C++STL剖析(四)—— stack和queue的概念和使用
文章目录
- 1. stack的介绍
- 2. stack的构造
- 3. stack的使用
- 🍑 push
- 🍑 top
- 🍑 pop
- 🍑 empty
- 🍑 size
- 🍑 swap
- 🍑 emplace
- 4. queue的介绍
- 5. queue的构造
- 6. queue的使用
- 🍑 push
- 🍑 size
- 🍑 front
- 🍑 back
- 🍑 pop
- 🍑 empty
- 🍑 swap
- 🍑 emplace
- 7. 容器适配器
- 🍑 什么是适配器
- 🍑 stack和queue的底层结构
- 🍑 deque的原理介绍
- 🍑 deque的缺陷
- 🍑 选择deque的原因
- 8. 模拟实现「stack」和「queue」
- 🍑 stack的模拟实现
- 🍑 queue的模拟实现
- 9. 总结
1. stack的介绍
「stack」是一种 容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
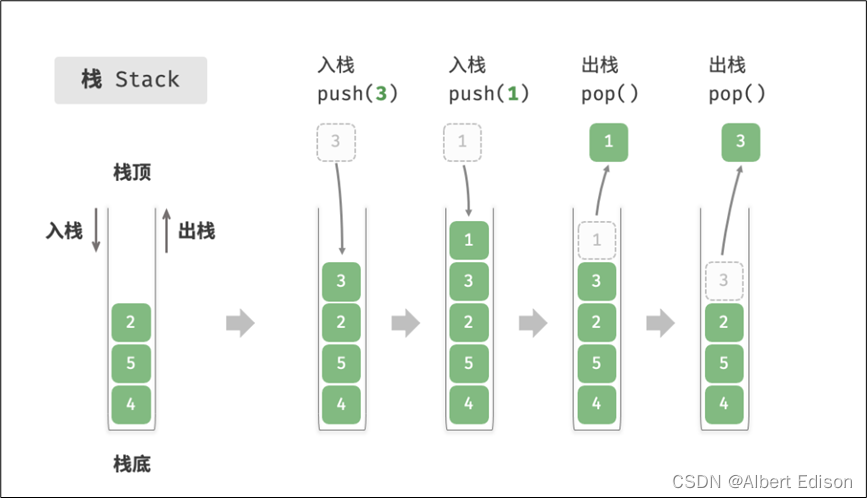
可以看到「stack」是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。

也就是说, 「stack」的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
empty:判空操作back:获取尾部元素操作push_back:尾部插入元素操作pop_back:尾部删除元素操作
标准容器 vector、deque、list 均符合上面这些需求,默认情况下,如果没有为「stack」指定特定的底层容器,默认情况下使用 deque。
2. stack的构造
它的构造方式如下:

(1)使用默认的适配器构造一个空栈
stack<int> st1;
(2)使用其他的容器适配器构造一个空栈
stack<int, vector<int>> st2;
stack<int, list<int>> st3;
3. stack的使用
相对于前面学习的容器,「Stack」的接口更简单也更少,基本的使用函数如下。
🍑 push
在堆栈顶部插入一个新元素,位于其当前顶部元素之上。

代码示例
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);
}
🍑 top
返回堆栈顶部元素的引用。

代码示例
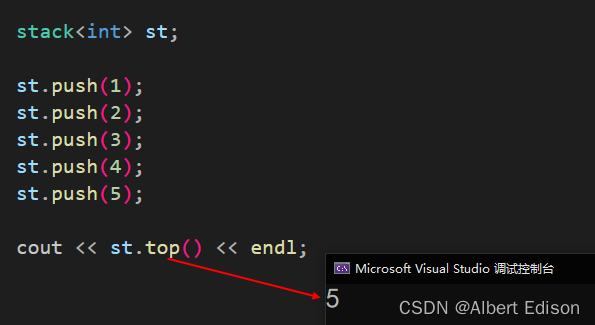
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);cout << st.top() << endl;
}
运行结果
🍑 pop
删除堆栈顶部的元素,有效地将其大小减小 1。

代码示例
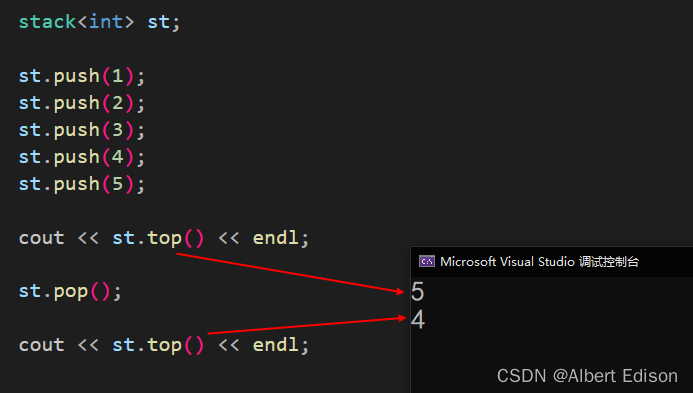
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);cout << st.top() << endl;st.pop();cout << st.top() << endl;
}
可以看到,最开始栈顶元素是 5,删除以后,就变成了 4
🍑 empty
返回堆栈是否为空,即它的大小是否为 0。

因为栈是不支持遍历的,所以这个接口可以用来实现栈的遍历。
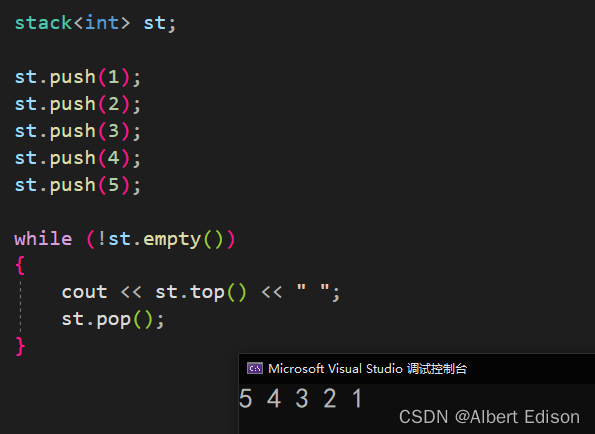
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);while (!st.empty()){cout << st.top() << " ";st.pop();}}
运行结果
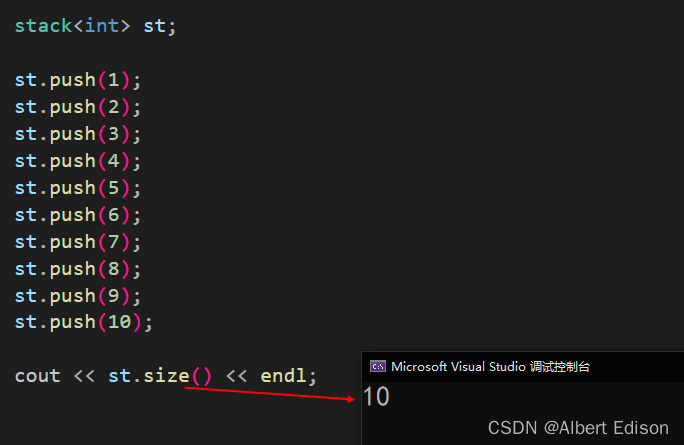
🍑 size
返回栈中元素的数量。

代码示例
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);st.push(6);st.push(7);st.push(8);st.push(9);st.push(10);cout << st.size() << endl;
}
运行结果
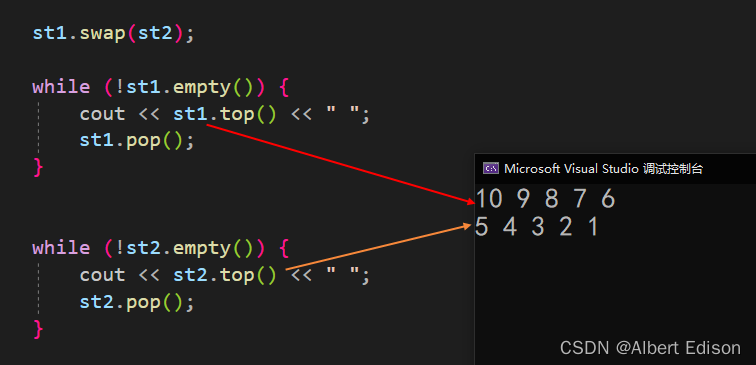
🍑 swap
将容器适配器(*this)的内容与 x 的内容交换。
其实就是交换两个栈的元素数据。

代码示例
void test_stack()
{stack<int> st1;st1.push(1);st1.push(2);st1.push(3);st1.push(4);st1.push(5);stack<int> st2;st2.push(6);st2.push(7);st2.push(8);st2.push(9);st2.push(10);st1.swap(st2);while (!st1.empty()) {cout << st1.top() << " ";st1.pop();}while (!st2.empty()) {cout << st2.top() << " ";st2.pop();}
}
运行结果
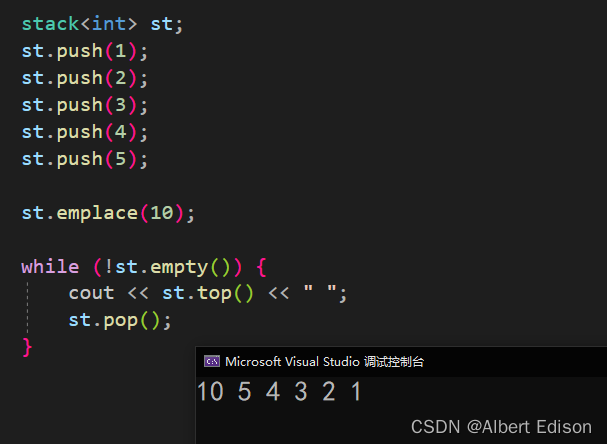
🍑 emplace
在栈顶部添加一个新元素,位于其当前顶部元素之上。
在适当的位置构造这个新元素,并将 args 作为其构造函数的参数传递。

代码示例
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);st.emplace(10);while (!st.empty()) {cout << st.top() << " ";st.pop();}
}
可以看到这个函数确实没啥用处…
4. queue的介绍
「队列 Queue」是一种容器适配器,专门用于在 FIFO 上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
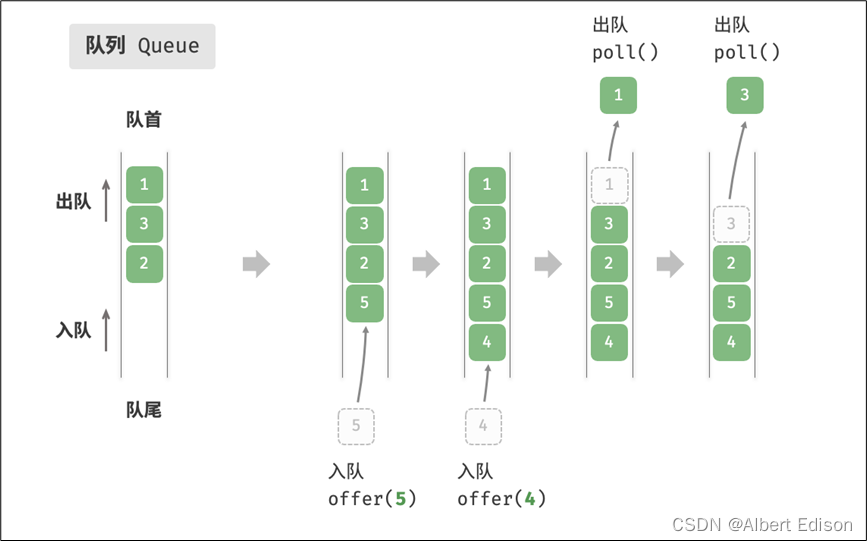
可以看到「queue」也是作为容器适配器实现的,容器适配器即将特定容器类封装作为其底层容器类,「queue」提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。

底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
empty:检测队列是否为空size:返回队列中有效元素的个数front:返回队头元素的引用back:返回队尾元素的引用push_back:在队列尾部入队列pop_front:在队列头部出队列
标准容器类 deque 和 list 满足了这些要求。默认情况下,如果没有为 queue 实例化指定容器类,则使用标准容器 deque。
5. queue的构造
它的构造方式如下:

(1)使用默认的适配器构造一个空栈
queue<int> q1;
(2)使用其他的容器适配器构造一个空栈
queue<int, vector<int>> q2;
queue<int, list<int>> q2;
6. queue的使用
相对于前面学习的容器,「queue」的接口更简单也更少,基本的使用函数如下。
🍑 push
在队列的末尾插入一个新元素,位于当前最后一个元素之后。

代码示例
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);
}
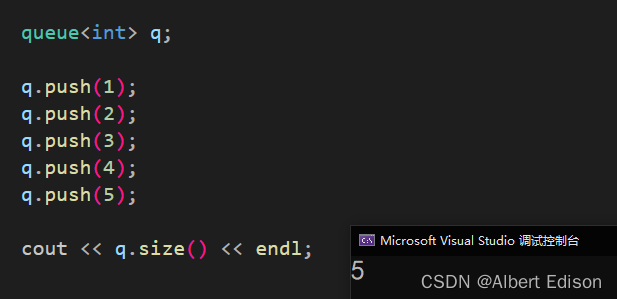
🍑 size
返回队列中元素的数量。

代码示例
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);cout << q.size() << endl;
}
运行结果
🍑 front
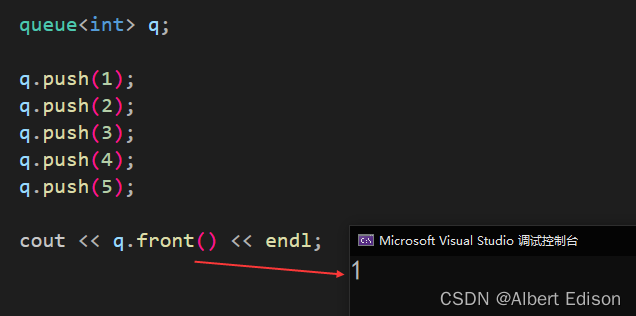
返回对队列中下一个元素的引用。
也就是获取队头的元素。

代码示例
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);cout << q.front() << endl;
}
运行结果
🍑 back
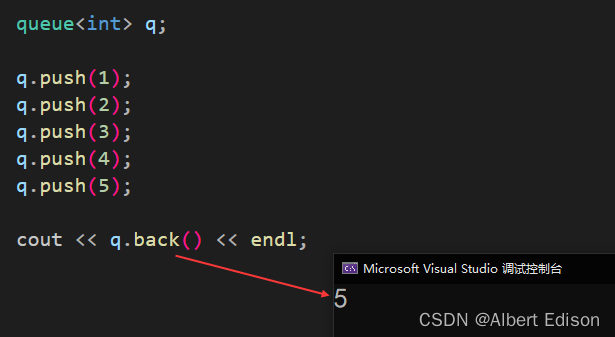
返回对队列中最后一个元素的引用。
也就是获取队尾元素。

代码示例
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);cout << q.back() << endl;
}
运行结果
🍑 pop
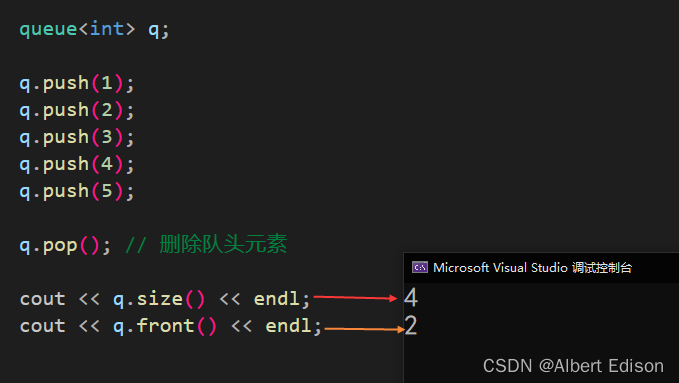
删除队列中的下一个元素,有效地将其大小减少 1。
也就是删除队头元素

代码示例
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);q.pop(); // 删除队头元素cout << q.size() << endl;cout << q.front() << endl;
}
运行结果
🍑 empty
返回队列是否为空,即队列大小是否为 0。

因为队列是先进先出,不支持遍历的,所以这个接口可以用来实现队列的遍历。
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);q.push(6);while (!q.empty()) {cout << q.front() << " ";q.pop();}}
运行结果
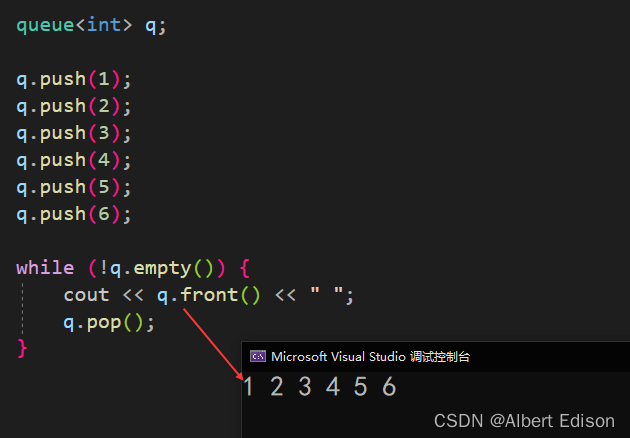
🍑 swap
将容器适配器(*this)的内容与 x 的内容交换。
其实就是交换两个队列中的元素数据。

代码示例
void test_queue()
{queue<int> q1;q1.push(1);q1.push(2);q1.push(3);q1.push(4);q1.push(5);q1.push(6);queue<int> q2;q2.push(8);q2.push(9);q2.push(10);q1.swap(q2);while (!q1.empty()) {cout << q1.front() << " ";q1.pop();}while (!q2.empty()) {cout << q2.front() << " ";q2.pop();}
}
运行结果
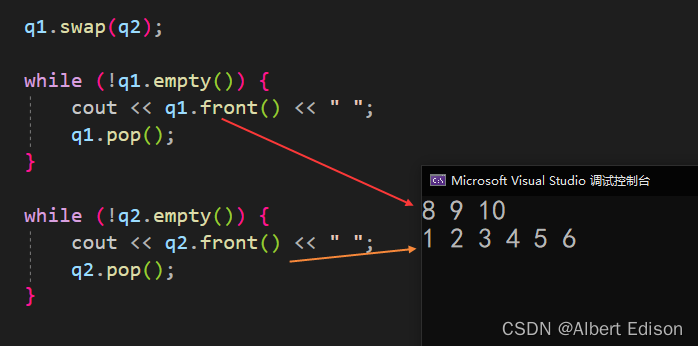
🍑 emplace
在队列的末尾添加一个新元素,位于当前最后一个元素之后。
在适当的位置构造这个新元素,并将 args 作为其构造函数的参数传递。

代码示例
void test_queue()
{queue<int> q1;q1.push(1);q1.push(2);q1.push(3);q1.push(4);q1.push(5);q1.push(6);while (!q1.empty()) {cout << q1.front() << " ";q1.pop();}q1.emplace(100);while (!q1.empty()) {cout << q1.front() << " ";q1.pop();}
}
这个接口和 stack 一样,没太大用处…
7. 容器适配器
🍑 什么是适配器
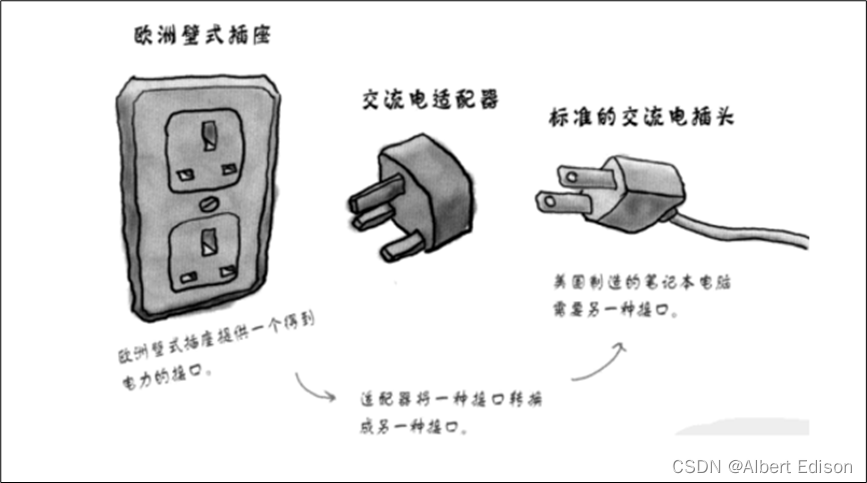
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
🍑 stack和queue的底层结构
虽然「stack」和「queue」中也可以存放元素,但在 STL 中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为「stack」和「queue」只是对其他容器的接口进行了包装,STL 中「queue」和「queue」默认使用「deque」比如:
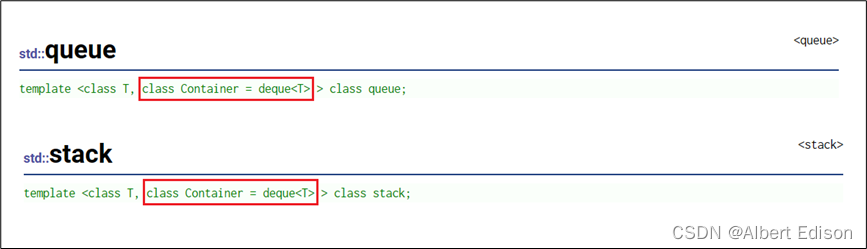
注意:容器支持迭代器,但是容器适配器不支持迭代器,因为栈和队列这种数据结构不能随便去遍历,不然会导致性质不易维护。
🍑 deque的原理介绍
「双端队列 deque」:是一种双开口的 “连续” 空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1)O(1)O(1),与「vector」比较,头插效率高,不需要搬移元素;与「list」比较,空间利用率比较高。
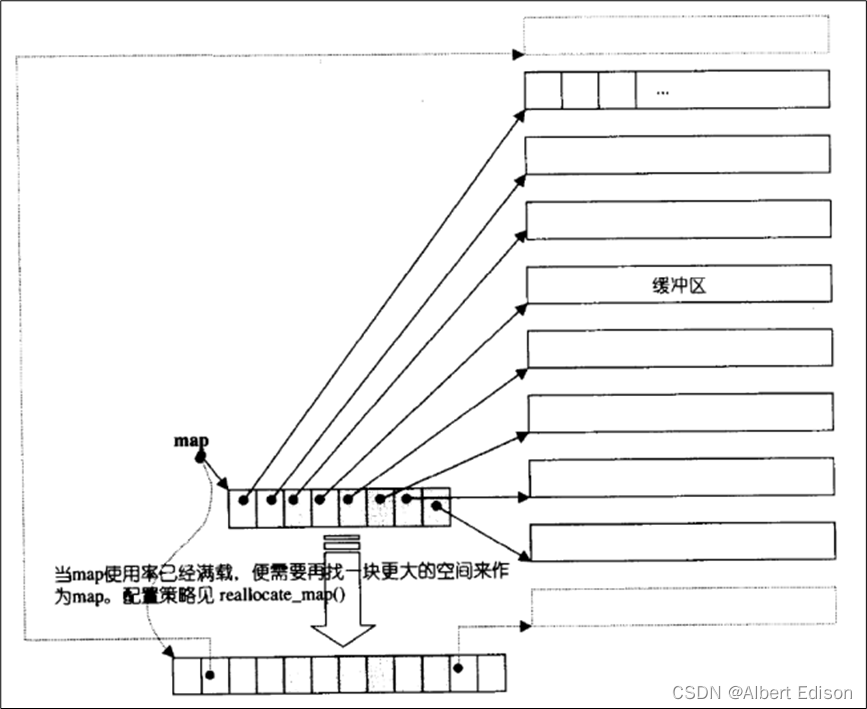
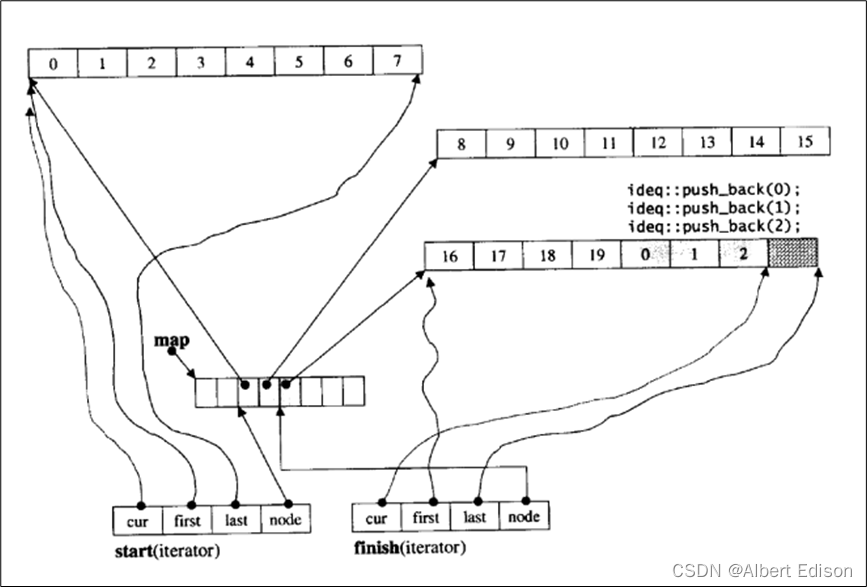
「deque」并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际「deque」类似于一个动态的二维数组,其底层结构如下图所示:
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其 “整体连续” 以及随机访问的假象,落
在了「deque」的迭代器身上,因此「deque」的迭代器设计就比较复杂,如下图所示:
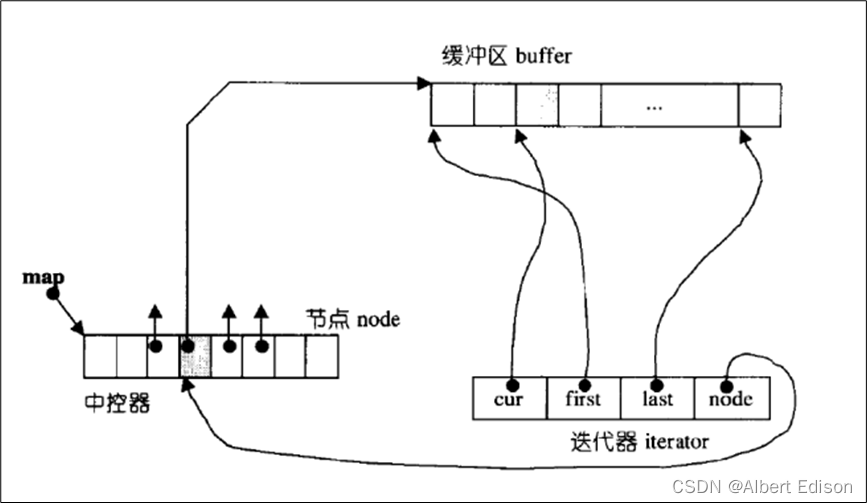
那「deque」是如何借助其迭代器维护其假想连续的结构呢?
🍑 deque的缺陷
「vector」的优缺点:
- 优点:适合尾插尾删,随机访问
- 缺点:不适合头部或者中部插入删除,效率低,需要挪动数据;扩容有一定性能消耗,还可能存在一定程度的空间浪费。
「list」的优缺点:
- 优点:任意位置插入删除效率高;按需申请释放空间。
- 缺点:不支持随机访问;cpu 高速缓存命中低
「deque」就是结合了「vector」和「list」的优缺点而发明的!!!
与「vector」比较,「deque」的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是比「vector」高的。
与「list」比较, 其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,「deque」有一个致命缺陷: 不适合遍历!因为在遍历时,「deque」的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑「vector」和「list」。
「deque」的应用并不多,而目前能看到的一个应用就是,STL 用其作为「stack」和「queue」的底层数据结构。
🍑 选择deque的原因
为什么选择「deque」作为「stack」和「queue」的底层默认容器?
「stack」是一种后进先出的特殊线性数据结构,因此只要具有 push_back() 和 pop_back() 操作的线性结构,都可以作为「stack」的底层容器,比如「vector」和「list」都可以;
「queue」是先进先出的特殊线性数据结构,只要具有 push_back() 和 pop_back() 操作的线性结构,都可以作为「queue」的底层容器,比如「list」。
但是 STL 中对「stack」和「queue」默认选择「deque」作为其底层容器,主要是因为:
- 「stack」和「queue」不需要遍历(因此 stack 和 queue 没有迭代器),只需要在固定的一端或者两端进行操作。
- 在「stack」中元素增长时,「queue」比「vector」的效率高(扩容时不需要搬移大量数据)
- 「queue」中的元素增长时,「deque」不仅效率高,而且内存使用率高。
总的来说,就是结合了「deque」的优点,而完美的避开了其缺陷。
8. 模拟实现「stack」和「queue」
🍑 stack的模拟实现
关于 stack 的模拟实现很简单,主要就是针对一些常用的接口,具体代码如下:
namespace edc
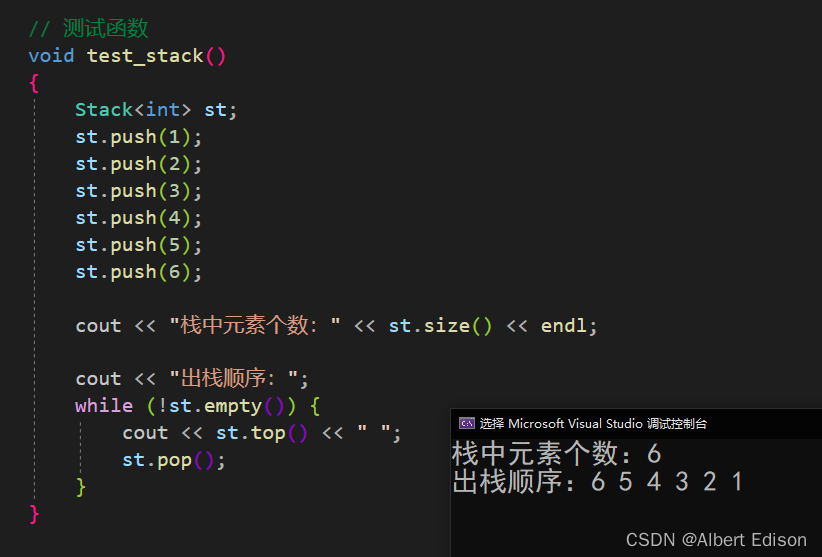
{template<class T, class Container = deque<T>>class Stack{public:// 入栈void push(const T& x){_con.push_back(x);}// 出栈void pop(){_con.pop_back();}// 获取栈顶元素T& top(){return _con.back();}const T& top() const{return _con.back();}//获取栈中有效元素个数size_t size() const{return _con.size();}//判断栈是否为空bool empty() const{return _con.empty();}//交换两个栈中的数据void swap(Stack<T, Container>& st){_con.swap(st._con);}private:Container _con;};// 测试函数void test_stack(){Stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);st.push(6);cout << "栈中元素个数:" << st.size() << endl;cout << "出栈顺序:";while (!st.empty()) {cout << st.top() << " ";st.pop();}}
}
测试结果:
🍑 queue的模拟实现
关于 queue 的模拟实现也很简单,主要就是针对一些常用的接口,具体代码如下:
namespace edc
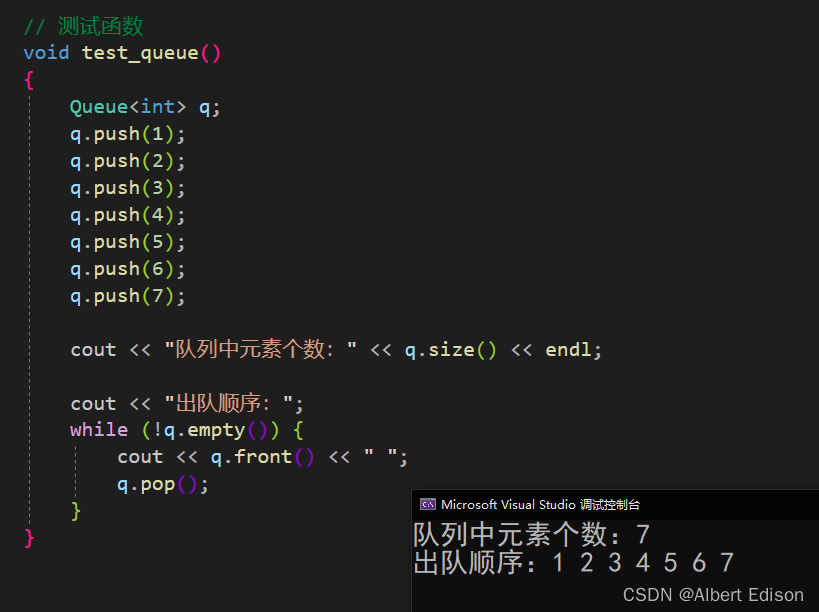
{template<class T, class Container = deque<T>>class Queue{public:// 入队void push(const T& x){_con.push_back(x);}// 出队void pop(){_con.pop_front();}// 获取队头元素T& front(){return _con.front();}const T& front() const{return _con.front();}// 获取队尾元素T& back(){return _con.back();}const T& back() const{return _con.back();}//获取队列中有效元素个数size_t size() const{return _con.size();}//判断队列是否为空bool empty() const{return _con.empty();}//交换两个栈中的数据void swap(Queue<T, Container>& q){_con.swap(q._con);}private:Container _con;};// 测试函数void test_queue(){Queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);q.push(6);q.push(7);cout << "队列中元素个数:" << q.size() << endl;cout << "出队顺序:";while (!q.empty()) {cout << q.front() << " ";q.pop();}}
}
测试结果:
9. 总结
对于栈和队列,我相信只要数据结构的基础还不错,那么本篇文章的接口函数肯定是手到擒来!
最后我们再看一下栈和队列在实际生活中的应用吧。
栈典型应用:
- 浏览器中的后退与前进、软件中的撤销与反撤销。 每当我们打开新的网页,浏览器就讲上一个网页执行入栈,这样我们就可以通过「后退」操作来回到上一页面,后退操作实际上是在执行出栈。如果要同时支持后退和前进,那么则需要两个栈来配合实现。
- 程序内存管理。 每当调用函数时,系统就会在栈顶添加一个栈帧,用来记录函数的上下文信息。在递归函数中,向下递推会不断执行入栈,向上回溯阶段时出栈。
队列典型应用:
- 淘宝订单。 购物者下单后,订单就被加入到队列之中,随后系统再根据顺序依次处理队列中的订单。在双十一时,在短时间内会产生海量的订单,如何处理「高并发」则是工程师们需要重点思考的问题。
- 各种待办事项。 例如打印机的任务队列、餐厅的出餐队列等等。
相关文章:
C++STL剖析(四)—— stack和queue的概念和使用
文章目录1. stack的介绍2. stack的构造3. stack的使用🍑 push🍑 top🍑 pop🍑 empty🍑 size🍑 swap🍑 emplace4. queue的介绍5. queue的构造6. queue的使用🍑 push🍑 size…...

流浪地球 | 建筑人是如何看待小破球里的黑科技的?
大家好,这里是建模助手。 想问问大家今年贺岁档,都跟上没有,今天请允许我蹭一下热点表达一下作为一个科幻迷的爱国之情。 抛开大刘的想象力、各种硬核科技&以及大国情怀不提,破球2中的传承还是让小编很受感动,无…...
软中断在bottom-half中调用
https://www.bilibili.com/read/cv20785285/简介软中断可以在两个位置得到机会执行:硬中断返回前 irq_exit中断下半部 Bottom-half Enable后情景分析情景1spin_unlock_bh__raw_spin_unlock_bh__local_bh_enable_ip 打开Bottom-half,并让softirq有机会…...
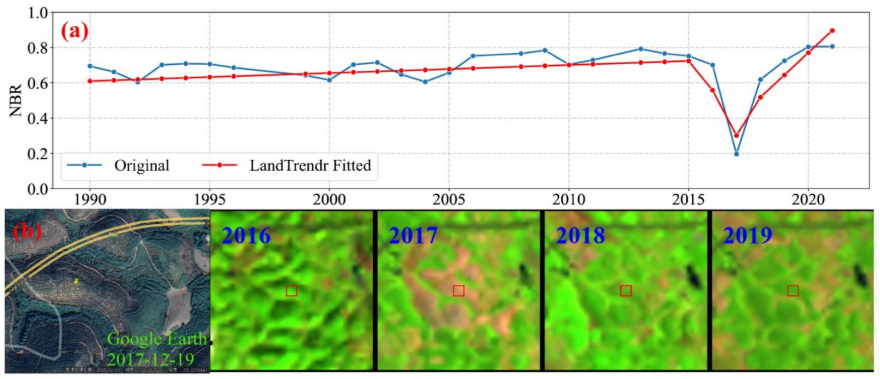
GEE遥感云大数据在林业中的应用
近年来遥感技术得到了突飞猛进的发展,航天、航空、临近空间等多遥感平台不断增加,数据的空间、时间、光谱分辨率不断提高,数据量猛增,遥感数据已经越来越具有大数据特征。遥感大数据的出现为相关研究提供了前所未有的机遇…...

Apollo架构篇 - 客户端架构
前言 本文基于 Apollo 1.8.0 版本展开分析。 客户端 使用 Apollo 支持 API 方式和 Spring 整合两种方式。 API 方式 API 方式是最简单、高效使用使用 Apollo 配置的方式,不依赖 Spring 框架即可使用。 获取命名空间的配置 // 1、获取默认的命名空间的配置 C…...
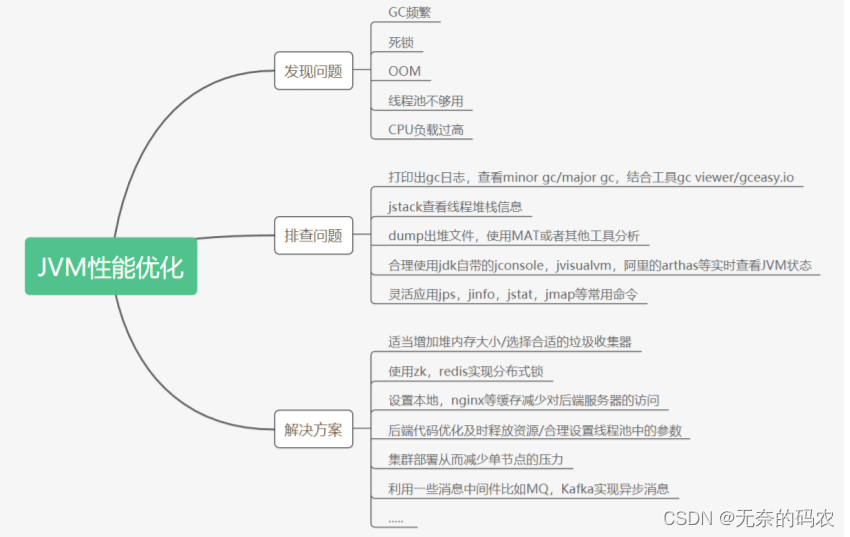
JVM调优最全面的成长 :参数详解+垃圾算法+示例展示+类文件到源码+面试问题
目录1.优秀的Java开发者1.1 什么是Java?1.2 编程语言1.3 计算机[硬件]能够懂的语言1.3.1 计算机发展史1.3.2 计算机体系结构1.3.3 计算机处理数据过程1.3.4 机器语言1.3.5 不同厂商的CPU1.3.6 操作系统1.3.7 汇编语言1.3.8 高级语言1.3.9 编译型和解释型1.3.9.1 编译…...

linux驱动常用函数
以下为一些常见用户态函数在内核中的替代,包括头文件和函数声明:1、动态申请内存:linux/vmalloc.hvoid *vmalloc(unsigned long size);void vfree(const void *addr);2、字符串操作:linux/string.hvoid * memset(void *,int,__ker…...

Flowable进阶学习(九)数据对象DataObject、租户Tenant、接收任务ReceiveTask
文章目录一、数据对象DataObject二、租户 Tenant三、接收任务 ReceiveTask案例一、数据对象DataObject DataObject可以⽤来定义⼀些流程的全局属性。 绘制流程图,并配置数据对象(不需要选择任意节点) 2. 编码与测试 /*** 部署流程*/ Test…...

C语言实现五子棋(n子棋)
五子棋的历史背景: 五子棋起源于中国,是全国智力运动会竞技项目之一,是一种两人对弈的纯策略型棋类游戏。双方分别使用黑白两色的棋子,下在棋盘直线与横线的交叉点上,先形成五子连珠者获胜。五子棋容易上手,…...
 | 安装Keystone)
OpenStack云平台搭建(2) | 安装Keystone
目录 1、登录数据库配置 2、数据库导入Keystone表 3、配置http服务 4、创建域、用户 5、创建脚本 Keystone(OpenStack Identity Service)是 OpenStack 框架中负责管理身份验证、服务访问规则和服务令牌功能的组件。下面我们进行Keystone的安装部署 1…...

基于javaFX的固定资产管理系统
1. 总体设计 本系统分为登录模块、资产管理模块、资产登记模块和信息展示模块共四个模块。 登录模块的主要功能是:管理员通过登录模块登录本系统; 资产管理模块的主要功能有:修改、删除系统中的固定资产; 在资产登记模块中&#…...
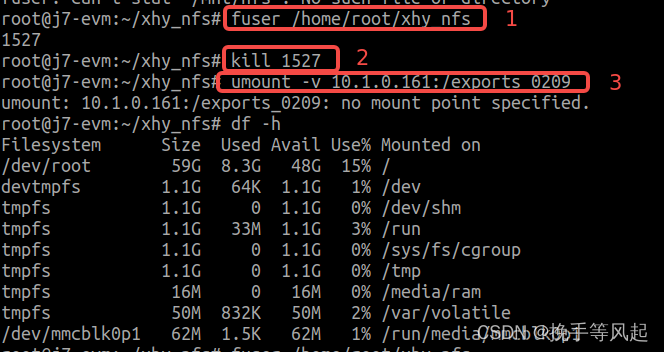
板子登录和挂载问题记录
ubuntu登录板子问题 ssh登录ssh 10.1.3.15,显示No route to host 则尝试在板子上ping 本机ip 试一下 挂载 本地机器vim /etc/export编辑此内容并保存 /exports_0209/tda4_build *(rw,no_root_squash,nohide,insecure,no_subtree_check,async)1.挂载nfs方法 mou…...
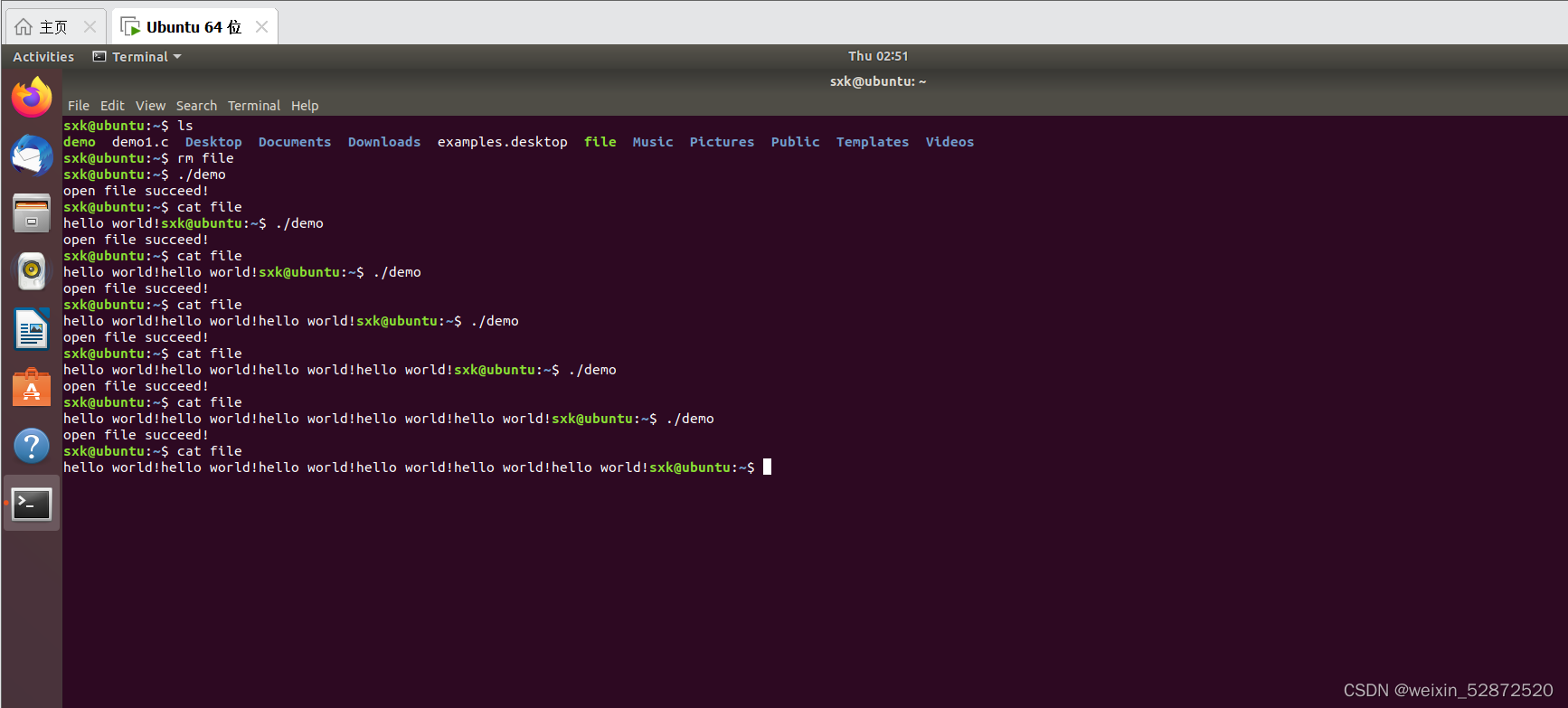
二、Linux文件 - Open函数讲解实战
目录 1.Open函数讲解 2.open函数实战 2.1 man 1 ls 查询Shell命令 2.2 man 2 open 查看系统调用函数 2.3项目实战 2.3.1O_RDWR和O_CREAT 2.3.2O_APPEND的用法 1.Open函数讲解 高频使用的Linux系统调用:open write read close Linux自带的工具…...
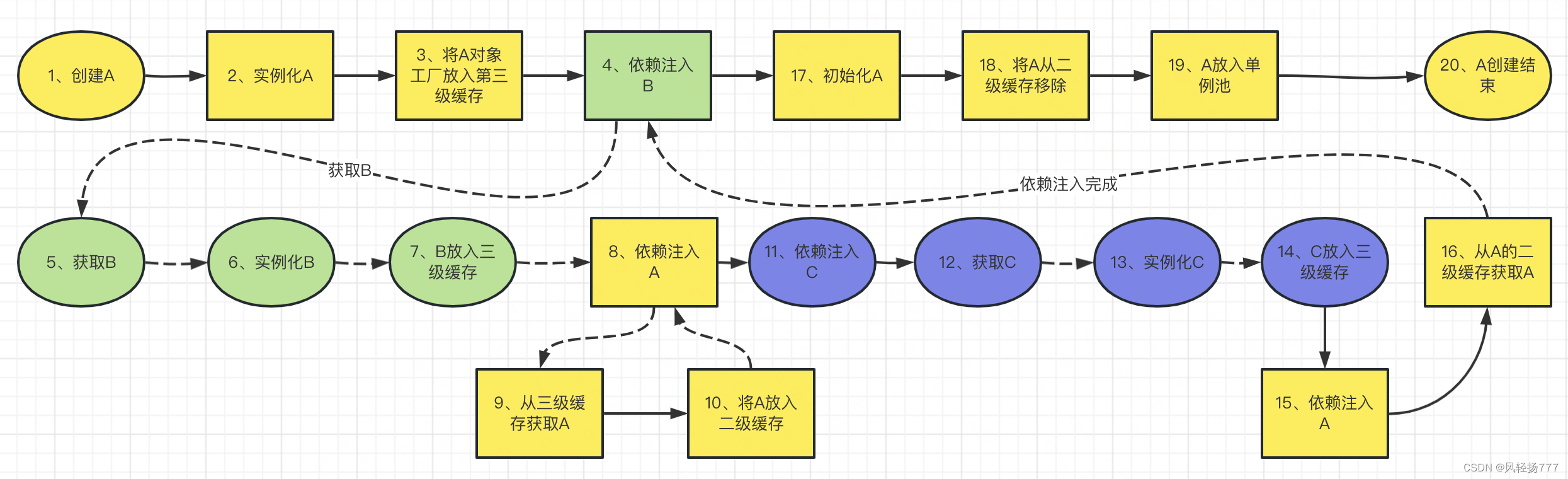
源码分析Spring解决循环依赖的过程
循环依赖是之前很爱问的一个面试题,最近不咋问了,但是梳理Spring解决循环依赖的源码,会让我们对Spring创建bean的流程有一个清晰的认识,有必要搞一搞。开始搞之前,先参考了这个老哥写的文章,对Spring处理循…...
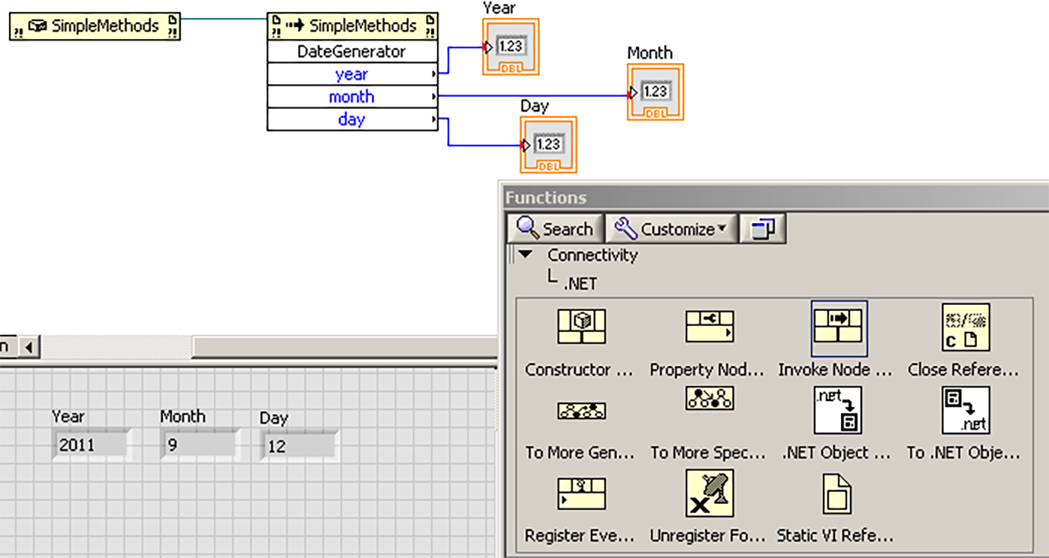
LabVIEW中加载.NET 2.0,3.0和3.5程序集
LabVIEW中加载.NET 2.0,3.0和3.5程序集已使用.NETFramework 2.0,3.0或3.5创建了.NET程序集,但是当尝试在构造函数节点中加载这些程序集时,却收到LabVIEW消息显示: 所选文件不是.NET程序集,所属类型库或自动化可执行文件。所以想确认是否可以在…...

Fluent Python 笔记 第 2 章 序列构成的数组
2.1 内置类型序列概览 容器序列(能存放不同类型的数据):(作者分的类) list、tuple 和 collections.deque扁平序列(只能容纳一种类型): str、byes、bytearray、memoryview 和 array.array可变:…...

句子扩充法
人,物,时,地,事 什么人和什么物在什么时间什么地点发生了什么事。 思维导图:以人为中心,人具有客观能动性。 例如:秋燕南飞。 扩展为: 盘旋在洞庭湖上方的大雁渐渐消失了。“它们都…...

Java并发编程概述
在学习并发编程之前,我们需要稍微回顾以下线程相关知识:线程基本概念程序:静态的代码,存储在硬盘中进程:运行中的程序,被加载在内存中,是操作系统分配内存的基本单位线程:是cpu执行的…...
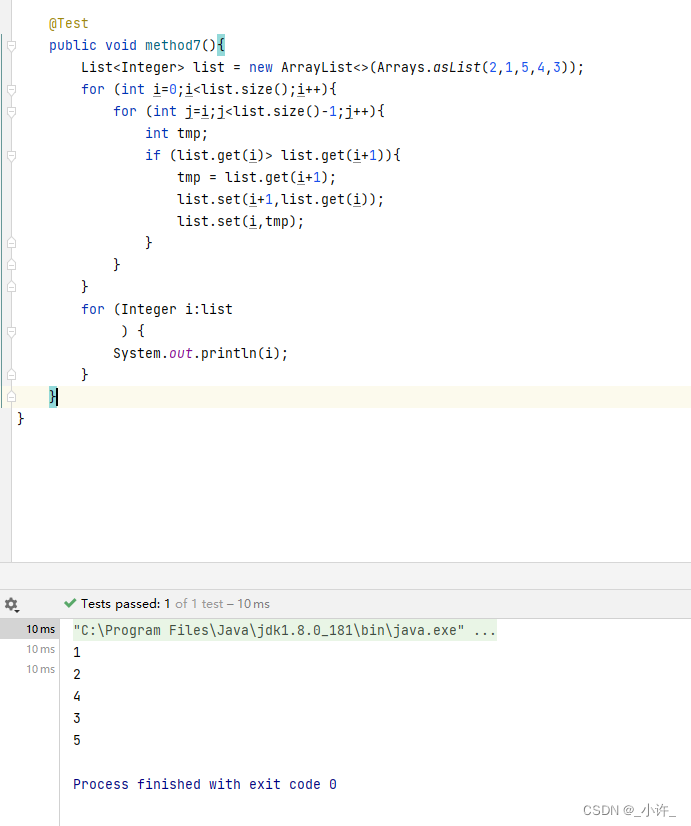
Java常见数据结构的排序与遍历(包括数组,List,Map)
数组遍历与排序 数组定义 //定义 int a[] new int[5]int[] a new int[5];//带初始值定义 int b[] {1,2,3,4,5};赋值 //定义时赋值 int b[] {1,2,3,4,5};//引用赋值 a[6] 1 a[9] 9 //未赋值为空取值 //通过下表取值,从0开始 b[1] 1 b[2] 2遍历 Test p…...
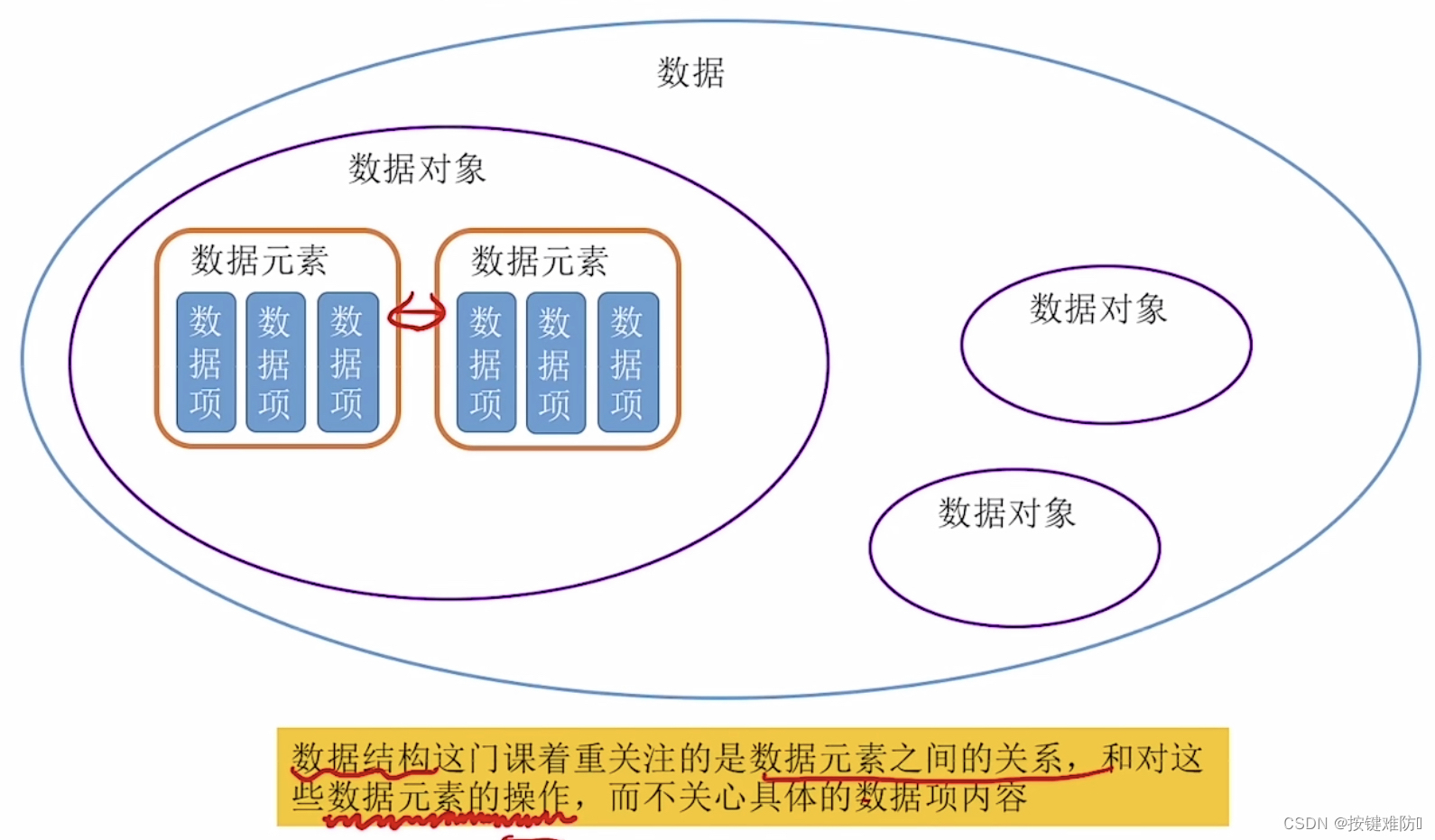
数据结构|绪论
🔥Go for it!🔥 📝个人主页:按键难防 📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀 📖系列专栏:数据结构与算法 ὒ…...

003、TinyML与传统ML、边缘AI的区别与联系
TinyML与传统ML、边缘AI的区别与联系 从一次“模型跑死”的现场说起 上周帮一个做智能门锁的团队调模型,他们用MobileNetV2在STM32F4上做人脸检测。板子一上电,串口疯狂打印“HardFault”,复位后连RTOS都起不来。我一看代码,好家伙,直接把一个4MB的TFLite模型塞进了256K…...

分数阶傅里叶变换在声纳阵列分析中的应用与优化
1. 分数阶傅里叶变换在声纳阵列分析中的核心价值在水下声学工程领域,准确计算声纳阵列的辐射模式一直是个技术难点。传统FFT算法虽然计算效率高,但在处理特定方位角的辐射特性时存在明显的精度局限。2005年日本防卫厅技术研究本所的这项研究,…...

第57篇:Vibe Coding时代:LangGraph + 代码所有者规则实战,解决 Agent 修改核心模块无人负责的问题
第57篇:Vibe Coding时代:LangGraph + 代码所有者规则实战,解决 Agent 修改核心模块无人负责的问题 一、问题场景:Agent 修改了核心文件,但没有找到该找谁审 在团队项目中,不同模块通常有不同负责人: auth 模块:安全团队 payment 模块:支付团队 database 模块:平台团…...

ces sdfsdfdsf
https://github.com/wgpsec/redc https://github.com/wgpsec/benchmark-platform...

MATLAB 2018a/2023b实测:Libsvm安装后如何用自带数据集快速验证与跑通第一个模型
MATLAB 2018a/2023b实战:Libsvm安装后快速验证与模型跑通全流程 当你第一次在MATLAB中成功安装Libsvm后,那种兴奋感可能很快会被"接下来该做什么"的迷茫所取代。别担心,这篇文章将带你用Libsvm自带的heart_scale数据集,…...

WhisperPlus自动字幕生成:为视频添加多语言字幕的简单方法
WhisperPlus自动字幕生成:为视频添加多语言字幕的简单方法 【免费下载链接】whisper-plus WhisperPlus: Faster, Smarter, and More Capable 🚀 项目地址: https://gitcode.com/gh_mirrors/wh/whisper-plus WhisperPlus是一款功能强大的工具&…...

Python3.8环境下的OpenOPC实战:从模拟服务器搭建到KEPServerEX数据读写一条龙
Python3.8环境下的OpenOPC实战:从模拟服务器搭建到KEPServerEX数据读写全流程指南 工业自动化领域的数据采集一直是开发者需要掌握的核心技能之一。对于没有硬件设备或OPC服务器许可的学习者来说,如何在本地搭建完整的测试环境成为入门的第一道门槛。本文…...

Python 爬虫数据处理:富文本爬虫内容格式化还原
前言 互联网平台发布的文章、资讯、公众号推文、论坛帖子、商品详情、教程文案等内容,普遍以富文本形式存在,融合文字、段落层级、换行缩进、加粗引用、列表排版、超链接、分段结构等多种格式元素。普通爬虫仅能抓取原始 HTML 源码或纯文本内容…...

STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发?
STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发? 在嵌入式开发中,定时器中断是最基础也最常用的功能之一。然而,当开发者从标准库转向LL库(Low Layer Library)时,往往会遇到各种&quo…...

如何永久保存微信聊天记录?WeChatExporter一站式解决方案
如何永久保存微信聊天记录?WeChatExporter一站式解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录承载着我们的工…...