【python】Sklearn—Cluster

参考学习来自 10种聚类算法的完整python操作示例
文章目录
- 聚类数据集
- 亲和力传播——AffinityPropagation
- 聚合聚类——AgglomerationClustering
- BIRCH——Birch(✔)
- DBSCAN——DBSCAN
- K均值——KMeans
- Mini-Batch K-均值——MiniBatchKMeans
- 均值漂移聚类—— MeanShift
- OPTICS——OPTICS
- 光谱聚类——SpectralClustering
- 高斯混合模型——GaussianMixture(✔)
聚类数据集
sklearn.datasets.make_classification 是 Scikit-Learn 库中的一个函数,用于生成随机的多类分类问题数据集。以下是该函数的中文文档说明,包括参数和用法:
一、函数签名
sklearn.datasets.make_classification( n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None
)
二、参数说明
-
n_samples (int, 可选, 默认值=100): 要生成的样本数量。
-
n_features (int, 可选, 默认值=20): 要生成的特征数量。
-
n_informative (int, 可选, 默认值=2): 信息特征的数量,即实际影响目标变量的特征数量。
-
n_redundant (int, 可选, 默认值=2): 冗余特征的数量。这些特征是信息特征的随机线性组合。
-
n_repeated (int, 可选, 默认值=0): 从信息特征和冗余特征中随机抽取的重复特征的数量。
-
n_classes (int, 可选, 默认值=2): 分类问题的类别(或标签)数量。
-
n_clusters_per_class (int, 可选, 默认值=2): 每个类别的集群数量。
-
weights (list of floats or None, 可选, 默认值=None): 每个类别的样本权重。
-
flip_y (float, 可选, 默认值=0.01): 随机翻转目标变量y的比例。
-
class_sep (float, 可选, 默认值=1.0): 类别之间的分离程度。
-
hypercube (bool, 可选, 默认值=True): 如果为True,则数据从超立方体的顶点中抽取。
-
shift (float, 可选, 默认值=0.0): 特征值的范围移动量。
-
scale (float, 可选, 默认值=1.0): 特征值的缩放比例。
-
shuffle (bool, 可选, 默认值=True): 是否打乱样本和特征。
-
random_state (int, RandomState instance or None, 可选, 默认值=None): 控制随机性的种子或RandomState实例。
三、返回值
X (array of shape [n_samples, n_features]): 生成的样本数据。
y (array of shape [n_samples]): 每个样本的类别标签。
# 综合分类数据集
from numpy import where
from sklearn.datasets import make_classification
from matplotlib import pyplot
# 定义数据集
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 为每个类的样本创建散点图
for class_value in range(2):# 获取此类的示例的行索引row_ix = where(y == class_value)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()

亲和力传播——AffinityPropagation
sklearn.cluster.AffinityPropagation 是 Scikit-Learn 库中的一个聚类算法,它基于亲和传播(Affinity Propagation)进行聚类。以下是该算法的中文文档说明,包括参数、属性和用法:
一、参数(Parameters)
-
damping:float 类型,默认值为 0.5。阻尼系数,在 0.5 到 1 之间。这个参数决定了当前值相对于传入值(加权 1-阻尼)的保持程度,用于避免数值振荡。
-
max_iter:int 类型,默认值为 200。最大迭代次数。
-
convergence_iter:int 类型,默认值为 15。当估计的聚类数目连续 convergence_iter 次迭代都不再改变时,停止迭代。
-
copy:bool 类型,默认值为 True。是否对输入数据进行复制操作,以避免修改原始数据。
-
preference:array-like of shape (n_samples,) 或 float 类型,默认值为 None。每个点的偏好值。偏好值越大,该点越有可能被选作聚类中心。如果不指定偏好值,它们将被设置为输入相似性的中位数。
-
affinity:string 类型,默认值为 ‘euclidean’。用于计算数据点之间亲和度的度量方式。目前支持 ‘precomputed’ 和 ‘euclidean’。如果选择 ‘euclidean’,则使用点之间的负平方欧几里德距离作为亲和度。
-
verbose:bool 类型,默认值为 False。是否输出日志信息。
-
random_state:int 或 np.random.RandomStateInstance 类型,默认值为 None。用于控制随机性的种子或 RandomState 实例。
二、属性(Attributes)
-
cluster_centers_indices_:array-like of shape (n_clusters,)。聚类中心的索引。
-
labels_:array-like of shape (n_samples,)。每个样本的聚类标签。
-
n_iter_:int。实际迭代次数。
三、用法(Usage)
使用 AffinityPropagation 进行聚类时,首先需要创建一个 AffinityPropagation 的实例,并设置所需的参数。然后,使用 fit 方法对数据进行拟合,即可得到聚类结果。
# 亲和力传播聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AffinityPropagation(damping=0.9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
25

聚合聚类——AgglomerationClustering
AgglomerativeClustering,又称为聚合聚类,是一种基于距离的层次聚类算法。它采用自底向上的方式构建聚类层次,从将每个数据点作为单个聚类开始,然后迭代合并最接近的聚类对,直到所有数据点合并为一个聚类,或达到指定的聚类数量。
一、参数(Parameters)
-
n_clusters:整数,指定最终聚类中心的数量。如果不指定,算法将继续合并聚类直到只剩下一个聚类。
-
affinity:字符串或可调用对象,默认为’euclidean’。用于计算数据点之间距离的度量方法。例如,'euclidean’表示使用欧氏距离。
-
memory:用于缓存计算的结果,以便在多次调用fit和predict时提高效率。
-
connectivity:数组或可调用对象,用于定义数据点之间的连接性。如果指定,则算法将仅合并具有连接性的聚类。
-
compute_full_tree:布尔值,默认为False。如果为True,则构建一个完整的树并保存为children_属性。否则,只保存n_clusters个聚类。
-
linkage:字符串,默认为’ward’。确定合并聚类时使用的距离度量。'ward’使用方差最小化,'average’使用平均距离,'complete’使用最大距离。
-
distance_threshold:非负浮点数,默认为None。如果指定,则算法将在距离小于此阈值的聚类之间停止合并。
二、属性(Attributes)
-
labels_:每个数据点的聚类标签。
-
n_clusters_:聚类中心的数量。
-
children_:如果compute_full_tree为True,则保存层次聚类的树状结构。
三、步骤(Steps)
-
初始化:开始时,将每个数据点视为一个单独的聚类。
-
相似性度量:选择一个度量标准来衡量聚类之间的距离(如欧氏距离)。
-
连接准则:选择一个连接准则,这决定了作为观测对之间距离的函数的聚类集合之间的距离。常见的连接准则包括最短连接、最长连接和平均连接。
-
迭代合并:在每一步中,根据所选的距离和连接准则,找到最接近的聚类对并将它们合并为一个单独的聚类。更新存储聚类之间距离的距离矩阵。
-
终止:重复迭代合并,直到所有数据点合并为一个聚类或达到停止准则(例如,期望的聚类数量或距离阈值)。
四、优点与缺点
优点:
- 聚合聚类在距离和连接准则的选择上具有多样性,适用于各种数据集。
- 产生了一个层次结构,这对于不同规模的聚类数据结构是有信息量的。
缺点:
- 对于大数据集来说,它可能计算成本高,因为它需要在每次迭代中计算和更新所有聚类对之间的距离。
- 算法的结果可能对距离和连接准则的选择敏感。
五、应用
聚合聚类在多个领域都有广泛应用,包括生物学、文档和文本挖掘、图像分析以及客户细分等。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AgglomerativeClustering(n_clusters=2)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
2

BIRCH——Birch(✔)
sklearn.cluster.Birch 是 scikit-learn 库中的一个聚类算法,它实现了 Birch 聚类算法。Birch 是一种内存高效的在线学习算法,适用于大规模数据集。以下是关于 sklearn.cluster.Birch 的中文文档概述:
一、概述
Birch 聚类算法通过构建一个称为 CF 树(Clustering Feature Tree)的数据结构来进行聚类。CF 树由 CF(Clustering Feature)节点组成,每个 CF 节点是一个三元组,包含点的数量(N)、点的线性和(LS)以及 CF 各分量的平方和(SS)。Birch 算法能够识别数据集中数据分布的不均衡性,对稠密区域的数据进行更精细的聚类,同时能够处理稀疏区域的异常点。
二、参数(Parameters)
-
threshold:float 类型,默认值为 0.5。该参数定义了合并新样本和最近的子簇获得的子簇的半径阈值。如果合并后的子簇半径大于该阈值,则会启动一个新的子聚类。较小的值会促进子簇的分裂,而较大的值则会减少分裂。
-
branching_factor:int 类型,默认值为 50。该参数定义了每个节点中 CF 子聚类的最大数目。如果新的样本进入导致子簇数目超过该值,则节点会被分裂成两个节点,每个子簇重新分布。
-
n_clusters:int 或 sklearn.cluster 模型的实例,默认值为 3。该参数定义了最终聚类步骤后的簇数。如果设置为 None,则不执行最后的聚类步骤,子聚类按原样返回。如果提供一个 sklearn.cluster 估计器,则该模型将子聚类作为新样本处理进行拟合,并将初始数据映射到最近的子聚类的标签上。如果设置为整数,则使用 AgglomerativeClustering 模型进行最后的聚类。
-
compute_labels:bool 类型,默认值为 True。该参数决定是否为每次拟合计算标签。
-
copy:bool 类型,默认值为 True。如果设置为 False,则原始数据可能会被覆盖。
三、属性(Attributes)
-
root_:CF 树的根节点。
-
dummy_leaf_:指向所有叶子的指针(如果存在)。
-
subcluster_centers_:所有子簇的质心数组。
四、注意事项
Birch 算法是一种增量聚类方法,它基于已经处理过的数据点进行聚类决策,而不是全局的数据点。
Birch 算法适用于大规模数据集,因为它是一种内存高效的在线学习算法。
在使用 Birch 算法时,需要注意选择合适的 threshold 和 branching_factor 参数,这些参数会影响聚类的结果。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import Birch
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = Birch(threshold=0.01, n_clusters=2)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()

已经比较逼近真实的标签了
DBSCAN——DBSCAN
sklearn.cluster.DBSCAN 是 scikit-learn 库中的一个聚类算法,该算法基于密度的空间聚类,并能够在包含噪声的数据集中发现任意形状的簇。以下是对 sklearn.cluster.DBSCAN 的中文文档概述,按照要求以清晰的格式进行分点表示和归纳:
一、概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的空间聚类算法。它通过将具有足够高密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇。该算法是一种非监督式学习方法,不需要事先知道要聚成几类。
二、主要参数
-
eps(float, default=0.5):两个样本之间的最大距离,即扫描半径。一个点被视为另一个点的邻域内,当且仅当这两个点之间的距离小于或等于 eps。
-
min_samples(int, default=5):一个点被视为核心点的邻域内的样本数(或总权重)。这包括点本身。
-
metric(string, or callable, default=’euclidean’):用于计算特征数组中实例之间距离的度量。
-
algorithm({‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’):用于计算点态距离和寻找最近邻的算法。
三、主要属性
- core_sample_indices_:核心样本的索引数组。
- labels_:每个点的聚类标签。噪声点标记为-1。
四、算法步骤
-
遍历所有点:寻找核心点,即邻域内至少有 min_samples 个样本(包括自己)的点。
-
扩展聚类:从一个核心点出发,不断查找其邻域内的核心点,并将其加入当前聚类。
-
重复这个过程,直到当前聚类的边界无法再扩展。
-
标记噪声点:不属于任何聚类的点被标记为噪声点。
五、注意事项
-
eps 的选择:eps 是 DBSCAN 算法中一个非常重要的参数,它决定了聚类的密度。eps 过大,则可能导致原本不应该聚在一起的点被聚为一类;eps 过小,则可能导致原本应该聚在一起的点被拆散。
-
min_samples 的选择:min_samples 决定了核心点的定义。min_samples 过小,则可能导致过多的点被识别为核心点,从而导致聚类结果过于细碎;min_samples 过大,则可能导致过少的点被识别为核心点,从而导致聚类结果过于粗糙。
-
度量方式:根据数据的特性选择合适的度量方式,如欧氏距离、曼哈顿距离等。
六、总结
DBSCAN 是一种基于密度的聚类算法,适用于任意形状的聚类,并能有效处理噪声数据。通过调整 eps 和 min_samples 参数,可以控制聚类的密度和大小。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = DBSCAN(eps=0.30, min_samples=9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
3

K均值——KMeans
sklearn.cluster.KMeans
一、概述
KMeans算法是一种无监督学习方法,用于将数据点划分为K个聚类(或簇)。每个聚类的中心(或称为质心)是由该聚类中所有数据点的均值计算得出的。KMeans算法通过迭代的方式将数据点分配给最近的聚类中心,并重新计算聚类中心,直到聚类中心不再显著变化或达到预设的迭代次数。
二、主要参数
-
n_clusters: int类型,默认值为8。表示要生成的聚类数(即K值)。
-
init: 字符串或ndarray,默认值为’k-means++'。用于初始化聚类中心的方法。
‘k-means++’: 一种选择初始聚类中心的方法,可以加速收敛。
‘random’: 随机选择K个中心。
也可以传入一个形状为(n_clusters, n_features)的ndarray来指定初始聚类中心。 -
n_init: int类型,默认值为10。表示在不同初始中心上运行KMeans算法的次数,最终选择最优解(即最小惯性值或平方误差)对应的聚类结果。
max_iter: int类型,默认值为300。表示KMeans算法单次运行中的最大迭代次数。 -
tol: float类型,默认值为1e-4。表示容忍的最小优化值,即当聚类中心的变化小于该值时,算法会停止迭代。
三、其他参数
除了上述主要参数外,KMeans类还提供了其他一些参数,如:
-
precompute_distances: {‘auto’, True, False},预计算距离(可以加速计算,但占用更多内存)。
-
verbose: int类型,控制日志输出。
-
random_state: 控制随机种子,以确保结果的可重复性。
-
copy_x: bool类型,默认为True,表示是否对数据进行拷贝。如果为False,则直接在原始数据上进行操作,这可能会导致数据被修改。
四、注意事项
-
KMeans算法对初始中心的选择和K值的选择较为敏感,不同的初始中心和K值可能会导致不同的聚类结果。
-
在大规模数据集上,KMeans算法可能收敛较慢,可以通过增加max_iter或调整其他参数来优化性能。
-
KMeans算法只能找到凸形的聚类,对于非凸形的聚类或具有复杂形状的聚类可能效果不佳。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = KMeans(n_clusters=2)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
2

Mini-Batch K-均值——MiniBatchKMeans
sklearn.cluster.MiniBatchKMeans 是 scikit-learn 库中用于小批量 K-Means 聚类的一个类。以下是对其用法的中文文档概述:
一、简介
MiniBatchKMeans 是 K-Means 聚类的一个变体,它使用小批量样本来更新质心,从而降低了计算成本。这使得 MiniBatchKMeans 在处理大型数据集时更加高效,尤其是当数据集不适合一次性加载到内存中时。
二、参数
-
n_clusters (int, default=8): 要形成的簇数以及要生成的质心数。
-
init ({‘k-means++’, ‘random’ 或一个 ndarray, 或一个可调用的}, default=‘k-means++’): 初始化质心的方法。
‘k-means++’: 以智能方式为 K-Means 聚类选择初始聚类中心以加速收敛。
‘random’: 从数据中随机选择 n_clusters 个观测值作为初始质心。 -
max_iter (int, default=100): 在任何早期停止标准启发式停止之前,对完整数据集的最大迭代次数。
-
batch_size (int, default=1024): 小批量的大小。
-
verbose (int, default=0): 详细模式。
-
compute_labels (bool, default=True): 一旦小批量优化收敛到合适的位置,计算整个数据集的标签分配和惯性。
-
random_state (int, RandomState instance, 或 None, default=None): 确定质心初始化和随机重新分配的随机数生成。
-
tol (float, default=0.0): 两次连续迭代之间的相对容差,以判断收敛性。
-
max_no_improvement (int, default=10): 连续多少次迭代没有改善时停止。
-
init_size (int 或 None, default=None): 用于“k-means++”初始化的样本数。
-
n_init (int, default=3): 用不同的质心种子运行算法的次数,并选择最佳初始化。
-
reassignment_ratio (float, default=0.01): 用于“k-means++”初始化的重分配阈值。
三、属性
-
cluster_centers_ (array-like, shape (n_clusters, n_features)): 簇的质心。
-
labels_ (array-like, shape (n_samples,)): 每个样本的标签。
-
inertia_ (float): 簇内平方和,即每个样本到其所属簇的质心的距离的平方和。
四、注意事项
-
由于 MiniBatchKMeans 使用小批量数据来更新质心,因此它的结果可能略不同于标准的 K-Means 算法。
-
如果你的数据集适合一次性加载到内存中,并且计算资源足够,那么标准的 KMeans 可能更准确。
-
在使用 MiniBatchKMeans 时,可能需要调整 batch_size 以获得最佳的性能和准确性之间的权衡。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MiniBatchKMeans(n_clusters=2)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
2

均值漂移聚类—— MeanShift
sklearn.cluster.MeanShift 是 scikit-learn 库中的一个聚类算法,它基于非参数密度估计进行聚类。以下是对 MeanShift 的中文文档概述:
一、算法介绍
MeanShift 是一种基于质心的算法,它尝试找到数据分布中的密集区域。它的工作原理是通过不断更新候选质心,使其成为给定区域内点的均值。这个过程类似于“梯度上升”,即寻找数据分布中概率密度的局部最大值。
二、参数说明
-
bandwidth (float, optional):定义用于核函数估计的窗口大小,也称为“带宽”。较大的带宽意味着更大的平滑度,可能导致更多的点被归类到同一个簇中。默认值为 None,通常需要根据数据集进行调整。
-
seeds (array-like, shape=[n_seeds, n_features], optional):指定用于初始化质心的种子点。如果为 None,则使用数据集中的点作为种子。默认值为 None。
-
bin_seeding (boolean, optional):如果设置为 True,则使用二进制方法进行质心初始化,这可能会加速算法但可能影响结果的质量。默认值为 False。
-
min_bin_freq (int, optional):在二进制种子初始化中使用的最小箱频率。这决定了在初始化质心时,至少需要多少个点落入同一个箱中。默认值为 1。
其他参数还包括 cluster_all、n_jobs 和 max_iter 等,但它们在大多数情况下不是必需的。
三、主要属性
- cluster_centers_ (array-like, shape=[n_clusters, n_features]):每个簇的质心。
- labels_ (array-like, shape=[n_samples]):每个样本的簇标签。
四、工作流程
- 初始化:随机选择数据集中的点或使用提供的种子点作为初始质心。
- 迭代过程:
对于每个质心,计算其周围区域(由 bandwidth 定义)内所有点的均值。
将质心移动到计算出的均值位置。
重复此过程,直到质心的移动小于某个阈值或达到最大迭代次数。 - 合并簇:如果两个质心的距离小于某个阈值,则将它们合并为一个簇。
- 分配标签:对于新样本,找到其最近的质心,并将其分配给相应的簇。
五、注意事项
-
MeanShift 算法对 bandwidth 参数非常敏感,不同的值可能会导致截然不同的聚类结果。
-
由于 MeanShift 算法需要计算每个质心周围区域内所有点的均值,因此它在大型数据集上可能会变得非常慢。
-
MeanShift 可以发现任意形状的簇,但可能会受到噪声和异常值的影响。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MeanShift
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MeanShift()
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
3

OPTICS——OPTICS
需要 scikit-learn 0.24 以上
sklearn中的OPTICS(Ordering Points To Identify the Clustering Structure)算法是一种基于密度的聚类算法,它是DBSCAN算法的一种改进。以下是sklearn OPTICS的中文文档概述,结合相关数字和信息进行了详细解释:
一、算法介绍
OPTICS算法是一种基于密度的聚类算法,它旨在通过发现数据集中样本的可达性(reachability)来识别出不同的聚类结构。OPTICS算法可以看作是DBSCAN算法的扩展,它克服了DBSCAN算法对邻域参数ε(epsilon)的敏感性,并允许用户通过可达性图(reachability plot)来灵活选择不同密度的聚类。
二、主要参数
- min_samples (int > 1 或 float between 0 and 1, default=5):一个点被视为核心点的邻域样本数。如果设置为浮点数,则表示为样本数的小数部分(至少四舍五入为2)。
- max_eps (float, optional, default=inf):两个样本之间的最大距离,其中一个被视为另一个样本的邻域。较大的值会识别出更大规模的聚类;减小该值可以缩短运行时间。
- metric (str 或 callable, optional, default=‘minkowski’):用于距离计算的度量标准。
- p (int, optional, default=2):当使用Minkowski距离时,该参数指定了距离的幂次。
- metric_params (dict, optional):用于距离计算的额外关键字参数。
- cluster_method (str, optional, default=‘xi’):用于从可达性图中提取簇的方法。'xi’表示使用Xi方法;'dbscan’表示使用类似于DBSCAN的方法。
- eps (float, optional):在cluster_method='dbscan’时使用的邻域参数。注意,当使用OPTICS时,eps参数被忽略。
- xi (float, optional, default=0.05):在cluster_method='xi’时使用的参数,用于确定哪些点被视为簇的一部分。
- predecessor_correction (bool, optional, default=True):是否对可达性图中的前驱节点进行校正。
- min_cluster_size (float or None, optional):作为簇一部分所需的最小样本数比例。如果为None,则不应用此限制。
三、主要属性
- labels_ (array-like, shape=(n_samples,)): 每个样本的簇标签。未分配到任何簇的样本将被标记为-1。
- cluster_hierarchy_ (array-like, shape=(n_samples, 2)):每个样本的可达性和其前驱节点的索引。这是算法生成的可达性图的表示。
四、工作流程
-
初始化:设置参数,包括邻域样本数、最大距离等。
-
计算可达性:对于数据集中的每个样本,计算其与其他样本的可达性,并记录其前驱节点。
-
提取簇:根据选择的cluster_method(‘xi’或’dbscan’),从可达性图中提取出不同密度的簇。
-
分配标签:为数据集中的每个样本分配簇标签。
五、注意事项
-
OPTICS算法对min_samples参数的选择较为敏感,需要根据数据集的特性进行调整。
-
与DBSCAN相比,OPTICS算法提供了更多的灵活性,允许用户通过可达性图来观察不同密度的聚类结构。
-
在处理大型数据集时,OPTICS算法可能会比DBSCAN更加耗时,因为它需要计算每个样本的可达性。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = OPTICS(eps=0.8, min_samples=10)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
17

光谱聚类——SpectralClustering
sklearn.cluster.SpectralClustering 是 scikit-learn 库中提供的一个谱聚类算法的实现。以下是对 SpectralClustering 的中文文档概述:
一、算法介绍
SpectralClustering 是一种基于图论的聚类方法,它将数据样本视为图上的节点,并通过节点之间的相似度(或称为边)来构建图。然后,算法利用图的拉普拉斯矩阵(Laplacian matrix)的特征值和特征向量来进行聚类。谱聚类特别适用于处理非凸形状的簇或当传统的距离度量无法很好描述数据分布时。
二、主要参数
- n_clusters (int, optional, default=8):需要形成的簇的个数。
- affinity (str or callable, default=‘rbf’):
‘nearest_neighbors’:使用最近邻方法构建相似度矩阵。
‘rbf’:使用径向基函数(Radial basis function)作为核函数来计算相似度矩阵。
其他选项包括 ‘precomputed’(预计算的相似度矩阵)、‘linear’(线性核)等。 - gamma (float, default=1.0):当使用 ‘rbf’、‘poly’ 或 ‘sigmoid’ 作为 affinity 参数时,该参数为核函数的系数。对于 ‘rbf’,它决定了函数宽度。
- n_neighbors (int, default=10):当 affinity 设置为 ‘nearest_neighbors’ 时,用于确定每个点的邻居数量。
- eigen_solver ({‘auto’, ‘arpack’, ‘lobpcg’, ‘amg’}, default=‘auto’):用于计算拉普拉斯矩阵特征值的求解器。
- assign_labels ({‘kmeans’, ‘discretize’}, default=‘kmeans’):用于将特征向量转换为聚类标签的方法。
- random_state (int, RandomState instance, default=None):随机数生成器的种子或实例,用于可复现的结果。
三、主要属性
- labels_ (array-like, shape (n_samples,)):每个样本的簇标签。
- affinity_matrix_ (array-like, shape (n_samples, n_samples)):用于聚类的相似度矩阵(如果 affinity 参数设置为 ‘precomputed’ 除外)。
四、工作流程
- 构建相似度矩阵:根据选定的 affinity 参数,计算数据点之间的相似度矩阵。
- 计算拉普拉斯矩阵:基于相似度矩阵,计算归一化的拉普拉斯矩阵。
- 求解特征值和特征向量:使用指定的 eigen_solver 求解拉普拉斯矩阵的特征值和特征向量。
- 分配簇标签:根据选定的 assign_labels 方法,将特征向量转换为簇标签。
五、注意事项
- 参数选择:谱聚类的效果对参数的选择(特别是 n_clusters、affinity 和 gamma)非常敏感。因此,可能需要通过实验来确定最佳的参数设置。
- 计算复杂度:谱聚类算法的计算复杂度通常较高,特别是在处理大型数据集时。因此,在选择算法时需要考虑到计算资源和时间成本。
- 数据预处理:在使用谱聚类之前,通常需要对数据进行适当的预处理,如缩放或归一化,以确保算法的有效性。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = SpectralClustering(n_clusters=2)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()

高斯混合模型——GaussianMixture(✔)
一、算法介绍
GaussianMixture 类实现了高斯混合模型(GMM),这是一种概率模型,表示数据点是由未知参数的有限数量的高斯分布混合生成的。GMM 是一种无监督学习算法,常用于聚类分析、概率密度估计等领域。
二、主要参数
- n_components (int, default=1):混合模型中高斯分布的数量,即聚类的数量。
- covariance_type ({‘full’, ‘tied’, ‘diag’, ‘spherical’}, default=‘full’):
‘full’:每个组件都有自己的协方差矩阵。
‘tied’:所有组件共享同一个协方差矩阵。
‘diag’:每个组件都有自己的对角协方差矩阵。 - ‘spherical’:每个组件的协方差矩阵都是球面协方差矩阵,即对角线元素相同,非对角线元素为零。
- tol (float, default=1e-3):EM(期望最大化)算法的收敛阈值。
- reg_covar (float, default=1e-6):协方差矩阵对角线上的正则化项。
- max_iter (int, default=100):EM 算法的最大迭代次数。
- n_init (int, default=1):初始化EM算法的次数,用于找到最佳参数。
- init_params ({‘kmeans’, ‘random’}, default=‘kmeans’):初始化方法,可以是 ‘kmeans’ 或 ‘random’。
- weights_init (array-like of shape (n_components,), default=None):各个高斯分布的初始权重。
- means_init (array-like of shape (n_components, n_features), default=None):各个高斯分布的初始均值。
- precisions_init (array-like of shape (n_components, n_features, n_features), default=None):各个高斯分布的初始精度矩阵(协方差矩阵的逆)。
三、主要属性
weights_ (array-like of shape (n_components,)):每个高斯分布的权重。
means_ (array-like of shape (n_components, n_features)):每个高斯分布的均值。
covariances_ (list of array-like):每个高斯分布的协方差矩阵。其形状取决于 covariance_type 参数。
precisions_ (list of array-like):每个高斯分布的精度矩阵(协方差矩阵的逆)。
precisions_cholesky_ (list of array-like):每个高斯分布的精度矩阵的Cholesky分解。
四、主要方法
-
fit(X):从数据 X 中学习高斯混合模型。
-
predict(X):预测每个样本 X 属于哪个高斯分布(即哪个聚类)。
-
predict_proba(X):预测每个样本 X 属于各个高斯分布的概率。
-
score(X):返回给定数据 X 下模型的平均对数似然值。
-
sample(n_samples=1):从模型中生成新的样本。
五、注意事项
-
选择合适的 n_components:n_components 参数的选择对模型性能至关重要,它决定了聚类的数量。可以使用如BIC(贝叶斯信息准则)等方法来选择合适的 n_components 值。
-
正则化:当数据点不足或协方差矩阵难以估计时,可以通过设置 reg_covar 参数来避免协方差矩阵的奇异性。
-
初始化方法:init_params 参数可以选择 ‘kmeans’ 或 ‘random’ 初始化方法。‘kmeans’ 方法通常更快且更稳定,但 ‘random’ 方法有时可能找到更好的局部最优解。
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = GaussianMixture(n_components=2)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
print(len(clusters))# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()
output
2

相关文章:
【python】Sklearn—Cluster
参考学习来自 10种聚类算法的完整python操作示例 文章目录 聚类数据集亲和力传播——AffinityPropagation聚合聚类——AgglomerationClusteringBIRCH——Birch(✔)DBSCAN——DBSCANK均值——KMeansMini-Batch K-均值——MiniBatchKMeans均值漂移聚类——…...
测试开发面经分享,面试七天速成 DAY 1
1. get、post、put、delete的区别 a. get请求: i. 用于从服务器获取资源。请求参数附加在URL的查询字符串中。 ii. 对服务器的请求是幂等的,即多次相同的GET请求应该返回相同的结果。 iii. 可以被缓存,可以被收藏为书签。 iv. 对于敏感数据不…...

C++ Primer Plus第五版笔记(p201-250)
第六章 函数(下) 在含有return语句的循环后面应该也有一条return语句 不要返回局部对象的引用或指针,当函数结束时临时对象占用的空间也就随之释放掉了,所以两条return语句都指向了不再可用的内存空间。 如果函数返回指针、引用…...
vba学习系列(5)--指定区域指定字符串计数
系列文章目录 文章目录 系列文章目录前言一、需求背景二、vba自定义函数1.引入库 总结 前言 一、需求背景 想知道所有客诉项目里面什么项目最多,出现过多少次。 二、vba自定义函数 1.引入库 引用: CountCharInRange(区域,“字符串”) Function CountCh…...

将Firefox插件导入Edge/Chrome中
目录 将Firefox插件导入Edge/Chrome中前言导出火狐插件.xpi格式插件导入edge/chorme中错误示范1错误示范2修改过程manifest.jsondict文件夹修改backgroundScript.jsinjectedScript.jsdebug过程最终backgroundScript.js和injectedScript.js代码 完工阶段修改后的源码 将Firefox插…...

云计算【第一阶段(14)】Linux的目录和结构
一、Liunx目录结构 1.1、linux目录结构 linux目录结构是树形目录结构 根目录(树根) 所有分区,目录,文件等的位置起点整个树形目录结构中,使用独立的一个"/",表示 1.2、常见的子目录 必须知道 目录路径目…...

Zynq学习笔记--AXI4-Stream到视频输出IP是如何工作的?
目录 1. 简介 2. 原理详解 2.1 示例工程 2.2 AXI4-Stream to Video Out 3. Master/Slave Timing Mode 3.1 Slave Timing Mode 3.2 Master Timing Mode 4. 总结 1. 简介 本文主要介绍了 AXI4-Stream 到视频输出 的内容。其中,示例工程展示了一个具体的设计&…...

2016-2023 年美国农业部作物序列边界
简介 2016-2023 年美国农业部作物序列边界 作物序列边界(CSB)是与美国农业部经济研究局合作开发的,它提供了美国毗连地区的田间边界、作物种植面积和作物轮作的估计数据。该数据集利用卫星图像和其他公共数据,并且是开放源码的,使用户能够对美国种植的商品进行面积和统计…...

数字人源码部署怎么做?如何高效搭建好用的数字人系统?
作为人工智能时代的风口项目,AI数字人自出现之日起便引发了大量的关注。不少创业者都有了搭建数字人系统的想法,但却苦于没有强大的专业背景和雄厚资金支撑,只能在局外徘徊,而这恰恰为数字人源码公司推出的数字人源码部署服务的火…...
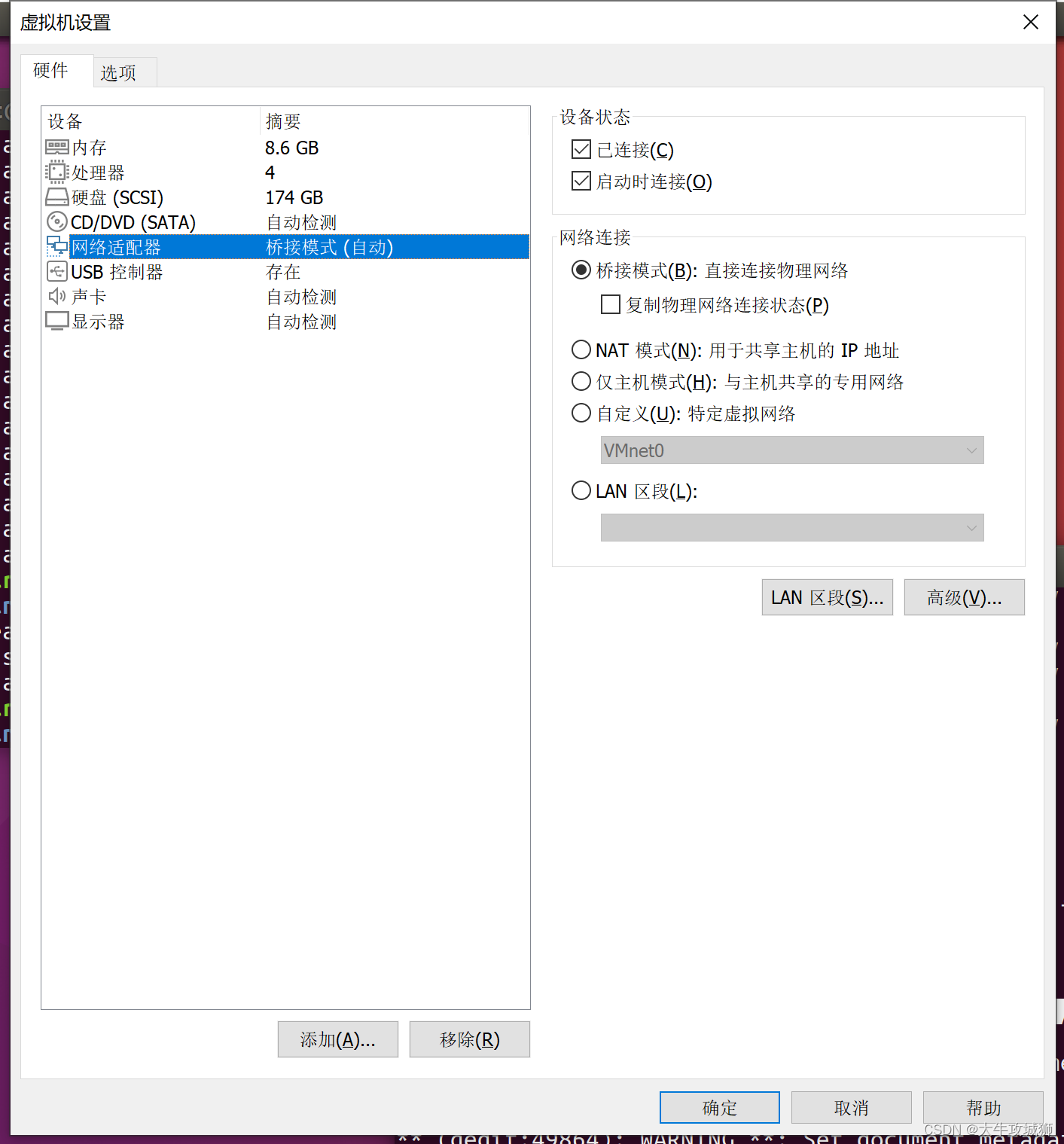
解决虚拟机Ubuntu IP总是掉的问题
问题 嵌入式开发过程中,需要使用NFS/TFTP等等,虚拟机Ubuntu就需要和板卡进行网络连接,但是我发现虚拟机Ubuntu的IP地址经常动不动就掉线,本文记录解决该问题的一些思路。 其实这个问题很简单,我早该想到,…...

[13] CUDA_Opencv联合编译过程
CUDA_Opencv联合编译过程 详细编译过程可见我之前的文章:Win10下OpencvCUDA联合编译详细教程(版本455、460、470,亲测可用!!!)本文给出Windows\linux下的opencvcuda的编译总结,摘自 <基于GP…...

uni-app canvas创建画布
canvasTmp: function(arr2, store_name, successFn, errFun) {let that this;const ctx uni.createCanvasContext(myCanvas);ctx.clearRect(0, 0, 0, 0);/*** 只能获取合法域名下的图片信息,本地调试无法获取* */uni.getImageInfo({ src: arr2[0],success: function(res) {…...
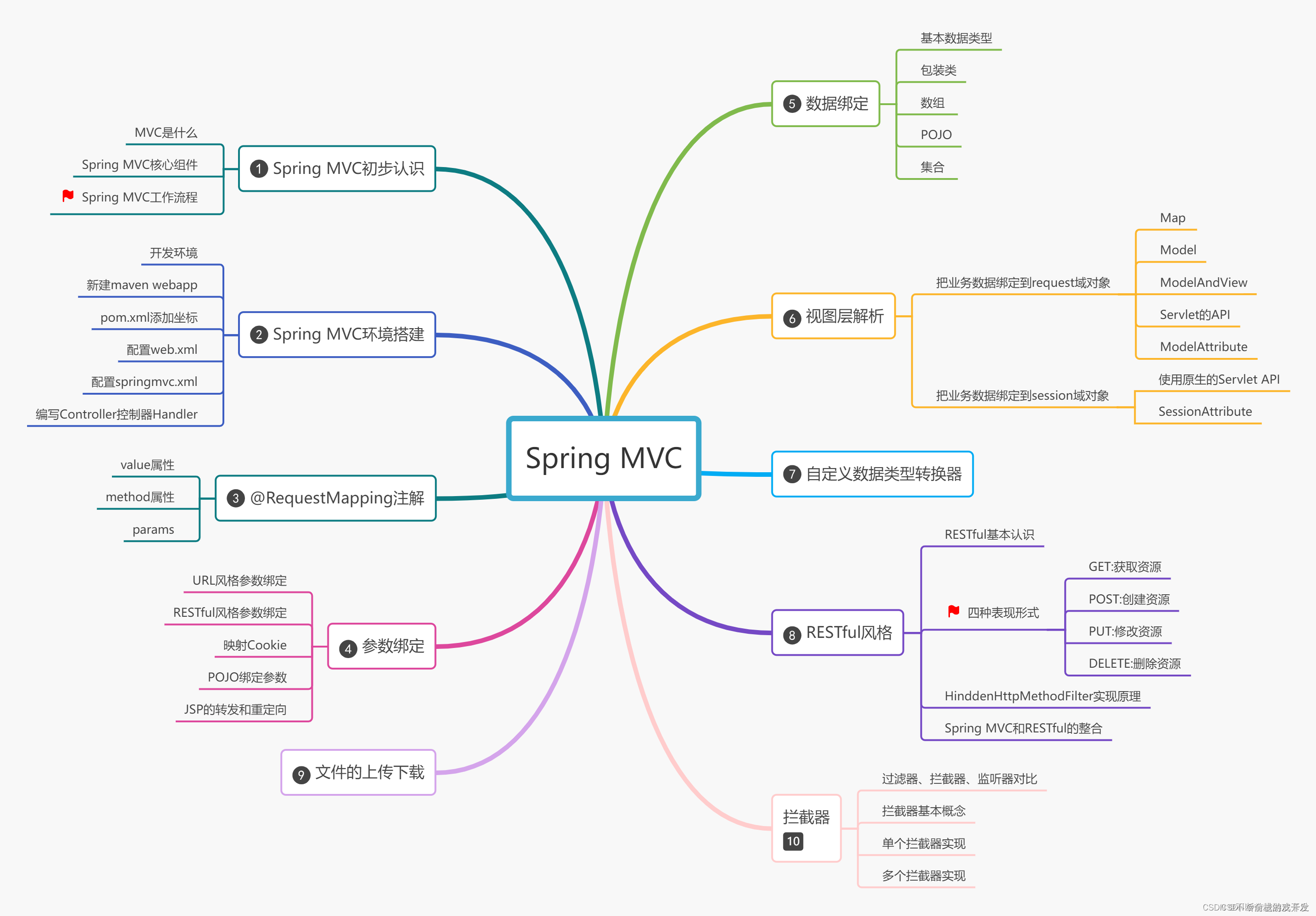
Spring MVC详解(上)
一、Spring MVC初步认识 1.1介绍 Spring MVC是Spring Framework提供的Web组件,全称是Spring Web MVC,是目前主流的实现MVC设计模式的框架,提供前端路由映射、视图解析等功能 Java Web开发者必须要掌握的技术框架 1.2MVC是什么 MVC是一种软件架构思想…...
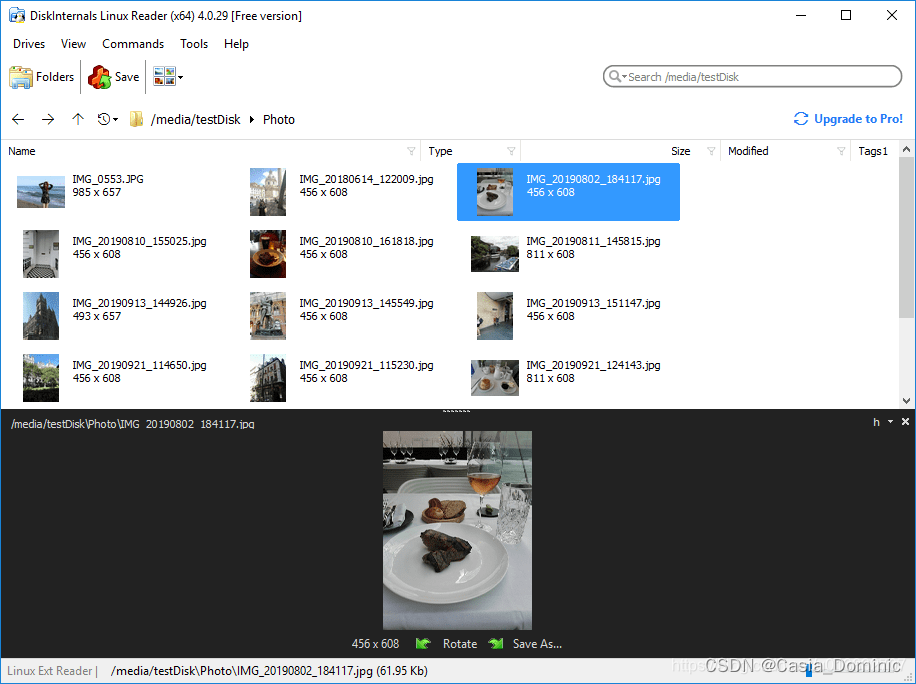
【Linux硬盘读取】Windows下读取Linux系统的文件解决方案:Linux Reader4.5 By DiskInternals
前言 相信做机器视觉相关的很多人都会安装 Windows 和 Linux 双系统。在 Linux 下,我们可以很方便的访问Windows的磁盘,反过来却不行。但是这又是必须的。通过亲身体验,向大家推荐这么一个工具,可以让 Windows 方便的访问 Ext 2/3…...

操作系统—页表(实验)
文章目录 页表1.实验目标2.实验过程记录(1).增加打印页表函数(2).独立内核页表(3).简化软件模拟地址翻译 3.实验问题及相应解答问题1问题2问题3问题4 实验小结 页表 1.实验目标 了解xv6内核当中页表的实现原理,修改页表,使内核更方便地进行用户虚拟地址…...
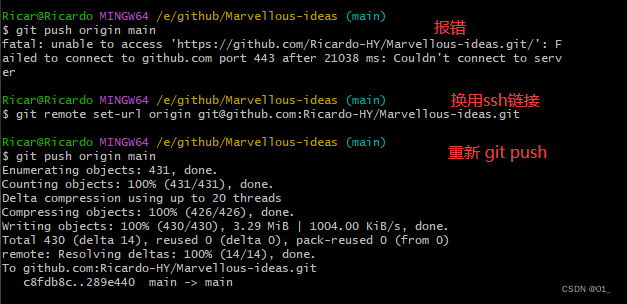
github 本地仓库上传及报错处理
一.本地文件上传 这里为上传部分,关于gitbash安装配置,读者可自行搜索,由于已经安装完成,未进行截图保存,这里便不做赘述。 1.登录git账号并创建一个仓库 点击仓库打开后会看到这个仓库的网址链接(这个链…...
)
【ZZULIOJ】1104: 求因子和(函数专题)
题目描述 输入正整数n(2<n<1000),计算并输出n的所有正因子(包括1,不包括自身)之和。要求程序定义一个FacSum ()函数和一个main()函数,FacSum ()函数计算并返回n的所有正因子之和,其余功能在main()函…...

轨迹优化 | 图解欧氏距离场与梯度场算法(附ROS C++/Python实现)
目录 0 专栏介绍1 什么是距离场?2 欧氏距离场计算原理3 双线性插值与欧式梯度场4 仿真实现4.1 ROS C实现4.2 Python实现 0 专栏介绍 🔥课程设计、毕业设计、创新竞赛、学术研究必备!本专栏涉及更高阶的运动规划算法实战:曲线生成…...

【二维差分】2132. 用邮票贴满网格图
本文涉及知识点 二维差分 LeetCode2132. 用邮票贴满网格图 给你一个 m x n 的二进制矩阵 grid ,每个格子要么为 0 (空)要么为 1 (被占据)。 给你邮票的尺寸为 stampHeight x stampWidth 。我们想将邮票贴进二进制矩…...
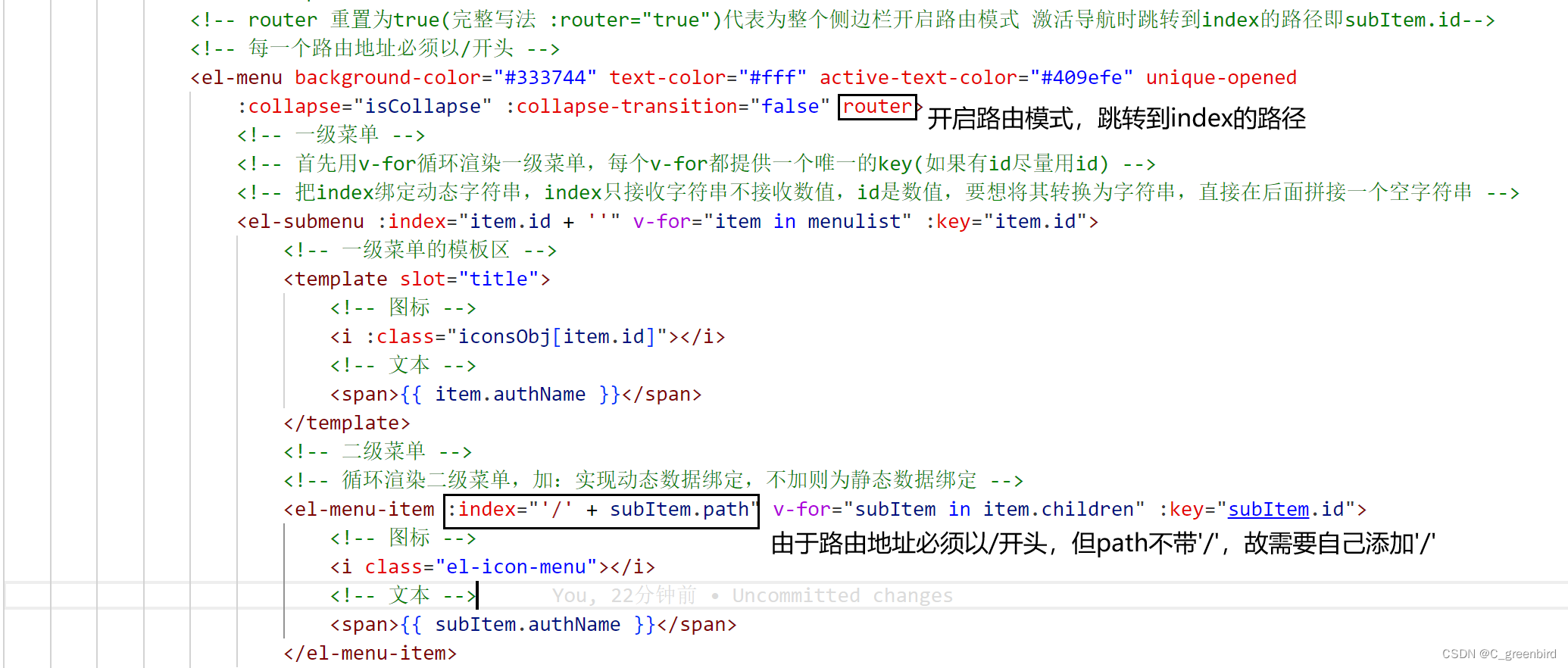
【前端项目笔记】2 主页布局
主页布局 element-ui提供的组件名称就是它的类名 ☆☆ CSS选择器: (1)基本选择器 类型选择器 p/span/div…… 类选择器 (.classname) ID选择器 (#idname) 通配选择器 ( * ) (2)属性选择器 选择具有特定属性或属性值的…...

5V/7.4V/12V三个升压档位!智能门锁供电选它
在智能门锁硬件设计与实操过程中,常见的痛点是锂电池的常见电压(3.7V、3.2V)与门锁电机的工作电压需求(5V、7.4V、甚至12V)不匹配,电压不足直接导致电机无法正常驱动,进而影响门锁开关功能的实现…...
:92.7%可维护性提升背后的11个关键断点)
AI时代Clean Code新标准(DeepSeek R1实测验证版):92.7%可维护性提升背后的11个关键断点
更多请点击: https://intelliparadigm.com 第一章:AI时代Clean Code范式迁移的必然性 当大语言模型能自动生成函数、修复漏洞、甚至重构整包逻辑时,“可读性优先”的传统Clean Code原则正遭遇结构性挑战。人类开发者编写的代码不再唯一面向…...

Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析
Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一款高性能的Adobe ExtendScript二进制格式(JSXBIN&#…...

OFIRM 视角下的多重宇宙:双拐点确认度增长模型之本宇宙V4.1开篇,我提出一个深刻的哲学问题:如果宇宙全部演化都可以被一个数学公式精确描述,那么人类独立意识应该如何定位?我思考一夜,越想越觉得恐怖
OFIRM 视角下的多重宇宙:双拐点确认度增长模型之本宇宙V4.1开篇,我提出一个深刻的哲学问题:如果宇宙全部演化都可以被一个数学公式精确描述,那么人类独立意识应该如何定位?我思考一夜,越想越觉得恐怖 问&am…...
)
从“能用”到“愿用”:Lovable Serverless平台的6大心理学设计法则(基于87家头部企业DevOps调研数据)
更多请点击: https://intelliparadigm.com 第一章:从“能用”到“愿用”:Lovable Serverless平台的认知跃迁 Serverless 并非仅关于函数执行与自动扩缩——真正的分水岭在于开发者是否**主动选择、持续信任并乐于传播**该平台。当运维负担归…...

票据的采集,更新业务 todo 抽空迁移并废弃掉
采集过程 用户校验 参数校验部分 代码号码开票日期校验码(普票或电票必须)金额 是否有id,有id说明已存在,则应该是更新(该用更新接口)如果能查到,说明重复采集了查不到,新增存库...

Taotoken提供的审计日志功能如何满足企业级安全与合规需求
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken提供的审计日志功能如何满足企业级安全与合规需求 1. 企业引入大模型能力后的审计挑战 当企业将大模型API能力整合到内部…...

Yunzai-Bot阴天插件:免费集成百款AI大模型的QQ机器人全能助手
1. 项目概述与核心价值如果你正在寻找一个能让你在QQ机器人上免费、便捷地体验上百种主流AI大模型的解决方案,那么“阴天插件”(Y-Tian-Plugin)绝对值得你花时间深入了解。作为一名长期混迹于机器人开发社区的开发者,我见过太多要…...

Aegon协议:AI内容授权的可信审计架构解析
1. Aegon协议:AI内容授权的可信审计架构在AI内容爆炸式增长的今天,版权合规已成为行业核心痛点。传统授权方案存在三大致命缺陷:一是缺乏可验证的访问记录,二是无法追踪内容在AI处理流水线中的流转,三是移动端完全处于…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...