自动驾驶场景下TCP协议参数优化调整案例分享
RTT
往返时间,从tcp协议栈决定发包,到收到回包的时间。
包含本地驱动,网卡硬件,网线,交换机,收包方处理的耗时。需注意如果开了delayed ack,协议栈未做特殊处理(默认没做),则RTT可能包含delayed ack时间。
delay ack
理论上来说有可能会延迟40ms发ack;实际对我们来说概率非常小,详见delayed ack代码和实车环境影响分析
cwnd 40
拥塞窗口。in flights数据包的数量不能大于cwnd。linux是按照包数而不是数据字节来管理的。
当开启gso后,会根据skb→size / mss来计算发出的包量;4.9的内核收到ack时也会按照确认的包数量扩大拥塞窗口(老内核不是)。
所以gso不影响拥塞窗口计算。
initcwnd 30
初始拥塞窗口。当连接刚建立,或者重置拥塞窗口时,使用这个值。
RTO 4ms
如果发出的数据包,未得到回复,会在rto时间之后进行重传。
在丢包场景下,rto就是丢包带来的额外延迟。
linux内核代码写死了全局rto_min=200ms,可以通过路由表ip route change ..... rto_min 10ms覆盖全局的rto_min
rto需要跟quickack联动,默认delayed ack可能40ms才回ack包,rto_min < ack时间可能导致大量无效重传。
快速重传
当收到3个“错误”的ack时,对未确认数据包进行重传。
涉及的扩展算法较多,对我们影响不大,不展开。
TLP 4ms
当发包端最后一个数据包丢包时,响应ack达不到三个,无法触发快速重传。
此时会把最后一个包重传一下,触发对端响应。
但在linux内核实现时,TLP和RTO共用了一个定时器;
判断1: tlp时间 = max(..., 200ms),这200ms是写死的,除了改内核代码外无法修改
接着判断2: tlp时间 = min( tlp时间, rto时间)
因为rto_min可以被路由表覆盖,实际上在我们修改rto_min后,tlp时间等于rto时间
从结果上来看,非常的蛋疼。因为在局域网情况下,TLP时间总是小于RTO时间,导致未能起到尽快触发重传的效果,反而还抢了RTO的定时器
TODO 实验记录单独记录文档,引用到这里
下图中 8253 就是一个 TLP 包,因为 50362853 + 12567 - 983 = 50374437。12ms 后重传了尾包

cubic
linux默认使用的拥塞控制算法。windows多个版本也是使用此算法。
启动时使用initcwnd,每个rtt窗口倍增,达到ssthresh后线性增长。
发生丢包时cwnd=1,同时调整ssthresh。丢包的cwnd=1是在tcp协议栈写死的,不受拥塞控制算法影响,见tcp_enter_lost函数。
bbr
google做的拥塞控制算法,bbr比传统拥塞策略要先进很多,主要体现在:
1 摒弃了用丢包触发限速的策略,会通过延迟的变动来调整对网络情况的探测;
2 除了in flights包数量控制外,还会控制发包的频率间隔。
但是bbr的很多设计细节不适合自动驾驶领域。
例如对rtt<1ms场景的适配,传输的DAG优先级,定频流量场景等都可以做针对性优化,能取得非常大的提升。
长期来看我们会针对自动驾驶场景自己写拥塞算法,故不把使用bbr算法纳入计划中。
备注:平行驾驶推流通常会内置拥塞算法,这里建议尝试bbr。
gso/gro
gso允许tcp协议栈直接发送大报文,且无需计算checksum,由网卡负责拆包+计算checksum。
gro是在napi类型的网卡中断处理时,将一次循环中收到的数据包合并后,再交给上层协议栈处理。(napi是硬中断触发后一直轮询直到数据为空)
在我们用的4.9版本内核里,拥塞窗口的变动考虑了gso/gro的情况。
gso/gro会导致tcp协议栈收发的数据包尺寸大于mss和mtu,并减少收发的包数量。会带来一定的附加影响。
从实车抓包来看,收包方抓到的包基本都经过gro处理,发包方收到的ack也是明显收到gro影响的。
但是结合内核gro相关代码 + 火焰图分析来看,感觉gro触发几率很小。gro收包的CPU占用0.08,普通收包的CPU占用2.74。
不确定是分析过程有问题,还是xavier在网卡硬件层面实现了gro。
时间有限不展开分析,后续相信实际抓包情况,认为gro大量生效。
TODO-低优先级:分析gro生效路径
二 自动驾驶的网络模型分析
网络丢包的理论模型
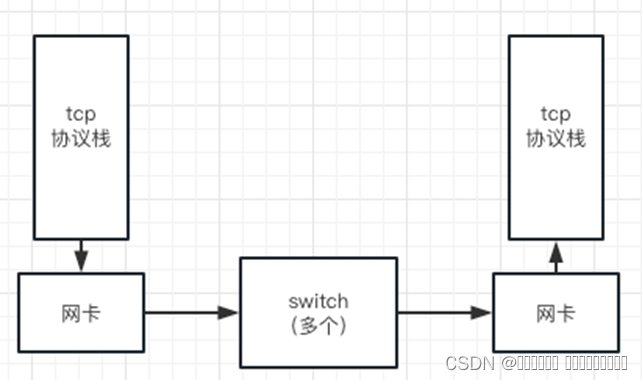
上图是一个简化的从发包到收包的环节描述。
各个环节都可能因为故障导致丢包,如md5错误,网卡硬件错误等。
因故障导致的丢包,在正常环境中是非常非常少见的。一般出现在网口接触不良,网线损坏等情况下。
除了故障之外,各环节的缓冲区满也会导致丢包,这是实际场景中最常见的情况。
例如xavier的内置switch是SJA1105型号,根据其手册buffer=128KB,根据我们的实验测试,也能得到相应的结论。
xavier上linux内核的发包缓冲区满时,会阻止socket发包(socket不可写);收包缓冲区满时tcp的滑动窗口会降为0。
故重点考察的是网卡和switch缓冲区满导致的丢包。
无论是对网卡,还是switch,当入流量 > 出流量时,缓冲区开始积压,积压超过buffer size时就会丢包。
根据我们的实验可以证明这一点:
TODO 这里单抽一个文档,贴代码,测试环境,详细记录,引用到这里
udp发包实验测网卡缓冲区大小:
1400字节,10us一个包,延迟增加1800us左右开始丢包。即180个包,250KB积压开始丢包。
700字节,设10us一个包,实际7.7ms左右一个包,延迟增加3000us左右开始丢包(不稳定,可能是发包速率就不稳定)。即390个包,273KB积压开始丢包。
14000字节,100us一个包,延迟增加1800us左右开始丢包。即18个包,250KB积压开始丢包。
根据实车观察,一旦触发丢包,会在几毫秒内有很大的丢包率。
现象1:dup ack很少,远少于rto/tlp超时触发的次数。
现象2: rto/tlp触发时,一般都是连续一段数据都需要重传。
这个现象符合理论分析。当入流量>出流量时,缓冲区增加,当缓冲区满时丢包。
一旦触发丢包,入流量无改善的情况下,会有相当高的丢包率。
带宽 ,RTT,窗口
带宽/ms = 窗口 * 每ms包数量 = 窗口 ÷ RTT
以xavier的1Gb/s网络计算:
每个数据包的发送速度 = 1.5KB ÷ 1Gb/s = 0.012ms
打满1Gb/s带宽,需要每秒传输83个1.5KB的数据包 => 打满1Gb/s带宽,窗口 >= 83 * rtt
以switch 128KB buffer计算:
积压85个包会打满缓冲区,85 * 0.012ms = 1ms,即当入流量大于出流量时,缓存积压的包会增加,由此会导致rtt上升。
这也是bbr基于rtt变化调整发送速率的理论基础。
使用ss -i -t实车观察rtt:
在网络良好且空闲时一般在0.25ms左右;
在流量上升时,一般在0.5-1ms(缓存积压+收包端CPU0繁忙导致耗时增加);
如果持续超过1.6ms,一般丢包就比较严重了。
因为是手动采集了100多次数据做的观察,具体数值不够准确,但大致趋势应该是没错的。
实验:rtt,带宽随cwnd变化
不锁的情况,speed [829.35 Mb/s],rtt:1.467/0.181,cwnd:149
锁40的情况,见抓包no_drop,speed [781.53 Mb/s],rtt:0.408/0.08,cwnd:40
锁30的情况,speed [707.76 Mb/s],rtt:0.314/0.057,cwnd:30
锁20的情况,speed [590.34 Mb/s],rtt:0.293/0.059,cwnd:20
自动驾驶的场景特征
1 自动驾驶中大多数流量,是定频发生的。
2 不同流量(topic)有不同的优先级(DAG优先级)。
3 硬件环境是已知的,如6*xavier的网络拓扑,2*orin的网络拓扑。当实际探测到的硬件环境与设计不符时,应报故障并做降级处理。
丢包场景分两种:
场景1 MAP在中间件中的多个topic流量同时触发。此场景的特点是持续时间短,一般<10ms。
场景2 MAP之外的持续大流量。此场景具有不确定性,如果有人手动拷数据包,则可能是持续十几分钟的高丢包环境。
场景3 MAP之外的短暂大流量。如filebeat突然上传数据,激光雷达的udp点云。
目前根据在多个车型上tcpdump抓包总计3小时观察,丢包在80%的情况下持续<10ms,20%的情况下持续10-20ms,尚未看到前后两帧数据(间隔100ms)都出现丢包的情况。
TODO-重点:通过毫秒级流量监控,做更全面的流量模型分析
三 参数调整方案
可以调整的方案,重点集中在几组:
修改重传间隔: rto_min + quickack,TLP开关
修改窗口上限:tcp_rmem控制滑动窗口,路由表cwnd_limit控制拥塞窗口上限
修改窗口初始值:initcwnd + ssthresh + tcp_slow_start_after_idle
修改快速重传门限:tcp_reordering
参数含义和修改方法参考:ip route下的tcp参数设置 /proc/sys/net/ipv4/tcp相关参数说明
1 重传间隔修改
因无法完全规避丢包,通过修改重传间隔可以减少丢包带来的影响。
根据前面的理论分析,switch缓冲区打满最多使得rtt上升1ms。
实车观察到的rtt,最高到1.87ms,同一时刻的tcpdump已能观察到较多丢包。
即使再计算收包方CPU0打满的情况,最多也是增加2ms延迟(网卡硬件缓冲区满丢包)。
理论上在有TLP时,无效重传应该不会很多。改到8ms可能都是可行的,但是不确定各种极端场景下是否会触发大量无效重传,需要大量测试&观察验证。
稳妥起见,将rto_min设置为10ms,实车观察到的rto都是16ms。这是因为rto_min设置有坑,具体看ip route下的tcp参数设置内关于rto_min的描述
TODO-重点:实车调参,尝试把rto_min降低到7ms,看是否会触发大量无效重传。
TLP开关默认开启,不需要关闭
关闭的收益是在丢包发生时,直接开始重传,减少一次rtt耗时。在已经发送丢包的情况下,这一次rtt的耗时不算什么。
打开的收益是在ack丢包时,不按丢包的流程走(会把cwnd降低为1),更友好。
理论上即使关闭了TLP影响也不大,因为还有“拥塞撤销机制”:
当触发重传,ack回包发现不需要重传时,cwnd会回复。但是具体效果得详细看内核代码+测试,时间有限未深入确认。
保险起见可以不关闭TLP。
2 窗口上限修改
拥塞窗口管理的是in flight数据包总数。这些数据包可能在各个环节上跑着(也可能丢了)。
考虑到各环节都是需要耗时的,cwnd通常不会全都集中在switch buffer上。
但是在空闲时突然发包的情况下,cwnd更容易集中卡在一个点上,比较危险。
这里给出两个典型值:
1 cwnd_limit=80
即使运气不好,单个tcp连接的in flight数据包都积压在switch buffer上,也不会丢包。
当rtt=1ms时,单tcp连接可以把流量打到800Mb/s以上,完全够用了。
即使网络环境差rtt=1.5ms,单tcp连接可以把流量打到650Mb/s以上,也是够用的。
2 cwnd_limit=40
即使运气很不好,两个tcp连接的in flight数据包都积压在switch buffer上,也不会丢包。
在rtt=0.8ms时,单tcp连接可以把流量打到500Mb/s以上,不是特别好,基本也够用。
在rtt=0.5ms时,单tcp连接可以把流量打到700Mb/s以上,够用了。
从另一个角度来看,cwnd=40 => 60KB/rtt,60KB以下数据一次rtt时间,120KB两次rtt时间,180KB三次rtt时间可以完成传输
cwnd_limit=40等于是牺牲一定的平均延迟,来降低丢包率
TODO-重点-优先:实车观察丢包时流量超标原因,调参。
如果丢包原因不受我们控制,例如一个topic给三端发,或者udp流量,或者102-106之外的大流量,则cwnd_limit倾向于调到80
另外cwnd_limit对丢包的影响可能需要较长时间观察。可以调整一个cwnd值观察几天/一周,确保统计数据稳定后,换cwnd值继续观察。作为偏长期的技术优化项
目前cwnd提测给的40,观察了四辆车*三天,统计数据没有观察到p50,p90,p99,p999传输延迟上升。
但是也未能观察到丢包率下降。需通过毫秒级监控分析引发丢包的主要原因。
备注:通过抓包能看到cwnd设置是生效的。
3 窗口初始值修改
tcp_slow_start_after_idle默认打开,不修改。
打开的理由:
1 在我们的环境下,丢包几乎不会持续到100ms以上,所以10HZ定频的topic不需要在发下一帧时继承上一帧的窗口设置。
2 这是全局参数,影响所有连接,需要考虑对平行驾驶,鹰眼,大屏,数据上云等业务等影响,修改有风险。
3 如果一个连接“在使用中增长cwnd”,其cwnd对应的in flight数据包通常分布在各个环节上;而从空闲开始突然按cwnd发包的连接,有更大的概率将in flight数据包集中在一个环节上从而引起丢包。
通过重置,可以避免空闲状态下,直接使用之前的大cwnd连续发出大流量。
102-107之间的流量设置了cwnd上限,此问题不突出,对未受我们管理的其他业务有很大的价值。遗憾的是其他业务的rto_min也未做调整,需要200ms空闲才会重置cwnd。
TODO-重点:如实车观察到大屏/鹰眼业务的突发流量导致大量丢包,出相应解决方案,例如telemtics通过setsockopt设置tcp参数。
initcwnd暂定30, ssthresh暂定40:
设置逻辑:
传统拥塞控制中,不丢包就增加cwnd,丢包就降为1这个策略太傻了。
增加策略会顶着rtt上升,奔着丢包而去。
丢包之后又自己把自己按在地上摩擦。
通过将initcwnd设置到接近cwnd_limit,ssthresh设置为cwnd_limit,直接初始化时就按我们的理想速率发送。
之所以initcwnd略小于cwnd_limit,是为了避免在空闲时直接while循环发出cwnd大小数据,导致数据包集中在一个环节上。
修改cwnd_limit后,需要记得同步修改initcwnd和cwnd_limit
4 快速重传门限
不修改
理论上来说,在开启gro后,由于收包方收到的是合并后的数据包,回复的ack会显著变少。而且当连续10ms丢包率都较高时,ack会进一步减少。
在我们的场景下,快速重传未能发挥原本tcp协议设计中的作用。
从实车抓包来看:
现象1:dup ack很少,连续三个dup ack非常少,远少于rto/tlp超时触发的次数。很少看到有触发快速重传的场景。
现象2: rto/tlp触发时,一般都是连续一段数据都需要重传。丢包经常有连续性。
tcp_reordering参数可以把默认的三个dup ack包触发快速重传,改成一个或两个dup ack即触发快速重传。(改更大也行)
考虑到以下几个因素,本次不做改动:
1 这是全局参数,影响所有连接,需要考虑对平行驾驶,鹰眼,大屏,数据上云等业务等影响,修改有风险。
2 从实车抓包来看,即使快速重传门限改成1,也只是减少5-10%的超时重传。收益不是非常大。
5 优化指标
从结果来看,我们要优化的是两个指标:
1 降低因丢包-超时重传引起高延迟的概率
观察pub_recv./local_planning.p99的各分位数值
此延迟一般会存在跳变,从未触发超时重传的个位数毫秒,跳变到丢包的16+ms。
找出现跳变的百分位数值,大致上可以判断超时重传出现的概率。
目前尚未观察到明显优化,需依赖340的毫秒级流量监控分析丢包瞬间流量打满的原因。
2 降低发生丢包-超时重传后带来的延迟
直接看pub_recv./local_planning的p99.p99数值即可。
目前已可以从100ms降低到20ms左右,调整rto_min可进一步降低。
相关文章:

自动驾驶场景下TCP协议参数优化调整案例分享
RTT 往返时间,从tcp协议栈决定发包,到收到回包的时间。 包含本地驱动,网卡硬件,网线,交换机,收包方处理的耗时。需注意如果开了delayed ack,协议栈未做特殊处理(默认没做ÿ…...

奇思妙想:多头RAG
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提…...
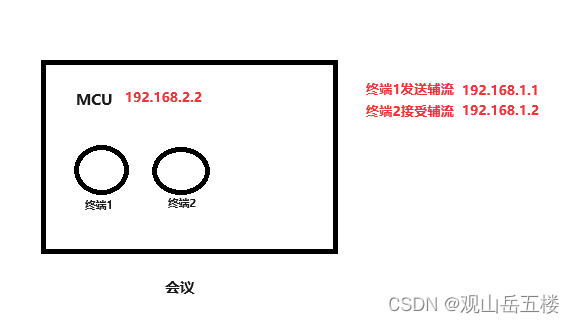
H323 截包分析辅流问题
辅流问题(h264\h264hp\h265) 终端1 : 192.168.1.1 入会发送辅流 终端2 : 192.168.1.2 入会接收辅流 问题 : 终端2不显示辅流 1、筛选 h245 h225 协议 分别筛选以下IP进行查看截包内容 (h225 || h245) && …...
低成本和颜值兼顾的 HomeLab 设备:HPE MicroServer Gen10(二)
本篇文章,继续分享另外一台端午假期折腾的设备,HP MicroServer Gen10 一代。同样分享下我的折腾思路,希望能够帮助到有类似需求的你。 写在前面 Gen10 “标准版”(第一代)和 Plus 版本设计风格一致,同样颜…...
面试题:ArrayList和LinkedList的区别
ArrayList和LinkedList都是Java中实现List接口的集合类,用于存储和操作对象列表,但它们在内部数据结构、性能特性和适用场景上有所不同: 1.内部数据结构: ArrayList:基于动态数组实现。这意味着它在内存中是连续存储…...

【王树森】深度强化学习(DRL)学习笔记
目录 第一部分:基础知识1.机器学习基础2.蒙特卡洛估计3.强化学习基础知识3.1 马尔科夫决策过程马尔可夫决策过程(Markov decision process,MDP)智能体环境状态状态空间动作动作空间奖励状态转移状态转移概率 3.2 策略策略定义 3.3…...

LLM应用实战:当图谱问答(KBQA)集成大模型(三)
1. 背景 最近比较忙(也有点茫),本qiang~想切入多模态大模型领域,所以一直在潜心研读中... 本次的更新内容主要是响应图谱问答集成LLM项目中反馈问题的优化总结,对KBQA集成LLM不熟悉的客官可以翻翻之前的文章《LLM应用实战:当KBQ…...

Django框架中Ajax GET与POST请求的实战应用
系列文章目录 以下几篇侧重点为JavaScript内容0.0 JavaScript入门宝典:核心知识全攻略(上)JavaScript入门宝典:核心知识全攻略(下)Django框架中Ajax GET与POST请求的实战应用VSCode调试揭秘:L…...

web前端怎么挣钱, 提升技能,拓宽就业渠道
web前端怎么挣钱 在当今数字化时代,Web前端技术已成为互联网行业中不可或缺的一部分。越来越多的人选择投身于这个领域,希望能够通过掌握前端技术来实现自己的职业发展和经济收益。那么,Web前端如何挣钱呢?接下来,我们…...

基于Python的信号处理(包络谱,低通、高通、带通滤波,初级特征提取,机器学习,短时傅里叶变换)及轴承故障诊断探索
Python是一种广泛使用的解释型、高级和通用的编程语言,众多的开源科学计算软件包都提供了Python接口,如计算机视觉库OpenCV、可视化工具库VTK等。Python专用计算扩展库,如NumPy、SciPy、matplotlab、Pandas、scikit-learn等。 开发工具上可用…...

大型语言模型智能体(LLM Agent)在实际使用的五大问题
在这篇文章中,我将讨论人们在将代理系统投入生产过程中经常遇到的五个主要问题。我将尽量保持框架中立,尽管某些问题在特定框架中更加常见。 1. 可靠性问题 可靠性是所有代理系统面临的最大问题。很多公司对代理系统的复杂任务持谨慎态度,因…...
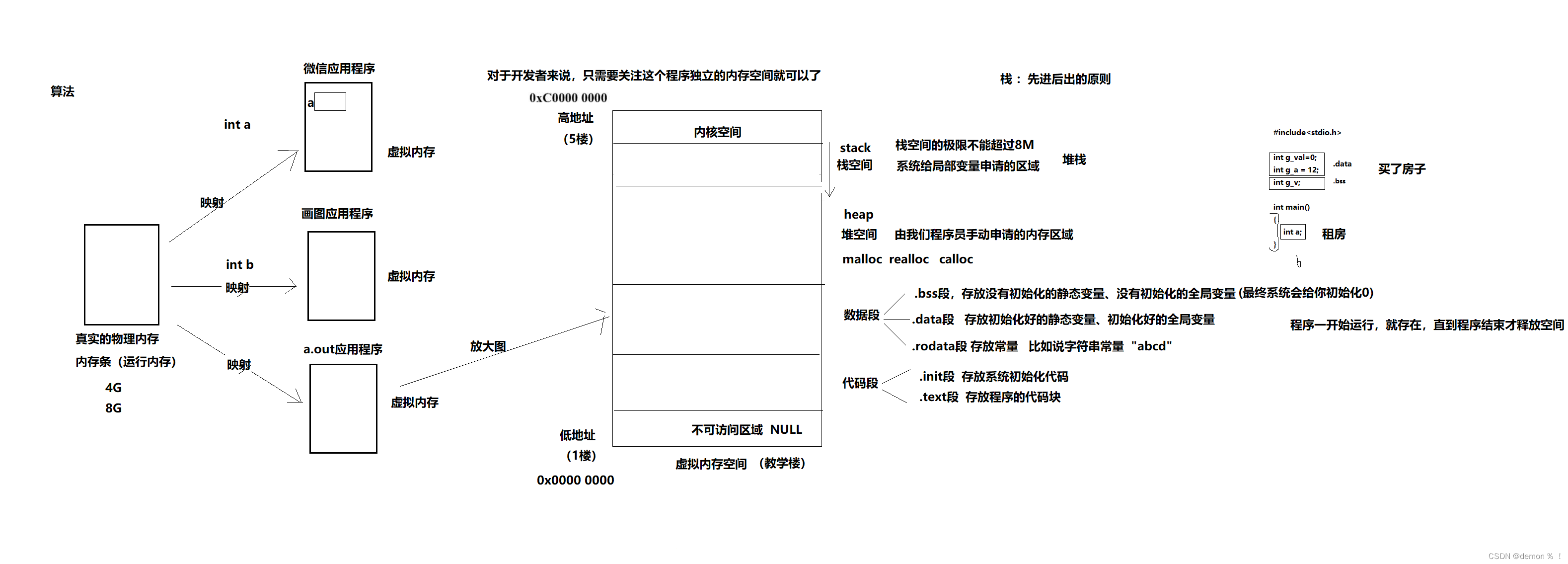
C语言内存管理
1.进程的内存分布 练习:编写一个程序,测试栈空间的大小 #include<stdio.h>#define SIZE 1024*1024*7void main (void) {char buf[SIZE];buf[SIZE-1] 100;printf("%d\n",buf[SIZE-1]); }如果SIZE 大小超过8M(102410248),…...
AD24设计步骤
一、元件库的创建 1、AD工程创建 然后创建原理图、PCB、库等文件 2、电阻容模型的创建 注意:防止管脚时设置栅格大小为100mil,防止线段等可以设置小一点,快捷键vgs设置栅格大小。 1.管脚的设置 2.元件的设置 3、IC类元件的创建 4、排针类元件模型创建…...

基于MBD的大飞机模块化广域协同研制
引言 借鉴国外航空企业先进经验,在国内,飞机型号的研制通常采用基于模型定义(MBD)的三维数模作为唯一的设计制造协同数据源,从而有效减少了设计和制造部门之间的模型沟通成本和重构所需的时间,也减少或避免…...

鸿蒙轻内核M核源码分析系列二十 Newlib C
LiteOS-M内核LibC实现有2种,可以根据需求进行二选一,分别是musl libC和newlibc。本文先学习下Newlib C的实现代码。文中所涉及的源码,均可以在开源站点https://gitee.com/openharmony/kernel_liteos_m 获取。 使用Musl C库的时候,…...

力扣1818.绝对差值和
力扣1818.绝对差值和 把nums1拷贝复制一份 去重排序 对于每个nums2都找到差距最小的那个数(二分) 作差求最大可优化差值去重排序可以直接用set 自动去重排序了 const int N 1e97;class Solution {public:int minAbsoluteSumDiff(vector<int>& nums1, vector<i…...
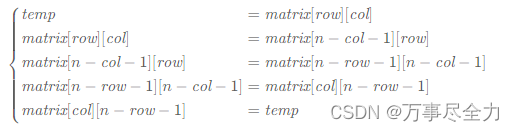
矩阵练习2
48.旋转图像 规律: 对于矩阵中第 i行的第 j 个元素,在旋转后,它出现在倒数第i 列的第 j 个位置。 matrix[col][n−row−1]matrix[row][col] 可以使用辅助数组,如果不想使用额外的内存,可以用一个临时变量 。 还可以通…...
2024海南省大数据教师培训-Hadoop集群部署
前言 本文将详细介绍Hadoop分布式计算框架的来源,架构和应用场景,并附上最详细的集群搭建教程,能更好的帮助各位老师和同学们迅速了解和部署Hadoop框架来进行生产力和学习方面的应用。 一、Hadoop介绍 Hadoop是一个开源的分布式计算框架&…...

力扣算法题:将数字变为0的操作次数--多语言实现
无意间看到,力扣存算法代码居然还得升级vip。。。好吧,我自己存吧 golang: func numberOfSteps(num int) int {steps : 0for num > 0 {if num%2 0 {num / 2} else {num - 1}steps}return steps } javascript: /*** param {number} num…...

vue前段处理时间格式,设置开始时间为00:00:00,设置结束时间为23:59:59
在Vue开发中,要在前端控制日期时间选择器的时间范围,可以通过以下方式实现: 使用beforeDestroy生命周期钩子函数来处理时间范围: 在Vue组件中,可以监听日期时间选择器的变化,在选择开始日期时,自…...

收藏!小白程序员必看:从AI提效到重构产品,企业智能转型4阶段实战指南
本文深入探讨了企业如何拥抱智能时代,通过4个阶段实现AI落地。从提升内部效率开始,逐步激活沉睡数据,重构产品价值,最终形成深场景智能闭环。强调AI不应仅用于替代人工,更要关注为客户创造新价值、提升产品智能化&…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...

AJV布尔验证终极指南:掌握JSON Schema中最简单的数据类型处理技巧
AJV布尔验证终极指南:掌握JSON Schema中最简单的数据类型处理技巧 【免费下载链接】ajv The fastest JSON schema Validator. Supports JSON Schema draft-04/06/07/2019-09/2020-12 and JSON Type Definition (RFC8927) 项目地址: https://gitcode.com/gh_mirror…...

【C++ 多态】虚函数 · 虚表 · 重写,一篇彻底弄明白!
C 多态详解 C多态是面向对象的核心灵魂,本文将由浅入深,带你循序渐进地掌握多态的方方面面,全程干货,坐稳发车~ ദ്ദി˶ー̀֊ー́ )✧ 文章目录C 多态详解1. 什么是多态?2. 运行时多态的实现前…...
零成本复现SlowFast视频动作识别,附完整配置文件与避坑指南)
手把手教你用云GPU(极链AI云)零成本复现SlowFast视频动作识别,附完整配置文件与避坑指南
零成本云端复现SlowFast视频动作识别全攻略:极链AI云实战与参数精解 在计算机视觉领域,视频理解一直是个充满挑战的方向。不同于静态图像,视频数据包含丰富的时序信息,这对模型架构设计提出了更高要求。SlowFast作为Facebook AI R…...

从找石油到防灾害:地震勘探技术如何跨界守护城市安全?
地震勘探技术的跨界革命:从油气勘探到城市安全守护者 上世纪20年代,当第一批地球物理学家尝试用炸药激发地震波来寻找石油时,他们或许不会想到,这项技术会在百年后成为保护现代城市安全的"透视眼"。传统的地震勘探技术…...

基于MCP协议与HaE工具构建AI安全情报助手实战指南
1. 项目概述:一个为安全工程师量身定制的“情报雷达”如果你是一名安全工程师、渗透测试人员或者负责企业安全运营的从业者,那么你一定对“信息收集”和“威胁情报”这两个词深有体会。每天,我们都需要从海量的数据源中——无论是公开的漏洞库…...

如何在Windows电脑上轻松安装安卓应用:5步完成轻量级跨平台部署
如何在Windows电脑上轻松安装安卓应用:5步完成轻量级跨平台部署 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上运行安卓应用&…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

一次搞清楚:Agent、Skill、Prompt、MCP
文章深入探讨了AI Agent在落地过程中面临的三大核心痛点:Prompt的临时性与不可复用性、Agent专业能力的难以沉淀与迁移、以及AI能力无法融入现有工程化流程。文章提出Agent Skills作为AI Agent的专业能力说明书,通过标准化能力描述与执行框架,…...