用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网
- 三国演义
- 获取文本
- 文本预处理
- 分词与词频统计
- 引入停用词后进行词频统计
- 构建人物关系网
- 完整代码
三国演义
《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间的纷争与英雄们的传奇故事。今天,我们将通过Python,初步探索《三国演义》的文本处理,感受这部古典名著的魅力。
获取文本
我们需要从本地读取《三国演义》的文本文件。
# 读取本地《三国演义》文本文件
with open('三国演义.txt', 'r', encoding='utf-8') as file:sanguo_text = file.read()输出看一下读取的文件内容:
print(sanguo_text[:30])
输出如下:

文本预处理
对文本进行分词前,先去除标点符号,使用正则库re来进行。
import re# 去除标点符号和特殊字符
sanguo_text = re.sub(r'[^\w\s]', '', sanguo_text)
sanguo_text = re.sub(r'\n', '', sanguo_text)
分词与词频统计
使用jieba库进行中文分词,并进行词频统计,输出频率最高的10个词。
import jieba
from collections import Counter
# 使用jieba进行分词
words = jieba.lcut(sanguo_text)
# 统计词频
word_counts = Counter(words)# 输出出现频率最高的10个词
print(word_counts.most_common(10))
当前输出如下:
[('曰', 7669), ('之', 2797), ('也', 2232), ('吾', 1815), ('与', 1722), ('将', 1643), ('而', 1600), ('了', 1397), ('有', 1386), ('在', 1286)]
可以看到,现在大多数是一些语气助词。这里我们要引入停用词。
引入停用词后进行词频统计
在文本处理中,停用词是指那些在文本分析中没有实际意义的词汇,如“的”、“了”、“在”等。在进行词频统计时,我们通常会去除这些停用词,以便更准确地分析有意义的词汇。
import jieba
from collections import Counter
# 使用jieba进行分词
words = jieba.lcut(sanguo_text)# 读取停用词列表
with open('常用停用词.txt', 'r', encoding='utf-8') as file:stopwords = set(file.read().split())# 去除停用词
filtered_words = [word for word in words if word not in stopwords]# 统计词频
word_counts = Counter(filtered_words)
# 输出出现频率最高的10个词
print(word_counts.most_common(10))当前输出:
[('曹操', 938), ('孔明', 809), ('玄德', 494), ('丞相', 489), ('关公', 478), ('荆州', 412), ('玄德曰', 385), ('孔明曰', 382), ('张飞', 349), ('商议', 343)]
我使用的停用词文件:

实际上可以根据自己的需求进行调整。
构建人物关系网
注意:三国中人物可能有多个称呼,比如说刘备也可以用玄德称呼
# 三国演义主要人物及其别名列表(扩展版)
characters = {"刘备": ["刘备", "玄德", "皇叔"],"关羽": ["关羽", "云长"],"张飞": ["张飞", "翼德"],"曹操": ["曹操", "孟德", "丞相", "曹孟德"],"孙权": ["孙权", "仲谋"],"诸葛亮": ["诸葛亮", "孔明", "卧龙"],"周瑜": ["周瑜", "公瑾"],"吕布": ["吕布", "奉先"],"貂蝉": ["貂蝉"],"赵云": ["赵云", "子龙"],"黄忠": ["黄忠", "汉升"],"马超": ["马超", "孟起"],"许褚": ["许褚", "仲康"],"典韦": ["典韦"],"司马懿": ["司马懿", "仲达"],"郭嘉": ["郭嘉", "奉孝"],"袁绍": ["袁绍", "本初"],"袁术": ["袁术", "公路"],"孙策": ["孙策", "伯符"],"甘宁": ["甘宁", "兴霸"],"鲁肃": ["鲁肃", "子敬"],"庞统": ["庞统", "凤雏"],"姜维": ["姜维", "伯约"]
}# 创建一个人物关系计数字典
relation_counts = defaultdict(int)# 遍历文本,统计人物间的关系
for i in range(len(filtered_words) - 1):for name1, aliases1 in characters.items():if filtered_words[i] in aliases1:for name2, aliases2 in characters.items():if filtered_words[i + 1] in aliases2 and name1 != name2:relation_counts[(name1, name2)] += 1# 创建网络图
G = nx.Graph()# 添加节点
for character in characters.keys():G.add_node(character)# 添加边及权重
for (name1, name2), count in relation_counts.items():G.add_edge(name1, name2, weight=count)# 绘制关系图
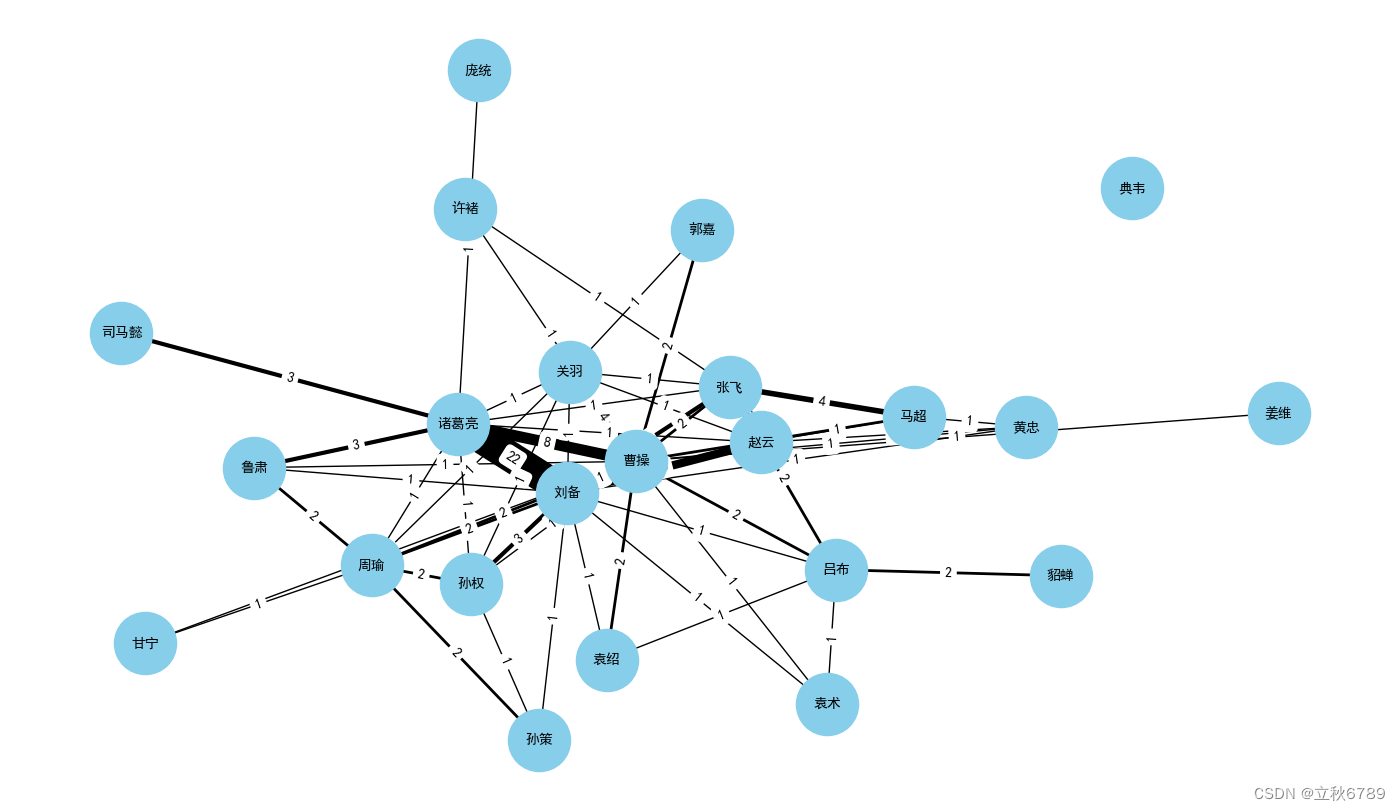
plt.figure(figsize=(14, 10))
pos = nx.spring_layout(G, k=1)
edges = G.edges(data=True)
weights = [edge[2]['weight'] for edge in edges]# 绘制节点和边
nx.draw(G, pos, with_labels=True, node_size=2000, node_color='skyblue', font_size=10, font_weight='bold', width=weights)# 在图中显示边的权重
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)plt.title('《三国演义》人物关系网(扩展版)')
plt.show()
完整代码
import re
import jieba
from collections import Counter, defaultdict
import networkx as nx
import matplotlib.pyplot as plt
from pylab import mpl# 设置中文字体,确保图表中能显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei']# 读取本地《三国演义》文本文件
with open('三国演义.txt', 'r', encoding='utf-8') as file:sanguo_text = file.read()# 去除标点符号和换行符
sanguo_text = re.sub(r'[^\w\s]', '', sanguo_text)
sanguo_text = re.sub(r'\n', '', sanguo_text)# 使用jieba进行分词
words = jieba.lcut(sanguo_text)# 读取停用词列表
with open('常用停用词.txt', 'r', encoding='utf-8') as file:stopwords = set(file.read().split())# 去除停用词
filtered_words = [word for word in words if word not in stopwords]# 三国演义主要人物及其别名列表(扩展版)
characters = {"刘备": ["刘备", "玄德", "皇叔"],"关羽": ["关羽", "云长"],"张飞": ["张飞", "翼德"],"曹操": ["曹操", "孟德", "丞相", "曹孟德"],"孙权": ["孙权", "仲谋"],"诸葛亮": ["诸葛亮", "孔明", "卧龙"],"周瑜": ["周瑜", "公瑾"],"吕布": ["吕布", "奉先"],"貂蝉": ["貂蝉"],"赵云": ["赵云", "子龙"],"黄忠": ["黄忠", "汉升"],"马超": ["马超", "孟起"],"许褚": ["许褚", "仲康"],"典韦": ["典韦"],"司马懿": ["司马懿", "仲达"],"郭嘉": ["郭嘉", "奉孝"],"袁绍": ["袁绍", "本初"],"袁术": ["袁术", "公路"],"孙策": ["孙策", "伯符"],"甘宁": ["甘宁", "兴霸"],"鲁肃": ["鲁肃", "子敬"],"庞统": ["庞统", "凤雏"],"姜维": ["姜维", "伯约"]
}# 创建一个人物关系计数字典
relation_counts = defaultdict(int)# 遍历文本,统计人物间的关系
for i in range(len(filtered_words) - 1):for name1, aliases1 in characters.items():if filtered_words[i] in aliases1:for name2, aliases2 in characters.items():if filtered_words[i + 1] in aliases2 and name1 != name2:relation_counts[(name1, name2)] += 1# 创建网络图
G = nx.Graph()# 添加节点
for character in characters.keys():G.add_node(character)# 添加边及权重
for (name1, name2), count in relation_counts.items():G.add_edge(name1, name2, weight=count)# 绘制关系图
plt.figure(figsize=(14, 10))
pos = nx.spring_layout(G, k=1)
edges = G.edges(data=True)
weights = [edge[2]['weight'] for edge in edges]# 绘制节点和边
nx.draw(G, pos, with_labels=True, node_size=2000, node_color='skyblue', font_size=10, font_weight='bold', width=weights)# 在图中显示边的权重
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)plt.title('《三国演义》人物关系网(扩展版)')
plt.show()相关文章:
用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网 三国演义获取文本文本预处理分词与词频统计引入停用词后进行词频统计构建人物关系网完整代码 三国演义 《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间…...
k8s上使用ConfigMap 和 Secret
使用ConfigMap 和 Secret 实验目标: 学习如何使用 ConfigMap 和 Secret 来管理应用的配置。 实验步骤: 创建一个 ConfigMap 存储应用配置。创建一个 Secret 存储敏感信息(如数据库密码)。在 Pod 中挂载 ConfigMap 和 Secret&am…...
hexo实战:(二)个人独立博客优化合集
前言 上次介绍了使用 HexoGitHub Pages,零成本搭建一个专属自己的独立博客网站。我觉得那篇文章是没有入门门槛的,不管你是什么行业,只要想打造个人 IP,又不太想受博客平台约束,那么读完后动手操作一下也能轻松完成。…...

PostgreSQL的pg_relation_filepath函数
PostgreSQL的pg_relation_filepath函数 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777在 PostgreSQL 中&…...

Vue开发中Element UI/Plus使用指南:常见问题(如Missing required prop: “value“)及中文全局组件配置解决方案
文章目录 一、vue中使用el-table的typeindex有时不显示序号Table 表格显示索引自定义索引报错信息解决方案 二、vue中Missing required prop: “value” 报错报错原因解决方案 三、el-table的索引值index在翻页的时候可以连续显示方法一方法二 四、vue3中Element Plus全局组件配…...
安装golang
官网:All releases - The Go Programming Language (google.cn) 下载对应的版本安装即可...

Kubernetes面试整理-Kubernetes的主要组件有哪些?
Kubernetes 的主要组件分为控制平面组件和节点组件。以下是每个组件的详细介绍: 控制平面组件 1. API 服务器(kube-apiserver): ● 是 Kubernetes 控制平面的前端,接收、验证并处理所有的 API 请求。 ● 提供集群的管理接口,所有的集群操作都是通过 API 服务器进行的。...
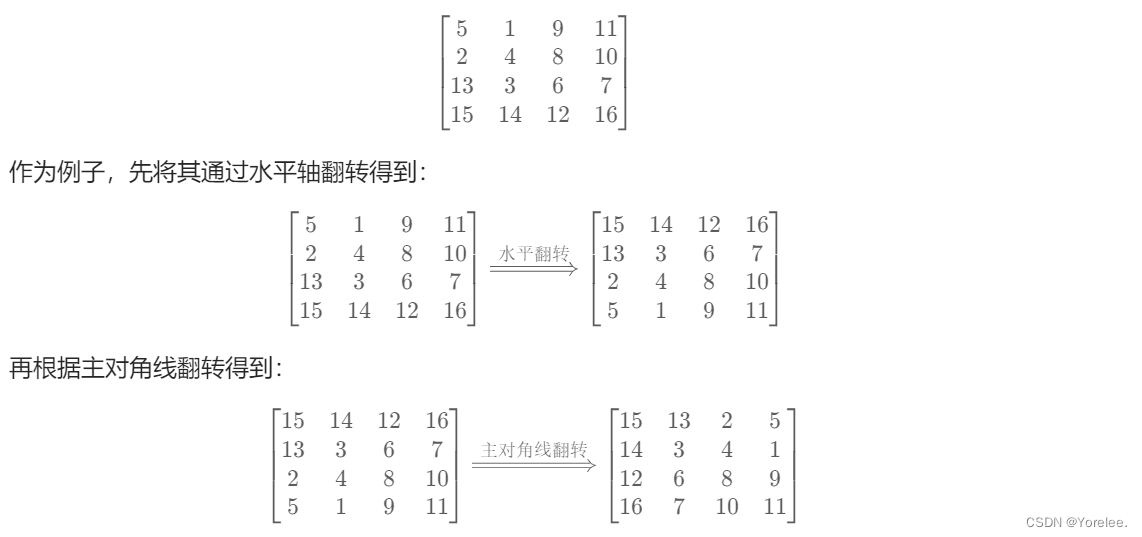
力扣hot100: 48. 旋转图像
LeetCode:48. 旋转图像 受到力扣hot100:54. 螺旋矩阵的启发,我们可以对旋转图像按层旋转,我们只需要记录四个顶点,并且本题是一个方阵,四个顶点就能完成图像的旋转操作。 1、逐层旋转 注意到࿰…...

基于FPGA的VGA协议实现
目录 一、VGA简介 二、VGA引脚的定义 三、VGA显示原理: 四、VESA标准下的VGA时序: 五、VGA显示模式以及相关参数: 六、数字信号与模拟信号的转换 实战演练一:VGA显示彩条 1、实验目标 2、各模块框图及其波形图 3、模块代…...

Java线程池的抛弃策略
Java线程池的抛弃策略 Java线程池是Java并发编程中非常重要的一个组件。它通过重用已创建的线程来减少线程创建和销毁的开销,从而提高应用程序的性能和响应速度。然而,当线程池中的任务数量超过其处理能力时,就需要一种机制来处理新提交的任…...

【python】Sklearn—Cluster
参考学习来自 10种聚类算法的完整python操作示例 文章目录 聚类数据集亲和力传播——AffinityPropagation聚合聚类——AgglomerationClusteringBIRCH——Birch(✔)DBSCAN——DBSCANK均值——KMeansMini-Batch K-均值——MiniBatchKMeans均值漂移聚类——…...
测试开发面经分享,面试七天速成 DAY 1
1. get、post、put、delete的区别 a. get请求: i. 用于从服务器获取资源。请求参数附加在URL的查询字符串中。 ii. 对服务器的请求是幂等的,即多次相同的GET请求应该返回相同的结果。 iii. 可以被缓存,可以被收藏为书签。 iv. 对于敏感数据不…...

C++ Primer Plus第五版笔记(p201-250)
第六章 函数(下) 在含有return语句的循环后面应该也有一条return语句 不要返回局部对象的引用或指针,当函数结束时临时对象占用的空间也就随之释放掉了,所以两条return语句都指向了不再可用的内存空间。 如果函数返回指针、引用…...
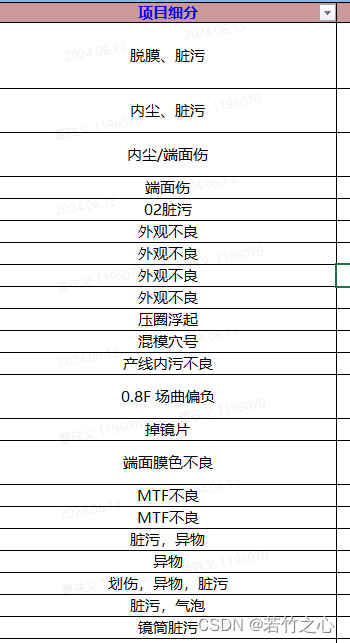
vba学习系列(5)--指定区域指定字符串计数
系列文章目录 文章目录 系列文章目录前言一、需求背景二、vba自定义函数1.引入库 总结 前言 一、需求背景 想知道所有客诉项目里面什么项目最多,出现过多少次。 二、vba自定义函数 1.引入库 引用: CountCharInRange(区域,“字符串”) Function CountCh…...

将Firefox插件导入Edge/Chrome中
目录 将Firefox插件导入Edge/Chrome中前言导出火狐插件.xpi格式插件导入edge/chorme中错误示范1错误示范2修改过程manifest.jsondict文件夹修改backgroundScript.jsinjectedScript.jsdebug过程最终backgroundScript.js和injectedScript.js代码 完工阶段修改后的源码 将Firefox插…...

云计算【第一阶段(14)】Linux的目录和结构
一、Liunx目录结构 1.1、linux目录结构 linux目录结构是树形目录结构 根目录(树根) 所有分区,目录,文件等的位置起点整个树形目录结构中,使用独立的一个"/",表示 1.2、常见的子目录 必须知道 目录路径目…...

Zynq学习笔记--AXI4-Stream到视频输出IP是如何工作的?
目录 1. 简介 2. 原理详解 2.1 示例工程 2.2 AXI4-Stream to Video Out 3. Master/Slave Timing Mode 3.1 Slave Timing Mode 3.2 Master Timing Mode 4. 总结 1. 简介 本文主要介绍了 AXI4-Stream 到视频输出 的内容。其中,示例工程展示了一个具体的设计&…...

2016-2023 年美国农业部作物序列边界
简介 2016-2023 年美国农业部作物序列边界 作物序列边界(CSB)是与美国农业部经济研究局合作开发的,它提供了美国毗连地区的田间边界、作物种植面积和作物轮作的估计数据。该数据集利用卫星图像和其他公共数据,并且是开放源码的,使用户能够对美国种植的商品进行面积和统计…...

数字人源码部署怎么做?如何高效搭建好用的数字人系统?
作为人工智能时代的风口项目,AI数字人自出现之日起便引发了大量的关注。不少创业者都有了搭建数字人系统的想法,但却苦于没有强大的专业背景和雄厚资金支撑,只能在局外徘徊,而这恰恰为数字人源码公司推出的数字人源码部署服务的火…...
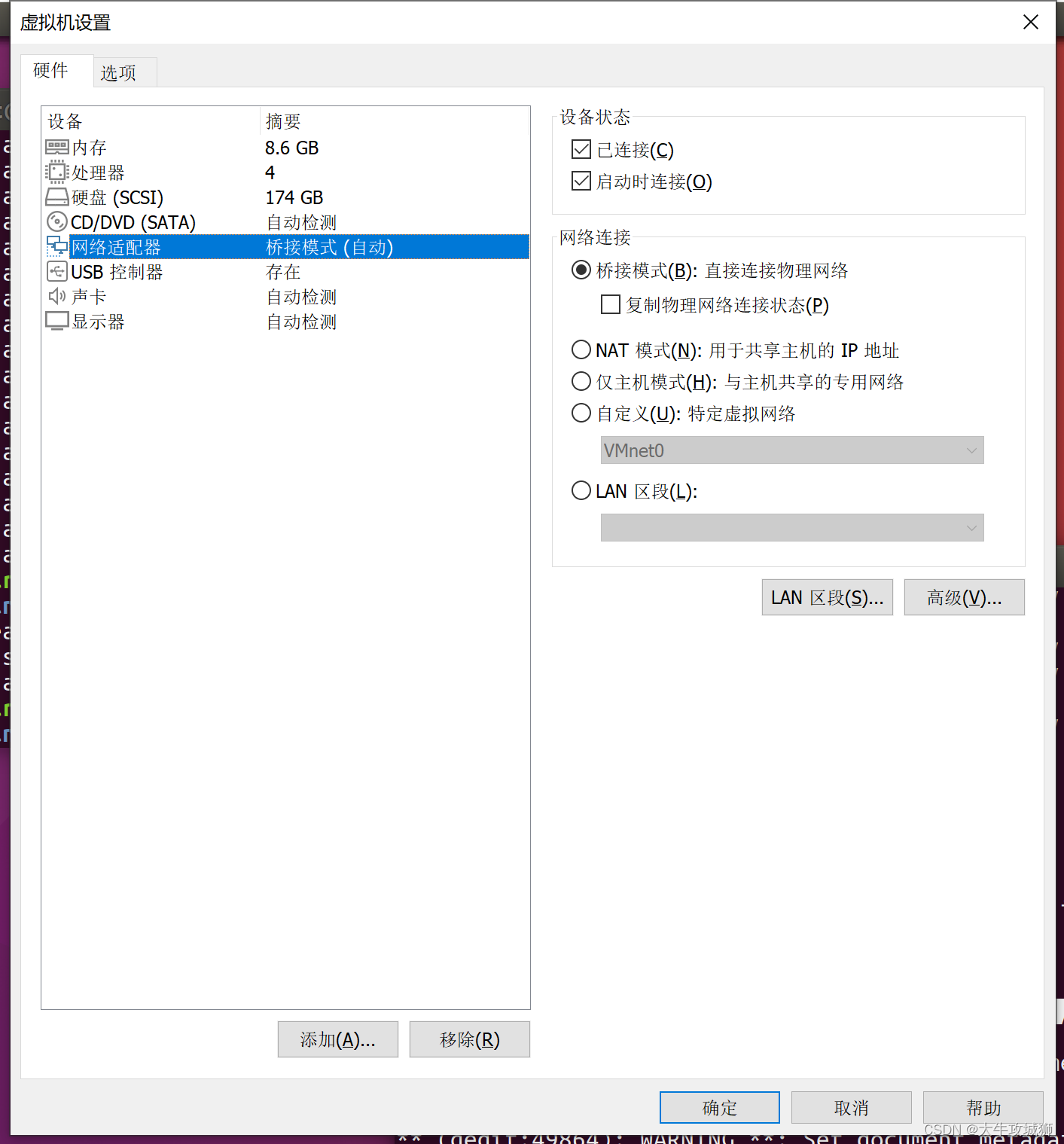
解决虚拟机Ubuntu IP总是掉的问题
问题 嵌入式开发过程中,需要使用NFS/TFTP等等,虚拟机Ubuntu就需要和板卡进行网络连接,但是我发现虚拟机Ubuntu的IP地址经常动不动就掉线,本文记录解决该问题的一些思路。 其实这个问题很简单,我早该想到,…...

AI智能体文化档案:用Next.js静态站点构建数字人类学观察站
1. 项目概述:一个观察AI智能体文化的数字档案馆最近在GitHub上闲逛,发现了一个让我眼前一亮的项目:The MoltStein Files。这可不是一个普通的代码仓库,而是一个专注于记录和存档AI智能体之间“社交”行为的数字档案馆。简单来说&a…...

汽车后市场品牌营销路径:以奇正沐古和康明斯为例
在汽车后市场,很多品牌真正的难题并非没有技术、没有产品、没有资源,而是这些优势到了终端之后,无法变成司机、经销商和维修点愿意相信、愿意推荐、愿意购买的理由。康明斯发动机润滑油就是个典型例子,康明斯作为全球柴油发动机技…...

【收藏】2026测试人必看!再不学大模型AI,真的要被行业淘汰了
最近和身边做测试的朋友闲聊,发现大家的焦虑感比往年更重了——有人做了3年功能测试,跳槽面试连初筛都过不了;有人深耕性能测试5年,薪资原地踏步,反而被刚入行、懂AI测试的新人弯道超车。 从ChatGPT横空出世引爆AI行业…...

在Node.js后端服务中集成Taotoken调用大模型指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用大模型指南 将大模型能力集成到后端服务是现代应用开发的常见需求。Taotoken平台提供了OpenA…...

Python 爬虫反爬突破:CDN 防护节点穿透采集
前言 当下大型互联网站点、电商平台资讯门户、行业数据网站均全面接入 CDN 内容分发网络,借助全球节点缓存、流量调度、智能分流、节点 IP 隐身、区域访问限制等机制构建底层防护体系。传统爬虫直接请求源站 IP 的方式会被 CDN 节点拦截、跳转、限速、IP 封禁、节点…...

3分钟掌握完全离线的实时语音转文字:TMSpeech让你彻底告别云端依赖
3分钟掌握完全离线的实时语音转文字:TMSpeech让你彻底告别云端依赖 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字时代,语音转文字已成为现代办公和学习的高效助手,但你是…...

在Taotoken模型广场中根据任务与预算选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场中根据任务与预算选择合适的模型 当开发者需要将大模型能力集成到自己的应用或工作流中时,面对市场…...

对比自行维护与使用Taotoken在模型接入效率上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护与使用Taotoken在模型接入效率上的差异 在开发需要集成大语言模型能力的应用时,团队通常面临一个核心选择…...

VR大空间项目屡获行业大奖,AI数字人公司赋能文旅智慧升级
在经历了早期的概念普及和单点试验后,AI数字人、VR、MR等技术正在文旅行业完成从“尝鲜”到“刚需”的蜕变。不再仅仅是博物馆或景区里的一块互动屏幕,而是一套能够重塑服务流程、活化文化IP、创造全新消费场景的完整解决方案。从边疆秘境到城市地标&…...

Windows运行Android应用终极指南:APK Installer让你的电脑秒变安卓手机
Windows运行Android应用终极指南:APK Installer让你的电脑秒变安卓手机 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在移动应用生态日益丰富的今天&…...