OceanBase 4.3 特性解析:列存技术
在涉及大规模数据的复杂分析或即时查询时,列式存储是支撑业务负载的关键技术之一。相较于传统的行式存储,列式存储采用了不同的数据文件组织方式,它将表中的数据以列为单位进行物理排列。这种存储模式允许在分析过程中,查询计算仅需针对所需的列数据进行扫描,从而避免了不必要的整行扫描,显著降低了IO和内存等资源的消耗,进而提升了计算效率。此外,列式存储天然具备更佳的数据压缩优势,能够实现较高的压缩比,有效节约了存储空间,并降低了网络传输带宽的占用。
常见的列存存储引擎在实现上往往假设不会有大量随机更新, 尽量保证列存组织数据是静态的。当真正伴随大量数据随机更新时,也会不可避免的存在系统性能问题。OceanBase LSM-Tree 架构可以将基线数据和增量数据分别处理,正好可以解决这一场景问题。因此 OceanBase 4.3 版本基于当前架构基础进行扩展,正式推出列存引擎,在一个架构、一个数据库上,实现了列存和行存数据存储一体化,兼顾 TP 和 AP 查询性能。
为了让有分析诉求的用户顺畅使用新版本,围绕列存引擎,从优化器到执行器、从 DDL 到事务处理等多模块都进行了适配优化。包括基于列存的新的代价模型和向量化引擎,查询下压功能的扩展和增强,Skip Index,新的列式编码算法,自适应 Compaction 等。本文将深入探讨 OceanBase 4.3 版本带来的列存能力、应用场景,以及用户关心的未来发展规划。
一、列存整体架构
OceanBase 作为原生分布式数据库,默认情况下会为用户数据创建多个副本。为了充分利用多副本的优势,为用户提供数据强校验和数据迁移重用等增强体验,OceanBase 自研的 LSM-Tree 存储引擎做了深度优化:
○ 基线数据:相较于业内常见的 LSM-Tree 实现逻辑,OceanBase 提出了"每日合并"的概念。用户可定期或根据操作选择一个全局版本号,所有副本的租户数据将在这个版本上进行一轮 Major Compaction,生成这个版本的基线数据。所有副本在同一版本下的基线数据完全一致,物理上保持一致。
○ 增量数据:相对于基线数据,增量数据是指在最新版本的基线数据之后写入的数据。增量数据可以是刚写入Memtable的内存数据,也可以是已经转储为SSTable 的磁盘数据。增量数据在每个副本中独立维护,不保证一致性,并且包含了所有多版本的数据。
基于列存应用场景随机更新量可控的背景,OceanBase 4.3 结合自身基线数据和增量数据的特质,提出了一套对上层透明的列存实现方式:基线数据存储为列存模式,增量数据保持行存,确保用户所有 DML 操作不受影响,上下游同步无缝接入,列存表数据仍然可以像行存表一样进行所有事务操作。列存模式下每列数据存储为一个独立 SSTable,所有列的 SSTable 组合成为一个虚拟 SSTable 作为用户的列存基线数据。同时,用户可根据实际业务诉求在建表环节指定设置,基线数据可以支持行存、列存、行存列存冗余三种模式,提供更好的灵活性。

OceanBase 4.3 版本中不仅在存储引擎中实现了列存模式,更从优化器、执行器以等多维度进行列存的适配优化。用户在迁移到列存模式后基本上不会感受到业务变化,能够像使用行存一样享受到列存带来的性能优势。列存引擎的全面优化,也使得 OceanBase 真正实现了 TP & AP 一体化,实现了一套引擎、一套代码支持不同类型业务的目标,打造更加完善的 HTAP 混合负载实时分析能力。
二、OceanBase 实现列存,有哪些天然优势
(一)成熟的 LSM-Tree 引擎
与传统数据库相比,OceanBase 拥有天然的 Delta Store,非常适合实现列存。基于 LSM-Tree 存储引擎的支持,OceanBase 列存不仅支持完整的事务,而且基础算子的性能不弱于传统的 TP 数据库。在列存上,完整的事务支持使得 OceanBase 在更新方面具有天然优势,所有事物语义和多样事物的管理对用户来说完全透明的,用户可以轻松切换到列存模式,将列存数据库当成行存数据库使用,对业务完全透明,不需要做任何改动。
(二)完善的执行引擎
OceanBase 不仅拥有完整的执行引擎,还具备通用的优化器是通用的。在行存模式下,OceanBase 已经实现向量化存储引擎的无缝对接,无需任何修改即可支持向量化执行。此外,OceanBase 实现一套优化器的代码在上层对行存和列存进行不同代价的估算,使得用户的 SQL 可以自动选择行存或列存。
(三)灵活的原生分布式
OceanBase 天然支持分布式并行查询引擎,未来还可以轻松扩展到列存异构副本。列存异构副本的优势体现在用户需要完全硬隔离的应用场景中,未来的OceanBase 版本将新增这一功能。
综上所述,OceanBase 凭借其天然优势推动了 4.3 版本中列存功能的实现。引入列存储引擎后,OceanBase 整体架构在外部表现上完全不变,并且从架构层面支持了列存相关的三种模式:
○ 基线列存 +增量行存:基线数据采用列存方式存储,增量数据采用行存方式存储。
○ 灵活的行存/列存索引:可以对行存表建立列存索引,也可以对列存表建立行存索引,还可以对两者进行任意组合。由于所有列存表和索引的底层存储结构是统一的,因此 OceanBase 可以自动支持列存和行存的索引。
○ 列存副本:OceanBase 正在研发的列存副本功能。得益于原生分布式能力,只需对模式或表做部分修改,即可以通过 Compaction 将新增的只读副本转换为列存存储模式。
三、列存使用方法
(一)默认创建列存表
对于 OLAP 业务需求,我们推荐默认创建列存表。如何确保租户创建出来的表默认为列存表?只通过下面的配置项即可实现:
alter system set default_table_store_format = "column";随后我们创建的表格没有指定 column group 时,默认创建为列存表。
OceanBase(root@test)>create table t1 (c1 int primary key, c2 int ,c3 int);
Query OK,0 rows affected (0.301 sec)OceanBase(root@test)>show create table t1;CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
WITH COLUMN GROUP(each column)1 row in set (0.101 sec)(二)指定创建列存表
为了方便用户创建列存表,列存引入新的语法 with column group,当用户建表时最后指定 `with column group(each column)` ,即表示创建列存表。
OceanBase(root@test)>create table tt_column_store (c1 int primary key, c2 int ,c3 int) with column group (each column);
Query OK,0 rows affected (0.308 sec)OceanBase(root@test)>show create table tt_column_store;CREATE TABLE `tt_column_store` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 WITH COLUMN GROUP(each column)1 row in set (0.108 sec)(三)指定创建列存行存冗余表
在某些场景下,用户可以容忍一定程度的数据冗余,以满足 AP/TP 业务场景的双重需求。此时,可以增加行存数据的冗余,通过 `with column group` 语法增加指定 `all columns` 即可实现。
create table tt_column_row (c1 int primary key, c2 int , c3 int) with column group (all columns, each column);
Query OK, 0 rows affected (0.252 sec)OceanBase(root@test)>show create table tt_column_row;
CREATE TABLE `tt_column_row` (`c1` int(11) NOT NULL, `c2` int(11) DEFAULT NULL, `c3` int(11) DEFAULT NULL, PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 WITH COLUMN GROUP(all columns, each column)1 row in set (0.075 sec)(四)列存扫描
如何查看是否列存扫描计划?计划展示上新增 COLUMN TABLE FULL SCAN,描述列存表的范围扫描。
OceanBase(root@test)>explain select * from tt_column_store;
+--------------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|tt_column_store|1 |7 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), filter(nil), rowset=16 |
| access([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), partitions(p0) |
| is_index_back=false, is_glOceanBaseal_index=false, |
| range_key([tt_column_store.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------------+计划展示上新增 COLUMN TABLE GET,描述列存表上的指定主键的 get 操作。
OceanBase(root@test)>explain select * from tt_column_store where c1 = 1;
+--------------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------------+
| =========================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------- |
| |0 |COLUMN TABLE GET|tt_column_store|1 |14 | |
| =========================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), filter(nil), rowset=16 |
| access([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_store.c1]), range[1 ; 1], |
| range_cond([tt_column_store.c1 = 1]) |
+--------------------------------------------------------------------------------------------------------+
12 rows in set (0.051 sec)如何通过 Hint 指定列存行存冗余表走列存扫描?对于列存行存冗余表,优化器会根据代价选择走行存或者列存扫描,如简单场景做全表扫描,会默认使用行存生成计划。
OceanBase(root@test)>explain select * from tt_column_row;
+--------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------- |
| |0 |TABLE FULL SCAN|tt_column_row|1 |3 | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 |
| access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------+如果用户希望通过手动调优走列存扫描,可以通过 hint USE_COLUMN_TABLE 来强制 tt_column_row 表走列存扫描。
OceanBase(root@test)>explain select /*+ USE_COLUMN_TABLE(tt_column_row) */ * from tt_column_row;
+--------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------+
| =============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|tt_column_row|1 |7 | |
| =============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 |
| access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------+
类似的方式,通过 Hint NO_USE_COLUMN_TABLE 可以强制表不进行列存扫描。
OceanBase(root@test)>explain select /*+ NO_USE_COLUMN_TABLE(tt_column_row) */ c2 from tt_column_row;
+------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------- |
| |0 |TABLE FULL SCAN|tt_column_row|1 |3 | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c2]), filter(nil), rowset=16 |
| access([tt_column_row.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+------------------------------------------------------------------+
11 rows in set (0.053 sec)四、未来展望
OceanBase 4.3 列存的引入,为用户的数据分析以及实时分析场景提供了新的选择。未来,OceanBase 列存将持续演进,为用户带来更加丰富的 feature、更强劲的性能以及更灵活的部署模式。
第一,更丰富的功能。目前,我们支持纯列存储引擎,未来将实现可自定义的灵活列组组织支持,满足不同场景的分析需求。此外,我们计划将增量旁路导入功能进一步增强,帮助用户实现高效的数据导入,缩短数据分析准备时间。
第二,更好的性能。增强 Skip Index 的支持,使其能够更好地满足用户的查询需求。此外,我们计划实现格式一体化,目前存储的格式多样化,未来将实现存储格式与 SQL 向量化引擎的紧密结合,使得在执行 SQL 计算时,系统能够识别不同的存储格式,从而帮助用户节省更多的数据转换开销。
第三,更灵活的部署模式。在未来的版本中,我们将支持 OLAP 所需的异构副本,以满足用户对强依赖异构副本的需求。此外,未来还将支持存算分离模式,使得所有用户的 AP 数据库都能够以更低的成本享受存储与计算的分离。
相关文章:
OceanBase 4.3 特性解析:列存技术
在涉及大规模数据的复杂分析或即时查询时,列式存储是支撑业务负载的关键技术之一。相较于传统的行式存储,列式存储采用了不同的数据文件组织方式,它将表中的数据以列为单位进行物理排列。这种存储模式允许在分析过程中,查询计算仅…...
ARM32开发--PWM与通用定时器
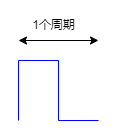
知不足而奋进望远山而前行 目录 文章目录 前言 学习目标 学习内容 PWM pwm原理 需求 开发流程 初始化PWM PWM占空比控制 main函数修改duty 输出通道 关心的内容 重要的关键词 周期 分频 占空比 总结 前言 在微控制器开发中,理解和掌握PWM&#x…...
:栈帧(backtrace))
debugger(七):栈帧(backtrace)
〇、前言 在前面已经详细得介绍了栈帧,这里实现 backtrace。 一、backtrace 思路是遍历 stack,搜索 stack pointer,逐个打印栈帧信息,一直打印到 main 函数。 void Debugger::print_backtrace() {auto output_frame [frame_n…...
kafka-重试和死信主题(SpringBoot整合Kafka)
文章目录 1、重试和死信主题2、死信队列3、代码演示3.1、appication.yml3.2、引入spring-kafka依赖3.3、创建SpringBoot启动类3.4、创建生产者发送消息3.5、创建消费者消费消息 1、重试和死信主题 kafka默认支持重试和死信主题 重试主题:当消费者消费消息异常时&…...
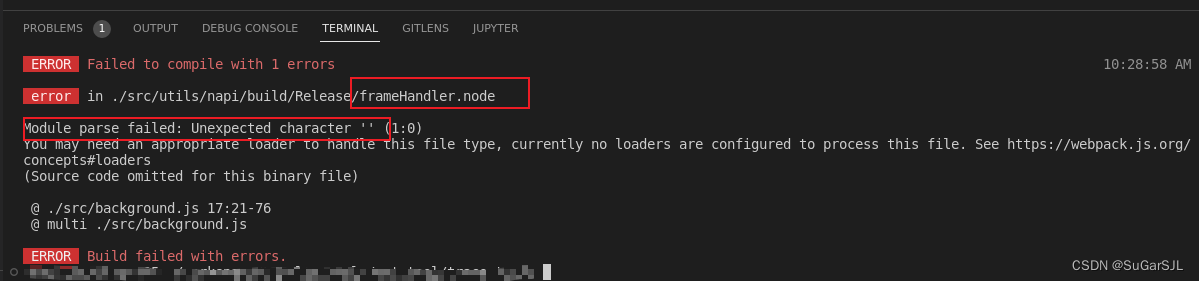
electron-Vue: Module parse failed: Unexpected character ‘ ‘
electron-Vue项目中,我自己写了一个node的C扩展(xx.node),然后在.vue文件里import它,然后运行npm run electron:serve,报错如下: electron-Vue打包默认使用webpack,默认情况下webpack没…...

贪心算法-数组跳跃游戏(mid)
目录 一、问题描述 二、解题思路 1.回溯法 2.贪心算法 三、代码实现 1.回溯法实现 2.贪心算法实现 四、刷题链接 一、问题描述 二、解题思路 1.回溯法 使用递归的方式,找到所有可能的走步方式,并记录递归深度(也就是走步次数&#x…...

C++经典150题
经典150题 数组/字符串 文章目录 经典150题数组/字符串88. 合并两个有序数组27.移除元素26.删除有序数组中的重复项80.删除有序数组重点重复项II169.多数元素189.轮转数组121.买卖股票的最佳时机123.买卖股票的最佳时机 III55.跳跃游戏45.跳跃游戏II 88. 合并两个有序数组 给…...

超详解——Python 序列详解——基础篇
目录 1. 序列的概念 字符串(String) 列表(List) 元组(Tuple) 2. 标准类型操作符 连接操作符() 重复操作符(*) 索引操作符([]) …...

DVWA-DC-6
靶机IP:192.168.20.140 kaliIP:192.168.20.128 网络有问题的可以看下搭建Vulnhub靶机网络问题(获取不到IP) 信息收集 nmap扫描靶机端口及版本信息 dirsearch扫目录 发现是个wordpress建站 我们去访问前端界面 存在重定向,修改hosts文件,加入192.168…...

ubuntu早期版本以及18.04后的版本,通过rc.local配置开机自启
在ubuntu早期版本以及18.04后的版本,还是支持在rc.local中进行操作开机自启。 1、编辑rc.local文件 cat <<EOF >/etc/rc.local #!/bin/sh -e # rc.local # This script is executed at the end of each multiuser runlevel. # Make sure that the script…...

【环境搭建】1.阿里云ECS服务器 安装jdk8
在阿里云服务器上安装 JDK 8 可以通过以下步骤完成。假设你使用的是 CentOS 或者其他基于 Red Hat 的发行版或Alibaba Cloud Linux 3.2104 LTS 64位。 1.更新系统软件包 sudo yum update -y2.安装 OpenJDK 8 使用 yum 包管理器安装 OpenJDK 8 sudo yum install -y java-1.8…...
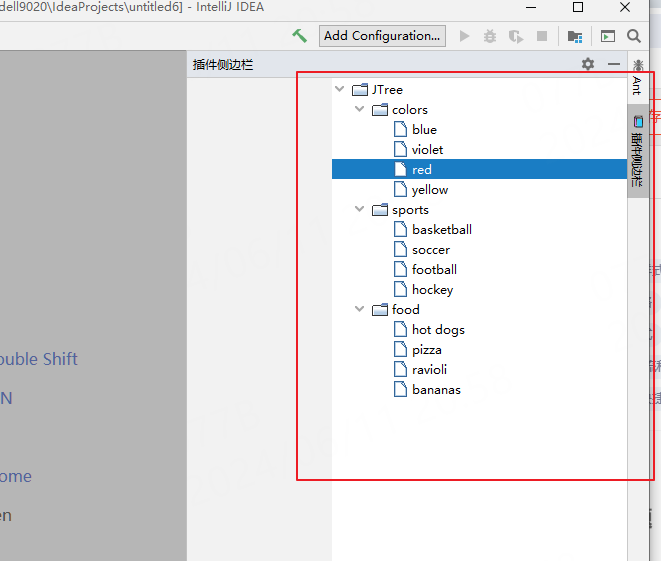
idea插件开发之定义侧边栏
写在前面 看下如何在侧边栏定义窗口,如下的效果: 1:正戏 先来定义UI,随便拖拽个组件,就看个效果: 接着定义一个工厂类来创建这个UI,需要实现接口com.intellij.openapi.wm.ToolWindowFactor…...

HarmonyOS未来五年的市场展望
一、引言 随着科技的不断进步和消费者对于智能化设备需求的日益增长,操作系统作为连接硬件与软件的核心平台,其重要性愈发凸显。HarmonyOS(鸿蒙系统),作为华为自主研发的分布式操作系统,自诞生以来便备受瞩…...
?)
R语言:什么是向量化操作(Vectorization)?
在R语言中,向量化操作是一个非常重要且强大的概念。它不仅提高了代码的简洁性和可读性,还大大提升了代码的执行效率。本文将详细介绍什么是向量化操作,并通过几个示例来展示其应用。 什么是向量化操作? 向量化操作是指在不使用显…...

Python 机器学习 基础 之 【实战案例】中药数据分析项目实战
Python 机器学习 基础 之 【实战案例】中药数据分析项目实战 目录 Python 机器学习 基础 之 【实战案例】中药数据分析项目实战 一、简单介绍 二、中药数据分析项目实战 三、数据处理与分析实战 1、数据读取 2、中药材数据集的数据处理与分析 2.1数据清洗 2.2、 提取别…...

python中报错“ModuleNotFoundError: No module named ‘docx2txt‘”
python中from langchain_community.document_loaders import Docx2txtLoader报错“ModuleNotFoundError: No module named ‘docx2txt’” 问题描述: python中from langchain_community.document_loaders import Docx2txtLoader报错“ModuleNotFoundError: No module named ‘…...

json.dumps参数
json.dumps()是 Python 中json 模块的一个函数,用于将 Python 对象编码成 JSON格式的字符串。这个函数有几个常用的参数,下面是一些主要的参数及其描述: 1. **obj**: 必需。要转换的 Python 对象。 2. *…...

未来已来,划时代革命性产品——全息数字人管家系统,全网首发
尊敬的投资人、亲爱的网友们: 大家好,我是数字人管家项目总设计师,我叫William wang。在这个科技日新月异的时代,我们正站在一个前所未有的交汇点上,数字与现实的边界日益模糊,智能技术正以前所未有的方式…...

psql导入数据报错排查
问题:采用pg_dump导出表数据后,用psql导入表数据,导入时报错 无效的命令 \N定位该问题的方法 --进入psql \set ON_ERROR_STOP on --退出psqlpsql -U postgres -d test -v ON_ERROR_STOPon < /home/postgres/test.dmp参考文章:…...
项目:双人五子棋对战-对战模块(6)
完整代码见: 邹锦辉个人所有代码: 测试仓库 - Gitee.com 当玩家进入到游戏房间后, 就要开始一局紧张而又刺激的五子棋对战了, 本文将就前端后端的落子与判断胜负的部分作详细讲解. 模块详细讲解 约定前后端交互的接口 首先是建立连接后, 服务器需要生成一些游戏的初始信息(可…...

私域团队如何用企业微信 API 提升客户维护效率?
一、 场景描述:为什么你的团队每天都在“瞎忙”? 很多私域团队看似忙碌,实则效率低下。典型的现象包括: • 重复回答:每天 70% 的时间在复制粘贴相同的话术(如:发货时间、优惠券怎么领ÿ…...

Java集成ChatGPT实战:PlexPt SDK核心功能与生产部署指南
1. 项目概述与核心价值如果你是一名Java开发者,最近正琢磨着怎么在自己的应用里集成ChatGPT的能力,比如做个智能客服、代码助手或者内容生成工具,那你大概率已经搜过一圈了。官方的OpenAI API虽然强大,但直接用在Java项目里&#…...

3分钟掌握:如何在Windows电脑上直接运行安卓应用?APK安装器终极指南
3分钟掌握:如何在Windows电脑上直接运行安卓应用?APK安装器终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接安装…...

RedBox容器编排工具:在Docker与K8s间的轻量级生产实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫Jamailar/RedBox。乍一看这个名字,你可能会联想到一个红色的盒子,或者某种特定的工具。实际上,它确实是一个“盒子”,一个用于构建、管理和部署容器化应用的…...

清华PPT模板:5分钟打造专业学术演示的终极方案
清华PPT模板:5分钟打造专业学术演示的终极方案 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为每一次学术汇报、论文答辩或教学课件而烦恼吗?THU-PPT-Theme清华PPT模板库为你…...

压电定位平台建模与运动控制【附仿真】
✨ 长期致力于压电定位平台、磁滞非线性、反步控制、滑模控制、有限时间控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)Prandtl-Ishlinskii磁滞模…...
)
小驴西藏旅游网站(10018)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

兔抗FANCI抗体亲和纯化,IP-WB全流程兼容设计,一站式解决FANCI蛋白分析功能
产品概述由艾美捷Bethyl Laboratories推出的FANCI抗体(货号A301-254A)是一款针对人源范可尼贫血互补组I蛋白(FANCI)的兔多克隆抗体,经抗原亲和纯化,以未偶联完整IgG形式提供。该抗体特异性识别人源FANCI蛋白…...

Taotoken多模型聚合平台为arm7边缘AI应用提供稳定API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合平台为arm7边缘AI应用提供稳定API服务 对于在arm7架构硬件上部署轻量级AI应用的开发者而言,将大模型…...

GPT-4 Turbo访问权、优先响应、高级数据分析——ChatGPT Plus五大隐藏权益深度拆解,92%用户根本没用全
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Plus订阅值不值得买 ChatGPT Plus 提供每月 $20 的固定订阅服务,主打 GPT-4 模型访问、优先响应队列、文件上传解析(PDF/CSV/TXT 等)及自定义 GPTs 功能。是…...