SQL Server中的CTE和临时表优化
在SQL Server中,优化查询性能是数据库管理的核心任务之一。使用公用表表达式(CTE)和临时表是两种重要的技术手段。本文将深入探讨CTE如何简化代码,以及临时表如何优化查询性能。通过实例和详尽解释,我们将展示这两种技术在实际应用中的优点和注意事项。
第一部分:公用表表达式(CTE)
公用表表达式(CTE)是SQL Server 2005引入的一项功能。CTE通过将复杂查询分解成多个可读性高的部分,使代码更加简洁明了。CTE主要有两种类型:递归CTE和非递归CTE。
1.1 非递归CTE
非递归CTE主要用于简化查询,提高代码可读性。以下是一个典型的非递归CTE示例:
WITH SalesCTE AS (SELECT SalesPersonID,SUM(TotalDue) AS TotalSalesFROM Sales.SalesOrderHeaderGROUP BY SalesPersonID
)
SELECT sp.FirstName, sp.LastName, sc.TotalSales
FROM SalesCTE sc
JOIN Sales.SalesPerson sp
ON sc.SalesPersonID = sp.SalesPersonID;
在这个示例中,我们使用CTE将总销售额的计算与人员信息的查询分开,从而提高了代码的清晰度。
1.2 递归CTE
递归CTE用于处理层次结构数据,如组织结构或目录树。以下是一个递归CTE示例:
WITH OrgCTE AS (SELECT EmployeeID, ManagerID, TitleFROM HumanResources.EmployeeWHERE ManagerID IS NULLUNION ALLSELECT e.EmployeeID, e.ManagerID, e.TitleFROM HumanResources.Employee eINNER JOIN OrgCTE oON e.ManagerID = o.EmployeeID
)
SELECT EmployeeID, ManagerID, Title
FROM OrgCTE;
这个示例展示了如何使用递归CTE来获取一个组织结构中的所有员工信息,包括他们的管理层级。
第二部分:临时表优化查询性能
临时表在SQL Server中扮演着重要角色,特别是在处理复杂查询时。临时表允许我们将中间结果存储在一个临时的存储结构中,从而优化查询性能。
2.1 临时表的创建
临时表分为局部临时表和全局临时表。局部临时表以单个会话为作用范围,而全局临时表则可以在多个会话间共享。以下是创建局部临时表的示例:
CREATE TABLE #TempSales (SalesPersonID INT,TotalSales MONEY
);INSERT INTO #TempSales (SalesPersonID, TotalSales)
SELECT SalesPersonID, SUM(TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader
GROUP BY SalesPersonID;
2.2 临时表的应用场景
临时表在以下几种场景中尤为有用:
- 复杂的多步查询:将查询分解为多个步骤,每个步骤的结果存储在临时表中,可以提高整体查询效率。
- 大数据量的处理中间结果存储:在处理大数据量时,临时表可以避免重复计算,从而显著提高性能。
- 索引和统计信息的应用:临时表允许我们创建索引,从而优化查询性能。
以下是一个结合临时表和索引的示例:
CREATE TABLE #TempSales (SalesPersonID INT,TotalSales MONEY
);INSERT INTO #TempSales (SalesPersonID, TotalSales)
SELECT SalesPersonID, SUM(TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader
GROUP BY SalesPersonID;CREATE INDEX IX_TempSales_SalesPersonID ON #TempSales(SalesPersonID);SELECT sp.FirstName, sp.LastName, ts.TotalSales
FROM #TempSales ts
JOIN Sales.SalesPerson sp
ON ts.SalesPersonID = sp.SalesPersonID;
在这个示例中,我们首先创建了一个临时表,并将中间结果存储在其中。接着,我们为临时表创建了一个索引,从而优化了后续的查询性能。
第三部分:CTE与临时表的比较与选择
在使用CTE和临时表时,我们需要根据具体情况选择最优方案。以下是CTE和临时表的优缺点比较:
3.1 CTE的优点
- 代码简洁:CTE使得复杂查询更加易读和维护。
- 临时作用域:CTE仅在当前查询中有效,不会影响其他查询。
3.2 CTE的缺点
- 性能限制:对于大数据量的处理中,CTE可能会导致性能问题,因为CTE不会自动创建索引。
- 复杂查询受限:在多步骤复杂查询中,CTE的灵活性较低。
3.3 临时表的优点
- 性能优化:临时表可以通过创建索引和统计信息显著提高查询性能。
- 灵活性高:在多步骤复杂查询中,临时表提供了更多的操作空间和灵活性。
3.4 临时表的缺点
- 代码复杂度:与CTE相比,临时表的代码更加复杂,需要显式创建和删除。
- 资源占用:临时表会占用临时数据库资源,可能导致系统负载增加。
第四部分:实例与实践
通过实际案例,我们可以更好地理解CTE和临时表的应用场景和性能表现。以下是一个实际案例,展示如何使用CTE和临时表来优化查询。
4.1 实例背景
假设我们有一个在线销售系统,需要定期生成销售报告。这个报告包括每个销售人员的总销售额、销售订单数量以及客户信息。
4.2 使用CTE的实现
首先,我们使用CTE来实现这个查询:
WITH SalesData AS (SELECT SalesPersonID,COUNT(SalesOrderID) AS OrderCount,SUM(TotalDue) AS TotalSalesFROM Sales.SalesOrderHeaderGROUP BY SalesPersonID
),
CustomerData AS (SELECT c.CustomerID, c.FirstName, c.LastName, s.SalesPersonIDFROM Sales.Customer cJOIN Sales.SalesOrderHeader sON c.CustomerID = s.CustomerID
)
SELECT sd.SalesPersonID, sd.OrderCount, sd.TotalSales, cd.FirstName, cd.LastName
FROM SalesData sd
JOIN CustomerData cd
ON sd.SalesPersonID = cd.SalesPersonID;
这个查询使用了两个CTE,将销售数据和客户数据分开处理,最后在主查询中合并结果。
4.3 使用临时表的实现
接下来,我们使用临时表来实现相同的查询:
CREATE TABLE #SalesData (SalesPersonID INT,OrderCount INT,TotalSales MONEY
);INSERT INTO #SalesData (SalesPersonID, OrderCount, TotalSales)
SELECT SalesPersonID, COUNT(SalesOrderID) AS OrderCount,SUM(TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader
GROUP BY SalesPersonID;CREATE TABLE #CustomerData (CustomerID INT,FirstName NVARCHAR(50),LastName NVARCHAR(50),SalesPersonID INT
);INSERT INTO #CustomerData (CustomerID, FirstName, LastName, SalesPersonID)
SELECT c.CustomerID, c.FirstName, c.LastName, s.SalesPersonID
FROM Sales.Customer c
JOIN Sales.SalesOrderHeader s
ON c.CustomerID = s.CustomerID;SELECT sd.SalesPersonID, sd.OrderCount, sd.TotalSales, cd.FirstName, cd.LastName
FROM #SalesData sd
JOIN #CustomerData cd
ON sd.SalesPersonID = cd.SalesPersonID;DROP TABLE #SalesData;
DROP TABLE #CustomerData;
使用临时表,我们将中间结果存储在两个临时表中,并在最终查询中合并结果。最后,我们删除临时表以释放资源。
第五部分:总结
CTE和临时表在SQL Server中的应用各有优劣。CTE简化代码,提高可读性,适合较简单的查询和层次结构数据处理。而临时表则提供更高的灵活性和性能优化手段,适用于复杂的多步骤查询和大数据量处理。在实际应用中,我们需要根据具体需求选择最合适的技术手段,以达到最佳的性能和可维护性。
相关文章:

SQL Server中的CTE和临时表优化
在SQL Server中,优化查询性能是数据库管理的核心任务之一。使用公用表表达式(CTE)和临时表是两种重要的技术手段。本文将深入探讨CTE如何简化代码,以及临时表如何优化查询性能。通过实例和详尽解释,我们将展示这两种技…...

CCRC信息安全服务资质认证是什么
什么是CCRC认证? CCRC 全称 China Cybersecurity Review Technology and Certification Center。CCRC认证是指中国网络安全审查技术与认证中心进行的信息安全服务资质认证。简称信息安全服务资质认证。 CCRC,即中国网络安全审查技术与认证中心࿰…...
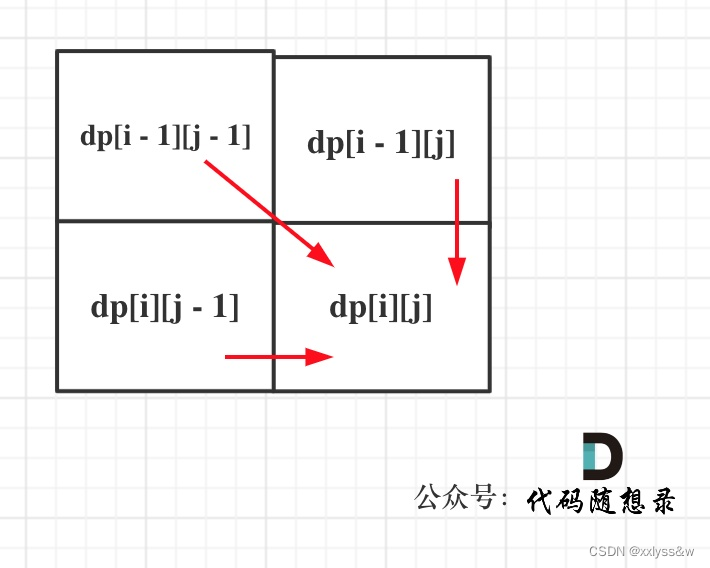
第五十一天 | 1143.最长公共子序列
题目:1143.最长公共子序列718.最长重复子数组的区别是,子序列不要求连续,子数组要求连续。这一差异体现在dp数组含义和递推公式中,本题是子序列,那就要考虑上nums1[i - 1] ! nums2[j - 1]的情况。 本道题与 1.dp数组…...

未来的5-10年,哪些行业可能会被AI代替?
在未来的5-10年,多个行业可能会受到AI技术的影响,其中一些工作可能会被AI所代替。以下是对可能被AI替代的行业及工作的一些概述: 客户服务与代表:随着AI技术的发展,特别是自动话术对话和语音生成技术的进步࿰…...

据报道,FTC 和 DOJ 对微软、OpenAI 和 Nvidia 展开反垄断调查
据《纽约时报》报道,联邦贸易委员会 (FTC) 和司法部 (DOJ) 同意分担调查微软、OpenAI 和 Nvidia 潜在反垄断违规行为的职责。 美国司法部将牵头对英伟达进行调查,而联邦贸易委员会将调查 OpenAI 与其最大投资者微软之间的交易。 喜好儿网 今年 1 月&a…...

人工智能发展历程和工具搭建学习
目录 人工智能的三次浪潮 开发环境介绍 Anaconda Anaconda的下载和安装 下载说明 安装指导 模块介绍 使用Anaconda Navigator Home界面介绍 Environment界面介绍 使用Jupter Notebook 打开Jupter Notebook 配置默认目录 新建文件 两种输入模式 Conda 虚拟环境 添…...

Dijkstra算法的原理
Dijkstra算法的原理可以清晰地分为以下几个步骤和要点: 初始化: 引入一个辅助数组D,其中D[i]表示从起始点(源点)到顶点i的当前已知最短距离。如果起始点与顶点i之间没有直接连接,则D[i]被初始化为无穷大&a…...
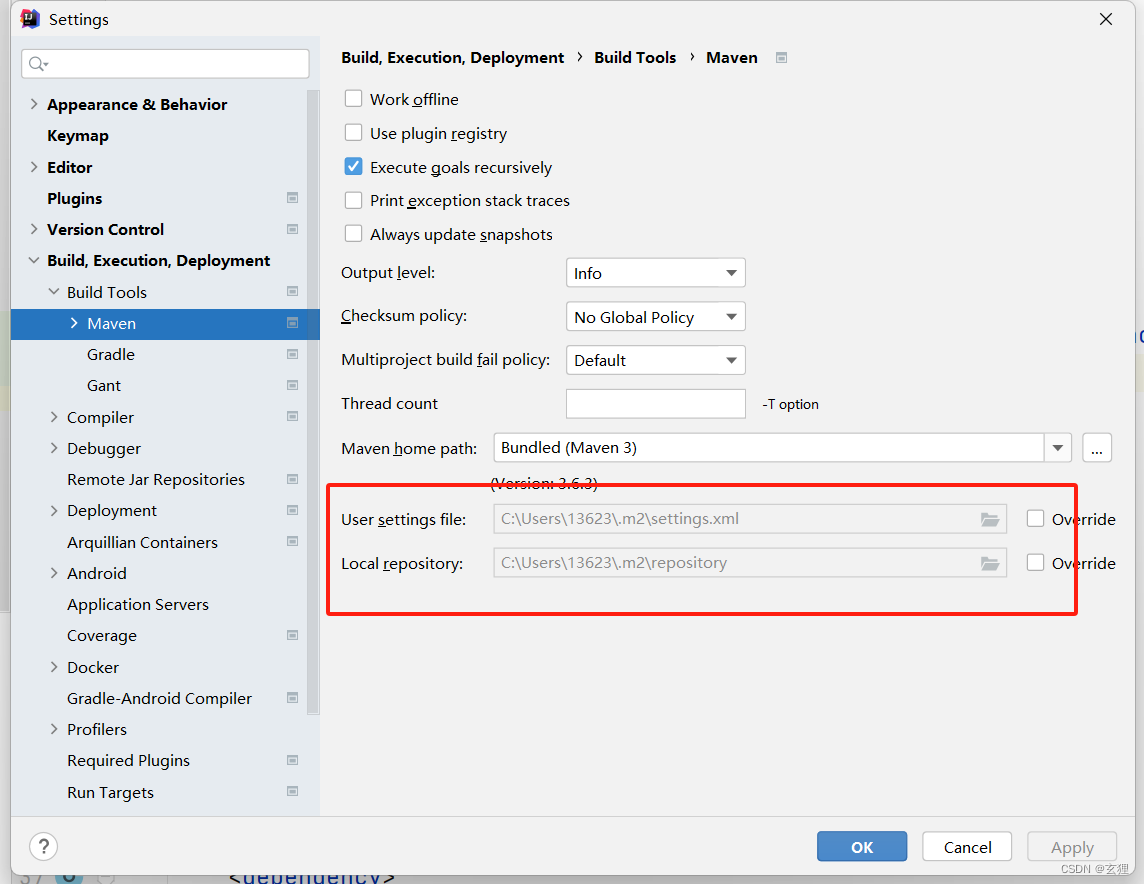
maven引入依赖时莫名报错
一般跟依赖的版本无关,会报出 Cannot resolve xxx 的错误。 这种情况下去IDEA的setting中找maven的仓库位置 在仓库中顺着包路径下寻找,可能会找到.lastUpdated 的文件,这样的文件一般是下载失败了,而且在一段时间内不再下载&…...

graalvm编译springboot3 native应用
云原生时代容器先行,为了更好的拥抱云原生,spring boot3之后,推出了graalvm编译boot项目,利用jvm的AOT( Ahead Of Time )运行前编译技术,可以将javay源码直接构建成机器码二进制的文件ÿ…...

代码随想录Day58
392.判断子序列 题目:392. 判断子序列 - 力扣(LeetCode) 思路:定义重合数记录s与t的比对情况,挨个取出t的字符,与s的字符进行比较,如果相同,重合数就加1,跳到s的下一个字…...
 与 dm-verity 之间的关系、相同点与差异点)
Android Verified Boot (AVB) 与 dm-verity 之间的关系、相同点与差异点
标签: AVB; dm-verity ;Android Android Verified Boot (AVB) 与 dm-verity 之间的关系、相同点与差异点 概述 Android Verified Boot (AVB) 和 dm-verity 是 Android 操作系统中用于确保设备启动过程和运行时数据完整性的两个重要技术。尽管它们有着不同的实现和侧重点,…...

C++学习笔记“类和对象”:多态;
目录 4.7 多态 4.7.1 多态的基本概念 4.7.2 多态案例--计算器类 4.7.3 纯虚函数和抽象类 4.7.4 多态案例二 - 制作饮品 4.7.5 虚析构和纯虚析构 4.7.6 多态案例三-电脑组装 4.7 多态 4.7.1 多态的基本概念 多态是C面向对象三大特性之一 多态分为两类 静志多态: 函数…...
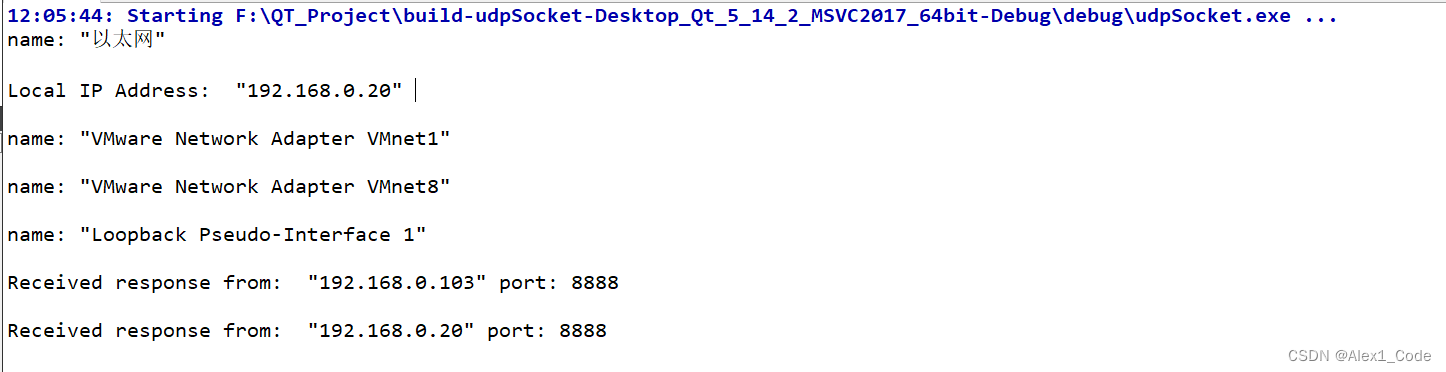
QT Udp广播实现设备发现
测试环境 本文选用pc1作为客户端,pc2,以及一台虚拟机作为服务端。 pc1,pc2(客户端): 虚拟机(服务端): 客户端 原理:客户端通过发送广播消息信息到ip:255.255.255.255(QHostAddress::Broadcast),局域网…...

PyTorch 统计属性-Tensor基本操作
最小 min, 最大 max, 均值 mean,累加 sum,累乘 prod … >>> a torch.arange(0,8).view(2,4).float() >>> a tensor([[0., 1., 2., 3.],[4., 5., 6., 7.]])>>> a.min() ## 最小值:tensor(0.) >>> a.ma…...
波拉西亚战记加速器 台服波拉西亚战记免费加速器
波拉西亚战记是一款新上线的MMORPG游戏,游戏内我们有多个角色职业可以选择,可以体验不同的战斗流派玩法,开放式的地图设计,玩家可以自由的进行探索冒险,寻找各种物资。各种随机事件可以触发,让玩家的冒险过…...

Mocha + Chai 测试环境配置,支持 ES6 语法
下面是一个完整的 Mocha Chai 测试环境配置,支持 ES6 语法。我们将使用 Babel 来转译 ES6 代码。 步骤一:初始化项目 首先,在项目目录中运行以下命令来初始化一个新的 Node.js 项目: npm init -y步骤二:安装必要的…...

华为网络设备攻击防范
畸形报文攻击防范 攻击行为 畸形报文攻击是通过向交换机发送有缺陷的IP报文,使得交换机在处理这样的IP包时会出现崩溃,给交换机带来损失。 畸形报文攻击主要有如下几种: 没有IP载荷的泛洪攻击 IGMP空报文攻击 LAND攻击 Smurf攻击 TCP标…...

RK3588开发笔记-100M网口自协商成1000M网口
目录 前言 一、问题描述 二、原理图连接 三、解决方法 总结 前言 在进行RK3588开发过程中,遇到一个令人困惑的问题:在使用RTL8211F-CG phy芯片出来的100M网口在自协商后连接速率变成了1000M。这篇博客将详细记录这个问题的产生、排查过程以及最终的解决方案,希望能对遇到…...
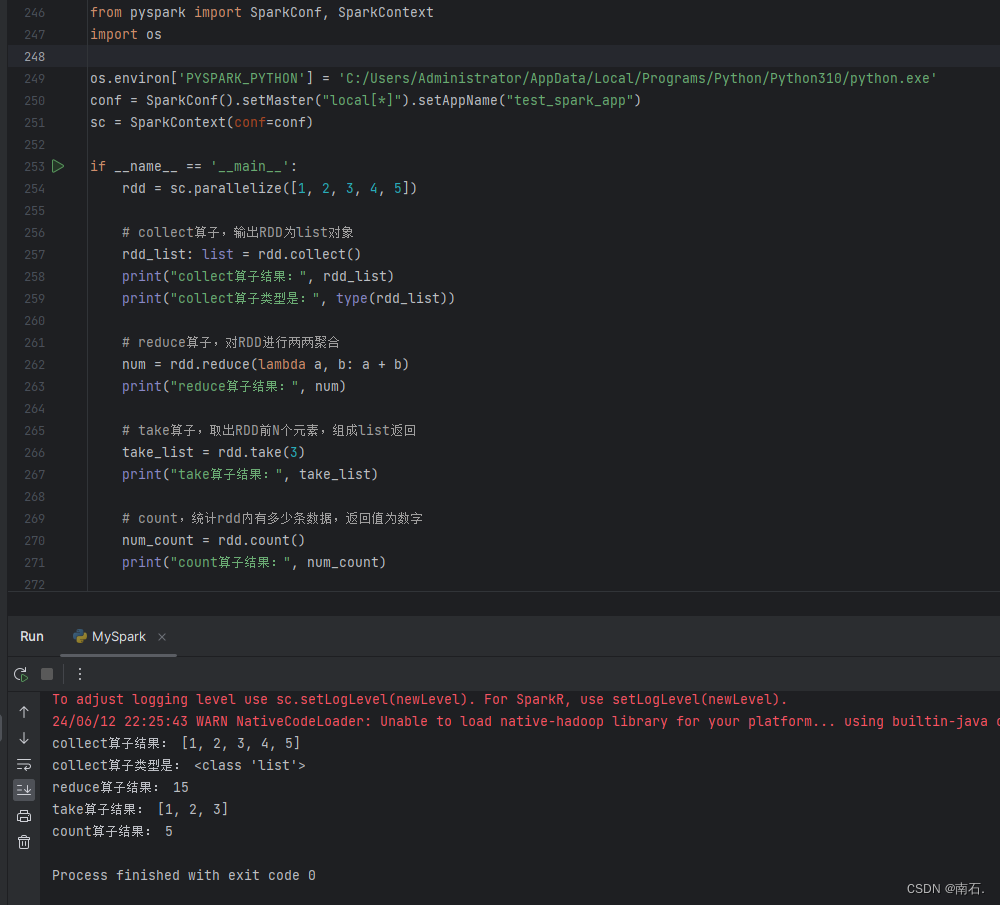
Python第二语言(十三、PySpark实战)
目录 1.开篇 2. PySpark介绍 3. PySpark基础准备 3.1 PySpark安装 3.2 掌握PySpark执行环境入口对象的构建 3.3 理解PySpark的编程模型 4. PySpark:RDD对象数据输入 4.1 RDD对象概念:PySpark支持多种数据的输入,完成后会返回RDD类的对…...

《阅读的方法》读后感——超越期待的收获
当我翻开这本书的扉页时,未曾料到它会给我带来如此深远的启示和收获。依照推荐序言中的指引,我随意翻阅、精心选读,每一次都如同打开一扇新的窗户,让我窥见不同领域的智慧和美好。 等地铁时、临睡前随便读点什么,有什么…...

深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践
深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript…...

如何快速掌握ppInk:Windows平台上的终极屏幕标注工具指南
如何快速掌握ppInk:Windows平台上的终极屏幕标注工具指南 【免费下载链接】ppInk Fork from Gink 项目地址: https://gitcode.com/gh_mirrors/pp/ppInk 你是否曾经在演示时需要快速标注屏幕内容,却发现现有工具要么功能太简陋,要么操作…...

Sendwithus模板与现代邮件客户端兼容性测试:终极解决方案
Sendwithus模板与现代邮件客户端兼容性测试:终极解决方案 【免费下载链接】templates Sendwithus Open Source Email Templates 项目地址: https://gitcode.com/gh_mirrors/temp/templates Sendwithus Open Source Email Templates是一套强大的开源邮件模板集…...

wBlock Safari扩展架构详解:5个内容拦截扩展的协同工作原理
wBlock Safari扩展架构详解:5个内容拦截扩展的协同工作原理 【免费下载链接】wBlock The next-generation ad blocker for Safari. 项目地址: https://gitcode.com/gh_mirrors/wb/wBlock wBlock是一款下一代Safari广告拦截器,通过创新的多扩展架构…...

Cursor AI插件开发:从代码补全到智能动作执行的范式演进
1. 项目概述:当AI代码助手遇上插件生态最近在GitHub上看到一个挺有意思的项目,叫RightbrainAI/cursor-plugin。光看名字,可能很多用惯了Cursor的朋友会眼前一亮,以为这是Cursor编辑器官方或者某个社区大神出的插件。但点进去仔细一…...

制造业生产能耗智能管控,落地步骤与落地成本优化方案:基于AI Agent与TARS大模型的全链路实战指引
在2026年的工业数字化浪潮中,制造业正面临前所未有的能源双控压力。随着工信部办公厅发布《关于组织开展2026年度工业节能监察工作的通知》,针对新能源产业链及重点耗能环节的监管已进入“精细化、实时化、透明化”的新阶段。对于企业而言,能…...

在 Claude Code 中配置 Taotoken 以解决封号与 Token 不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Claude Code 中配置 Taotoken 以解决封号与 Token 不足问题 对于依赖 Claude Code 进行编程辅助的开发者而言,服务中…...

MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验
MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验 【免费下载链接】MultiFunPlayer flexible application to synchronize various devices with media playback 项目地址: https://gitcode.com/gh_mirrors/mu/MultiFunPlayer …...

深度学习在甲状腺细胞病理诊断中的创新应用
1. 深度学习在甲状腺细胞病理学中的应用背景甲状腺癌是全球范围内最常见的内分泌系统恶性肿瘤之一,其发病率在过去几十年中持续上升。细针穿刺活检(FNAB)作为甲状腺结节诊断的金标准,其准确率直接影响后续治疗方案的选择。然而&am…...

YOLO26 + PySide6 采油井智能检测系统
基于YOLO26pyside6的采油井系统 代码界面全配齐! 核心优势: 1⃣️前沿技术:采用YOLO26深度学习模型,检测精度高、速度快,轻松识别采油井目标! 2⃣️功能齐全:含完整训练代码数据集(…...