[12] 使用 CUDA 进行图像处理
使用 CUDA 进行图像处理
- 当下生活在高清摄像头的时代,这种摄像头能捕获高达1920*1920像素的高解析度画幅。想要实施的处理这么多的数据,往往需要几个TFlops地浮点处理性能,这些要求CPU也无法满足
- 通过在代码中使用CUDA,可以利用GPU提供的强大地计算能力
- CUDA支持多维地Grid和块,因此可以根据图像地尺寸、数据量大小,合理的分配块和线程进行图像处理
- 简单图像处理过程地特定编程模式:
for(int i=0;i<image_height;i++)
{for(int j=0;j<image_width;j++){//Pixel Processing code for pixel located at(i,j)}
}
- 将像素处理映射到CUDA地一批线程上:
int i = blockidx.y * blockDim.y + threadIdx.y
int j = blockidx.x * blockDim.x + threadIdx.x
1. 在GPU上通过CUDA进行直方图统计
- 首先介绍CPU版本的直方图统计,实现如下:
int h_a[1000] = Random values between 0 and 15//假设图像取值范围在【0-15】,定义数组并初始化
int histogram[16];
for(int i=0;i<16;i++)
{histogram[i] = 0;
}
//统计每个值的个数
for(int i=0;i<1000;i++)
{histogram[h_a[i]]+=1;
}
- 下面写一个同样功能的GPU代码,我们将使用3种不同的方法写这个代码,前两种方法的内核代码如下:
__global__ void histogram_without_atomic(int* d_b, int* d_a)
{int tid = threadIdx.x + blockDim.x * blockIdx.x;int item = d_a[tid];if (tid < SIZE){d_b[item]++;}}__global__ void histogram_atomic(int* d_b, int* d_a)
{int tid = threadIdx.x + blockDim.x * blockIdx.x;int item = d_a[tid];if (tid < SIZE){atomicAdd(&(d_b[item]), 1);}
}
- 第一个函数是最简单方式实现的直方图统计,每个线程读取 1 个元素值。使用线程ID作为输入数组的索引获取该元素的数值,然后此值再将对应的d_b结果数组中的索引位置处进行 +1 操作。最后d_b数组应该包含输入数据中0-15之间每个值的频次,这种方式将得出错误的结果,因为对相同的存储器位置将有大量的线程试图同时进行不安全的修改,其运行结果如下:
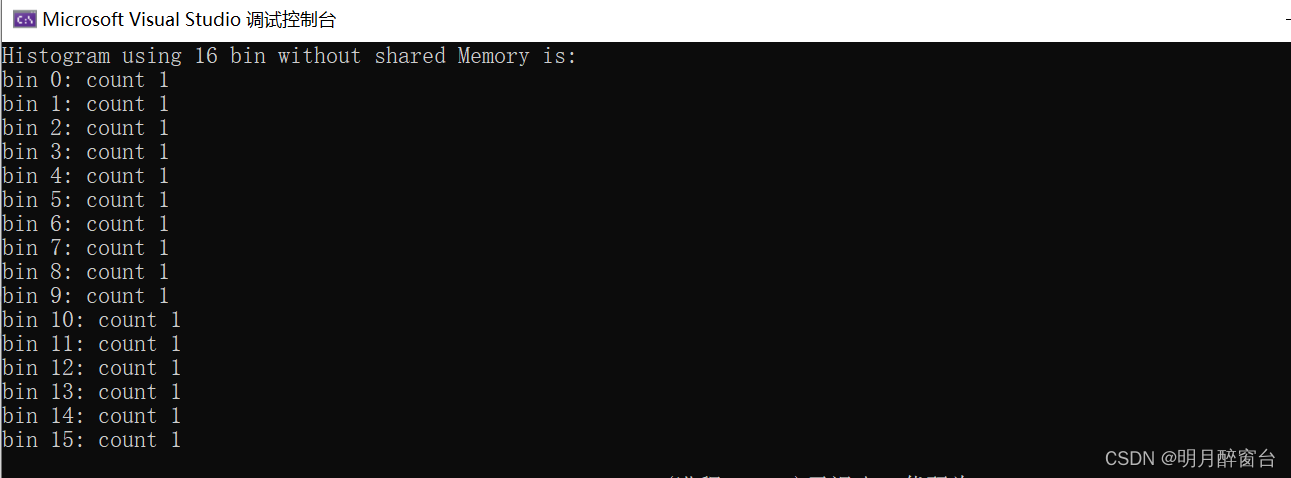
- 第二个函数用原子操作实现统计,避免多线程并行时的资源占用导致的计算异常问题,其计算结果如下:
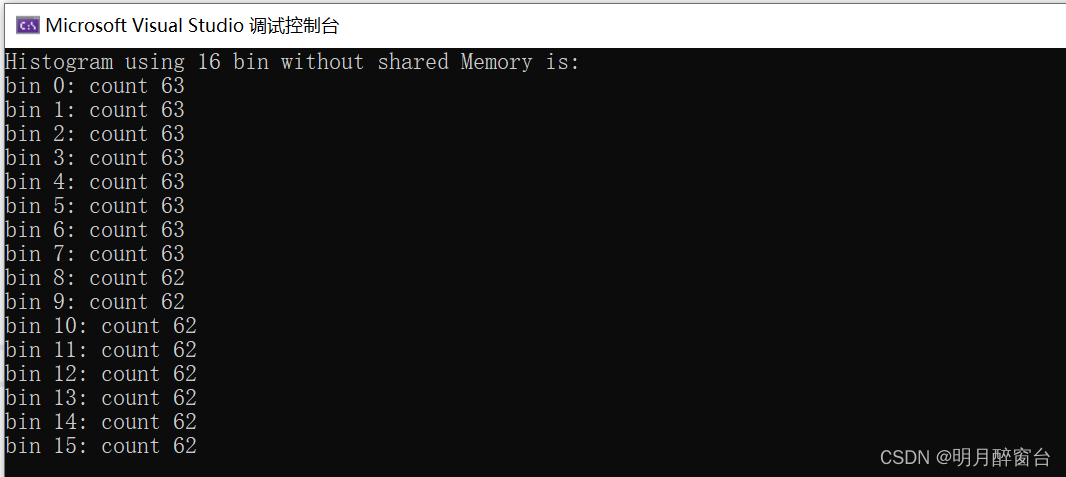
- main函数如下:
int main()
{//定义设备变量并分配内存int h_a[SIZE];for (int i = 0; i < SIZE; i++) {h_a[i] = i % NUM_BIN;}int h_b[NUM_BIN];for (int i = 0; i < NUM_BIN; i++) {h_b[i] = 0;}// 声明GPU指针变量int* d_a;int* d_b;// 分配GPU变量内存cudaMalloc((void**)&d_a, SIZE * sizeof(int));cudaMalloc((void**)&d_b, NUM_BIN * sizeof(int));// transfer the arrays to the GPUcudaMemcpy(d_a, h_a, SIZE * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, NUM_BIN * sizeof(int), cudaMemcpyHostToDevice);// 进行直方图统计//histogram_without_atomic << <((SIZE + NUM_BIN - 1) / NUM_BIN), NUM_BIN >> > (d_b, d_a);histogram_atomic << <((SIZE+NUM_BIN-1) / NUM_BIN), NUM_BIN >> >(d_b, d_a);// copy back the sum from GPUcudaMemcpy(h_b, d_b, NUM_BIN * sizeof(int), cudaMemcpyDeviceToHost);printf("Histogram using 16 bin without shared Memory is: \n");for (int i = 0; i < NUM_BIN; i++) {printf("bin %d: count %d\n", i, h_b[i]);}// free GPU memory allocationcudaFree(d_a);cudaFree(d_b);return 0;
}
- 当我们试图测量使用了原子操作的该代码的性能的时候,你会发现相比CPU的性能,对于很大规模的数组,GPU的实现更慢。这就引入了一个问题:我们真的应当使用CUDA进行直方图统计吗?如果必须能否将这个计算更快些?
- 这两个问题的答案都是:YES 。如果我们在一个块中用共享内存进行直方图统计,最后再将每个块的部分统计结果叠加到全局内存上的最终结果上去。这样就能加速该操作。这是因为整数加法满足交换律。我需要补充的是:只有当原始数据就在GPU的显存上的时候,才应当考虑使用GPU计算,否则完全不应当 cudaMemcpy 过来再计算,因为仅 cudaMemcpy 的时间就将等于或者大于 CPU 计算的时间,用共享内存进行直方图统计的内核函数代码实现如下:
#include <stdio.h>
#include <cuda_runtime.h>#define SIZE 1000
#define NUM_BIN 256__global__ void histogram_shared_memory(int* d_b, int* d_a)
{int tid = threadIdx.x + blockDim.x * blockIdx.x;int offset = blockDim.x * gridDim.x;__shared__ int cache[256];cache[threadIdx.x] = 0;__syncthreads();while (tid < SIZE){atomicAdd(&(cache[d_a[tid]]), 1);tid += offset;}__syncthreads();atomicAdd(&(d_b[threadIdx.x]), cache[threadIdx.x]);
}
- 我们要为当前的每个块都统计一次局部结果,所以需要先将共享内存清空,然后用类似之前的方式在共享内存中进行直方图统计。这种情况下,每个块只会统计部分结果存储在各自的共享内存中,并非像以前那样直接统计为全局内存上的总体结果。
- 本例中,块中256个线程进行共享内存上的256个元素的访问,而原本的代码则在全局内存上的16个元素位置上进行访问。因为共享内存本身要比全局内存具有更高效的并行访问性能,同时将16个统一的竞争访问的位置放宽到了每个共享内存上的256个竞争位置,这两个因素共同缩小了原子操作累计统计的时间。
- 最终还需要进行一次原子操作,将每个块的共享内存上的部分统计结果累加到全局内存上的最终统计结果。因为整数加法满足交换律,我们不需要担心每个块执行的顺序。
- main函数如上一个类似:
int main()
{// generate the input array on the hostint h_a[SIZE];for (int i = 0; i < SIZE; i++) {//h_a[i] = bit_reverse(i, log2(SIZE));h_a[i] = i % NUM_BIN;}int h_b[NUM_BIN];for (int i = 0; i < NUM_BIN; i++) {h_b[i] = 0;}// declare GPU memory pointersint* d_a;int* d_b;// allocate GPU memorycudaMalloc((void**)&d_a, SIZE * sizeof(int));cudaMalloc((void**)&d_b, NUM_BIN * sizeof(int));// transfer the arrays to the GPUcudaMemcpy(d_a, h_a, SIZE * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, NUM_BIN * sizeof(int), cudaMemcpyHostToDevice);// launch the kernelhistogram_shared_memory << <SIZE / 256, 256 >> > (d_b, d_a);// copy back the result from GPUcudaMemcpy(h_b, d_b, NUM_BIN * sizeof(int), cudaMemcpyDeviceToHost);printf("Histogram using 16 bin is: ");for (int i = 0; i < NUM_BIN; i++) {printf("bin %d: count %d\n", i, h_b[i]);}// free GPU memory allocationcudaFree(d_a);cudaFree(d_b);return 0;
}
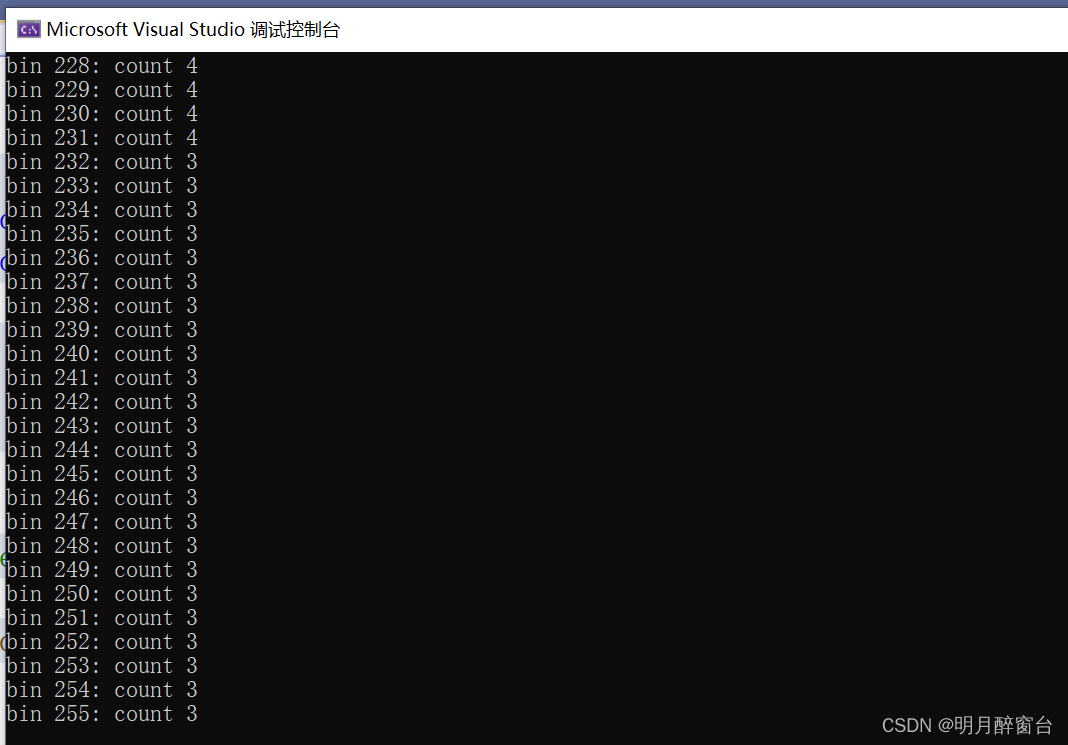
- 执行结果:
相关文章:
[12] 使用 CUDA 进行图像处理
使用 CUDA 进行图像处理 当下生活在高清摄像头的时代,这种摄像头能捕获高达1920*1920像素的高解析度画幅。想要实施的处理这么多的数据,往往需要几个TFlops地浮点处理性能,这些要求CPU也无法满足通过在代码中使用CUDA,可以利用GP…...
MyBatisPlus代码生成器(交互式)快速指南
引言 本片文章是对代码生成器(交互)快速配置使用流程,更多配置方法可查看官方文档: 代码生成器配置官网 如有疑问欢迎评论区交流! 文章目录 引言演示效果图引入相关依赖创建代码生成器对象引入Freemarker模板引擎依赖支持的模板引擎 MyBat…...

深度学习模型训练之日志记录
在深度学习模型训练过程中,进行有效的训练日志记录是至关重要的。以下是一些常见的策略和工具来实现这一目标: 1. 使用TensorBoard TensorBoard是TensorFlow提供的一个可视化工具,用于记录和展示训练过程中的各种指标。 设置TensorBoard&a…...

深入理解Python中的装饰器
装饰器是Python中一个强大且灵活的工具,允许开发者在不修改函数或类定义的情况下扩展或修改其行为。装饰器广泛应用于日志记录、访问控制、缓存等场景。本文将详细探讨Python中的装饰器,包括基本概念、函数装饰器和类装饰器、内置装饰器以及装饰器的高级用法。 目录 装饰器概…...

基于springboot的人力资源管理系统源码数据库
传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,员工信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广大用户的…...
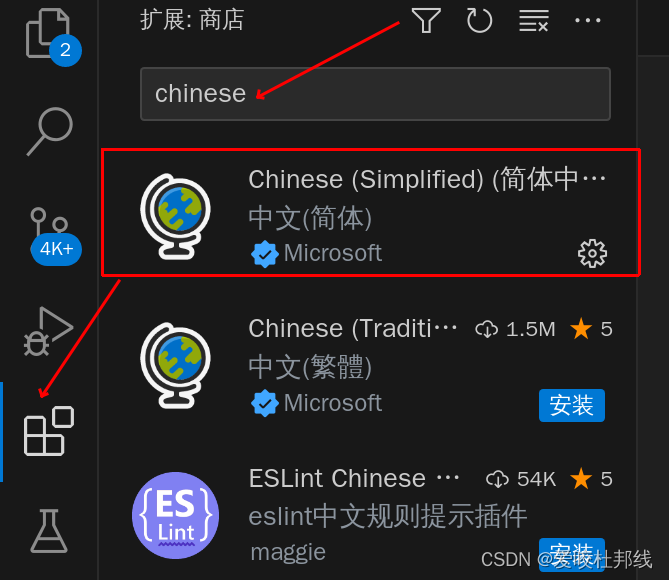
如何舒适的使用VScode
安装好VScode后通常会很不好用,以下配置可以让你的VScode变得好用许多。 VScode的配置流程 1、设置VScode中文2、下载C/C拓展,使代码可以跳转3、更改编码格式4、设置滚轮缩放5、设置字体6、设置保存自动改变格式7、vscode设置快捷代码 1、设置VScode中文…...
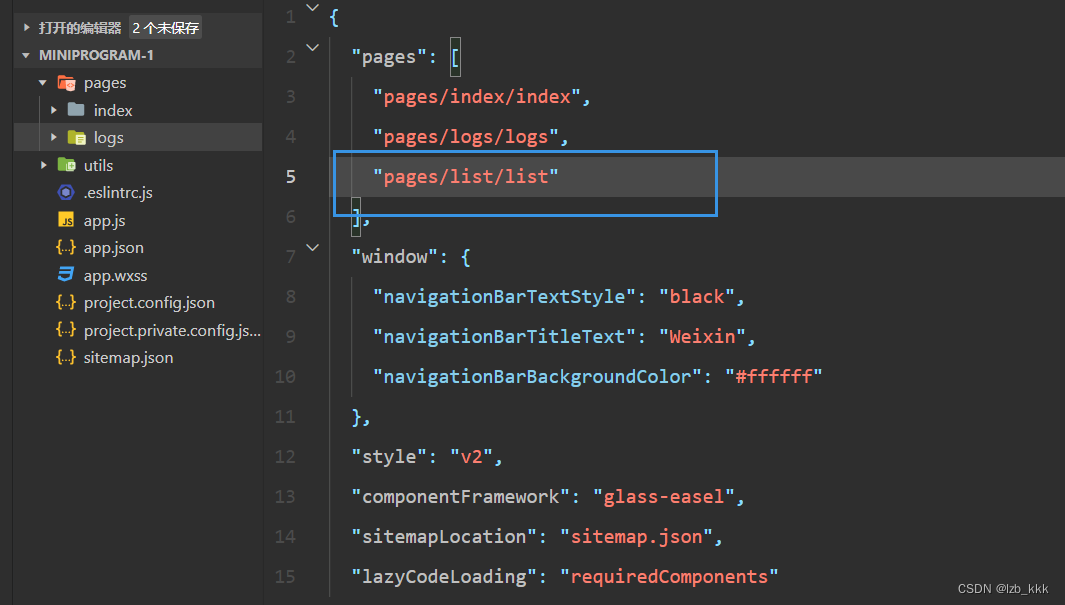
【微信小程序】开发环境配置
目录 小程序的标准开发模式: 注册小程序的开发账号 安装开发者工具 下载 设置外观和代理 第一个小程序 -- 创建小程序项目 查看项目效果 第一种:在模拟器上查看项目效果 项目的基本组成结构 小程序代码的构成 app.json文件 project.config…...
启动盘镜像制作神器(下载即用)
一、简介 1、一款受欢迎且功能强大的USB启动盘制作工具,允许用户将操作系统镜像文件(如Windows或Linux的ISO文件)制作成可引导的USB启动盘。它支持多种操作系统,包括Windows、Linux和各种基于UEFI的系统。Rufus的一个显著特点是制作速度快,据称其速度比其他常用工具如UNet…...

PHP框架详解 - Symfony框架
引言 在现代Web开发中,PHP作为一种灵活且功能强大的编程语言,广泛应用于各种Web应用程序的开发中。为了提高开发效率、代码的可维护性和可扩展性,开发者通常会选择使用框架来构建应用程序。在众多PHP框架中,Symfony以其强大的功能…...

鸿蒙开发:【线程模型】
线程模型 线程类型 Stage模型下的线程主要有如下三类: 主线程 执行UI绘制。管理主线程的ArkTS引擎实例,使多个UIAbility组件能够运行在其之上。管理其他线程的ArkTS引擎实例,例如使用TaskPool(任务池)创建任务或取消…...

初级网络工程师之从入门到入狱(三)
本文是我在学习过程中记录学习的点点滴滴,目的是为了学完之后巩固一下顺便也和大家分享一下,日后忘记了也可以方便快速的复习。 中小型网络系统综合实战实验 前言一、详细拓扑图二、LSW2交换机三、LSW3交换机四、LSW1三层交换机4.1、4.2、4.3、4.4、4.5、…...

【数据结构】排序(直接插入、折半插入、希尔排序、快排、冒泡、选择、堆排序、归并排序、基数排序)
目录 排序一、插入排序1.直接插入排序2.折半插入排序3.希尔排序 二、交换排序1.快速排序2.冒泡排序 三、选择排序1. 简单选择排序2. 堆排序3. 树排序 四、归并排序(2-路归并排序)五、基数排序1. 桶排序(适合元素关键字值集合并不大)2. 基数排序基数排序的…...

MongoDB ObjectId 详解
MongoDB ObjectId 详解 MongoDB 是一个流行的 NoSQL 数据库,它使用 ObjectId 作为文档的唯一标识符。ObjectId 是一个 12 字节的 BSON 类型,它在 MongoDB 中用于保证每个文档的唯一性。本文将详细解释 ObjectId 的结构、生成方式以及它在 MongoDB 中的应用。 ObjectId 的结…...
)
大数据-11-案例演习-淘宝双11数据分析与预测 (期末问题)
目录 第一部分 Hadoop是什么 官方解释: 个人总结 HDFS 是什么? 官方解释: 个人总结 yarn是什么? 官方解释: 个人总结 mapreduce,spark 是什么? 官方解释: MapReduce Spark 个人总结 MapReduce Spa…...

Kubernetes集群监控,kube-prometheus安装教程,一键部署
Kube-prometheus介绍 Kube-prometheus 是一个用于监控 Kubernetes 集群的完整解决方案。它基于 Prometheus 生态系统,提供了一整套预配置的组件和配置文件,以便轻松地在 Kubernetes 上部署和运行 Prometheus 监控系统。 Kube-prometheus 主要包括以下组…...
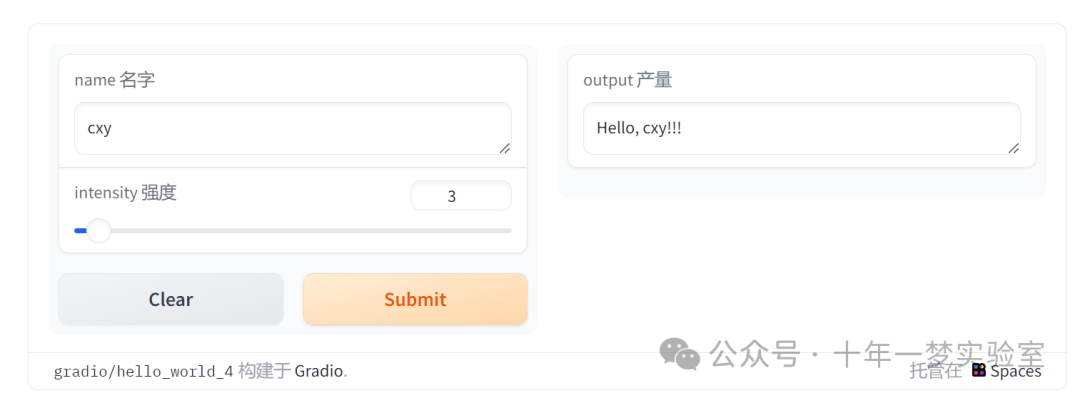
【Gradio】快速入门
https://www.gradio.app/ Gradio 是一个开源 Python 软件包https://github.com/gradio-app/gradio ,可以让你快速为机器学习模型、API 或任何任意 Python 函数创建一个演示或网络应用程序。然后,您就可以使用 Gradio 内置的分享功能,在几秒钟…...
深度学习Day-19:DenseNet算法实战与解析
🍨 本文为:[🔗365天深度学习训练营] 中的学习记录博客 🍖 原作者:[K同学啊 | 接辅导、项目定制] 要求: 根据 Pytorch 代码,编写出 TensorFlow 代码研究 DenseNet 与 ResNetV 的区别改进思路是…...

基于openssl实现AES ECB加解密
AES加密,全称高级加密标准(Advanced Encryption Standard),是一种广泛使用的对称加密算法,用于保护电子数据的安全。以下是AES加密的基本原理和特点: 基本概念 对称加密:AES是一种对称加密算法…...

Git:从配置到合并冲突
目录 1.前言 2.Git的下载与初始化配置 3.Git中新建仓库 4.Git的工作区域和文件状态 5.Git中查看操作和提交记录 6.Git中添加和提交文件 7.Git中回退提交版本 8.Git中查看版本间的差异 9.Git中删除文件 10.Git中忽略指定文件 11.Git中配置SSH密钥 12.Git中关联克隆仓库 13.Git中…...

leetcode hot100 之 最长公共子序列
题目 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(…...

避坑指南:ArcGIS处理SRTM DEM时空间参考丢失、裁剪异常的终极解决方案
ArcGIS处理SRTM DEM数据避坑实战手册:从空间参考丢失到精准裁剪的全流程解析 当你从NASA官网下载了SRTM DEM数据,满心欢喜地准备进行地形分析时,是否遇到过这些"玄学"问题?裁剪后的中国地图边界莫名其妙偏移了几百公里&…...
)
Gemini深度研究模式权限与数据隔离机制全披露(含GDPR/等保2.0合规对照表)
更多请点击: https://intelliparadigm.com 第一章:Gemini深度研究模式权限与数据隔离机制全景概览 Gemini 深度研究模式(Deep Research Mode)是 Google 提供的高级推理能力,专为复杂多步信息检索与跨源分析设计。该模…...

MetaGPT多智能体协作框架:从原理到实战的AI自动化软件开发指南
1. 项目概述:当AI学会“开会”,一个智能体协作框架的诞生 如果你关注AI领域,最近可能被一个叫“MetaGPT”的项目刷屏了。它不是一个单一的模型,而是一个雄心勃勃的框架,其核心目标直指一个激动人心的未来:…...

光纤链路故障排查:从指示灯误导到光功率测量的工程实践
1. 项目概述:一个关于“指示灯谎言”的工程教训在电子工程和测试测量领域,我们习惯于依赖设备上的指示灯——那些绿色、红色或琥珀色的小灯——来快速判断系统状态。它们是我们与复杂硬件对话的直观语言。然而,今天我想分享一个十多年前的真实…...

别再只测SSRF读内网了:手把手教你用dict/gopher协议探测并攻击内网Redis服务
从SSRF到内网Redis渗透:实战进阶指南 发现SSRF漏洞只是开始,真正的挑战在于如何将其转化为实际的攻击路径。当目标内网存在Redis服务时,一个看似简单的SSRF可能成为整个内网沦陷的起点。本文将带你深入探索如何通过dict和gopher协议ÿ…...
)
Gemini Deep Research调用失败?5类报错代码详解+官方未公开的API绕过方案(限时技术内参)
更多请点击: https://intelliparadigm.com 第一章:Gemini Deep Research功能怎么用 Gemini Deep Research 是 Google 推出的面向专业研究者的增强型推理能力模块,专为长上下文分析、跨文档信息整合与假设验证设计。启用该功能需通过 Gemini …...

泉盛UV-K5/K6固件深度定制指南:解锁专业级无线电功能
泉盛UV-K5/K6固件深度定制指南:解锁专业级无线电功能 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 你是否对原厂固件的功能限制感到…...
)
别再全网搜了!企业微信后台三步找到你的CorpID和Secret(附AccessToken一键生成工具)
企业微信开发实战:3分钟获取CorpID与Secret的终极指南 第一次接触企业微信API开发时,最让人头疼的莫过于找不到CorpID和Secret这两个关键凭证。官方文档信息分散,后台界面又不够直观,很多开发者在这个环节浪费了大量时间。本文将…...
)
ConcurrentHashMap详细讲解(java)
文章目录前言一、 为什么用ConcurrentHashMap1.1 什么是 ConcurrentHashMap1.2 为什么用ConcurrentHashMap二、 并发和锁的基础知识2.1 缘起:硬件的“木桶效应”与 JMM 的诞生2.2 并发编程的三大核心危机2.2.1 可见性问题:CPU 缓存引发的“盲区”2.2.2 原…...

基于区块链与IPFS的视频版权存证系统之区块链部分设计
本节对视频版权存证系统的区块链部分做一个简单的介绍,包括目录结构、文件作用、设计思路。 购买专栏前请认真阅读:《基于区块链与IPFS的视频版权存证系统》专栏简介 一、区块链部分文件目录简介 ├── bin //保存了二进制文件方便启动网络 │ ├── configtxgen //生成…...