ES 操作
1、删除索引的所有记录
curl -X POST "localhost:9200/<index-name>/_delete_by_query" -H 'Content-Type: application/json' -d'
{"query": {"match_all": {}}
}
'POST /content_erp_nlp_help/_delete_by_query
{
"query": {
"match_all": {}
}
}
2、创建索引模板
PUT _template/content_erp_nlp_help
{
"index_patterns": [
"content_vector*"
],
"settings": {
"analysis": {
"analyzer": {
"my_ik_analyzer": {
"type": "ik_smart"
}
}
},
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content_vector": {
"type": "dense_vector",
"similarity": "cosine",
"index": true,
"dims": 768,
"element_type": "float",
"index_options": {
"type": "hnsw",
"m": 16,
"ef_construction": 128
}
},
"content_answer": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"param": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"type": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
3
使用must还是should在布尔查询中取决于你的具体需求和期望的查询行为。
使用 must
当你使用must时,所有包含在must列表中的子查询都必须匹配。这意味着,为了使文档成为搜索结果的一部分,文档必须同时满足所有must查询的条件。如果你的意图是找到同时与文本查询和KNN向量查询匹配的文档,那么使用must是合适的。这通常用于要求严格的匹配场景,比如需要文档同时具有特定的文本特征和与某向量相近。
使用 should
相比之下,should表示查询中的任意子查询匹配即可。如果至少有一个should子查询匹配,那么文档就会被视为匹配。这提供了更大的灵活性,意味着即使文档只满足文本查询或KNN查询中的一个,它也可能出现在结果中。这对于希望扩大搜索范围,或者允许部分条件匹配的情况非常有用。
效果比较
- 精确性 vs. 宽泛性:
must查询倾向于提供更精确的结果集,因为所有条件都必须满足。而should查询可能产生更宽泛的结果,因为它允许部分条件匹配。 - 性能影响: 在某些情况下,使用
should可能会导致更多的文档被扫描和评估,从而可能略微降低查询性能。这是因为Elasticsearch需要检查每个should子查询是否匹配。
混合使用 must 和 should
在很多情况下,混合使用must和should可以达到最佳的效果。例如,你可以定义一些硬性条件作为must,确保结果至少满足这些核心需求,同时使用should来增加结果的丰富度和多样性,如:
Java
1BoolQuery boolQuery = new BoolQuery.Builder()
2 .must(matchQuery) // 必须满足的文本匹配
3 .should(knnQuery) // 可以满足的向量相似性
4 .build();在这个例子中,所有结果必须与文本查询匹配,但如果文档还与KNN查询匹配,则会获得更高的相关性评分,从而可能在结果中排名更高。
总结
选择使用must还是should主要取决于你的业务逻辑和你对查询结果的期望。如果你需要严格的匹配条件,使用must;如果你希望结果更加宽泛和多样化,使用should;如果你需要两者之间的平衡,考虑混合使用两者。
相关文章:

ES 操作
1、删除索引的所有记录 curl -X POST "localhost:9200/<index-name>/_delete_by_query" -H Content-Type: application/json -d {"query": {"match_all": {}} }POST /content_erp_nlp_help/_delete_by_query { "query": { &quo…...

uniapp如何实现跳转
在 UniApp 中,页面跳转主要可以通过两种方式实现:使用 <navigator> 组件和调用 UniApp 提供的导航 API。以下是这两种方式的详细说明: 1. 使用 <navigator> 组件 <navigator> 组件允许你在页面上创建一个可点击的元素&am…...
Stable-Diffusion-WebUI 常用提示词插件
SixGod提示词插件 SixGod提示词插件可以帮助用户快速生成逼真、有创意的图像。其中包含,清空正向提示词”和“清空负向提示词、提示词起手式包含人物、服饰、人物发型等各个维度的提示词、一键清除正面提示词与负面提示词、随机灵感关键词、提示词分类组合随机、动…...
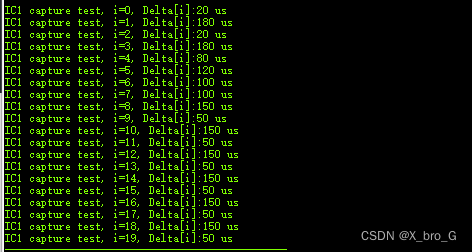
单片机 PWM输入捕获【学习记录】
前言 学习是永无止境的,就算之前学过的东西再次学习一遍也能狗学习到很多东西,输入捕获很早之前就用过了,但是仅仅是照搬例程没有去进行理解。温故而知新! 定时器 定时器简介 定时器的分类 高级定时器 通用定时器 基本定时器…...
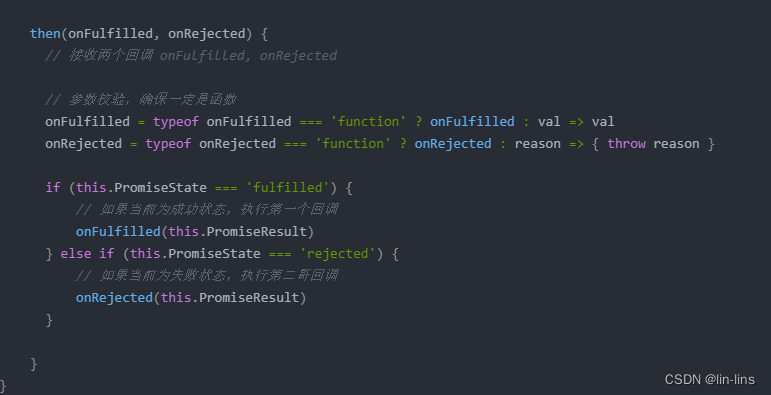
3.1、前端异步编程(超详细手写实现Promise;实现all、race、allSettled、any;async/await的使用)
前端异步编程规范 Promise介绍手写Promise(resolve,reject)手写Promise(then)Promise相关 API实现allraceallSettledany async/await和Promise的关系async/await的使用 Promise介绍 Promise是一个类,可以翻…...

3.1. 马氏链-马氏链的定义和示例
马氏链的定义和示例 马氏链的定义和示例1. 马氏链的定义2. 马氏链的示例2.1. 随机游走2.2. 分支过程2.3. Ehrenfest chain2.4. 遗传模型2.5. M/G/1 队列 马氏链的定义和示例 1. 马氏链的定义 对于可数状态空间的马氏链, 马氏性指的是给定当前状态, 其他过去的状态与未来的预测…...
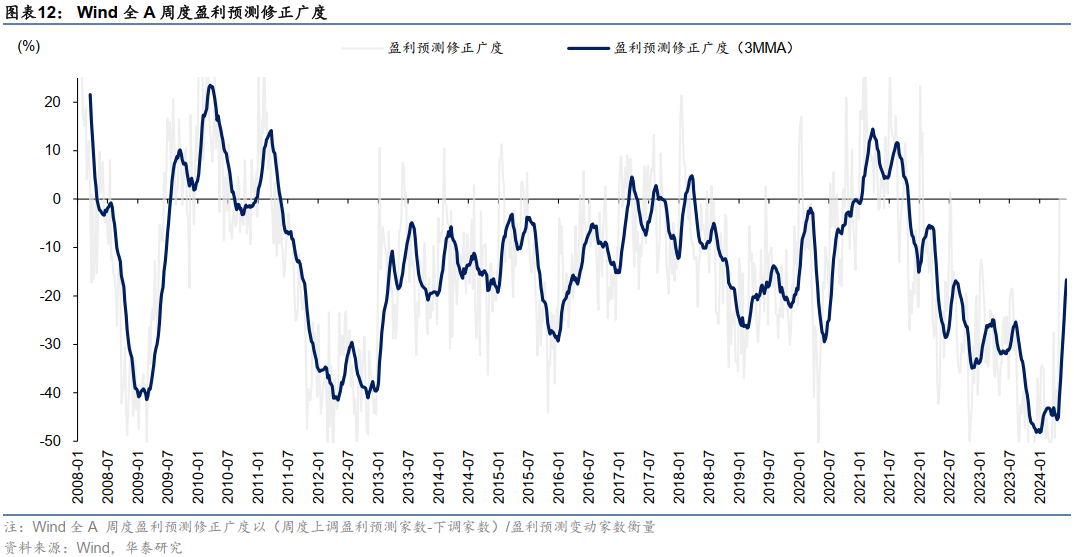
红利之外的A股底仓选择:A50
内容提要 华泰证券指出,当前指数层面下行风险不大,市场再入震荡期下,可关注三条配置线索:1)A50为代表的产业巨头;2)以家电/食饮/物流/出版为代表的稳健消费龙头,3)消费电…...

wondershaper 一款限制 linux 服务器网卡级别的带宽工具
文章目录 一、关于wondershaper二、文档链接三、源码下载四、限流测试五、常见报错1. /usr/local/sbin/wondershaper: line 145: tc: command not found2. Failed to download metadata for repo ‘appstream‘: Cannot prepare internal mirrorlist: No URLs.. 一、关于wonder…...

独孤思维:盲目进群,根本赚不到钱
01 我看有些伙伴,对标同行找写作素材和灵感的时候。 喜欢把对标文章发给ai提炼总结。 这个方法好是好,但是,有一个问题。 即,无法感受全文的细节。 更无法感受作者的情感和温度。 就好像电影《记忆大师》一样。 我提取了记…...
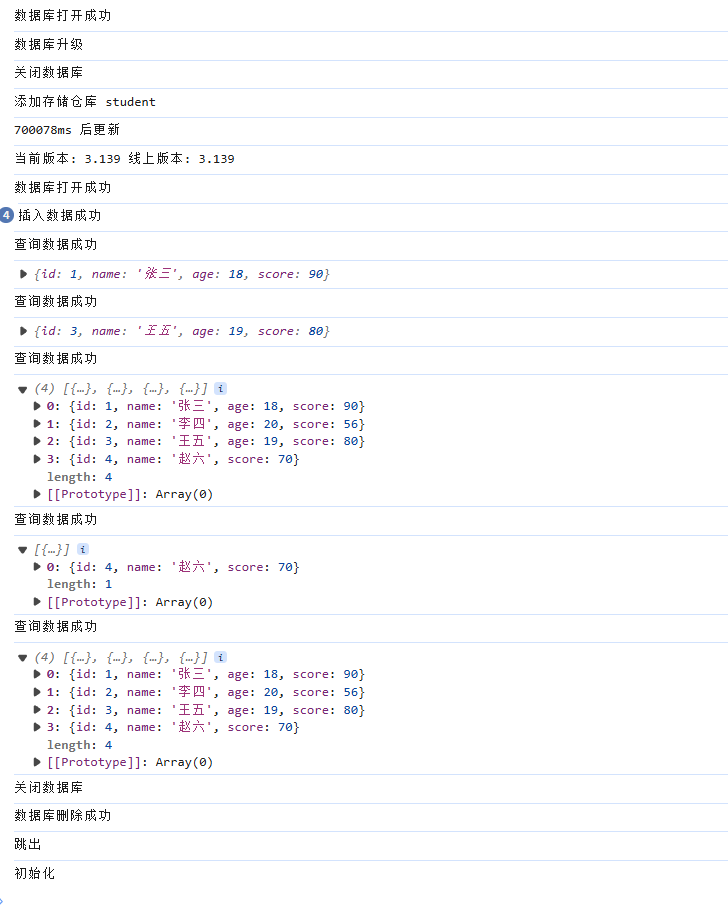
针对indexedDB的简易封装
连接数据库 我们首先创建一个DBManager类,通过这个类new出来的对象管理一个数据库 具体关于indexedDB的相关内容可以看我的这篇博客 indexedDB class DBManager{}我们首先需要打开数据库,打开数据库需要数据库名和该数据库的版本 constructor(dbName,…...
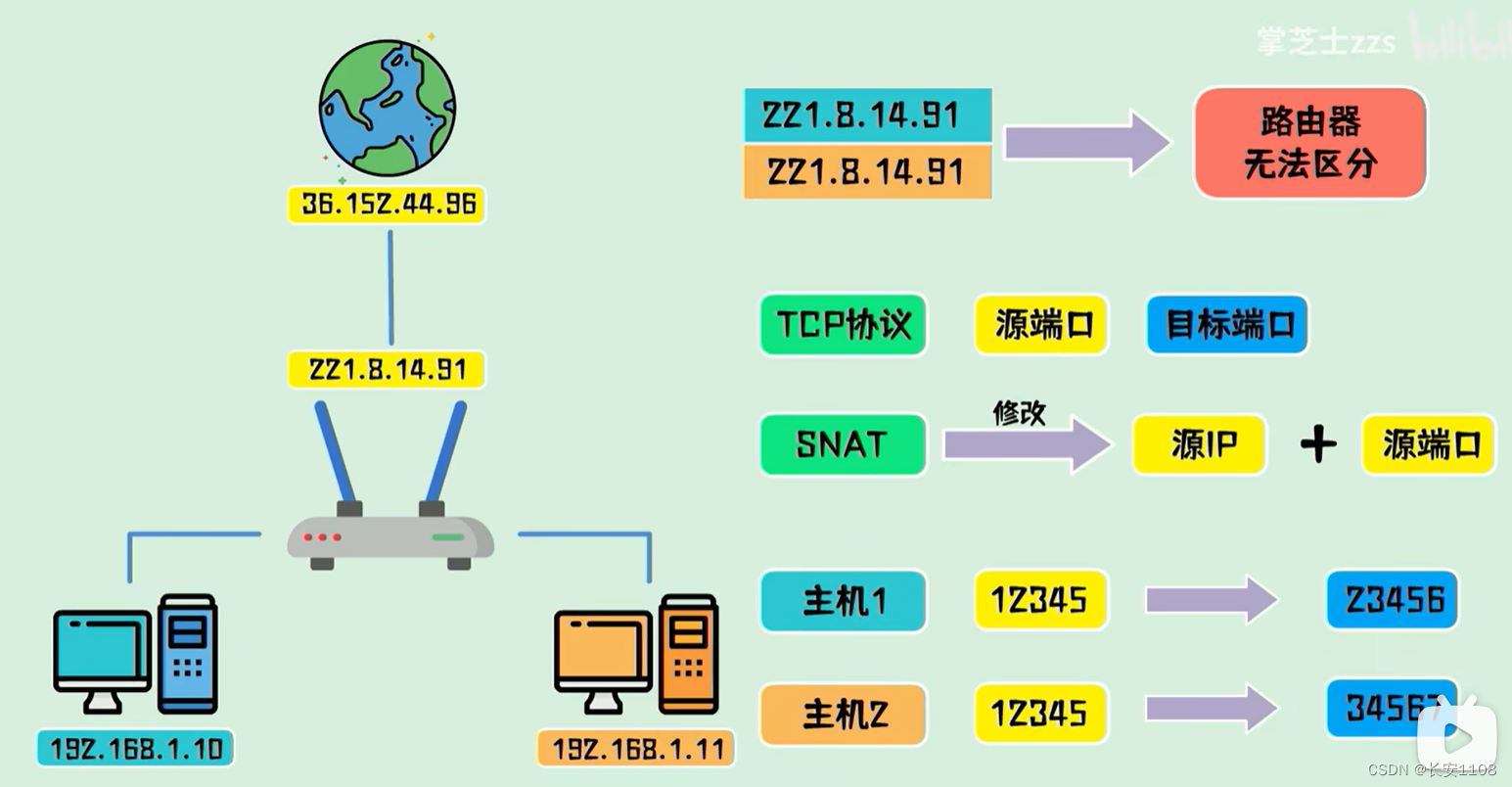
网络编程--网络理论基础(二)
这里写目录标题 网络通信流程mac地址、ip地址arp协议交换机路由器简介子网划分网关 路由总结 为什么ip相同的主机在与同一个互联网服务通信时不冲突公网ip对于同一个路由器下的不同设备,虽然ip不冲突,但是因为都是由路由器的公网ip转发通信,接…...

Python MongoDB 基本操作
本文内容主要为使用Python 对Mongodb数据库的一些基本操作整理。 目录 安装类库 操作实例 引用类库 连接服务器 连接数据库 添加文档 添加单条 批量添加 查询文档 查询所有文档 查询部分文档 使用id查询 统计查询 排序 分页查询 更新文档 update_one方法 upd…...

Node.js 入门:
Node.js 是一个开源、跨平台的 JavaScript 运行时环境,它允许开发者在浏览器之外编写命令行工具和服务器端脚本。以下是一些关于 Node.js 的基础教程: 1. **Node.js 入门**: - 了解 Node.js 的基本概念,包括它是一个基于 Chro…...
)
java8 List的Stream流操作 (实用篇 三)
目录 java8 List的Stream流操作 (实用篇 三) 初始数据 1、Stream过滤: 过滤-常用方法 1.1 筛选单元素--年龄等于18 1.2 筛选单元素--年龄大于18 1.3 筛选范围--年龄大于18 and 年龄小于40 1.4 多条件筛选--年龄大于18 or 年龄小于40 and sex男 1.5 多条件筛…...

机器学习python实践——数据“相关性“的一些补充性个人思考
在上一篇“数据白化”的文章中,说到了数据“相关性”的概念,但是在统计学中,不仅存在“相关性”还存在“独立性”等等,所以,本文主要对数据“相关性”进行一些补充。当然,如果这篇文章还能入得了各位“看官…...

MySQL——触发器(trigger)基本结构
1、修改分隔符符号 delimiter $$ $$可以修改 2、创建触发器函数名称 create trigger 函数名 3、什么样在操作触发,操作哪个表 after :……之后触发 before :……之后触发 insert :……之后触发 update :……之后触…...

数字孪生定义及应用介绍
数字孪生定义及应用介绍 1 数字孪生(Digital Twin, DT)概述1.1 定义1.2 功能1.3 使用场景1.4 数字孪生三步走1.4.1 数字模型1.4.2 数字影子1.4.3 数字孪生 数字孪生地球平台Earth-2 参考 1 数字孪生(Digital Twin, DT)概述 数字孪…...
——体系:数据清洗——技术方法、主要工具)
数据赋能(122)——体系:数据清洗——技术方法、主要工具
技术方法 数据清洗标准模型是将数据输入到数据清洗处理器,通过一系列步骤“清理”数据,然后以期望的格式输出清理过的数据。数据清洗从数据的准确性、完整性、一致性、惟一性、适时性、有效性几个方面来处理数据的丢失值、越界值、不一致代码、重复数据…...

【SCAU数据挖掘】数据挖掘期末总复习题库简答题及解析——中
1. 某学校对入学的新生进行性格问卷调查(没有心理学家的参与),根据学生对问题的回答,把学生的性格分成了8个类别。请说明该数据挖掘任务是属于分类任务还是聚类任务?为什么?并利用该例说明聚类分析和分类分析的异同点。 解答: (a)该数据…...

2024年注册安全工程师报名常见问题汇总!
注册安全工程师报名 24年注册安全工程师报名已正式拉开序幕,报名时间为6月18日—7月10日,考试时间为10月26日—10月27日。 目前经有12个地区公布了2024年注册安全工程师报名时间: 注册安全工程师报名信息完善 根据注安报名系统提示&am…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...

016、Git版本控制与协作开发流程
016 Git版本控制与协作开发流程 一个让我熬夜到凌晨三点的.gitignore 去年做一款基于STM32U5的TinyML手势识别项目,团队四个人,代码库从第一天就开始膨胀。第三天晚上,我习惯性git push,然后去睡觉。凌晨三点被手机震醒——同事在群里@我:“你push了个啥?编译不过了。”…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...

Linux磁盘挂载与开机自启配置
Linux磁盘挂载与开机自启配置磁盘挂载是 Linux 存储管理中的基础操作。很多线上问题都与挂载配置有关,例如重启后数据盘没挂上、路径指向错误分区、应用因挂载点缺失而启动失败。中级阶段不仅要会临时挂载,更要理解永久挂载的配置方式和风险控制。一、先…...

Cortex-A78C架构解析:AMU与ETM寄存器实战指南
1. Cortex-A78C核心架构与寄存器概览Cortex-A78C是Armv8-A架构的高性能实现,面向移动计算和边缘AI场景优化。作为A78系列的安全增强版本,它在保留原有3发射乱序执行流水线的基础上,新增了Pointer Authentication等安全扩展,同时强…...

基于Rust的网页正文提取工具web-reader:从原理到自动化实践
1. 项目概述:一个为现代阅读场景而生的开源利器最近在折腾个人知识库和稍后读工具链,发现市面上的网页内容抓取工具要么太重,要么太“脏”——抓下来的内容常常带着一堆广告、导航栏,甚至还有烦人的弹窗代码。直到我遇到了Cat-tj/…...