集合面试题
目录
- ①HashMap的理解?以及为什么要把链表转换为红黑树?
- ②HashMap的put?
- ③HashMap的扩容?
- ④加载因子为什么是0.75?
- ⑤modcount的作用?
- ⑥HashMap与HashTable的区别?
- ⑥HashMap中1.7和1.8的区别?
- ⑦HashMap与ConcurrentHashMap的区别?
- ⑧ArrayList和LinkedList的区别?

ArrayList:底层是数组,并且线程不安全。初始大小为0,第一次add的时候扩容(扩容使用grow()方法)为10,再次扩容则为1.5倍。
Vector:底层也是数组,但是线程安全,因为其方法被synchronized修饰。
LinkedList:底层是双向链表,增加删除效率高,查效率低要遍历链表。
HashSet:底层其实是HashMap,即数组+链表+红黑树。
TreeSet:底层是TreeMap。
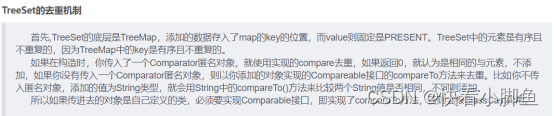

①HashMap的理解?以及为什么要把链表转换为红黑树?
答:HashMap是双列集合中存放以k-v键值对(并且支持null)的一种集合类型,其底层在jdk1.7之前为数组+链表,在jdk1.8引入了红黑树,底层实现就变成了链表+数组+红黑树(当链表的长度大于8并且数组的长度大于64时链表就会树化为红黑树)。并且HashMap的底层采用链地址法来解决哈希冲突。引入红黑树的原因:链表长度变长就会导致查找的效率降低,将链表转换为红黑树可以加快查询效率。因为链表查询时间复杂度是O(n),而红黑树的查询时间复杂度是O(log n)。(如果数据直接在数组上时间复杂度就是O(1))
②HashMap的put?
①构造器:HashMap初始化时,就只设置了一下加载因子(0.75)

②put方法:
第一步:首先通过hash()方法去计算出哈希值
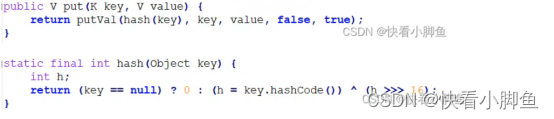
第二步:判断table是否为空,为空就调用resize()方法去创建一个初始大小为16的table
第三步:然后根据数组长度和哈希值得到索引位置,再判断这个位置是否为空,如果为空就创建一个Node然后放进去
![]()
第四步:如果不为空,则去判断其hash值和Key是否相同,如果都是相同的,就会将其value替换掉

第五步:如果比较出key不相同,则去链表上循环比较,直到找到有相同的hash值和key,替换掉就退出,如果整个链表上都没有的话,就会在链表的尾部插入,加入后就会判断是否要扩容还是树化。

③HashMap的扩容?

答:首先hashmap在创建的时候是一个空的,然后在第一次put的时候去检查到table为空,就调用resize()方法给扩容到初始大小16。
然后一直添加数据,当发现链表的长度大于8的时候,就会调用treeifBin()方法去树化,不是直接树化,而是还要先判断数组的长度是否大于64,如果没有的话就还是先会调用resize()去扩容数组为2倍的长度,直到判断出链表长度大于8并且数组长度大于64时,才会把链表转换为红黑树,再添加数据进去。
④加载因子为什么是0.75?
答:首先加载因子是表示hashmap的扩容阈值,当元素数量到达数组长度的0.75就会发生扩容。0.75是默认的加载因子,我们也可以设置成自己想要的值,为什么0.75,首先加载因子的选择是一种权衡,如果加载因子较小,就到导致频繁的扩容发生,导致哈希表的填充度较低,可能会浪费空间。如果加载因子较大虽然减少了扩容的频率,也会导致更多的哈希冲突的发生,导致链表的长度增加,从而影响性能。所以默认的0.75在大多数情况下能够提供较好的性能和空间利用率。所以官方文档中有一段话说明了0.75提供了一个时间复杂度和空间复杂度的一个折中点。
⑤modcount的作用?
答:首先modcount是用来记录被修改的次数。每次put或者remove都会使其加一。这个字段一般是用来实现快速失败(fast-fail)和保证数据一致性的,比如说一个线程在对集合进行遍历的时候会首先把modcount放到一个expectedmodcount中,然后遍历的时候会去比较当前的modcount和expectedmodcount,此时如果当另外一个线程去修改或者删除了集合元素时,会使modcount+1,然后该线程就会发现此时有并发修改的发生,就会抛出一个并发修改的异常,这样去避免数据不一致和错误的情况。
⑥HashMap与HashTable的区别?
答:其都是map下的集合,都是存储k-v键值对的。区别在于
①首先HashMap是线程不安全的,HashTable则是线程安全的,因为其所有的方法都加了synchronized关键字,但是这样导致了性能大大降低所以HashMap的效率要比HashTable快。
②HashTable底层是基于数组+链表实现的,而HashMap在jdk1.7时是数组+链表,但在jdk1.8的时候引入了红黑树,在链表长度大于8并且数组长度大于64时,链表会转换为红黑树。
③HashMap的默认初始大小为16,扩容容量为2倍,而HashTable默认初始大小为11,扩容容量为2n+1。
④HashMap可以null作为键值,但是null键只能有一个,而Hashtable不行。 而且像现在不推荐使用HashTable
⑥HashMap中1.7和1.8的区别?
答:①首先底层结构,1.7是数组加链表,1.8是数组+链表+红黑树。提高了插入和查询的效率。
②插入数据的方式:1.7是头插法,1.8是尾插法。
③1.7中哈希算法比较复杂,为了提高Key的散列性,存在各种右移和异或运算,而1.8引入了红黑树,简化了哈希算法,节省CPU资源。
⑦HashMap与ConcurrentHashMap的区别?
答:首先二者都是以k-v键值对存储数据的集合。其区别在于:
①HashMap是线程不安全的,ConcurrentHashMap是JUC下的是线程安全的,在jdk1.7的时候是通过分段锁来实现的线程安全,jdk1.8则是用Synchronized和CAS以及volatile来保证了线程的安全。
②HashMap允许以null作为键值,而ConcurrentHashMap不允许,因为要避免空值在多线程并发场景下的歧义问题,即如果一个线程读到了一个null的数据,无法判断其是空值还是不存在。
③ConcurrentHashMap支持协助扩容,而HashMap扩容时需要暂停其他操作。 ④迭代:HashMap迭代器因为有modcount的使用导致其他线程修改或删除时,遍历失败,而ConcurrentHashMap则提供了安全的迭代器。
⑧ArrayList和LinkedList的区别?
答:首先他们都是实现了List接口的集合。主要区别在于:
①数据结构:ArrayList是数组实现的,而LinkedList是双向链表实现的。
②访问效率:ArrayList的访问效率比LinkedList快。ArrayList的访问的时间复杂度是O(1)可以通过下标直接定位,而LinkedList访问的时间复杂度是O(n),只能通过遍历链表去找到。
③增加和删除:LinkedList的增加和删除的效率要比ArrayList快。因为LinkedList只要去修改前后元素的指针即可,而ArrayList要移动插入点或者删除点后面的元素位置。
④空间占用:LinkedList的占用空间比ArrayList大,因为LinkedList的每个节点不仅要保存数据吗,还要保存前后元素的指针。
相关文章:
集合面试题
目录 ①HashMap的理解?以及为什么要把链表转换为红黑树?②HashMap的put?③HashMap的扩容?④加载因子为什么是0.75?⑤modcount的作用?⑥HashMap与HashTable的区别?⑥HashMap中1.7和1.8的区别&am…...
集成学习概述
概述 集成学习(Ensemble learning)就是将多个机器学习模型组合起来,共同工作以达到优化算法的目的。具体来讲,集成学习可以通过多个学习器相结合,来获得比单一学习器更优越的泛化性能。集成学习的一般步骤为:1.生产一组“个体学习…...

记录一次root过程
设备: Redmi k40s 第一步, 解锁BL(会重置手机系统!!!所有数据都会没有!!!) 由于更新了澎湃OS系统, 解锁BL很麻烦, 需要社区5级以上还要答题。 但是,这个手机…...

函数(上)(C语言)
函数(上) 一. 函数的概念二. 函数的使用1. 库函数和自定义函数(1) 库函数(2) 自定义函数的形式 2. 形参和实参3. return语句4. 数组做函数参数 一. 函数的概念 数学中我们其实就见过函数的概念,比如:一次函数ykxb,k和b都是常数&a…...
系统架构之系统安全能力的侧信道抵御)
ARM-V9 RME(Realm Management Extension)系统架构之系统安全能力的侧信道抵御
安全之安全(security)博客目录导读 目录 一、系统PMU计数器 二、使用信号和功耗操作进行的故障攻击 一、系统PMU计数器 性能监测单元 (PMU) 计数器可能成为泄露机密信息的侧信道,如访问模式或受RME安全保障保护的安全状态下的执行控制流。以下规则补充了《Arm CoreSight™…...
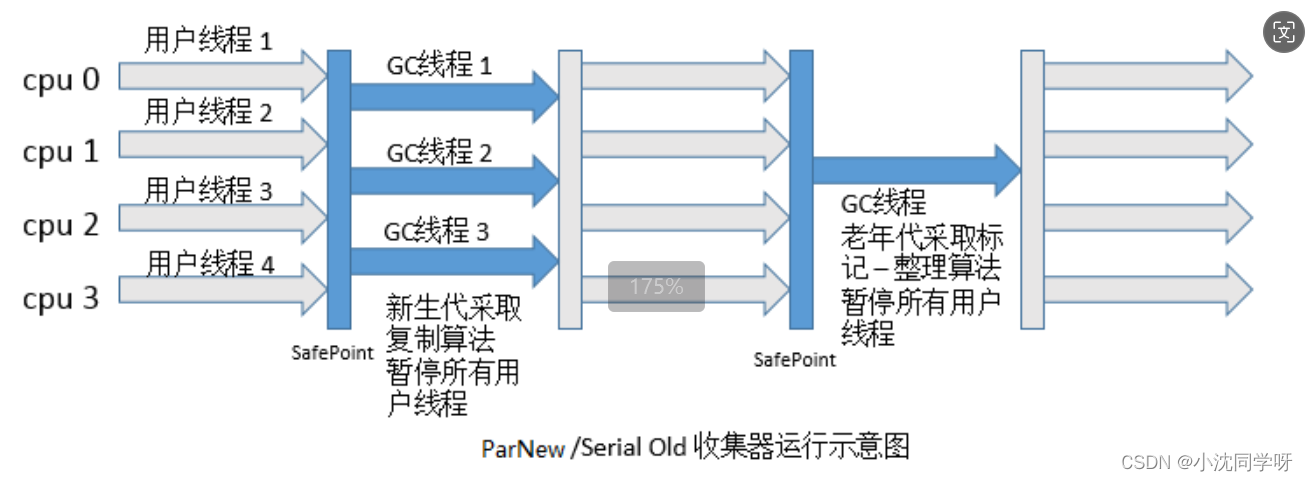
Java高级技术探索:深入理解JVM内存分区与GC机制
文章目录 引言JVM内存分区概览垃圾回收机制(GC)GC算法基础常见垃圾回收器ParNew /Serial old 收集器运行示意图 优化实践结语 引言 Java作为一门广泛应用于企业级开发的编程语言,其背后的Java虚拟机(JVM)扮演着至关重…...

新视野大学英语2 词组 6.15
do you feel as confused and manipulated as i do with this question 你是否和我一样,对这个问题感到困惑和被操控 manipulated:被操控 defy common sense and contradict each other 违背常识且相互矛盾 defy:违背 contradict…...

【JavaScript】MDN
一、初识 1.1 基础 1.1.1 语言速成课 1.1.1.1 变量 变量是存储值的容器。首先用let关键字声明一个变量,后面跟着你给变量的名字 变量命名区分大小写 分号在JavaScript中是用来分隔语句的,但是如果语句后面有一个换行符(或者在{block}中只…...

Qt/C++中的异步编程
Qt/C++中的异步编程 1 介绍2 含义2.1 QtConcurrent2.2 std::future2.3 Qml中的Promise3 使用场景4 代码示例5 注意事项5.1异常处理5.2 线程安全5.3 性能优化5.4 线程间通信5.5 避免死锁1 介绍 异步编程是现代应用程序开发中不可或缺的一部分。它允许程序在执行耗时任务时保持响…...

解决javadoc一直找不到路径的问题
解决javadoc一直找不到路径的问题 出现以上问题就是我们在下载jdk的时候一些运行程序安装在C:\Program Files\Common Files\Oracle\Java\javapath下: 一开始是没有javadoc.exe文件的,我们只需要从jdk的bin目录下找到复制到这个里面,就可以使用…...

存储器的性能指标以及层次化存储器
存储器的性能指标 存储器有三个性能指标:速度、容量和位价(每位价格) 1.存储速度 (1)存取时间 想衡量存储速度,最直观的指标就是完成一次存储器读写操作所需要的时间,这叫做存取时间&#x…...

【C++】C++入门的杂碎知识点
思维导图大纲: namespac命名空间 什么是namespace命名空间namespace命名空间有什么用 什么是命名空间 namespace命名空间是一种域,它可以将内部的成员隔绝起来。举个例子,我们都知道有全局变量和局部变量,全局变量存在于全局域…...

springboot 整合redis问题,缓存击穿,穿透,雪崩,分布式锁
boot整合redis 压力测试出现失败 解决方案 排除lettuce 使用jedis <!-- 引入redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclus…...
免费个人站 独立站 wordpress 自建网站
制作免费网站 | 免费网站构建器 | WordPress.com https://bioinformatics7.wordpress.com WordPress.com...

散列函数的基本概念
散列函数 算法不能设计太过复杂 太复杂的散列函数,势必会消耗很多计算时间 散列函数生成的值要尽可能随机并且均匀分布 这样才能避免或者最小化散列冲突而且即便出现来冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多…...

【C++拷贝构造函数深浅拷贝】
拷贝构造函数 注意:访问权限是public 拷贝构造函数:类名(const 类名& 对象名){} 可以有多个参数 。 没有常引用就是普通构造函数 如果不写,编译器自己会给一个(作用仅仅是赋值,默认拷…...

快速编译安装tensorrt_yolo
快速编译安装 安装 tensorrt_yolo 通过 PyPI 安装 tensorrt_yolo 模块,您只需执行以下命令即可: pip install -U tensorrt_yolo 如果您希望获取最新的开发版本或者为项目做出贡献,可以按照以下步骤从 GitHub 克隆代码库并安装: …...

外盘黄金期货需要注意什么?
为大家整理了关于黄金做单的五大原则,相信对于新手投资者来说肯定会产生一定的帮助。 1、看多空:主要有两种方法,基本面判断和技术面判断,基本面判断,主要是借助基本信息面,如政策。供需,产量…...

Allegro光绘Gerber文件、IPC网表、坐标文件、装配PDF文件导出打包
Allegro光绘Gerber文件、IPC网表、坐标文件、装配PDF文件导出打包 一、Gerber文件层叠与参数设置二、装配图文件设置导出三、光绘参数设置四、Gerber孔符图、钻孔表及钻孔文件输出五、输出Gerber文件六、输出IPC网表七、导出坐标文件八、文件打包 一、Gerber文件层叠与参数设置…...

mysql的索引可以分为哪些类型
MySQL的索引是用于提高查询性能的重要数据结构。不同类型的索引在不同的使用场景中具有不同的优势和适用性。 1. 主键索引(Primary Key Index) 特点:唯一且不允许 NULL 值。用途:唯一标识表中的每一行。自动创建:定义…...

企业AI转型的底层逻辑与路径选择
文章核心内容围绕企业如何实现AI原生转型展开。首先,强调AI转型重点在于如何实现“AI原生”,而非简单叠加AI功能。其次,提出AI产品应超越对话框,实现隐形化与自动化,并成为记录系统。再次,建议企业技术路径…...

本地AI网关实战:统一管理多模型服务,实现智能路由与成本控制
1. 项目概述:一个本地化的AI网关如果你正在同时使用多个AI模型服务商,比如OpenAI、Anthropic、Google Gemini,或者还在本地运行着Ollama、vLLM这样的模型,那你一定体会过那种切换的繁琐。每个客户端、每个脚本都要配置不同的API密…...

Herc.ai:一站式AI API网关,统一调用GPT-4、Gemini等主流模型
1. 项目概述:Herc.ai,一个面向开发者的全能AI API网关如果你正在寻找一个能让你在项目中轻松集成GPT-4、Gemini、DALL-E、Flux等主流AI模型,同时又不想被单一供应商绑定、不想处理复杂的多API密钥管理、并且希望有一个统一的、开发者友好的接…...
中文翻译项目:打破语言壁垒,赋能中文AI社区)
AI技能(SKILL)中文翻译项目:打破语言壁垒,赋能中文AI社区
1. 项目概述:一个为中文AI社区“破壁”的翻译工程如果你和我一样,在过去一年里深度使用过Claude、ChatGPT或者各类AI Agent平台,那你一定对“SKILL”这个概念不陌生。简单来说,SKILL就是AI的“技能包”,它把特定领域的…...

[具身智能-680]:ROS2 可视化与调试工具与示例
按日常开发必用分类,每条可直接复制运行,新手也能马上上手。一、3D 可视化工具1. rviz2(核心 3D 可视化)功能查看:机器人模型、激光雷达、点云、地图、TF 坐标、导航路径、相机图像、机械臂、代价地图等。启动bash运行…...

大核小核架构的演进:从DVFS到异构计算,应对先进制程挑战
1. 项目概述:大核小核架构的十字路口在移动计算和嵌入式领域,ARM的“大核小核”(big.LITTLE)架构在过去十年里几乎成了高性能低功耗的代名词。从智能手机到平板电脑,再到如今的物联网边缘设备,这套将高性能…...
)
手把手教你用STM32和电位器,临时搭建一个TTL转485调试器(附电路图)
应急调试利器:用STM32和电位器快速搭建TTL转485监听器 在嵌入式开发现场调试时,最让人头疼的莫过于设备串口输出异常却找不到合适的调试工具。上周在客户工厂就遇到了这样的窘境——需要监控设备TTL串口数据,但手边只有RS485转换器和几根杜邦…...

【Portal实战指南】STEP 7 Basic许可证丢失排查与一键修复
1. 问题现象与紧急处理 当你满心欢喜地打开TIA Portal准备开始一天的工作,突然弹出一个令人窒息的提示框:"找不到许可证STEP 7 Basic"。这种情况我遇到过不下十次,每次都能让工程师血压瞬间飙升。别慌,我们先来快速判断…...

3种方法打造企业级Windows Syslog监控系统
3种方法打造企业级Windows Syslog监控系统 【免费下载链接】visualsyslog Syslog Server for Windows with a graphical user interface 项目地址: https://gitcode.com/gh_mirrors/vi/visualsyslog 你是否曾因网络设备日志分散而难以定位故障?当路由器、防火…...

FanControl风扇识别故障排查指南:从零开始解决“风扇隐身“问题
FanControl风扇识别故障排查指南:从零开始解决"风扇隐身"问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/G…...