Elasticsearch 第二期:倒排索引,分析,映射
前言
正像前面所说,ES真正强大之处在于可以从无规律的数据中找出有意义的信息——从“大数据”到“大信息”。这也是Elasticsearch一开始就将自己定位为搜索引擎,而不是数据存储的一个原因。因此用这一篇文字记录ES搜索的过程。
关于ES搜索计划分两篇或者三篇内容进行整理。一篇整理相关知识和设计思想。后面根据不同场景整理对应的命令使用。
这一篇文字记录ES搜索的过程。采用倒序的方式,从上到下分别介绍了三方面的内容
-
倒排索引:ES支持全文搜索的数据支持
-
分析和分析器:倒排索引是怎么产生的
-
映射:根据映射后的索引类型来判断分析和搜索策略
倒排索引
Elasticsearch 不只会存储(stores)文档,为了能被搜索到也会为文档添加索引(indexes)。
为了可以进行快速的全文搜索,Elasticsearch 使用一种称为 倒排索引(inverted index,也称反向索引) 的结构。
有倒排索引,肯定会对应有正向索引(forward index)
所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。
但是互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射(跟正向索引反过来了),每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
关于倒序索引,官方的例子很经典。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
-
The quick brown fox jumped over the lazy dog
-
Quick brown foxes leap over lazy dogs in summer
在看官网的时候就很困惑。"content域"如何解释?找遍全网,几乎关于倒排索引都是举的这个例子,一字不差。对于"content域"也都是照搬官网。
灵机一动,看一下英文原文吧。恍然大悟。所谓“域”,其英文为“field”。这就好理解了。
field也是ES的一个重要概念,官方翻译为“字段”,类比MySQL中的Colums(列)
为了创建倒排索引,我们首先将每个文档的 content 字段拆分成单独的 词(我们称它为 词条 或 tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
但是,我们目前的倒排索引有一些问题:
-
大小写:
Quick和quick以独立的词条出现,然而用户可能认为它们是相同的词。 -
词根相同或相似:
fox和foxes非常相似, 就像dog和dogs -
词义相同或相似:
jumped和leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
使用前面的索引搜索,如果想搜索 同时出现 Quick 和 fox 的文档,会发现没有两个文档都不满足查询条件。尽管第一个文档包含 quick fox ,第二个文档包含 Quick foxes 。关于这种场景,可以进一步将倒排索引中的词条规范为标准模式,那么我们可以找到与用户搜索的词条不完全一致,但具有足够相关性的文档。
例如:
-
统一大小写:
Quick可以小写化为quick。 -
提前词根:
foxes可以 词干提取 --变为词根的格式-- 为fox。类似的,dogs可以为提取为dog。 -
同义词关联:
jumped和leap是同义词,可以索引为相同的单词jump。
现在索引看上去像这样:
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
------------------------这还远远不够。我们搜索 +Quick +fox 仍然 会失败,因为在我们的索引中,已经没有 Quick 了。但是,如果我们对搜索的字符串使用与 content 域相同的标准化规则,会变成查询 +quick +fox ,这样两个文档都会匹配!
若想了解倒排索引是如何生成的,就继续往下看“分析与分析器”。
分析与分析器
在保存的数据的时候,往往都是保存长句子或者长段落。而倒排索引是以独立的词条为单位进行索引的,如何将长句子分割成词条呢?就需要用到分析和分析器。
分析(Analysis),全文是如何处理使之可以被搜索的。分析 包含下面的过程:
-
首先,将一块文本分成适合于倒排索引的独立的 词条 ,
-
之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器
分析器 实际上是将三个功能封装到了一起:
| 字符过滤器 | 首先,字符串按顺序通过每个字符过滤器 。他们的任务是在分词前整理字符串。如去掉HTML,或者将 & 转化成 and。 |
| 分词器 | 其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。 |
| Token 过滤器 (词单元过滤器) | 最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化 |
ES自带了分析器,我们称之为:内置分析器。以下面的一句话为例来对比不同分析器的分析结果。
"Set the shape to semi-transparent by calling set_trans(5)"| 分析器名称 | 介绍 | 分析结果 |
| 标准分析器 | 默认使用的分析器。它根据 Unicode 联盟定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写。 | set, the, shape, to, semi, transparent, by, calling, set_trans, 5 |
| 简单分析器 | 在任何不是字母的地方分隔文本,将词条小写。 | set, the, shape, to, semi, transparent, by, calling, set, trans |
| 空格分析器 | 在空格的地方划分文本。 | Set, the, shape, to, semi-transparent, by, calling, set_trans(5) |
| 语言分析器 | 语言分析器可以根据特定来设定相应的语言分析器,从而考虑指定语言的特点。 例如, 英语 分析器附带了一组英语无用词(常用单词,例如 and 或者 the ,它们对相关性没有多少影响),它们会被删除。 由于理解英语语法的规则,这个分词器可以提取英语单词的 词干 。英语 分词器会产生下面的词条: | set, shape, semi, transpar, call, set_tran, 5(注意看 |
中文分析器
ES自带的分析器对英文单词比较友好,对中文分词效果不好。如使用自带的分析器来分析“天安门广场”,可能会分为:“天”,“安”,“门”,“广”,“场”。不过ES支持安装分词插件,增加新的分词器。目前中文分词器比较常用的有:smartcn和ik两种。
其中,smartcn是目前ES官方推荐的中文分词插件,不过目前不支持自定义词库。
ik分词器支持自定义扩展词库,有时候分词的结果不满足我们业务需要,需要根据业务设置专门的词库,分词的时候优先根据词库设置的关键词分割内容。
ik分词插件支持 ik_smart 和 ik_max_word 两种分词器
-
ik_smart - 粗粒度的分词
-
ik_max_word - 会尽可能的枚举可能的关键词,就是分词比较细致一些,会分解出更多的关键词
映射
用过ES就知道,当向ES新增数据时,不用向Mysql一样需要来指明字段的类型,这是因为ES默认为每个字段分配了类型。并且在ES中,不同字段类型的搜索方式是不同的。默认:日期、数值的搜索方式是精确等值搜索,而字符串默认是全文搜索。
所谓的映射是指,将输入和其对应的数据类型进行一一对应,如输入123,就会映射到数值类型。然后根据映射到的索引类型进行分析。
| JSON类型 | 索引类型 |
| true或false | boolean |
| integer | long |
| object | object(对象) |
| array | 根据数组中的第一个非空值进行判断 |
| string | date、double、long、text,根据数据形式进行判断 |
| keyword | keyword类型是不进行切分的字符串类型。这里的"不进行切分"指的是: 在索引时,对keyword类型的数据不进行切分,直接构建倒排索引; 在搜索时,对该类型的查询字符串不进行切分后的部分匹配。 在现实场景中,keyword经典用于描述姓名、产品类型、用户ID、URL和状态码等。对数据进行部分匹配,因此一般查询这种类型的数据时使用term查询。 |
text | text类型是可进行切分的字符串类型。这里的“可切分”指的是: 在索引时,可按照相应的切词算法对文本内容进行切分,然后构建倒排索引; 在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分。 |
| 整数 |
|
| 浮点数 |
|
| 布尔型 | 使用boolean定义写入或者查询该类型的数据时,其值可以使用true和false,或者使用字符串形式的"true"和"false" |
| 日期 |
|
在一般情况下,如果使用基本类型数据,最好先把数据类型定义好,因为ES的动态映射生成的字段类型可能会与用户的预期有差别。如 price=“1.334”。若不定义数据类型,ES会将该字段设置为text类型。对于搜索时可能会造成歧义。
当然,对于一个字段,我们可能既需要text类型来保证实现模糊查询,又希望有keyword类型的特性来进行排序。ES也是支持这种操作的,可以对该字段先后定义为text类型和keyword类型,其中,keyword类型的字段叫作子字段,这样ES在建立索引时会将姓名字段建立两份索引,即text类型的索引和keyword类型的索引。
总结
这篇笔记各章节的顺序其实是反的。应该是在索引保存的时候,根据字段映射,判断各字段的分析策略,从而再构建对应的倒排索引。其实还有个疑问,对于多条件搜索时,mysql会对每个索引创建一个B+树,倒排索引如何创建索引呢?
拓展文档
Elasticsearch 存储结构 - 梯子教程网
Elasticsearch(四)--一文弄懂ES的映射操作_es 动态映射-CSDN博客
倒排索引 | Elasticsearch: 权威指南 | Elastic
相关文章:

Elasticsearch 第二期:倒排索引,分析,映射
前言 正像前面所说,ES真正强大之处在于可以从无规律的数据中找出有意义的信息——从“大数据”到“大信息”。这也是Elasticsearch一开始就将自己定位为搜索引擎,而不是数据存储的一个原因。因此用这一篇文字记录ES搜索的过程。 关于ES搜索计划分两篇或…...
函数的一点点习题
1、利用递归计算0-n的和 #include <stdio.h> #include <string.h> #include <stdlib.h> int rec(int n) {if(n0)return 0;elsereturn nrec(n-1); } int main(int argc, const char *argv[]) {int n0;printf("please enter n:");scanf("%d&quo…...

使用Java计算Linux系统中sum命令得到的校验值
目录 ■相关知识 ・sum 命令 ・BSD校验算法是什么 ・BSD校验算法 和hash值 有区别吗 ・BSD校验算法,为什么是BSD,这个缩写代表什么 ■Java代码 ■效果 ====== ■相关知识 ・…...
】)
鸿蒙开发电话服务:【 @ohos.telephony.sms (短信服务)】
短信服务 说明: 本模块首批接口从API version 6开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import sms from ohos.telephony.sms;sms.createMessage createMessage(pdu: Array, specification: string, callback: Asy…...
算法02 递归算法及其相关问题【C++实现】
递归 在编程中,我们把函数直接或者间接调用自身的过程叫做递归。 递归处理问题的过程是:通常把一个大型的复杂问题,转变成一个与原问题类似的,规模更小的问题来进行求解。 递归的三大要素 函数的参数。在用递归解决问题时&…...

Sermant标签路由能力在同城双活场景的应用
作者:聂子雄 华为云高级软件工程师 摘要:目前应用上云已成为趋势,用户也对应用在云上的高可靠方案有更高追求,目前同城双活场景作为应用高可靠方案中的一种常见实践方案,对微服务流量提出了数据中心亲和性的要求&…...

javascript-obfuscator混淆
安装 npm install javascript-obfuscator -g 配置 重度混淆,性能低 性能下降50-100% { "compact": true, "controlFlowFlattening": true, "controlFlowFlatteningThreshold": 0.75, // 设置为0到1之间的值 "deadCodeI…...

GitHub项目里的api
在一个GitHub项目中提到的"api"通常指的是该项目提供的应用程序编程接口(Application Programming Interface)。这意味着该项目包含了一套规则和工具,允许其他开发者通过代码调用该接口来与项目功能互动、获取数据或执行特定任务。…...

k8s可练习实验分享
实验环境介绍:单master节点+3node节点 环境已提前配置完毕,如果你环境还未做,请移步 k8s集群V1.27.3安装 在 k8s 上可以做许多实验来提升你的动手能力和理解。以下是一些常见且有用的实验项目: 1、部署一个简单的应用…...

浏览器支持http-flv协议
Google Chrome 浏览器和Microsoft Edge 浏览器原生并不支持 HTTP-FLV 协议。HTTP-FLV 主要与 Flash Player 相关,而 Flash Player 已经在 2020 年底停止支持,并且 Microsoft Edge 也逐步淘汰了对 Flash 的支持。 flv.js 利用 HTML5 和 Media Source Exte…...
)
一千题,No.0077(计算谱半径)
在数学中,矩阵的“谱半径”是指其特征值的模集合的上确界。换言之,对于给定的 n 个复数空间的特征值 { a1b1i,⋯,anbni },它们的模为实部与虚部的平方和的开方,而“谱半径”就是最大模。 现在给定一些复数空间的特征值&a…...
安卓/iOS/Linux系统影音边下边播P2P传输解决方案
在当今的数字时代,IPTV 影音行业正经历着快速的发展和变革,但影音行业的流量带宽成本一直很高,有没有什么办法既能保证现有的用户观看体验,又能很好降低流量带宽成本呢? P2P技术可能是一个很好的选择,它不仅仅可以提…...

STORM论文阅读笔记
这是篇NIPS2023的 world model 论文文章提出,WM的误差会在训练过程中积累从而影响policy的训练,向WM中加噪声可以改善这一点。其他的流程和IRIS差不多,差别在以下几点: image encoder,IRIS用的VQVAE, 本文用的是VAE&am…...

Web前端遇到的难题:挑战与突破之路
Web前端遇到的难题:挑战与突破之路 在快速发展的互联网时代,Web前端技术作为连接用户与应用程序的桥梁,扮演着举足轻重的角色。然而,在实际开发中,Web前端开发者往往会遇到诸多难题。本文将从四个方面、五个方面、六个…...

C#防止多次注册事件
事件声明和使用部分的代码,防止多次注册事件主要通过判断事件中类型的委托实例是否为空实现 public class ReRegisterEvent {public delegate void Mydelegate(string message);private Mydelegate? mydel;public event Mydelegate Myevent{add{if (mydel null){…...
【UML用户指南】-16-对高级结构建模-构件
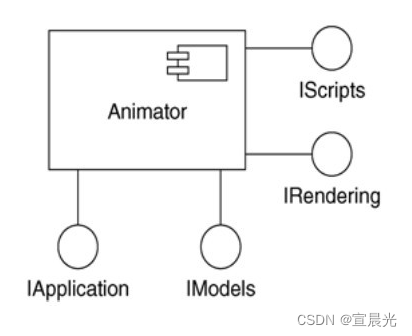
目录 1、概念 2、构件与接口 3、可替换性 4、组织构件 5、端口 6、内部结构 6.1、部件 6.2、连接件 7、常用建模技术 7.1、对结构类建模 7.2、对API建模 构件是系统中逻辑的并且可替换的部分,它遵循并提供对一组接口的实现。好的构件用定义良好的接口来定…...
双Token方案实现Token自动续期(基于springboot+vue前后端分离项目)
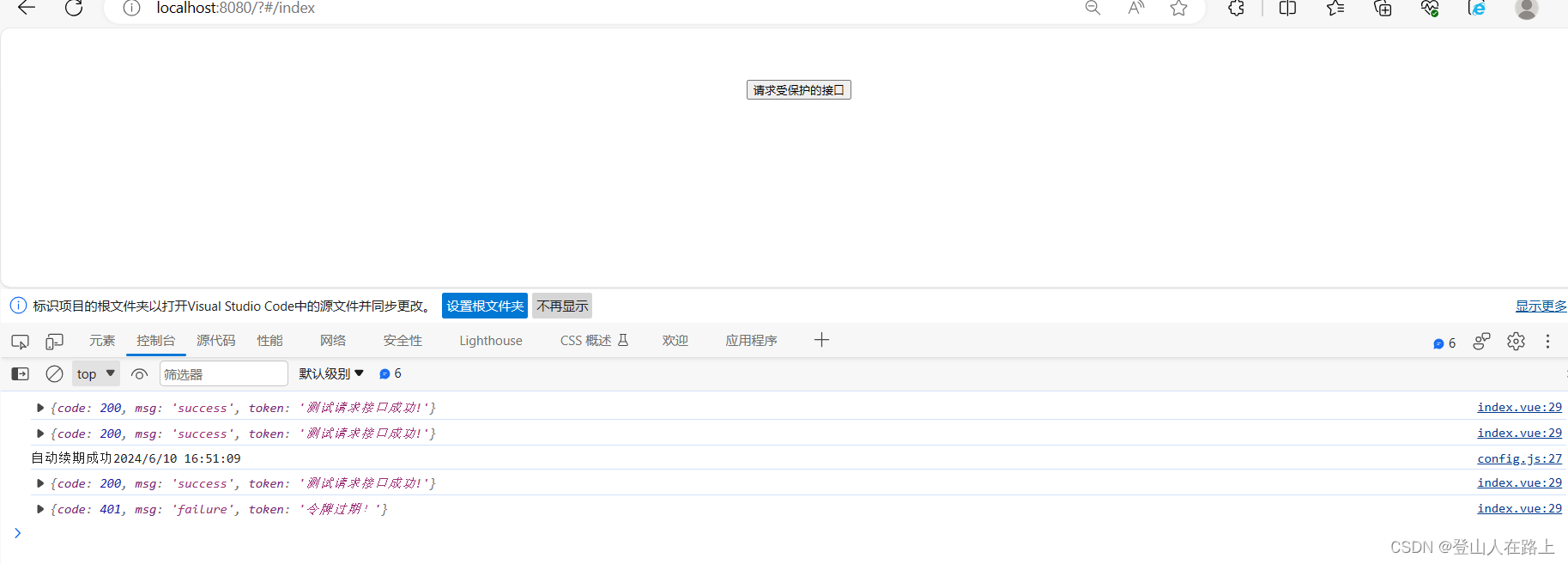
文章目录 前言一、双Token方案介绍1. 令牌类型与功能2.双Token方案的优点3.实现流程 二、具体实现1.后端实现1.1 jwt工具类1.2 响应工具类1.3 实体类1.4 过滤器1.5 controller1.6 启动类 2、前端实现2.1 登录页面2.2 index页面2.3 请求拦截器和响应拦截器 效果展示 前言 更多j…...

别太小看“静态免杀“
0x01 简述 免杀总体来说可分为两种,静态免杀/动态免杀。往往来说,我们更注重于在内部代码层面实现一些免杀技巧,但在有些时候,动态免杀静态免杀以"打组合拳"的方式效果往往会更出人所料。 当我们的程序生成后…...

SQL server 内连接 左连接 右连接 全连接 语句
在SQL Server中,连接(JOIN)操作用于从两个或多个表中检索相关数据。内连接、左连接、右连接和全连接是最常用的几种连接类型。下面详细介绍每种连接的用法和区别: 1. 内连接 (INNER JOIN) 内连接只返回两个表中满足连接条件的匹…...

k8s中的pod域名解析失败定位案例
问题描述 我在k8s中启动了一个Host网络模式的pod,这个pod的域名解析失败了。 定位步骤 敲kubectl exec -it [pod_name] -- bash进入pod后台,查看/etc/resolv.conf,发现nameserver配的有问题。这里我预期的nameserver应该使用宿主机的&…...

EDA工具链互操作性:从概念到实践,破解芯片设计数据孤岛
1. 互操作性:一个被误解的工程圣杯 在半导体和电子设计自动化(EDA)这个行当里干了十几年,我听到“互操作性”这个词的频率,可能比听到“摩尔定律”还要高。每次行业巨头们坐下来,宣布要共同制定一个新标准时…...

汽车电喷系统间歇性启动故障诊断:从信号缺失到精准修复
1. 故障现象与初步排查:一个“不合常理”的启动问题我父亲打电话来,说他的皮卡又启动不了了,得“灌点油”才能着车。我一听就觉得不对劲,这车是电喷的,又不是化油器老古董,哪有用汽油“灌喉”来启动的道理&…...

告别臃肿!Dell G15笔记本散热控制的轻量级开源替代方案
告别臃肿!Dell G15笔记本散热控制的轻量级开源替代方案 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否厌倦了Dell原厂AWCC软件的缓慢响应和…...

如何快速掌握 AI 工具应用能力
先选常用工具,聚焦深耕不用贪多,熟练 2-3 款主流大模型、AI 办公、AIGC 工具,专注实操,不盲目跟风换工具。学好提示词使用技巧学会清晰、具体、结构化提问,精准下达指令,让 AI 高质量完成文案、整理、解题、…...

Go语言单例模式如何实现_Go语言单例模式教程【通俗】
sync.Once是最安全的单例初始化方式,天然解决并发首次调用竞态问题,只执行一次闭包;须作包级或结构体字段,避免局部变量失效;panic后会持续失败,需自行兜底。Go 里 sync.Once 是最安全的单例初始化方式直接…...

SyntaxUI:基于Tailwind CSS与Framer Motion的React组件库实战指南
1. 项目概述:SyntaxUI,一个为现代Web开发者提速的组件库如果你和我一样,常年奋战在React、Next.js项目的一线,那你一定对“重复造轮子”这件事深恶痛绝。每次新项目启动,从零开始搭建按钮、卡片、模态框、导航栏&#…...

终极开源语音AI工具包:Sherpa-Onnx一站式解决方案
终极开源语音AI工具包:Sherpa-Onnx一站式解决方案 【免费下载链接】sherpa-onnx Speech-to-text, text-to-speech, speaker diarization, speech enhancement, source separation, and VAD using next-gen Kaldi with onnxruntime without Internet connection. Sup…...

用Claude Code+R零代码复现医学顶刊论文:零基础到掌握全流程医学SCI论文训练营
人工智能飞速发展,对于研究生、科研工作者而言,只需要聚焦研究问题创新,统计实操、图表制作、结果呈现等等SCI论文中涉及的工作都有工具可以帮你……我们团队最新开设:“零基础掌握SCI论文全流程:Claude CodeR零代码复…...

LocalChat:零门槛本地部署开源大语言模型,实现隐私安全的离线AI对话
1. 项目概述与核心价值如果你和我一样,对ChatGPT这类大语言模型的能力感到兴奋,但又对数据隐私、服务依赖和网络延迟心存顾虑,那么LocalChat这个项目可能就是为你量身打造的。简单来说,LocalChat是一个让你能在自己电脑上…...

从HEX到芯片:使用J-Flash实现高效固件烧录与生产级加密
1. 认识J-Flash:你的芯片烧录好帮手 第一次接触J-Flash时,我正为一个量产项目发愁——需要给500片GD32F103烧录固件。手动用IDE一个个烧?效率太低;找代工厂?成本太高。直到同事推荐了J-Flash,我才发现原来烧…...