图像分割——U-Net论文介绍+代码(PyTorch)
0、概要
原理大致介绍了一下,后续会不断精进改的更加详细,然后就是代码可以对自己的数据集进行一个训练,还会不断完善,相应其他代码可以私信我。
一、论文内容总结
摘要:人们普遍认为,深度网络成功需要数千样本,在本文中,提出一种网络和训练方法,它使用大量数据增强来有效使用现存的样本,我们的体系结构由一个捕获上下文的收缩路径和能够实现精确定位的对称扩展路径组成。我们证明出这个网络可以使用少量图像进行端到端训练,并且在ISBI挑战赛上优先于先前的最佳方法(滑动窗口卷积)。并且我们的网络速度很快。
1介绍
目前卷积神经网络的具体用途是用在分类任务上,其中对图像的输出是一个单一的类标签。然而,在许多视觉任务中,特别是在生物医学图像处理中,所期望的输出应该包括定位(每个像素都应该分配一个类标签),另外,医学图像数目不是很多。因此,ciresan等人,在一个滑动窗口设置中训练一个网络,通过在每个像素周围提供一个局部区域(补丁)来预测每个像素的类标签,这个网络可以本地化,并且在当时效果还可以,但是这个网络的也有缺陷,很慢,每个网络必须在每个补丁单独运行,而且由于重叠的补丁,会有很多多余的预测,并且补丁的大小,也决定了预测的这个像素点所结合的上下文或者说是感受野的大小,而这个补丁不能太大也不能太小。所以这就是这个网络所存在问题。
而我们的网络,建立了一个更好的网络,所谓的全卷积网络,我们修改和扩展了这种体系结构,使它可以在很少的训练图像下,产生更精确的分割,网络结构如下图所示。
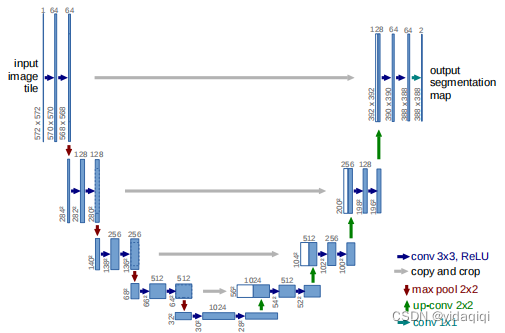
主要思想如下(1)编码器-解码器架构(Encoder-Decoder Structure):U-Net采用了经典的编码器-解码器设计。编码器部分通过一系列的卷积和池化操作对输入图像进行下采样,目的是提取出越来越抽象的特征表示。解码器部分则通过上采样操作(例如转置卷积)逐步将这些特征映射回原始输入的空间维度,以便进行像素级别的预测。
(2)跳跃连接:它允许将编码器路径中的特征图与相应解码器层的特征进行合并。具体来说,在每个上采样步骤之后,会将对应编码器层的输出与解码器的输出拼接在一起。这样做的目的是保留局部的精细结构信息,有助于恢复分割结果中的细节,因为编码器的早期层包含更多空间信息但语义信息较少。
(3)对称性:U-Net的结构在视觉上呈现为“U”形,体现了其编码器和解码器的对称性。这种对称不仅体现在网络结构上,也反映在处理图像信息的方式中,从特征提取到细节恢复的完整流程。
(4)端到端学习与像素级预测:U-Net能够直接在每个像素上进行类别预测,实现了端到端的学习,这对于图像分割任务尤为重要。网络的输出与输入图像大小相同,每个像素都有一个类别标签,适用于精确的图像分割任务。
(5)轻量级和高效性:
2、网络结构
从上图能很清晰的清楚结构,结果十分简单。
3、训练
利用输入图像及其相应的分割图,利用随机梯度下降来训练网络,由于当时还未有填充的卷积,因此输出图像比输入图像小了一个恒定的边界宽度。后边的一些解释大家可以代码过程,这里介绍起来不是很清楚。
4、数据增强
当只有少量的训练样本可用的时候,数据增强对于教会网络所需的不变性和鲁棒性是非常重要的,对于显微镜图像,我们主要需要位移和旋转不变性,以及对变形和灰度值变化的鲁棒性,而训练样本的随机弹性变形时训练一个很少标注图像的分割网络的观念概念。因此我们采用了相应的方法进行了数据增强。
二、代码结构+解释
一、工程文件中有一个文件夹叫model,里面含有两个文件夹,一个是unet_model,另一个是unet_parts,这两个用来定义模型结构。
(1)unet_parts.py 主要包含常用的一些块
""" Parts of the U-Net model """
"""https://github.com/milesial/Pytorch-UNet/blob/master/unet/unet_parts.py"""
import torch
import torch.nn as nn
import torch.nn.functional as F
# 导入torch相关库class DoubleConv(nn.Module): # 继承pytorch中的nn.Moudle类,该类用于构建神经网络中的双卷积块,利用两次连续的卷积操作增强特征表示能力,"""(convolution => [BN] => ReLU) * 2"""def __init__(self, in_channels, out_channels): # 初始化参数,设置输入特征图参数和输出而整体参数super().__init__() # 调用父类的初始化方法,继承父类必要步骤self.double_conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), # padding=1来保持输出尺寸和输入相同nn.BatchNorm2d(out_channels), # 批量归一化层(BN),加速训练过程,提高模型的稳定性和泛化能力。这里针对的是 out_channels 个通道。nn.ReLU(inplace=True), # 应用ReLU激活函数,非线性地增加网络的表达能力nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):return self.double_conv(x) # 返回处理后的输出章# 旨在通过连续的卷积和非线性提取更高级别的特征表示
class Down(nn.Module): # 下采样模块"""Downscaling with maxpool then double conv"""def __init__(self, in_channels, out_channels):super().__init__()self.maxpool_conv = nn.Sequential(nn.MaxPool2d(2), # 最大池化层DoubleConv(in_channels, out_channels) # 卷积或者是下采样)def forward(self, x):return self.maxpool_conv(x)class Up(nn.Module): # 上采样模块"""Upscaling then double conv"""def __init__(self, in_channels, out_channels, bilinear=True): # 初始化参数,选择上采样方式(双线性插值或转置卷积)、定义内部组件。这里选用的是双线性插值来进行上采样super().__init__()# if bilinear, use the normal convolutions to reduce the number of channelsif bilinear:self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)# 缩放因子为2,模式是对齐角落的选项else:self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels) # 用于进一步处理上采样后的特征def forward(self, x1, x2): # 上采样、尺寸调整以及特征融合x1 = self.up(x1) # 上采样特征图# input is CHW# 计算x1和x2在高度和宽度上的插值diffY = torch.tensor([x2.size()[2] - x1.size()[2]])diffX = torch.tensor([x2.size()[3] - x1.size()[3]])x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2]) # 对x1进行填充x = torch.cat([x2, x1], dim=1) # 沿着维度进行拼接,实现特征融合return self.conv(x)class OutConv(nn.Module):def __init__(self, in_channels, out_channels):super(OutConv, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1) # 1*1卷积核降维def forward(self, x):return self.conv(x)(2)unet的网络结构,这里相对于原版的有一些更改的地方,代码也很简单
""" Full assembly of the parts to form the complete network """
"""Refer https://github.com/milesial/Pytorch-UNet/blob/master/unet/unet_model.py"""
import torch.nn as nn
import torch.nn.functional as F
from unet_parts import *
# 导入相关库
# 定义了一个完整的U-Net模型
class UNet(nn.Module):def __init__(self, n_channels, n_classes, bilinear=True):super(UNet, self).__init__()self.n_channels = n_channelsself.n_classes = n_classesself.bilinear = bilinearself.inc = DoubleConv(n_channels, 64)self.down1 = Down(64, 128)self.down2 = Down(128, 256)self.down3 = Down(256, 512)self.down4 = Down(512, 512)self.up1 = Up(1024, 256, bilinear)self.up2 = Up(512, 128, bilinear)self.up3 = Up(256, 64, bilinear)self.up4 = Up(128, 64, bilinear)self.outc = OutConv(64, n_classes)def forward(self, x):x1 = self.inc(x)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)x = self.up1(x5, x4)x = self.up2(x, x3)x = self.up3(x, x2)x = self.up4(x, x1)logits = self.outc(x)return logitsif __name__ == '__main__':net = UNet(n_channels=3, n_classes=1)print(net)二、数据集设定以及图像增强代码
第一个文件夹主要是对数据集进行处理的一个脚本,第二个就是数据集的一个样式或者说规则,在训练过程中,主要相关的代码就是utils中的dataset.py这个脚本,主要作用是根据data路径,然后对数据集进行预处理,翻转这些操作,代码如下所示
import torch
import cv2
import os
import glob
from torch.utils.data import Dataset
import randomclass ISBI_Loader(Dataset):def __init__(self, data_path):# 初始化函数,读取所有data_path下的图片self.data_path = data_pathself.imgs_path = glob.glob(os.path.join(data_path, 'Training_Images/*.jpg')) # 查找指定路径下的所有JPEG图片文件# 表示在data_path路径下的Training_Images文件夹中寻找扩展名为.jpg的所有文件,glob.glob函数会遍历这个路径并且返回一个包含所有匹配文件路径的列表def augment(self, image, flipCode):# 使用cv2.flip进行数据增强,filpCode为1水平翻转,0垂直翻转,-1水平+垂直翻转flip = cv2.flip(image, flipCode)return flipdef __getitem__(self, index):# 根据index读取图片image_path = self.imgs_path[index]# 根据image_path生成label_pathlabel_path = image_path.replace('Training_Images', 'Training_Labels')label_path = label_path.replace('.jpg', '.png') # todo 更新标签文件的逻辑# 生成对应标签图像的路径# 读取训练图片和标签图片# print(image_path)# print(label_path)image = cv2.imread(image_path) # 读进来后就是numpy数组了label = cv2.imread(label_path)image = cv2.resize(image, (512, 512))label = cv2.resize(label, (512, 512), interpolation=cv2.INTER_NEAREST)# 对于label的图像处理时候,明确采用最近邻插值方法来处理尺寸变化,确保标签图像在缩放过程中类别标签不发生模糊,保持其原有的清晰界限。# 将数据转为单通道的图片image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # BGR转成二值图label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)# 处理标签,将像素值为255的改为1if label.max() > 1:label = label / 255# 随机进行数据增强,为2时不做处理,即flipCode = random.choice([-1, 0, 1, 2])if flipCode != 2:image = self.augment(image, flipCode)label = self.augment(label, flipCode)image = image.reshape(1, image.shape[0], image.shape[1])label = label.reshape(1, label.shape[0], label.shape[1])return image, labeldef __len__(self):# 返回训练集大小return len(self.imgs_path)if __name__ == "__main__":isbi_dataset = ISBI_Loader("data/train/")print("数据个数:", len(isbi_dataset))train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,batch_size=2,shuffle=True)for image, label in train_loader:print(image.shape)三、训练代码
这部分就是训练的一整个过程。大
from model.unet_model import UNet
from utils.dataset import ISBI_Loader
from torch import optim
import torch.nn as nn
import torch
from tqdm import tqdmdef train_net(net, device, data_path, epochs=40, batch_size=1, lr=0.00001):# 加载训练集isbi_dataset = ISBI_Loader(data_path)per_epoch_num = len(isbi_dataset) / batch_sizetrain_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,batch_size=batch_size,shuffle=True)# 定义RMSprop算法optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)# 定义Loss算法criterion = nn.BCEWithLogitsLoss()# best_loss统计,初始化为正无穷best_loss = float('inf')# 训练epochs次with tqdm(total=epochs*per_epoch_num) as pbar:for epoch in range(epochs):# 训练模式net.train()# 按照batch_size开始训练for image, label in train_loader:optimizer.zero_grad()# 将数据拷贝到device中image = image.to(device=device, dtype=torch.float32)label = label.to(device=device, dtype=torch.float32)# 使用网络参数,输出预测结果pred = net(image)# 计算lossloss = criterion(pred, label)# print('{}/{}:Loss/train'.format(epoch + 1, epochs), loss.item())# 保存loss值最小的网络参数if loss < best_loss:best_loss = losstorch.save(net.state_dict(), 'best_model.pth')# 更新参数loss.backward()optimizer.step()pbar.update(1)if __name__ == "__main__":# 选择设备,有cuda用cuda,没有就用cpudevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载网络,图片单通道1,分类为1。net = UNet(n_channels=1, n_classes=1) # todo edit input_channels n_classes# 将网络拷贝到deivce中net.to(device=device)# 指定训练集地址,开始训练data_path = r"D:\新建文件夹 (3)\VOCdevkit3000\VOCdevkit\VOC2007\data" # todo 修改为你本地的数据集位置train_net(net, device, data_path, epochs=50, batch_size=4)
四、总结
大致可能有些粗劣的介绍了U-Net的相关原理,以及代码,给出的代码可以训练,如果有需要完整工程文件的可以私信我。有错误的地方希望批评指正,感谢感谢
相关文章:
图像分割——U-Net论文介绍+代码(PyTorch)
0、概要 原理大致介绍了一下,后续会不断精进改的更加详细,然后就是代码可以对自己的数据集进行一个训练,还会不断完善,相应其他代码可以私信我。 一、论文内容总结 摘要:人们普遍认为,深度网络成功需要数…...
C#进阶-ASP.NET的WebService跨域CORS问题解决方案
在现代的Web应用程序开发中,跨域资源共享(Cross-Origin Resource Sharing, CORS)问题是开发者经常遇到的一个挑战。特别是当前端和后端服务部署在不同的域名或端口时,CORS问题就会显得尤为突出。在这篇博客中,我们将深…...

如何利用TikTok矩阵源码实现自动定时发布和高效多账号管理
在如今社交媒体的盛行下,TikTok已成为全球范围内最受欢迎的短视频平台之一。对于那些希望提高效率的内容创作者而言,手动发布和管理多个TikTok账号可能会是一项繁琐且耗时的任务。幸运的是,通过利用TikTok矩阵源码,我们可以实现自…...

Java高级编程技术详解:从多线程到算法优化的全面指南
复杂度与优化 复杂度与优化在算法中的应用 算法复杂度是衡量算法效率的重要指标。了解和优化算法复杂度对提升程序性能非常关键。本文将介绍时间复杂度和空间复杂度的基本概念,并探讨一些优化技术。 时间复杂度和空间复杂度 时间复杂度表示算法执行所需时间随输…...

Redis 分布式锁过期了,还没处理完怎么办?
为了防止死锁,我们会给分布式锁加一个过期时间,但是万一这个时间到了,我们业务逻辑还没处理完,怎么办? 这是一个分布式应用里很常见到的需求,关于这个问题,有经验的程序员会怎么处理呢ÿ…...

Vue2+Element-ui后台系统常用js方法
el-dialog弹框关闭清空form表单并清空验证 cancelDialog(diaLog, formRef) {this[diaLog] falseif (formRef) {this.$refs[formRef].resetFields()} }页面使用: <el-dialog :visible.sync"addSubsidyDialog.dialog" close"cancelDialog(addSub…...

Kafka高频面试题整理
文章目录 1、什么是Kafka?2、kafka基本概念3、工作流程4、Kafka的数据模型与消息存储机制1)索引文件2)数据文件 5、ACKS 机制6、生产者重试机制:7、kafka是pull还是push8、kafka高性能高吞吐的原因1)磁盘顺序读写:保证了消息的堆积2)零拷贝机…...

uniapp地图自定义文字和图标
这是我的结构: <map classmap id"map" :latitude"latitude" :longitude"longitude" markertap"handleMarkerClick" :show-location"true" :markers"covers" /> 记住别忘了在data中定义变量…...

k8s_探针专题
关于探针 生产环境中一定要给pod设置探针,不然pod内的应用发生异常时,K8s将不会重启pod。 需要遵循以下几个原则(本人自己总结,仅供参考): 探针尽量简单,不要消耗过多资源。因为探针较为频繁的…...

MySQL触发器基本结构
1、修改分隔符符号 delimiter $$ 可以修改成$$ //都行 2、创建触发器函数名称 create trigger 函数名 3、什么样的操作出发,操作那个表 after:......之后触发 befor:......之前触发 insert:插入被触发 update:修改被触…...

前缀和(一维前缀和+二维前缀和)
前缀和 定义: 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的逆运算。合理的使用前缀和与差分,可以将某些复杂的问题简单化。 用途: 前缀和一般用于统计一个区间的和&…...

web前端五行属性:深入探索与实战解析
web前端五行属性:深入探索与实战解析 在Web前端开发中,五行属性这一概念或许听起来有些陌生。然而,如果我们将其与前端开发的核心理念相结合,就能发现其中蕴含的深刻内涵。本文将从四个方面、五个方面、六个方面和七个方面&#…...

白酒:茅台镇白酒的酒厂社会责任与可持续发展
云仓酒庄豪迈白酒,作为茅台镇的品牌,不仅在产品品质和口感方面有着卓着的表现,在酒厂社会责任和可持续发展方面也做出了积极的探索和实践。 首先,云仓酒庄豪迈白酒注重环境保护和资源利用。酒厂在生产过程中严格控制能源消耗和排放…...

音视频开发_SDL音频播放器的实现
今天向大家介绍一下如何通过 SDL 实现一个PCM音频播放器。这是一个最简单的播放器,它不涉及到音频的解复用,解码等工作。我们只需要将音频原始数据喂给 SDL 音频接口就可以听到悦耳的声音了。在下面的列子中我将向你演示,使用 SDL 做这样一个…...
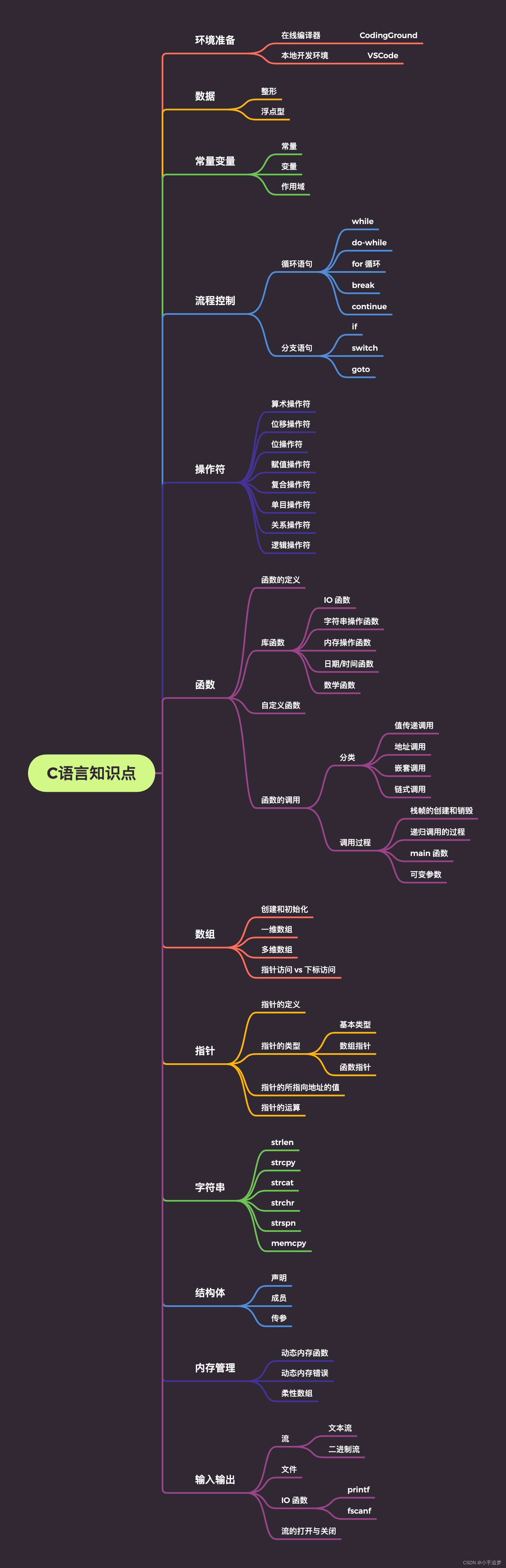
C语言学习系列:初识C语言
前言,C语言是什么 语言,比如中文、英语、法语、德语等,是人与人交流的工具。 C语言也是语言,不过是一种特殊的语言,是人与计算机交流的工具。 为什么叫C语言呢? 这就要从C语言的历史说起了。 一&#…...
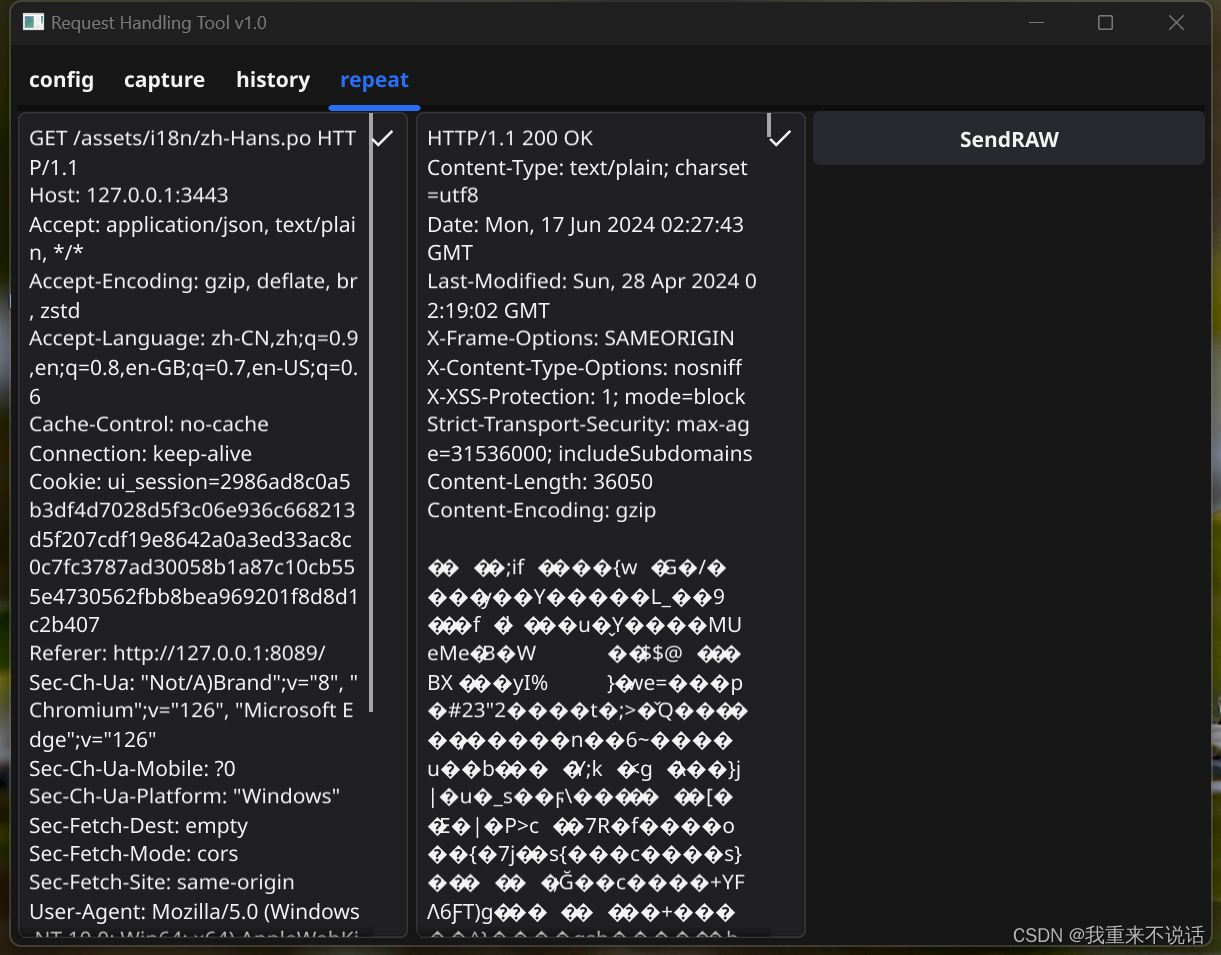
利用反向代理编写HTTP抓包工具——可视化界面
手写HTTP抓包工具——可视化界面 项目描述语言golang可视化fynev2功能代理抓包、重发、记录 目录 1. 示例1.1 主界面1.2 开启反向代理1.3 抓包1.4 历史记录1.5 重发 2. 核心代码2.1 GUI2.1 抓包 3. 结语3.1 传送门 1. 示例 1.1 主界面 1.2 开启反向代理 1.3 抓包 1.4 历史记录…...

下拉框数据被遮挡 且 后续数据无法下拉的 解决方法
目录 前言1. 问题所示2. 原理分析3. 解决方法3.1 添加空白版2.2 调整z-index2.3 父容器的溢出属性2.4 调整样式属性4. 效果图前言 小程序使用的是Uniapp,原理都差不多,索性标题就不标注Uniapp(小程序) 对于该问题调试了一个晚上,最终解决,对此记录下来 1. 问题所示 执…...

课设--学生成绩管理系统(二)
欢迎来到 Papicatch的博客 目录 🐋引言 🦈编写目的 🦈项目说明 🐋产品介绍 🦈产品概要说明 🦈产品用户定位 🦈产品中的角色 🐋 产品总体业务流程图 🐋 产品功…...

STM32CubeMX配置-外部中断配置
一、简介 MCU为STM32G070,配置为上升沿触发外部中断,在上升沿外部中断回调函数中进行相关操作。 二、外部中断配置 查看规格书中管教描述,找到I/O对应的外部中断线,然后进行如下上升沿触发外部中断配置。 三、生成代码 调用上升沿…...

基于Vue的日程排班表 - common-schedule
原文:基于Vue的日程排班表 - common-schedule-CSDN博客...

零基础学 Web 安全 20256最全系统入门攻略
“未知攻,焉知防”——真正的安全始于理解攻击者的思维 在日益数字化的世界中,Web安全工程师已成为企业防护体系的“数字盾牌”。本文将提供一条清晰的进阶路径,助你在2025年的网络安全领域脱颖而出。 一、认知篇:理解安全本质 …...

影刀RPA 从0到1:自动化系统架构收敛与工程化演进总结
影刀RPA 从0到1:自动化系统架构收敛与工程化演进总结 作者:林焱 写到这里。 这个系列其实已经慢慢进入后半段了。 前面聊了很多内容。 包括: 浏览器池 节点集群 Redis 队列 调度系统 容灾恢复 日志监控 性能治理 很多人刚开始接…...

Agent Runtime 正在 commoditize:从 session-as-event-log 看 AI 基础设施分层
1. 这不是新赛道,而是 runtime 层的“操作系统时刻”正在重演你打开手机看到新闻标题《Anthropic Just Shipped the Layer That’s Already Going to Zero》,第一反应可能是:又一个大模型公司搞出了什么黑科技?但如果你真花十分钟…...

AI Newsletter的本质:一种高信噪比的信息过滤与认知校准方法论
1. 项目概述:一份“AI Newsletter”背后的真实工作流与信息筛选逻辑你点开邮箱,看到标题为This AI newsletter is all you need #41的邮件——它没用夸张的“爆炸性突破”“颠覆认知”这类词,也没塞满emoji和感叹号,但你还是点了开…...

VHS Pro深度解析:Unity中模拟真实录像机信号链的原理与实践
1. 这不是“加个滤镜”那么简单:VHS Pro 的真实定位与行业缺口你打开 Unity Asset Store,搜“vhs”,会跳出二十多个插件。有的叫 VHS Effect,有的叫 Retro Tape,还有的直接叫 “80s Glitch”。点开预览图,全…...

美国签证预约机器人:3分钟掌握24小时智能抢号终极方案
美国签证预约机器人:3分钟掌握24小时智能抢号终极方案 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 还在为美国签证面试预约的漫长等待而烦恼吗?面对有限的面试名额和激烈的竞争环境&…...

JWT密钥轮换缺陷与零停机热修复实战指南
1. 这不是一次普通升级,而是一次密钥信任体系的临界点崩塌Seedance2.0 v2.0.3发布不到72小时,我在给客户做例行安全巡检时,发现一个反直觉的现象:所有新签发的JWT令牌在旧版本客户端(v2.0.2)上验证失败&…...

VM振弦采集模块精度实测:从标准信号源到误差分析全流程
1. 项目概述与核心价值最近在做一个岩土工程安全监测的项目,其中有个环节让我琢磨了好一阵子:如何准确地评估我们用的那批VM振弦采集模块的测量精度。这玩意儿在结构健康监测、桥梁隧道、边坡稳定性监测里用得非常多,核心任务就是读取振弦式传…...

消费电子贴膜的光学技术革新:圆偏振光与磁控溅射AR的原理解析
摘要随着用户对屏幕使用健康关注的提升,消费电子贴膜行业正在经历从“物理防护”到“光学级视觉守护”的技术升级。本文从光学原理出发,解析圆偏振光柔光标准与磁控溅射AR抗眩镀膜两项核心技术的工作机制,并分析其在屏幕保护场景中的应用逻辑…...

带标注的螺丝、螺栓、垫圈缺陷识别数据集,包含缺陷里包含生锈和划痕,1291张图,支持yolo,coco json,voc xml,文末有模型训练代码。
带标注的螺丝、螺栓、垫圈缺陷识别数据集,包含缺陷里包含生锈和划痕,1291张图,支持yolo,coco json,voc xml,文末有模型训练代码。 数据集拆分 总图数:1291 张图数 训练集 1143 张图 验证集 106 张图…...