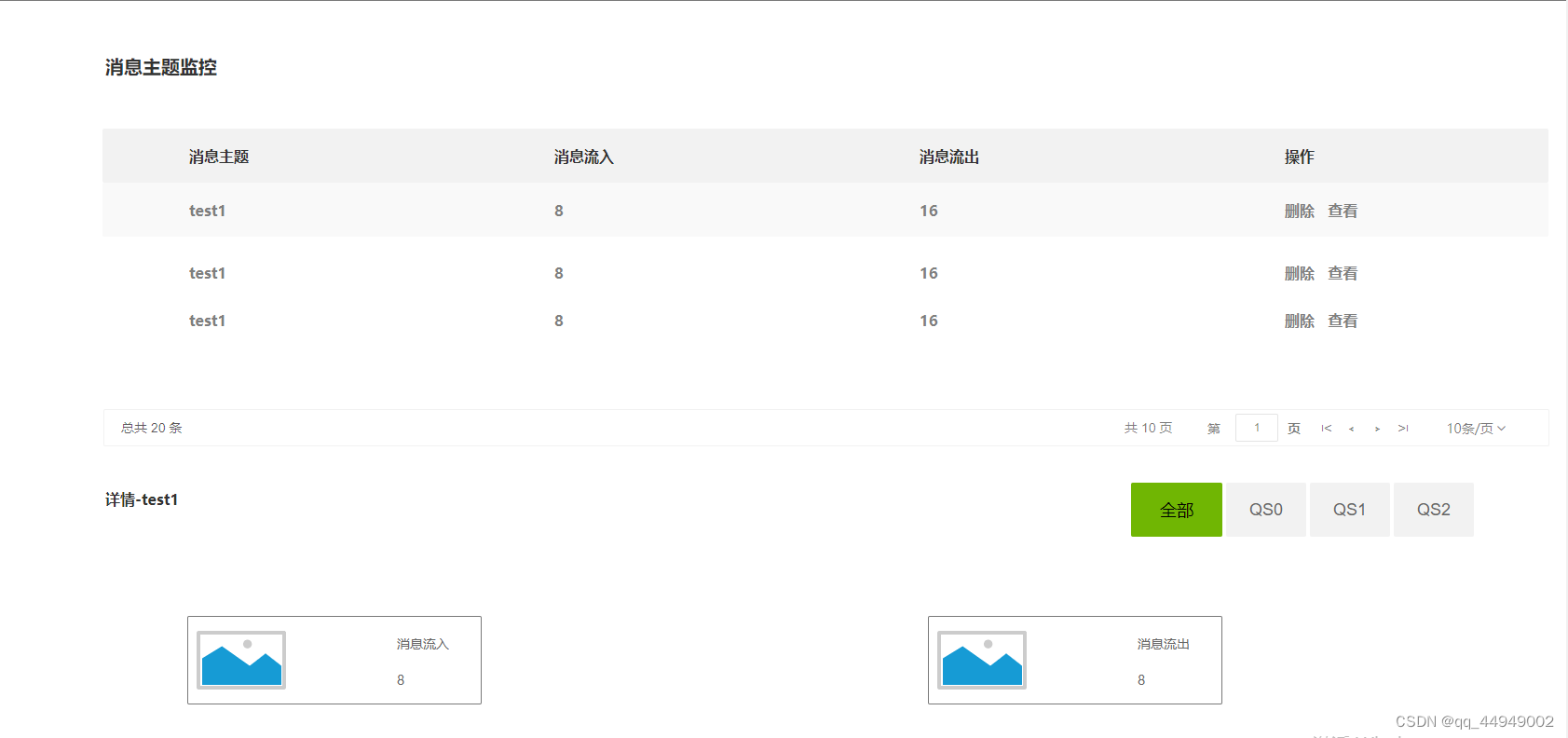
硬件产品经理
边端协调管理平台 主页一:模型管理1.1 边侧模型管理 二:配置管理2.1 终端软件配置管理 三:设备管理3.1 区域位置管理3.2 工控机管理(其实就是围绕授权)3.3 生产设备管理3.4 设备运行管理 四:数据服务4.1 实…...

AES加密、解密工具类
1、AES加密、解密工具类 这篇文章,主要记录一下AES加密、解密的工具类代码,在需要使用的时候,直接复制黏贴即可。 package com.gitcode.pms.common.util;import org.slf4j.Logger; import org.slf4j.LoggerFactory;import javax.crypto.Cipher; import javax.crypto.spec.…...

普通人想要自学ai,该如何入手,看完这篇你就懂了,零基础教程!
学会了AIGC之后,我只想说:无敌是多么寂寞? 之前我整理一篇会议记录起码要2小时。现在交给AI ,5分钟搞定; 之前整理账目总是出错,现在利用AI财务整合器,轻松解决统计难题; 之前写个…...

Less的简单总结
Less 是一个开源的 CSS 预处理器,它扩展了 CSS 语言,增加了变量、嵌套规则、运算符、函数等特性,使编写 CSS 更加高效、灵活且易于维护。下面是对 "Less" 的一个总结文档: 简介 名称:Less(通常表…...

Android:UI:Drawable:View/ImageView与Drawable
文章目录 在View/ImageVIew中显示DrawableDrawable对View的更新操作在View/ImageVIew中显示Drawable API View.setBackground(Drawable) ImageView.setImagDrawable(Drawable) 源码分析 View.mBackground在View.draw(Canvas)中绘制,调用Drawable.draw(Canvas) ImageView.m…...

网络安全实验BUAA-全套实验报告打包
下面是部分BUAA网络安全实验✅的实验内容 : 认识路由器、交换机。掌握路由器配置的基本指令。掌握正确配置路由器的方法,使网络正常工作。 本博客包括网络安全课程所有的实验报告:内容详细,一次下载打包 实验1-路由器配置实验2-AP…...

监控易监测对象及指标之:全面监控SQL Server 2008
随着企业信息化建设的不断深入,数据库作为存储和管理关键业务数据的核心,其稳定性和性能至关重要。SQL Server 2008作为一款广泛使用的关系型数据库管理系统,承载着众多企业的核心业务数据。 为了确保SQL Server 2008数据库的稳定运行和高效性…...
告别元路径!用HGT(异构图Transformer)处理学术图谱实战:从OAG数据到作者消歧
异构图Transformer实战:从OAG数据到作者消歧的完整解决方案 学术图谱中的作者消歧一直是知识图谱构建中的核心挑战。当两位学者姓名相同时,如何准确区分他们的研究成果?传统方法依赖人工设计的元路径和复杂规则,而HGT(…...

3种智能策略自动化将Markdown笔记转化为交互式思维导图
3种智能策略自动化将Markdown笔记转化为交互式思维导图 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap 面对繁杂的Markdown技术文档和会议纪要,如何快速理清信息层次、展示复杂架构…...

如何在Mac上免费实现NTFS磁盘完整读写:终极解决方案指南
如何在Mac上免费实现NTFS磁盘完整读写:终极解决方案指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management …...

ARM GICD_CTLR寄存器详解与中断控制实践
1. GICD_CTLR寄存器概述GICD_CTLR是ARM通用中断控制器(GIC)中Distributor模块的核心控制寄存器,作为中断系统的"总开关",它直接决定了整个中断控制器的行为模式。在GICv3/v4架构中,这个32位寄存器主要实现三大核心功能:…...

FreeMove:Windows系统磁盘空间智能优化解决方案
FreeMove:Windows系统磁盘空间智能优化解决方案 【免费下载链接】FreeMove Move directories without breaking shortcuts or installations 项目地址: https://gitcode.com/gh_mirrors/fr/FreeMove 当C盘空间告急时,大多数Windows用户面临着一个…...

微信网页版访问难题如何破解?wechat-need-web浏览器扩展的轻量级替代方案探索
微信网页版访问难题如何破解?wechat-need-web浏览器扩展的轻量级替代方案探索 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 你是否曾在公…...

QMCDecode终极指南:一键解锁QQ音乐加密音频的完整解决方案
QMCDecode终极指南:一键解锁QQ音乐加密音频的完整解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默…...

WordPress Puock主题深度解析:高颜值集成化设计与实战配置指南
1. 项目概述:为什么选择Puock主题?如果你正在寻找一款功能强大、颜值在线,并且能让你从繁琐的WordPress主题配置中解脱出来的产品,那么Puock主题绝对值得你花时间深入了解。我接触过不少WordPress主题,从付费到开源&am…...

MAXON 机电高压油安全切断阀 通用型摆动式闸阀 灰铸铁 8790
在工业锅炉、熔炉及加热系统中,燃料管路的安全切断是防控火灾与爆炸风险的核心环节。MAXON(麦克森)8790 机电高压油安全切断阀,作为霍尼韦尔旗下经典的通用型摆动式闸阀,以灰铸铁阀体、毫秒级切断速度与严苛安全认证&a…...

终极指南:使用boardgame.io实现Web与移动端完美同步的游戏开发
终极指南:使用boardgame.io实现Web与移动端完美同步的游戏开发 【免费下载链接】boardgame.io State Management and Multiplayer Networking for Turn-Based Games 项目地址: https://gitcode.com/gh_mirrors/bo/boardgame.io 🚀 boardgame.io 是…...