如何保证数据库和缓存的一致性
背景:为了提高查询效率,一般会用redis作为缓存。客户端查询数据时,如果能直接命中缓存,就不用再去查数据库,从而减轻数据库的压力,而且redis是基于内存的数据库,读取速度比数据库要快很多。
更新数据库,更新缓存
由于引入了缓存,那么在数据更新时,不仅要更新数据库,而且要更新缓存,这两个更新操作存在前后的问题:
- 先更新数据库,再更新缓存;
- 先更新缓存,再更新数据库;
先更新数据库,再更新缓存
会存在并发问题。
举个例子,比如「请求 A 」和「请求 B 」两个请求,同时更新「同一条」数据,则可能出现这样的顺序:

请求A先将数据库更新为1,然后因为网络原因,缓存更新延迟了,在这之间请求B将数据库更新为2,并且把缓存更新为2了,之后缓存更新为1才更新成功,那么此时数据库中数据是2,缓存中数据为1,出现了数据不一致现象。
先更新缓存,再更新数据库
那换成「先更新缓存,再更新数据库」这个方案,还会有问题吗?
依然还是存在并发的问题。
假设「请求 A 」和「请求 B 」两个请求,同时更新「同一条」数据,则可能出现这样的顺序:
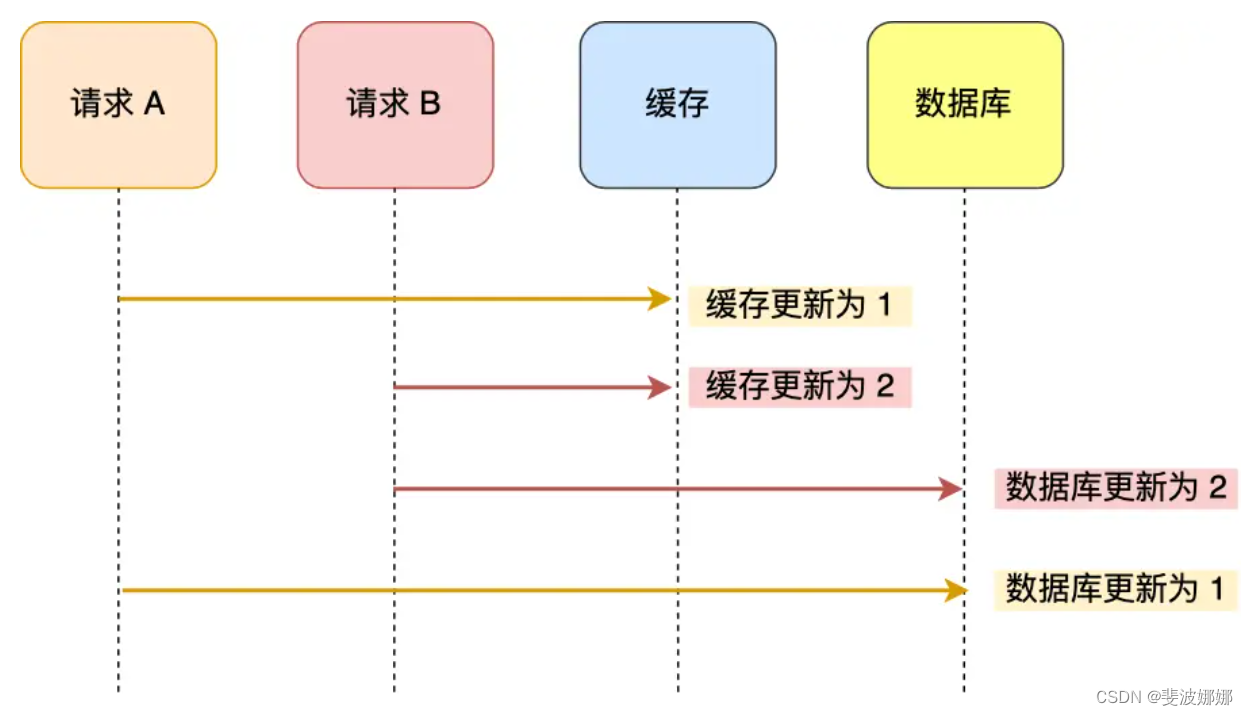
A 请求先将缓存的数据更新为 1,然后在更新数据库前,B 请求来了, 将缓存的数据更新为 2,紧接着把数据库更新为 2,然后 A 请求将数据库的数据更新为 1。
此时,数据库中的数据是 1,而缓存中的数据却是 2,出现了缓存和数据库中的数据不一致的现象。
所以,无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
更新数据库,删除缓存
在更新数据时,不更新缓存,而是删除缓存中的数据。然后,到读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。这个策略叫 Cache Aside 策略,中文是叫旁路缓存策略。
该策略又可以细分为「读策略」和「写策略」。
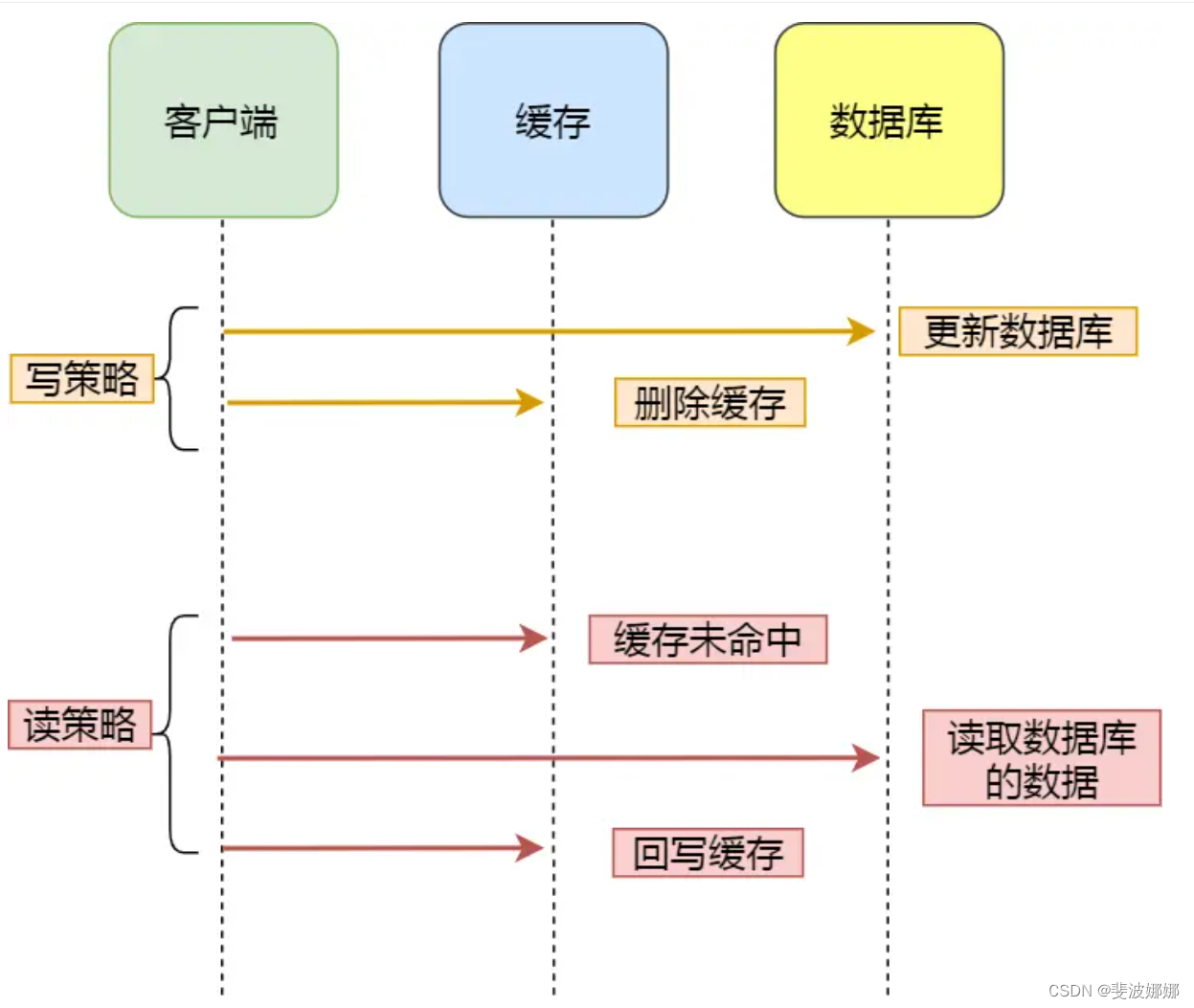
写策略的步骤:
- 更新数据库中的数据;
- 删除缓存中的数据。
读策略的步骤:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
先删除缓存,再更新数据库
假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21。
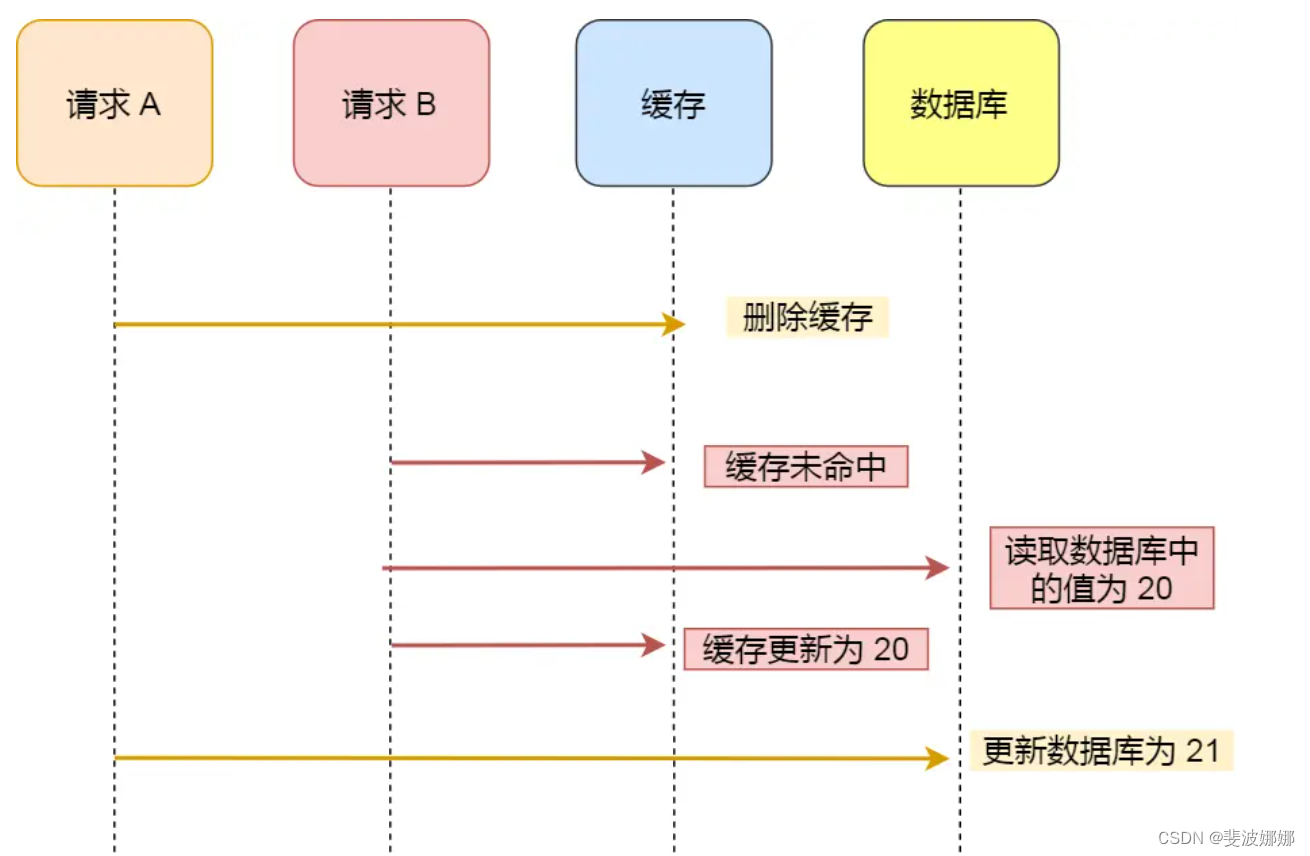
最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库的数据不一致。
可以看到,先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题。
延迟双删
针对这个问题,可以使用延迟双删
延迟双删实现的伪代码如下:
#删除缓存
redis.delKey(X)
#更新数据库
db.update(X)
#睡眠
Thread.sleep(N)
#再删除缓存
redis.delKey(X)
加了个睡眠时间,主要是为了确保请求 A 在睡眠的时候,请求 B 能够在这这一段时间完成「从数据库读取数据,再把缺失的缓存写入缓存」的操作,然后请求 A 睡眠完,再删除缓存。
所以,请求 A 的睡眠时间就需要大于请求 B 「从数据库读取数据 + 写入缓存」的时间。
先更新数据库,再删除缓存
假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中。
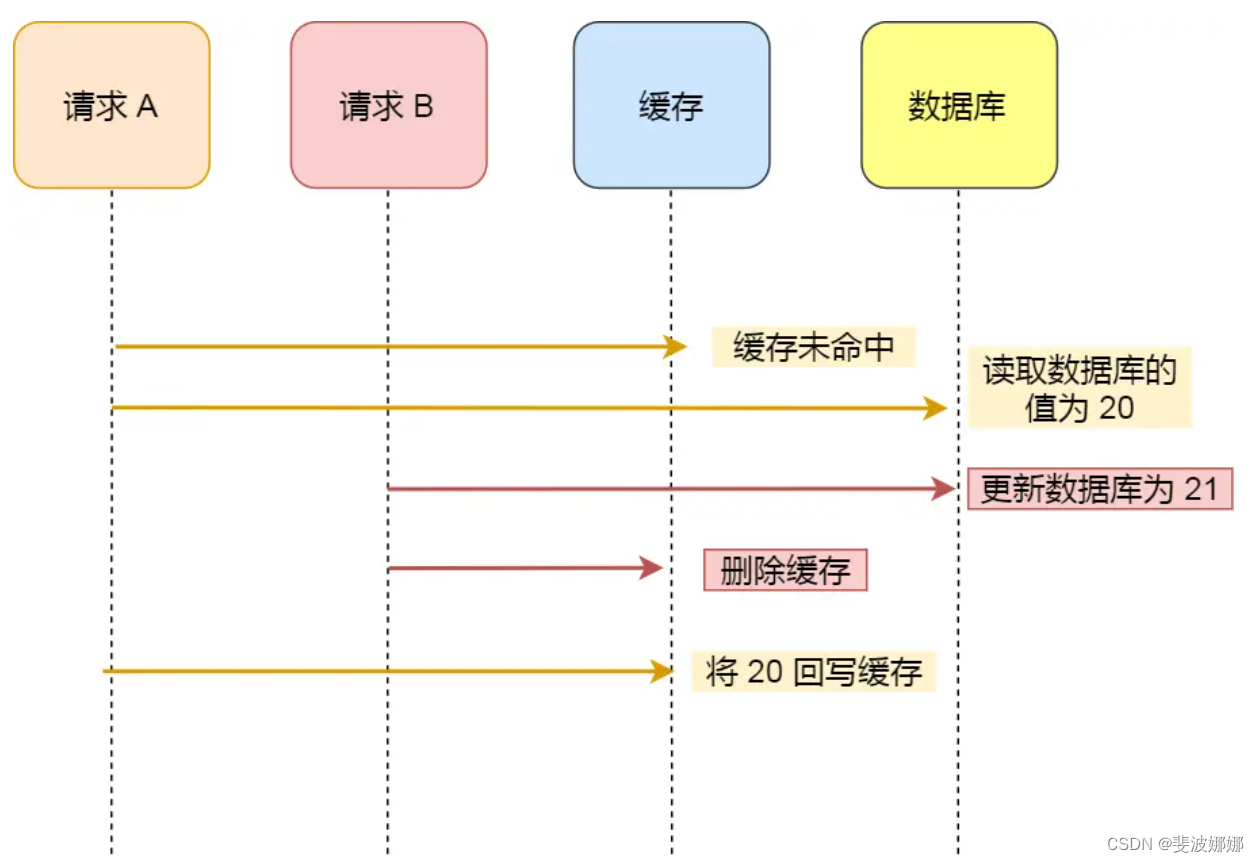
最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库数据不一致。
从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题,但是在实际中,这个问题出现的概率并不高。
因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。
而一旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据,所以不会出现这种不一致的情况。
所以,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
为了确保万无一失,还可以给缓存数据加上了「过期时间」,就算在这期间存在缓存数据不一致,有过期时间来兜底,这样也能达到最终一致。
问题:
「先更新数据库, 再删除缓存」其实是两个操作,前面的所有分析都是建立在这两个操作都能同时执行成功,但是删除缓存(第二个操作)的时候失败了,导致缓存中的数据是旧值。
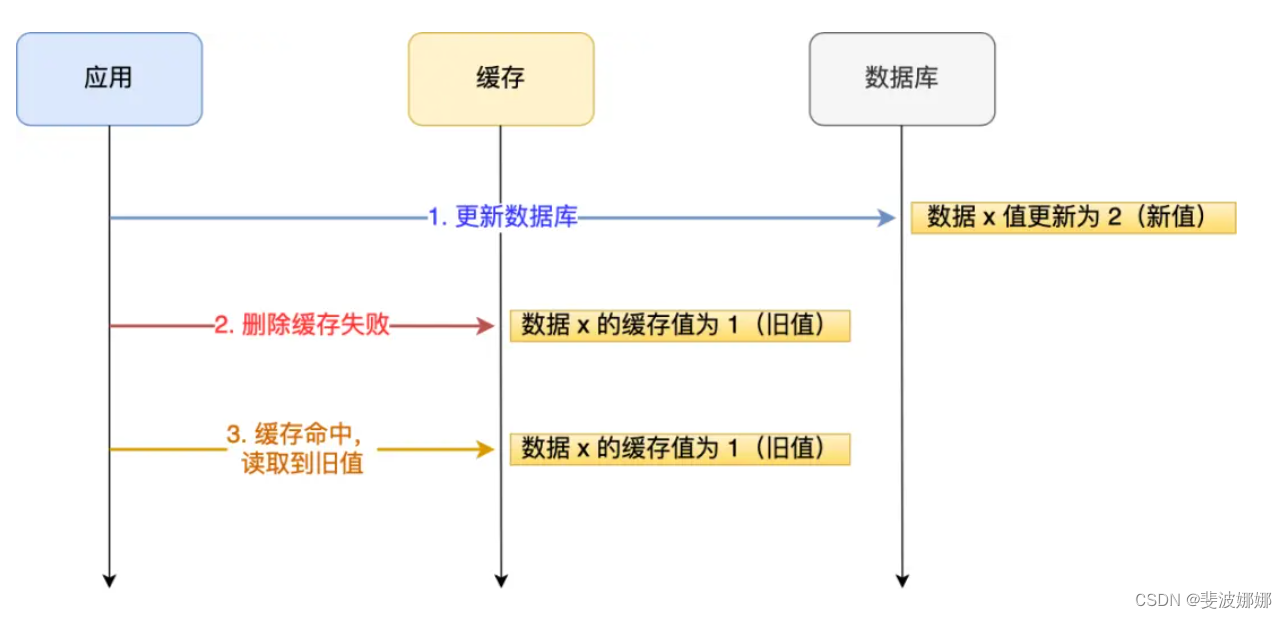
怎么解决?
重试机制
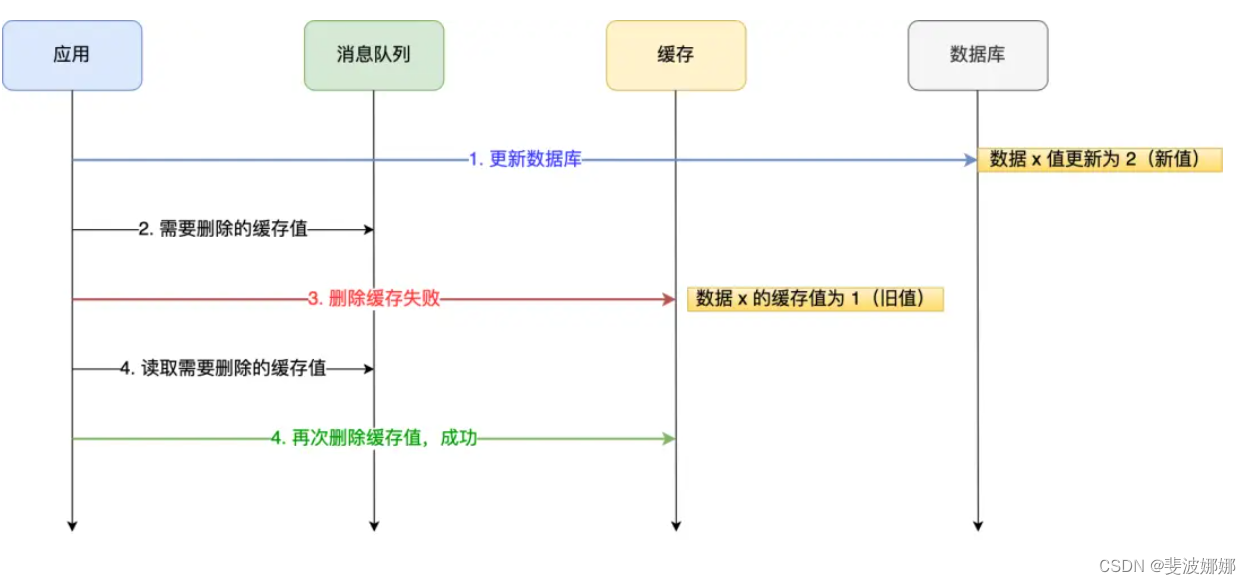
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
- 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
可能疑惑的点
为什么是删除缓存,而不是更新缓存呢?
删除一个数据,相比更新一个数据更加轻量级,出问题的概率更小。在实际业务中,缓存的数据可能不是直接来自数据库表,也许来自多张底层数据表的聚合。
比如商品详情信息,在底层可能会关联商品表、价格表、库存表等,如果更新了一个价格字段,那么就要更新整个数据库,还要关联的去查询和汇总各个周边业务系统的数据,这个操作会非常耗时。 从另外一个角度,不是所有的缓存数据都是频繁访问的,更新后的缓存可能会长时间不被访问,所以说,从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是一个更好的方案。
系统设计中有一个思想叫 Lazy Loading,适用于那些加载代价大的操作,删除缓存而不是更新缓存,就是懒加载思想的一个应用。
相关文章:
如何保证数据库和缓存的一致性
背景:为了提高查询效率,一般会用redis作为缓存。客户端查询数据时,如果能直接命中缓存,就不用再去查数据库,从而减轻数据库的压力,而且redis是基于内存的数据库,读取速度比数据库要快很多。 更新…...

Java基础 - 多线程
多线程 创建新线程 实例化一个Thread实例,然后调用它的start()方法 Thread t new Thread(); t.start(); // 启动新线程从Thread派生一个自定义类,然后覆写run()方法: public class Main {public static void main(String[] args) {Threa…...

云顶之弈-测试报告
一. 项目背景 个人博客系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据,同时将其部署到云服务器上。前端主要有四个页面构成:登录页、列表页、详情页以及编辑页,以上模拟实现了最简单的个人博客系统。其结合后…...
TCP/IP协议分析实验:通过一次下载任务抓包分析
TCP/IP协议分析 一、实验简介 本实验主要讲解TCP/IP协议的应用,通过一次下载任务,抓取TCP/IP数据报文,对TCP连接和断开的过程进行分析,查看TCP“三次握手”和“四次挥手”的数据报文,并对其进行简单的分析。 二、实…...
)
Python项目开发实战:企业QQ小程序(案例教程)
一、引言 在当今数字化快速发展的时代,企业对于线上服务的需求日益增长。企业QQ小程序作为一种轻量级的应用形态,因其无需下载安装、即开即用、占用内存少等优势,受到了越来越多企业的青睐。本文将以Python语言为基础,探讨如何开发一款企业QQ小程序,以满足企业的实际需求。…...

list模拟与实现(附源码)
文章目录 声明list的简单介绍list的简单使用list中sort效率测试list的简单模拟封装迭代器insert模拟erase模拟头插、尾插、头删、尾删模拟自定义类型迭代器遍历const迭代器clear和析构函数拷贝构造(传统写法)拷贝构造(现代写法) 源…...

Java应用中文件上传安全性分析与安全实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一. 文件上传的风险 二. 使用合适的框架和库 1. Spr…...
noVNC 小记
1. 怎么查看Ubuntu版本...
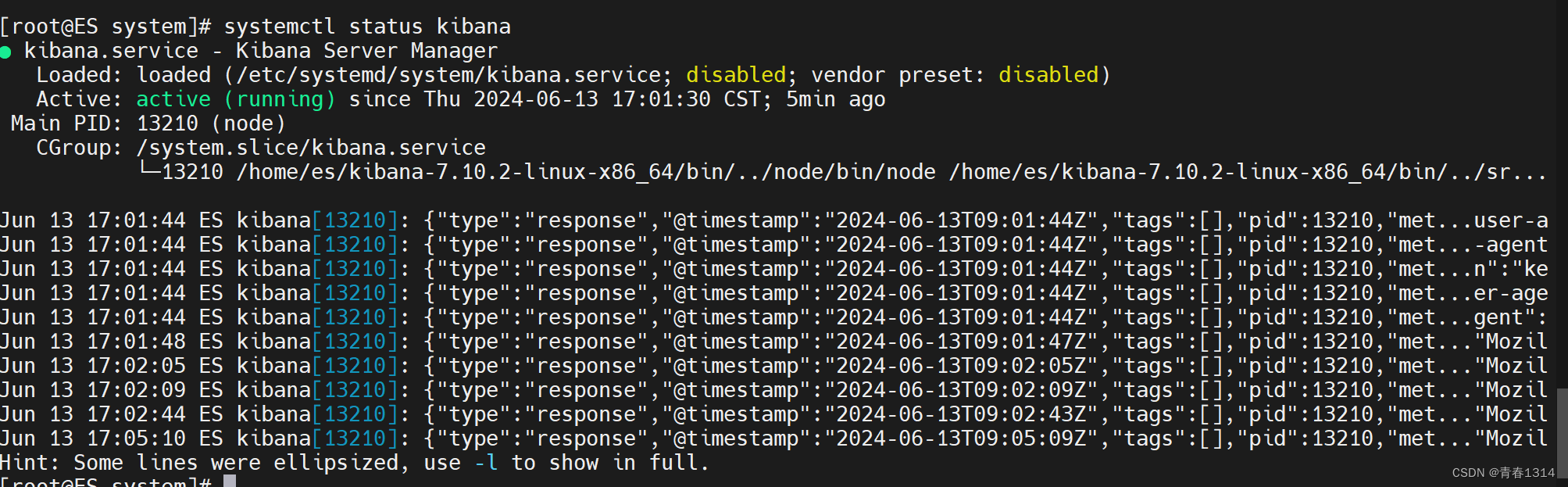
设置systemctl start kibana启动kibana
1、编辑kibana.service vi /etc/systemd/system/kibana.service [Unit] DescriptionKibana Server Manager [Service] Typesimple Useres ExecStart/home/es/kibana-7.10.2-linux-x86_64/bin/kibana PrivateTmptrue [Install] WantedBymulti-user.target 2、启动kibana # 刷…...

PostgreSQL:在CASE WHEN语句中使用SELECT语句
CASE WHEN语句是一种条件语句,用于多条件查询,相当于java的if/else。它允许我们根据不同的条件执行不同的操作。你甚至能在条件里面写子查询。而在一些情况下,我们可能需要在CASE WHEN语句中使用SELECT语句来检索数据或计算结果。下面是一些示…...

游戏心理学Day13
游戏成瘾 成瘾的概念来自于药物依赖,表现为为了感受药物带来的精神效应,或是为了避免由于断药所引起的不适和强迫性,连续定期使用该药的 行为现在成瘾除了药物成瘾外,还包括行为成瘾。成瘾的核心特征是不知道成瘾的概念来自于药…...

GitLab中用户权限
0 Preface/Foreword 1 权限介绍 包含5种权限: Guest(访客):可以创建issue、发表comment,不能读写版本库Reporter(报告者):可以克隆代码,不能提交。适合QA/PMDeveloper&…...

RunMe_About PreparationForDellBiosWUTTest
:: ***************************************************************************************************************************************************************** :: 20240613 :: 该脚本可以用作BIOS WU测试前的准备工作,包括:自动检测"C:\DellB…...

C++中变量的使用细节和命名方案
C中变量的使用细节和命名方案 C提倡使用有一定含义的变量名。如果变量表示差旅费,应将其命名为cost_of_trip或 costOfTrip,而不要将其命名为x或cot。必须遵循几种简单的 C命名规则。 在名称中只能使用字母字符、数字和下划线()。 名称的第一个字符不能是数字。 区分…...

[ACTF新生赛2020]SoulLike
两个文件 ubuntu运行 IDA打开 清晰的逻辑 很明显,我们要sub83a 返回ture 这里第一个知识点来了 你点开汇编会发现 这里一堆xor巨多 然后IDA初始化设置的函数,根本不能分析这么多 我们要去改IDA的设置 cfg 里面的 hexrays文件 在max_funsize这 修改为1024,默认是64 等待一…...

C#——析构函数详情
析构函数 C# 中的析构函数(也被称作“终结器”)同样是类中的一个特殊成员函数,主要用于在垃圾回收器回收类实例时执行一些必要的清理操作。 析构函数: 当一个对象被释放的时候执行 C# 中的析构函数具有以下特点: * 析构函数只…...

探索重要的无监督学习方法:K-means 聚类模型
在数据科学和机器学习领域,聚类分析是一种重要的无监督学习方法,用于将数据集中的对象分成多个组(簇),使得同一簇中的对象相似度较高,而不同簇中的对象相似度较低。K-means 聚类是最广泛使用的聚类算法之一,它以其简单、快速和易于理解的特点受到了广泛关注。本文将深入…...

将web项目打包成electron桌面端教程(二)vue3+vite+ts
说明:我用的demo项目是vue3vitets,如果是vue2/cli就不用往下看啦,建议找找其他教程哦~下依赖npm下载不下来的,基本换成cnpm/pnpm/yarn就可以了 一、项目准备 1、自己新创建一个,这里就不过多赘述了 2、将需要打包成…...

Linux下的/etc/resolv.conf
Linux下的/etc/resolv.conf 文件用于配置域名解析器的设置,告诉系统在解析域名时要查询哪些DNS服务器。nameserver:指定DNS服务器的IP地址。你可以列出多个nameserver,系统将按顺序尝试它们,直到找到可用的DNS服务器。 nameserve…...

大语言模型 (LLM) 红队测试:提前解决模型漏洞
大型语言模型 (LLM) 的兴起具有变革性,以其在自然语言处理和生成方面具有与人类相似的卓越能力,展现出巨大的潜力。然而,LLM 也被发现存在偏见、提供错误信息或幻觉、生成有害内容,甚至进行欺骗行为的情况。一些备受关注的事件包括…...

Qwen2.5-VL-7B-Instruct Visual Studio开发环境配置全攻略
Qwen2.5-VL-7B-Instruct Visual Studio开发环境配置全攻略 1. 开篇:为什么选择Visual Studio进行AI开发 如果你正在探索多模态AI开发,特别是像Qwen2.5-VL-7B-Instruct这样的视觉语言模型,那么Visual Studio可能是你最得力的开发伙伴。作为一…...

qmc-decoder:QMC加密音乐格式转换工具的全方位应用指南
qmc-decoder:QMC加密音乐格式转换工具的全方位应用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 一、问题引入:当音乐文件被"锁住"…...

网络原理视角下的CasRel模型分布式部署与通信优化
网络原理视角下的CasRel模型分布式部署与通信优化 最近在帮一个团队落地一个关系抽取项目,他们用的就是CasRel模型。模型本身效果不错,但一到线上高并发场景,单实例就扛不住了,响应延迟飙升,还时不时挂掉。这让我意识…...

LM339比较器:从基础参数到典型应用场景解析
1. LM339比较器基础解析 第一次接触LM339时,我完全被它"四合一"的设计惊艳到了——这个比指甲盖还小的芯片里,竟然藏着四个独立工作的电压比较器。简单来说,它就像四个并排摆放的天平,能同时比较八路电压信号的高低。实…...

UI-TARS-desktop部署避坑指南:快速解决模型启动问题
UI-TARS-desktop部署避坑指南:快速解决模型启动问题 1. UI-TARS-desktop概述 1.1 核心功能与架构 UI-TARS-desktop是一款基于Qwen3-4B-Instruct-2507模型的多模态AI应用框架,采用vLLM推理引擎提供高效服务。该系统将大语言模型能力与桌面自动化操作相…...

OpenClaw版本升级指南:Qwen3.5-9B兼容性测试方法
OpenClaw版本升级指南:Qwen3.5-9B兼容性测试方法 1. 为什么需要专门的升级测试 上周五凌晨三点,我的OpenClaw自动化脚本突然集体罢工——前一天刚更新的框架版本与Qwen3.5-9B模型产生了微妙的兼容性问题。鼠标指针在屏幕上鬼畜般抖动,却始终…...

DirectDraw兼容性新纪元:让经典游戏在现代Windows系统重生
DirectDraw兼容性新纪元:让经典游戏在现代Windows系统重生 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DD…...

OpenClaw节能模式:让SecGPT-14B在笔记本上流畅运行的配置
OpenClaw节能模式:让SecGPT-14B在笔记本上流畅运行的配置 1. 为什么需要节能模式? 去年冬天,我的MacBook Pro在运行SecGPT-14B时发烫到可以当暖手宝的程度,续航时间从8小时骤降到不足90分钟。这促使我开始研究OpenClaw的节能配置…...

无感方波控制方案-脉冲启动与凸极性电机保护功能全面标题:‘无感方波方案-无抖动无反转启动...
无感方波方案,无感启动无抖动,无反转,启动方式为脉冲注入检测位置,换相方式为AD比较器,电机要有一定凸极性 ,电机要有一定凸极性,电机要有一定凸极性! 软件做有各种保护功能&#x…...

嵌入式系统LCD汉字显示原理与优化实践
1. 嵌入式屏幕显示汉字的基本原理在嵌入式系统中,LCD屏幕显示汉字的核心原理可以概括为"点阵映射"。这与我们小时候玩过的LED点阵显示原理完全相同。想象一下,当你用许多小灯泡排列成一个方阵,通过控制每个灯泡的亮灭来组成图案或文…...