Elasticsearch:简化数据流的数据生命周期管理
作者:来自 Elastic Andrei Dan

今天,我们将探索 Elasticsearch 针对数据流的新数据管理系统:数据流生命周期,从版本 8.14 开始提供。凭借其简单而强大的执行模型,数据流生命周期可让n 你专注于数据生命周期的业务相关方面,例如降采样和保留。在后台,它会自动确保存储数据的 Elasticsearch 结构得到有效管理。
Elasticsearch 中的数据生命周期管理演变
自 6.x Elasticsearch 系列以来,索引生命周期管理 (index lifecycle management - ILM) 已使用户能够通过自动在层之间迁移数据来维护健康的索引并节省成本。
ILM 根据索引独特的性能、弹性和保留需求来处理索引,同时提供对成本的显着控制并详细定义索引的生命周期。
ILM 是一种非常通用的解决方案,可满足广泛的用例,从时间序列索引和数据流到存储文本内容的索引。对于所有这些用例,生命周期定义将非常不同,当我们考虑每个单独部署的可用硬件和数据分层资源时,它会变得更加不同。因此,ILM 允许完全可定制的生命周期定义,但代价是复杂性(精确的滚动定义;何时强制合并、收缩和(部分)挂载索引)。
当我们开始研究无服务器(serverless)解决方案时,我们有机会通过新的视角来审视生命周期管理,我们的用户可以(并且将)免受 Elasticsearch 内部概念(如分片、分配或集群拓扑)的影响。更重要的是,在无服务器中,我们希望能够根据需要更改内部 Elasticsearch 配置,以保持用户的最佳体验。
在这种新情况下,我们研究了现有的 ILM 解决方案,该解决方案为用户提供了内部 Elasticsearch 概念作为构建块,并决定我们需要一个新的解决方案来管理数据的生命周期。
我们吸取了从大规模构建和维护 ILM 中吸取的经验教训,并为未来创建了一个更简单的生命周期管理系统。该系统更具体,仅适用于数据流(data streams)。它直接在数据流上配置为属性(类似于索引设置属于索引的方式),我们称之为数据流生命周期。它是一种内置机制(继续使用索引设置类比),始终处于开启状态,并且始终对数据流的生命周期需求做出反应。
通过将适用范围限定在数据流(即带有很少更新的时间戳的数据),我们能够避免自定义,转而使用易用性和自动默认值。数据流生命周期将自动执行数据结构维护操作,如滚动和强制合并,并允许你仅处理你应该关心的业务相关生命周期功能,例如降采样(downsampling)和数据保留(data retention)。
数据流生命周期的功能不如 ILM 丰富;最值得注意的是,它目前不支持数据分层、缩减或可搜索快照。但是,不需要这些特定功能的用例将更好地由数据流生命周期服务。
虽然数据流生命周期最初是为无服务器环境的需求而设计的,但它们也可用于常规本地和 ESS Elasticsearch 部署。
配置数据流生命周期
让我们创建一个 Elasticsearch Serverless 项目,并开始创建由数据流生命周期管理的数据流。
创建项目后,转到索引管理并为 my-data-* 索引模式创建索引模板并配置 30 天的保留期:

让我们浏览这些步骤并完成此索引模板(我在映射部分配置了一个文本字段,但这是可选的):
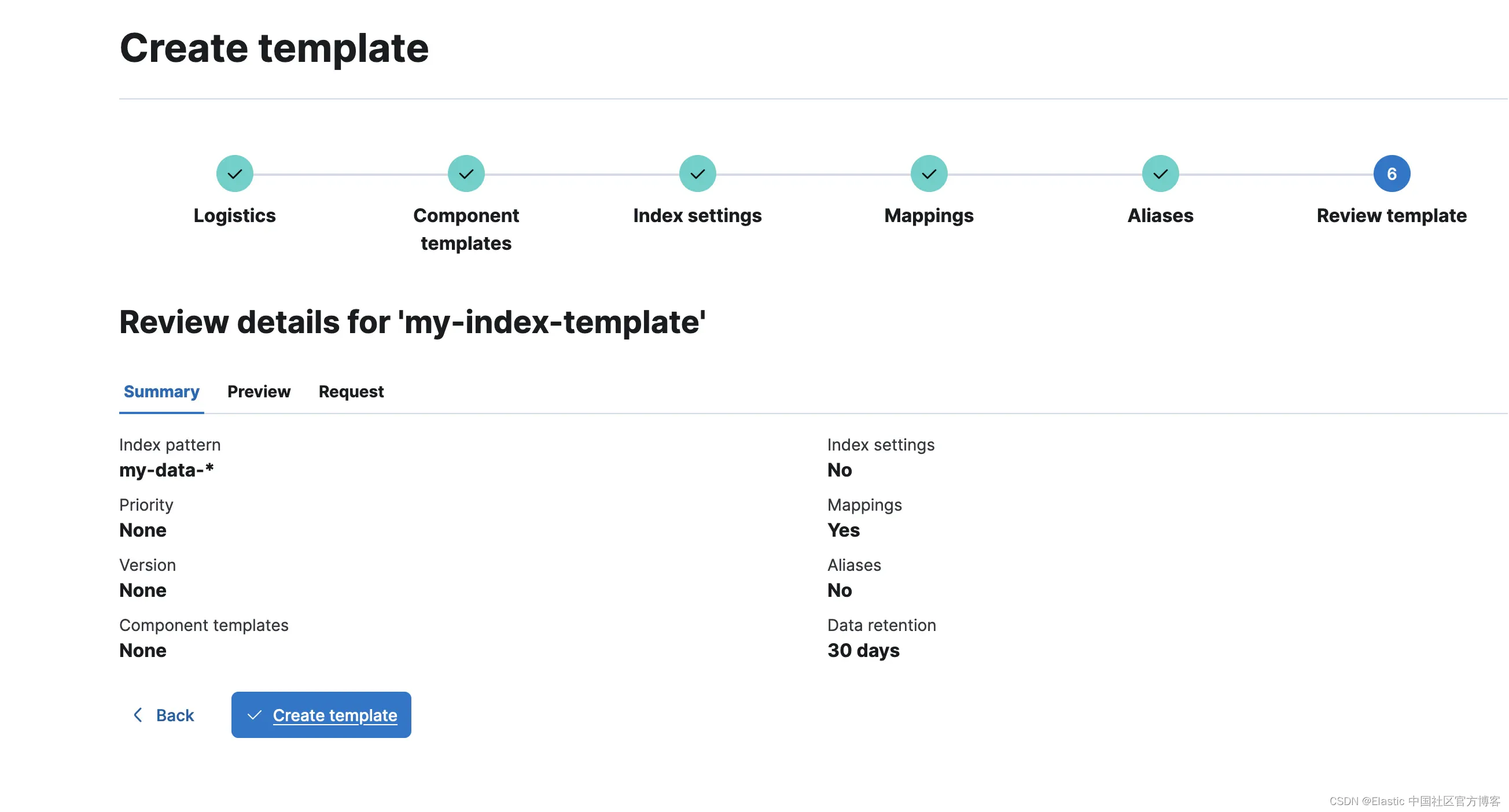
现在,我们将提取一些以 my-data-stream 命名空间为目标的数据。我将使用左侧的 Dev Tools 部分,但你也可以选择自己喜欢的数据提取方式:

my-data-stream 现已创建,它包含 2 个文档。让我们转到 Index Management/Data Streams 并检查一下:

就这样!🎉 我们的数据流由数据流生命周期管理,数据保留期配置为 30 天。所有与 my-data-* 模式匹配的新数据流都将由数据流管理,并获得 30 天的数据保留期。
更新已配置的生命周期
数据流生命周期属性属于数据流。因此,我们可以通过直接导航到数据流来配置更新现有数据流的生命周期。让我们转到索引管理/数据流并将 my-data-stream 的保留期编辑为 7 天:
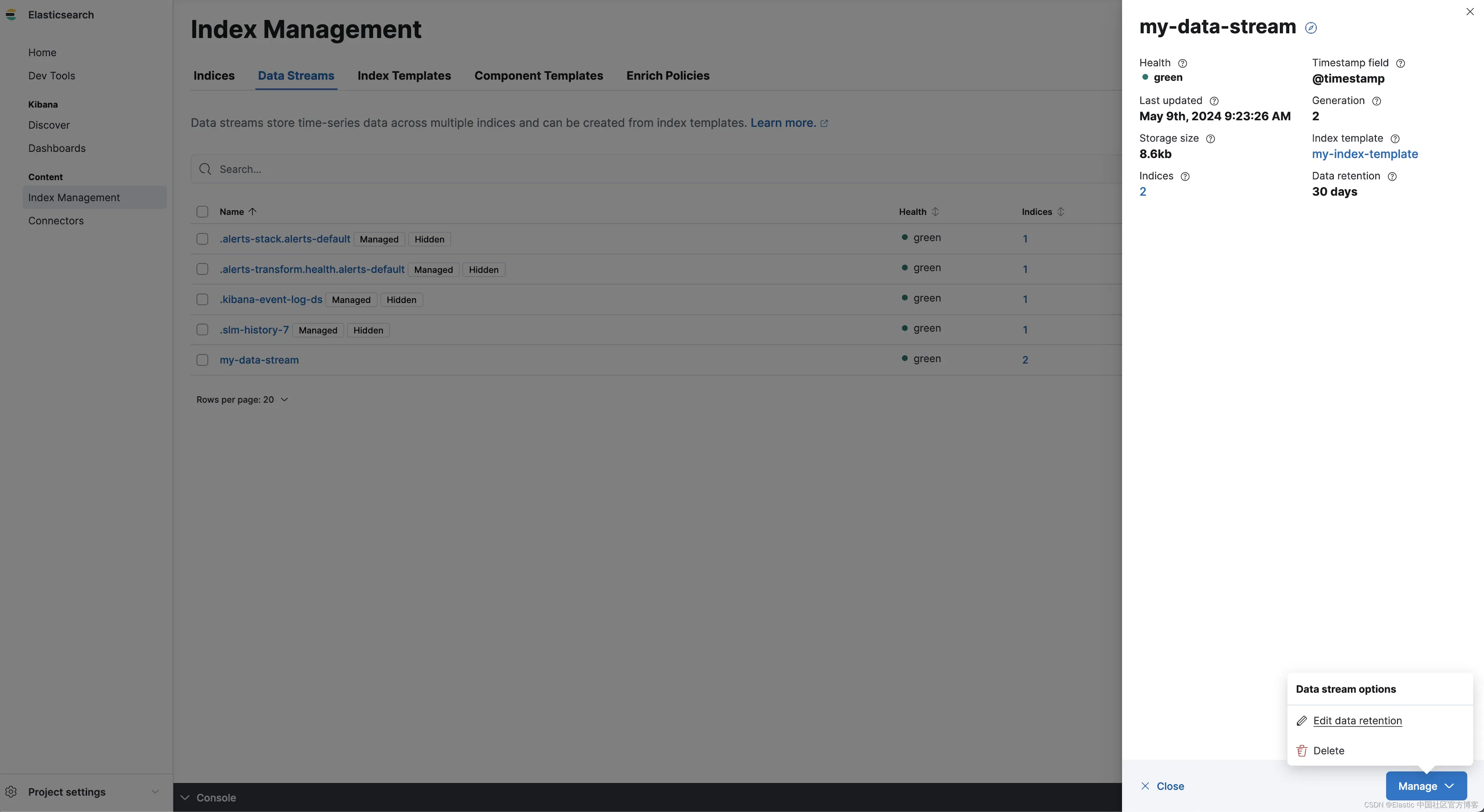

我们现在看到我们的数据流的数据保留期为 7 天:
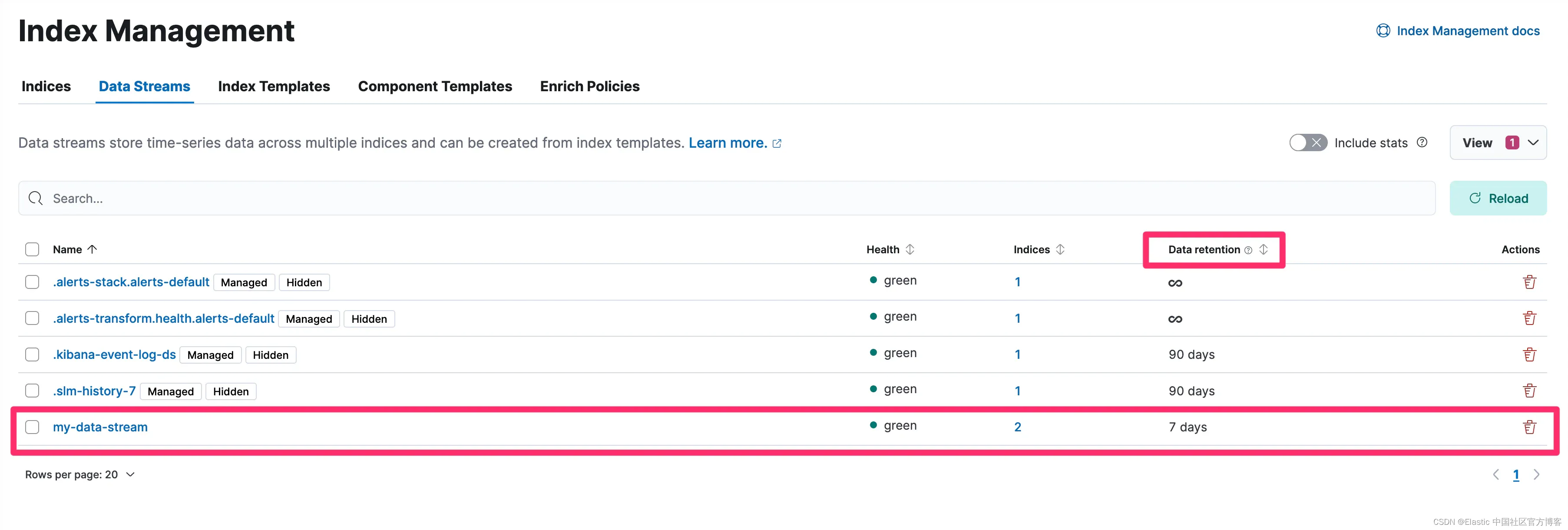
现在系统中现有数据流已配置所需的 7 天保留期,我们还要更新索引模板保留,以便创建的新数据流也能获得 7 天的保留期:


实施细节
主节点定期(根据 data_streams.lifecycle.poll_interval 设置,默认情况下每 5 分钟一次)迭代系统中配置为由生命周期管理的数据流。在每次迭代中,系统中的每个后备索引状态都会被评估,并执行一个操作以实现配置的生命周期所描述的目标状态。
对于每个管理的数据流,我们首先尝试根据 cluster.lifecycle.default.rollover 条件滚动数据流。这是对数据流的写入索引尝试的唯一操作。
滚动后,前一个写入索引将有资格进行合并。由于我们希望分片维护任务的合并是我们自动执行的,因此我们实施了一个更轻量的合并操作,这是强制合并到 1 个段的替代方法,它只合并小段的长尾(long tail)而不是整个分片。这种方法的主要好处是它可以在滚动后自动和尽早应用。
合并后备索引后,在下一次生命周期执行运行时,索引将被降采样。
完成所有计划的降采样轮次后,每次生命周期运行时,都会检查后备索引是否符合数据保留条件。当指定的数据保留期过后(自滚动时间起),后备索引将被删除。
降采样和数据保留都是基于时间的操作(例如 data_retention: 7d),并且是从索引滚动以来计算的。索引滚动以来的时间在 explain lifecycle API 中可见,我们称之为generation_time,表示后备索引成为世代索引(而不是数据流的写入索引)以来的时间。
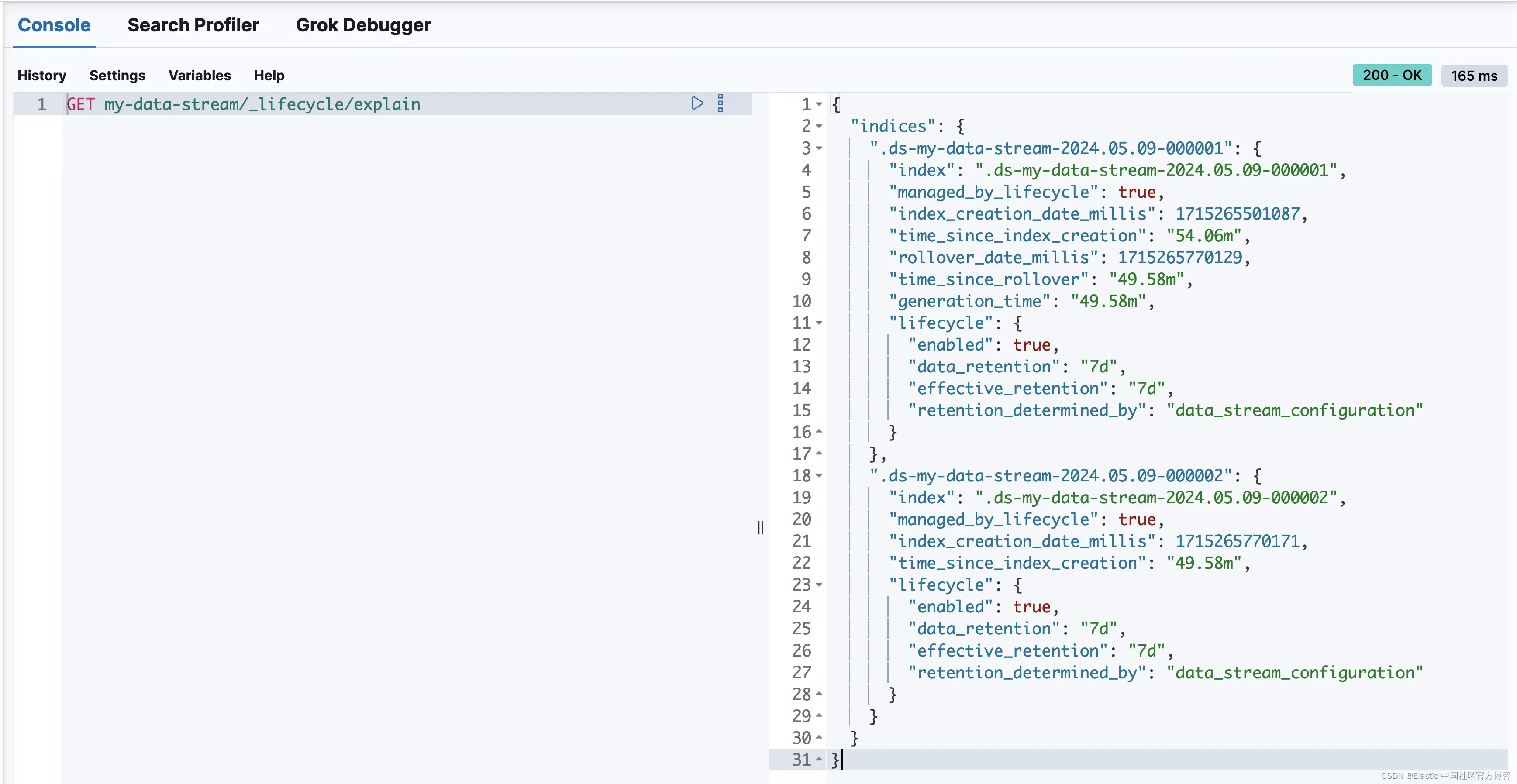
我已经运行了 my-data-stream(在轮转时有 2 个后备索引)的 explain lifecycle API,以深入了解
我们可以看到两个索引的 lifecycle 定义都包括 7 天的更新数据保留期。
较旧的索引 .ds-my-data-stream-2024.05.09-000001 不再是数据流的写入索引,我们可以看到解释 API 将 generation_time 报告为 49 分钟。一旦生成时间达到 7 天,.ds-my-data-stream-2024.05.09-000001 后备索引将被删除以符合配置的数据保留期。
索引 .ds-my-data-stream-2024.05.09-000002 是数据流的写入索引,一旦满足 rollover 标准,就会等待轮转。
time_since_index_creation 字段用于帮助计算当数据流不再接收大量数据时何时根据自动 max_age 标准滚动数据流。
从 ILM 迁移到数据流生命周期
促进数据流生命周期的平稳过渡,以便对数据流进行测试、试验,并最终将其迁移到生产环境,这始终是此功能的目标。因此,我们决定允许 ILM 和数据流生命周期在云环境和本地部署中的数据流上共存。
ILM 配置继续直接存在于支持索引上,而数据流生命周期则配置在数据流本身上。
支持索引一次只能由一个管理系统管理。如果 ILM 和数据流生命周期都适用于支持索引,则 ILM 优先(默认情况下,但可以使用 index.lifecycle.prefer_ilm 索引设置将优先级更改为数据流生命周期)。
数据流的迁移路径将允许现有的 ILM 管理的支持索引老化并最终被 ILM 删除,而新的支持索引将开始由数据流生命周期管理。
我们增强了 GET _data_stream API,使其包含每个支持索引的滚动信息(managed_by 字段,可能值为 Index Lifecycle Management、Data stream lifecycle 或Unmanaged,以及 prefer_ilm 设置的值),并在数据流级别包含 next_generation_managed_by 字段,以指示将管理下一代支持索引的系统。
要将未来的支持索引(在数据流滚动后创建)配置为由数据流生命周期管理,需要执行两个步骤:
- 更新支持数据流的索引模板,将 prefer_ilm 设置为 false(请注意,prefer_ilm 是一个索引设置,因此在索引模板中配置它意味着它只会在新的支持索引上配置)并配置所需的数据流生命周期(这将确保新的数据流将开始由数据流生命周期管理)。
- 使用 lifecycle API 为现有数据流配置数据流生命周期。
有关迁移到数据流生命周期的完整教程,请查看我们的文档。
结论
我们为数据流构建了一个生命周期功能,可以自动处理底层数据结构的维护,让你专注于业务生命周期需求,如降采样和数据保留。
试用我们新的无服务器(serverless)产品,并了解更多有关数据流生命周期的可能性的信息。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证?了解下一期 Elasticsearch 工程师培训何时举行!
原文:Data lifecycle management: Simplifying data lifecycle management for data streams — Elastic Search Labs
相关文章:
Elasticsearch:简化数据流的数据生命周期管理
作者:来自 Elastic Andrei Dan 今天,我们将探索 Elasticsearch 针对数据流的新数据管理系统:数据流生命周期,从版本 8.14 开始提供。凭借其简单而强大的执行模型,数据流生命周期可让n 你专注于数据生命周期的业务相关方…...

Verilog综合出来的图
Verilog写代码时需要清楚自己综合出来的是组合逻辑、锁存器还是寄存器。 甚至,有时写的代码有误,vivado不能识别出来,这时打开综合后的schematic简单查看一下是否综合出想要的结果。 比如:误将一个always模块重复一遍,…...
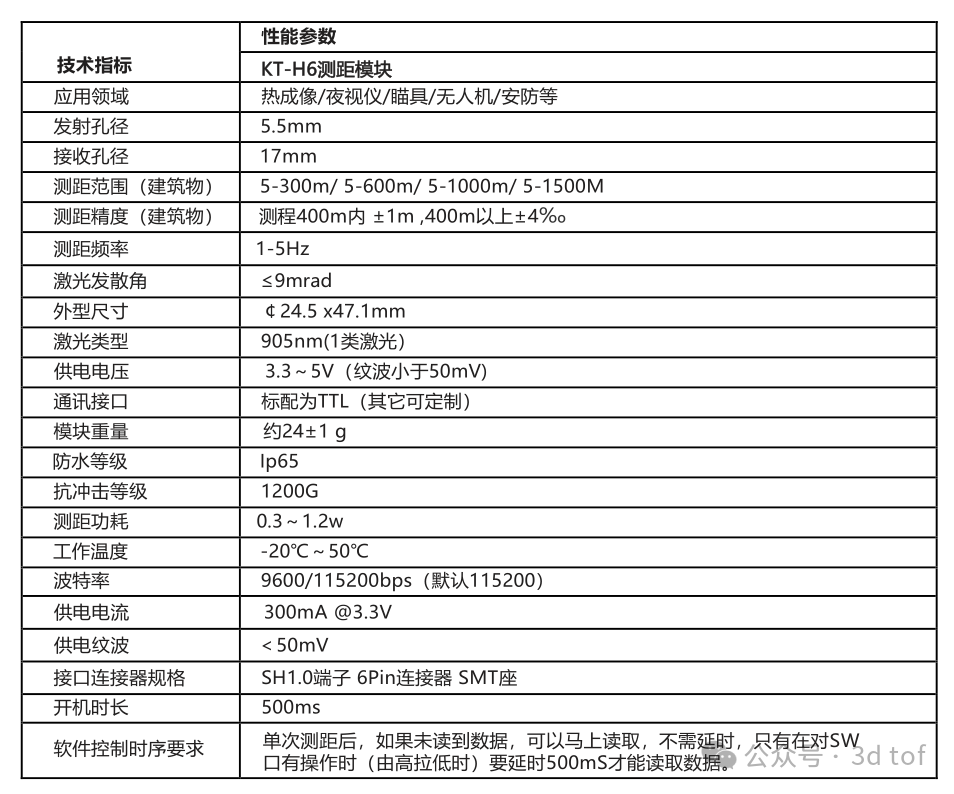
KT-H6测距模块标品,测距范围1500m,demo报价1000RMB,批量报价500RMB
激光测距传感器是一种用于测量距离的模块,通常由传感器和相关电子设备组成,测距模块可以集成到各种设备和系统中,以实现准确的测距和定位功能。KT-H6系列激光测距模块,为自主研发,激光波长905nm的激光器,专为热成像、夜视仪、无人机、安防、瞄具等产品定身打造,其优点是…...
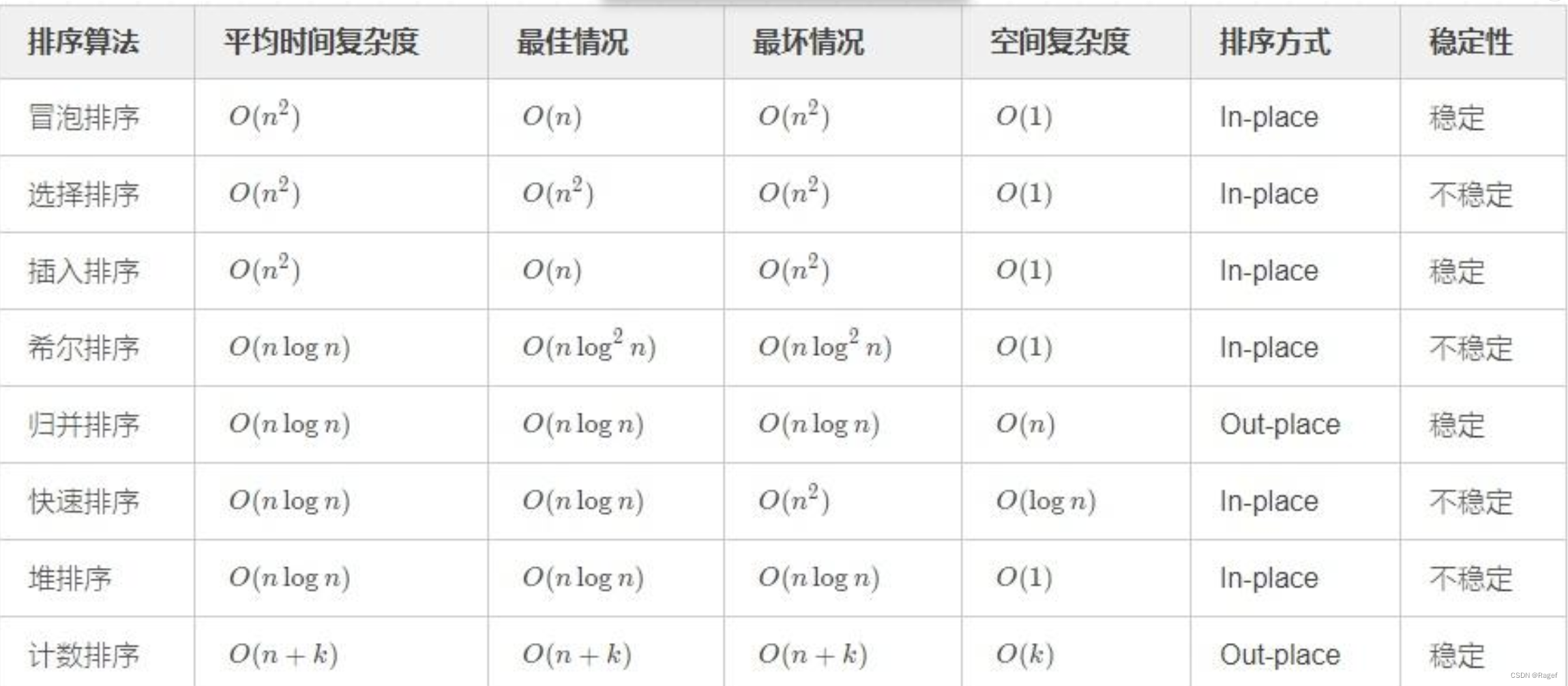
C数据结构:排序
目录 冒泡排序 选择排序 堆排序 插入排序 希尔排序 快速排序 hoare版本 挖坑法 前后指针法 快速排序优化 三数取中法 小区间优化 快速排序非递归 栈版本 队列版本 归并排序 归并排序非递归 编辑 计数排序 各排序时间、空间、稳定汇总 冒泡排序 void Bub…...

【Python】在 Pandas 中使用 AdaBoost 进行分类
我们都找到天使了 说好了 心事不能偷藏着 什么都 一起做 幸福得 没话说 把坏脾气变成了好沟通 我们都找到天使了 约好了 负责对方的快乐 阳光下 的山坡 你素描 的以后 怎么抄袭我脑袋 想的 🎵 薛凯琪《找到天使了》 在数据科学和机器学习的工作…...
)
持续总结中!2024年面试必问 20 道并发编程面试题(九)
上一篇地址:持续总结中!2024年面试必问 20 道并发编程面试题(八)-CSDN博客 十七、请解释什么是Callable和FutureTask。 Callable和FutureTask是Java并发API中的重要组成部分,它们用于处理可能产生结果的异步任务。 …...
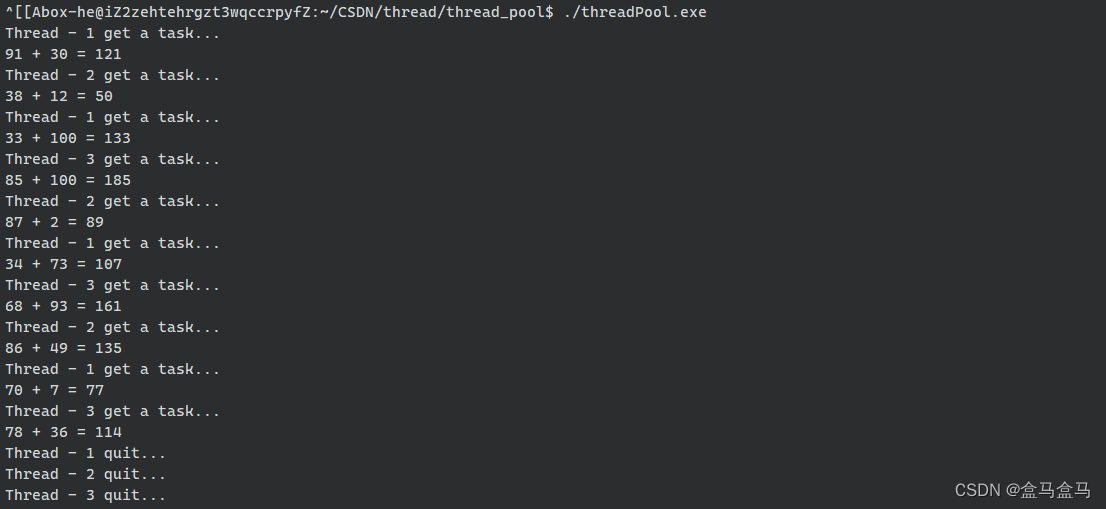
Linux:线程池
Linux:线程池 线程池概念封装线程基本结构构造函数相关接口线程类总代码 封装线程池基本结构构造与析构初始化启动与回收主线程放任务其他线程读取任务终止线程池测试线程池总代码 线程池概念 线程池是一种线程使用模式。线程过多会带来调度开销,进而影…...

集成学习方法:Bagging与Boosting的应用与优势
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

JEnv-for-Windows 2 java版本工具的安装使用踩坑
0.环境 windows11pro 1.工具下载 GitHub - Mu-L/JEnv-for-Windows: Change your current Java version with one line or JEnv-for-Windows:Change your current Java version with one line - GitCode 2.执行jenv 初始化 2.1 问题:PowerShell 未对文件\XXX.…...
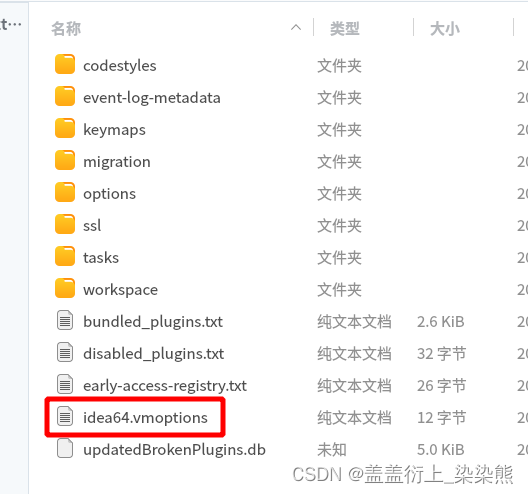
linux中: IDEA 由于JVM 设置内存过小,导致打开项目闪退问题
1. 找到idea安装目录 由于无法打开idea,只能找到idea安装目录 在linux(debian/ubuntu)中idea的插件默认安装位置和配置文件在哪里? 默认路径: /home/当前用户名/.config/JetBrains/IntelliJIdea2020.具体版本号/options2. 找到jvm配置文件 IDEA安装…...

d3.js获取流程图不同的节点
在D3.js中,获取流程图中不同的节点通常是通过选择SVG元素并使用数据绑定来实现的。流程图的节点可以通过BPMN、JSON或其他数据格式定义,然后在D3.js中根据这些数据动态生成和选择节点。 以下是一个基本的示例,展示如何使用D3.js选择和操作流…...

MFC socket编程-服务端和客户端流程
MFC 提供了一套丰富的类库来简化 Windows 应用程序的网络编程。以下是使用 MFC 进行 socket 编程时服务端和客户端的基本流程: 服务端流程: 初始化 Winsock: 调用 AfxSocketInit 初始化 Winsock 库。 创建 CSocket 或 CAsyncSocket 对象&am…...

22.1 正则表达式-定义正则表达式、正则语法
1.定义正则表达式 正则表达式意在描述隐藏在数据中的某种模式或规则。 例如:下面的几个字符串看似各不相同: slimshady999roger1813Wagner但看似不同的数据却隐藏着相同的特征: 仅由英语字母和数字组成英语字母有小写也有大写总字符数介于 …...
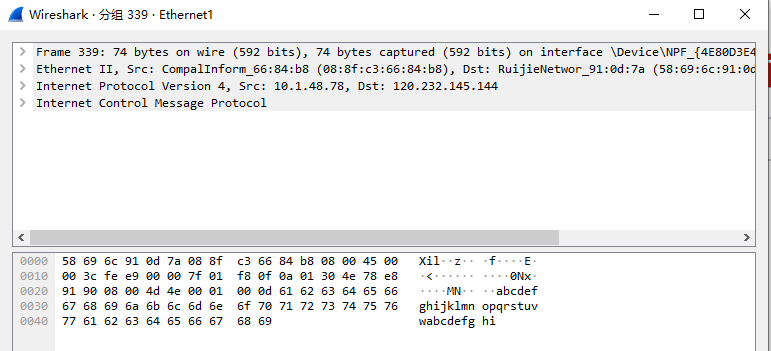
网络数据包抓取与分析工具wireshark的安及使用
WireShark安装和使用 WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。 1 任务目标 1.1 知识目标 了解WireShark的过滤器使用,通过过滤器可以筛选出想要分析的内容 掌握Wir…...
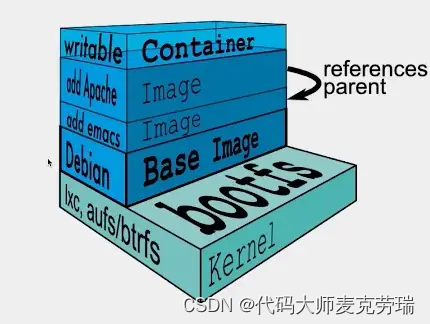
Docker镜像技术剖析
目录 1、概述1.1 什么是镜像?1.2 联合文件系统UnionFS1.3 bootfs和rootfs1.4 镜像结构1.5 镜像的主要技术特点1.5.1 镜像分层技术1.5.2 写时复制(copy-on-write)策略1.5.3 内容寻址存储(content-addressable storage)机制1.5.4 联合挂载(union mount)技术 2.机制原理…...
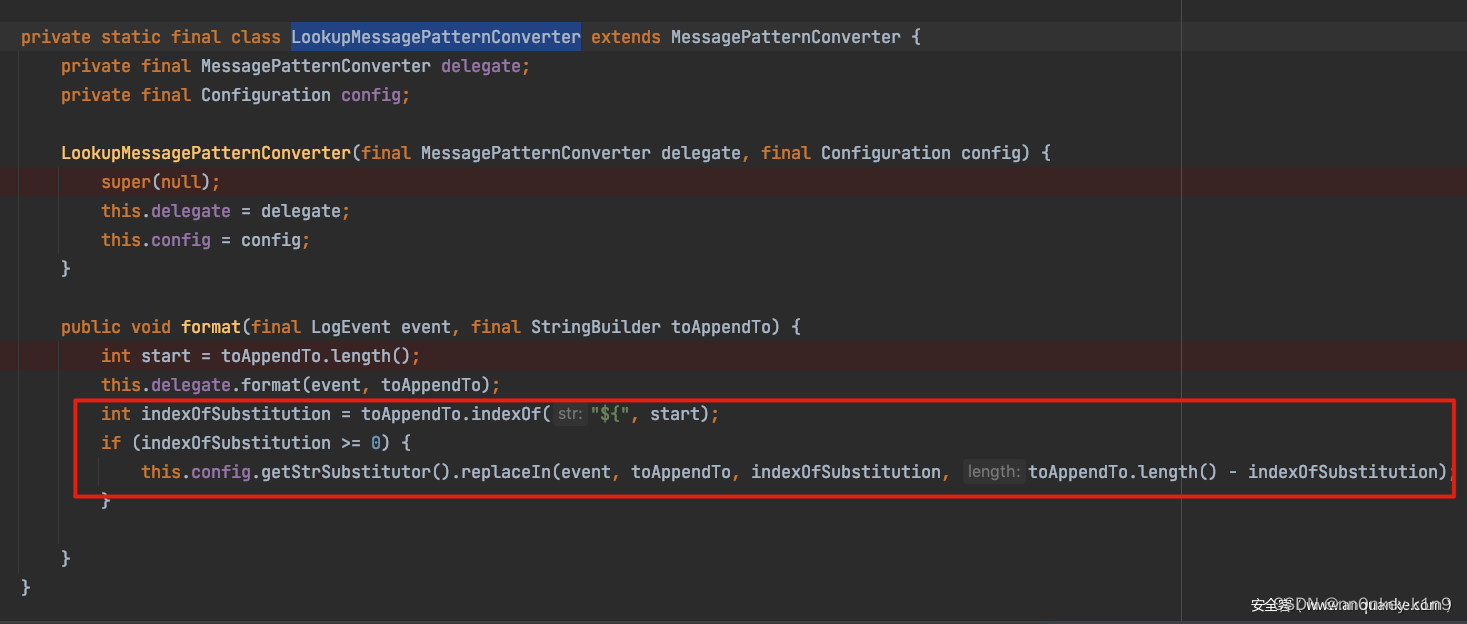
log4j漏洞学习
log4j漏洞学习 总结基础知识属性占位符之Interpolator(插值器)模式布局日志级别 Jndi RCE CVE-2021-44228环境搭建漏洞复现代码分析日志记录/触发点消息格式化 Lookup 处理JNDI 查询触发条件敏感数据带外漏洞修复MessagePatternConverter类JndiManager#l…...

架构设计 - WEB项目的基础序列化配置
摘要:web项目中做好基础架构(redis,json)的序列化配置有重要意义 支持复杂数据结构:Redis 支持多种不同的数据结构,如字符串、哈希表、列表、集合和有序集合。在将这些数据结构存储到 Redis 中时,需要将其序列化为字节…...
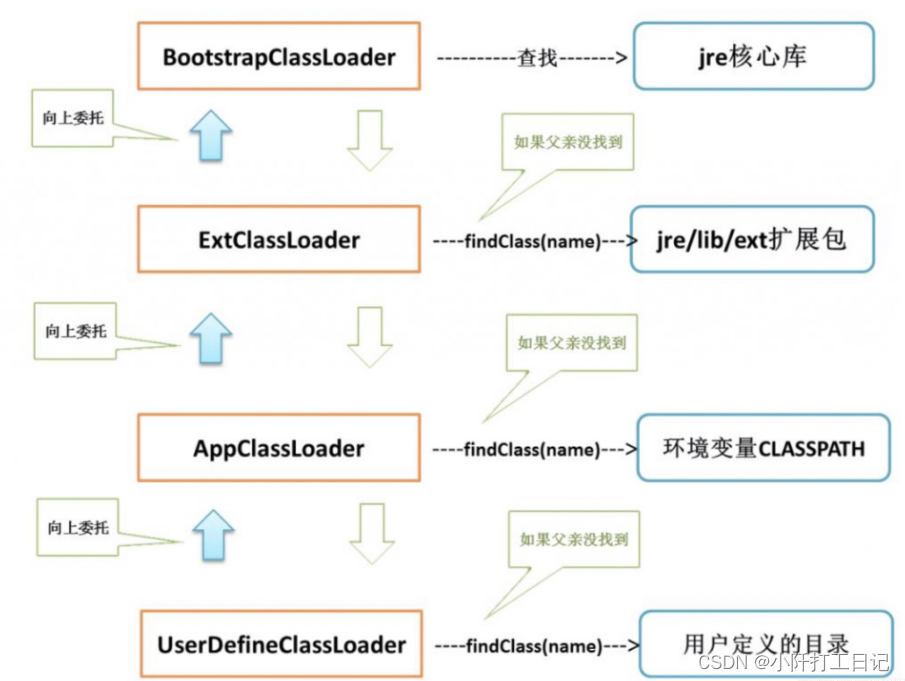
java(JVM)
JVM Java的JVM(Java虚拟机)是运行Java程序的关键部件。它不直接理解或执行Java源代码,而是与Java编译器生成的字节码(Bytecode)进行交互。下面是对Java JVM更详尽的解释: 1.字节码: 当你使用J…...

【网络安全】【深度学习】【入侵检测】SDN模拟网络入侵攻击并检测,实时检测,深度学习【二】
文章目录 1. 习惯终端2. 启动攻击3. 接受攻击4. 宿主机查看h2机器 1. 习惯终端 上次把ubuntu 22自带的终端玩没了,治好用xterm: 以通过 AltF2 然后输入 xterm 尝试打开xterm 。 然后输入这个切换默认的终端: sudo update-alternatives --co…...
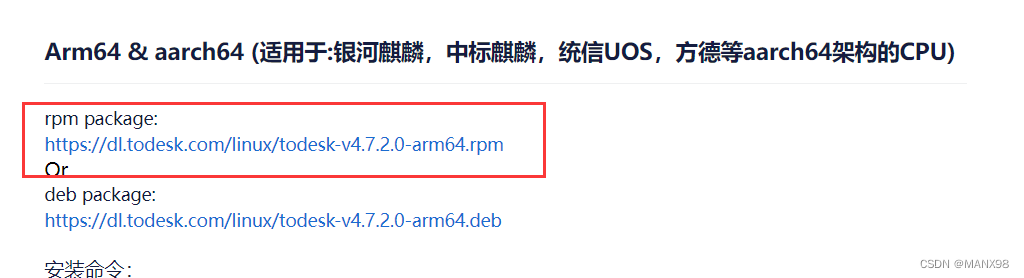
飞腾银河麒麟V10安装Todesk
下载安装包 下载地址 https://www.todesk.com/linux.html 安装 yum makecache yum install libappindicator-gtk3-devel.aarch64 rpm -ivh 下载的安装包文件后台启动 service todeskd start修改配置 编辑 /opt/todesk/config/config.ini 移除自动更新临时密码 passupda…...

DSP+FPGA异构架构在实时信号处理中的应用与优化
1. 实时信号处理系统架构解析在工业自动化、医疗影像和通信系统中,对信号处理实时性要求极高的场景比比皆是。传统纯软件方案往往受限于CPU的串行处理特性,难以满足严格的时序要求。这正是DSPFPGA异构架构大显身手的领域——我曾参与过多个类似项目&…...

利用大模型分歧优化NLP标注
In this blogpost I’d like to talk about large language models. There’s a bunch of hype, sure, but there’s also an opportunity to revisit one of my favourite machine learning techniques: disagreement. 在本文中,我想讨论大语言模型。虽然存在大量炒…...
)
DIY红外热像仪进阶:手把手教你用C语言实现7种伪彩色编码(附完整代码)
DIY红外热像仪进阶:手把手教你用C语言实现7种伪彩色编码(附完整代码) 当32x24的温度矩阵在屏幕上呈现为单调的灰度图像时,你是否想过如何让它焕发生机?伪彩色编码技术正是打开这扇门的钥匙。本文将带你深入探索七种经…...

如何用Layerdivider在3步内将单张图片智能分层为PSD文件
如何用Layerdivider在3步内将单张图片智能分层为PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一张精美的插画,想要修改…...

终极视频字幕提取指南:如何用本地OCR工具高效提取87种语言硬字幕
终极视频字幕提取指南:如何用本地OCR工具高效提取87种语言硬字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测…...

Dell G15散热终极解决方案:开源温度控制中心完全指南
Dell G15散热终极解决方案:开源温度控制中心完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 Dell G15笔记本用户是否经常遭遇游戏卡顿、性…...

隐私优先的API密钥泄露检测工具:compromising-position设计与实战
1. 项目概述:一个帮你确认API密钥是否已泄露的隐私优先工具最近在开发者圈子里,一个叫OpenClaw的技能市场平台因为安全漏洞闹得沸沸扬扬,据说有几万个API密钥被泄露了。安全公告总是千篇一律地告诉你“请立即轮换你的密钥”,但说实…...

3种方法修复ROG游戏本色彩配置文件丢失问题:G-Helper实战指南
3种方法修复ROG游戏本色彩配置文件丢失问题:G-Helper实战指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenb…...

如何用猫抓浏览器扩展轻松捕获在线视频资源?一个实用工具的全方位指南
如何用猫抓浏览器扩展轻松捕获在线视频资源?一个实用工具的全方位指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 当你在浏览器中观…...

Cursor编辑器集成Claude 3:AI双模型编程实战与成本优化指南
1. 项目概述:当AI代码助手遇上你的IDE 最近在开发者圈子里,一个名为“Cursor-Claude-Extension”的开源项目热度持续攀升。简单来说,它是一款为Cursor编辑器设计的扩展插件,核心功能是将Anthropic公司强大的Claude系列模型&#x…...