操作系统—页表(实验)
文章目录
- 页表
- 1.实验目标
- 2.实验过程记录
- (1).增加打印页表函数
- (2).独立内核页表
- (3).简化软件模拟地址翻译
- 3.实验问题及相应解答
- 问题1
- 问题2
- 问题3
- 问题4
- 实验小结
页表
1.实验目标
了解xv6内核当中页表的实现原理,修改页表,使内核更方便地进行用户虚拟地址的翻译。
2.实验过程记录
(1).增加打印页表函数
操作内容: 在VS Code中修改代码,增加打印页表函数
首先打开kernel/defs.h文件,找到// vm.c部分增加一个函数声明:
// vm.c
void kvminit(void);
void kvminithart(void);
uint64 kvmpa(uint64);
void kvmmap(uint64, uint64, uint64, int);
int mappages(pagetable_t, uint64, uint64, uint64, int);
pagetable_t uvmcreate(void);
void uvminit(pagetable_t, uchar *, uint);
uint64 uvmalloc(pagetable_t, uint64, uint64);
uint64 uvmdealloc(pagetable_t, uint64, uint64);
// + vmprint declaration
void vmprint(pagetable_t);
在增加了函数声明之后,在exec.c文件中对exec函数也增加一个对应打印页表信息的操作(这里忽略了增加代码前后的部分信息):
int exec(char *path, char **argv) {…// + Use vmprint to print page infoif (p->pid == 1) {vmprint(p->pagetable);}return argc; // this ends up in a0, the first argument to main(argc, argv)bad:…
}
之后,就要具体实现vmprint函数了,在这里采取如同实验指导中一样的vmprint与一个对应的print_pgtbl递归函数的实现方式,因此需要在vm.c文件的最后加上这样一系列代码:
// + print_pgtbl definition
void print_pgtbl(pagetable_t pgtbl, int depth, long virt) {virt <<= 9; // + 拿到上一层的虚拟地址,需要先左移9位,方便加上下一级页表号for (int i = 0; i < 512; i++) {pte_t pte = pgtbl[i]; // 获取每一条pteif (pte & PTE_V) { // 如果pte有效uint64 pa = PTE2PA(pte); // 求出pachar prefix[16] = "||";int str_end = 2;for (int j = depth; j > 0; j--) {prefix[str_end] = ' ';prefix[str_end + 1] = '|';prefix[str_end + 2] = '|';str_end += 3;}printf(prefix);if (depth == 2) {// + 虚拟地址加上最后一级页表号,之后再左挪12位printf("idx: %d: va: %p -> pa: %p, flags: ", i,
((virt + i) << 12), pa);}else {printf("idx: %d: pa: %p, flags: ", i, pa);}// + 增加BIT_MACRO和symbol数组用于打印flagslong BIT_MACRO[4] = {PTE_R, PTE_W, PTE_X, PTE_U};char symbol[][4] = {"r", "w", "x", "u"};for (int i = 0; i < 4; i++) {if ((pte & BIT_MACRO[i]) != 0) {printf("%s", symbol[i]);}else {printf("-");}}printf("\n");if ((pte & (PTE_R | PTE_W | PTE_X)) == 0) {print_pgtbl((pagetable_t)pa, depth + 1, virt + i);}}}
}// + vmprint definition
void vmprint(pagetable_t pgtbl) {printf("page table %p\n", pgtbl);// 递归打印pte和paprint_pgtbl(pgtbl, 0, 0L);
}
在实验手册中给出的vmprint与print_pgtbl两个函数实例实际上还有一些区别,因为要求最终输出的内容中包含转换前的虚拟地址,因此需要增加一个计算虚拟地址的内容,并且由于实验还需要增加对于页面的访问属性的检测,因此还需要增加一个flags部分用于输出,在这里我采用了一个一个long数组加一个字符串数组的实现方式,对于每一个有效的页面都会通过直接for循环检测对应的属性是否满足,之后输出对应的字符,从而就实现了合法的页表打印。
在完成了代码编写之后首先直接使用make qemu编译运行xv6内核,可以发现启动的时候已经打印出了对应的内容

之后使用grade-lab-pgtbl脚本进行测试,可以发现,第一个打印页表项的实验已经顺利通过了:

(2).独立内核页表
操作内容: 修改代码,使用全局页表,为每个进程分配独立页表
首先打开kernel/proc.h,找到struct proc的定义,增加两个字段:
// Per-process state
struct proc {struct spinlock lock;// p->lock must be held when using these:enum procstate state; // Process statestruct proc *parent; // Parent processvoid *chan; // If non-zero, sleeping on chanint killed; // If non-zero, have been killedint xstate; // Exit status to be returned to parent's waitint pid; // Process ID// these are private to the process, so p->lock need not be held.uint64 kstack; // Virtual address of kernel stackuint64 sz; // Size of process memory (bytes)pagetable_t pagetable; // User page tablestruct trapframe *trapframe; // data page for trampoline.Sstruct context context; // swtch() here to run processstruct file *ofile[NOFILE]; // Open filesstruct inode *cwd; // Current directorychar name[16]; // Process name (debugging)// + k_pagetable, kstack_papagetable_t k_pagetable;uint64 kstack_pa;
};
为了实现独立内核页表,在defs.h当中首先添加两个独立内核页表相关的函数声明:
// + kvminit_for_each_process, kvmmap_for_each_process declaration
pagetable_t kvminit_for_each_process(void);
void kvmmap_for_each_process(pagetable_t, uint64, uint64, uint64, int);
在添加完函数声明之后,就可以在vm.c的合适位置加上函数的定义了,kvminit_for_each_process和kvmmap_for_each_process两个函数要仿照kvminit和kvmmap两个函数来实现:
// + kvminit_for_each_process definition
pagetable_t kvminit_for_each_process() {pagetable_t k_pagetable = (pagetable_t)kalloc();memset(k_pagetable, 0, PGSIZE);// uart registerskvmmap_for_each_process(k_pagetable, UART0, UART0, PGSIZE, PTE_R | PTE_W);// virtio mmio disk interfacekvmmap_for_each_process(k_pagetable, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);// 不映射CLINT// PLICkvmmap_for_each_process(k_pagetable, PLIC, PLIC, 0x400000, PTE_R | PTE_W);// map kernel text executable and read-only.kvmmap_for_each_process(k_pagetable, KERNBASE, KERNBASE, (uint64)etext - KERNBASE, PTE_R | PTE_X);// map kernel data and the physical RAM we'll make use of.kvmmap_for_each_process(k_pagetable, (uint64)etext, (uint64)etext, PHYSTOP - (uint64)etext, PTE_R | PTE_W);// map the trampoline for trap entry/exit to// the highest virtual address in the kernel.kvmmap_for_each_process(k_pagetable, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);return k_pagetable;
}// + kvmmap_for_each_process definition
void kvmmap_for_each_process(pagetable_t k_pagetable, uint64 va, uint64 pa, uint64 sz, int perm) {if (mappages(k_pagetable, va, sz, pa, perm) != 0) {panic("kvmmap");}
}
之后需要修改proc.c中定义的procinit函数,将内核栈的物理地址pa拷贝到PCB的新成员kstack_pa当中:
// initialize the proc table at boot time.
void procinit(void) {struct proc *p;initlock(&pid_lock, "nextpid");for (p = proc; p < &proc[NPROC]; p++) {initlock(&p->lock, "proc");// Allocate a page for the process's kernel stack.// Map it high in memory, followed by an invalid// guard page.char *pa = kalloc();if (pa == 0) panic("kalloc");uint64 va = KSTACK((int)(p - proc));kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);p->kstack = va;// + 将内核栈的物理地址pa拷贝到kstack_pa当中p->kstack_pa = (uint64)pa; }kvminithart();
}
之后同时也需要更改allocproc函数从而完成页表k_pagetable的映射,在这里忽略了allocproc函数的其他部分代码,代码中主要添加了两个部分,首先是创建内核页表,如果创建失败则释放对应的进程块,之后再将内核栈通过kvmmap_for_each_process函数映射到页表k_pagetable当中:
static struct proc *allocproc(void) {…
found:p->pid = allocpid();// Allocate a trapframe page.if ((p->trapframe = (struct trapframe *)kalloc()) == 0) {release(&p->lock);return 0;}// + 为每一个找到的空闲进程创建内核页表p->k_pagetable = kvminit_for_each_process();if (p->k_pagetable == 0) {freeproc(p);release(&p->lock);return 0;}// + 将创建的内核栈映射到页表k_pagetable中kvmmap_for_each_process(p->k_pagetable, p->kstack, p->kstack_pa, PGSIZE, PTE_R | PTE_W);// An empty user page table.…
}
之后需要修改调度器,首先给vm.c增加将内核页表放入satp寄存器的函数,首先依旧是在defs.h中增加函数声明:
// + kvminithart_for_each_process declaration
void kvminithart_for_each_process(pagetable_t);
之后是增加函数定义(写法只需仿照kvminithart完成即可):
// + kvminithart_for_each_process definition
void kvminithart_for_each_process(pagetable_t k_pagetable) {w_satp(MAKE_SATP(k_pagetable));sfence_vma();
}
之后修改scheduler完成内核页表的切换操作(这里同样忽略了部分没有变化的代码):
void scheduler(void) {
…c->proc = p;// + 在上下文切换前切换到当前进程的页表,放入satp中:kvminithart_for_each_process(p->k_pagetable);swtch(&c->context, &p->context);// Process is done running for now.// It should have changed its p->state before coming back.c->proc = 0;// + 如果目前没有进程运行,则让satp载入全局内核页表kvminithart();found = 1;}
…
}
在defs.h中增加free_pagetable_except_for_leaf的函数声明:
// + free_pagetable_except_for_leaf declaration
void free_pagetable_except_for_leaf(pagetable_t);
再仿照freewalk在vm.c当中实现一个释放所有非叶子页表的函数:
// + free_pagetable_except_for_leaf definition
void free_pagetable_except_for_leaf(pagetable_t pagetable) {for (int i = 0; i < 512; i++) {pte_t pte = pagetable[i]; // 获取当前页表pte// pte有效且为根/次页表的目录项if ((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0) {uint64 pa = PTE2PA(pte);free_pagetable_except_for_leaf((pagetable_t)pa);pagetable[i] = 0;}pagetable[i] = 0;// 对于叶子页表不能释放物理页,直接置零即可}// 释放物理内存kfree((void*)pagetable);
}
然后修改proc.c当中的freeproc函数,使之正常释放独立内核页表:
// + Use free_pagetable_except_for leaf to release k_pagetableif (p->k_pagetable) {free_pagetable_except_for_leaf(p->k_pagetable);}
在修改完上述所有代码之后,在目录下使用make qemu编译,在内核中使用kvmtest进行测试,可以看到:

再使用grade-lab-pgtbl进行测试,可以发现独立内核页表的测试这一次也顺利通过了:

(3).简化软件模拟地址翻译
操作内容: 修改代码,在独立内核页表上加上用户地址空间映射,避免花费大量时间进行软件模拟便利页表
首先打开kernel/defs.h,添加首先需要完成的将进程的用户页表映射到内核页表的sync_pagetable函数:
// + sync_pagetable declaration
int sync_pagetable(pagetable_t, pagetable_t, uint64, uint64);
之后在vm.c中实现这个函数:
// + sync_pagetable definition
int sync_pagetable(pagetable_t old, pagetable_t new, uint64 sz, uint64 sz_n) {pte_t* pte;uint64 pa, i;uint flags;sz = PGROUNDUP(sz);for (i = sz; i < sz_n; i += PGSIZE) {if ((pte = walk(old, i, 0)) == 0) {panic("sync_pagetable:pte should exist");}if ((*pte & PTE_V) == 0) {panic("sync_pagetable:page not present");}pa = PTE2PA(*pte);// 允许内存访问flags = PTE_FLAGS(*pte) & (~PTE_U); // 对第四位为1的掩码取反if (mappages(new, i, PGSIZE, (uint64)pa, flags) != 0) { // 创建页表项// 移除映射goto err;}}return 0;err:uvmunmap(new, 0, i / PGSIZE, 0);return -1;
}
之后利用vmcopyin.c当中定义的copyin_new函数直接替代掉copyin()的内容,这里我没有删除代码,只是将之前实现的部分进行了注释:
int copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) {
// uint64 n, va0, pa0;// while (len > 0) {
// va0 = PGROUNDDOWN(srcva);
// pa0 = walkaddr(pagetable, va0);
// if (pa0 == 0) return -1;
// n = PGSIZE - (srcva - va0);
// if (n > len) n = len;
// memmove(dst, (void *)(pa0 + (srcva - va0)), n);// len -= n;
// dst += n;
// srcva = va0 + PGSIZE;
// }// + Use copyin_new directly replace copyin definitionreturn copyin_new(pagetable, dst, srcva, len);
}
在这里我忘了提前把函数声明加上,于是回到vm.c中增加了两个会用到的copyin函数的声明:
// vmcopyin.c
int copyin_new(pagetable_t, char*, uint64, uint64);
int copyinstr_new(pagetable_t, char*, uint64, uint64);
然后进行copyinstr的修改,修改的操作和copyin是一致的:
int copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) {
// uint64 n, va0, pa0;
// int got_null = 0;// while (got_null == 0 && max > 0) {
// va0 = PGROUNDDOWN(srcva);
// pa0 = walkaddr(pagetable, va0);
// if (pa0 == 0) return -1;
// n = PGSIZE - (srcva - va0);
// if (n > max) n = max;// char *p = (char *)(pa0 + (srcva - va0));
// while (n > 0) {
// if (*p == '\0') {
// *dst = '\0';
// got_null = 1;
// break;
// } else {
// *dst = *p;
// }
// --n;
// --max;
// p++;
// dst++;
// }// srcva = va0 + PGSIZE;
// }
// if (got_null) {
// return 0;
// } else {
// return -1;
// }// + Use copyinstr_new to replace copyinstrreturn copyinstr_new(pagetable, dst, srcva, max);
}
这里对比一下两个新函数的差距:
// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
int copyin_new(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) {struct proc *p = myproc();if (srcva >= p->sz || srcva + len >= p->sz || srcva + len < srcva) return -1;memmove((void *)dst, (void *)srcva, len);stats.ncopyin++; // XXX lockreturn 0;
}int copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) {uint64 n, va0, pa0;while (len > 0) {va0 = PGROUNDDOWN(srcva);pa0 = walkaddr(pagetable, va0);if (pa0 == 0) return -1;n = PGSIZE - (srcva - va0);if (n > len) n = len;memmove(dst, (void *)(pa0 + (srcva - va0)), n);len -= n;dst += n;srcva = va0 + PGSIZE;
}
return 0;
}
原先的copyin函数是通过walkaddr软件模拟转换页表实现的,它的实现需要很长一段时间的遍历,而copyin_new直接通过硬件方式完成了内存的拷贝,此时就无需进行遍历实现,效率明显提高,而copyinstr和copyinstr_new的区别也是类似的:
// Copy a null-terminated string from user to kernel.
// Copy bytes to dst from virtual address srcva in a given page table,
// until a '\0', or max.
// Return 0 on success, -1 on error.
int copyinstr_new(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) {struct proc *p = myproc();char *s = (char *)srcva;stats.ncopyinstr++; // XXX lockfor (int i = 0; i < max && srcva + i < p->sz; i++) {dst[i] = s[i];if (s[i] == '\0') return 0;}return -1;
}
这里没有附上copyinstr的代码,它的实现基本也是一致的,只是因为字符串类型相对比较特别,所以需要一个拷贝的最大字符,以及对于0字符的特别判断等操作,但是除此之外的操作基本上是如同copyin一样的,它也直接通过for循环的方式完成了字节的拷贝,而没有使用walkaddr的方式来进行软件模拟,从而提升了效率。
之后修改proc.c中fork、exec和growproc三个函数的定义,首先对于growproc,增加n < 0时对于独立内核页表的释放操作:
int growproc(int n) {uint sz;struct proc *p = myproc();sz = p->sz;if (n > 0) {if ((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {return -1;}sync_pagetable(p->pagetable, p->k_pagetable, p->sz, p->sz + n);} else if (n < 0) {sz = uvmdealloc(p->pagetable, sz, sz + n);// + 用户删内核也删,如果这里释放物理内存可能导致重复回收uvmdealloc_u_in_k(p->k_pagetable, p->sz, p->sz + n);}p->sz = sz;return 0;
}
之后增加fork函数最后调用sync_pagetable函数:
int fork(void) {…np->state = RUNNABLE;// + fork也会产生子进程sync_pagetable(np->pagetable, np->k_pagetable, 0, np->sz);release(&np->lock);return pid;
}
然后就是在exec.c当中修改exec函数的代码(没有变更的部分省略):
int exec(char *path, char **argv) {…// Commit to the user image.oldpagetable = p->pagetable;p->pagetable = pagetable;// + 释放oldpagetable映射,建立新的pagetable映射uvmdealloc_u_in_k(p->k_pagetable, p->sz, 0);sync_pagetable(p->pagetable, p->k_pagetable, 0, sz);p->sz = sz;p->trapframe->epc = elf.entry; // initial program counter = main
…
}
然后分别在defs.h和vm.c当中添加先前用到的uvmdealloc_u_in_k函数的声明与定义:
// + uvmdealloc_u_in_k declaration
uint64 uvmdealloc_u_in_k(pagetable_t, uint64, uint64);
// + uvmdealloc_u_in_k definition
uint64 uvmdealloc_u_in_k(pagetable_t pagetable, uint64 oldsz, uint64 newsz) {if (newsz >= oldsz) return oldsz;if (PGROUNDUP(newsz) < PGROUNDUP(oldsz)) {int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE;uvmunmap(pagetable, PGROUNDUP(newsz), npages, 0); // 释放物理内存会报错}return newsz;
}
在proc.c当中为第一个进程创建用的userinit也增加用户页表映射的过程:
void userinit(void) {struct proc *p;p = allocproc();initproc = p;// allocate one user page and copy init's instructions// and data into it.uvminit(p->pagetable, initcode, sizeof(initcode));p->sz = PGSIZE;// + 用户初始化进程映射到内核页表中
sync_pagetable(p->pagetable, p->k_pagetable, 0, p->sz);
…
}
最终使用make qemu编译,运行stats,可以看到copyin和copyinstr的次数都不为0了:

之后在终端中运行grade-lab-pgtbl,可以看到结果为100分,所有测试均能够通过:

3.实验问题及相应解答
问题1
问题: 将自己电脑上输出的三层页表绘制成图
解决: 利用工具将输出的两个三层页表绘制成为下面的图,第一个是对于第一组三个PTE的页表示意图:

下面是第二组两个PTE的页表示意图:

问题2
问题: 查阅资料,简要阐述页表机制为什么会被发明,它有什么好处?
解决:
页表机制的必要性:
- 正如操作系统理论课上说的,内存管理会随着计算机的广泛应用变得越来越复杂,首先不同进程之间如果直接使用物理内存可能会导致相互之间无法隔离,一个进程可以比较轻松地入侵另外一个进程的地址空间,这是一件很危险的事情;
- 二来是内存线性分配可能会导致很多外部碎片,这样可用的内存可能会随着计算机的运行越变越少。
- 第三是多任务操作的需求,传统的线性内存管理机制无法满足进程之间的内存冲突和数据泄露的问题,因此综上所述,页表机制是必备的。
页表机制的好处:
- 通过页表,操作系统可以灵活地分配和管理内存。页表允许非连续的内存分配,使得操作系统可以更高效地利用内存,减少内存碎片。例如,一个进程可以分配多个不连续的物理内存页,而这些页在虚拟地址空间中表现为连续的。
- 页表机制是虚拟内存的重要组成部分。虚拟内存允许操作系统使用磁盘空间来扩展物理内存的容量。页表记录了哪些虚拟地址映射到物理内存,哪些映射到磁盘。当程序访问不在物理内存中的页面时,会触发页面置换机制,将所需页面从磁盘调入内存。这种机制大大扩展了程序可以使用的内存容量,使得运行大型程序成为可能。
- 页表可以包含每个页面的权限标志,如只读、可写和可执行。这使得操作系统可以精细地控制每个页面的访问权限,防止程序执行未授权的操作。例如,代码段通常被标记为只读和可执行,数据段被标记为可读写但不可执行。这种细粒度的权限控制增强了系统的安全性。
问题3
问题: xv6本会在 procinit()中分配内核栈的物理页并在页表建立映射。但是现在,应该在allocproc()中实现该功能。这是为什么?
解决: procinit函数的作用是在操作系统启动的初始化阶段对整个PCB表进行初始化,这个时段会完成所有PCB的基本资源的申请,如果在这个阶段就分配内核栈的物理页并在页表建立映射就可能会在很多PCB没有使用的情况下造成大量资源浪费。
而allocproc函数会在每一个PCB真正创建的时候再去分配相应的资源,所以将分配物理页建立映射的操作放在allocproc,也就是创建进程真实需要用到资源的时候再完成操作。
问题4
问题: 为什么像kminithart_for_each_process这种函数,我们需要重写,实现的逻辑与原本的函数却是一样的,那重写的意义在哪里,或者如果不重写,能不能直接使用原本的函数。(为什么不能直接用原来的函数)
解决: xv6 中,kvminithart 函数用于初始化和设置全局内核页表。这个全局页表用于所有进程的内核态切换。然而,当引入独立内核页表的机制时,每个进程都有自己的内核页表,而不是共享一个全局内核页表。因此,kvminithart 函数需要进行相应的修改以支持独立内核页表。
如果直接修改 kvminithart 函数来支持独立内核页表,意味着所有调用 kvminithart 的地方都需要进行相应的修改和调整。这会导致代码的改动范围非常大,增加了引入新错误的风险,并且会对现有功能的稳定性造成影响。
所以重写一个新的函数实际上反而要比进行修改会更加简单,在已经存在大量使用到某个函数的逻辑的情况下,写一个新的实现不同的功能相比于队原来的函数逻辑修改的开发效率会明显更高。
实验小结
- 1、阅读了xv6内核中关于页表等的代码,了解了xv6是如何进行页表地址转换等一系列操作的。
- 2、本次实验完成了对于xv6内核页表结构的打印,给进程添加了独立内核页表,并在之后优化了代码使得地址转换不再通过软件模拟的方式实现,提升了效率。
相关文章:
操作系统—页表(实验)
文章目录 页表1.实验目标2.实验过程记录(1).增加打印页表函数(2).独立内核页表(3).简化软件模拟地址翻译 3.实验问题及相应解答问题1问题2问题3问题4 实验小结 页表 1.实验目标 了解xv6内核当中页表的实现原理,修改页表,使内核更方便地进行用户虚拟地址…...
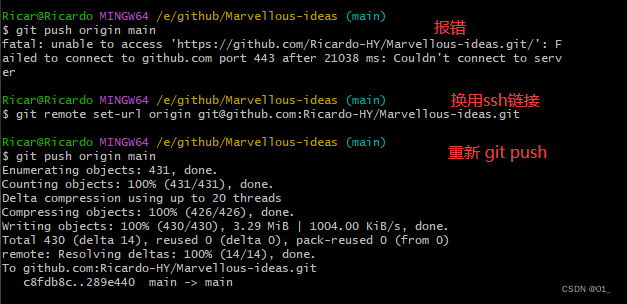
github 本地仓库上传及报错处理
一.本地文件上传 这里为上传部分,关于gitbash安装配置,读者可自行搜索,由于已经安装完成,未进行截图保存,这里便不做赘述。 1.登录git账号并创建一个仓库 点击仓库打开后会看到这个仓库的网址链接(这个链…...
)
【ZZULIOJ】1104: 求因子和(函数专题)
题目描述 输入正整数n(2<n<1000),计算并输出n的所有正因子(包括1,不包括自身)之和。要求程序定义一个FacSum ()函数和一个main()函数,FacSum ()函数计算并返回n的所有正因子之和,其余功能在main()函…...

轨迹优化 | 图解欧氏距离场与梯度场算法(附ROS C++/Python实现)
目录 0 专栏介绍1 什么是距离场?2 欧氏距离场计算原理3 双线性插值与欧式梯度场4 仿真实现4.1 ROS C实现4.2 Python实现 0 专栏介绍 🔥课程设计、毕业设计、创新竞赛、学术研究必备!本专栏涉及更高阶的运动规划算法实战:曲线生成…...

【二维差分】2132. 用邮票贴满网格图
本文涉及知识点 二维差分 LeetCode2132. 用邮票贴满网格图 给你一个 m x n 的二进制矩阵 grid ,每个格子要么为 0 (空)要么为 1 (被占据)。 给你邮票的尺寸为 stampHeight x stampWidth 。我们想将邮票贴进二进制矩…...
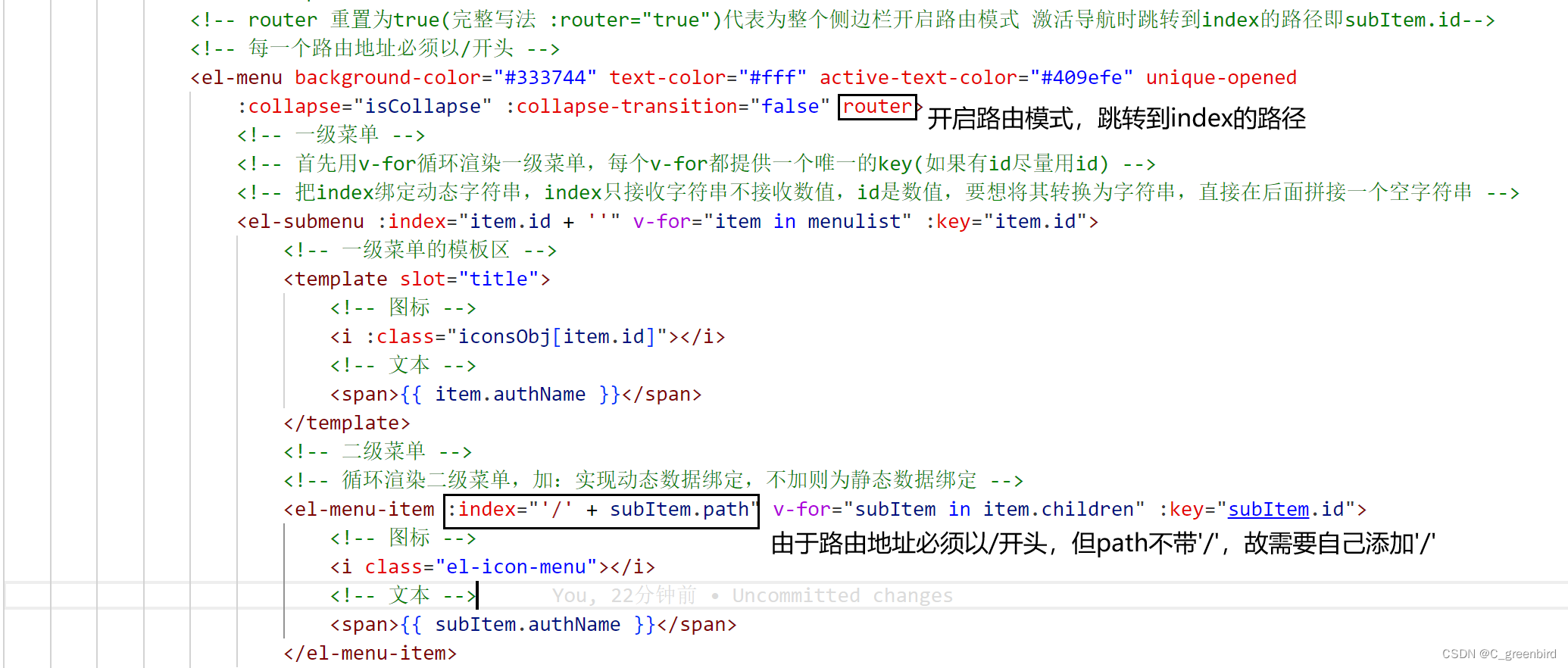
【前端项目笔记】2 主页布局
主页布局 element-ui提供的组件名称就是它的类名 ☆☆ CSS选择器: (1)基本选择器 类型选择器 p/span/div…… 类选择器 (.classname) ID选择器 (#idname) 通配选择器 ( * ) (2)属性选择器 选择具有特定属性或属性值的…...

t265 jetpack 6 px4 ros2
Ubuntu22.04 realsenseSDK2和ROS2Wrapper安装方法,包含T265版本踩坑问题_ros2 realsense-CSDN博客 210 git clone https://github.com/IntelRealSense/librealsense.git 212 git branch 215 git tag 218 git checkout v2.51.1 219 git branch 265 git clone https://…...
vue 应用测试(一) --- 介绍
vue 应用测试(一) ---介绍 前端测试简介组件测试Jest 测试框架简介其他测试框架 第一个测试避免误报如何组织测试代码 组件挂载Vue2 组件挂载的方式Vue3 的挂载方式vue-test-utils挂载选项 如何调试测试用例参考小结 前端测试简介 软件测试:…...

Perl 语言入门学习
一、介绍 Perl 是一种高级的、动态的、解释型的通用编程语言,由Larry Wall于1987年开发。它是一种非常灵活和强大的语言,广泛用于文本处理、系统管理、网络编程、图形编程等领域。 Perl 语言的设计理念是“用一种简单的语法,去解决复杂的编…...

HarmongOS打包[保姆级]
创建应用 首先进入 华为开发者联盟-HarmonyOS开发者官网 然后进行登录。 登录成功后,鼠标悬停在在登录右上角那个位置后再点击管理中心,进入下面这个界面。 再点击:应用服务–>应用发布–>新建–>完善信息 构建和生成私钥和证书请求…...

SpringBoot怎么实现自定义接口全局异常捕获?详细教程
自定义异常 package com.single.bean;import org.springframework.core.NestedRuntimeException;public class FDWException extends NestedRuntimeException {private static final long serialVersionUID = 6046035491210083235L;public FDWException(String msg) {super(msg…...

Ms08067安全实验室成功实施多家业务系统渗透测试项目
点击星标,即时接收最新推文 近日,Ms08067安全实验室针对多家公司重要系统实施渗透测试项目。公司网络信息系统的业务应用和存储的重要信息资产均较多,存在网络系统结构的复杂性和庞杂等特点,使得公司网络信息系统面临一定风险。项…...

小熊家政帮day22-day23 订单系统优化(订单状态机、练习分库分表、索引、订单缓存)
目录 1 状态机1.1 状态机介绍1.1.1 当前存在的问题1.1.2 使用状态机解决问题 1.2 实现订单状态机1.2.1 编写订单状态机1.2.1.1 依赖引入1.2.1.2 订单状态枚举类1.2.1.3 状态变更事件枚举类1.2.1.4 定义订单快照类1.2.1.5 定义事件变更动作类1.2.1.5 定义订单状态机类1.2.1.6 状…...

LeetCode 1731, 151, 148
目录 1731. 每位经理的下属员工数量题目链接表要求知识点思路代码 151. 反转字符串中的单词题目链接标签思路代码 148. 排序链表题目链接标签Collections.sort()思路代码 归并排序思路代码 1731. 每位经理的下属员工数量 题目链接 1731. 每位经理的下属员工数量 表 表Emplo…...

Codeforces Round 953 (Div. 2)(A~D题解)
这次比赛是我最顺利的一次比赛,也是成功在中途打进前1500,写完第三道题的时候也是保持在1600左右,但是后面就啥都不会了,还吃了点罚时,虽说如此也算是看到进步了,D题学长说很简单,但是我当时分析…...

晶圆切割机(晶圆划片机)为晶圆加工重要设备 我国市场国产化进程不断加快
晶圆切割机(晶圆划片机)为晶圆加工重要设备 我国市场国产化进程不断加快 晶圆切割机又称晶圆划片机,指能将晶圆切割成芯片的机器设备。晶圆切割机需具备切割精度高、切割速度快、操作便捷、稳定性好等特点,在半导体制造领域应用广…...
39、基于深度学习的(拼音)字符识别(matlab)
1、原理及流程 深度学习中常用的字符识别方法包括卷积神经网络(CNN)和循环神经网络(RNN)。 数据准备:首先需要准备包含字符的数据集,通常是手写字符、印刷字符或者印刷字体数据集。 数据预处理࿱…...

CCF 矩阵重塑
第一题:矩阵重塑(一) 本题有两种思路 第一种 (不确定是否正确 但是100分) #include<iostream> using namespace std; int main(){int n,m,p,q,i,j;cin>>n>>m>>p>>q;int a[n][m];for(i…...

Aigtek高压放大器在柔性爬行机器人驱动性能研究中的应用
实验名称:柔性爬行机器人的材料测试 研究方向:介电弹性体的最小能量结构是一种利用DE材料的电致变形与柔性框架形变相结合设计的新型柔性驱动器,所谓最小能量是指驱动器在平衡状态时整个系统的能量最小,当系统在外界的电压刺激下就…...

Postman下发流表至Opendaylight
目录 任务目的 任务内容 实验原理 实验环境 实验过程 1、打开ODL控制器 2、网页端打开ODL控制页面 3、创建拓扑 4、Postman中查看交换机的信息 5、L2层流表下发 6、L3层流表下发 7、L4层流表下发 任务目的 1、掌握OpenFlow流表相关知识,理解SDN网络中L…...

Vibe Annotations:AI编程时代的视觉反馈工具,精准沟通前端修改意图
1. 项目概述:一个为AI编程时代量身定制的视觉反馈工具如果你和我一样,每天都在和AI编程助手(比如Cursor、Claude Code)打交道,那你肯定遇到过这个痛点:想让它帮你改一个网页按钮的颜色,或者调整…...

Epsilla向量数据库实战:10倍性能提升的RAG系统核心架构解析
1. 项目概述:为什么我们需要另一个向量数据库?如果你最近在折腾大语言模型应用,尤其是RAG(检索增强生成)系统,那你肯定对向量数据库这个概念不陌生。从Pinecone、Weaviate到Milvus、Qdrant,市面…...

Flutter For Openharmony第三方库: animated_text_kit 的鸿蒙化适配指南
Flutter 三方库 animated_text_kit 的鸿蒙化适配指南 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 前言:文字是可动的 嘿~亲爱的开发者小伙伴们,大家好呀!👋 今天我们要一起探索一个超级有…...

最小扩张三角剖分:算法优化与计算几何实践
1. 最小扩张三角剖分问题概述在计算几何领域,最小扩张三角剖分(Minimum Dilation Triangulation, MDT)是一个经典的优化问题。给定平面上的n个点集P,MDT的目标是找到一个三角剖分T,使得对于P中的任意两点s和tÿ…...

嵌入式产品如何通过RTOS选型抢占市场先机
1. 项目概述:为什么“上市时机”是嵌入式产品的生死线在嵌入式系统开发这个行当里摸爬滚打了十几年,我见过太多团队把“功能实现”和“性能达标”作为项目的终极目标,却在一个更根本的问题上栽了跟头:上市时机。你可能觉得&#x…...

终极指南:如何用ChatLaw构建你的免费中文法律AI助手
终极指南:如何用ChatLaw构建你的免费中文法律AI助手 【免费下载链接】ChatLaw ChatLaw:A Powerful LLM Tailored for Chinese Legal. 中文法律大模型 项目地址: https://gitcode.com/gh_mirrors/ch/ChatLaw 面对复杂的法律问题,你是否…...

Photoshop AVIF插件实战:解锁下一代图像格式的完整解决方案
Photoshop AVIF插件实战:解锁下一代图像格式的完整解决方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 为Adobe Photoshop添加AVIF格式支持不再…...

中国半导体产业崛起:资本驱动下的存储器攻坚与全产业链布局
1. 行业格局的十字路口:当西方整合遇上东方崛起最近几年,半导体行业的头条新闻几乎被一系列重磅并购案所占据:恩智浦收购飞思卡尔、安华高并购博通、英特尔鲸吞阿尔特拉。这些动辄数百亿美元的巨无霸交易,背后传递出一个清晰的信号…...

Pega Helm Charts:Kubernetes上自动化部署Pega平台的完整指南
1. 项目概述与核心价值如果你正在或即将在Kubernetes上部署Pega Platform,那么pegasystems/pega-helm-charts这个项目绝对是你绕不开的“官方说明书”和“自动化工具箱”。简单来说,这是Pega官方维护的一套Helm Chart,专门用于将Pega Platfor…...

ClawGuard:为Clawdbot AI智能体打造的安全监控与熔断防护系统
1. 项目概述:ClawGuard 是什么,以及为什么你需要它如果你正在使用或开发基于 Clawdbot 框架的 AI 智能体,那么“安全”和“可控”这两个词,大概率已经在你脑海里盘旋过无数次了。我接触过不少团队,从最初的兴奋于 AI 智…...