Spark高手之路1—Spark简介
文章目录
- Spark 概述
- 1. Spark 是什么
- 2. Spark与Hadoop比较
- 2.1 从时间节点上来看
- 2.2 从功能上来看
- 3. Spark Or Hadoop
- 4. Spark
- 4.1 速度快
- 4.2 易用
- 4.3 通用
- 4.4 兼容
- 5. Spark 核心模块
- 5.1 Spark-Core 和 弹性分布式数据集(RDDs)
- 5.2 Spark SQL
- 5.3 Spark Streaming
- 5.4 Spark MLlib
- 5.5 Spark GraphX

Spark 概述
1. Spark 是什么


Spark官网
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算.
Spark 只是一个计算框架, 不像 Hadoop 一样包含了分布式文件系统和完备的调度系统, 如果要使用 Spark, 需要搭载其它的文件系统和更成熟的调度系统
2. Spark与Hadoop比较
在之前的学习中,Hadoop 的 MapReduce 是大家广为熟知的计算框架,那为什么咱们还要学习新的计算框架 Spark 呢,这里就不得不提到 Spark 和 Hadoop 的关系。
2.1 从时间节点上来看
➢ Hadoop
⚫ 2006 年 1 月,Doug Cutting 加入 Yahoo,领导 Hadoop 的开发
⚫ 2008 年 1 月,Hadoop 成为 Apache 顶级项目
⚫ 2011 年 1.0 正式发布
⚫ 2012 年 3 月稳定版发布
⚫ 2013 年 10 月发布 2.X (Yarn)版本
⚫ 2014-2017:Spark成为Apache顶级项目Hadoop3.0.0版本发布。
➢ Spark
⚫ 2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室
⚫ 2010 年,伯克利大学正式开源了 Spark 项目
⚫ 2013 年 6 月,Spark 成为了 Apache 基金会下的项目
⚫ 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目
⚫ 2014 年 11 月, Spark的母公司Databricks团队使用Spark刷新数据排序世界记录
⚫ 2015 年至今,Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark
2.2 从功能上来看
➢ Hadoop
⚫ Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架
⚫ 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有的 数 据 , 支 持 着 Hadoop 的 所 有 服 务 。 它 的 理 论 基 础 源 于 Google 的TheGoogleFileSystem 这篇论文,它是 GFS 的开源实现。
⚫ MapReduce 是一种编程模型,Hadoop 根据 Google 的 MapReduce 论文将其实现,作为 Hadoop 的分布式计算模型,是 Hadoop 的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了 HDFS 的分布式存储和 MapReduce 的分布式计算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。
⚫ HBase 是对 Google 的 Bigtable 的开源实现,但又和 Bigtable 存在许多不同之处。HBase 是一个基于 HDFS 的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是 Hadoop 非常重要的组件。
➢ Spark
⚫ Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
⚫ Spark Core 中提供了 Spark 最基础与最核心的功能
⚫ Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
⚫ Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
Spark 和 Hadoop 的异同
| Hadoop | Spark | |
|---|---|---|
| 类型 | 基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算,交互式计算,流计算 |
| 延迟 | 大 | 小 |
| 易用性 | API较为底层,算法适应性差 | API较为顶层,方便使用 |
| 价格 | 对机器要求低,便宜 | 对内存有要求,相对较贵 |
由上面的信息可以获知,Spark 出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实 Spark 一直被认为是 Hadoop 框架的升级版。
3. Spark Or Hadoop
Hadoop 的 MR 框架和 Spark 框架都是数据处理框架,那么我们在使用时如何选择呢?
⚫ Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。认识到这个问题后, 学术界的 AMPLab 提出了一个新的模型, 叫做 RDDs。RDDs 是一个可以容错且并行的数据结构, 它可以让用户显式的将中间结果数据集保存在内中, 并且通过控制数据集的分区来达到数据存放处理最优化。同时 RDDs 也提供了丰富的 API 来操作数据集。后来 RDDs 被 AMPLab 在一个叫做 Spark 的框架中提供并开源。Spark 就是在传统的 MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。
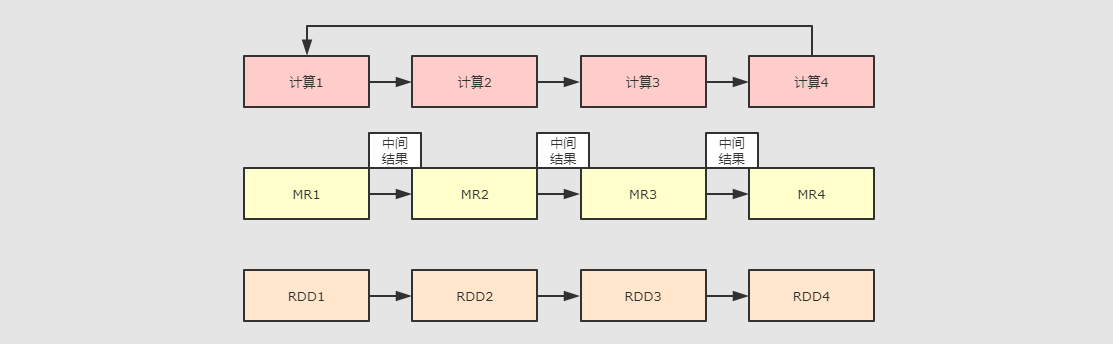
⚫ 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR 这种模式不太合适,即使多 MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而Spark 所基于的 scala 语言恰恰擅长函数的处理。
⚫ Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
⚫ Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
⚫ Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。
⚫ Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互
⚫ Spark 的缓存机制比 HDFS 的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
4. Spark
4.1 速度快
- Spark 的在内存时的运行速度是 Hadoop MapReduce 的100倍
- 基于硬盘的运算速度大概是 Hadoop MapReduce 的10倍
- Spark 实现了一种叫做 RDDs 的 DAG 执行引擎, 其数据缓存在内存中可以进行迭代处理
4.2 易用
- Spark 支持 Java, Scala, Python, R, SQL 等多种语言的API.
- Spark 支持超过80个高级运算符使得用户非常轻易的构建并行计算程序
- Spark 可以使用基于 Scala, Python, R, SQL的 Shell 交互式查询.
4.3 通用
- Spark 提供一个完整的技术栈, 包括 SQL执行, Dataset命令式API, 机器学习库MLlib, 图计算框架GraphX, 流计算SparkStreaming
- 用户可以在同一个应用中同时使用这些工具, 这一点是划时代的
4.4 兼容
- Spark 可以运行在 Hadoop Yarn, Apache Mesos, Kubernets, Spark Standalone等集群中
- Spark 可以访问 HBase, HDFS, Hive, Cassandra 在内的多种数据库
5. Spark 核心模块

5.1 Spark-Core 和 弹性分布式数据集(RDDs)
- Spark 最核心的功能是 RDDs, RDDs 存在于 Spark-core 这个包内,,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
- Spark-Core 是整个 Spark 的基础, 提供了分布式任务调度和基本的 I/O 功能
- Spark 的基础的程序抽象是弹性分布式数据集(RDDs), 是一个可以并行操作, 有容错的数据集合
- RDDs 可以通过引用外部存储系统的数据集创建(如HDFS, HBase), 或者通过现有的 RDDs 转换得到
- RDDs 抽象提供了 Java, Scala, Python 等语言的API
- RDDs 简化了编程复杂性, 操作 RDDs 类似通过 Scala 或者 Java8 的Streaming 操作本地数据集合
5.2 Spark SQL
- Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark SQL 在 spark-core 基础之上带出了一个名为 DataSet 和 DataFrame 的数据抽象化的概念
- Spark SQL 提供了在 Dataset 和 DataFrame 之上执行 SQL 的能力
- Spark SQL 提供了 DSL, 可以通过 Scala, Java, Python 等语言操作 DataSet 和 DataFrame
- 它还支持使用 JDBC/ODBC 服务器操作 SQL 语言
5.3 Spark Streaming
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- Spark Streaming 充分利用 spark-core 的快速调度能力来运行流分析
- 它截取小批量的数据并可以对之运行 RDD Transformation
- 它提供了在同一个程序中同时使用流分析和批量分析的能力
5.4 Spark MLlib
- MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- MLlib 是 Spark 上分布式机器学习的框架. Spark分布式内存的架构 比 Hadoop磁盘式 的 Apache Mahout 快上 10 倍, 扩展性也非常优良
- MLlib 可以使用许多常见的机器学习和统计算法, 简化大规模机器学习
- 汇总统计, 相关性, 分层抽样, 假设检定, 随即数据生成
- 支持向量机, 回归, 线性回归, 逻辑回归, 决策树, 朴素贝叶斯
- 协同过滤, ALS
- K-means
- SVD奇异值分解, PCA主成分分析
- TF-IDF, Word2Vec, StandardScaler
- SGD随机梯度下降, L-BFGS
5.5 Spark GraphX
- GraphX 是 Spark 面向图计算提供的框架与算法库。
- GraphX 是分布式图计算框架, 提供了一组可以表达图计算的 API, GraphX 还对这种抽象化提供了优化运行
Spark
相关文章:
Spark高手之路1—Spark简介
文章目录Spark 概述1. Spark 是什么2. Spark与Hadoop比较2.1 从时间节点上来看2.2 从功能上来看3. Spark Or Hadoop4. Spark4.1 速度快4.2 易用4.3 通用4.4 兼容5. Spark 核心模块5.1 Spark-Core 和 弹性分布式数据集(RDDs)5.2 Spark SQL5.3 Spark Streaming5.4 Spark MLlib5.5…...

社科院与杜兰大学金融管理硕士项目——人生没有太晚的开始,不要过早的放弃
经常听到有人问,“我都快40了,现在学车晚不晚呢”“现在考研晚不晚?”“学画画晚不晚?”提出这些疑问的人,往往存在拖延,想法只停留在想的阶段,从来不去行动。当看到周边行动起来的人开始享受成…...

Spatial-Temporal Graph ODE Networks for Traffic Flow Forecasting
Spatial-Temporal Graph ODE Networks for Traffic Flow Forecasting 摘要 交通流量的复杂性和长范围时空相关性是难点 经典现存的工作: 1.利用浅图神经网络(shallow graph convolution networks)和 时间提取模块去分别建模空间和时间依赖…...

IP协议+以太网协议
在计算机网络体系结构的五层协议中,第三层就是负责建立网络连接,同时为上层提供服务的一层,网络层协议主要负责两件事:即地址管理和路由选择,下面就网络层的重点协议做简单介绍~~ IP协议 网际协议IP是TCP/IP体系中两…...
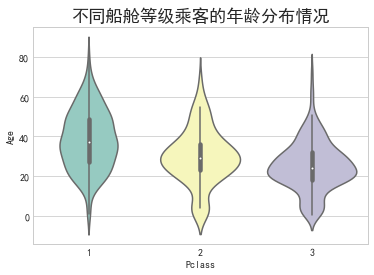
可视化组件届的仙女‖蝴蝶结图、玫瑰环图、小提琴图
在上一篇内容中为大家介绍了几个堪称可视化组件届吴彦祖的高级可视化图表。既然帅哥有了,怎么能少得了美女呢?今天就为大家介绍几个可视化组件届的“美女姐姐”,说一句是组件届的刘亦菲不为过。蝴蝶结图蝴蝶结图因其形似蝴蝶结而得名…...

人的高级认知:位置感
你知道吗?人有个高级认知:位置感 位置感是啥?咋提高位置感? 趣讲大白话:知道自己几斤几两 【趣讲信息科技99期】 ******************************* 位置感 就是对自己所处环境和自身存在的领悟 属于人生智慧 来源于阅历…...
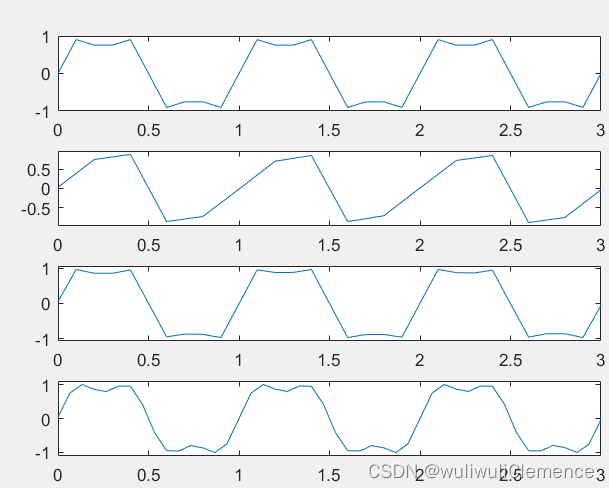
MATLAB——信号的采样与恢复
**题目:**已知一个连续时间信号 其中:f01HZ,取最高有限带宽频率fm5f0。分别显示原连续时间信号波形和 3种情况下抽样信号的波形。并画出它们的幅频特性曲线,并对采样后的信号进行恢复。 step1.绘制出采样信号 这部分相对简单…...

Docker Nginx 反向代理
最近在系统性梳理网关的知识,其中网关的的功能有一个是代理,正好咱们常用的Nginx也具备次功能,今天正好使用Nginx实现一下反向代理,与后面网关的代理做一个对比,因为我使用的docker安装的Nginx,与直接部署N…...

手把手教你实现书上的队列,进来试试?
一.队列的基本概念队列的定义队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允…...
【springboot】springboot介绍
学习资料 SpringBoot 语雀 (yuque.com)【尚硅谷】SpringBoot2零基础入门教程(spring boot2干货满满)_哔哩哔哩_bilibiliSpringBoot2核心技术与响应式编程: SpringBoot2核心技术与响应式编程 (gitee.com) Spring 和Springboot 1、Spring能做什么 1.1…...
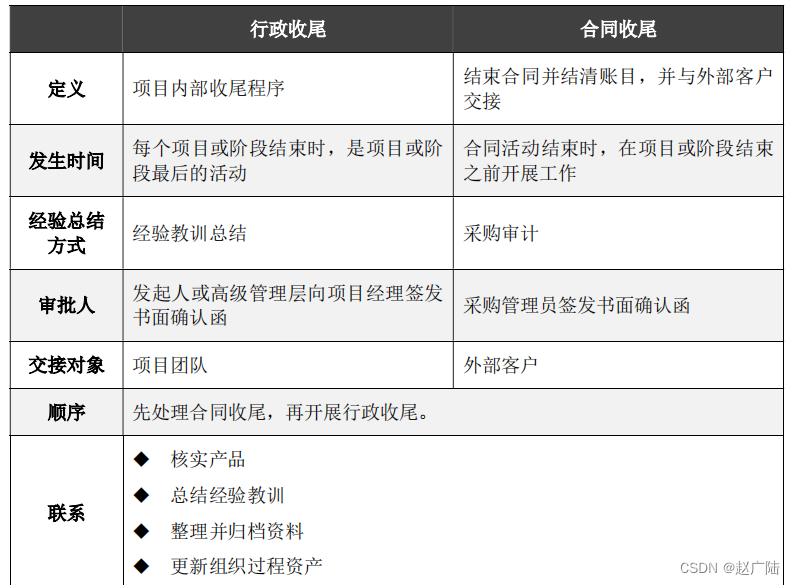
PMP项目管理项目整合管理
目录1 项目整合管理概述2 制定项目章程3 制定项目管理计划4 指导与管理项目工作5 管理项目知识6 监控项目工作7 实施整体变更控制8 结束项目或阶段1 项目整合管理概述 项目整合管理包括对隶属于项目管理过程组的各种过程和项目管理活动进行识别、定义、组合、统一和协调的各个…...
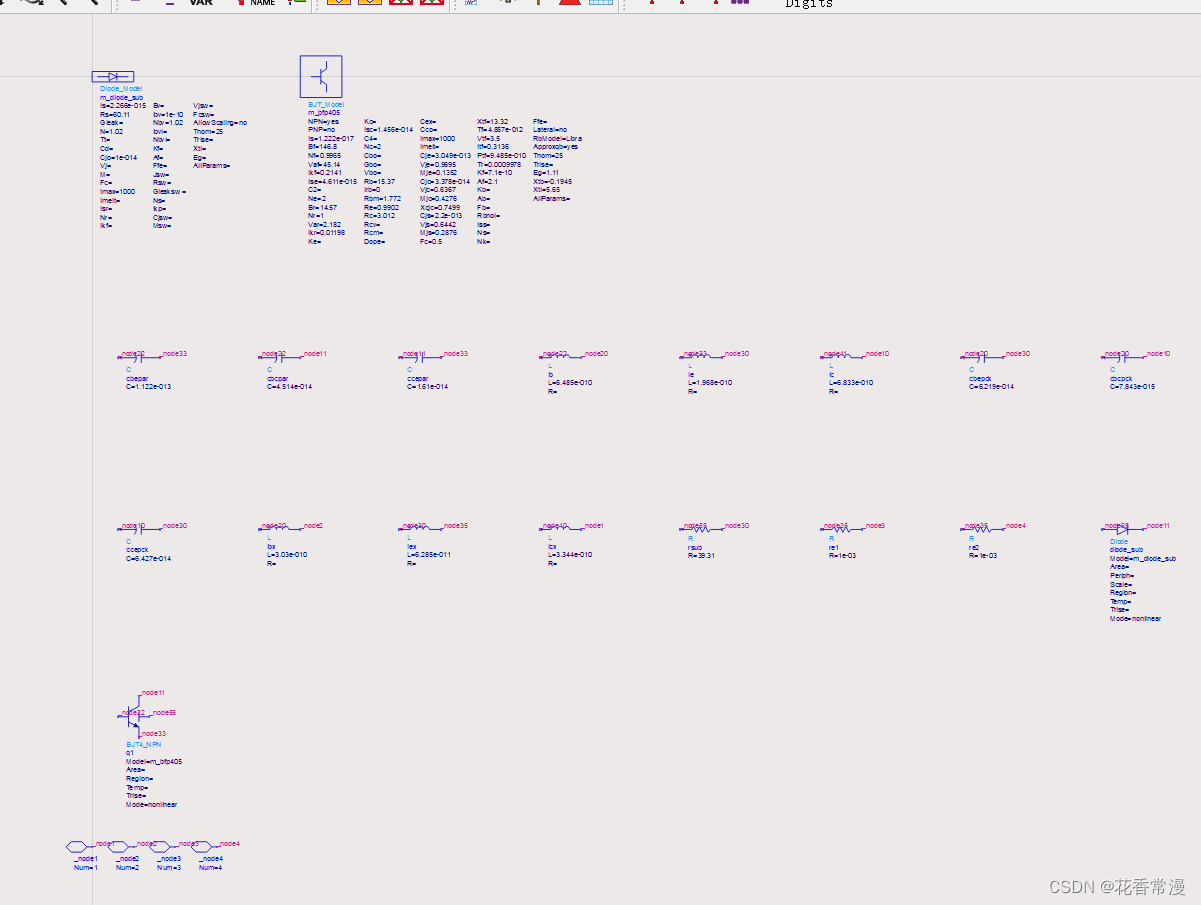
ADS中导入SPICE模型
这里写目录标题在官网中下载SPICE模型ADS中导入SPICE模型在官网中下载SPICE模型 英飞凌官网 ADS中导入SPICE模型 点击option,设置导入选项 然后点击ok 如果destination选择当前的workspace,那么导入完成之后如下: (推荐使用…...
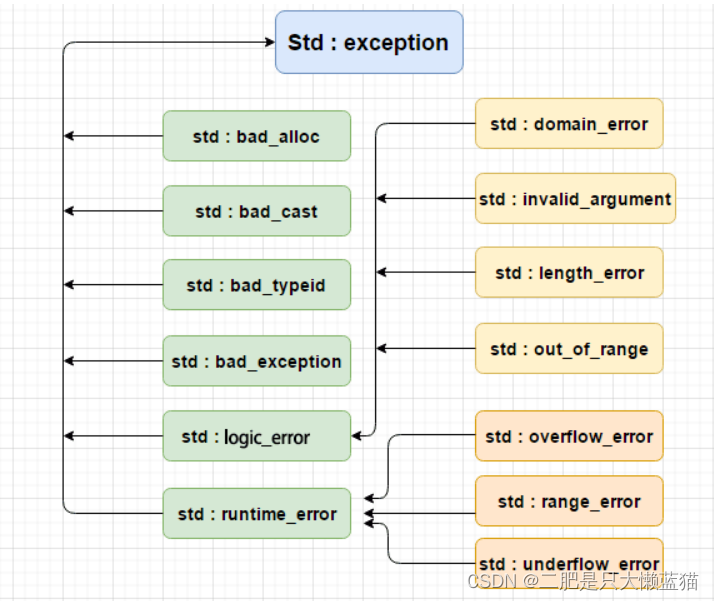
C++:异常
在学习异常之前,来简单总结一下传统的处理错误的方式: 1. 终止程序,如assert,缺陷:用户难以接受。如发生内存错误,除0错误时就会终止程序。 2. 返回错误码,缺陷:需要程序员自己去查找…...
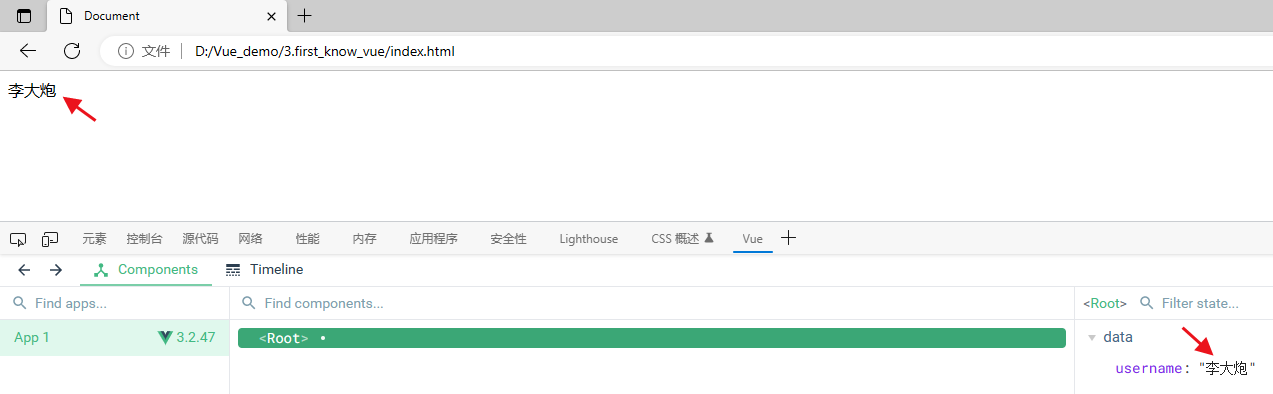
3.初识Vue
目录 1 vue 浏览器调试工具 1.1 安装 1.2 配置 2 数据驱动视图与双向数据绑定 3 简单使用 3.1 下载 3.2 将信息渲染到DOM上 4 使用vue浏览器调试工具 5 vue指令 1 vue 浏览器调试工具 chrome可能是我浏览器的原因,装上用不了,我们使…...

【C语言复习】程序的编译与链接
程序的编译与链接写在前面程序的编译与链接编译的过程程序编译环境程序执行过程编译链接的过程预处理预处理符号#define条件编译写在前面 程序的编译与链接是C语言中非常重要的一节。关键点在于详解C语言的程序编译和链接、宏的定义和与函数的区别、条件编译等知识。 程序的编…...

Golang sql 事务如何进行分层
在写代码过程中遇到了需要使用gorm执行sql事务的情况,研究了一下各位大佬的实现方案,结合了自身遇到的问题,特此记录。 代码架构介绍 . ├── apis ├── config ├── internal │ ├── constant │ ├── controller │ ├──…...

linux系统openssh升级
linux系统openssh升级 说明 整个过程不需要卸载原先的openssl包和openssh的rpm包。本文的环境都是系统自带的openssh,没有经历过手动编译安装方式。如果之前有手动编译安装过openssh,请参照本文自行测试是否能成功。 如果严格参照本文操作,保…...

力扣-求关注者的数量
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1729. 求关注者的数量二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.正确…...
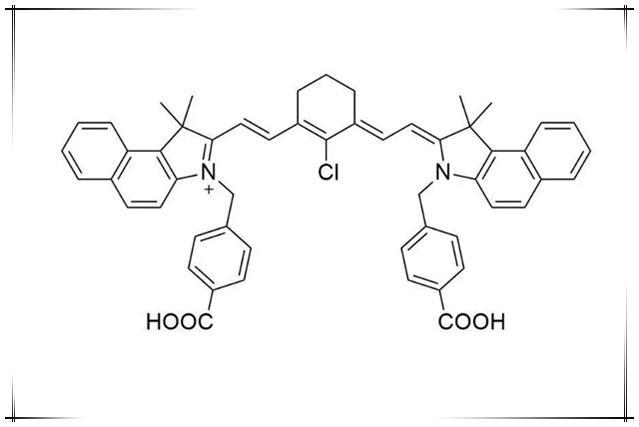
近红外荧光染料修饰氨基IR 825 NH2,IR 825-Amine,IR-825 NH2
IR 825 NH2,IR 825-NH2,IR825 Amine,IR825-Amine,新吲哚菁绿-氨基,荧光染料修饰氨基产品规格:1.CAS号:N/A2.包装规格:10mg,25mg,50mg,包装灵活&am…...
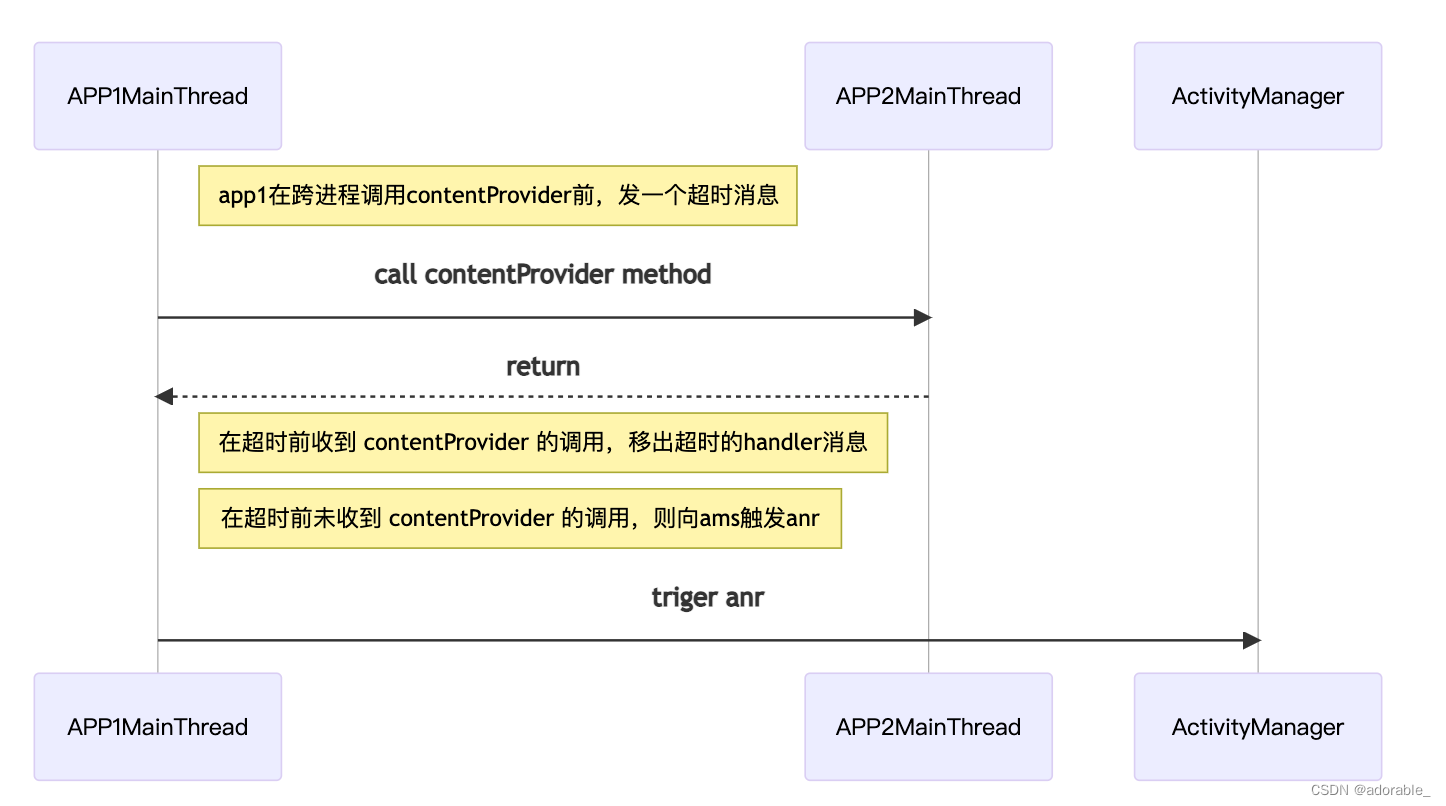
Android Crash和ANR监控
文章目录一、Crash1.1 概念1.2 类型二、ANR2.1 概念2.2 类型2.2.1 KeyDispatchTimeout(常见)2.2.2 BroadcastTimeout2.2.3 ServiceTimeout2.2.4 ContentProviderTimeout三、测试中如何关注3.1 Crash测试关注方法3.2 ANR测试关注方法四、如何记录与处理4.…...
的输出格式应该从 Markdown 转向 HTML吗?)
AI Agent(智能体)的输出格式应该从 Markdown 转向 HTML吗?
在近期(2026年5月)的技术圈和AI社区引发了非常热烈的讨论。提出这个观点的是 Anthropic(Claude背后的公司)负责 Claude Code 团队的工程师 Thariq Shihipar,他最近发表了一篇题为《使用 Claude Code:HTML 极…...

LeagueAkari:3分钟快速上手的英雄联盟终极本地自动化工具指南
LeagueAkari:3分钟快速上手的英雄联盟终极本地自动化工具指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾经在英雄联盟…...

3个关键场景解析:如何使用iperf3 Windows版精准诊断网络性能问题
3个关键场景解析:如何使用iperf3 Windows版精准诊断网络性能问题 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds 在当今数字化时代&…...

绝区零自动化助手:5分钟掌握全自动游戏任务管理
绝区零自动化助手:5分钟掌握全自动游戏任务管理 【免费下载链接】ZenlessZoneZero-OneDragon 绝区零 一条龙 | 全自动 | 自动闪避 | 自动每日 | 自动空洞 | 支持手柄 项目地址: https://gitcode.com/gh_mirrors/ze/ZenlessZoneZero-OneDragon 绝区零一条龙是…...

2026年小白适用Hermes Agent/OpenClaw Token Plan集成全攻略大全
2026年小白适用Hermes Agent/OpenClaw Token Plan集成全攻略大全。OpenClaw作为阿里云生态下新一代的开源AI自动化代理平台,曾用名Moltbot/Clawdbot,凭借“自然语言交互自动化任务执行大模型智能决策”的核心能力,正在重构个人与企业的工作效…...

从‘前后台’到‘多任务’:用UCOSIII官方例程理解RTOS内核如何接管你的单片机
从裸机到实时操作系统:UCOSIII内核如何重构单片机开发思维 第一次接触实时操作系统(RTOS)的嵌入式开发者,往往会被那些看似复杂的任务调度、优先级机制搞得一头雾水。我们习惯了在main函数里写一个无限循环,在中断服务例程(ISR)里处理紧急事件…...

3分钟掌握Linux桌面便签神器:Sticky让你的数字工作台效率翻倍!
3分钟掌握Linux桌面便签神器:Sticky让你的数字工作台效率翻倍! 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 还在为桌面杂乱无章的纸质便利贴烦恼吗?Sti…...

3分钟掌握B站缓存转换:开源m4s-converter工具全攻略
3分钟掌握B站缓存转换:开源m4s-converter工具全攻略 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站下架视频而烦恼吗&…...

终极指南:如何快速解决Windows应用程序运行库缺失问题
终极指南:如何快速解决Windows应用程序运行库缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的情况:下载了…...

5分钟掌握直播间数据抓取:Live Room Watcher终极指南
5分钟掌握直播间数据抓取:Live Room Watcher终极指南 【免费下载链接】live-room-watcher 📺 可抓取直播间 弹幕, 礼物, 点赞, 原始流地址等 项目地址: https://gitcode.com/gh_mirrors/li/live-room-watcher Live Room Watcher是一款基于Java开发…...