AI论文速读 | 2024[SIGIR]基于大语言模型的下一个兴趣点推荐
论文标题:Large Language Models for Next Point-of-Interest Recommendation
作者:Peibo Li ; Maarten de Rijke ; Hao Xue (薛昊); Shuang Ao ; Yang Song ; Flora D. Salim
机构:新南威尔士大学(UNSW),阿姆斯特丹大学(UVA)
论文链接:https://arxiv.org/abs/2404.17591
Cool Paper:https://papers.cool/arxiv/2404.17591
代码:https://github.com/neolifer/LLM4POI
TL, DR:本文通过利用预训练的大语言模型处理位置基社交网络数据,提出了一种新的方法来提高下一个兴趣点推荐的性能,同时通过轨迹提示和关键查询对相似性来缓解冷启动问题。
关键词:位置基社交网络(LBSN)、POI推荐、大语言模型(Large Language Models, LLMs)
Total 10 Pages(2 Methodology+3.5 Experiment)

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
摘要
下一个兴趣点 (POI) 推荐任务是根据用户的历史数据来预测用户的下一次 POI 访问。基于位置的社交网络(LBSN)数据通常用于下一个 POI 推荐任务,但也面临着挑战。一项经常被忽视的挑战是如何有效地利用 LBSN 数据中存在的丰富上下文信息。以前的方法受到数值性质的限制,无法解决这一挑战。本文提出了一个使用预训练大语言模型(LLM)来应对这一挑战的框架。该框架允许我们以原始格式保存异构 LBSN 数据,从而避免上下文信息的丢失。此外,由于包含常识知识,该框架能够理解上下文信息的内在含义。在实验中,在三个真实的 LBSN 数据集上测试框架。结果表明,所提出的框架在所有三个数据集中都优于最先进的模型。分析证明了所提出的框架在使用上下文信息以及缓解常见的冷启动和短轨迹问题方面的有效性。
Q: 这篇论文试图解决什么问题?

A: 这篇论文试图解决的问题是如何有效地利用位置基社交网络(Location-based Social Network, LBSN)数据中的丰富上下文信息来提高下一个兴趣点(Point-of-Interest, POI)推荐任务的性能。具体来说,论文提出了以下几个关键挑战:
- 上下文信息的提取:如何从原始数据中提取上下文信息,如时间、POI类别和地理坐标。
- 上下文信息与常识知识的连接:如何将上下文信息与常识知识相结合,以有效地促进下一个POI推荐。
传统的基于数值的方法在处理上下文信息时存在两个主要限制:
- 它们需要将异构的LBSN数据转换为数字,这可能导致上下文信息的固有含义丢失。
- 它们仅依赖于统计和人为设计来理解上下文信息,缺乏对上下文信息提供的语义概念的理解。
为了解决这些挑战,论文提出了一个框架,使用预训练的大语言模型(Large Language Models, LLMs)来处理LBSN数据。该框架允许在原始格式下保留异构的LBSN数据,从而避免上下文信息的丢失,并且能够通过包含常识知识来理解上下文信息的内在含义。
论文的主要贡献包括:
- 提出了一个使用预训练大语言模型的框架,用于下一个POI推荐任务,这是首次在标准尺寸的数据集上微调语言模型以利用常识知识。
- 提出了基于提示(prompt-based)的轨迹相似性概念,用于结合历史轨迹和不同用户的轨迹信息,以缓解冷启动问题,并提高对各种长度轨迹的预测准确性。
- 在三个真实世界的LBSN数据集上进行了广泛的实验评估,证明了所提出的下一个POI推荐模型在所有三个数据集上都显著优于现有的最先进模型。
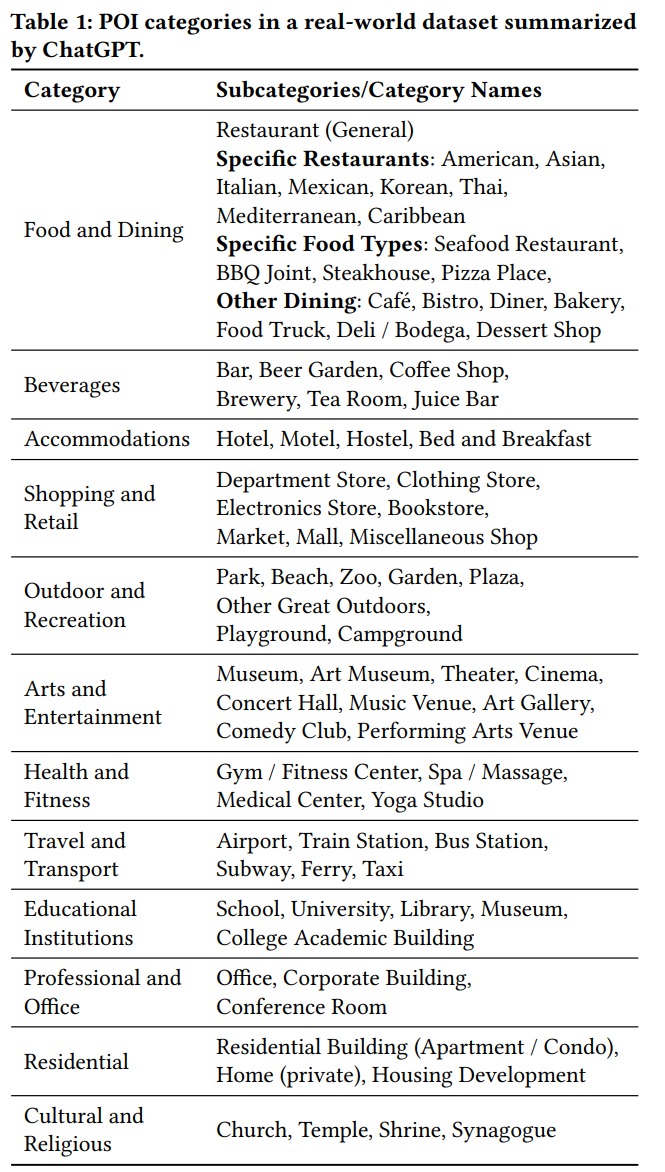
Q: 有哪些相关研究?
A: 论文中提到的相关研究主要分为以下几个领域:
- 下一个POI推荐(Next POI Recommendation):
- 早期工作通常将下一个POI推荐视为序列推荐任务,使用了FPMC、Markov链和softmax函数等方法。
- 随着深度学习的发展,开始应用基于RNN的模型,如HST-LSTM、LSTPM、PLSPL、STAN和CFPRec等,这些模型能够捕捉复杂的序列模式。
- 基于图的模型(Graph-based models):
- 用于解决序列模型的局限性,如STP-UDGAT、HMT-GRN、DRGN、GETNEXT和STHGCN等,这些模型通过全局视角和图注意力网络来捕捉用户和POI之间的复杂关系。
- 大语言模型(Large Language Models, LLMs)在时间序列数据(Time-series Data)中的应用:
- SHIFT和AuxMobLCast等研究将人类移动性预测视为语言翻译问题,使用序列到序列的语言模型。
- LLM4TS采用了两阶段微调方法,首先对LLM进行监督微调以适应时间序列数据,然后进行特定任务的微调。
- 大语言模型在推荐系统(Recommender Systems)中的应用:
- 近期的研究工作采用了LLMs,如通过设计多个提示模板来从不同角度处理新闻数据,并使用BERT进行提示学习。
- 其他方法包括直接微调LLMs进行提示完成,或者将LLMs的嵌入与现有序列模型结合,以增强模型的性能。
这些研究为本文提出的使用预训练的大语言模型来处理下一个POI推荐任务提供了理论和技术基础。论文中提到的相关工作还包括了如何通过提示工程(prompt engineering)和微调技术来利用LLMs,以及如何将这些技术应用于推荐系统和时间序列预测任务。
Q: 论文如何解决这个问题?
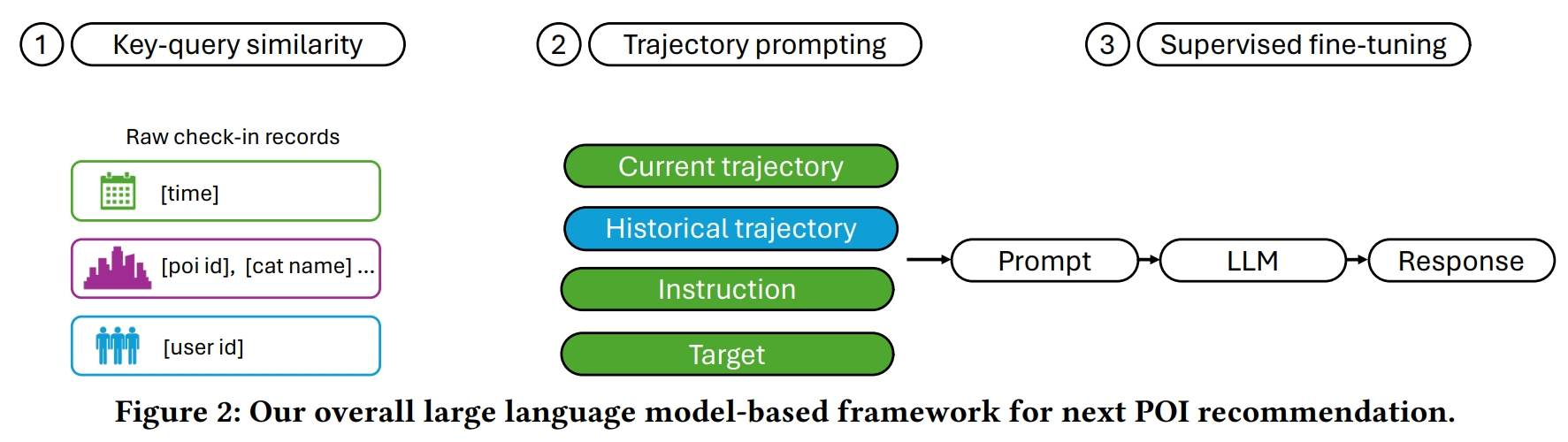

红色表示当前轨迹块。紫色表示历史轨迹块。橙色表示指令块。蓝色表示目标块。
A: 论文提出了一个基于大语言模型(LLMs)的框架来解决下一个兴趣点(POI)推荐任务中的挑战,具体方法如下:
- 轨迹提示(Trajectory Prompting):
- 将用户的检查点数据序列转换为自然语言问答格式,以便LLMs能够遵循提示中的指令并生成POI推荐。
- 通过设计不同的句子块来构建提示,包括当前轨迹块、历史轨迹块、指令块和目标块。
- 关键查询对相似性(Key-Query Pair Similarity):
- 提出一种计算框架,用于计算自然语言格式中轨迹的相似性,以便从历史轨迹和其他用户的轨迹中捕获用户行为模式。
- 通过计算关键提示(当前轨迹,不包括最后一个条目)和所有查询提示(代表早于关键提示开始时间的轨迹)之间的相似性,选择与关键提示相似性高的查询提示。
- 监督微调(Supervised Fine-tuning):
- 采用参数高效的微调技术,包括低秩适应(LoRA)、量化技术和FlashAttention,以减少训练成本和提高模型的效率。
- 实验评估:
- 在三个真实世界的LBSN数据集上进行广泛的实验评估,证明了所提出的模型在所有数据集上都显著优于现有的最先进模型。
- 分析:
- 对模型进行了深入分析,包括用户冷启动分析、轨迹长度分析、历史数据变体数量分析、未见数据泛化分析和上下文信息分析,以展示模型在处理冷启动问题、不同长度轨迹、利用历史数据和上下文信息方面的有效性。
通过这些方法,论文提出的框架能够有效地利用LBSN数据中的上下文信息,并缓解冷启动和短轨迹问题,同时提高下一个POI推荐任务的性能。
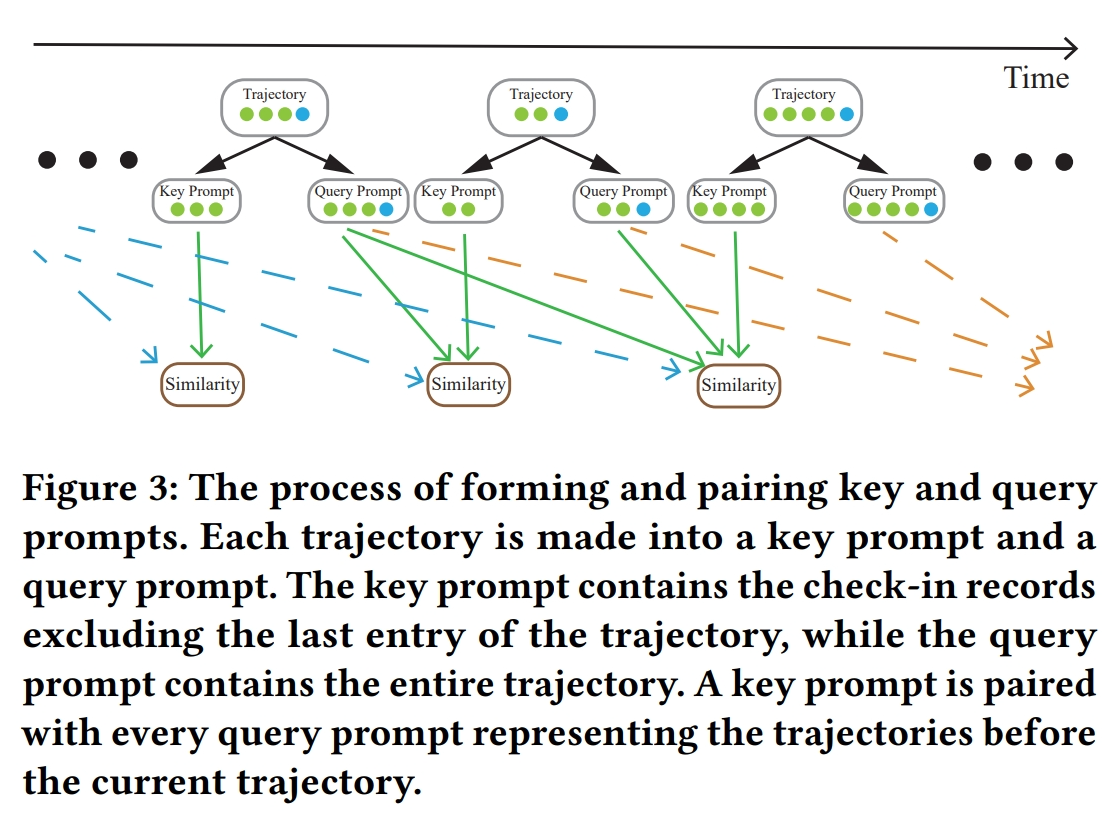
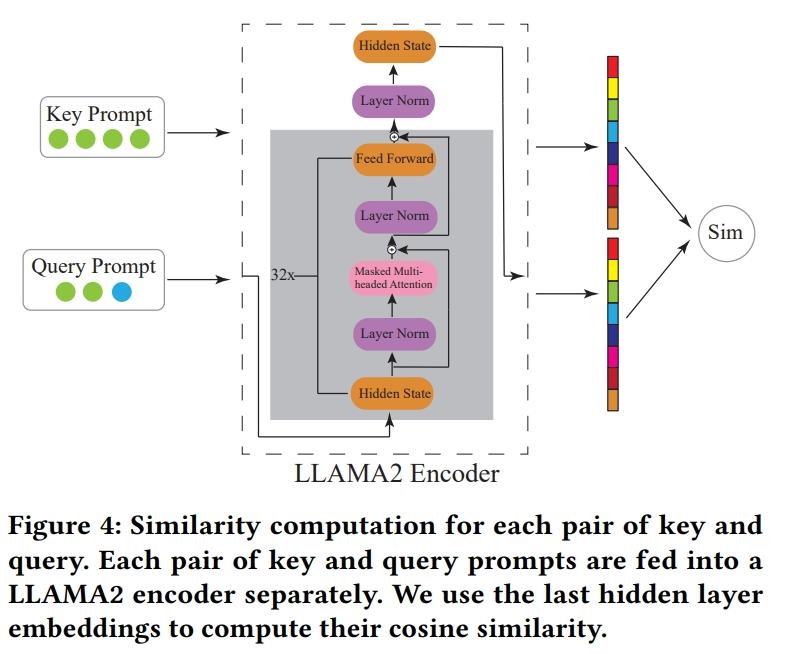
Q: 论文做了哪些实验?



A: 论文中进行了多项实验来评估提出的基于大语言模型(LLMs)的下一个兴趣点(POI)推荐框架的性能。具体的实验包括:
- 数据集选择:
- 实验使用了三个公开的数据集:Foursquare-NYC、Foursquare-TKY和Gowala-CA。
- 基线模型比较:
- 与多个现有的推荐模型进行比较,包括FPMC、LSTM、PRME、STGCN、PLSPL、STAN、GETNext和STHGCN。
- 模型变体评估:
- 评估了三种不同的模型变体,包括仅使用当前轨迹块的LLAMA2-7b、加上历史轨迹块但不考虑关键查询相似性的LLAMA2-7b*,以及结合历史轨迹块和关键查询相似性的LLAMA2-7b**。
- 评估指标:
- 使用Accuracy@1作为主要的评估指标,即预测的准确性在推荐列表的第一位。
- 实验设置:
- 描述了实验的具体设置,包括数据预处理、训练集、验证集和测试集的划分,以及模型训练的超参数设置。
- 主要结果:
- 展示了在三个数据集上的实验结果,显示提出的模型在所有数据集上都显著优于基线模型。
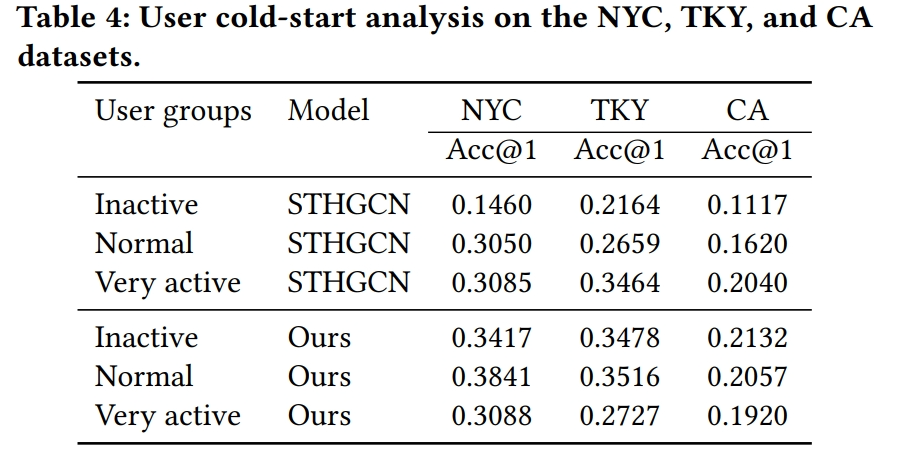
- 用户冷启动分析:
- 分析了模型对冷启动问题的处理能力,通过将用户分为活跃、正常和非活跃三组,比较了模型在不同用户群体上的性能。
- 轨迹长度分析:
- 探讨了轨迹长度对模型性能的影响,将轨迹分为长、中、短三类,并分析了模型在不同长度轨迹上的表现。
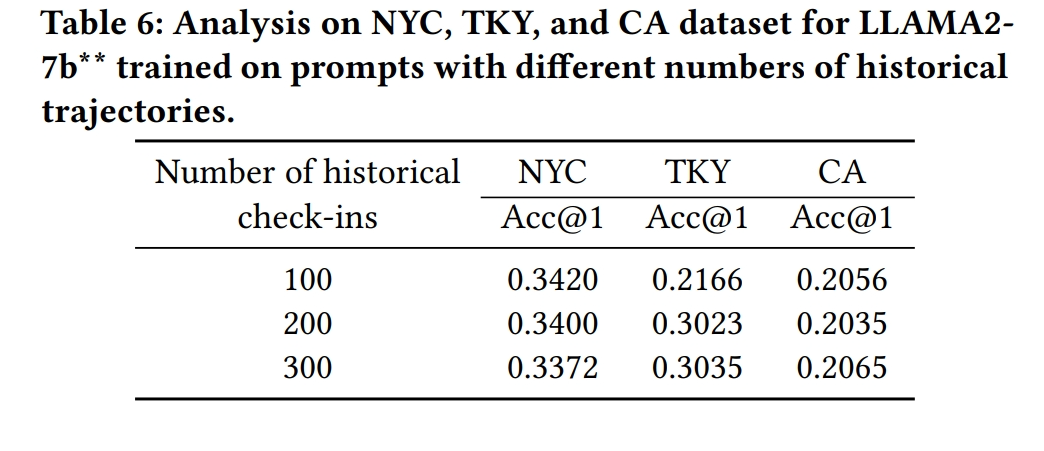
- 历史数据变体数量分析:
- 研究了在提示中使用不同数量的历史检查记录对模型性能的影响。
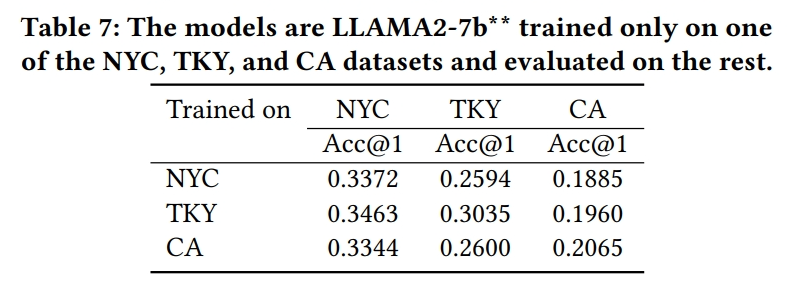
- 未见数据泛化分析:
- 评估了模型在未见过的数据集上的泛化能力,即在某个数据集上训练并在其他数据集上评估。
- 上下文信息分析:
- 分析了上下文信息在模型中的作用,通过在提示中移除POI类别名称的上下文信息来评估其对模型性能的影响。
- 不同组件效果分析:
- 通过去除历史轨迹块、关键查询相似性或上下文信息,来评估这些组件对模型性能的贡献。
这些实验全面评估了提出的框架在不同方面的表现,并与现有的推荐模型进行了深入的比较。通过这些实验,论文证明了其方法在处理冷启动问题、不同长度的轨迹、利用上下文信息以及泛化到未见数据方面的优势。




Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
- 问题定义:论文旨在解决如何利用位置基社交网络(LBSN)数据中的丰富上下文信息来提高下一个兴趣点(POI)推荐任务的性能。
- 挑战:现有的POI推荐方法在处理上下文信息时存在局限性,包括信息的数值化转换导致语义丢失,以及缺乏对上下文信息语义概念的理解。
- 方法:提出了一个基于预训练大语言模型(LLMs)的框架,通过轨迹提示(Trajectory Prompting)将POI推荐任务转化为问答任务,同时利用关键查询对相似性(Key-Query Pair Similarity)来缓解冷启动问题。
- 实验:在三个真实世界的LBSN数据集上进行实验,与多个基线模型相比,提出的框架在所有数据集上均显著提高了推荐性能。
- 分析:通过用户冷启动分析、轨迹长度分析、历史数据变体数量分析、未见数据泛化分析和上下文信息分析,展示了模型在处理不同用户行为和数据特性方面的有效性。
- 贡献:主要贡献包括提出了一个新的框架,利用预训练的LLMs来推荐下一个POI,以及一种新的基于提示的轨迹相似性方法。
- 未来工作:论文提出了未来工作的方向,包括效率优化、提示设计改进、链式思考推理、多步未来偏好推断、上下文信息的深入利用等。
型在处理不同用户行为和数据特性方面的有效性。 - 贡献:主要贡献包括提出了一个新的框架,利用预训练的LLMs来推荐下一个POI,以及一种新的基于提示的轨迹相似性方法。
- 未来工作:论文提出了未来工作的方向,包括效率优化、提示设计改进、链式思考推理、多步未来偏好推断、上下文信息的深入利用等。
- 结论:论文证明了利用LLMs进行下一个POI推荐任务的潜力,并展示了模型在未见数据上的泛化能力,同时指出了当前方法的局限性和未来改进的可能方向。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
相关文章:
AI论文速读 | 2024[SIGIR]基于大语言模型的下一个兴趣点推荐
论文标题:Large Language Models for Next Point-of-Interest Recommendation 作者:Peibo Li ; Maarten de Rijke ; Hao Xue (薛昊); Shuang Ao ; Yang Song ; Flora D. Salim 机构:新南威尔士大学(UNSW),…...

Rust 实战丨通过实现 json! 掌握声明宏
在 Rust 编程语言中,宏是一种强大的工具,可以用于在编译时生成代码。json! 是一个在 Rust 中广泛使用的宏,它允许我们在 Rust 代码中方便地创建 JSON 数据。 声明宏(declarative macros)是 Rust 中的一种宏࿰…...

vue+elementUI实现在表格中添加输入框并校验的功能
背景: vue2elmui 需求: 需要在一个table中添加若干个输入框,并且在提交时需要添加校验 思路: 当需要校验的时候可以考虑添加form表单来触发校验,因此需要在table外面套一层form表单,表单的属性就是ref…...

为国产加油:“缺芯少屏”暂缓,另一领域,也要加把劲
说起咱中国之前的“缺芯少屏”,真的是让人挺闹心的。 不过呢,为了改变这个状况,咱们的工程师们可是费了不少劲儿,辛辛苦苦努力了数十年。现在好了,咱们也迎来了柔性屏的时代。 柔性屏 说起来,在触摸屏或者…...

【Qnx】Qnx coredump解析
Qnx coredump解析 coredump文件 Qnx运行的程序崩溃时,会生成coredump文件。 默认情况下这些文件默认会保存在/var/log/*.core 文件中。 解析coredump文件,可以帮忙加快分析程序崩溃的原因,比如了解崩溃的堆栈。 通常可以使用gdb和coreinfo…...

超级签名源码/超级签/ios分发/签名端本地linux服务器完成签名
该系统完全在linux下运行,不存在使用第三方收费工具,市面上很多系统都是使用的是第三方收费系统,例如:某心签名工具,某测侠等,不开源而且需要每年交费,这种系统只是在这些工具的基础上套了一层壳…...
RocketMQ在Centos7系统上单机部署
最近因为一些信创问题,要将RabbitMQ替换为RocketMQ,因此在此分享一些RocketMQ在Centos7系统上单机部署相关过程。 优缺点 RocketMQ的优点: 性能优越:RocketMQ在处理大量消息时,性能优于RabbitMQ。当面临每秒数万到数…...
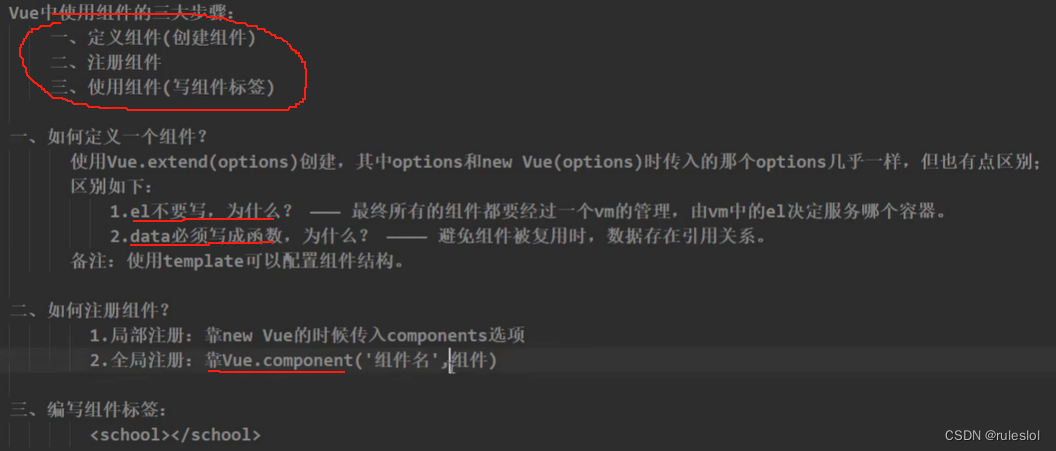
Vue37-非单文件组件
一、组件的两种编写形式: 非单文件组件;单文件组件。 二、创建一个组件 2-1、组件中的el 组件中不写el,不说为谁服务。 2-2、组件中的data 因为对象形式,多处复用的话,有引用关系,改一处,另一…...

CSS实现经典打字小游戏《生死时速》
🌻 前言 CSS 中有这样一个模块:Motion Path 运动模块,它可以使元素按照自定义的路径进行移动。本文将为你讲解这个模块属性的使用,并且利用它实现我小时候电脑课经常玩的一个打字游戏:金山打字的《生死时速》。 &…...

推箱子-小游戏
学习目标: 巩固Java基础,数据类型、二维数组、条件语句等; 效果展示:...
AI数字人的开源解决方案
目前,国内外已经涌现出一些优秀的数字人开源解决方案,这些解决方案为开发者提供了构建数字人应用的工具和基础设施。以下是一些比较知名的数字人开源解决方案。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1…...

java写一个验证码
生成验证码 内容:可以是小写字母,也可以是大写字母,还可以是数字 规则 长度为5 内容中是四位字母,1位数字。 其中数字只有1位,但是可以出现在任意的位置。 package User;import java.util.ArrayList; import jav…...

【星海随笔】ELK优化
ELS 再遇到大的日志文件的时候不会自动进行清理的,我们可以通过 logrotate 转储工具进行操作。 该命令是基于 Cron 实现,由系统执行,当然也可以手动进行执行例如 logrotate -f configfile# more /etc/logrotate.confweekly // 默认每一周执行一次rotate轮转工作 r…...

SQL Auto Increment
SQL Auto Increment 在关系型数据库中,自动增量(Auto Increment)是一个常见且实用的特性。它允许数据库自动为表中插入的新行分配唯一的标识符,通常用于主键字段。本文将深入探讨SQL中的自动增量功能,包括其工作原理、…...

网络安全练气篇——PHP编程语言基础
目录 PHP基础 一、PHP简介与环境搭建 什么是PHP? PHP环境安装 代码编辑选择 二、基本语法 PHP基本语法操作 PHP变量与输出 啥是常量? PHP注释 PHP单引号双引号声明 三、PHP表单 PHP表单 四、登录界面搭建与讲解 构建登陆页面 登陆页面端 服务器端…...
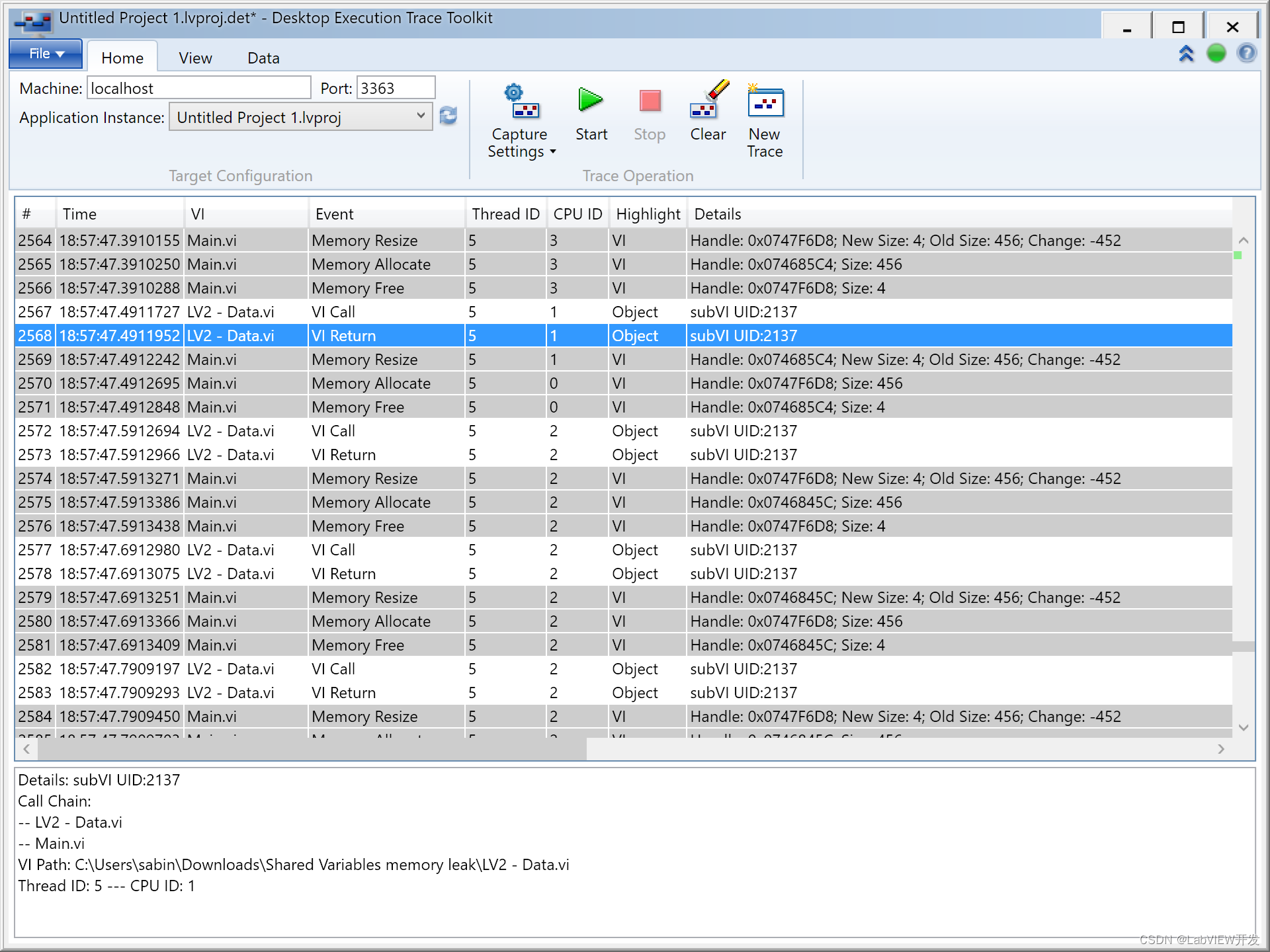
LabVIEW程序内存泄漏分析与解决方案
维护他人编写的LabVIEW程序时,若发现程序运行时间越长,占用内存越大直至崩溃,通常是内存泄漏导致的。本文从多角度分析内存泄漏的可能原因,包括数组和字符串处理、未释放的资源、循环中的对象创建等,并提供具体的解决方…...

JVM垃圾回收器介绍
Serial GC: 算法: 使用的是标记-清除算法。特点: 串行执行,适用于单CPU环境或较小的堆内存配置。在新生代和老年代的回收中都是单线程执行,因此在进行垃圾回收时会暂停所有应用线程(Stop-The-World)。 Parallel GC (也称为吞吐量优…...

subprocess隐藏cmd窗口
process subprocess.Popen(command, shellTrue, stdoutsubprocess.PIPE, stderrsubprocess.PIPE,creationflagssubprocess.CREATE_NO_WINDOW) 添加参数即可不显示cmd运行窗口 creationflagssubprocess.CREATE_NO_WINDOW...

编程前端看什么书比较好:深入解析与推荐
编程前端看什么书比较好:深入解析与推荐 在编程前端的学习道路上,书籍无疑是我们最宝贵的财富。一本好的书籍,不仅可以提供系统的知识体系,还能引导我们深入探索技术的奥秘。然而,面对市面上琳琅满目的前端书籍&#…...
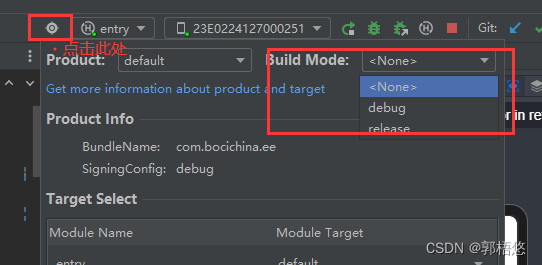
HarmonyOS(36) DevEco Studio 配置debug和release
在android开发中可以在build.gradle来配置realease和debug,在HarmonyOS中可以通过build-profile.json5文件中通过buildModeSet配置: 在DevEco Studio 中可以通过下面来选择运行debug还是release: 我们可以通过BuildProfile.ets里面的静态变量获取当前…...

SSM+Vue大学生兼职网站源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

亚洲美女-造相Z-Turbo算力适配实践:24G显存下支持batch_size=2高清图并行生成
亚洲美女-造相Z-Turbo算力适配实践:24G显存下支持batch_size2高清图并行生成 1. 快速了解亚洲美女-造相Z-Turbo 亚洲美女-造相Z-Turbo是一个专门针对亚洲女性形象生成优化的文生图模型,基于Z-Image-Turbo的LoRA版本进行深度定制。这个模型最大的特点是…...

别再被空白页坑了!用html2canvas + print-js打印Vue/React组件,保姆级避坑指南
彻底解决前端组件打印难题:html2canvas与print-js深度整合实践 在管理后台、数据报表等企业级应用中,精确打印特定组件是刚需,但现代前端框架的组件化特性让这个"简单需求"变得异常棘手。当你的Vue/React组件在屏幕上完美呈现&…...

FreeSWITCH 1.10.10 图形化部署实战 - 麒麟V10 SP3 X86/ARM双架构服务器安装与配置指南
1. FreeSWITCH与麒麟V10 SP3的完美组合 FreeSWITCH作为一款开源的软交换平台,在企业通信、呼叫中心、即时通讯等领域有着广泛应用。而麒麟V10 SP3作为国产操作系统的代表,在信创领域扮演着重要角色。将这两者结合起来,既能满足国产化需求&am…...

OpCore-Simplify:智能配置引擎如何破解开源系统硬件兼容性难题
OpCore-Simplify:智能配置引擎如何破解开源系统硬件兼容性难题 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 一、问题挑战:开…...

深入RK3588 NPU架构:从NVDLA远亲到CNN加速器的设计取舍与性能真相
RK3588 NPU架构深度解构:CNN加速器的设计哲学与性能边界 当一块指甲盖大小的芯片宣称能提供6 TOPS的AI算力时,我们不禁要问:这数字背后隐藏着怎样的工程智慧与妥协?RK3588的NPU模块正引发这样的思考——它既非纯粹的学术创新&…...

告别兼容性烦恼,让老旧应用在现代浏览器中“无缝”运行
在数字化转型的浪潮中,企业的技术架构往往承载着历史的痕迹。当我们享受着现代浏览器带来的极速体验与丰富扩展时,一个不容忽视的挑战正悄然影响着员工的工作效率与IT运维的平静——那就是“传统浏览器支持”问题。这并非一个遥不可及的技术概念…...

在ALV当中上传的excel形式的layout,没法删除怎么办?
明明点了上边的删除键(-)也保存了,下次进入还是存在。OAOR,上传的模板都在里面,点击删除即可...

如何高效保存B站视频?全功能跨平台工具BiliTools使用指南
如何高效保存B站视频?全功能跨平台工具BiliTools使用指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

4个步骤掌握Faze4机械臂开发:从硬件组装到智能控制的完整实践指南
4个步骤掌握Faze4机械臂开发:从硬件组装到智能控制的完整实践指南 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm Faze4开源六轴机械臂项目…...