TensorFlow2.x基础与mnist手写数字识别示例
文章目录
- Github
- 官网
- 文档
- Playground
- 安装
- 声明张量
- 常量
- 变量
- 张量计算
- 张量数据类型转换
- 张量数据维度转换
- ReLU 函数
- Softmax 函数
- 卷积神经网络
- 训练模型
- 测试模型
- 数据集保存目录
- 显示每层网络的结果

TensorFlow 是一个开源的深度学习框架,由 Google Brain 团队开发和维护。它被广泛应用于机器学习和深度学习领域,可用于构建各种人工智能模型,包括图像识别、自然语言处理、语音识别、推荐系统等。
-
灵活性和可扩展性:TensorFlow 提供了灵活且可扩展的架构,可以在各种硬件平台上运行,包括 CPU、GPU 和 TPU(Tensor Processing Unit)。这使得 TensorFlow 成为构建大规模深度学习模型的理想选择。
-
计算图:TensorFlow 使用静态计算图的概念来表示机器学习模型。在构建模型时,首先定义计算图,然后执行计算图以训练模型或进行推理。
-
自动求导:TensorFlow 提供了自动求导功能,能够自动计算模型中各个参数的梯度。这简化了模型训练过程中的反向传播步骤。
-
高级 API:TensorFlow 提供了多种高级 API,如 tf.keras、tf.estimator 和 tf.data 等,使得构建、训练和部署机器学习模型更加简单和高效。
-
跨平台支持:TensorFlow 不仅支持在各种硬件平台上运行,还可以在多种操作系统上运行,包括 Linux、Windows 和 macOS。
-
社区支持:TensorFlow 拥有庞大的开发者社区,提供了丰富的文档、教程和示例代码,使得学习和使用 TensorFlow 更加容易。
Github
- https://github.com/tensorflow/tensorflow
官网
- https://tensorflow.google.cn/?hl=zh-cn
文档
- https://tensorflow.google.cn/api_docs/python/tf
Playground
- https://playground.tensorflow.org/
TensorFlow Playground 是一个交互式可视化工具,旨在帮助用户理解和探索神经网络的基本概念和行为。它提供了一个易于使用的界面,可以在浏览器中运行,不需要编写代码。用户可以通过调整参数和观察结果,直观地理解神经网络的工作原理。
安装
- 清理所有安装包
pip freeze | xargs pip uninstall -y
pip install tensorflow==2.13.1
pip install matplotlib==3.7.5
pip install numpy==1.24.3
- 查看版本
pip list
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
声明张量
常量
- https://tensorflow.google.cn/api_docs/python/tf/constant
tf.constant(value, dtype=None, shape=None, name=None)
-
value:常量张量的值。可以是标量、列表、数组等形式的数据。如果传入的是标量,则创建的是一个标量张量;如果传入的是列表或数组,则创建的是一个多维张量。
-
dtype:常量张量的数据类型。可选参数,默认为 None。如果未指定数据类型,则根据传入的 value 推断数据类型。
-
shape:常量张量的形状。可选参数,默认为 None。如果未指定形状,则根据传入的 value 推断形状。
-
name:常量张量的名称。可选参数,默认为 None。如果未指定名称,则 TensorFlow 将自动生成一个唯一的名称。
import tensorflow as tftensor_constant = tf.constant([[1, 2], [3, 4]], dtype=tf.int32, shape=(2, 2), name="constant")
print("常量张量:", tensor_constant)
- 输出
常量张量: tf.Tensor(
[[1 2][3 4]], shape=(2, 2), dtype=int32)
变量
- https://tensorflow.google.cn/api_docs/python/tf/Variable
tf.Variable(initial_value, dtype, name=None)
-
initial_value:变量张量的初始值。可以是标量、列表、数组等形式的数据。如果传入的是标量,则创建的是一个标量张量;如果传入的是列表或数组,则创建的是一个多维张量。
-
dtype:变量张量的数据类型。此参数是必须的,不能为 None。你需要明确指定变量张量的数据类型。
-
name:变量张量的名称。可选参数,默认为 None。如果未指定名称,则 TensorFlow 将自动生成一个唯一的名称。
import tensorflow as tftensor_variable = tf.Variable(initial_value=[1, 2], dtype=tf.int32, name="variable")
print("变量张量:", tensor_variable)
- 输出
变量张量: <tf.Variable 'variable:0' shape=(2,) dtype=int32, numpy=array([1, 2], dtype=int32)>
张量计算
import tensorflow as tfa_constant = tf.constant([[1, 2], [3, 4]], dtype=tf.int32, shape=(2, 2), name="a")
print("常量张量:", a_constant)b_variable = tf.Variable(initial_value=[1, 2], dtype=tf.int32, name="b")
print("变量张量:", b_variable)# 定义加法操作节点
c = tf.add(a_constant, b_variable, name="c")
# 执行加法操作并获取结果
print("输出结果: a + b = ", c.numpy())
- 输出
常量张量: tf.Tensor(
[[1 2][3 4]], shape=(2, 2), dtype=int32)
变量张量: <tf.Variable 'b:0' shape=(2,) dtype=int32, numpy=array([1, 2], dtype=int32)>
输出结果: a + b = [[2 4][4 6]]
张量数据类型转换
import tensorflow as tfint_tensor = tf.constant([[1, 2], [3, 4]], dtype=tf.int32, shape=(2, 2), name="constant")
print("整型张量:", int_tensor)
# 将整数张量转换为浮点数张量
float_tensor = tf.cast(int_tensor, dtype=tf.float32)
print("浮点张量:", float_tensor)
- 输出
整型张量: tf.Tensor(
[[1 2][3 4]], shape=(2, 2), dtype=int32)
浮点张量: tf.Tensor(
[[1. 2.][3. 4.]], shape=(2, 2), dtype=float32)
张量数据维度转换
- 张量转换为指定形状的新张量,而不改变张量中的元素值
import tensorflow as tf# [2, 3] 形状的张量
tensor = tf.constant([[1, 2, 3], [4, 5, 6]])
# [3, 2] 形状的张量
new_tensor = tf.reshape(tensor, [3, 2])print("[2, 3] 形状的张量:", tensor)
print("[3, 2] 形状的张量:", new_tensor)
- 输出
[2, 3] 形状的张量: tf.Tensor(
[[1 2 3][4 5 6]], shape=(2, 3), dtype=int32)
[3, 2] 形状的张量: tf.Tensor(
[[1 2][3 4][5 6]], shape=(3, 2), dtype=int32)
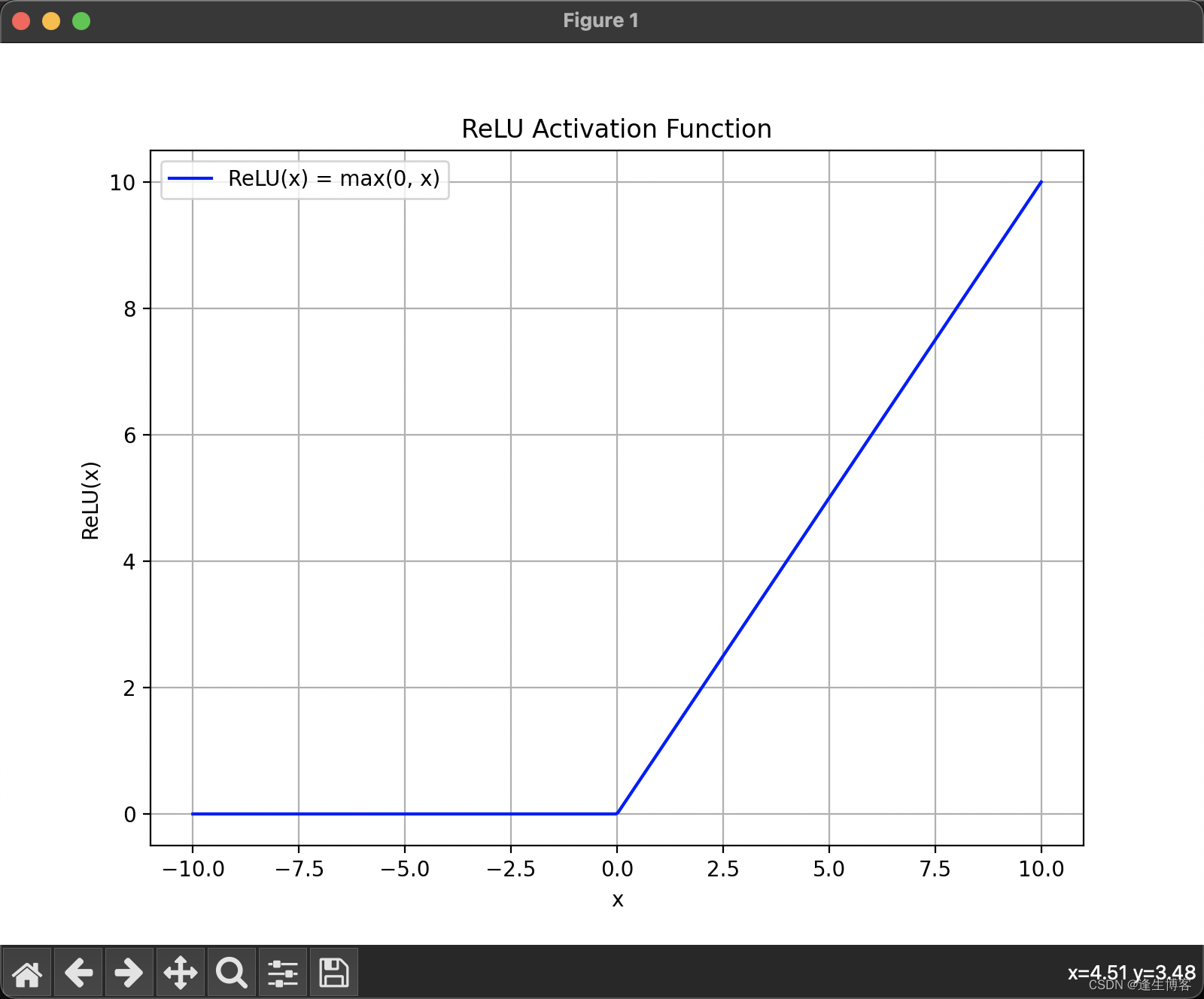
ReLU 函数
ReLU(x)=max(0,x) 即当输入值 x 大于0时,输出 𝑥;否则输出0。
-
引入非线性:
ReLU 函数能够引入非线性,使得 CNN 能够学习和表示更复杂的模式和特征。卷积操作本身是线性的,而非线性激活函数使得网络可以逼近任意复杂的函数。 -
计算效率高:
计算 ReLU 非常简单,只需要对输入进行比较操作,这使得训练和推理过程更加高效。 -
缓解梯度消失问题:
相比 Sigmoid 和 Tanh,ReLU 的梯度在正区间是常数1,这帮助梯度在反向传播时不会消失,使得深层网络的训练更加稳定。 -
稀疏激活:
ReLU 的一部分输出为零,这使得神经元在同一时间不必全部激活,导致更为稀疏和高效的计算。
import numpy as np
import matplotlib.pyplot as plt# 定义ReLU函数
def relu(x):return np.maximum(0, x)# 生成输入数据
x = np.linspace(-10, 10, 400)
y = relu(x)# 绘制ReLU函数图形
plt.figure(figsize=(8, 6))
plt.plot(x, y, label="ReLU(x) = max(0, x)", color='b')
plt.xlabel('x')
plt.ylabel('ReLU(x)')
plt.title('ReLU Activation Function')
plt.legend()
plt.grid(True)
plt.show()
Softmax 函数
Softmax 函数是一种用于多分类问题的激活函数,通常用在神经网络的输出层。它将一个未归一化的数字向量(称为“logits”)转换为一个归一化的概率分布。
在卷积神经网络(CNN)中,Softmax 函数通常用于多分类问题的输出层。
-
概率分布:
Softmax 函数将网络的输出转换为概率分布,使得每个类别的输出值在0到1之间,且所有类别的输出值之和为1。这使得输出值可以直接解释为各个类别的概率。 -
分类决策:
在多分类任务中,通常选择 Softmax 函数输出概率最高的类别作为模型的预测结果。 -
梯度计算:
Softmax 函数与交叉熵损失函数(Cross-Entropy Loss)结合使用效果很好。交叉熵损失函数能够很好地衡量预测的概率分布与真实标签分布之间的差异,从而指导模型参数的优化。
import numpy as np
import matplotlib.pyplot as plt# Softmax 函数
def softmax(x):exp_x = np.exp(x - np.max(x)) # 稳定计算,防止溢出return exp_x / exp_x.sum(axis=0)# 定义输入值范围
x = np.linspace(-2, 2, 400)
scores = np.vstack([x, np.ones_like(x), 0.2 * np.ones_like(x)])# 计算 Softmax 输出
softmax_scores = softmax(scores)# 绘制图形
plt.plot(x, softmax_scores[0], label='x')
plt.plot(x, softmax_scores[1], label='1')
plt.plot(x, softmax_scores[2], label='0.2')
plt.title('Softmax Function')
plt.xlabel('Input Value')
plt.ylabel('Softmax Output')
plt.legend()
plt.show()
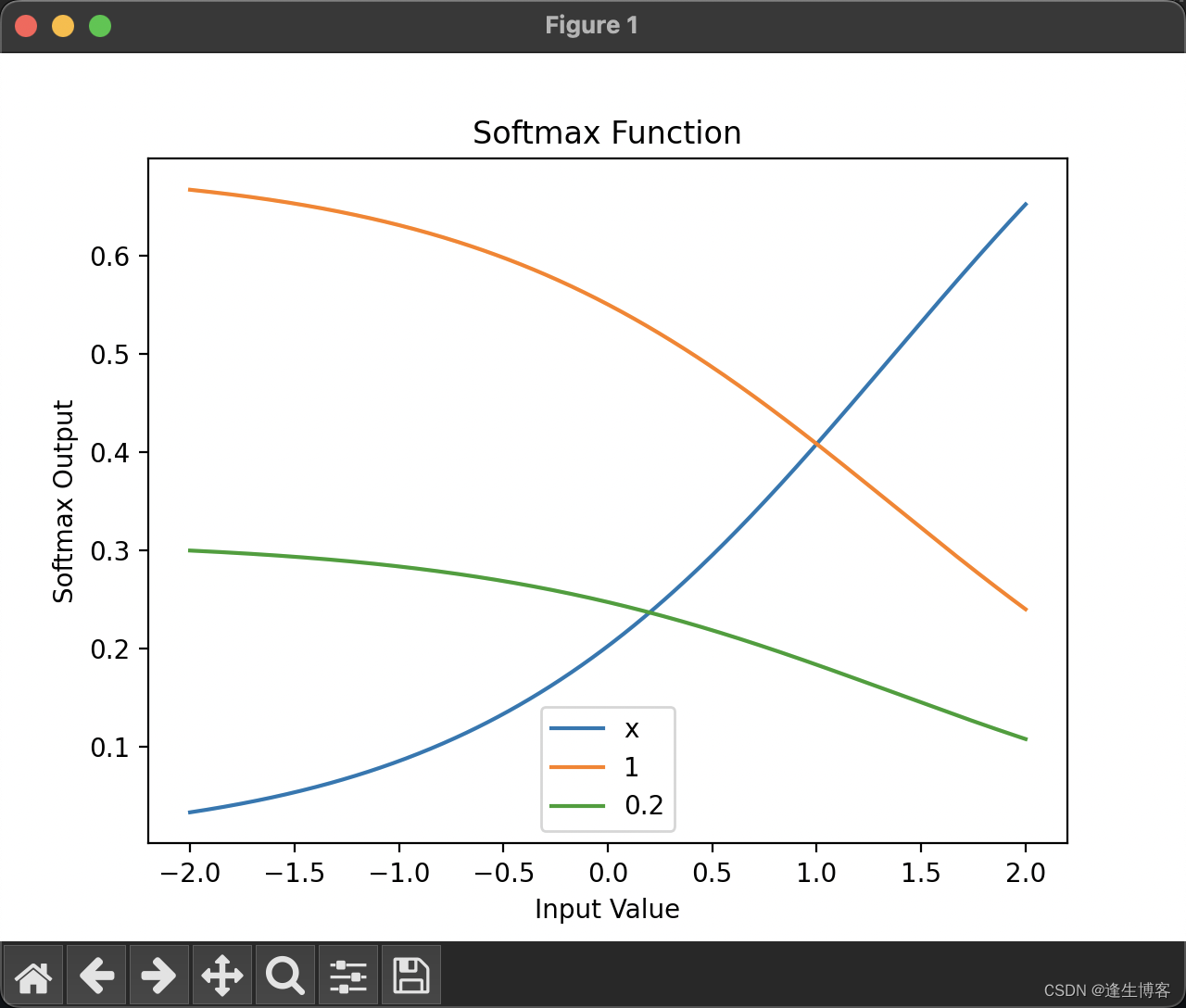
Softmax 函数如何将不同输入转换为概率分布,并且可以清晰地看到随着输入值 x 的变化,Softmax 输出的动态变化。
- 第一条线(label=‘x’):代表输入值从 -2 到 2 的变化范围。由于 x 的变化较大,Softmax 函数的输出也会随之变化,反映出该行输入在整个向量中的相对影响力。
- 第二条线(label=‘1’):代表一个常数值 1 的输入。由于这个值是常数,Softmax 的输出会相对稳定,不会随着 x 的变化而变化太大。
- 第三条线(label=‘0.2’):代表一个常数值 0.2 的输入。与常数值 1 类似,这条线也相对稳定,但因为 0.2 小于 1,在 Softmax 输出中,其影响力会更小。
卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一类深度学习模型,主要用于图像识别、语音识别和自然语言处理等领域。CNN 在计算机视觉任务中取得了巨大成功,是许多图像识别任务的首选模型。
CNN 的核心思想是通过卷积层和池化层来提取输入图像的特征,并将这些特征输入到全连接层中进行分类或回归。
-
卷积层(Convolutional Layer): 卷积层通过使用卷积核(也称为过滤器)来提取图像中的特征。卷积操作会在输入图像上滑动卷积核,并将卷积核与输入图像的局部区域进行点积运算,从而得到特征图(也称为卷积特征映射)。
-
池化层(Pooling Layer): 池化层用于降低特征图的空间尺寸,同时保留重要的特征信息。最常见的池化操作是最大池化(Max Pooling),它选取输入区域的最大值作为输出;还有平均池化(Average Pooling),它计算输入区域的平均值作为输出。
-
激活函数(Activation Function): 激活函数引入非线性性质,使得 CNN 能够学习非线性的特征。常用的激活函数包括ReLU(Rectified Linear Unit)、Sigmoid、Tanh等。
-
全连接层(Fully Connected Layer): 全连接层将卷积层和池化层提取的特征进行展开,并连接到一个或多个全连接层中。全连接层通常用于将特征映射到输出类别或进行回归预测。
-
损失函数(Loss Function): 损失函数用于衡量模型预测值与真实标签之间的差异。在分类任务中常用的损失函数包括交叉熵损失函数(Cross Entropy Loss)等。
-
优化器(Optimizer): 优化器用于更新模型的参数,以最小化损失函数。常用的优化器包括随机梯度下降(SGD)、Adam、RMSProp等。
训练模型
-
Conv2D 层:用于提取图像特征。每个 Conv2D 层都包括一组卷积核(filters),用于对输入图像进行卷积操作。在这个模型中,我们使用了三个 Conv2D 层,每个 Conv2D 层后面跟着一个 ReLU 激活函数,以引入非线性。
-
MaxPooling2D 层:用于下采样和减少模型复杂度。MaxPooling2D 层通过在局部区域内取最大值来减小特征图的空间大小,从而降低计算量和参数数量。在这个模型中,我们使用了两个 MaxPooling2D 层,每个层将特征图的大小减半。
-
Flatten 层:用于将多维的特征图展平成一维向量,以便与全连接层相连。
-
Dense 层:全连接层,用于最终分类。我们使用了两个 Dense 层,其中最后一个 Dense 层的激活函数为 softmax,用于输出每个类别的概率分布。
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt# 加载 MNIST 数据集,这个数据集包含手写数字的图像(0 到 9)
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()# 归一化处理,将像素值从 0-255 缩放到 0-1 之间
train_images, test_images = train_images / 255.0, test_images / 255.0# 创建卷积神经网络模型
model = models.Sequential([# 第一层卷积层,使用 32 个 3x3 的卷积核,激活函数为 ReLU,输入形状为 28x28x1layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),# 第一层池化层,使用 2x2 的池化窗口layers.MaxPooling2D((2, 2)),# 第二层卷积层,使用 64 个 3x3 的卷积核,激活函数为 ReLUlayers.Conv2D(64, (3, 3), activation='relu'),# 第二层池化层,使用 2x2 的池化窗口layers.MaxPooling2D((2, 2)),# 第三层卷积层,使用 64 个 3x3 的卷积核,激活函数为 ReLUlayers.Conv2D(64, (3, 3), activation='relu'),# 将多维的卷积层输出展平成一维向量layers.Flatten(),# 第一个全连接层,包含 64 个神经元,激活函数为 ReLUlayers.Dense(64, activation='relu'),# 输出层,包含 10 个神经元,对应 10 个类别,使用 Softmax 激活函数输出概率分布layers.Dense(10, activation='softmax')
])# 编译模型,指定优化器、损失函数和评估指标
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 调整数据维度,以匹配卷积层输入的形状要求 (28, 28, 1)
train_images = train_images[..., tf.newaxis]
test_images = test_images[..., tf.newaxis]# 开始跟踪计算图,记录模型结构和计算过程
tf.summary.trace_on(graph=True)# 训练模型,使用训练数据,进行 5 个周期(epochs)的训练
model.fit(train_images, train_labels, epochs=5)# 停止跟踪计算图并将其写入日志文件,以便在 TensorBoard 中进行可视化
with tf.summary.create_file_writer('logs').as_default():tf.summary.trace_export(name="model_trace",step=0,profiler_outdir='logs')# 评估模型使用测试数据集,输出损失值和准确率
test_loss, test_acc = model.evaluate(test_images, test_labels)
print("Test accuracy:", test_acc)# 保存模型,将模型结构和权重保存到文件 "mnist_model.h5"
model.save("mnist_model.h5")
print("Model saved successfully.")
- 输出
Epoch 1/5
1875/1875 [==============================] - 33s 17ms/step - loss: 0.1454 - accuracy: 0.9555
Epoch 2/5
1875/1875 [==============================] - 34s 18ms/step - loss: 0.0465 - accuracy: 0.9856
Epoch 3/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.0320 - accuracy: 0.9902
Epoch 4/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.0251 - accuracy: 0.9923
Epoch 5/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.0196 - accuracy: 0.9935
313/313 [==============================] - 2s 4ms/step - loss: 0.0293 - accuracy: 0.9906
Test accuracy: 0.9905999898910522
Model saved successfully.
-
Adam优化器(Adam Optimizer)是深度学习中广泛使用的一种优化算法,它结合了动量优化和RMSProp优化的优点。Adam是“Adaptive Moment Estimation”的缩写,即自适应动量估计。它在处理稀疏梯度和非平稳目标函数方面表现良好。
-
sparse_categorical_crossentropy 是一种用于多类别分类问题的损失函数,特别适用于目标标签为整数编码的情形。它在深度学习中广泛应用,尤其是在处理类别数量较多且标签为整数编码(如0, 1, 2, …)的分类问题中。
-
accuracy(准确率)是衡量分类模型性能的一个常用指标。它表示模型预测正确的样本数量占总样本数量的比例。准确率适用于各种分类问题,但在类别不平衡的数据集中需要谨慎使用,因为它可能会误导模型性能的真实情况。
测试模型
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt# 加载 MNIST 测试集
mnist = tf.keras.datasets.mnist
(_, _), (test_images, test_labels) = mnist.load_data()# 加载保存的模型
loaded_model = tf.keras.models.load_model("mnist_model.h5")
print("Model loaded successfully.")# 选择五个测试图片
num_samples = 5
indices = np.random.randint(0, len(test_images), size=num_samples)
test_images_sample = test_images[indices]
test_labels_sample = test_labels[indices]# 归一化处理并添加批处理维度
test_images_sample = np.expand_dims(test_images_sample / 255.0, axis=(3))# 进行预测
predictions = loaded_model.predict(test_images_sample)
predicted_labels = np.argmax(predictions, axis=1)# 输出预测结果和真实标签
for i in range(num_samples):print(f"True label: {test_labels_sample[i]}, Predicted label: {predicted_labels[i]}")# 显示测试图片
plt.figure(figsize=(15, 3))
for i in range(num_samples):plt.subplot(1, num_samples, i + 1)plt.imshow(test_images_sample[i, :, :, 0], cmap='gray')plt.title(f"True: {test_labels_sample[i]}, Predicted: {predicted_labels[i]}")plt.axis('off')plt.subplots_adjust(wspace=0.5)
plt.show()
- 输出
Model loaded successfully.
1/1 [==============================] - 0s 125ms/step
True label: 6, Predicted label: 6
True label: 0, Predicted label: 0
True label: 4, Predicted label: 4
True label: 2, Predicted label: 2
True label: 1, Predicted label: 1

数据集保存目录
cd ~/.keras/datasets
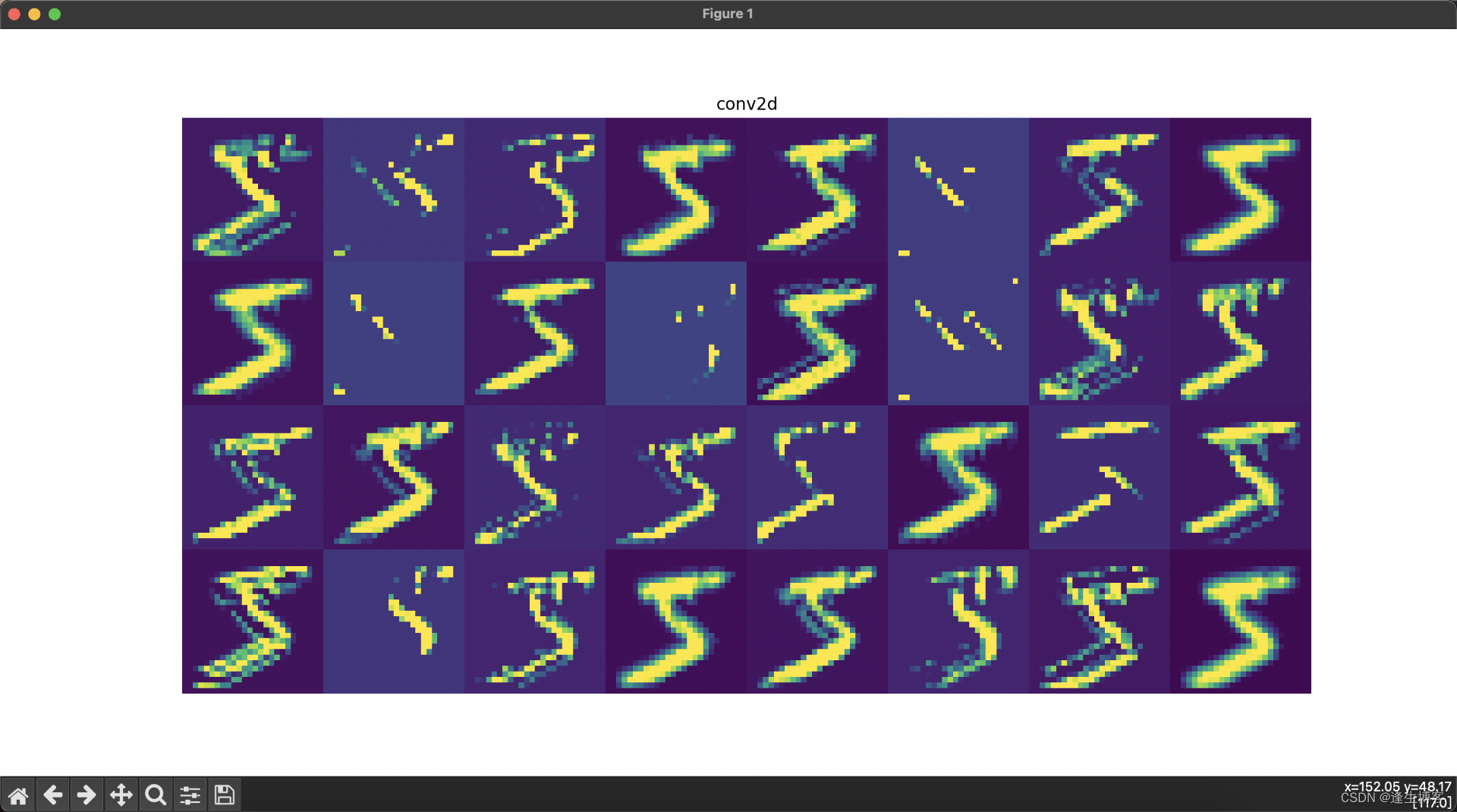
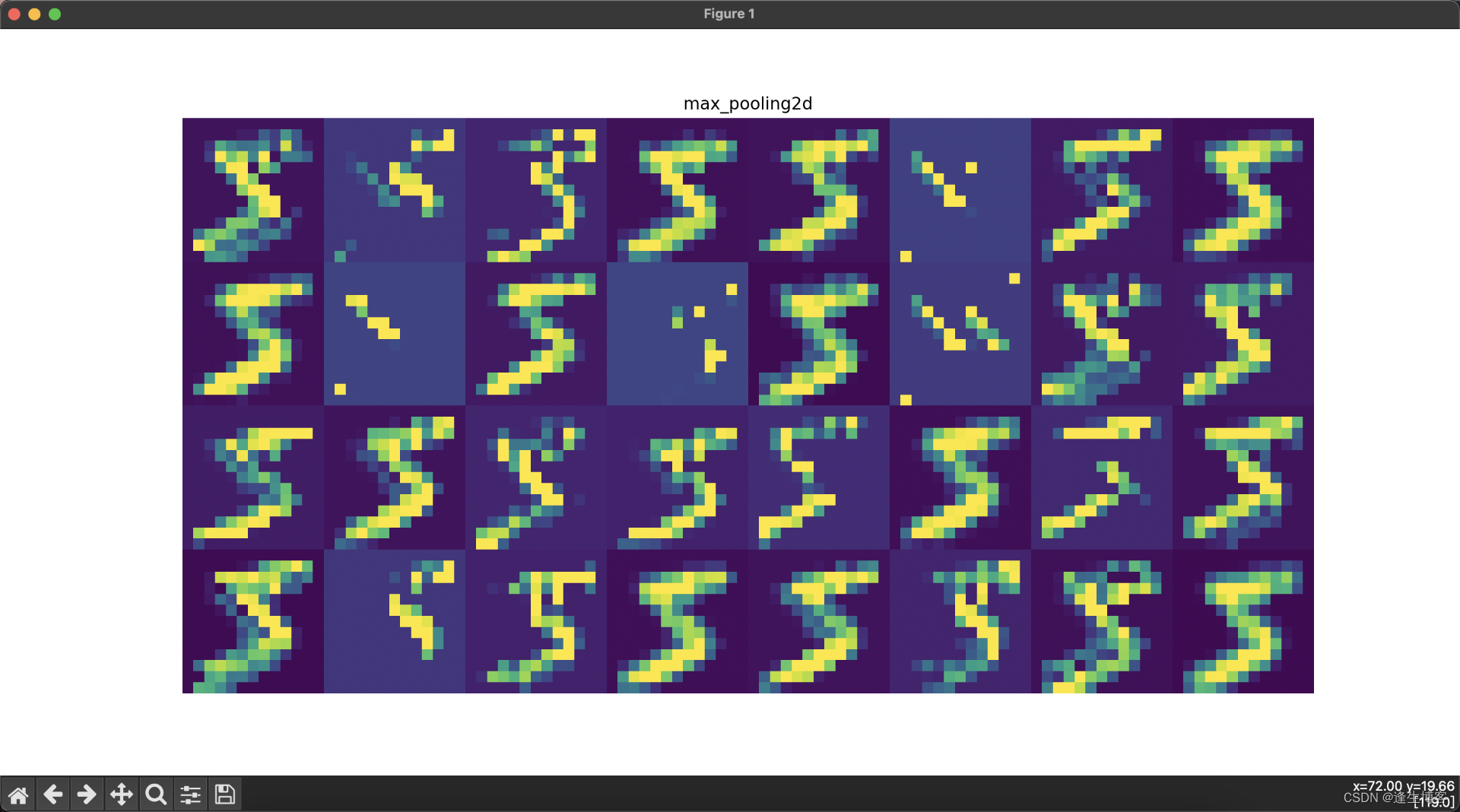
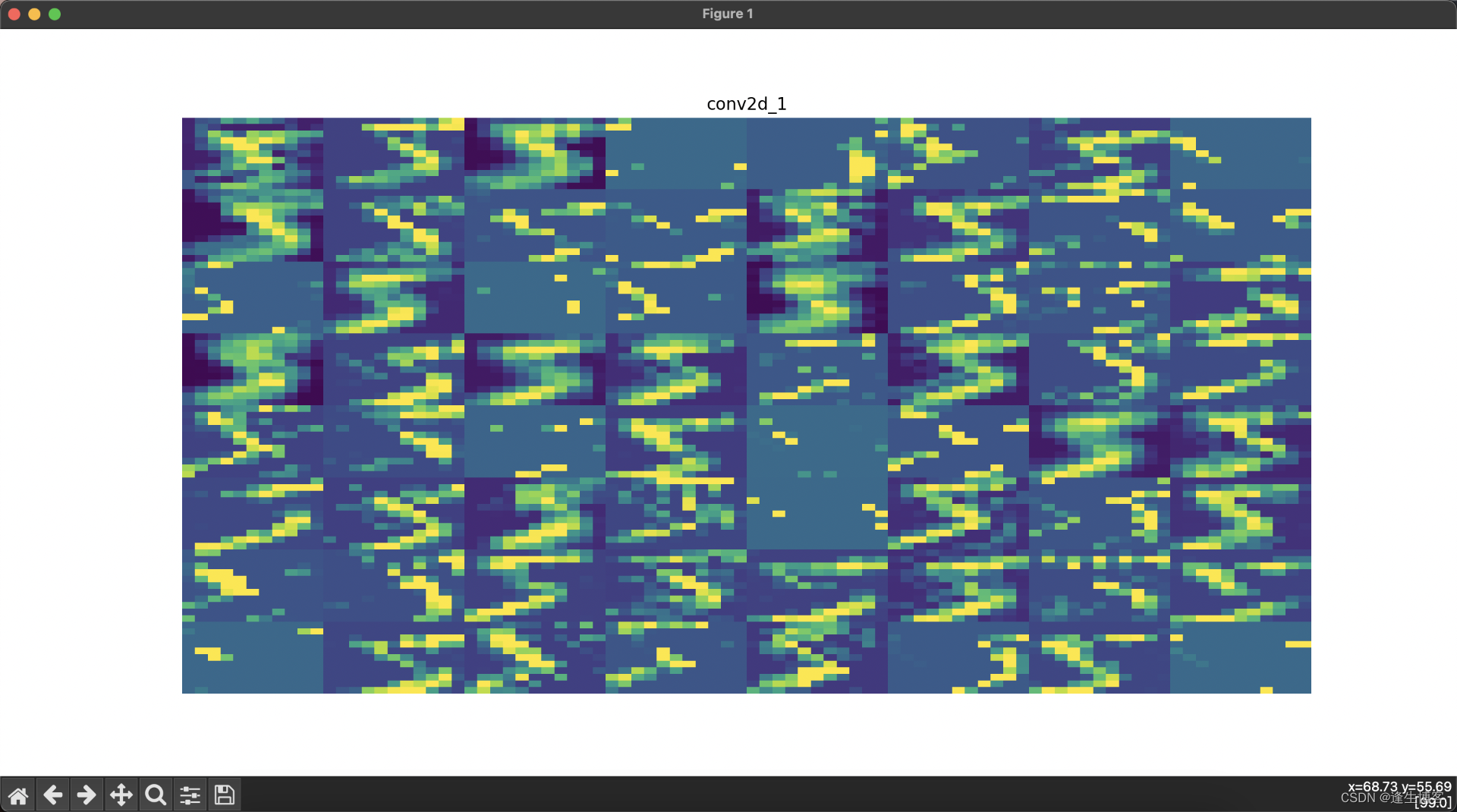
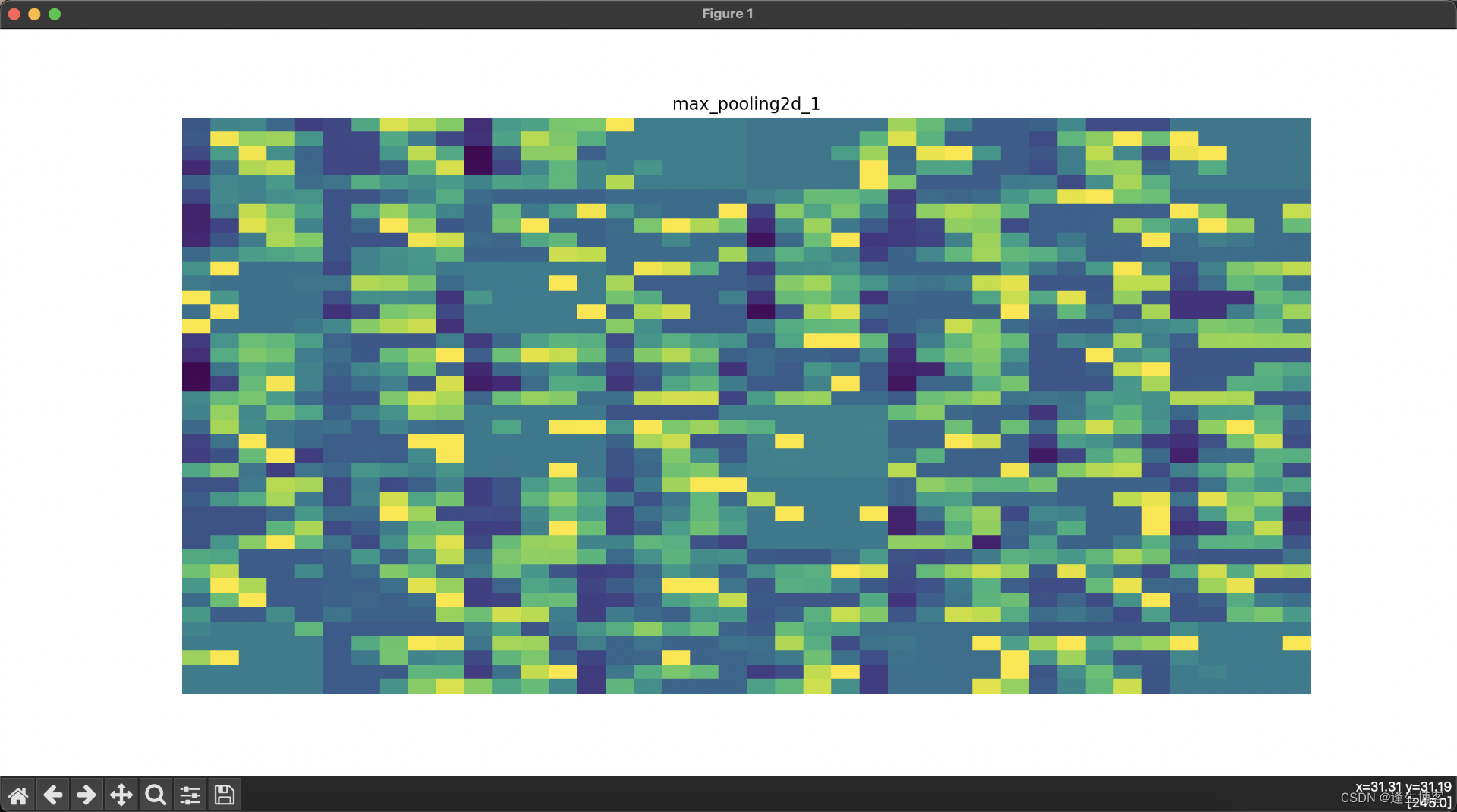
显示每层网络的结果
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import layers, models# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(-1, 28, 28, 1).astype('float32') / 255.0# 创建卷积神经网络模型
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 创建一个新的模型,该模型的输出为每一层的输出
layer_outputs = [layer.output for layer in model.layers] # 获取所有层的输出
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)# 选择一张训练集中的图像并进行预测
img = train_images[0][np.newaxis, ...]
activations = activation_model.predict(img)# 可视化每一层的输出
layer_names = [layer.name for layer in model.layers] # 获取所有层的名称for i, (layer_name, layer_activation) in enumerate(zip(layer_names, activations)):plt.figure(figsize=(15, 15))if len(layer_activation.shape) == 4: # 处理卷积层输出n_features = layer_activation.shape[-1] # 特征图的数量size = layer_activation.shape[1] # 特征图的大小n_cols = n_features // 8 # 显示列数display_grid = np.zeros((size * n_cols, 8 * size))for col in range(n_cols): # 遍历所有的特征图for row in range(8):channel_image = layer_activation[0, :, :, col * 8 + row]channel_image -= channel_image.mean() # 标准化图像if channel_image.std() != 0:channel_image /= channel_image.std()channel_image *= 64channel_image += 128channel_image = np.clip(channel_image, 0, 255).astype('uint8')display_grid[col * size: (col + 1) * size,row * size: (row + 1) * size] = channel_image# 显示每一层的特征图plt.title(layer_name)plt.grid(False)plt.imshow(display_grid, aspect='auto', cmap='viridis')plt.axis('off')else: # 处理展平层和全连接层输出plt.title(layer_name)plt.grid(False)plt.plot(layer_activation[0])plt.axis('off')plt.show()
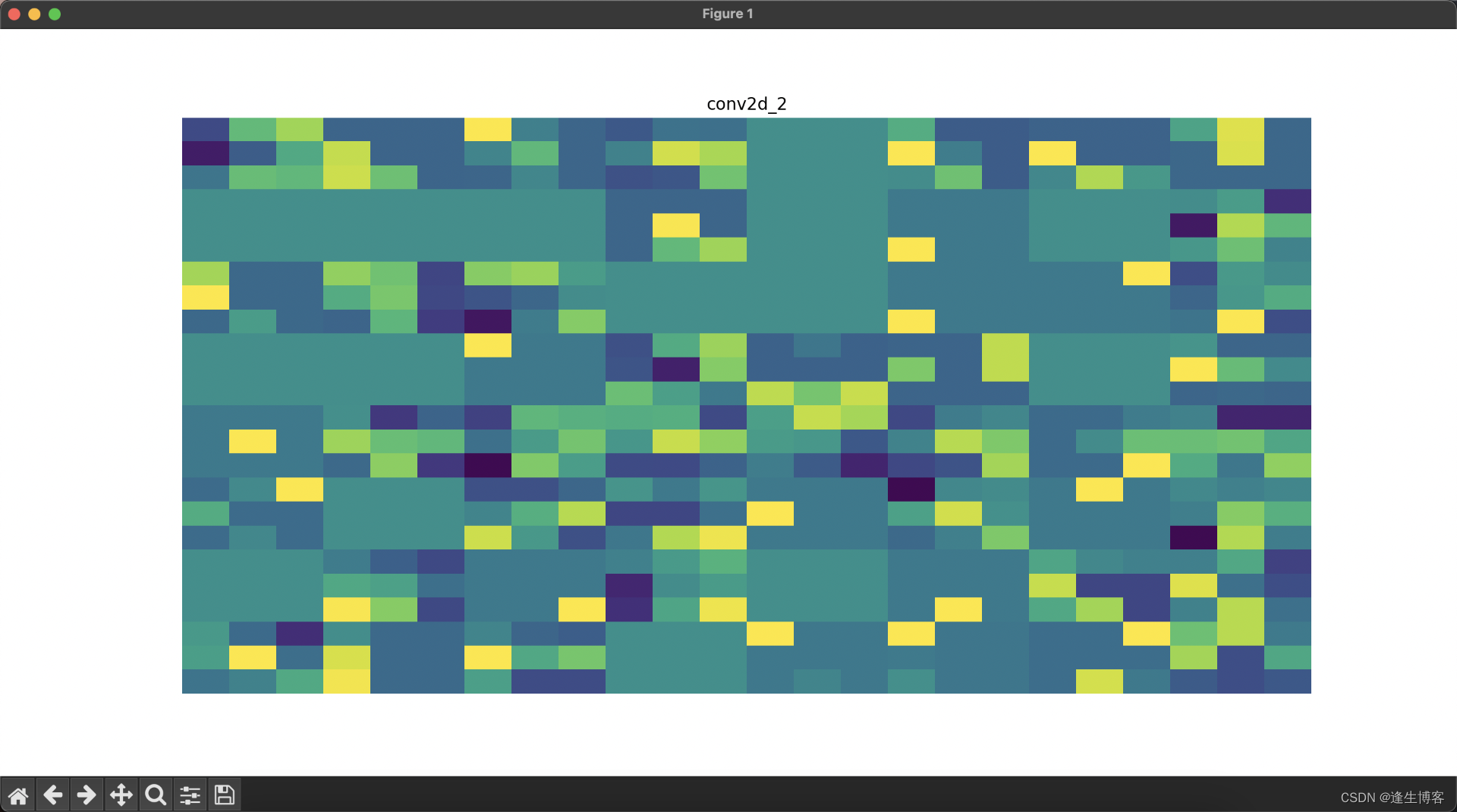
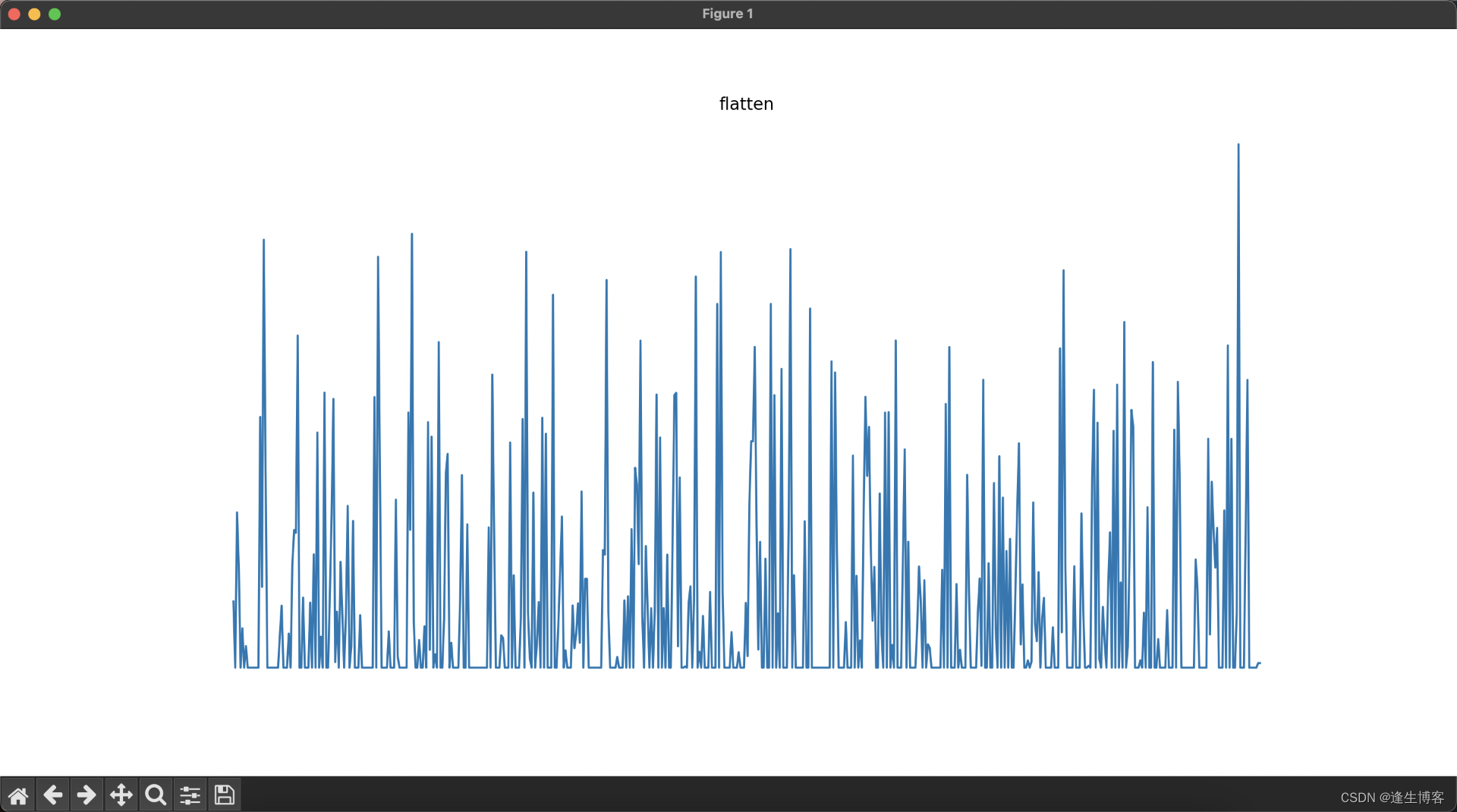

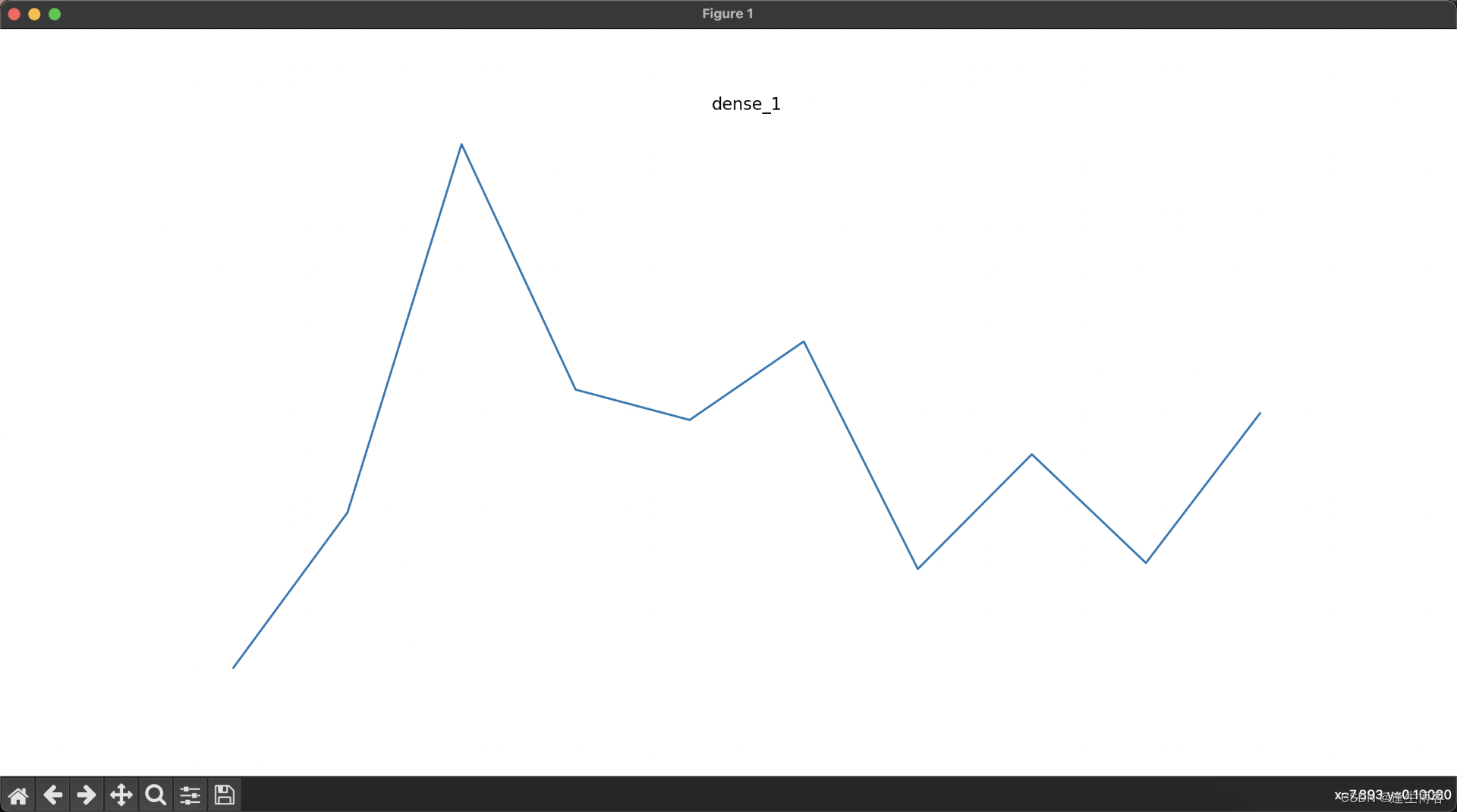
相关文章:
TensorFlow2.x基础与mnist手写数字识别示例
文章目录 Github官网文档Playground安装声明张量常量变量 张量计算张量数据类型转换张量数据维度转换ReLU 函数Softmax 函数卷积神经网络训练模型测试模型数据集保存目录显示每层网络的结果 TensorFlow 是一个开源的深度学习框架,由 Google Brain 团队开发和维护。它…...

大数据开发语言Scala入门
Scala是一种多范式编程语言,它集成了面向对象编程和函数式编程的特性。Scala运行在Java虚拟机上,并且可以与Java代码无缝交互,这使得它成为大数据处理和分析领域中非常受欢迎的语言,尤其是在使用Apache Spark这样的框架时。 Scal…...
【CDN】逆天 CDN !BootCDN 向 JS 文件中植入恶意代码
今天在调试代码,突然控制台出现了非常多报错。 这非常可疑,报错指向的域名也证实了这一点。 因为我的 HTML 中只有一个外部开源库(qrcode.min.js),因此只有可能是它出现了问题。 我翻看了请求记录,发现这…...
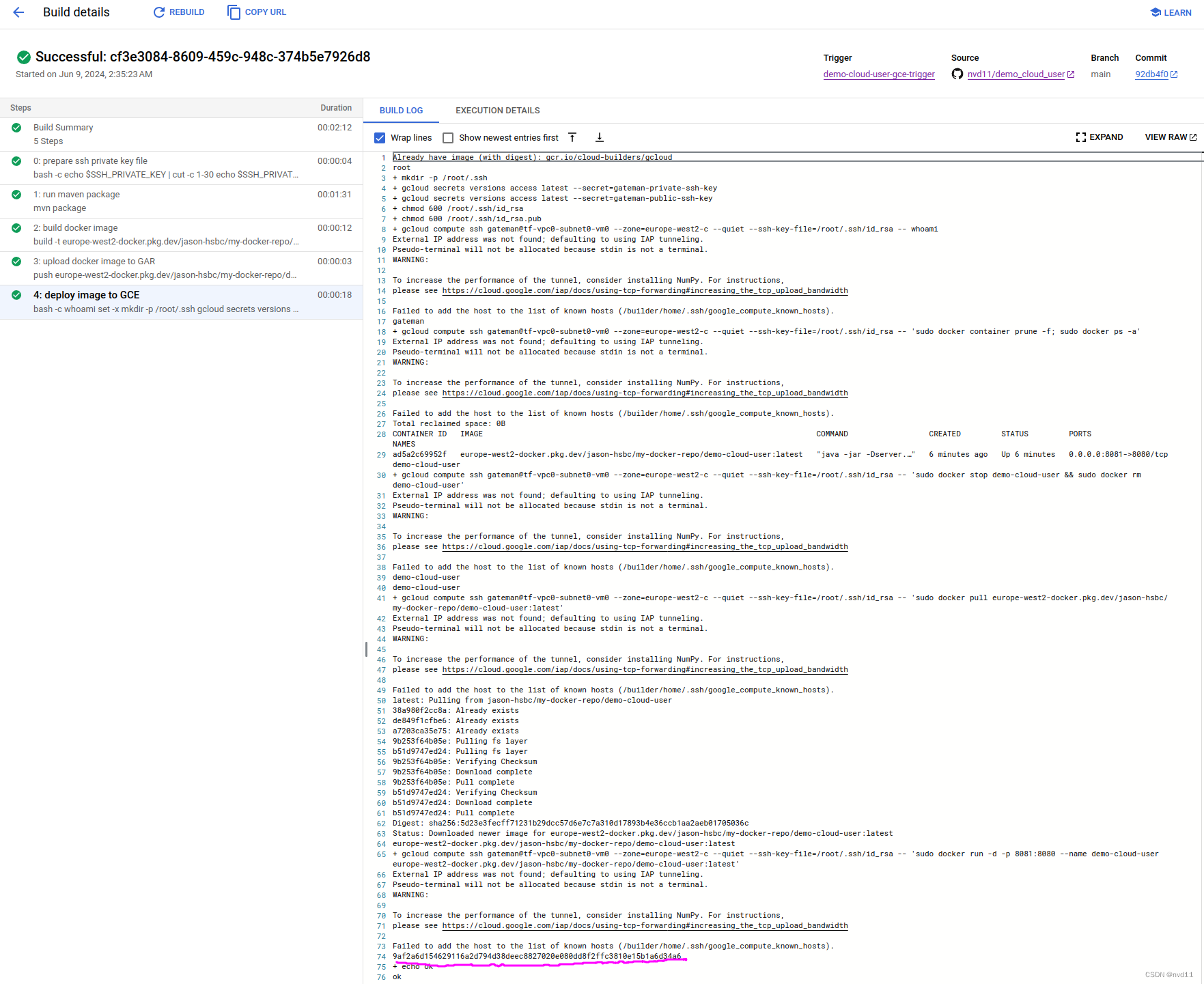
摆脱Jenkins - 使用google cloudbuild 部署 java service 到 compute engine VM
在之前 介绍 cloud build 的文章中 初探 Google 云原生的CICD - CloudBuild 已经介绍过, 用cloud build 去部署1个 spring boot service 到 cloud run 是很简单的, 因为部署cloud run 无非就是用gcloud 去部署1个 GAR 上的docker image 到cloud run 容…...

【CS.PL】Lua 编程之道: 控制结构 - 进度24%
3 初级阶段 —— 控制结构 文章目录 3 初级阶段 —— 控制结构3.1 条件语句:if、else、elseif3.2 循环语句:for、while、repeat-until3.2.1 输出所有的命令行参数3.2.2 while.lua3.2.3 repeat.lua及其作用域 🔥3.2.4 for.lua (For Statement)…...
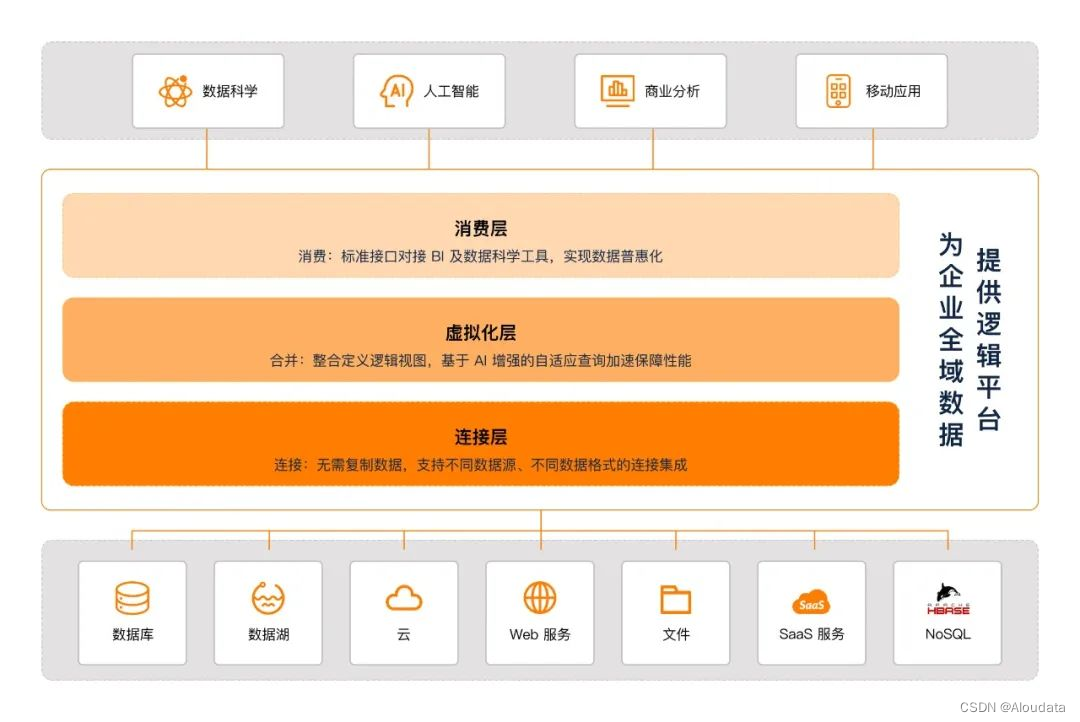
从“数据孤岛”、Data Fabric(数据编织)谈逻辑数据平台
提到逻辑数据平台,其核心在于“逻辑”,与之相对的便是“物理”。在过去,为了更好地利用和管理数据,我们通常会选择搭建数据仓库和数据湖,将所有数据物理集中起来。但随着数据量、用数需求和用数人员的持续激增…...

vuex4.x 升级pinia,router 中使用同步组件导致项目启动失败
背景描述 升级的项目本来是vue2的项目,先升级成vue3,这个过程相关的问题都被决绝,当时状态管理使用的还是vuex4.x版本。 后面发现变成复杂模块时,后续再对复杂模块的功能进行迭代时,由于js的弱类型,改动时…...
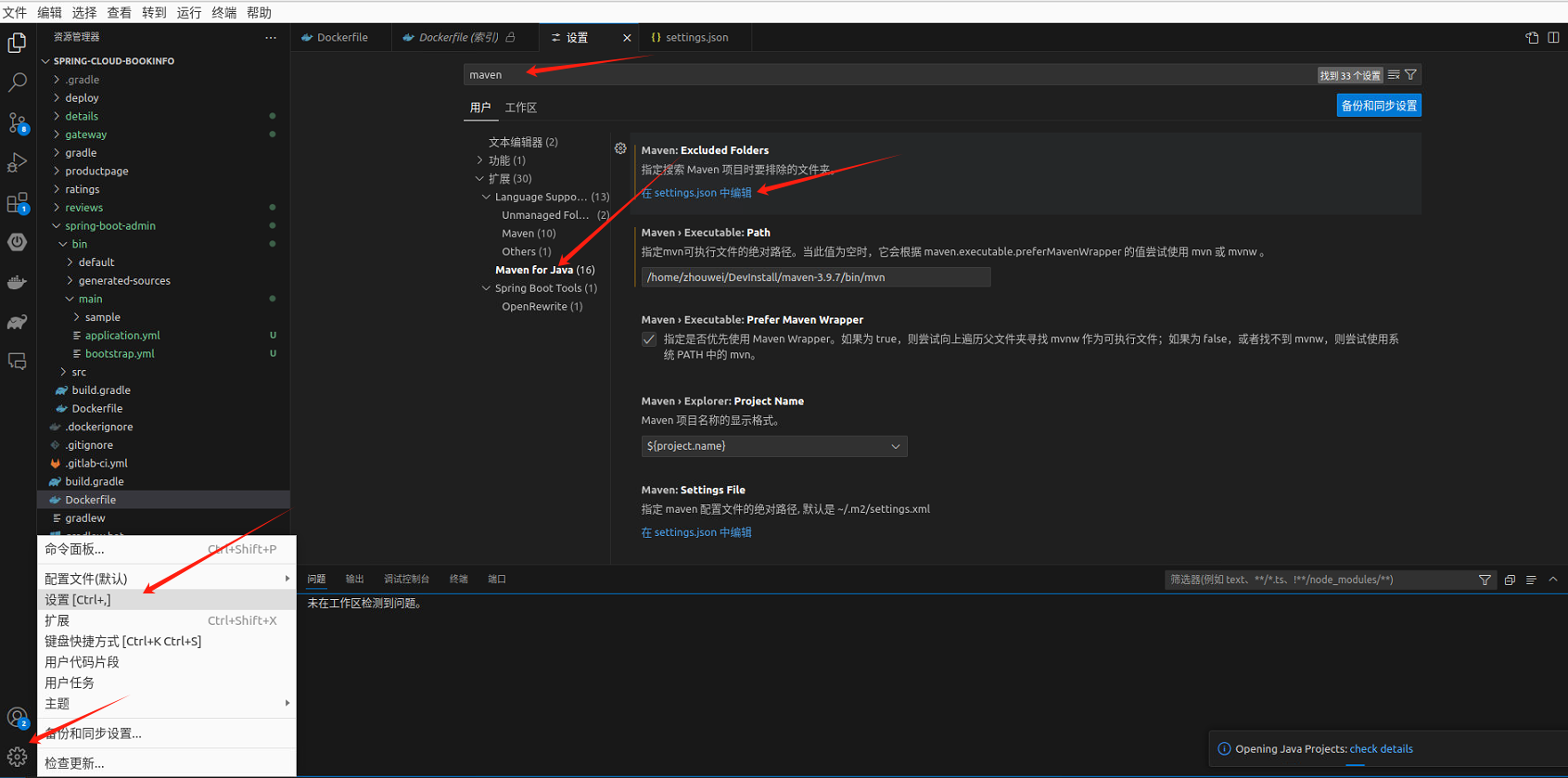
0. 云原生之基于乌班图远程开发
云原生专栏大纲 文章目录 安装乌班图配置静态IP重置root密码开启root远程登录开启远程SSH访问安装docker安装docker-compose安装Edge浏览器安装搜狗输入法安装TeamViewer安装虚拟显示器安装JDK安装maven安装vscodevscode插件安装VSCode配置maven、git、jdk、自动报错vscode快捷…...

C++ 字符串处理5-手机号邮箱如何脱敏处理
1. 关键词2. strutil.h3. strutil.cpp4. 测试代码5. 运行结果6. 源码地址 1. 关键词 关键词: C 字符串处理 分割字符串 连接字符串 跨平台 应用场景: 有些重要信息需要保密,比如手机号、邮箱等,如何在不影响用户阅读的情况下…...

【lesson8】云备份服务端完整版代码
文章目录 util.hppconfig.hpphot.hppdata.hppserver.hppserver.ccMakefilecloud.conf util.hpp #pragma once #include <iostream> #include <fstream> #include <string> #include <vector> #include <sys/stat.h> #include <unistd.h> …...

AI办公自动化:kimi批量搜索提取PDF文档中特定文本内容
工作任务:PDF文档中有资料来源这一行,比如: 资料来源:moomoo tech、The Information、Bloomberg、Reuters,浙商证券研究所 数据来源:CSDN、浙商证券研究所 数据来源:CSDN、arXiv、浙商证券研…...
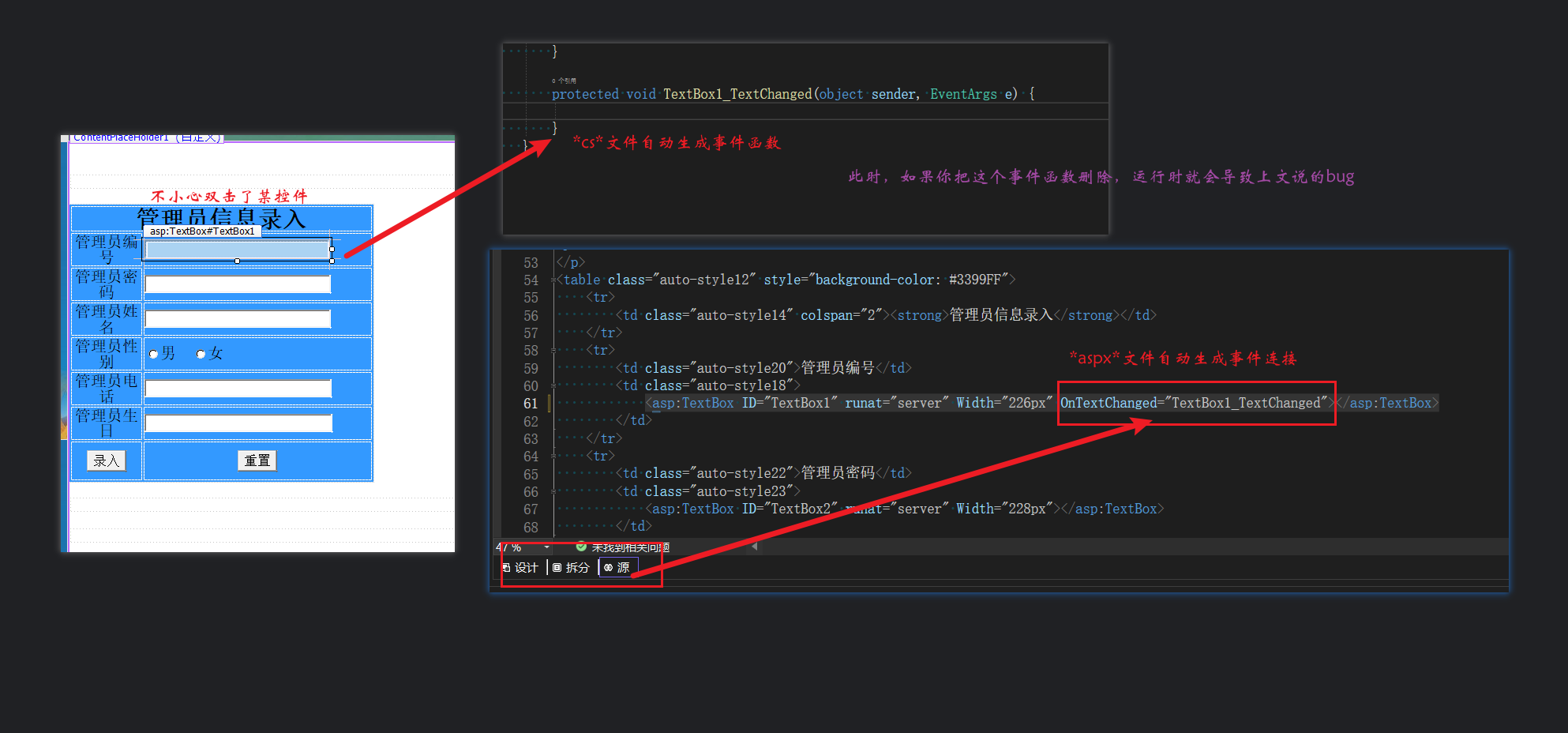
基于C#开发web网页管理系统模板流程-总集篇
第一篇 基于C#开发web网页管理系统模板流程-登录界面和主界面_c#的网页编程-CSDN博客 第二篇 基于C#开发web网页管理系统模板流程-主界面管理员录入和编辑功能完善_c#网页设计-CSDN博客 第三篇 基于C#开发web网页管理系统模板流程-主界面管理员入库和出库功能完善_c#web程序设计…...
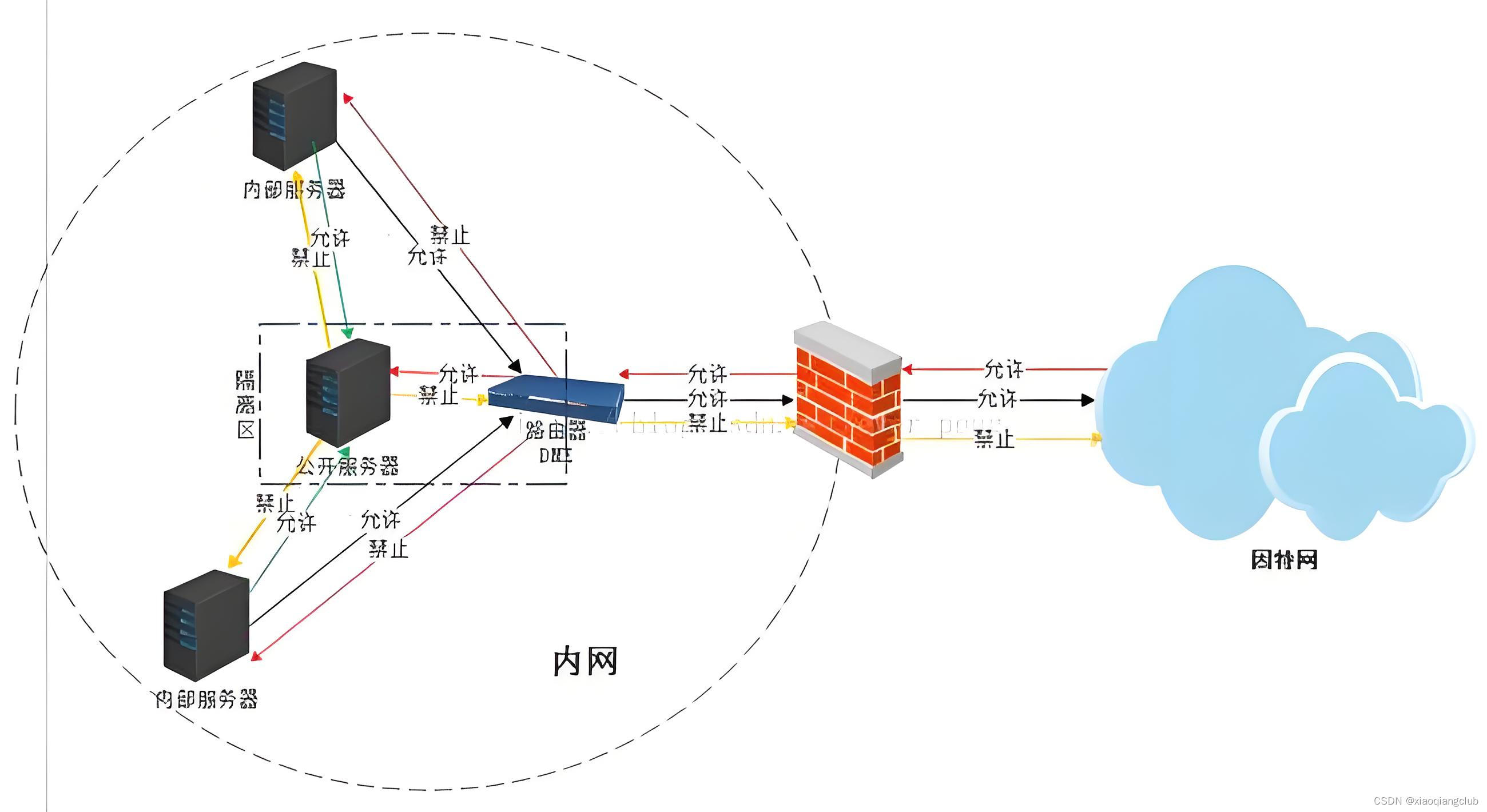
什么是DMZ?路由器上如何使用DMZ?
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 DMZ 📒🚀 DMZ的应用场景💡 路由器设置DMZ🎈 注意事项 🎈⚓️ 相关链接 ⚓️📖 介绍 📖 在网络管理中,DMZ(Demilitarized Zone,隔离区)是一个特殊的网络区域,常用于将公共访问和内部网络隔离开来。DMZ功能允许…...

【bugfix】解决Redis缓存键清理问题
前言 在Spring Boot应用中集成Redis作为缓存存储时,合理配置RedisTemplate是确保数据正确存储和检索的关键。本文将通过对比分析一段初始存在问题的Redis配置代码及其修正后的版本,探讨如何正确处理Redis键前缀,以避免清理缓存时遇到的问题。…...
泛微开发修炼之旅--15后端开发连接外部数据源,实现在ecology系统中查询其他异构系统数据库得示例和源码
文章链接:15后端开发连接外部数据源,实现在ecology系统中查询其他异构系统数据库得示例和源码...
弹幕逆向signature、a_bogus
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 本文章未经许可禁止转载&a…...

jEasyUI 使用标记创建树形菜单
jEasyUI 使用标记创建树形菜单 jEasyUI 是一个基于 jQuery 的用户界面插件库,它提供了一系列的组件,用于快速构建网页用户界面。其中,树形菜单(Tree Menu)是 jEasyUI 提供的一个非常实用的组件,它可以帮助…...

IT人的拖延——拖是因为不想离开“舒适区”?
人都是求“稳”的,在一个区域内呆了很久,也很舒适了,如果冒险离开进入未知的区域,万一结果不好怎么办?万一自己不适合怎么办?万一这个区域有着自己难以忍受的东西怎么办?这些对未知区域的恐惧感让我们在面对应该要做的事情时,不自觉地又拖延了起来。比如,我们在面临需…...
JUnit 5学习笔记
JUnit 5 学习笔记 1.JUnit5的改变2.JUnit5常用注解及测试2.1 DisplayName/Disabled/BeforeEach/AfterEach/BeforeAll/AfterAll2.2 Timeout2.3 RepeatedTest 3.断言3.1 简单断言3.2 数组断言3.3 组合断言3.4 异常断言3.5 超时断言3.6 快速失败 4.前置条件5.嵌套测试6.参数化测试…...
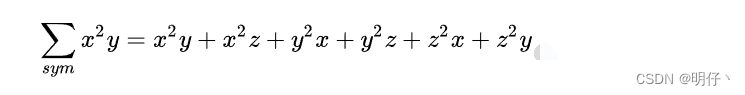
西格玛 ------ 第18个希腊字母学习
名词解释 在数学中,我们把∑作为求和符号使用,用小写字母σ,表示标准差。 ∑符号表示求和,读音为sigma,英文意思为Sum,Summation,汉语意思为“和”“总和”。 例1 公式使用说明:…...

瑞昱RTL8762CMF蓝牙5.0芯片烧录避坑指南:从MPTool配置到功耗优化实战
瑞昱RTL8762CMF蓝牙5.0芯片工程化烧录与性能调优全解析 当产品开发进入小批量试产阶段,工程师面临的核心挑战从"功能实现"转向"量产稳定性"和"性能优化"。瑞昱RTL8762CMF作为一款集成蓝牙5.0功能的低功耗芯片,其烧录配置与…...

Awesome-AITools:AI开发者必备的开源工具聚合地图
1. 项目概述:一份AI工具的“藏宝图”如果你是一名AI开发者、研究者,或者只是一个对AI工具充满好奇的探索者,那么你肯定经历过这样的时刻:面对网络上浩如烟海的AI工具,从聊天机器人、代码助手到图像生成、模型训练平台&…...

CodeGPT:基于AI的Git提交信息自动生成工具实战指南
1. 项目概述:CodeGPT,一个用Go写的AI驱动Git工具 如果你和我一样,每天都要在终端里敲无数次 git commit -m "..." ,并且为写一个清晰、规范的提交信息而绞尽脑汁,那今天分享的这个工具绝对能让你眼前一亮…...

10个无状态服务构建技巧:解锁gh_mirrors/awe/awesome-sre中的水平扩展最佳实践
10个无状态服务构建技巧:解锁gh_mirrors/awe/awesome-sre中的水平扩展最佳实践 【免费下载链接】awesome-sre A curated list of Site Reliability and Production Engineering resources. 项目地址: https://gitcode.com/gh_mirrors/awe/awesome-sre 在现代…...

一文看懂:什么是大语言模型
在过去很长一段时间里,计算机只是“执行命令的工具”。但这两年,一种新的技术正在改变这一切——它不仅能理解人类语言,还能写文章、写代码,甚至和你对话。从 ChatGPT 到 DeepSeek,再到 Claude 和 Gemini,“…...

为什么你的Windows任务栏需要一次彻底的美学革命?
为什么你的Windows任务栏需要一次彻底的美学革命? 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否曾经盯着Windows桌面…...

n8n与Claude集成指南:构建AI代码生成与自动化执行工作流
1. 项目概述与核心价值最近在折腾自动化工作流时,我偶然发现了一个名为n8n-claude-code-guide的开源项目。这个项目乍一看名字,你可能以为它只是一个简单的代码指南,但深入探究后,你会发现它实际上是一个将两个强大的工具——n8n和…...
来了!)
一句话就能“劫持”你的AI?DZS 分层式自适应提示词注入攻击的防御机制框架 (HAA)来了!
本文所展示的提示词技术已在Research square 发表论文预印本。DOI:https://doi.org/10.21203/rs.3.rs-9653510/v1 作者“抖知书(douzhishu),涉及到相关测试数据是本人自行测试的,并未通过多专家评审,所以仅…...
)
从‘古董’到统一:聊聊Linux内核中buffer与cache合并背后的那些事儿(附free命令实战)
从‘古董’到统一:Linux内核中buffer与cache合并背后的设计哲学 在Linux系统的性能优化领域,free命令的输出一直是开发者关注的焦点。当你键入free -h时,那行看似简单的"buff/cache"统计背后,隐藏着一段跨越二十年的内…...

【DeepSeek安全防护权威指南】:20年攻防专家亲授Prompt注入3大高危场景与7层防御体系
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Prompt注入防护的演进与现状 随着 DeepSeek 系列大模型在企业级场景中的深度部署,Prompt 注入攻击已从理论威胁演变为高频真实风险。早期防护策略依赖于简单的关键词过滤和长度截断…...