【后端开发】服务开发场景之高可用(冗余设计,服务限流,降级熔断,超时重试,性能测试)
【后端开发】服务开发场景之高可用(冗余设计,服务限流,降级熔断,超时重试,性能测试)
文章目录
- 序:如何设计一个高可用的系统?
- 可用性的判断指标是什么?
- 哪些情况会导致系统不可用?
- 有哪些提高系统可用性的方法?
- 1、未雨绸缪(冗余设计)
- 2、东窗事发(服务的限流、降级、熔断)
- 服务限流(请求速率)
- 服务降级(整体功能)
- 服务熔断(下游故障)
- 3、事后补救(超时重试,性能测试)
- 超时重试
- 性能测试
- 附:参考资料
序:如何设计一个高可用的系统?
可用性的判断指标是什么?
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
-
一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
-
除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
-
什么是“5个9”的可靠性?,
3个9:(1-99.9%)36524=8.76小时,表示该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
4个9:(1-99.99%)36524=0.876小时=52.6分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
5个9:(1-99.999%)36524*60=5.26分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。 -
【MTBF】MTBF,即平均故障间隔时间,英文全称是“Mean Time Between Failure”。是衡量一个产品(尤其是电器产品)的可靠性指标。单位为“小时”。具体来说,是指相邻两次故障之间的平均工作时间,也称为平均故障间隔。
-
【失效率】失效率是指工作到某一时刻尚未失效的产品,在该时刻后,单位时间内发生失效的概率。一般记为λ,它也是时间t的函数,故也记为λ(t),称为失效率函数,有时也称为故障率函数或风险函数。
-
【MTTR】MTTR,全称是Mean Time To Repair,即平均修复时间。是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。MTTR越短表示易恢复性越好。
-
【修复率】修复率(μ) repair rate 产品维修性的一种基本参数。修理时间已达到某个时刻但尚未修复的产品,在该时刻后的单位时间内完成修理的概率。
哪些情况会导致系统不可用?
- 黑客攻击;
- 硬件故障,比如服务器坏掉。
- 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。
- 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。
- 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。
- 自然灾害或者人为破坏。
有哪些提高系统可用性的方法?
-
注重代码质量,测试严格把关
代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。比较实际可用的就是 CodeReview。 -
使用集群,减少单点故障
如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。 -
限流
流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性 -
超时和重试机制设置
一旦用户请求超过某个时间的得不到响应,就抛出异常。 这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。
一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。
重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。 -
熔断机制
熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。
比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。 -
异步调用
异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。 -
使用缓存
如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快!
更多
- 核心应用和服务优先使用更好的硬件
- 监控系统资源使用情况增加报警设置。
- 注意备份,必要时候回滚。
- 灰度发布: 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可
- 定期检查/更换硬件: 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
1、未雨绸缪(冗余设计)
冗余设计是保证系统和数据高可用的最常的手段。
- 对于服务来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。
- 对于数据来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。
- 实际上,日常生活中就有非常多的冗余思想的应用。我对于重要文件的保存方法就是冗余思想的应用,GitHub+个人云盘。
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
- 高可用集群 : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
- 同城灾备:一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
- 异地灾备:类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
- 同城多活:类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
- 异地多活 : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
特点:
- 高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
- 和传统的灾备设计相比,同城多活和异地多活最明显的改变在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
- 光做好冗余还不够,必须要配合上 故障转移 才可以! 所谓故障转移,简单来说就是实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉。
- 举个例子:哨兵模式的 Redis 集群中,如果 Sentinel(哨兵) 检测到 master 节点出现故障的话, 它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。 整个过程完全自动,不需要人工介入。
- 再举个例子:Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。
2、东窗事发(服务的限流、降级、熔断)
服务限流(请求速率)
服务限流是什么?
- 针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。
- 限流可能会导致用户的请求无法被正确处理或者无法立即被处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
常见限流算法有哪些?
- 1、固定窗口计数器算法
固定窗口其实就是时间窗口,其原理是将时间划分为固定大小的窗口,在每个窗口内限制请求的数量或速率,即固定窗口计数器算法规定了系统单位时间处理的请求数量。
优点:实现简单,易于理解。
缺点:限流不够平滑。例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差! - 2、滑动窗口计数器算法
固定窗口计数器算法的升级版,限流的颗粒度更小。优化在于:它把时间以一定比例分片 。我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次。当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
缺点:与固定窗口计数器算法类似,滑动窗口计数器算法依然存在限流不够平滑的问题。 - 3、漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)
缺点:无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。实际业务场景中,基本不会使用漏桶算法。 - 4、令牌桶算法:
我们的主角还是桶,不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
缺点:如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
如何做服务限流?
-
针对什么来进行限流?
IP :针对 IP 进行限流,适用面较广,简单粗暴。
业务 ID:挑选唯一的业务 ID 以实现更针对性地限流。例如,基于用户 ID 进行限流。
个性化:根据用户的属性或行为,进行不同的限流策略。例如, VIP 用户不限流,而普通用户限流。根据系统的运行指标(如 QPS、并发调用数、系统负载等),动态调整限流策略。例如,当系统负载较高的时候,控制每秒通过的请求减少。 -
单机限流怎么做?
单机限流可以直接使用 Google Guava 自带的限流工具类 RateLimiter 。 RateLimiter 基于令牌桶算法,可以应对突发流量。 -
分布式限流怎么做?
针对的分布式/微服务应用架构应用,常见的方案:
借助中间件限流:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
网关层限流:比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现RedisRateLimiter就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
服务降级(整体功能)
怎么做服务降级? 引用
- 延迟服务:比如发表了评论,重要服务,比如在文章中显示正常,但是延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行。
- 在粒度范围内关闭服务(片段降级或服务功能降级):比如关闭相关文章的推荐,直接关闭推荐区
- 页面异步请求降级:比如商品详情页上有推荐信息/配送至等异步加载的请求,如果这些信息响应慢或者后端服务有问题,可以进行降级;
- 页面跳转(页面降级):比如可以有相关文章推荐,但是更多的页面则直接跳转到某一个地址
- 写降级:比如秒杀抢购,我们可以只进行Cache的更新,然后异步同步扣减库存到DB,保证最终一致性即可,此时可以将DB降级为Cache。
- 读降级:比如多级缓存模式,如果后端服务有问题,可以降级为只读缓存,这种方式适用于对读一致性要求不高的场景。
服务熔断(下游故障)
怎么做服务熔断?
-
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C有调用其他的微服务,如果整个链路上某个微服务的调用响应式过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统雪崩,所谓的”雪崩效应”
-
断路器
“断路器”本身是一种开关装置,当某个服务单元发生故障监控(类似熔断保险丝),向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延。乃至雪崩。
-
服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制,当整个链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。
-
Hystrix
Hystrix是一个用于分布式系统的延迟和容错的开源库。在分布式系统里,许多依赖不可避免的调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个服务失败,避免级联故障,以提高分布式系统的弹性。
- 基本的断路器(Curcuit Breaker)结构如下:
close状态下, client向supplier发起的服务请求, 直接无阻碍通过断路器, supplier的返回值接直接由断路器交回给client.
open状态下,client向supplier发起的服务请求后,断路器不会将请求转到supplier, 而是直接返回client, client和supplier之间的通路是断的
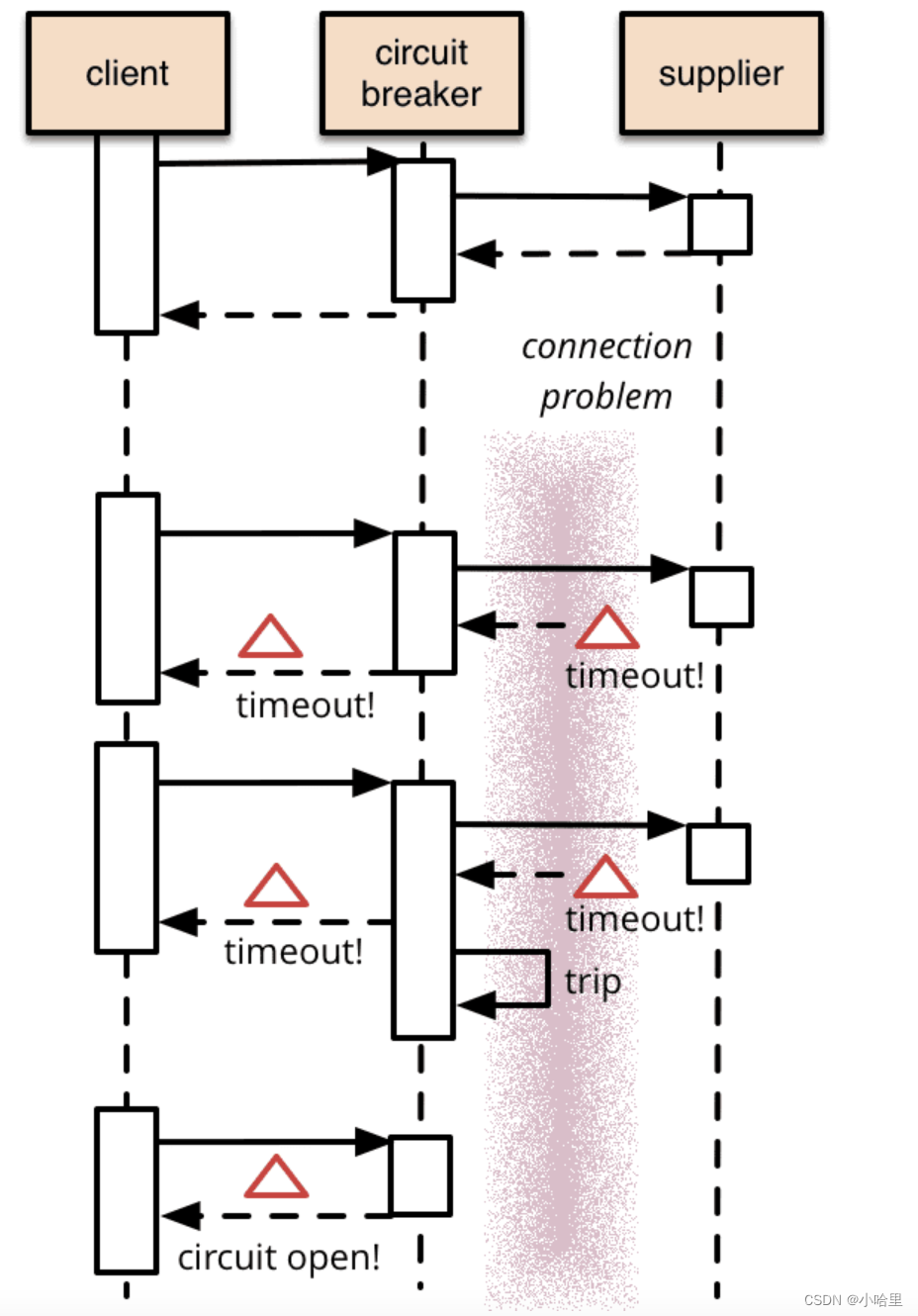
- 扩展的断路器模式
基本的断路器模式下,保证了断路器在open状态时,保护supplier不会被调用, 但我们还需要额外的措施可以在supplier恢复服务后,可以重置断路器。一种可行的办法是断路器定期探测supplier的服务是否恢复, 一但恢复, 就将状态设置成close。断路器进行重试时的状态为半开(half-open)状态。
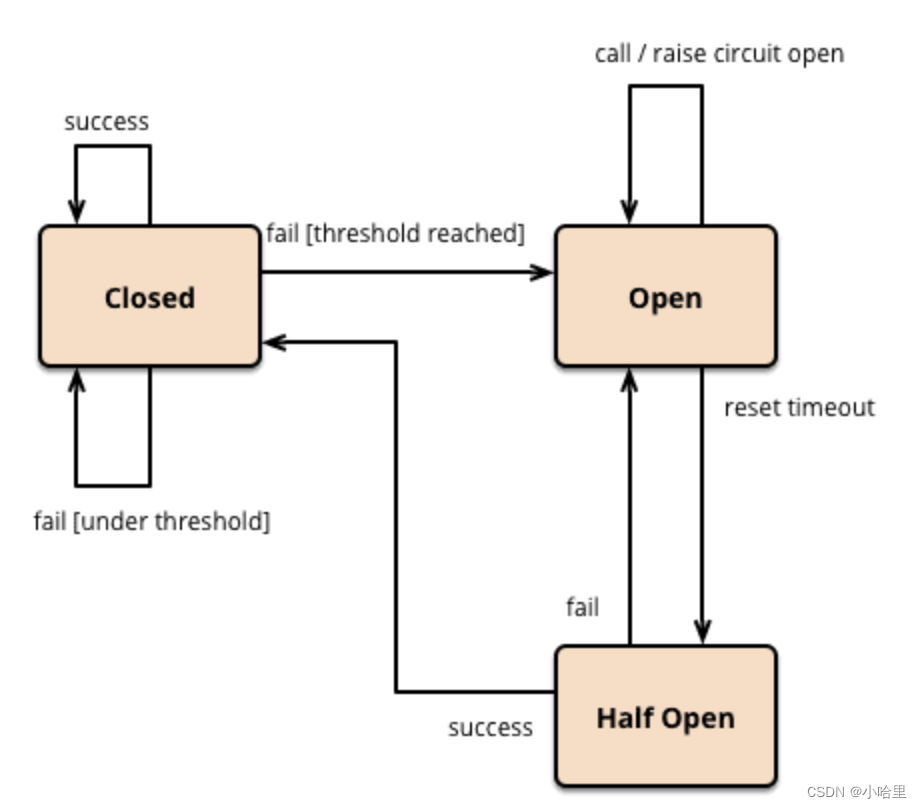
服务熔断与服务降级比较?
- 服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑。
- 共性:
- 目的 -> 都是从可用性、可靠性出发,提高系统的容错能力。
- 最终表现->使某一些应用不可达或不可用,来保证整体系统稳定。
- 粒度 -> 一般都是服务级别,但也有细粒度的层面:如做到数据持久层、只许查询不许增删改等。
- 自治 -> 对其自治性要求很高。都要求具有较高的自动处理机制。
- 区别:
- 触发原因 -> 服务熔断通常是下级服务故障引起;服务降级通常为整体系统而考虑。
- 管理目标 -> 熔断是每个微服务都需要的,是一个框架级的处理;而服务降级一般是关注业务,对业务进行考虑,抓住业务的层级,从而决定在哪一层上进行处理:比如在IO层,业务逻辑层,还是在外围进行处理。
- 实现方式 -> 代码实现中的差异。
3、事后补救(超时重试,性能测试)
超时重试
超时重试存在的意义?
- 由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
- 为了最大限度的减小系统或者服务出现故障之后带来的影响,我们需要用到的 超时(Timeout) 和 重试(Retry) 机制。
- 对于微服务系统来说,正确设置超时和重试非常重要。单体服务通常只涉及数据库、缓存、第三方 API、中间件等的网络调用,而微服务系统内部各个服务之间还存在着网络调用。
什么是超时机制?
-
超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 504 Gateway Timeout)。
-
平常的两种超时:
连接超时(ConnectTimeout):客户端与服务端建立连接的最长等待时间。
读取超时(ReadTimeout):客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。 -
一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。 -
整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
超时时间应该如何设置?
- 超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。
如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。
如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。 - 通常情况下,我们建议读取超时设置为 1500ms ,这是一个比较普适的值。
什么是重试机制?
- 重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。
瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。
重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。 由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
常见的重试策略有哪些?
- 固定间隔时间重试:
每次重试之间都使用相同的时间间隔,比如每隔 1.5 秒进行一次重试。这种重试策略的优点是实现起来比较简单,不需要考虑重试次数和时间的关系,也不需要维护额外的状态信息。但是这种重试策略的缺点是可能会导致重试过于频繁或过于稀疏,从而影响系统的性能和效率。如果重试间隔太短,可能会对目标系统造成过大的压力,导致雪崩效应;如果重试间隔太长,可能会导致用户等待时间过长,影响用户体验。 - 梯度间隔重试:
根据重试次数的增加去延长下次重试时间,比如第一次重试间隔为 1 秒,第二次为 2 秒,第三次为 4 秒,以此类推。这种重试策略的优点是能够有效提高重试成功的几率(随着重试次数增加,但是重试依然不成功,说明目标系统恢复时间比较长,因此可以根据重试次数延长下次重试时间),也能通过柔性化的重试避免对下游系统造成更大压力。但是这种重试策略的缺点是实现起来比较复杂,需要考虑重试次数和时间的关系,以及设置合理的上限和下限值。另外,这种重试策略也可能会导致用户等待时间过长,影响用户体验。 - 重试的次数如何设置?
重试的次数通常建议设为 3 次。大部分情况下,我们还是更建议使用梯度间隔重试策略。 - 如何实现重试?
如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。
不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现,例如 Spring Retry、Resilience4j、Guava Retrying。
什么是重试幂等?
-
超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
-
什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
-
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
性能测试
性能测试是什么?
- 性能测试一般情况下都是由测试这个职位去做的,了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序。
- 不同角色看网站性能
- 用户:在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
- 开发人员:系统处理用户请求的速度。
项目架构是分布式的吗?用到了缓存和消息队列没有?高并发的业务有没有特殊处理?数据库设计是否合理?系统用到的算法是否还需要优化?系统是否存在内存泄露的问题?项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘? - 测试人员: 根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:响应时间;请求成功率;吞吐量;
- 运维人员:倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。
如何进行性能测试?
-
性能测试需要注意的点?
1、性能测试之前更需要你了解当前的系统的业务场景。 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。
2、当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些 service 承受的压力最大。 -
性能测试的指标?
1、响应时间:用户发出请求到用户收到系统处理结果所需要的时间。比较出名的 2-5-8 原则是这样描述的:通常来说,2 到 5 秒,页面体验会比较好,5 到 8 秒还可以接受,8 秒以上基本就很难接受了。一般取多次请求的平均响应时间。
2、并发数:系统能同时处理请求的数目。
3、吞吐量:单位时间内系统处理的请求数量。
衡量吞吐量有几个重要的参数:QPS(TPS)、并发数、响应时间。
QPS(Query Per Second):服务器每秒可以执行的查询次数;
TPS(Transaction Per Second):服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
4、理清他们的概念
QPS(TPS) = 并发数/平均响应时间
并发数 = QPS*平均响应时间
5、QPS vs TPS:
QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。
6、性能计数器
性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU 使用、磁盘与网络 I/O 等情况。 -
常见的性能测试?
性能测试: 性能测试方法是通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
负载测试: 对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和了,比如系统的缓存已经不够用了或者系统的响应时间已经不满足要求了。负载测试说白点就是测试系统的上限。
压力测试: 不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务。
稳定性测试: 模拟真实场景,给系统一定压力,看看业务是否能稳定运行。 -
常用性能测试工具?
后端常用:
1、Jmeter:Apache JMeter 是 JAVA 开发的性能测试工具。
2、LoadRunner:一款商业的性能测试工具。
3、Galtling:一款基于 Scala 开发的高性能服务器性能测试工具。
4、ab:全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
前端常用
1、Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
2、HttpWatch: 可用于录制 HTTP 请求信息的工具。
常见的性能优化策略?
- 系统是否需要缓存?
- 系统架构本身是不是就有问题?
- 系统是否存在死锁的地方?
- 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏)
- 数据库索引使用是否合理?
附:参考资料
1,2,3
相关文章:
【后端开发】服务开发场景之高可用(冗余设计,服务限流,降级熔断,超时重试,性能测试)
【后端开发】服务开发场景之高可用(冗余设计,服务限流,降级熔断,超时重试,性能测试) 文章目录 序:如何设计一个高可用的系统?可用性的判断指标是什么?哪些情况会导致系统…...
在 Selenium 中更改 User-Agent | 步骤与最佳实践
在 Selenium 中更改 User Agent 是许多网页抓取任务中的关键步骤。它有助于将自动化脚本伪装成常规浏览器,从而避免被网站检测到。本指南将带您了解如何在 Selenium 中更改 Google Chrome 的 User Agent,并提供最佳实践以确保您的网页抓取任务顺利进行。…...
2024酒店IPTV云桌面系统建设方案
Hello大家好,我是点量小芹,这一年多的时间一直在分享实时云渲染像素流相关的内容,今天和大家聊聊酒店IPTV云桌面电视系统解决方案,或者有的朋友也会称之为IPTV服务器。熟悉小芹的朋友知道,IPTV软件系统是我们一直在推的…...

java Thrift TThreadPoolServer 多个processor 的实现
当我们使用Thrift 通信的时候,服务端有时候需要注册多个类,去实现通信,这时候我们就不能再使用单一Processor的方式,就要使用多个Processor,那么如何去实现呢? 多个Process 服务端 public static void m…...

失眠焦虑的解脱之道:找回内心的平静
🍃 在这个快节奏的时代,失眠与焦虑似乎成了许多人的隐形敌人。每当夜幕降临,它们便悄悄潜入心底,扰乱我们的思绪,让宁静的夜晚变得无比漫长。然而,生活总有办法让我们找回内心的平静,只需稍作调…...

OLED柔性屏的显示效果如何
OLED柔性屏的显示效果非常出色,具有多方面的优势。以下是关于OLED柔性屏显示效果的详细分析: 色彩表现:OLED柔性屏的每个像素都可以独立发光,因此色彩准确性极高。黑色呈现得非常深邃,而亮部则展现出鲜明而生动的细节。…...

百货商城优选 伊利牛奶推出全国首款减甲烷环保学生奶
近日,伊利集团受邀参加在全国首个“国际首脑峰会零碳场馆”召开的“降碳增产科技助力奶业绿色高质量发展”首款低碳饲料创新大会。会上,伊利宣布将推出全国首款减甲烷环保学生牛奶——伊利QQ星学生纯牛奶,进一步将可持续发展落到实处…...

Fluid 1.0 版发布,打通云原生高效数据使用的“最后一公里”
作者:顾荣 前言 得益于云原生技术在资源成本集约、部署运维便捷、算力弹性灵活方面的优势,越来越多企业和开发者将数据密集型应用,特别是 AI 和大数据领域应用,运行于云原生环境中。然而,云原生计算与存储分离架构虽…...

软件测试--第十一章 设计和维护测试用例
1.单选题 (2分) 下面有关测试设计的叙述,说法不正确的是( )。 A 测试用例的设计是一项技术性强.智力密集型的活动 B 在开展测试用例设计前,必须将测试需求进行详细展开 C 在一般的测试组织内,测试用例的评审可能不是正式的评审会 D 在测试用例设计时,只设计覆盖正常流程和操…...

前端只允许一次函数调用
如果你正在进行前端开发,并且只想允许一次函数调用,你可以使用JavaScript的闭包结构创建一个只能被调用一次的函数。这样的函数有时被称为单次调用函数(“one-time call” functions)或一次性函数(“once” functions&…...

visdom使用时所遇的问题及解决方法
最近在用visdom进行可视化的过程中,虽然可有效的避免主机拒绝访问(该问题的解决方法,请参考深度学习可视化工具visdom使用-CSDN博客)即在终端输入python -m visom.server 1.训练过程中visdom出现ValueError: too many file descr…...
)
密封类(sealed class)
在 Kotlin 中,密封类(sealed class)是一种受限的类层次结构,允许您定义一个封闭的类层次结构,其中类的所有可能子类都已知并且位于同一文件中。密封类的主要作用是提供类型安全的受限层次结构,使得 when 表…...
私域引流宝PHP源码 以及搭建教程
私域引流宝PHP源码 以及搭建教程...
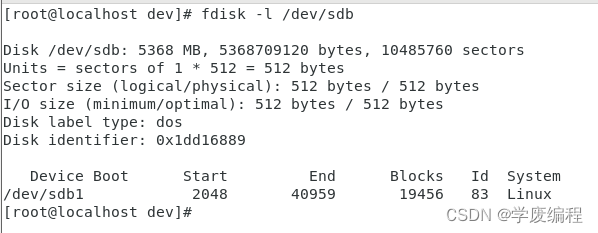
磁盘管理 以及磁盘的分区 详细版
磁盘管理 track:磁道,就是磁盘上同心圆,从外向里,依次1号、2号磁道sector:扇区,将磁盘分成一个一个扇形区域,每个扇区大小是512字节,从外向里,依次是1号扇区、2号扇区cylinder&…...

加码多肤色影像技术 这是传音找到的“出海利器“?
全球化时代,市场竞争愈演愈烈,产品差异化已然成为了企业脱颖而出的关键。在黄、白肤色长期占据人像摄影主赛道的背景下,传音就凭借独一无二的多肤色影像技术走出非洲,走向了更广阔的新兴市场。 聚焦深肤色人群拍照痛点,…...

C++方法封装成dll及C#调用示例
1,编译生成dll时可能出现错误,解决办法:pch.h文件头部,添加声明 #define _CRT_SECURE_NO_WARNINGS 2, c头文件声明 extern "C" __declspec(dllexport) char* getvalue(const char * param1, const char * param2); 3, c方法实现…...

定时清理Linux服务器缓存shell脚本
服务器内存占用过高,如何定时清理一下服务器内存呢?写一个清理缓存脚本,加入到定时任务中。 一、编写脚本 clear_cache.sh 脚本,放到home目录下。 #!/bin/bash# 清除页面缓存、目录项和 inode 缓存 sudo sync echo 3 | sudo tee /proc/sys/vm/drop_caches# 记录执行时间到日…...

Guava常用方法
目录 一、数学和数值操作 二、并发库 三、缓存 四、集合 五、I/O 与文件操作 六、网络 七、时间处理 八、事件总线 九、反射 十、范围和集合操作 十一、随机数和测试 十二、注解处理 十三、比较器和排序 十四、哈希和散列 Guava 是 Google 开源的一个 Java 工具库ÿ…...

干货分享:宏集物联网HMI通过S7 MPI协议采集西门子400PLC数据
前言 为了实现和西门子PLC的数据交互,宏集物联网HMI集成了S7 PPI、S7 MPI、S7 Optimized、S7 ETH等多个驱动来适配西门子200、300、400、1200、1500、LOGO等系列PLC。 本文主要介绍宏集HMI通过S7 MPI协议采集西门子400PLC数据的操作步骤,其他协议的操作…...
【Web API DOM11】节点操作
目录 一:DOM节点 1 什么是DOM节点 2 DOM节点分类 二:节点查找(元素节点) 1 节点关系 父节点 子节点 兄弟节点 三:增加节点 1 创建节点 2 追加节点 2 案例:渲染数据 案例中核心代码块 样式 四…...

深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战
深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电…...

百度网盘Mac版加速插件:突破下载限制的实用方案
百度网盘Mac版加速插件:突破下载限制的实用方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于经常使用百度网盘的Mac用户来说&#x…...

别再死记硬背了!用STM32H7的USB CDC类实战,反向理解USB协议栈核心概念
从实战出发:用STM32H7的USB CDC类逆向掌握协议栈精髓 当开发板上的LED第一次随着串口指令闪烁时,我意识到USB协议栈不再是手册里晦涩的名词——端点成了数据管道,描述符变身设备身份证,而曾经令人头疼的HID报告突然有了具象意义。…...

基于LLM的MBTI人格模拟对话实验:从系统设计到工程实践
1. 项目概述:当MBTI遇上AI,一次关于人格的深度对话实验最近在GitHub上看到一个挺有意思的项目,叫“Kali-Hac/ChatGPT-MBTI”。光看名字,你可能觉得这又是一个用ChatGPT玩MBTI性格测试的简单脚本。但当我真正clone下来,…...
)
告别杂音:手把手教你用RNNoise为你的实时语音应用降噪(附Python/C++实战代码)
实时语音降噪实战:从RNNoise原理到多语言工程集成 在视频会议、在线教育、语音社交等场景中,背景噪声一直是影响语音质量的顽疾。传统降噪方案如谱减法、Wiener滤波在应对突发噪声时往往力不从心,而端到端的深度学习方案又面临实时性挑战。本…...

从理论到仿真:深入解读Walker星座设计,用STK验证你的卫星通信作业
从理论到仿真:深入解读Walker星座设计,用STK验证你的卫星通信作业 卫星通信系统的设计从来不是纸上谈兵。当你在教科书上看到那些优美的轨道方程和覆盖计算公式时,是否想过如何将它们转化为真实的系统性能验证?这正是STKÿ…...

5分钟快速上手:roop-unleashed AI换脸神器完全指南
5分钟快速上手:roop-unleashed AI换脸神器完全指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要在几分钟内制作专业级AI换脸视频吗&…...

基于大语言模型的私有化AI健康助手:Open Health Agent设计与实践
1. 项目概述:一个真正属于你的AI健康数据管家 最近几年,我自己的健康数据越来越“散装”了。体重秤的数据在App A里,跑步机的记录在App B里,偶尔在微信上跟朋友吐槽一句“昨晚又没睡好”,这些碎片化的信息就像沙滩上的…...

机器学习在资产管理中的应用:从数据到投资组合的端到端框架
1. 项目概述:当机器学习遇见资产管理如果你在资产管理行业待过,或者对量化投资感兴趣,那你肯定不止一次想过:那些复杂的市场数据、财报、新闻,能不能让机器来帮我们分析,甚至做出决策?firmai/ma…...

开题报告一次通关密码:告别反复修改,虎贲等考 AI 重新定义高效开题
每一位本硕博学生都懂:开题不顺,论文全乱。开题报告是毕业论文的 “总设计图”,选题、框架、文献、技术路线只要一项不达标,就会被导师反复打回,浪费时间、消耗心态,甚至直接拖慢整个毕业节奏。可自己写开题…...