使用Hadoop MapReduce实现各省学生总分降序排序,根据省份分出输出到不同文件
使用Hadoop MapReduce实现各省学生总分降序排序,根据省份分出输出到不同文件
本文将展示如何使用Hadoop MapReduce对一组学生成绩数据进行处理,将各省的学生成绩按总分降序排序并按照省份进行分区将结果分别输出到不同的文件中。
数据样例
我们将使用以下格式的数据:

实现步骤
我们将通过以下步骤来实现这一目标:
**1、Mapper类:**解析每一行数据,提取省份和总分,并输出为键值对。
**2、Reducer类:**对每个省份的数据按总分降序排序后输出到相应的文件中。
**3、Partitioner类:**确保同一省份的数据被发送到同一个Reducer。
**4、Driver类:**配置并运行MapReduce作业。
代码实现
Mapper类
Mapper类将每一行数据解析为省份和总分,并输出为键值对,键是省份,值是总分和学生信息的组合。
package org.example.mapReduce;import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class ProvinceScoreMapper extends Mapper<Object, Text, Text, Text> {@Overrideprotected void map(Object key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();// Skip the header lineif (line.startsWith("考号")) {return;}String[] fields = line.split(" ");String province = fields[11];String totalScore = fields[10];context.write(new Text(province), new Text(totalScore + "," + line));}
}Reducer类
Reducer类将每个省份的数据按总分降序排序后输出,使用MultipleOutputs将每个省的数据写入单独的文件。
package org.example.mapReduce;import java.io.IOException;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;public class ProvinceScoreReducer extends Reducer<Text, Text, Text, Text> {private MultipleOutputs<Text, Text> multipleOutputs;@Overrideprotected void setup(Context context) throws IOException, InterruptedException {multipleOutputs = new MultipleOutputs<>(context);}@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {List<String> students = new LinkedList<>();for (Text val : values) {students.add(val.toString());}// Sort students by total score in descending orderCollections.sort(students, (a, b) -> {int scoreA = Integer.parseInt(a.split(",")[0]);int scoreB = Integer.parseInt(b.split(",")[0]);return Integer.compare(scoreB, scoreA);});for (String student : students) {String[] parts = student.split(",", 2);multipleOutputs.write(new Text(parts[1]), null, key.toString() + "/part");}}@Overrideprotected void cleanup(Context context) throws IOException, InterruptedException {multipleOutputs.close();}
}Partitioner类
Partitioner类确保同一省份的数据被发送到同一个Reducer。
package org.example.mapReduce;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner extends Partitioner<Text, Text> {@Overridepublic int getPartition(Text key, Text value, int numPartitions) {String province = key.toString();return (province.hashCode() & Integer.MAX_VALUE) % numPartitions;}
}Driver类
Driver类配置并运行MapReduce作业。
package org.example.mapReduce;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;public class ProvinceScoreSorter {public static void main(String[] args) throws Exception {if (args.length != 2) {System.err.println("Usage: ProvinceScoreSorter <input path> <output path>");System.exit(-1);}Configuration conf = new Configuration();Job job = Job.getInstance(conf, "Province Score Sorter");job.setJarByClass(ProvinceScoreSorter.class);job.setMapperClass(ProvinceScoreMapper.class);job.setPartitionerClass(ProvincePartitioner.class);job.setReducerClass(ProvinceScoreReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));MultipleOutputs.addNamedOutput(job, "province", FileOutputFormat.class, Text.class, Text.class);System.exit(job.waitForCompletion(true) ? 0 : 1);}
}运行MapReduce作业



总结
通过以上步骤,我们实现了一个Hadoop MapReduce作业来对各省的学生总分进行降序排序,并将结果写入不同的文件中。
如有遇到问题可以找小编沟通交流哦。另外小编帮忙辅导大课作业,学生毕设等。不限于MapReduce, MySQL, python,java,大数据,模型训练等。 hadoop hdfs yarn spark Django flask flink kafka flume datax sqoop seatunnel echart可视化 机器学习等

相关文章:
使用Hadoop MapReduce实现各省学生总分降序排序,根据省份分出输出到不同文件
使用Hadoop MapReduce实现各省学生总分降序排序,根据省份分出输出到不同文件 本文将展示如何使用Hadoop MapReduce对一组学生成绩数据进行处理,将各省的学生成绩按总分降序排序并按照省份进行分区将结果分别输出到不同的文件中。 数据样例 我们将使用…...
LeetCode | 66.加一
这道题有多个思路,可以依次取数组的每一位,乘10后加下一位,直到最后一位,就得到我们数组所表示的数字,然后加一,然后把新得到的数字再转化为对应的数组,我的做法是直接取数组的最后一位…...
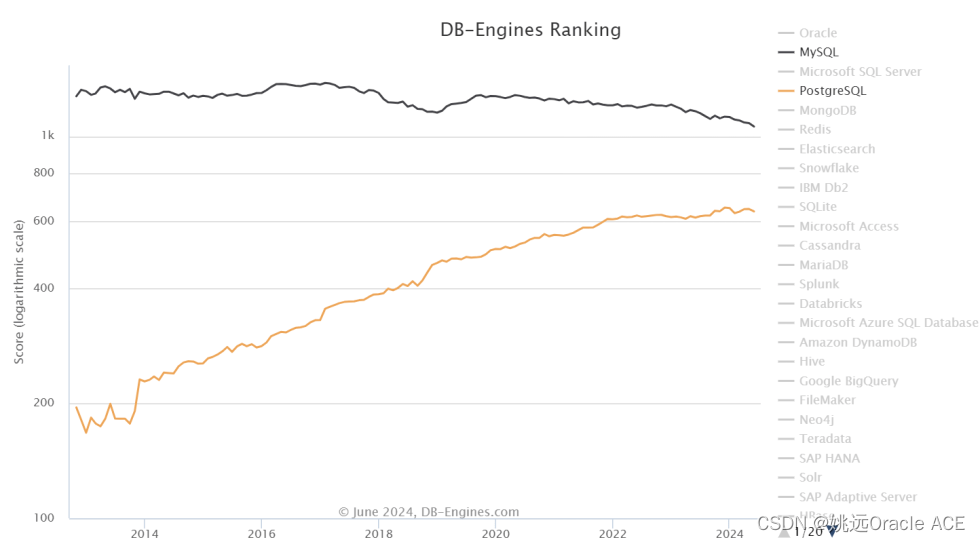
Oracle最终会扼杀MySQL?(译)
原文网站:https://www.percona.com/blog/is-oracle-finally-killing-mysql/ 作者:Peter Zaitsev 自从Oracle收购了MySQL后,很多人怀疑Oracle对开源MySQL的善意,这篇percona的文章深入分析了Oracle已经和将要对MySQL采取的措施&a…...
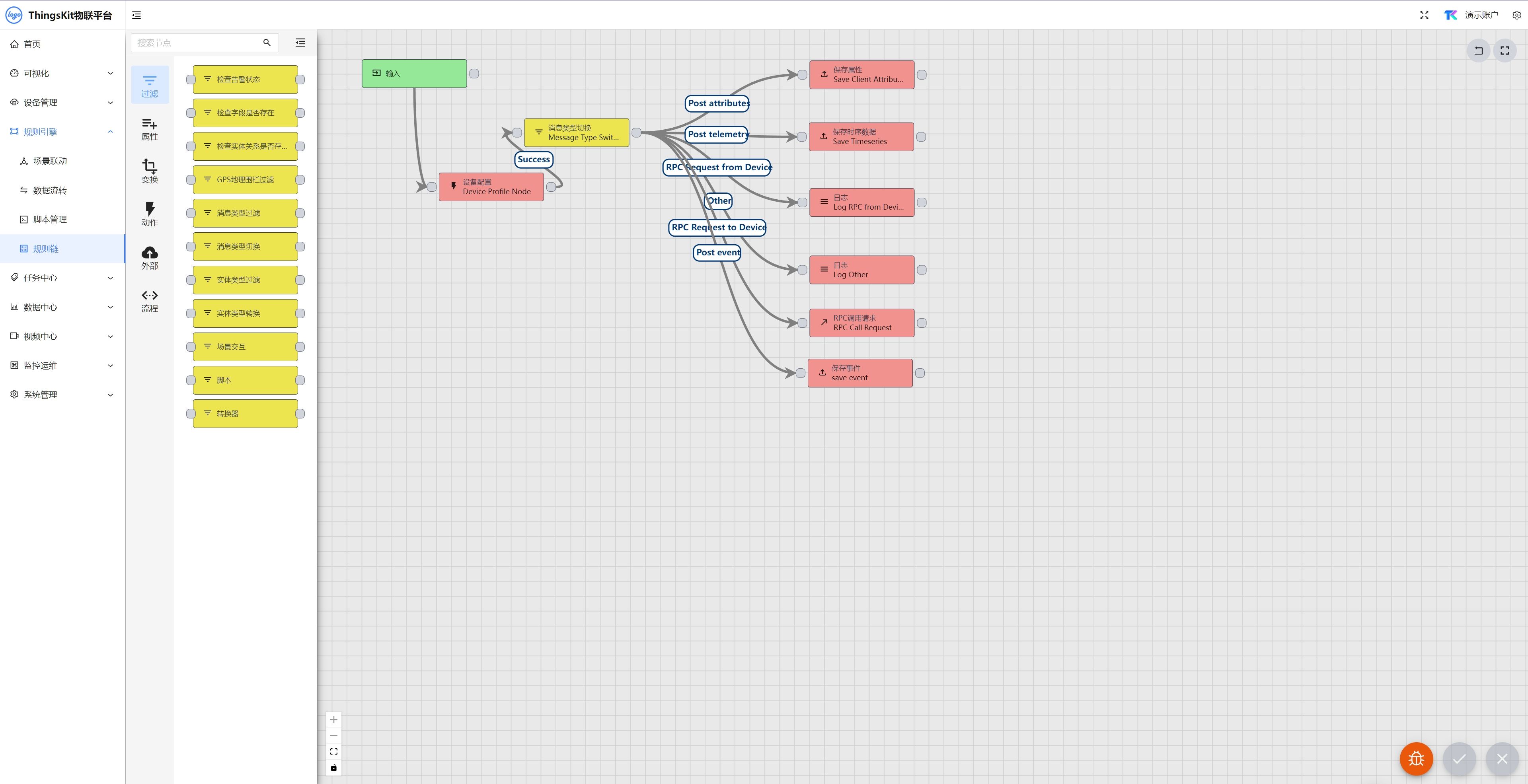
分布式物联网平台特点
随着物联网(IoT)技术的飞速发展,我们正步入一个万物互联的新时代。在这个时代,设备、数据和服务的无缝集成是实现智能化的关键。分布式物联网平台作为这一进程的核心,正在成为构建智能世界的基石。 一、分布式物联网平…...
)
【学习笔记】Linux文件编译调试相关(问题未解决)
//-I意为include 指定头文件搜索路径 -l:告诉编译器链接时需要的库 gcc *.c -I /usr/include/fastdfs/ -I /usr/include/fastcommon/ -l fdfsclient//调试gcc -g -rdynamic main.c如何解决 “ 段错误(吐核) ” ??? 【线上排错】记…...
微信小程序毕业设计-驾校管理系统项目开发实战(附源码+论文)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 💞当前专栏:微信小程序毕业设计 精彩专栏推荐👇🏻👇🏻👇🏻 🎀 Python毕业设计…...
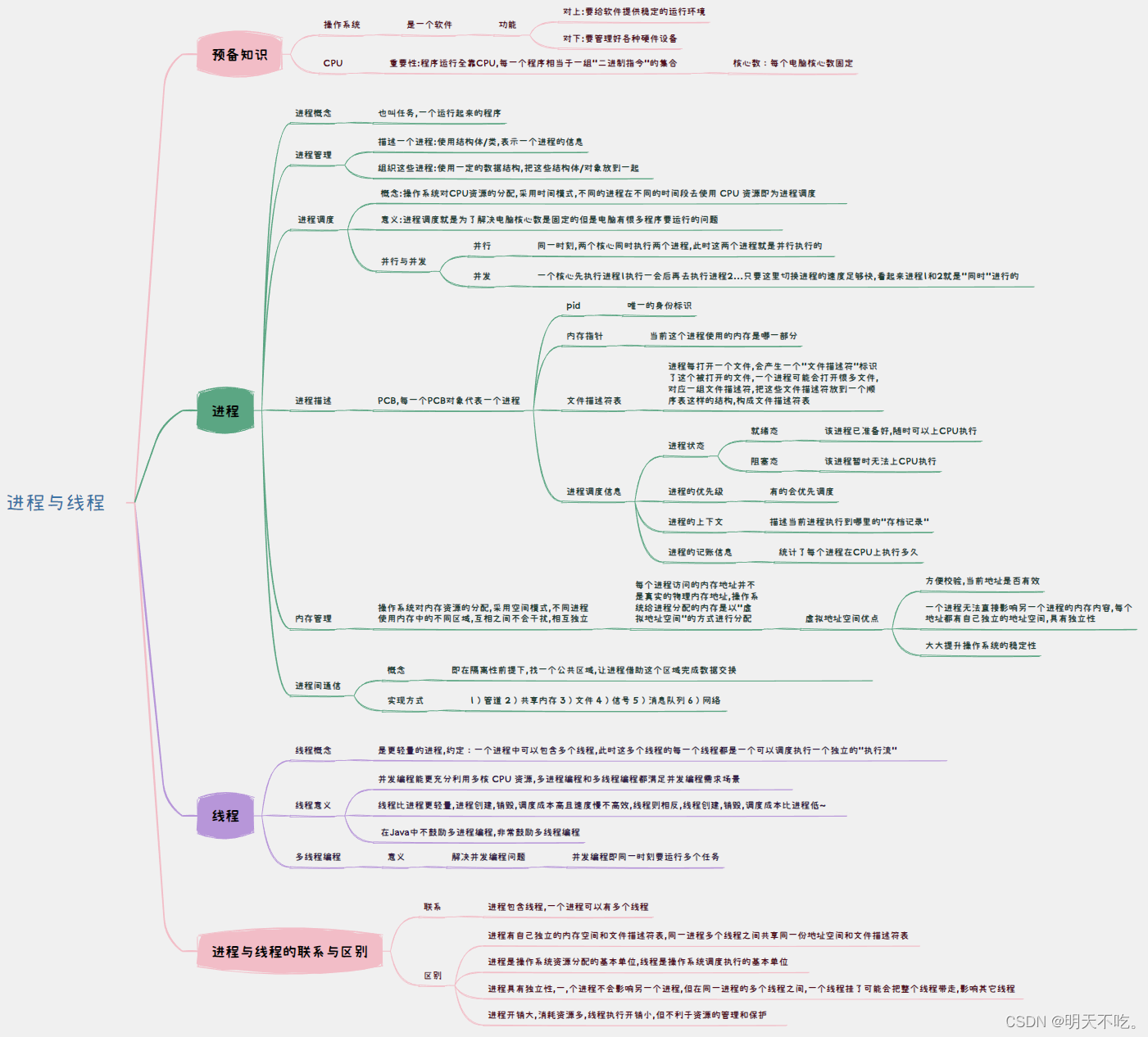
【多线程】进程与线程
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. 操作系统2. 进程2.1 进程是什么2.2 进程管理2.3 进程调度2.3 内存管理2.4 进程间通信 3. 线程3.1 线程是什…...

【文献阅读】一种多波束阵列重构导航抗干扰算法
引言 针对导航信号在近地表的信号十分微弱、抗干扰能力差的问题,文章提出了自适应波束形成技术。 自适应波束形成技术可以分为调零抗干扰算法和多波束抗干扰算法。 调零抗干扰算法主要应用功率倒置技术,充分利用导航信号功率低于环境噪声功率的特点&…...
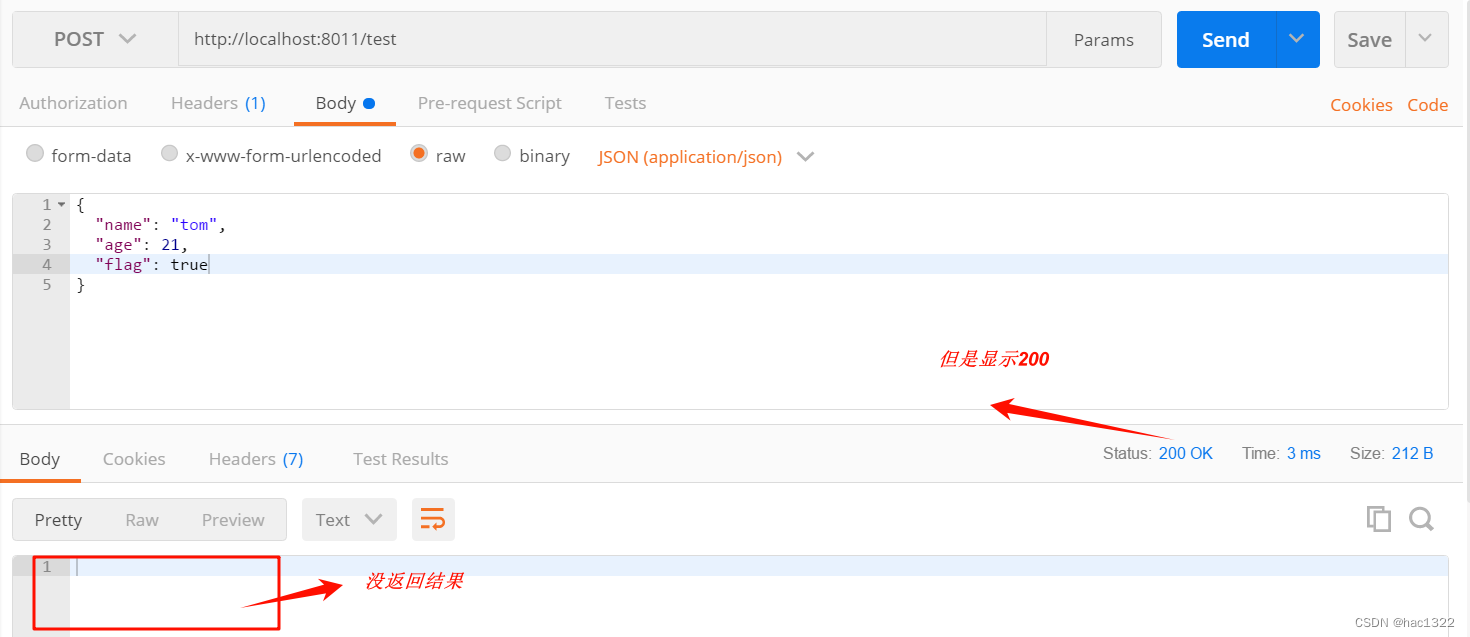
前端传递bool型后端用int收不到
文章目录 背景模拟错误点解决方法 背景 我前几天遇到一个低级错误,就是我前端发一个请求,把参数送到后端,但是我参数里面无意间传的布尔型(刚开始一直没注意到,因为当时参数有十几个),但是我后…...

巴伦在接收链路中的应用
一、巴伦的定义 "巴伦"(Balun),是一种平衡-不平衡转换器,通常用于将平衡信号(如差分信号)转换为不平衡信号(如单端信号),或者反之。巴伦在无线通信、广播、天…...
)
React常见面试题(2024最新版)
创建项目 npx create-react-app my-app启动项目 npm start目录结构 目录/文件名描述README.md项目的自述文件node_modules/项目依赖包存放目录package.json包管理配置文件,记录项目信息和依赖package-lock.json锁定依赖版本,确保跨环境一致性public/公共资源目录public/ind…...
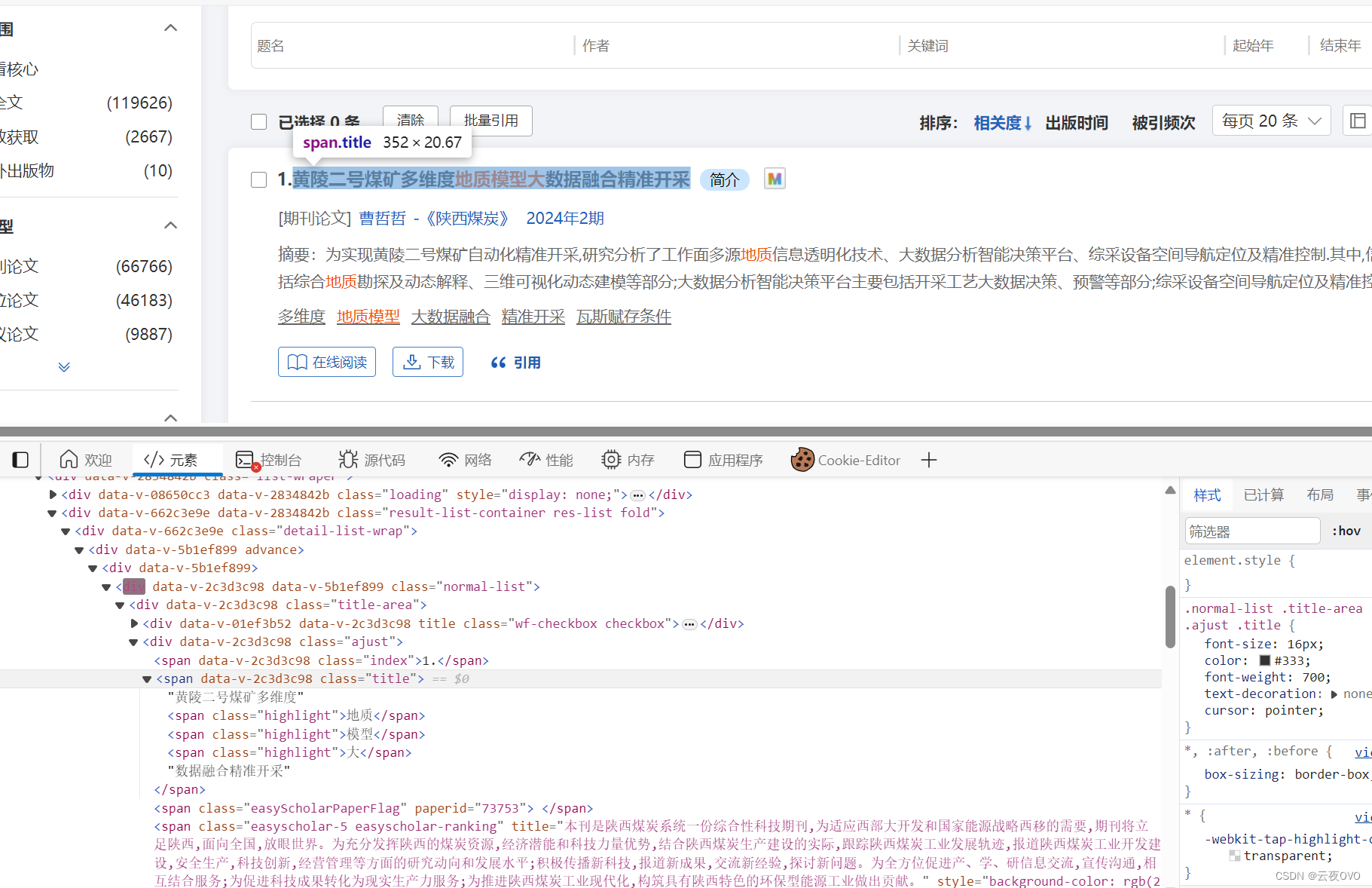
【万方数据库爬虫简单开发(自用)】
万方数据库爬虫简单开发(自用)(一) 使用Python爬虫实现万方数据库论文的搜索并获取信息1.获取url2.输入关键词3.使用BeautifulSoup解析4.获取文章标题信息 使用Python爬虫实现万方数据库论文的搜索并获取信息 后续会逐步探索更新…...

新渠道+1!TDengine Cloud 入驻 Azure Marketplace
近日,TDengine Cloud 正式入驻微软云 Marketplace,为全球更多用户带来全托管的时序数据处理服务。这一举措也丰富了 TDengine 的订阅渠道,为用户提供了极大的便捷性。现在,您可以通过微软云 Marketplace 轻松订阅并部署 TDengine …...
)
自动化压测工具开发(MFC)
1. 背景 为了减轻测试人员在进行MFC程序压力测试时的重复手动操作,本文档描述了开发一个自动化压力测试工具的过程。该工具能够根据程序界面某块区域的预定状态变化,自动执行鼠标点击或键盘输入操作。 2. 技术概览 串口控制:用于控制外部设备,如继电器。MFC CRectTracker…...

【嵌入式DIY实例】-Nokia 5110显示DHT11/DHT22传感器数据
Nokia 5110显示DHT11/DHT22传感器数据 文章目录 Nokia 5110显示DHT11/DHT22传感器数据1、硬件准备2、代码实现2.1 显示DHT11数据2.2 显示DHT22数据本文介绍如何将 ESP8266 NodeMCU 开发板 (ESP-12E) 与 DHT11 数字湿度和温度传感器以及诺基亚 5110 LCD 连接。 NodeMCU 从 DHT11…...

C# —— 字符串拼接
字符串拼接的方式一 之前的算术运算符 只是用来数值类型的相加 主要做的是数学的运算 // 而string 不存在算数运算 但是可以通过加号 进行拼接 string str "123" 字符串拼接 str str "456"; Console.WriteLine(str); // "123456&q…...

css3新增的伪类有哪些
CSS3 引入了许多新的伪类选择器,这些选择器为开发者提供了更多的样式控制选项。以下是一些 CSS3 中新增的主要伪类选择器: 结构性伪类: :root:选择文档的根元素(通常是 <html>)。:empty:…...

低代码开发:企业供应链数字化的挑战与应对
随着全球数字化浪潮的不断推进,企业供应链管理也面临着日益复杂的挑战。在这样的背景下,低代码开发技术的出现为企业提供了一种更高效、更灵活的数字化解决方案。本文将探讨低代码开发在企业供应链数字化中的应用,以及它所带来的挑战与应对策…...

线程池的创建与使用
目录 一、线程池1.1 线程池概念1.2 线程池原理1.3 创建线程池的方式1.4 不同特点的线程池1.5 ThreadPoolExecutor[重要]本文的思维导图 最后 一、线程池 1.1 线程池概念 如果有非常多的任务需要非常多的线程来完成,每个线程的工作时间不长,就需要创建很多线程,工作完又立即销毁…...
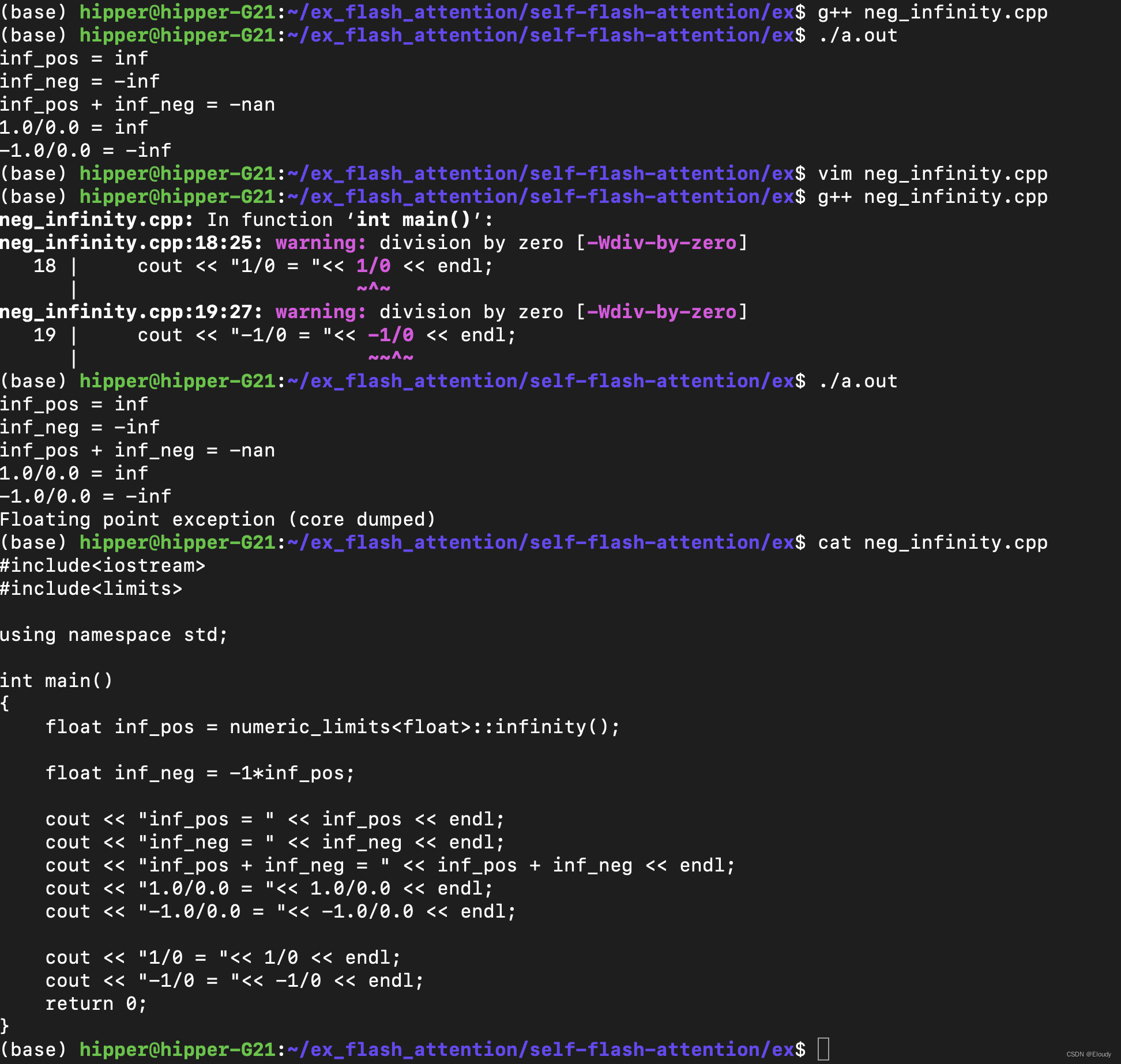
C++ 中的负无穷大赋值
1,代码先行 示例: #include<iostream> #include<limits>using namespace std;int main() {float inf_pos numeric_limits<float>::infinity();float inf_neg -1*inf_pos;cout << "inf_pos " << inf_pos &l…...

OpenClaw+GLM-4.7-Flash:智能读书笔记生成
OpenClawGLM-4.7-Flash:智能读书笔记生成 1. 为什么需要自动化读书笔记 作为一名技术从业者,我常年保持每周至少阅读两本专业书籍的习惯。但最困扰我的不是阅读本身,而是如何高效整理书中精华内容。过去我尝试过各种笔记工具,从…...

系统架构设计师知识点21-40
21.ABSD方法的三个基础。①功能分解,使用已有的基于模块的内聚与耦合技术②选择架构风格实现质量和业务需求③软件模板使用22.ABSD方法是一个自顶向下,递归细化的方法,软件系统的体系结构通过该方法得到细化,直到能产生软件构件和…...

BM12O2321-A高集成H桥模块的9位UART驱动原理与Arduino库实践
1. 项目概述BM12O2321-A 是由 Basetron(BestModules)推出的高集成度 H 桥驱动模块,专为中小功率直流电机、电磁阀、LED 阵列等双向负载控制场景设计。该模块并非传统意义上的分立 H 桥芯片(如 L298N、TB6612FNG)&#…...

高效PDF处理:用PDF Arranger实现极简文档管理
高效PDF处理:用PDF Arranger实现极简文档管理 【免费下载链接】pdfarranger Small python-gtk application, which helps the user to merge or split PDF documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical int…...
)
保姆级教程:用Android 12新特性为你的App打造丝滑启动页(附完整代码示例)
Android 12启动页开发实战:从基础配置到高级动画优化 在移动应用体验中,启动页作为用户接触产品的第一印象,其流畅度直接影响用户留存率。Android 12引入的SplashScreen API为开发者提供了标准化且高度可定制的启动解决方案,本文将…...

AI 开发实战:需求变更后,如何让 AI 自动补回归范围
AI 开发实战:需求变更后,如何让 AI 自动补回归范围 一、这个问题为什么值得专门拿出来做? 在 AI 工程落地里,真正拖慢团队的往往不是模型本身,而是流程和协作方式没有跟上。 围绕“需求变更后,如何让 AI 自…...

Element React:构建企业级UI的React组件解决方案
Element React:构建企业级UI的React组件解决方案 【免费下载链接】element-react Element UI 项目地址: https://gitcode.com/gh_mirrors/el/element-react 作为React开发者,你是否曾为UI组件的一致性和开发效率而困扰?Element React作…...

Fira Code技术揭秘:编程字体连字引擎的深度优化与实战应用
Fira Code技术揭秘:编程字体连字引擎的深度优化与实战应用 【免费下载链接】FiraCode Free monospaced font with programming ligatures 项目地址: https://gitcode.com/GitHub_Trending/fi/FiraCode 在当今的代码编辑环境中,开发者每天需要处理…...

破局B站音频提取难题:BilibiliDown革新性解决方案全解析
破局B站音频提取难题:BilibiliDown革新性解决方案全解析 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors…...

无限级数求和的Java实现与数学分析
本文旨在详细说明如何使用Java精确计算特定形式的无限级数 S -(2x)^2/2! (2x)^4/4! - (2x)^6/6! ... 在指定区间 [0.1, 1.5] 内部和。我们将深入分析等级数的数学性质,推导其闭合形式,并在此基础上纠正原始Java代码…...