Sklearn中逻辑回归建模

分类模型的评估
回归模型的评估方法,主要有均方误差MSE,R方得分等指标,在分类模型中,我们主要应用的是准确率这个评估指标,除此之外,常用的二分类模型的模型评估指标还有召回率(Recall)、F1指标(F1-Score)等等
准确率的局限性💥
准确率的定义是:对于给定的测试集,分类模型正确分类的样本数与总样本数之比。举个例子来讲,有一个简单的二分类模型model,专门用于分类动物,在某个测试集中,有30个猫+70个狗,这个二分类模型在对这个测试集进行分类的时候,得出该数据集有40个猫(包括正确分类的25个猫和错误分类的15个狗)和60个狗(包括正确分类的55个狗和错误分类的5个猫猫)。画成矩阵图表示,结果就非常清晰:

从图中可以看出,行表示该测试集中实际的类别,比如猫类一共有25+5=30个,狗狗类有15+55=70个。其中被分类模型正确分类的是该表格的对角线所在的数字。在sklearn中,这样一个表格被命名为混淆矩阵(Confusion Matrix),所以,按照准确率的定义,可以计算出该分类模型在测试集上的准确率为: Accuracy = 80%
💢即,该分类模型在测试集上的准确率为80%
在分类模型中可以定义
- Actual condition positive(P):样本中阳性样本总数,一般也就是真实标签为1的样本总数;
- Actual condition negative(N):样本中阴性样本总数,一般也就是真实标签为0的样本总数;
- Predicted condition positive(PP):预测中阳性样本总数,一般也就是预测标签为1的样本总数;
- Predicted condition negative(PN):预测中阴性样本总数,一般也就是预测标签为0的样本总数;
- 当前案例中,可以将猫猫类别作为阳性样本,也就是二分类中的1类,狗狗作为阴性数据,也就是0类样本
- 对于刚才的案例而言,P = 30, N = 70, PP = 40, PN = 60
进行二分类模型预测过程中,样本类别被模型正确识别的情况其实有两种,一种是阳性样本被正确识别,另一种是阴性样本被正确识别,据此我们可以有如下定义:
- True positive(TP):样本属于阳性(类别1)、并且被正确识别为阳性(类别1)的样本总数;TP发生时也被称为正确命中(hit);
- True negative(TN):样本属于阴性(类别0)、并且被正确识别为阴性(类别0)的样本总数;TN发生时也被称为正确拒绝(correct rejection);
上述样本中,TP=25,TN = 55 ~
当然,对于误分类的样本,其实也有两种情况,其一是阳性样本被误识别为阴性,其二是阴性样本被误识别为阳性,据此我们也有如下定义:
- False positive(FP):样本属于阴性(类别0),但被错误判别为阳性(类别1)的样本总数;FP发生时也被称为发生I类了错误(Type I error),或者假警报(False alarm)、低估(underestimation)等;
- False negative(FN):样本属于阳性(类别1),但被错误判别为阴性(类别0)的样本总数;FN发生时也被称为发生了II类错误(Type II error),或者称为错过目标(miss)、高估(overestimation)等;
混淆矩阵也可以写成如下形式

但是,准确率指标并不总是能够评估一个模型的好坏,比如对于下面的情况,假如有一个数据集,含有98个狗狗,2个猫,而分类器model,是一个很差劲的分类器,它把数据集的所有样本都划分为狗狗,也就是不管输入什么样的样本,该模型都认为该样本是狗狗。
💯 则该模型的准确率为98%,因为它正确地识别出来了测试集中的98个狗狗,只是错误的把2个猫咪也当做狗狗,所以按照准确率的计算公式,该模型有高达98%的准确率。
💢可是,这样的模型有意义吗?我们主要想识别出猫猫的类别,特意把猫猫作为1类,但是当前模型为了尽量追求准确率,完全牺牲了对猫猫识别的精度,这是一个极端的情况,却又是普遍的情况,准确率在一些场景并不适用,特别是对于这种样品数量偏差比较大的问题,准确率的“准确度”会极大的下降。所以,这时就需要引入其他评估指标评价模型的好坏。
召回率(Recall)💯
召回率侧重于关注全部的1类样本中别准确识别出来的比例,其计算公式为

对于当前案例,我们的召回率是 25 / (25+5) = 0.833, 30条正例样本,其中25条被预测正确
根据召回率的计算公式我们可以试想,如果以召回率作为模型评估指标,则会使得模型非常重视是否把1全部识别了出来,甚至是牺牲掉一些0类样本判别的准确率来提升召回率,即哪怕是错判一些0样本为1类样本,也要将1类样本识别出来,这是一种“宁可错杀一千不可放过一个”的判别思路。因此,召回率其实是一种较为激进的识别1类样本的评估指标,在0类样本被误判代价较低、而1类样本被误判成本较高时可以考虑使用。“宁可错杀一千不可放过一个
当然,对于极度不均衡样本,这种激进的判别指标也能够很好的判断模型有没有把1类样本成功的识别出来。例如总共100条数据,其中有99条样本标签为0、剩下一条样本标签为1,假设模型总共有A、B、C三个模型,A模型判别所有样本都为0类,B模型判别50条样本为1类50条样本为0类,并且成功识别唯一的一个1类样本,C模型判别20条样本为1类、80条样本为0类,同样成功识别了唯一的一个1类样本,则各模型的准确率和召回率如下:

不难发现,在偏态数据中,相比准确率,召回率对于1类样本能否被正确识别的敏感度要远高于准确率,但对于是否牺牲了0类别的准确率却无法直接体现。
精确率(Precision)💯
精确率的定义是:对于给定测试集的某一个类别,分类模型预测正确的比例,或者说:分类模型预测的正样本中有多少是真正的正样本,其计算公式是:
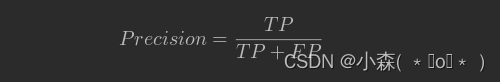
当前案例中,Precision = 25 / 25 + 15 = 0.625
精确度,衡量对1类样本的识别,能否成功(准确识别出1)的概率,也正是由于这种力求每次出手都尽可能成功的策略,使得当我们在以精确度作为模型判别指标时,模型整体对1的判别会趋于保守,只对那些大概率确定为1的样本进行1类的判别,从而会一定程度牺牲1类样本的准确率,在每次判别成本较高、而识别1样本获益有限的情况可以考虑使用精确度
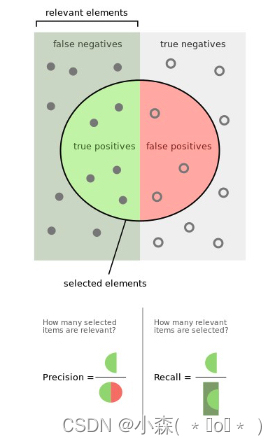
💤关于召回率和精确度,也可以通过如下形式进行更加形象的可视化展示
- F1值(F1-Measure)
-
在理想情况下,我们希望模型的精确率越高越好,同时召回率也越高越高,但是,现实情况往往事与愿违,在现实情况下,精确率和召回率像是坐在跷跷板上一样,往往出现一个值升高,另一个值降低,那么,有没有一个指标来综合考虑精确率和召回率了,再大多数情况下,其实我们是希望获得一个更加“均衡”的模型判别指标,即我们既不希望模型太过于激进、也不希望模型太过于保守,并且对于偏态样本,既可以较好的衡量1类样本是否被识别,同时也能够兼顾考虑到0类样本的准确率牺牲程度,此时,我们可以考虑使用二者的调和平均数(harmonic mean)作为模型评估指标,这个指标就是F值。F值的计算公式为
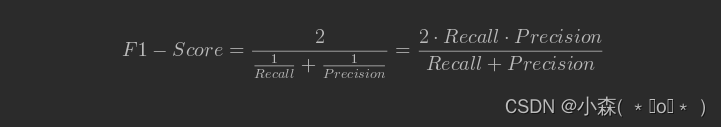
F1-Score指标能够一定程度上综合Recall和Precision的结果,综合判断模型整体分类性能。当然,除了F1-Score以外我们还可以取Recall和Precision的均值(balanced accuracy,简称BA)来作为模型评估指标
sklearn 中的指标计算
from sklearn.metrics import recall_score, precision_score, f1_scorey_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 0, 1, 1, 1, 0]
print(f"召回率:{recall_score(y_true, y_pred)}")
print(f"精确率:{precision_score(y_true, y_pred)}")
print(f"f1-score:{f1_score(y_true, y_pred)}") 召回率:0.5
精确率:0.6666666666666666
f1-score:0.5714285714285715- 在类别划分上,仍然需要强调的是,我们需要根据实际业务情况,将重点识别的样本类划为类别1,其他样本划为类别0
- 如果0、1两类在业务判断上并没有任何重要性方面的差异,那么我们可以将样本更少的哪一类划为1类
- 在评估指标选取上,同样需要根据业务情况判断,如果只需要考虑1类别的识别率,则可考虑使用Recall作为模型评估指标,若只需考虑对1样本判别结果中的准确率,则可考虑使用Precision作为评估指标。但一般来说这两种情况其实都不多,更普遍的情况是,需要重点识别1类但也要兼顾0类的准确率,此时我们可以使用F1-Score指标。F1-Score其实也是分类模型中最为通用和常见的分类指标
相关文章:
Sklearn中逻辑回归建模
分类模型的评估 回归模型的评估方法,主要有均方误差MSE,R方得分等指标,在分类模型中,我们主要应用的是准确率这个评估指标,除此之外,常用的二分类模型的模型评估指标还有召回率(Recallÿ…...

【ARM】MDK出现报错error: A\L3903U的解决方法
【更多软件使用问题请点击亿道电子官方网站】 1、 文档目标 解决MDK出现报错error: A\L3903U这样类型的报错 2、 问题场景 电脑或者软件因为意外情况导致崩溃,无法正常关闭,强制电脑重启之后,打开工程去编译出现下面的报错信息(…...

0018__字体的kerning是什么意思
泰山OFFICE技术讲座:字体的kerning是什么意思-CSDN博客 了解CSS属性font-kerning,font-smoothing,font-variant-CSDN博客...
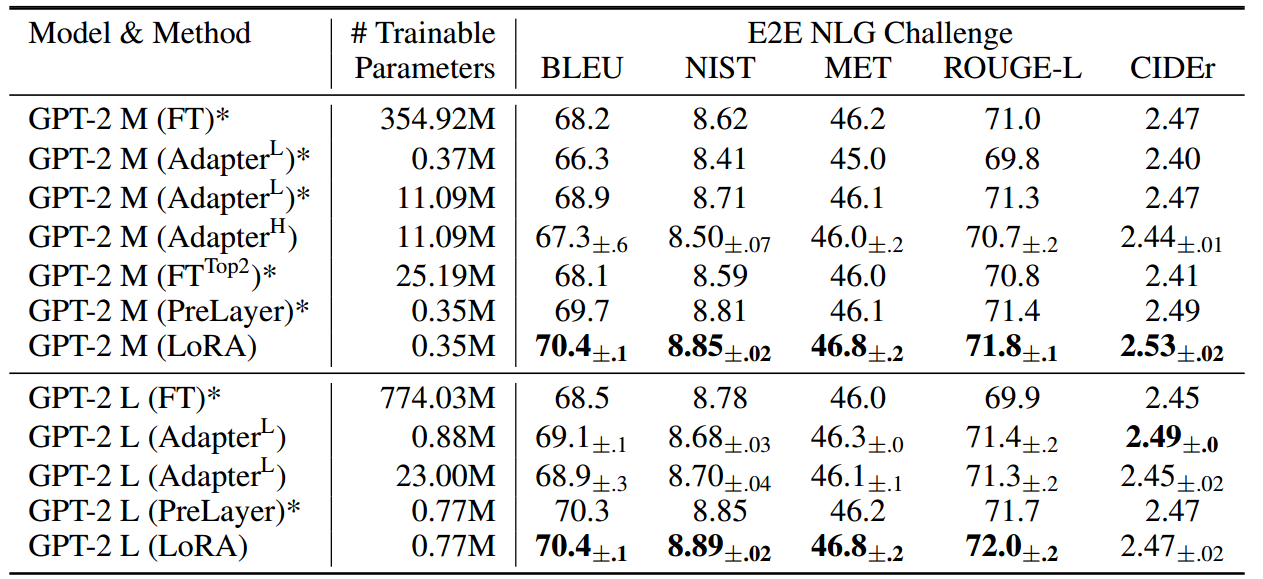
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
文章汇总 总体来看像是一种带权重的残差,但解决的如何高效问题的事情。 相比模型的全微调,作者提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。 模型架构 h W 0 x △…...

cmake、make、makefile、ninga的关系
CMake是一种跨平台的构建系统,它用来管理软件的编译过程。CMake可以生成本地平台特定的构建文件,例如Makefile或者Microsoft Visual Studio项目文件,以便开发人员更轻松地在不同的平台上构建他们的项目。它的主要功能是配置和生成构建脚本&am…...
StarRocks详解
什么是StarRocks? StarRocks是新一代极速全场景MPP数据库(高并发数据库)。 StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果。 1.可以在Spark和Flink里面处理数据,然后将处理完的数据写到StarRo…...

【C语言】进程间通信之管道pipe
进程间通信之管道pipe 一、进程间通信管道pipe()管道的读写行为 最后 一、进程间通信 管道pipe() 管道pipe也称为匿名管道,只有在有血缘关系的进程间进行通信。管道的本质就是一块内核缓冲区。 进程间通过管道的一端写,通过管道的另一端读。管道的读端…...
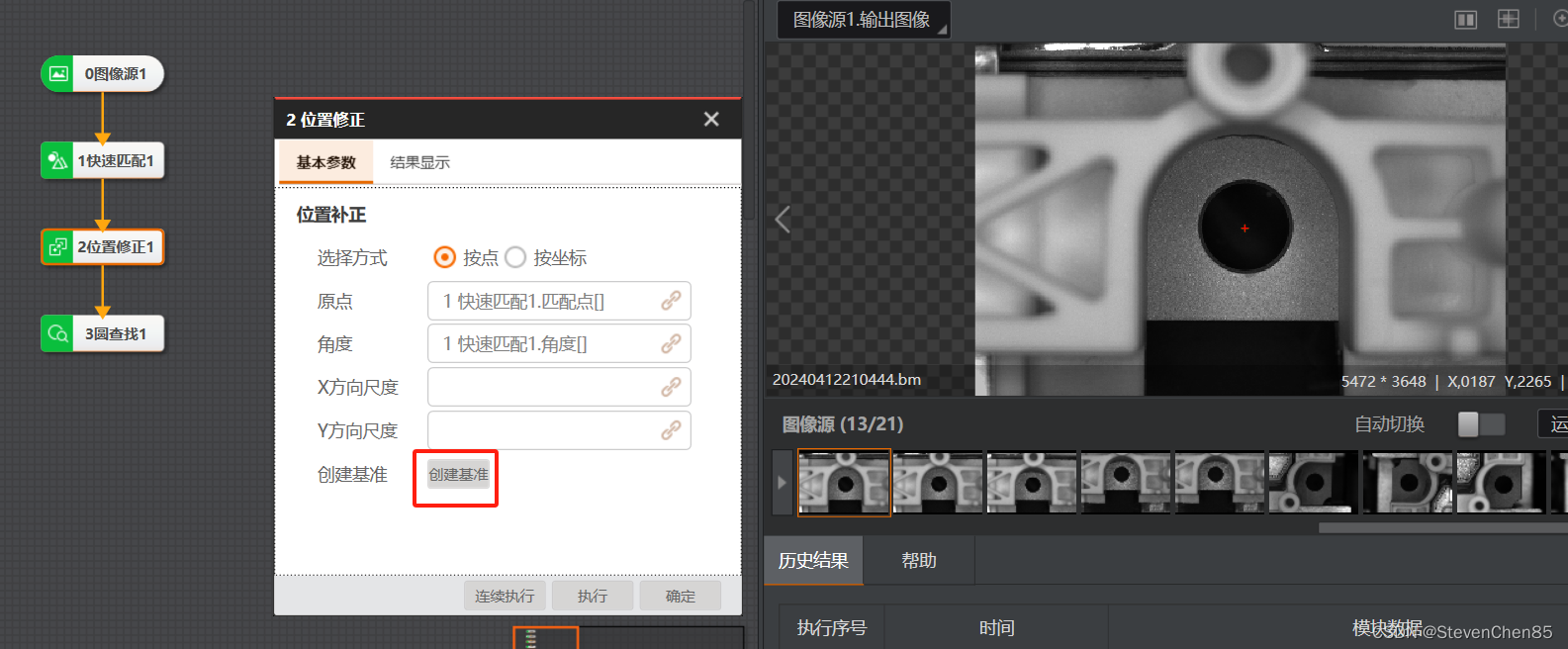
03.VisionMaster 机器视觉 位置修正 工具
VisionMaster 机器视觉 位置修正 工具 官方解释:位置修正是一个辅助定位、修正目标运动偏移、辅助精准定位的工具。可以根据模板匹配结果中的匹配点和匹配框角度建立位置偏移的基准,然后再根据特征匹配结果中的运行点和基准点的相对位置偏移实现ROI检测…...

Oracle 是否扼杀了开源 MySQL
Oracle 是否无意中扼杀了开源 MySQL Peter Zaitsev是一位俄罗斯软件工程师和企业家,曾在MySQL公司担任性能工程师。大约15年前,当甲骨文收购Sun公司并随后收购MySQL时,有很多关于甲骨文何时“杀死MySQL”的讨论。他曾为甲骨文进行辩护&#…...
机器学习归一化特征编码
特征缩放 因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度…...

抛光粉尘可爆性检测 打磨粉尘喷砂粉尘爆炸下限测试
抛光粉尘可爆性检测 抛光粉尘的可爆性检测是一种安全性能测试,用于确定加工过程中产生的粉尘在特定条件下是否会爆炸,从而对生产安全构成威胁。如果粉尘具有可爆性,那么在生产环境中就需要采取相应的防爆措施。粉尘爆炸的条件通常包括粉尘本身…...

python14 字典类型
字典类型 键值对方式,可变数据类型,所以有增删改功能 声明方式1 {} 大括号,示例 d {key1 : value1, key2 : value2, key3 : value3 ....} 声明方式2 使用内置函数 dict() 创建1)通过映射函数创建字典zip(list1,list2) 继承了序列的所有操作 …...

深入了解 .url文件中的 Prop3属性
在使用 Windows 操作系统时,我们经常会遇到以 .url 结尾的文件,它们通常被用来快速访问互联网上的特定网页。这些文件虽然看起来简单,但其中包含的 Prop3 属性却有其特殊的作用和意义。 1. Prop3 是什么? 在 .url 文件中&#x…...

vue3+vite:动态引入静态图片资源
目录 第一章 前言 第二章 vue2与vue3动态引入静态图片资源 2.1 vue2 webpack动态引入静态图片资源 2.1.1 了解 2.1.2 vue2项目动态引入静态图片资源 2.2 vue3 vite动态引入静态图片资源 2.2.1 了解 2.2.2 require vs import了解 2.2.3 vue3vite 项目动态引入静态图片…...

【K8s】专题五(3):Kubernetes 配置之 ConfigMap 与 Secret 异同
以下内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发!欢迎扫码关注个人公众号! 目录 一、相同点 二、不同点 一、相同点 功能作用:ConfigMap 与 Secret 都用于存储…...
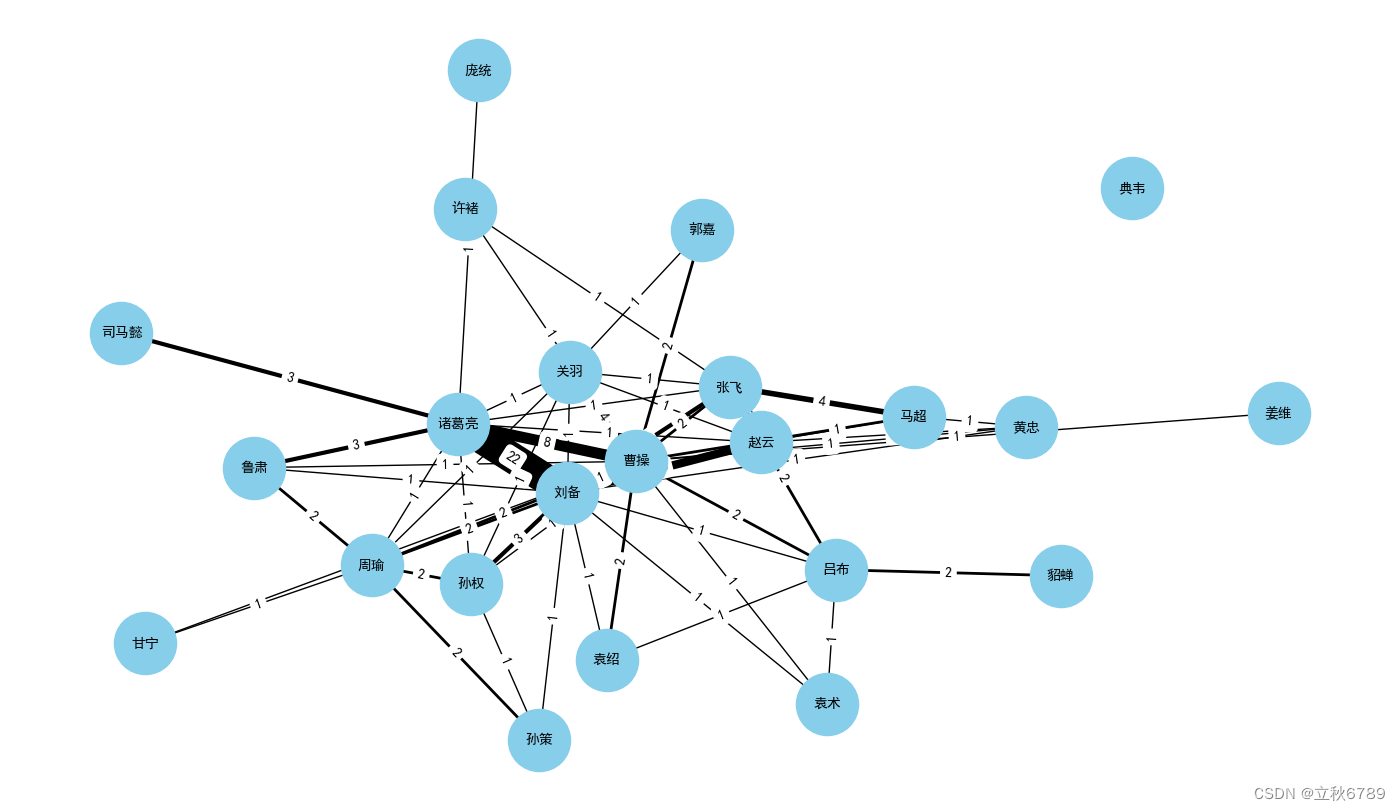
用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网 三国演义获取文本文本预处理分词与词频统计引入停用词后进行词频统计构建人物关系网完整代码 三国演义 《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间…...
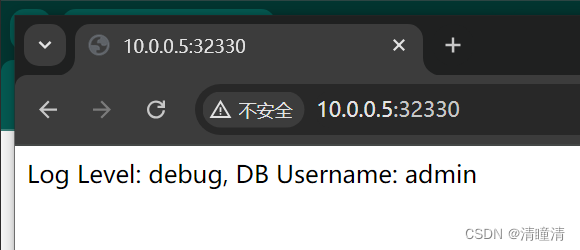
k8s上使用ConfigMap 和 Secret
使用ConfigMap 和 Secret 实验目标: 学习如何使用 ConfigMap 和 Secret 来管理应用的配置。 实验步骤: 创建一个 ConfigMap 存储应用配置。创建一个 Secret 存储敏感信息(如数据库密码)。在 Pod 中挂载 ConfigMap 和 Secret&am…...
hexo实战:(二)个人独立博客优化合集
前言 上次介绍了使用 HexoGitHub Pages,零成本搭建一个专属自己的独立博客网站。我觉得那篇文章是没有入门门槛的,不管你是什么行业,只要想打造个人 IP,又不太想受博客平台约束,那么读完后动手操作一下也能轻松完成。…...

PostgreSQL的pg_relation_filepath函数
PostgreSQL的pg_relation_filepath函数 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777在 PostgreSQL 中&…...

Vue开发中Element UI/Plus使用指南:常见问题(如Missing required prop: “value“)及中文全局组件配置解决方案
文章目录 一、vue中使用el-table的typeindex有时不显示序号Table 表格显示索引自定义索引报错信息解决方案 二、vue中Missing required prop: “value” 报错报错原因解决方案 三、el-table的索引值index在翻页的时候可以连续显示方法一方法二 四、vue3中Element Plus全局组件配…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

Fawkes踩过的坑以及如何解决非常详细
首先我是用anaconda创建的一个虚拟环境 fawkes_env后续的所有操作都是在该环境中实现 不使用anaconda 可直接看第一步 坑:直接用 conda create -n fawkes python3.9 后,pip install -e . 可能因为 TensorFlow 版本过新导致不兼容(Keras 2.3…...

数据中心机架内互连新范式:为何PCIe正取代以太网与InfiniBand?
1. 数据中心互连的十字路口:为什么是PCIe?在数据中心这个庞大而精密的数字世界里,服务器、存储和网络设备之间的“对话”效率,直接决定了整个系统的性能上限。过去十几年,我们习惯了用以太网(Ethernet&…...

JavaScript自动化PPT生成:如何用代码解放你的演示文稿生产力
JavaScript自动化PPT生成:如何用代码解放你的演示文稿生产力 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 还在为…...

从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的
从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的 接手一个结构混乱的遗留项目,就像面对一盘煮过头的意大利面——各种逻辑纠缠不清,随便动一处就可能引发连锁反应。去年我遇到这样一个Java项目:12万行代码࿰…...

高性能ai编程工具zed配置deepseek 开启ai agent对话及代码补全
配置ai助手 进入设置页配置deepseek apikey配置代码补全 进入setting->edit pridic -> config.json文件。替换下面内容{"show_edit_predictions": true,// ✅ 代码补全核心配置(关键修改)"edit_predictions": {"provide…...

书匠策AI让我的课程论文从“赶死线“变成了“喝茶局“
先交代背景。 上个月,我接了一个"极限挑战":一周五门课,四门要交课程论文,最短的截止日期只剩48小时。 说实话,那一刻我脑子里只有两个字——完蛋。 但作为一个天天教别人写论文的博主,我总不…...

【其他】Obsidian笔记Remotely Save插件中国科技云数据胶囊 配置免费的笔记同步
目录 一 注册中国科技云数据胶囊 二 插件下载 & 配置 三 同步测试 一 注册中国科技云数据胶囊 【1】搜索“中国科技云”,找到“数据胶囊”选项,实名注册可以领取20G的容量: 【2】选择“新数据空间”,输入库的标题…...

基于宏观通胀预测模型的利率预期重定价:华尔街降息路径为何出现系统性回撤?CPI成为关键校准变量
摘要:本文通过宏观通胀预测模型,结合利率预期曲线重定价算法与市场情绪迁移分析,对当前美通胀路径、CPI数据影响及华尔街降息预期变化进行系统性建模,分析利率政策预期从宽松交易向数据依赖模式切换的结构性原因。一、市场情绪迁移…...

如何零成本测试ZPL标签?Virtual ZPL Printer终极解决方案揭秘
如何零成本测试ZPL标签?Virtual ZPL Printer终极解决方案揭秘 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh_mi…...