python实现自动化测试框架如何进行数据参数化?这个包可以了解下
1.数据参数化介绍
只要你是负责编写自动化测试脚本的,数据参数化这个思想你就肯定会用 ,数据参数化的工具你肯定的懂一些 ,因为它能大大的提高我们自动化脚本编写效率 。
1.1什么是数据参数化
所谓的数据参数化 ,是指所执行的测试用例步骤相同、而数据不同 ,每次运行用例只变化的是数据 ,于是将这些数据专门放在一起进行批量循环运行 ,从而完成测试用例执行的目的 。
以登录功能为例 ,若一个登录功能每次操作的步骤是 :
- 输入用户名
- 输入密码
- 点击登录按钮 。
但是,因为每次输入的数据不同,导致生成的测试用例就不同了 ,同样还是这个登录功能,加上数据就变为以下的用例了 。
- case1 : 输入正确的用户名 ,输入正确的密码 ,点击登录
- case2 : 输入正确的用户,输入错误的密码,点击登录
- case3 :输入正确的用户名,输入空的密码,点击登录
- casen : ...
可以看到 ,在这些用例中,每条用例最大的不同是什么呢 ?其实就是数据不同 。但是由于数据不同,从而生成了多条测试用例 ,在功能测试中,这些用例是需要分别写、分别执行 。
1.2.为什么要进行数据参数化 ?
在功能测试中,即使是相同的步骤 ,只是数据不同 ,我们亦然也要尽量分开编写每一条用例 ,比如像上面的编写方式 ,因为这些编写它的易读性更好 ,功能测试设计测试用例和执行用例往往不是一个人 ,所以用例编写的易读性是就是一个很重要的因素 。
但是如果将上面的用例进行自动化实现 ,虽然按照一条用例对应一个方法是一种很清晰的思路 ,但是它的最大问题就是代码冗余 ,当一个功能中步骤相同,只是数据不同时,你的数据越多,代码冗余度就越高 。你会发现每个测试方法中的代码就会是相同的 。
像代码冗余这种问题,在编写自动化时是必须要考虑的一个问题,因为随着代码量越多 ,冗余度越高、越难维护 。
以下就是是通过正常方式实现登录的自动化脚本 :
-
import unittest -
from package_unittest.login import login -
class TestLogin(unittest.TestCase): -
# case1 : 输入正确的用户名和正确的密码进行登录 -
def test_login_success(self): -
expect_reslut = 0 -
actual_result = login('admin','123456').get('code') -
self.assertEqual(expect_reslut,actual_result) -
# case2 : 输入正确的用户名和错误的密码进行登录 -
def test_password_is_wrong(self): -
expect_reslut = 3 -
actual_result = login('admin', '1234567').get('code') -
self.assertEqual(expect_reslut, actual_result) -
# case3 : 输入正确的用户名和空的密码进行登录 -
def test_password_is_null(self): -
expect_reslut = 2 -
actual_result = login('admin', '').get('code') -
self.assertEqual(expect_reslut, actual_result)
可以看到,三条用例对应三个测试方法,虽然清晰 ,代码每个方法中的代码几乎是相同的。
那如果用参数化实现的代码是什么呢 ? 可以看下面的这段代码 :
-
class TestLogin(unittest.TestCase): -
@parameterized.expand(cases) -
def test_login(self,expect_result,username,password): -
actual_result = login(username,password).get('code') -
self.assertEqual(expect_result,actual_result)
以上代码只有一条用例 ,不管这个功能有几条都能执行 。
通过上面两种形式的比较可以看出 :为什么要进行数据参数化呢 ?其实就是降低代码冗余、提高代码复用度 ,将主要编写测试用例的时间转化为编写测试数据上来 。
1.3.如何进行数据参数化
在代码中实现数据参数化都需要借助于外部工具 ,比如专门用于unittest的ddt , 既支持unittest、也支持pytest的parameterized ,专门在pytest中使用的fixture.params .
| 参数化工具 | 支持测试框架 | 备注 |
| ddt | unittest | 第三方包,需要下载安装 |
| parameterized | nose,unittest,pytest | 第三方包,需要下载安装 |
| @pytest.mark.parametrize | pytest | 本身属于pytest中的功能 |
| @pytest.fixture(params=[]) | pytest | 本身属于pytest中的功能 |
以上实现数据参数化的工具有两个共同点:
- 都能实现数据参数化
- 都时装饰器来作用于测试用例脚本 。
2.模块介绍
1.下载安装 :
-
# 下载 -
pip install parameterized -
# 验证 : -
pip show parameterized
2.导包
-
# 直接导入parameterized类 -
from parameterized import parameterized
3.官网示例
@parameterized 和 @parameterized.expand 装饰器接受列表 或元组或参数(...)的可迭代对象,或返回列表或 可迭代:
-
from parameterized import parameterized, param -
# A list of tuples -
@parameterized([ -
(2, 3, 5), -
(3, 5, 8), -
]) -
def test_add(a, b, expected): -
assert_equal(a + b, expected) -
# A list of params -
@parameterized([ -
param("10", 10), -
param("10", 16, base=16), -
]) -
def test_int(str_val, expected, base=10): -
assert_equal(int(str_val, base=base), expected) -
# An iterable of params -
@parameterized( -
param.explicit(*json.loads(line)) -
for line in open("testcases.jsons") -
) -
def test_from_json_file(...): -
... -
# A callable which returns a list of tuples -
def load_test_cases(): -
return [ -
("test1", ), -
("test2", ), -
] -
@parameterized(load_test_cases) -
def test_from_function(name): -
...
请注意,使用迭代器或生成器时,将加载所有项 在测试运行开始之前放入内存(我们显式执行此操作以确保 生成器在多进程或多线程中只耗尽一次 测试环境)。
@parameterized装饰器可以使用测试类方法,并且可以独立使用 功能:
-
from parameterized import parameterized -
class AddTest(object): -
@parameterized([ -
(2, 3, 5), -
]) -
def test_add(self, a, b, expected): -
assert_equal(a + b, expected) -
@parameterized([ -
(2, 3, 5), -
]) -
def test_add(a, b, expected): -
assert_equal(a + b, expected)
@parameterized.expand可用于生成测试方法 无法使用测试生成器的情况(例如,当测试 类是单元测试的一个子类。测试用例):
-
import unittest -
from parameterized import parameterized -
class AddTestCase(unittest.TestCase): -
@parameterized.expand([ -
("2 and 3", 2, 3, 5), -
("3 and 5", 3, 5, 8), -
]) -
def test_add(self, _, a, b, expected): -
assert_equal(a + b, expected)
将创建测试用例:
-
$ nosetests example.py -
test_add_0_2_and_3 (example.AddTestCase) ... ok -
test_add_1_3_and_5 (example.AddTestCase) ... ok -
---------------------------------------------------------------------- -
Ran 2 tests in 0.001s -
OK
请注意,@parameterized.expand 的工作原理是在测试上创建新方法 .class。如果第一个参数是字符串,则该字符串将添加到末尾 的方法名称。例如,上面的测试用例将生成方法test_add_0_2_and_3和test_add_1_3_and_5。
@parameterized.expand 生成的测试用例的名称可以是 使用 name_func 关键字参数进行自定义。该值应 是一个接受三个参数的函数:testcase_func、param_num、 和参数,它应该返回测试用例的名称。testcase_func是要测试的功能,param_num将是 参数列表中测试用例参数的索引,参数(参数的实例)将是将使用的参数。
-
import unittest -
from parameterized import parameterized -
def custom_name_func(testcase_func, param_num, param): -
return "%s_%s" %( -
testcase_func.__name__, -
parameterized.to_safe_name("_".join(str(x) for x in param.args)), -
) -
class AddTestCase(unittest.TestCase): -
@parameterized.expand([ -
(2, 3, 5), -
(2, 3, 5), -
], name_func=custom_name_func) -
def test_add(self, a, b, expected): -
assert_equal(a + b, expected)
将创建测试用例:
-
$ nosetests example.py -
test_add_1_2_3 (example.AddTestCase) ... ok -
test_add_2_3_5 (example.AddTestCase) ... ok -
---------------------------------------------------------------------- -
Ran 2 tests in 0.001s -
OK
param(...) 帮助程序类存储一个特定测试的参数 箱。它可用于将关键字参数传递给测试用例:
-
from parameterized import parameterized, param -
@parameterized([ -
param("10", 10), -
param("10", 16, base=16), -
]) -
def test_int(str_val, expected, base=10): -
assert_equal(int(str_val, base=base), expected)
如果测试用例具有文档字符串,则该测试用例的参数将为 附加到文档字符串的第一行。可以控制此行为 doc_func参数:
-
from parameterized import parameterized -
@parameterized([ -
(1, 2, 3), -
(4, 5, 9), -
]) -
def test_add(a, b, expected): -
""" Test addition. """ -
assert_equal(a + b, expected) -
def my_doc_func(func, num, param): -
return "%s: %s with %s" %(num, func.__name__, param) -
@parameterized([ -
(5, 4, 1), -
(9, 6, 3), -
], doc_func=my_doc_func) -
def test_subtraction(a, b, expected): -
assert_equal(a - b, expected) -
$ nosetests example.py -
Test addition. [with a=1, b=2, expected=3] ... ok -
Test addition. [with a=4, b=5, expected=9] ... ok -
0: test_subtraction with param(*(5, 4, 1)) ... ok -
1: test_subtraction with param(*(9, 6, 3)) ... ok -
---------------------------------------------------------------------- -
Ran 4 tests in 0.001s -
OK
最后@parameterized_class参数化整个类,使用 属性列表或将应用于 .class
-
from yourapp.models import User -
from parameterized import parameterized_class -
@parameterized_class([ -
{ "username": "user_1", "access_level": 1 }, -
{ "username": "user_2", "access_level": 2, "expected_status_code": 404 }, -
]) -
class TestUserAccessLevel(TestCase): -
expected_status_code = 200 -
def setUp(self): -
self.client.force_login(User.objects.get(username=self.username)[0]) -
def test_url_a(self): -
response = self.client.get('/url') -
self.assertEqual(response.status_code, self.expected_status_code) -
def tearDown(self): -
self.client.logout() -
@parameterized_class(("username", "access_level", "expected_status_code"), [ -
("user_1", 1, 200), -
("user_2", 2, 404) -
]) -
class TestUserAccessLevel(TestCase): -
def setUp(self): -
self.client.force_login(User.objects.get(username=self.username)[0]) -
def test_url_a(self): -
response = self.client.get("/url") -
self.assertEqual(response.status_code, self.expected_status_code) -
def tearDown(self): -
self.client.logout()
@parameterized_class装饰器接受class_name_func论点, 它控制由 @parameterized_class 生成的参数化类的名称:
-
from parameterized import parameterized, parameterized_class -
def get_class_name(cls, num, params_dict): -
# By default the generated class named includes either the "name" -
# parameter (if present), or the first string value. This example shows -
# multiple parameters being included in the generated class name: -
return "%s_%s_%s%s" %( -
cls.__name__, -
num, -
parameterized.to_safe_name(params_dict['a']), -
parameterized.to_safe_name(params_dict['b']), -
) -
@parameterized_class([ -
{ "a": "hello", "b": " world!", "expected": "hello world!" }, -
{ "a": "say ", "b": " cheese :)", "expected": "say cheese :)" }, -
], class_name_func=get_class_name) -
class TestConcatenation(TestCase): -
def test_concat(self): -
self.assertEqual(self.a + self.b, self.expected) -
$ nosetests -v test_math.py -
test_concat (test_concat.TestConcatenation_0_hello_world_) ... ok -
test_concat (test_concat.TestConcatenation_0_say_cheese__) ... ok
使用单个参数
如果测试函数只接受一个参数并且该值不可迭代, 然后可以提供值列表,而无需将每个值包装在 元:
-
@parameterized([1, 2, 3]) -
def test_greater_than_zero(value): -
assert value > 0
但请注意,如果单个参数是可迭代的(例如列表或 元组),那么它必须包装在元组、列表或 param(...) 装饰器中:
-
@parameterized([ -
([1, 2, 3], ), -
([3, 3], ), -
([6], ), -
]) -
def test_sums_to_6(numbers): -
assert sum(numbers) == 6
虽然看似以上功能支持的挺多 ,但其实真正用的不多 ,因为它跟框架有很大关系的 。具体说明下 :
总结:
- 它支持nose是最好的 . 如果你的自动化中使用nose,那么以上功能基本都能用到 。
- 如果你用的测试框架是unittest ,你只能用到它的expand()这个函数 ,不过有这个函数也就够了 。
- 如果你用的测试框架是pytest , 它支持了Pytest3的版本,再高版本的就不支持了,同时pytest也有自己的参数化工具,一般也不用它了。
3.项目实践
通过数据参数胡重新编写登录测试用例 ,将以前yaml中的登录用例数据转化为paramterized的数据格式 ,它的数据格式要求为:[(),(),()] . 所以,编写测试用例的数据就变为了以下的代码 。
-
# 将登录数据转化为paramterize所识别的格式。 -
def get_data(): -
yaml_path = get_file_path('login.yaml') # 获取login.yaml的全路径 -
result = read_yaml(yaml_path) # 转化为python对象 -
login_data = result.get('login') # 获取字典中login的值 -
logger.debug("登录结果:{}".format(login_data)) -
return (login_data) # 获取字典中login的值 -
@allure.epic("vshop") -
@allure.story("登录") -
class TestLogin(unittest.TestCase): -
# case1 : 测试登录功能 -
@parameterized.expand(get_data()) -
def test_login(self,case_name,username,password,code,message): -
logger.info("从参数化获取的数据:{}|{}|{}|{}|{}".format(case_name,username,password,code,message)) -
with allure.step("执行用例:{},输入用户名:{},输入密码:{}".format(case_name,username,password)): -
login_result = login(username,password) -
self.assertEqual(code, login_result.get('errno')) -
self.assertEqual(message, login_result.get('errmsg'))
这样的话,我们只编写了一条测试用例 ,但是在测试数据中有几条数据 ,都可以正常运行 。
行动吧,在路上总比一直观望的要好,未来的你肯定会感 谢现在拼搏的自己!如果想学习提升找不到资料,没人答疑解惑时,请及时加入扣群: 455787643,里面有各种软件测试+开发资料和技术可以一起交流学习哦。
总结:感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。
相关文章:
python实现自动化测试框架如何进行数据参数化?这个包可以了解下
1.数据参数化介绍 只要你是负责编写自动化测试脚本的,数据参数化这个思想你就肯定会用 ,数据参数化的工具你肯定的懂一些 ,因为它能大大的提高我们自动化脚本编写效率 。 1.1什么是数据参数化 所谓的数据参数化 ,是指所执行的测…...

面试题:Redis和MySql数据库如何保持数据一致性?
前提引入: 在高并发的场景下,大量的请求直接访问Mysql很容易造成性能问题。所以,我们都会用Redis来做数据的缓存,削减对数据库的请求。但是,Mysql和Redis是两种不同的数据库,如何保证不同数据库之间数据的一…...

直流遥控器 继电器8-10V应用 降压恒压SL3036电源芯片
在现代电子设备中,电源的稳定性和可靠性对于设备的正常运行至关重要。特别是在直流遥控器这类设备中,由于其需要长时间稳定运行且对电压稳定性要求较高,因此选择一款合适的电源芯片显得尤为重要。本文将重点介绍SL3036电源芯片在直流遥控器继…...
论文Abstract怎么写
摘要是你要写的最后一项内容 步骤 首先先通读自己的文章,清楚自己写的文章是研究型还是技术型,适合描述性的摘要还是知识性。 描述性摘要内含研究目的、目标及方向等,不讲研究结果。字数大约100-200字。知识性摘要则包含研究结果,…...
PS系统教程19
渐变与照片调色 增加色彩背景新建图层选好渐变拉选图片渐变 与图层模式结合 也可以变换颜色 看起来比较自然,因为是与人物结合起来 也可以选择系统里面的一些色调 可以进行多次调试...

Excel函数之MAP
MAP 语法 MAP(array, [arrar2], ……, lambda(value,[value2], ……, calculation)) array:需要进行映射的数组,可以有多个 注:多个数组的形状大小尽可能保持一致,否则将出现错误值 value:数组中的每个值,每次取一个值,每个 array 按顺序对应一个 value calculation:…...
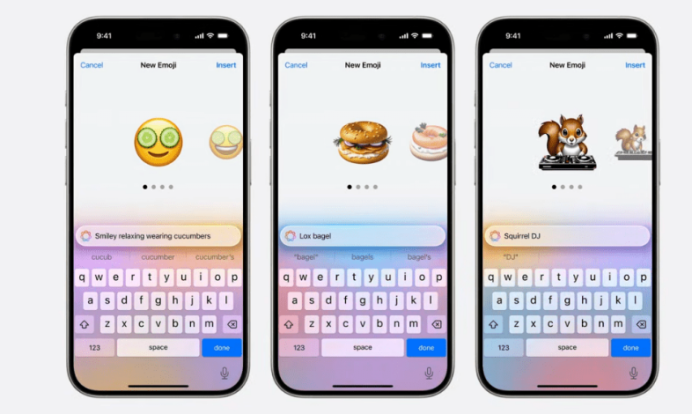
在2024年WWDC大会上,苹果宣布了其全新的“Apple Intelligence”AI功能以及ISO18功能
以下是一些主要的新增功能: Apple WWDC 2024开发者大会6月11日凌晨在总部Apple Park举行 1.智能照片编辑: 照片:AI驱动的照片润饰功能,可以根据用户描述生成自定义表情符号 2.Safari浏览助手: Safari:AI助手能够总…...
解决linux jenkins要求JDK版本与项目版本JDK不一致问题
背景–问题描述: 新入职公司,交接人说jenkins运行有问题,现在都是手动发布,具体原因让我自己看(笑哭)。我人都蒙了,测试环境都手动发布,那不是麻烦的要死! 接手后&am…...

推荐一款WPF绘图插件OxyPlot
开始 使用 NuGet 包管理器添加对 OxyPlot 的引用(如果要使用预发布包,请参阅下面的详细信息)向用户界面添加PlotView在代码中创建一个PlotModel绑定到你的属性PlotModelModelPlotView 例子 您可以在代码存储库的文件夹中找到示例。/Source/Ex…...

普通表在线重定义为分区表
普通表在线转换成分区表示例 源表表结构如下: CREATE TABLE EDC_SEPERATOR ( SEPERATOR_ID NUMBER(15) NOT NULL, EQUIPMENTINFO NVARCHAR2(20), RECORD NVARCHAR2(50), TITLE NVARCHAR2(50), ID NVARCHAR2(50), TE…...

自动驾驶场景下TCP协议参数优化调整案例分享
RTT 往返时间,从tcp协议栈决定发包,到收到回包的时间。 包含本地驱动,网卡硬件,网线,交换机,收包方处理的耗时。需注意如果开了delayed ack,协议栈未做特殊处理(默认没做ÿ…...

奇思妙想:多头RAG
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提…...
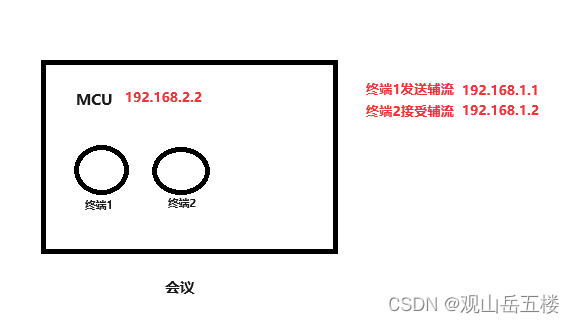
H323 截包分析辅流问题
辅流问题(h264\h264hp\h265) 终端1 : 192.168.1.1 入会发送辅流 终端2 : 192.168.1.2 入会接收辅流 问题 : 终端2不显示辅流 1、筛选 h245 h225 协议 分别筛选以下IP进行查看截包内容 (h225 || h245) && …...
低成本和颜值兼顾的 HomeLab 设备:HPE MicroServer Gen10(二)
本篇文章,继续分享另外一台端午假期折腾的设备,HP MicroServer Gen10 一代。同样分享下我的折腾思路,希望能够帮助到有类似需求的你。 写在前面 Gen10 “标准版”(第一代)和 Plus 版本设计风格一致,同样颜…...
面试题:ArrayList和LinkedList的区别
ArrayList和LinkedList都是Java中实现List接口的集合类,用于存储和操作对象列表,但它们在内部数据结构、性能特性和适用场景上有所不同: 1.内部数据结构: ArrayList:基于动态数组实现。这意味着它在内存中是连续存储…...

【王树森】深度强化学习(DRL)学习笔记
目录 第一部分:基础知识1.机器学习基础2.蒙特卡洛估计3.强化学习基础知识3.1 马尔科夫决策过程马尔可夫决策过程(Markov decision process,MDP)智能体环境状态状态空间动作动作空间奖励状态转移状态转移概率 3.2 策略策略定义 3.3…...

LLM应用实战:当图谱问答(KBQA)集成大模型(三)
1. 背景 最近比较忙(也有点茫),本qiang~想切入多模态大模型领域,所以一直在潜心研读中... 本次的更新内容主要是响应图谱问答集成LLM项目中反馈问题的优化总结,对KBQA集成LLM不熟悉的客官可以翻翻之前的文章《LLM应用实战:当KBQ…...

Django框架中Ajax GET与POST请求的实战应用
系列文章目录 以下几篇侧重点为JavaScript内容0.0 JavaScript入门宝典:核心知识全攻略(上)JavaScript入门宝典:核心知识全攻略(下)Django框架中Ajax GET与POST请求的实战应用VSCode调试揭秘:L…...

web前端怎么挣钱, 提升技能,拓宽就业渠道
web前端怎么挣钱 在当今数字化时代,Web前端技术已成为互联网行业中不可或缺的一部分。越来越多的人选择投身于这个领域,希望能够通过掌握前端技术来实现自己的职业发展和经济收益。那么,Web前端如何挣钱呢?接下来,我们…...

基于Python的信号处理(包络谱,低通、高通、带通滤波,初级特征提取,机器学习,短时傅里叶变换)及轴承故障诊断探索
Python是一种广泛使用的解释型、高级和通用的编程语言,众多的开源科学计算软件包都提供了Python接口,如计算机视觉库OpenCV、可视化工具库VTK等。Python专用计算扩展库,如NumPy、SciPy、matplotlab、Pandas、scikit-learn等。 开发工具上可用…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...

雨夜便利店的光,刚好够照亮你这一秒的疲惫
雨声比闹钟更懂你凌晨一点十七分,耳机里循环着一首没名字的 lo-fi beat,窗外的雨没停,也没下大,就那么轻轻敲着空调外机和生锈的铁皮棚。你站在楼道口犹豫要不要出门买泡面,其实不是饿,是心里空了一小块&am…...
)
别再只会点灯了!用51单片机和继电器模块,做个智能插座控制台灯(附完整代码)
从点灯到智能家居:51单片机与继电器模块的实战进阶指南 当你已经能够熟练地用51单片机点亮LED灯时,是否想过将这些基础技能转化为实际生活中的实用工具?本文将带你跨越实验板与真实世界的鸿沟,用最常见的51单片机和继电器模块&…...

从零构建大模型推理引擎:KV缓存、算子融合与量化优化实战
1. 项目概述:从零理解大模型推理引擎如果你正在关注大语言模型(LLM)的实际应用,特别是如何让这些动辄数百亿参数的“庞然大物”在你的本地机器或服务器上高效地跑起来,那么你很可能已经听说过“推理引擎”这个词。anik…...

揭秘AI教材生成秘诀!AI教材写作工具助力,低查重完成20万字教材!
教材编写难题与AI工具解决方案 在编写教材时,如何才能精准满足不同的需求呢?不同学段的学生在认知能力上存在显著差异,内容过于复杂或简单都不合适;而在课堂教学和自主学习等不同场景下,对教材的要求又各不相同&#…...

AI决策公平性:司法审查下的技术实践与算法治理
1. 项目概述:当算法成为“法官”,公平如何被审查?最近几年,我参与和观察了不少涉及算法决策的项目,从信贷审批到招聘筛选,再到内容推荐。一个越来越无法回避的问题是:当AI系统代替人类做出影响个…...

终极百度网盘加速解决方案:BaiduPCS-Web完整使用指南
终极百度网盘加速解决方案:BaiduPCS-Web完整使用指南 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在为百度网盘那令人抓狂的下载速度而烦恼吗?当下载进度条像蜗牛一样缓慢移动时,你是…...

Perplexity AI集成开发工具:MCP协议与零成本API实战指南
1. 项目概述:将Perplexity AI深度集成到你的开发工作流 如果你是一名开发者,或者经常需要处理信息检索、代码问题排查、技术方案调研这类工作,那么你肯定对“搜索”这件事又爱又恨。爱的是它能瞬间连接海量知识,恨的是在IDE和浏览…...

WeChatMsg:如何用开源工具构建你的个人数字记忆库
WeChatMsg:如何用开源工具构建你的个人数字记忆库 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg…...

STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳?
STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳? 调试STM32与PCF8591的模拟I2C通信时,AD/DA数据跳动是开发者最常遇到的棘手问题。本文将深入分析数据不稳定的根源,并提供一套完整的解决方案。不同于基础教程&#x…...