HIVE及SparkSQL优化经验
简介
针对高耗跑批时间长的作业,在公司近3个月做过一个优化专项;优化成效:综合cpu、内存、跑批耗时减少均在65%以上;
cpu和内存消耗指的是:vcoreseconds和memoryseconds
这里简单说下优化的一些思路,至于优化细节之前写过两篇,或可参考::
sparksql优化:https://blog.csdn.net/me_to_007/article/details/130916946
hive优化:https://blog.csdn.net/me_to_007/article/details/126921955
运行环境:yarn调度+hdfs存储(orc格式表)+hive2+spark2.4.3
大家有什么经验,也欢迎补充、指正
什么样的任务值得关注
一个作业运行时间很长就值得关注吗?不一定,如果一个用户把n段逻辑全都整到一个作业里,不是太长,跑批时耗在数仓规范范围内,可能也是可接受合理的;
这里将时间界限监控到stage层面,对应hive就是每一个job,在sparksql里就是每一个stage;一个作业跑批时间很长可能是合理的,也许是逻辑复杂由很多个stage构成;但是一个stage跑批时间很长,在分布式计算里,一般不正常;
hive的stage可以只有map逻辑,也可以是一段mr、union、limit语句;sparksql的stage则根据有无shuffle划分,遇到shuffle宽依赖则新划分一个stage;
这个时间界限可以根据经验及要求灵活设置,比如要尽可能地提升作业跑批时效和节省结算资源,那这个界限可以设置小点,比如一个小时;一般几十亿的数据join,没有倾斜、发散,一个小时也够了;
另外一方面是监控内存配置,hive里边的map和reduce内存配置,sparksql里的executor内置配置,这些参数都不应该设置过大;每个task的内存界限可以设置到4个g
hive里边map和reduce内存是单独设置的,sparksql单个task的内存约等于:单个executor内存/每个executor cpu核数 * 每个task跑批cpu核数(这个参数默认是1,一般不做额外设置)
hive-map内存参数:mapreduce.map.memory.mb
hive-reduce内存参数:mapreduce.reduce.memory.mb
sparksql-executor内存参数:spark.executor.memory
sparksql-executor核数:spark.executor.cores
sparksql-每task-cpu核数:spark.task.cpus该参数默认为1,一般无需额外设置;
spark-driver的内存,如果有广播和cahe缓存,需要配置大些,可根据实际情况设置;
配置自动监控
这里可以根据yarn日志,编写定时调度脚本,解析作业日志,将符合异常规则的作业发邮件出来筛查(也可配置短信接口通知作业属主整改);
这里可以手工配置一个白名单,作业如果已经审查无太大优化空间,则加入白名单避开筛查;当然这个白名单也可以设置特定的规则,比如把时间和资源界限的上限配大点,而不是无限放大,避免白名单后界限无限放大;
内存监控则直接读取作业配置参数即可,如触发条件则发邮件到相关团队优化(在我们这是数据治理组)
耗时长有两种情况,一种的倾斜导致的,这种就解决倾斜;另外一种每个task处理数据量都很大,这类情况一般把task数量调大点,再多给点资源;日志解析也比较好处理,倾斜监控作业各个stage中最大task耗时相比一般水平差异,这个界限也可以按需配置;比如我们这里设定为最大task跑批时长-上四分位时长 > 3倍四分差
数据倾斜是一个相对的概念,准确地说,每个作业都有倾斜,但对于一些跑批时间比较短的作业,至于整个数仓盘面来说,优化提升不大;这里可以在监控里筛跳过;
当然至于个别业务团队,视重要性个别对待,有的作业对时效要求比较高,比如涉及到重大活动数据,那就做精细化优化;
考虑到yarn日志文件比较大,解析耗时,集群作业比较多,解析日志应有筛选地进行;那些跑批时间相对短的作业或可暂时搁置;同时配置白名单,防止日志重复读取解析;
怎么去定位问题SQL段
主要是结合执行计划定位,在hive里面执行计划map-tree里显示的表名,如果sql中有写别名,则显示的是别名;为防止筛查混乱,难以定位,sql中的表别名尽量不要使用相同的,没有关联逻辑情况,尽量不要使用别名;
比如下面一段sql:
select group_name,count(1) as cnt
from tablename -- 这里不写表别名
group by group_name
在hive中,直接使用explain + sql字符串打印执行计划即可;看看日志里哪个stage异常,再根据执行计划去定位异常sql段落,进而进行作业分析;
explain select dt,count(1) as cnt from tablename group by dt
hive中如果有配置join倾斜参数(set hive.optimize.skewjoin=true)或者groupby倾斜参数(set hive.groupby.skewindata=true),如果作业stage倾斜会额外生成一个stage,这里在执行计划里是看不到的,这个stage紧跟运行在原来的stage后面;
这里需要注意的是,调度环境和我们查看执行计划的环境,引擎配置可能会不一样,我们通过执行计划查看的stage号可能跟实际作业跑批不一致;这里尽量在同一环境下去查看执行计划;
一方面,我们也可以通过yarn里map日志的syslog日志去查看map读取的表名,然后根据使用的表名大概定位到sql段(如果当前stage的数据源都是来自前依赖stage reduce的output则日志里看到的是临时文件名而不是表名)
sparksql,同样的,查看sparkui中stage对应的执行计划(stage二级页面),spark2.4.3中stage的执行计划不是很详细,可以结合数据量,算子然后在sparkui全局执行计划里去找,定位sql语句段;
如果是作业跑批失败,在执行计划中体现为上游依赖stage全跑完了,而这个stage没有打印执行数据(sparksql执行计划每个stage跑完都会显示跑批时间及输出数据)
大概的一些优化方向
-
优化sql
每一个作业就好比一个成型的积木,而成型的积木可由不同积木块不同方式拼凑而成,条条大路通罗马;使用怎样的积木块(表)以及怎样的拼凑方式是我们一个优化介入点;比如join顺序,使用不同的表,先聚合在join等(视具体场景,具体处理) -
增加stage的task个数
这类体现为某个stage跑批时间很长但是又没有倾斜,可以适当增加stage的reduce个数;这类现象一般出现在多维聚合、countdistinct数据膨胀,多个表关联包括开窗用的是一个mr(表关联join字段和开窗partitionby字段是同一个字段,计算会优化收拢到一个mr里,具体看执行计划),join数据发散多对多;
题外:数据量大,一定要reduce个数设置大些吗?
不一定,如果存在map预聚合,且预聚合能显著减少数据量的,有时候恰恰要手动把reduce配置少点;在hive里可以指定reduce个数mapred.reduce.tasks,亦可结合每reduce处理数据量hive.exec.reducers.bytes.per.reducer+hive.exec.reducers.max动态配置reduce个数(但这个数据量是map逻辑前的数据量,如果有filter筛选,需适当增加.bytes.per.reducer参数,减少reduce个数);sparksql则直接设置spark.sql.shuffle.partitions个数和动态分区参数spark.sql.adaptive.enabled即可;
有的跑批时间长可能是自定义函数优化做的不到位,这种情况优先使用内置函数或者找相关开发优化自定义函数;字符串处理能不正则的尽量不要用正则 -
解决倾斜
如果遇到倾斜,则按常规倾斜处理即可;在具体实践中,我们发现hive倾斜参数机制,优化效果不一定比手动处理要好;比如groupby倾斜参数set hive.groupby.skewindata=true大多时候并不比手工处理要好,这里可以手动打散试试(就是麻烦点,如果逻辑复杂,改起来会很耗时);hive的join的倾斜参数不适用于外连接,这里需要注意下;此外mapjoin不适用于外连接主表是小表的情况(比如小表 left join 大表) -
开启并行
这里主要是针对于hive计算,如果存在stage没有依赖(查看执行计划),可以开启并行执行参数set hive.exec.parallel=true,无依赖的stage可以并行执行,比如union all上下逻辑子句,join中嵌套的子句等;
sparksql可以通过堆资源来减少跑批时间,但一般不建议设置的总cpu核数大于并发task数量的1/2;官方推荐是task的数据大于cpu总核数的三倍。比如有300个task,那cpu总核数尽量设置在150以下。
在数据体量很大时,我们发现sparksql的map stage耗时比较长,这里可以根据实际情况切换合适的计算引擎;
此外,基于整个作业链路去优化目标作业跑批时效,要基于关键链路去优化,非关键链路作业优化对结果作业产出时间没有影响;
countdistinct,每一个distinct数据都会膨胀一倍;如果countdistinct数量过多,但去重的都是同一个字段,只是条件不同时,改写下sql,shuffle数据量可以显著减少;
比如(假设flag是一个标签字段,字段值只有0和1):
selecet group_name,count(distinct case when flag1=1 then id end) as dis_cnt1,count(distinct case when flag2=1 then id end) as dis_cnt2-- ,...,count(distinct case when flagn=1 then id end) as dis_cntn
from tablename
group by group_name
这里的数据有n个countdistinct,数据膨胀n倍;但让若我们这么改写:
selecet group_name,count(case when flag1=1 then id end) as dis_cnt1,count(case when flag2=1 then id end) as dis_cnt2-- ,...,count(case when flagn=1 then id end) as dis_cntn
(select group_name,id,max(flag1) as flag1,max(flag2) as flag2--,..,max(flagn) as flagnfrom tablenamegroup by group_name,id
) t
group by group_name
如此,数据没有膨胀,只是多了一个mr成本而已;需注意的是,hive在开启优化后,该改写,可能会合并到一个mr里,具体看执行计划&需求改写;
相关文章:

HIVE及SparkSQL优化经验
简介 针对高耗跑批时间长的作业,在公司近3个月做过一个优化专项;优化成效:综合cpu、内存、跑批耗时减少均在65%以上; cpu和内存消耗指的是:vcoreseconds和memoryseconds 这里简单说下优化的一些思路,至于…...

Django 5 Web应用开发实战
文章目录 一、内容简介二、目录内容三、值得一读四、适读人群 一、内容简介 《Django 5 Web应用开发实战》集Django架站基础、项目实践、开发经验于一体,是一本从零基础到精通Django Web企业级开发技术的实战指南。《Django 5 Web应用开发实战》内容以Python 3.x和…...
)
互联网摸鱼日报(2024-06-17)
互联网摸鱼日报(2024-06-17) 36氪新闻 本周双碳大事:历年最大规模SNEC人气火热;首批CCER审定与核查机构名单出炉;特斯拉储能业务年增长率将达200%至300% 烧光百亿,离奇破产!顶级天才,让广东损失惨重 奥特…...

Docker Desktop Installer For Windows 国内下载地址
官网: Docker Desktop For Windows: https://download.docker.com/win/stable/Docker%20Desktop%20Installer.exe 通过Docker官网下载Docker Desktop安装包非常慢,而且还会下载失败。 解决方案 网盘下载: 链接:https://pan.qu…...
做好程序前设计
不要小看任何一道编程题目!一定一定一定要想好之后再动手!!! 带上你的草稿本!!!!!!!!!!!…...

SpringCloud:Feign远程调用
程序员老茶 🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 P S : 点赞是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全栈&#…...

leetcode-05-[242]有效的字母异位词[349]两个数组的交集[202]快乐数[1]两数之和
重点: 哈希表:当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。 常用数据结构: List 数组 固定大小 如26个字母,10个数字 空间换时间 Set hashset 去重 Map hashmap <K,V>形式 …...

C语言实现动态栈
#include<stdio.h> #include<stdlib.h> #include<stdbool.h>// 每一个节点的数据类型 typedef struct Node {int data;struct Node * pNext; }NODE, * PNODE; // NODE等价 struct Node PNODE等价于 struct Node *// 栈 typedef struct Stack {PNODE pTop;P…...

进程间的通信
管道 匿名管道 匿名管道的⽣命周期,是随进程的创建⽽建⽴,随进程的结束⽽销毁 匿名管道的创建,需要通过下⾯这个系统调⽤: int pipe(int fd[2]) 这⾥表示创建⼀个匿名管道,并返回了两个描述符,⼀个是…...
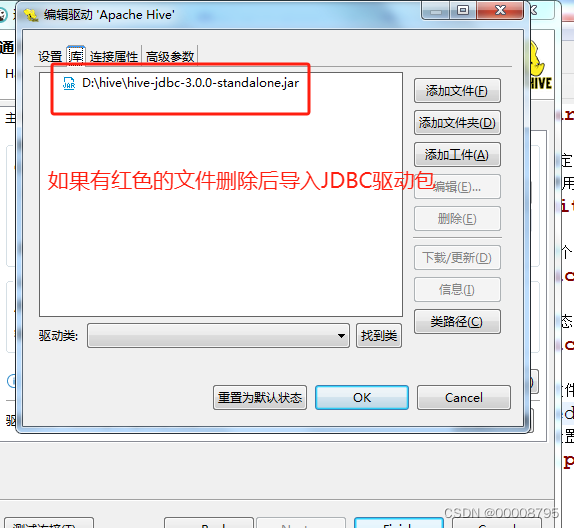
hadoop/hive/DBeaver启动流程
hadoop 启动 cd到指定目录下 cd /opt/module/hadoop-3.3.0/sbin/启动文件 ./start-all.shjps一下,查看显示的内容 应该显示以下内容 NameNode SecondaryNameNode DataNode ResourceManager NodeManager如果缺少namenode,那么执行 rm -rf /tmp/hadoo…...

1节18650锂电池的容量是多大,电流,电压是多大
1节标准的18650锂电池的规格通常如下: 容量: 18650锂电池的容量通常在1800mAh(毫安时)到3000mAh之间,这取决于电池的化学成分和制造商的设计。例如,许多常见的18650电池标称容量为2200mAh或2600mAh。 电流…...

基于GA遗传算法的多机无源定位系统GDOP优化matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于GA遗传算法的多机无源定位系统GDOP优化matlab仿真。仿真输出GDOP优化结果,遗传算法的优化收敛曲线以及三维空间坐标点。 2.测试软件版本以及运行…...

Linux C语言:多级指针(void指针和const)
一、多级指针 把一个指向指针变量的指针变量,称为多级指针变量对于指向处理数据的指针变量称为一级指针变量指向一级指针变量的指针变量称为二级指针变量 1、二级指针变量的说明形式 <数据类型> ** <指针名> ; 一张图理解二级指针 2、多…...
MicroPython+ESP32 C3开发上云
传感器PinI/O状态D412输出1开0关D513输出1开0关 概述 MicroPython是python3编程语言的精简实现,能够在资源非常有限的硬件上运行,如MCU微控制器Micropython的网络功能和计算功能很强大,有非常多的库可以使用,它为嵌入式开发带来了…...
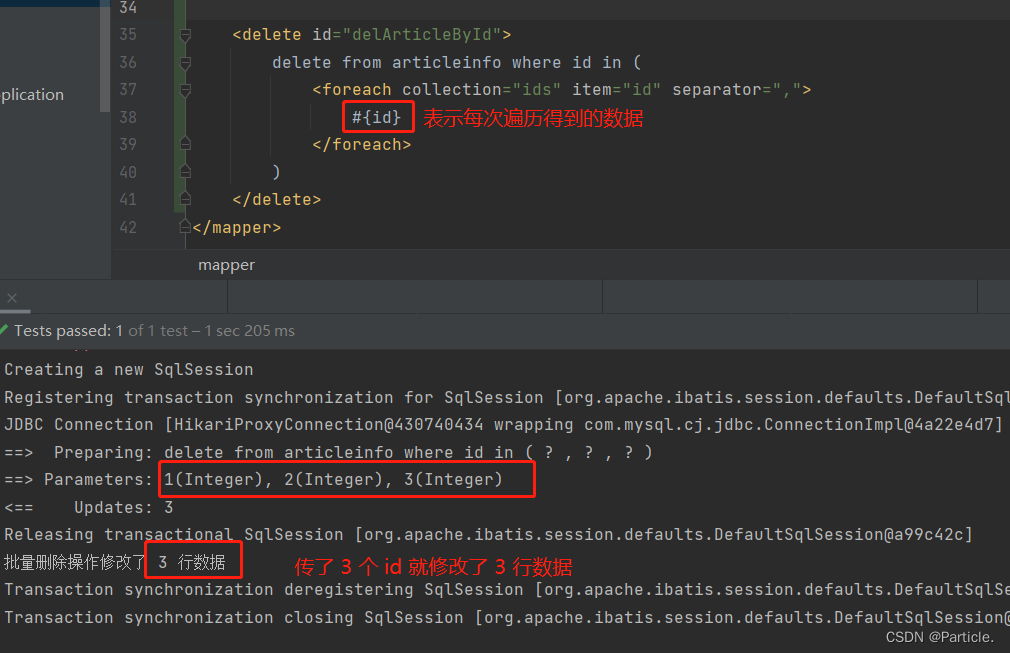
动态 SQL
动态 SQL 是 MyBatis 的强大特性之一,能够完成不同条件下不同的 sql 拼接。也就是说执行的 SQL 语句并不是固定的,而是不同人的不同操作执行的语句会有所差异。MyBatis 通过使用 标签 的方式来实现这种灵活性的。 <if>标签 例如在有一些网站进行…...
功能强大的多功能文档转换工具Neevia Document Converter Pro 7.5.0.241
Neevia Document Converter Pro是一款功能强大的Windows软件,旨在将文档转换为各种格式,包括PDF、TIFF、JPEG和许多其他格式。该程序专为在企业环境中使用而设计,提供文档转换和处理过程的自动化,这使其成为处理大量文档的组织的***工具。 Neevia Document Converter Pro的…...

从零到一,深入浅出大语言模型的奇妙世界
2022 年底,OpenAI 发布的 ChatGPT 模型在全球范围内引起了巨大轰动。本文详细的介绍了大语言模型的发展历程、构建过程和大语言模型如何使用等知识,帮助大家搞懂大语言模型。 一、大语言模型发展历程 大模型技术并不是一蹴而就的,大语言模型…...

ESP8266发送WOL幻数据包实现电脑远程唤醒
计算机远程唤醒(Wake-on-LAN, WOL) 计算机远程唤醒(Wake-on-LAN,简称 WOL)是一种局域网唤醒技术,可以将局域网内处于关机或休眠状态的计算机唤醒至引导(Boot Loader)或运行状态。无…...
用一个ESP32S3-Zero把有线键盘变为无线
三脚猫最近一直琢磨,那些喜欢买剪线键盘,以及自制键盘瞎折腾的人都是怎么搞的。经过不懈努力,终于想明白除了直接的硬件一个个pin针的高低电压判断后转给蓝牙,拿到现成的古董剪线键盘还有一个方式其实是在usb host转发给蓝牙类似这…...

Redis 7.x 系列【3】多种连接方式
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 概述2. Redis Cli3. 可视化管理工具3.1 Redis Insight3.2 RedisDesktopManager 4. …...

MagiskBoot:Android启动镜像解构与重构引擎深度解析
MagiskBoot:Android启动镜像解构与重构引擎深度解析 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk生态系统的核心组件,专门负责Android启动镜像的多格式解…...

Windows 10 PL2303驱动修复终极指南:3种方案解决串口设备兼容性问题
Windows 10 PL2303驱动修复终极指南:3种方案解决串口设备兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 PL2303驱动修复方案是解决Windows 10系…...

PrismLauncher-Cracked:终极离线启动器解决方案完全指南
PrismLauncher-Cracked:终极离线启动器解决方案完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Online Accou…...

金融机器学习实战:MlFinLab工具包核心模块解析与应用指南
1. 从零到一:为什么我们需要一个金融机器学习的“瑞士军刀”?如果你和我一样,在量化金融和算法交易这条路上摸爬滚打了好几年,那你一定经历过这样的场景:为了复现一篇顶级期刊论文里的某个特征工程方法,你需…...

终极指南:Visual C++运行库一键修复完整教程
终极指南:Visual C运行库一键修复完整教程 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹出"无法启动此程序…...

Open UI5 源代码解析之1378:DestinationField.js
源代码仓库: https://github.com/SAP/openui5 源代码位置:src\sap.ui.integration\src\sap\ui\integration\editor\fields\DestinationField.js DestinationField.js 文件分析 文件定位与整体判断 DestinationField.js 是 sap.ui.integration 编辑器体系中的一个专用字段…...

Tailark部署指南:从开发到生产环境的完整流程
Tailark部署指南:从开发到生产环境的完整流程 【免费下载链接】cnblocks Shadcn marketing blocks 项目地址: https://gitcode.com/gh_mirrors/cn/cnblocks Tailark是一个专为现代营销网站打造的响应式组件库,基于shadcn/ui、Tailwind CSS和Next.…...

【其他】Obsidian笔记Remotely Save插件中国科技云数据胶囊 配置免费的笔记同步
目录 一 注册中国科技云数据胶囊 二 插件下载 & 配置 三 同步测试 一 注册中国科技云数据胶囊 【1】搜索“中国科技云”,找到“数据胶囊”选项,实名注册可以领取20G的容量: 【2】选择“新数据空间”,输入库的标题…...

LeRobot:开源机器人学习的终极指南 - 从零到真实世界的AI机器人控制
LeRobot:开源机器人学习的终极指南 - 从零到真实世界的AI机器人控制 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot LeRobo…...

CANopen通信避坑指南:你的SDO为什么读不到映射变量?从对象字典EDS文件说起
CANopen通信避坑指南:你的SDO为什么读不到映射变量?从对象字典EDS文件说起 调试CANopen通信时,最令人抓狂的瞬间莫过于:从站程序明明能正常读写变量,主站却死活读不到映射值。上周我就遇到一个典型案例——某工业设备厂…...