企业中面试算法岗时会问什么pytorch问题?看这篇就够了!
如果要面试深度学习相关的岗位,JD上一般会明确要求要熟悉pytorch或tensorflow框架,那么会一般问什么相关问题呢?
文章目录
- 一. 基础知识与概念
- 1.1 PyTorch与TensorFlow的主要区别是什么?
- 1.2 解释一下PyTorch中的Tensor是什么,以及它与NumPy数组的区别?
- 1.3 如何在PyTorch中创建一个简单的计算图?
- 1.3 自动微分(autograd)机制是如何在PyTorch中工作的?
- 1.4 简述PyTorch中的Variable与Tensor的关系(注:在较新版本中,Variable已被合并进Tensor中)。
- 二. 模型构建与训练
- 2.1 如何在PyTorch中定义一个自定义的神经网络模型?
- 2.2 如何加载预训练模型并在其基础上进行微调?
- 2.3 解释一下如何在PyTorch中实现批量归一化(Batch Normalization)?
- 2.4 如何使用DataLoader来加载和处理数据集?
- 2.5 如何实施早停(early stopping)策略以避免过拟合?
- 三. 优化与调试
- 3.1 解释损失函数(Loss Function)和优化器(Optimizer)在PyTorch中的使用方法。
- 3.2 如何监控和可视化模型训练过程中的损失和准确率?
- 3.3 遇到GPU内存不足时,有哪些策略可以优化内存使用?
- 3.4 如何在PyTorch中实现模型的保存与加载?
- 3.5 如何进行模型的多GPU训练?
- 四. 高级主题
- 4.1 解释并行计算在PyTorch中的实现方式,比如DataParallel和DistributedDataParallel。
- 4.2 如何在PyTorch中实现自定义损失函数?
- 4.3 PyTorch中的动态图和静态图有什么区别?
- 4.4 谈谈你对PyTorch中的模型量化和编译(TorchScript)的理解。
- 4.5 如何使用PyTorch进行模型的剪枝和量化以优化推理速度和模型大小?
一. 基础知识与概念
1.1 PyTorch与TensorFlow的主要区别是什么?
1.动态图与静态图:
- PyTorch 使用动态图(eager execution)方式,这意味着你可以像编写常规Python代码一样编写和调试模型代码。在PyTorch中,操作立即执行,并且可以随时进行调试和检查中间结果,这对于研究和快速原型开发非常友好。
- TensorFlow在早期版本中主要采用静态图模式,你需要先定义整个计算图,然后通过会话(Session)运行。这虽然在大规模部署和分布式训练上提供了优势,但对初学者来说可能不够直观,调试也相对困难。不过,TensorFlow2.x 引入了Eager Execution,提供了类似PyTorch的动态执行环境,但其传统使用模式仍偏向于静态图。
2 易用性和学习曲线:
- PyTorch 因其直观的API设计和Python式的编程风格,通常被认为学习门槛较低,对于初学者更加友好。
- TensorFlow由于其复杂的API和静态图模型,学习曲线相对较陡峭,尤其是在进行复杂模型构建和调试时。
- 社区与资源:
- 两者都拥有庞大的开发者社区和丰富的资源,但PyTorch在学术界尤其是研究领域的受欢迎程度近年来有所上升,许多最新的研究论文和开源项目倾向于使用PyTorch。
- TensorFlow则因为Google的支持,拥有更多的企业级应用案例和官方支持的工具,如TensorBoard可视化工具。
- 模型部署与生产环境:
- TensorFlow 提供了更成熟的模型部署工具和解决方案,如TensorFlow Serving,便于将模型部署到生产环境,特别是在移动和边缘设备上。
- 虽然PyTorch在这方面的支持稍显滞后,但它也在不断进步,推出了TorchScript和PyTorch Mobile等工具来简化模型部署流程。
4.性能与扩展性:
在大规模分布式训练和GPU优化方面,两者都非常强大,但具体表现可能会因任务、模型和硬件配置而异。TensorFlow由于其成熟度和Google的基础设施支持,在某些大规模应用上可能略占优势。
1.2 解释一下PyTorch中的Tensor是什么,以及它与NumPy数组的区别?
在PyTorch中,Tensor是核心数据结构,它是一个包含单一数据类型的多维数组,可以存储在CPU或GPU上,支持自动微分,是构建和操作神经网络的基础。Tensor的设计灵感来源于NumPy库中的ndarray,但增加了对GPU加速、自动微分等深度学习特性支持,使得它成为深度学习模型的理想数据容器。
PyTorch Tensor的特点包括:
- 多维数组:可以表示标量、向量、矩阵直至更高维度的数据结构。
- 数据类型:支持多种数据类型,如float32、int64等,与NumPy类似。
- 运算操作:提供了丰富的数学运算接口,如加减乘除、点积、张量乘法等。
- GPU加速:可以轻松地在CPU和GPU之间转移数据,利用GPU进行加速计算。
- 自动微分:支持自动计算梯度,是实现神经网络反向传播的关键。
与NumPy数组的主要区别:
- GPU支持:PyTorch的Tensor可以直接在GPU上运行,而NumPy原生不支持GPU加速,虽然可以通过其他库如CuPy间接实现。
- 自动微分:PyTorch的Tensor内建了自动微分机制,这对于训练神经网络至关重要,而NumPy数组没有此功能。
- 动态图与静态图:虽然这是PyTorch与TensorFlow的对比点,但间接影响了Tensor与NumPy数组的使用体验。PyTorch的动态图使得Tensor的操作更加灵活,易于调试,而基于NumPy的静态图计算需要更复杂的框架集成(如Theano)才能实现类似自动微分的功能。
- 交互性:由于动态图的特性,PyTorch Tensors可以在Python环境中直接交互式地进行运算和调试,相比之下,使用NumPy时可能需要更复杂的逻辑来构建和执行计算图。
1.3 如何在PyTorch中创建一个简单的计算图?
在PyTorch中,计算图是在运行时动态构建的,这得益于它的即时执行(eager execution)机制。实际上,当你使用PyTorch的Tensor进行运算时,计算图就已经自动为你创建好了。下面是一个简单的示例,展示了如何在PyTorch中通过一系列运算创建一个计算图,并进行自动微分来计算梯度。
import torch# 创建一个张量并设置requires_grad=True以追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print("x:", x)# 执行一些运算
y = x + 2
print("y:", y)# 再进行一些运算,形成一个计算图
z = y * y * 3
out = z.mean()print("z:", z)
print("out:", out)# 计算梯度
out.backward()# 查看x的梯度
print("x的梯度:", x.grad)
这段代码做了以下几步:
STEP1: 定义了一个大小为2x2的张量x,并设置了requires_grad=True,这使得PyTorch将会记录所有关于这个张量的运算,构建计算图。
STEP2: 执行了一些基本的数学运算,如加法和乘法,每次运算都会在背后自动构建计算图的一部分。
STEP3: 通过调用.mean()函数对最终的张量z求平均值,得到out,这是我们的最终输出。
STEP4: 调用.backward()方法,根据最终输出out计算图中所有参与变量的梯度,这里主要是计算x的梯度。
STEP5: 最后,打印出x的梯度,可以看到每个元素的梯度值,这是因为我们对z的平均值求导,对于每个x的元素,其梯度都是相同的。
1.3 自动微分(autograd)机制是如何在PyTorch中工作的?
PyTorch中的自动微分(autograd)机制是基于反向自动微分(Reverse Mode Automatic Differentiation, RMAD),它通过构建和操作计算图来自动计算梯度。以下是其工作原理的详细步骤:
STEP1:构造计算图。
当您使用具有requires_grad=True属性的Tensor进行运算时,PyTorch会自动在后台记录这些运算,构建一个有向无环图(DAG)。在这个图中,节点代表张量及其运算,边表示依赖关系。输入张量位于图的顶部,输出张量位于底部,计算过程中的每一个操作都是图中的一个节点。
STEP2:前向传播。
在前向传播阶段,数据(通常是输入张量)从图的输入端流动至输出端。每个运算节点接收到上游节点的输出,并执行相应的数学运算,产生自己的输出,一直进行到得到最终的输出张量。这个过程同时也记录下了所有运算的中间结果。
STEP3:梯度计算请求。
当需要计算梯度时,通常是在损失函数关于模型参数的梯度,用户会调用输出张量上的.backward()方法。这标志着反向传播的开始。
STEP4: 反向传播。
从输出节点开始,autograd系统沿着计算图反向遍历,使用链式法则计算每个节点关于损失函数的梯度。每个运算节点都有一个预定义的反向传播函数,该函数指定了如何根据输出的梯度计算输入的梯度。这些梯度沿图向下流动,直到到达叶子节点(通常是要求梯度的输入张量)。
STEP5: 累积梯度。
对于具有多个输出分支的节点,其梯度会被累积。这意味着如果一个张量是多个计算路径的输入,那么它将累积来自所有路径的梯度。
STEP6:访问梯度。
一旦反向传播完成,所有参与计算且标记了requires_grad=True的输入张量的梯度将会被计算出来,并存储在其.grad属性中,可供访问和进一步使用,例如更新模型参数。
通过这个机制,PyTorch的autograd系统极大地简化了深度学习模型训练中的梯度计算过程,使得用户无需手动实现反向传播算法,从而能够更加专注于模型的设计和优化。
1.4 简述PyTorch中的Variable与Tensor的关系(注:在较新版本中,Variable已被合并进Tensor中)。
在较早版本的PyTorch中,Variable和Tensor是两个独立的概念,它们共同构成了PyTorch的核心数据结构。Tensor是存放数据的多维数组,类似于NumPy的ndarray,支持各种数学运算。而Variable则是在Tensor的基础上增加了一层封装,它主要负责跟踪和记录计算历史,以便于自动微分计算梯度。简单来说,Tensor是底层的数据容器,而Variable则提供了额外的自动微分功能。
然而,随着PyTorch的发展,为了简化API并减少用户的认知负担,从PyTorch 0.4版本开始,Variable和Tensor的概念被合并。现在,所有的Tensor都直接支持自动微分功能,不再需要单独创建Variable。这意味着,当你创建一个Tensor并设置requires_grad=True时,该Tensor就会自动记录其运算历史,从而能够在后续的计算中自动计算梯度。
二. 模型构建与训练
2.1 如何在PyTorch中定义一个自定义的神经网络模型?
在PyTorch中定义一个自定义的神经网络模型通常涉及继承torch.nn.Module基类并实现必要的方法。以下是一个简单的示例,展示如何定义一个具有两个全连接层(Linear Layers)的神经网络模型,用于分类任务:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass CustomClassifier(nn.Module):def __init__(self, input_size, hidden_size, output_size):"""初始化网络结构:param input_size: 输入特征的尺寸:param hidden_size: 隐藏层的尺寸:param output_size: 输出分类的类别数"""super(CustomClassifier, self).__init__()# 定义网络层self.fc1 = nn.Linear(input_size, hidden_size) # 第一个全连接层self.fc2 = nn.Linear(hidden_size, output_size) # 第二个全连接层def forward(self, x):"""前向传播过程:param x: 输入数据:return: 输出预测"""# 通过第一个全连接层,使用ReLU激活函数x = F.relu(self.fc1(x))# 通过第二个全连接层,得到最终的输出x = self.fc2(x)return x# 实例化模型
model = CustomClassifier(input_size=784, hidden_size=128, output_size=10) # 假设输入是28x28的图像展平后的向量,输出为10分类问题# 示例:使用随机数据通过模型
x = torch.randn(32, 784) # 假设一批32个样本,每个样本有784个特征
output = model(x)
print(output.shape) # 打印输出形状,应为(32, 10),对应32个样本的10分类概率分布
这个例子中,CustomClassifier类继承自nn.Module,并在__init__方法中定义了模型的层(这里是两个全连接层)。forward方法定义了网络的前向传播逻辑,即如何将输入数据通过各层变换得到最终的输出。实例化这个类后,就可以用输入数据调用模型的forward方法来进行前向传播了。
2.2 如何加载预训练模型并在其基础上进行微调?
在PyTorch中,加载预训练模型并在其基础上进行微调是一个常见的实践,特别是对于深度学习的迁移学习。以下是一个基本步骤指南,以图像分类任务为例,说明如何实现这一过程:
STEP1:下载并加载预训练模型
import torch
import torchvision.models as models# 加载预训练模型
pretrained_model = models.resnet18(pretrained=True)
pretrained_model.eval() # 设置模型为评估模式,这样BN层等会使用训练好的统计信息
STEP2: 冻结部分层
通常,微调时我们会冻结模型的前几层(通常是卷积基),只训练顶部的几层或添加新的全连接层以适应新的任务。冻结层可以通过设置其.requires_grad=False来实现:
for param in pretrained_model.parameters():param.requires_grad = False# 如果要微调最后的几层,取消对应层的梯度锁定
# 例如,解冻最后一个全连接层(对于ResNet,通常是fc层)
pretrained_model.fc.requires_grad = True
STEP3: 添加或调整顶层
根据你的任务需求,你可能需要修改模型的最后一层(或添加新的层)。对于新的分类任务,这通常意味着调整全连接层的输出维度以匹配新的类别数:
num_classes = 10 # 假设新的任务有10个类别
pretrained_model.fc = nn.Linear(pretrained_model.fc.in_features, num_classes)
STEP4: 训练模型
接下来,你可以使用你的数据集对模型进行微调。这包括定义损失函数、优化器,并进行训练循环:
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 数据预处理和加载
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])train_dataset = datasets.ImageFolder('path/to/your/train/dataset', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(pretrained_model.fc.parameters(), lr=0.001, momentum=0.9)# 训练循环
num_epochs = 10
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):outputs = pretrained_model(images)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()}')
STEP 5: 评估与保存模型
训练完成后,记得评估模型在验证集上的表现,并保存微调后的模型:
# 评估模型代码省略,一般包括加载验证数据集,计算准确率等
# 保存模型
torch.save(pretrained_model.state_dict(), 'path/to/save/your/model.pth')
2.3 解释一下如何在PyTorch中实现批量归一化(Batch Normalization)?
批量归一化(Batch Normalization,简称BN)是一种在深度学习中广泛使用的正则化技术,它可以加速模型训练过程,提高模型的泛化能力。在PyTorch中实现批量归一化非常直接,因为PyTorch的torch.nn模块已经内置了BatchNorm层。下面是使用BatchNorm的简单示例:
STEP1: 导入必要的库
import torch
import torch.nn as nn
STEP2: 定义模型时插入BatchNorm层
在定义神经网络模型时,在每一层的激活函数之前插入nn.BatchNorm层。例如,构建一个简单的卷积神经网络(CNN)模型,并在每个卷积层之后加入批量归一化层:
class SimpleCNN(nn.Module):def __init__(self, num_classes=10):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.bn1 = nn.BatchNorm2d(64) # 在卷积层后添加批量归一化层self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.bn2 = nn.BatchNorm2d(128) # 又一个批量归一化层# 其他层...self.fc = nn.Linear(128 * 8 * 8, num_classes) # 全连接层def forward(self, x):x = self.conv1(x)x = self.bn1(x) # 应用批量归一化x = self.relu(x)x = self.maxpool(x)x = self.conv2(x)x = self.bn2(x) # 应用批量归一化x = self.relu(x)# 继续其他层的前向传播...x = x.view(x.size(0), -1)x = self.fc(x)return x
STEP3: 模型训练
一旦模型定义完成,你可以像往常一样进行模型的训练。批量归一化的参数(均值和方差)会在训练过程中自动更新,无需手动干预。
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 假设有data_loader加载训练数据
for epoch in range(num_epochs):for inputs, labels in data_loader:outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
2.4 如何使用DataLoader来加载和处理数据集?
在PyTorch中,DataLoader是用于加载和处理数据集的一个重要类,它提供了对数据集的迭代访问,支持多线程加载数据以加快训练速度,并允许数据集的随机打乱、批量提取、数据转换等功能。下面是如何使用DataLoader来加载和处理数据集的基本步骤:
STEP1: 导入必要的库
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
STEP2: 定义自定义数据类
你需要创建一个继承自torch.utils.data.Dataset的子类,用来定义如何访问和处理数据集中的样本。这个类至少需要实现两个方法:len 和 getitem。
class CustomDataset(Dataset):def __init__(self, data, labels, transform=None):self.data = dataself.labels = labelsself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, idx):sample = self.data[idx]label = self.labels[idx]if self.transform:sample = self.transform(sample)return sample, label
STEP3: 数据预处理
定义好数据集类后,你可以使用transforms模块来定义数据预处理的步骤,如标准化、旋转、裁剪等。
transform = transforms.Compose([transforms.ToTensor(), # 将PIL图像或numpy数组转换为Tensortransforms.Normalize((0.5,), (0.5,)) # 标准化图像数据
])
STEP4 : 创建DataLoader实例
使用你的数据集和预处理转换来实例化DataLoader。你可以指定batch_size、是否打乱数据(shuffle)、是否使用多线程加载(num_workers)等参数。
dataset = CustomDataset(data, labels, transform=transform)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=2)
STEP5: 使用DataLoader进行训练或测试
现在,你可以在训练或测试循环中使用DataLoader来迭代数据集。DataLoader会按照指定的批次大小返回数据和标签。
for batch_idx, (data, targets) in enumerate(data_loader):# 将数据转移到GPU(如果可用)data, targets = data.to(device), targets.to(device)# 训练或评估模型# model.train() 或 model.eval()# outputs = model(data)# ... 计算损失、反向传播、优化等# 你可以根据需要在这里添加训练或测试的逻辑
通过上述步骤,你可以有效地利用DataLoader来管理和加载数据,进而提升模型训练的效率和便捷性。
2.5 如何实施早停(early stopping)策略以避免过拟合?
早停(Early Stopping)是一种常用的正则化策略,用于避免模型在训练过程中出现过拟合。其核心思想是在验证集上的性能不再提升时,提前终止训练过程。以下是实施早停策略的一般步骤:
STEP1:分割数据
首先,将数据集划分为训练集和验证集(有时还会有测试集,但早停策略主要关注训练和验证集)。验证集用于监控模型的泛化性能。
STEP2: 定义模型和优化器
创建神经网络模型,并选择合适的优化器(如SGD、Adam等)。
STEP3: 设定早停条件
- 性能指标:确定一个评价模型性能的指标,通常是验证集上的损失或准确率。
- 耐心(patience):设定一个容忍期,即连续多少个epoch验证性能没有提升后,就停止训练。例如,patience=5意味着如果验证损失连续5个epoch都没有下降,就触发早停。
- 最佳模型保存:维护当前最佳模型的状态,当发现更好的模型时(即验证性能提升),保存该模型的参数。
STEP4: 训练与监控
- 初始化计数器:记录没有性能提升的epoch数。
- 训练循环:开始训练模型,对于每个epoch:
- 训练模型在训练集上。
- 评估模型在验证集上的性能。
- 比较当前验证集性能与最佳性能。
- 如果当前性能优于之前的最佳性能,更新最佳性能记录,保存模型参数,并重置耐心计数器。
- 如果当前性能没有提升,增加耐心计数器。
- 如果耐心计数器达到设定值,触发早停,结束训练。
STEP5: 应用最佳模型
训练结束后,使用在验证集上表现最优时保存的模型参数进行后续的测试或部署。
Pytorch中的实现示例
在PyTorch中,可以使用自定义的训练循环来实现早停,也可以利用一些第三方库(如torch.utils.tensorboard来可视化监控早停条件)。下面是一个简化的代码示例:
import torch
from torch import nn, optim# 假设model, train_loader, valid_loader已定义
best_val_loss = float('inf')
patience = 5
counter = 0
best_model_weights = Nonefor epoch in range(num_epochs):# 训练阶段model.train()for inputs, targets in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()# 验证阶段model.eval()with torch.no_grad():total_loss = 0.0for inputs, targets in valid_loader:outputs = model(inputs)loss = criterion(outputs, targets)total_loss += loss.item()avg_val_loss = total_loss / len(valid_loader)# 早停逻辑if avg_val_loss < best_val_loss:best_val_loss = avg_val_lossbest_model_weights = model.state_dict().copy()counter = 0else:counter += 1if counter >= patience:print("Early stopping triggered. Restoring best weights.")model.load_state_dict(best_model_weights)break# 训练结束,使用最佳模型
model.load_state_dict(best_model_weights)
通过上述步骤,你可以有效地实施早停策略,防止模型过拟合,同时保证模型在验证集上的性能最佳。
三. 优化与调试
3.1 解释损失函数(Loss Function)和优化器(Optimizer)在PyTorch中的使用方法。
在PyTorch中,损失函数(Loss Function)和优化器(Optimizer)是训练神经网络模型不可或缺的两部分,它们分别负责评估模型预测的好坏和根据损失函数的反馈更新模型参数。
1.损失函数(Loss Function)
损失函数衡量了模型预测输出与实际目标值之间的差异。选择合适的损失函数对于训练过程至关重要,因为它指导着模型学习的方向。PyTorch提供了多种损失函数,它们都在torch.nn模块中定义。
-
导入损失函数:
首先,根据你的任务需求从torch.nn中导入相应的损失函数。例如,对于分类任务,常用的损失函数有CrossEntropyLoss;对于回归任务,可能会用到MSELoss(均方误差损失)或L1Loss(绝对误差损失)。from torch.nn import CrossEntropyLoss criterion = CrossEntropyLoss() -
计算损失:
在模型的训练循环中,利用损失函数计算预测输出outputs和真实标签targets之间的损失。loss = criterion(outputs, targets)
2. 优化器(Optimizer):
优化器负责根据损失函数计算出的梯度来更新模型的权重参数,以逐步减小损失。PyTorch同样提供了多种优化器,如SGD(随机梯度下降)、Adam、RMSprop等,这些优化器都在torch.optim模块中定义。
-
初始化优化器:
在定义模型并分配权重参数后,你需要根据模型的参数列表创建一个优化器实例。同时,你可以指定学习率等超参数。from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.001, momentum=0.9) -
更新模型参数:
在每个训练批次的末尾,你需要调用优化器的step方法来更新模型参数。在此之前,应先调用loss.backward()来计算梯度。optimizer.zero_grad() # 清零梯度,以免累加 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新模型参数
3.2 如何监控和可视化模型训练过程中的损失和准确率?
在PyTorch中监控和可视化模型训练过程中的损失和准确率是一个重要的环节,它帮助你理解模型的学习进度,调整训练策略。常用的可视化工具有TensorBoard(尽管它是TensorFlow的原生工具,但也可以与PyTorch一起使用)和Visdom。下面以TensorBoard为例,介绍如何进行监控和可视化:
- 导入必要的库
from torch.utils.tensorboard import SummaryWriter
- 创建SummaryWriter实例
writer = SummaryWriter(log_dir='runs/exp1') # 指定日志目录
- 在训练循环中记录数据
for epoch in range(num_epochs):# ... 训练循环中的代码running_loss = 0.0for inputs, labels in train_loader:# 前向传播、计算损失、反向传播、优化等# ...loss = ... # 计算损失running_loss += loss.item()# 每个epoch结束时,记录平均损失epoch_loss = running_loss / len(train_loader)writer.add_scalar('Loss/train', epoch_loss, epoch) # 记录训练损失# 如果有验证集,也可以记录验证集的损失和准确率val_loss = ... # 计算验证损失writer.add_scalar('Loss/validation', val_loss, epoch) # 记录验证损失accuracy = ... # 计算准确率writer.add_scalar('Accuracy/validation', accuracy, epoch) # 记录准确率# ... 其他训练代码
3.3 遇到GPU内存不足时,有哪些策略可以优化内存使用?
- 减小批次大小(Batch Size):批次大小是影响内存消耗的关键因素之一。减小批次大小可以显著降低内存需求,虽然这可能会影响到模型的收敛速度和稳定性,但在内存受限的情况下是个实用的选择。
- 使用混合精度训练:混合精度训练利用半精度(FP16)或自动混合精度(AMP)来减少内存使用和加速训练。PyTorch提供了torch.cuda.amp模块来支持这一特性。
- 梯度累积(Gradient Accumulation):当无法增大硬件内存时,可以通过梯度累积来模拟大批次训练的效果。这意味着在更新权重之前,多次向前传播和反向传播的梯度被累加起来,从而减少了每次更新所需的内存。
- 模型剪枝和量化:通过剪枝去除模型中不重要的权重,或者通过量化将浮点数转换为更紧凑的数据类型(如INT8),可以大幅度减少模型的内存占用。
- 优化数据加载器:使用torch.utils.data.DataLoader时,可以调整num_workers参数以控制数据加载的并发度,避免过多的数据加载线程占用GPU内存。同时,确保数据集经过适当预处理并尽可能减少内存占用。
- 内存释放:定期或在必要时手动释放不再使用的Tensor和模型。使用.detach()和.cuda()与.cpu()方法在GPU和CPU间移动数据,可以避免不必要的内存占用。
- 使用模型并行或数据并行:对于大型模型,可以考虑使用模型并行(将模型分布在多个GPU上)或数据并行(将数据批次分散到多个GPU上处理)。PyTorch提供了torch.nn.DataParallel和torch.nn.parallel.DistributedDataParallel来实现这一点。
3.4 如何在PyTorch中实现模型的保存与加载?
在PyTorch中,模型的保存与加载主要通过torch.save()和torch.load()函数完成。这里提供两种常见的保存与加载方式:
1.保存整个模型(包括架构和参数)
这种方式保存模型的全部状态,包括网络结构和所有参数,适合于完全复现模型。
- 保存模型
import torch
# 假设model是你的模型实例
model = YourModelClass()
torch.save(model, 'model.pth') # 保存模型到model.pth文件
- 加载模型
model = torch.load('model.pth') # 加载模型
model.eval() # 将模型设置为评估模式
2. 保存与加载模型参数(state_dict)
这种方式只保存模型的参数,不包含模型的架构。适用于当模型定义可能改变,但希望保持参数不变的情况。
- 保存参数
torch.save(model.state_dict(), 'params.pth') # 只保存模型参数到params.pth文件
- 加载参数
model = YourModelClass() # 新建一个与原模型结构相同的实例
model.load_state_dict(torch.load('params.pth')) # 加载参数到模型
model.eval() # 将模型设置为评估模式
3.5 如何进行模型的多GPU训练?
在PyTorch中进行多GPU训练主要可以通过DataParallel和DistributedDataParallel两种方式来实现。这两种方法都允许你在多个GPU上并行训练模型,从而加速训练过程。
1. 使用DataParallel
DataParallel是较为简单的一种方式,它通过在每个GPU上复制模型的一份副本,并将输入数据分割到各个GPU上进行并行计算,然后将各个GPU的结果汇总,以此来加速训练。这是最直接的多GPU训练方式,适用于单节点多卡场景。
import torch
from torch.nn.parallel import DataParallel
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 假设model是你的模型实例
model = YourModelClass().to(device)
if torch.cuda.device_count() > 1:print("Let's use", torch.cuda.device_count(), "GPUs!")model = DataParallel(model)# 然后像平时一样定义损失函数、优化器,并进行训练
2. 使用DistributedDataParallel
DistributedDataParallel(DDP)是PyTorch提供的更高级的并行训练方法,它不仅适用于单节点多卡,也支持多节点多卡的训练。DDP要求使用torch.distributed包来初始化进程组,并且在每个进程中管理模型的一个部分,通过网络通信交换梯度信息。
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.multiprocessing import Process
import osdef run(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'dist.init_process_group("nccl", rank=rank, world_size=world_size)# 假设model是你的模型实例model = YourModelClass().to(rank)ddp_model = DDP(model, device_ids=[rank])# 然后定义损失函数、优化器,并进行训练# 注意:数据加载和处理也需要考虑分布式训练的需求if __name__=="__main__":world_size = torch.cuda.device_count()processes = []for rank in range(world_size):p = Process(target=run, args=(rank, world_size))p.start()processes.append(p)for p in processes:p.join()
四. 高级主题
4.1 解释并行计算在PyTorch中的实现方式,比如DataParallel和DistributedDataParallel。
在PyTorch中,为了充分利用多GPU资源加速训练过程,提供了两种主要的并行计算实现方式:DataParallel和DistributedDataParallel(DDP)。这两种方法都是为了在多个GPU上同时执行计算任务,从而加快训练速度,但它们的工作原理和适用场景有所不同。
1.DataParallel
- 工作原理
- DataParallel是PyTorch中最基本的并行计算模式,它适用于单个机器上有多块GPU的情况。
- 这种模式下,PyTorch会自动将模型复制到每一块可用的GPU上,并将输入数据分割成若干部分,每个GPU处理一部分数据。每个GPU上的模型计算其对应数据的前向传播结果,然后将这些结果汇总到主GPU(通常是GPU0),在这里计算损失和进行反向传播。
- 因此,DataParallel在训练过程中实际上是在多个GPU上并行执行前向传播,但在反向传播和梯度更新时仍然是串行的,由主GPU完成。
- 适用场景
-适合快速搭建多GPU训练环境,无需复杂的分布式设置。- 对于模型不是特别大,或者数据并行化带来的通信开销相对较小的场景更为合适。
2. DistributedDataParallel (DDP)
- 工作原理
- DistributedDataParallel是更高级的并行计算模式,不仅支持单机多卡,还支持多台机器上的多卡并行。
- DDP通过torch.distributed包来初始化一个进程组,每个GPU运行一个独立的进程,并维护模型的一部分。每个进程处理数据集的一个子集,并在进程间通过高效的通信协议(如NCCL)同步梯度。
- 在DDP中,数据并行化和梯度同步都是分布式的,这意味着每个GPU独立计算自己的梯度,并通过网络与其他GPU的梯度聚合,实现了真正的并行训练。
- 适用场景
- 当模型非常大,单卡无法容纳,或者需要跨多台机器扩展训练规模时。
- 对于大规模训练或大规模模型,DDP能更高效地管理和利用计算资源,减少通信开销。
- 当需要更细粒度的控制和更高级的并行策略时,DDP提供了更多的灵活性和可扩展性。
4.2 如何在PyTorch中实现自定义损失函数?
在PyTorch中实现自定义损失函数非常直观,你只需要定义一个继承自torch.nn.Module的类,并实现forward方法来定义损失的计算逻辑。下面是一个简单的示例,演示如何定义一个均方误差损失(Mean Squared Error, MSE)的自定义损失函数,尽管PyTorch已经内置了这个损失函数,但此示例有助于理解如何构建自定义损失函数的基本框架。
import torch
import torch.nn as nnclass CustomMSELoss(nn.Module):def __init__(self):super(CustomMSELoss, self).__init__()def forward(self, predictions, targets):"""predictions: 模型的输出,形状为(N, *),N是批量大小targets: 目标值,形状应与predictions相同"""# 计算预测值与目标值之差的平方differences = predictions - targetssquared_diffs = differences ** 2# 计算均方误差,即平方差的平均值mse = torch.mean(squared_diffs)return mse# 使用自定义损失函数
custom_mse_loss = CustomMSELoss()# 假设我们有一些预测值和目标值
predictions = torch.randn(3, 5, requires_grad=True) # 预测值,requires_grad=True以便计算梯度
targets = torch.randn(3, 5) # 目标值# 计算损失
loss = custom_mse_loss(predictions, targets)# 反向传播计算梯度
loss.backward()print(f"Custom MSE Loss: {loss.item()}")
4.3 PyTorch中的动态图和静态图有什么区别?
PyTorch 使用动态图(Dynamic Computational Graph),而其他框架如早期的 TensorFlow 则倾向于使用静态图(Static Computational Graph)。这两者的主要区别在于图的构建和执行方式,这对模型的构建、调试以及性能优化等方面有直接影响:
-
动态图(PyTorch)
-
构建方式:在PyTorch中,计算图是在运行时动态构建的。这意味着图随着你的代码执行而实时生成,每一次前向传播(forward pass)都会构建一个新的计算图。这种机制使得模型的构建更加直观,更接近常规的Python编程体验。
-
调试便利性:由于图是动态生成的,开发者可以在运行时检查和修改计算图,这对于调试非常友好。你可以像调试普通的Python程序那样使用print语句或者调试器来查看中间变量的值。
-
控制流灵活:动态图更容易实现复杂的控制流(如条件分支、循环),因为这些控制流结构是直接嵌入到图的构造过程中的,能够更好地适应动态变化的网络结构。
-
-
静态图(早期TensorFlow)
-
构建方式:静态图在运行前就被定义和优化好了。开发者首先定义整个计算图结构,包括所有操作和张量,然后编译这个图。一旦图构建完毕,可以在不同的输入数据上重复执行,而不需要重新构建图。
-
性能优势:静态图在首次构建时可以进行广泛的优化,如图的融合、内存分配优化等,这使得在大规模数据训练时执行效率更高,特别是在分布式和并行计算环境中。
-
部署友好:静态图模型易于序列化和部署,因为模型是一个已经优化过的计算图,没有运行时构建图的开销,这对于生产环境中的推理特别有利。
-
4.4 谈谈你对PyTorch中的模型量化和编译(TorchScript)的理解。
PyTorch 中的模型量化和编译(尤其是通过 TorchScript)是两个旨在提高模型性能和部署效率的关键技术。下面分别对这两个概念进行解释:
-
模型量化
模型量化主要是指将模型中的权重和激活函数从浮点数转换为低精度表示(如int8),从而减少模型的内存占用和加速推理过程。这一过程通常包括以下几个步骤:-
训练后量化(Post-training Quantization):这是最常见的量化方法,它不对原始模型的训练过程进行修改,而是在模型训练完成后,通过对模型输入数据进行分析来确定合适的量化范围。量化后的模型在精度上可能会有轻微损失,但换来了显著的推理速度提升和存储空间节省,尤其是在嵌入式设备或移动设备上。
-
量化感知训练(Quantization-aware Training):为了进一步减小量化带来的精度损失,可以在训练过程中引入模拟量化操作,使模型能够在量化环境下进行微调,从而学习适应低精度表示。
-
-
TorchScript 编译
TorchScript 是 PyTorch 提供的一种模型编译技术,它的目标是将 PyTorch 模型转换成一种独立于 Python 的、可序列化的形式,这有利于模型的优化、部署和跨平台运行。-
脚本化(Scripting):通过 TorchScript 的脚本化功能,可以直接将 PyTorch 中的模型代码转换成 TorchScript。这一过程涉及追踪(Tracing)或脚本编写(Scripting)模型的前向传播过程,将Python代码转换为图表示。
-
优化与序列化:转换后的 TorchScript 图可以被进一步优化,比如消除死代码、合并操作等,以提高执行效率。优化后的模型可以序列化为文件,便于分发和部署到没有Python环境的生产服务器或移动设备上。
-
独立运行:编译后的 TorchScript 模型可以在 C++ 或其他支持的环境中直接加载和执行,无需依赖 Python,这对于性能敏感的应用场景和生产环境尤为重要。
-
-
结合使用
模型量化和 TorchScript 编译可以协同工作,首先通过量化减少模型的计算和存储需求,随后通过 TorchScript 编译来进一步优化模型的部署效率。这种结合不仅提升了模型的推理速度,还大大增强了模型的部署灵活性,使之能够无缝集成到多样化的应用环境之中。
4.5 如何使用PyTorch进行模型的剪枝和量化以优化推理速度和模型大小?
在PyTorch中,模型剪枝和量化是两种常用的模型优化技术,旨在减少模型的推理时间、内存占用和存储空间,同时尽可能地保持模型性能。下面分别介绍如何实施模型剪枝和量化:
-
模型剪枝
模型剪枝是指在不影响模型性能太多的前提下,删除模型中不重要的权重或连接,从而达到压缩模型的目的。剪枝可以分为几个层次,包括权重剪枝、通道剪枝等。- 权重剪枝示例
-
选择剪枝策略:决定哪些权重是“不重要”的,常见的策略包括基于权重绝对值的剪枝、基于敏感度的剪枝等。
-
实现剪枝:可以使用第三方库如torch.nn.utils.prune来实现剪枝。例如,进行一个简单的权重绝对值剪枝:
import torch.nn.utils.prune as prune# 假设model是你的模型 model = YourModelClass()# 选择要剪枝的层,例如第一个卷积层 conv1 = model.conv1 prune.l1_unstructured(conv1, name='weight', amount=0.5) # 剪枝50%的权重# 使剪枝永久化并移除被剪枝的权重 prune.remove(conv1, 'weight')
-
- 权重剪枝示例
-
量化
量化则是将模型中的浮点数权重和激活值转换为低精度(如int8)表示,这在许多硬件平台上可以实现更快的计算速度和更低的内存占用。-
PyTorch量化工具
PyTorch提供了torch.quantization模块来支持量化。一般步骤如下:-
准备模型:确保模型是量化友好的,这意味着使用量化感知的层(如torch.nn.quantized中的层)或者对现有模型进行适配。
-
量化准备:使用torch.quantization.prepare对模型进行标记,指示哪些层应该被量化。
-
校准:通过实际数据对模型进行校准,收集统计信息(如激活值的范围)来确定量化参数。
-
量化转换:使用torch.quantization.convert根据校准阶段得到的信息,将模型转换为量化模型。
import torch from torch.quantization import quantize_dynamic, QuantStub, DeQuantStub# 假设model是已经训练好的模型 model.train(False) # 转换为推理模式# 动态量化 quantized_model = quantize_dynamic(model, # 要量化的模型{nn.Linear}, # 要量化的层类型dtype=torch.qint8) # 量化数据类型# 现在,quantized_model是一个量化后的模型,可以用于推理
-
-
🔺面试时,除了直接回答问题,展示你如何解决具体问题、分享个人项目经验、以及讨论最佳实践也是很重要的。准备这些类型的问题可以帮助你全面展示你在PyTorch方面的知识和技能。
相关文章:

企业中面试算法岗时会问什么pytorch问题?看这篇就够了!
如果要面试深度学习相关的岗位,JD上一般会明确要求要熟悉pytorch或tensorflow框架,那么会一般问什么相关问题呢? 文章目录 一. 基础知识与概念1.1 PyTorch与TensorFlow的主要区别是什么? 1.2 解释一下PyTorch中的Tensor是什么&…...
【学习】程序员资源网址
1 书栈网 简介:书栈网是程序员互联网IT开源编程书籍、资源免费阅读的网站,在书栈网你可以找到很多书籍、笔记资源。在这里,你可以根据热门收藏和阅读查看大家都在看什么,也可以根据技术栈分类找到对应模块的编程资源,…...

【3D模型库】机械三维模型库整理
1 开拔网 简介:开拔网是中国较早的机械设计交流平台,广受行业内的各个大学,公司以及行业人士的欢迎。网站有非常丰富的3D模型,CAD图纸,以及各类热门软件的下载。同时我们也为行业搭建一个平台,提供各类设计…...

基于Python-CNN深度学习的物品识别
基于Python-CNN深度学习的物品识别 近年来,深度学习尤其是卷积神经网络(CNN)的快速发展,极大地推动了计算机视觉技术的进步。在物品识别领域,CNN凭借其强大的特征提取和学习能力,成为了主流的技术手段之一…...
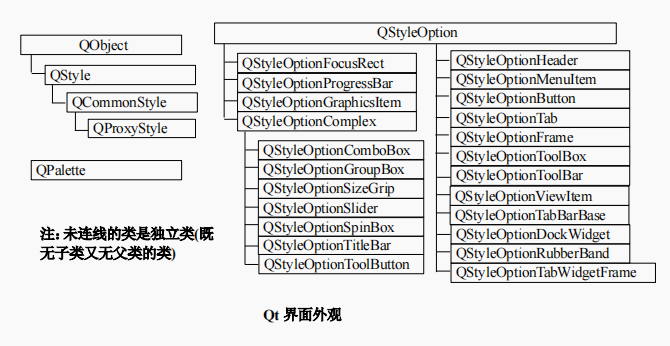
Qt | 简单的使用 QStyle 类(风格也称为样式)
01、前言 者在 pro 文件中已添加了正确的 QT+=widgets 语句 02、基础样式 1、QStyle 类继承自 QObject,该类是一个抽像类。 2、QStyle 类描述了 GUI 的界面外观,Qt 的内置部件使用该类执行几乎所有的绘制,以确保 使这些部件看起来与本地部件完全相同。 3、Qt 内置了一系…...
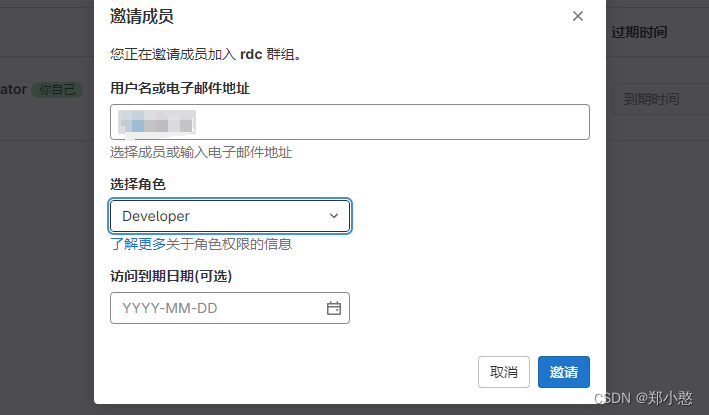
Idea连接GitLab的过程以及创建在gitlab中创建用户和群组
上期讲述了如何部署GitLab以及修复bug,这期我们讲述,如何连接idea。 首先安装gitlab插件 下载安装idea上并重启 配置ssh免密登录 使用管理员打开命令行输入:ssh-keygen -t rsa -C xxxaaa.com 到用户目录下.ssh查看id_rsa.pub文件 打开复制…...
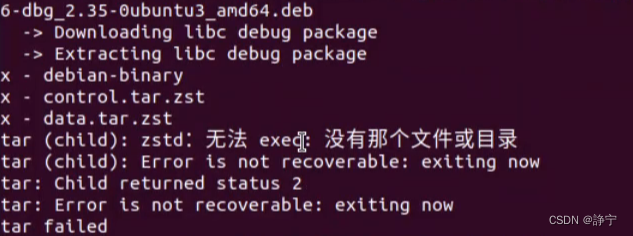
关于glibc-all-in-one下载libc2.35以上报错问题
./download libc版本 下载2.35时报错:原因是缺少解压工具zstd sudo apt-get install zstd 下载后重新输命令就可以了 附加xclibc命令 xclibc -x ./pwn ./libc-版本 ldd pwn文件 xclibc -c libc版本...

C语言之#define #if 预处理器指令
在 C 语言中,预处理器指令用于条件编译代码。你可以使用 #define 和 #if 指令来根据某些条件包含或排除代码块。以下是一个完整的例子,演示了如何使用 #define 和 #if 指令来控制代码的编译: #include <stdio.h>// 定义宏 MERGE_TYPE …...
modbus流量计数据解析(4个字节与float的换算)
通过modbus协议从流量计中读取数据后,需要将获得的字节数据合成float类型。以天信流量计为例: 如何将字节数据合并成float类型呢?这里总结了三种方法。 以温度值41 A0 00 00为例 目录 1、使用char*逐字节解析2、使用memcpy转换2、使用联合体…...

关于element-plus中el-select自定义标签及样式的问题
关于element-plus中el-select自定义标签及样式的问题 我这天天的都遇到各种坑,关于自定义,我直接复制粘贴代码都实现不了,研究了一下午,骂骂咧咧了一下午,服气了。官网代码实现不了,就只能 “ 曲线救国 ”…...
硕思logo设计师下载-2024官方最新版-logo制作软件安装包下载
硕思Logo设计师是一款操作灵活简单、功能强大的logo制作软件。可以通过简单的点击就可以为网站、博客、论坛和邮件创建专业的logo、条幅、按钮、标题、图标和签名等。 硕思logo设计师提供了很多精心设计的模板和丰富的资源,为更好的创建logo艺术作品…...
springboot和mybatis项目学习
#项目整体样貌 ##bean package com.example.demo.bean;public class informationBean {private int id;private String name;private String password;private String attchfile;public int getId() {return id;}public String getName() {return name;}public String getPas…...

simdjson 高性能JSON解析C++库
simdjson 是什么 simdjson 是一个用来解析JSON数据的 C 库,它使用常用的 SIMD 指令和微并行算法来每秒解析千兆字节的 JSON,在Velox, ClickHouse, Doris 中均有使用。 加载和解析 JSON documents 出于性能考虑,simdjson 需要一个末尾有几个…...

安卓Context上下文
目录 前言一、Context简介二、Application Context2.1 Application Context的创建过程2.2 Application Context的获取过程 三、Activity的Context创建过程四、Service的Context创建过程 前言 Context也就是上下文对象,是Android较为常用的类,但是对于Co…...
实验13 简单拓扑BGP配置
实验13 简单拓扑BGP配置 一、 原理描述二、 实验目的三、 实验内容四、 实验配置五、 实验步骤 一、 原理描述 BGP(Border Gateway Protocol,边界网关协议)是一种用于自治系统间的动态路由协议,用于在自治系统(AS&…...

面试题分享--Spring02
Spring 框架中都用到了哪些设计模式?(必会) 1. 工厂模式:BeanFactory 就是简单工厂模式的体现,用来创建对象的实例 2. 单例模式:Bean 默认为单例模式 3. 代理模式:Spring 的 AOP 功能用到了 JDK 的动态代理和 CGLIB 字节码生成…...
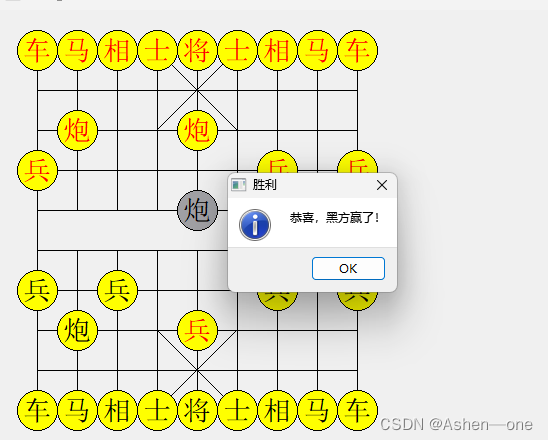
基于QT和C++实现的中国象棋
一,源码 board.h #ifndef BOARD_H #define BOARD_H#include <QWidget> #include "Stone.h"class Board : public QWidget {Q_OBJECT public:explicit Board(QWidget *parent 0);bool _bRedTurn; // 红方先走int _currentPlayer; // 当前玩家&…...

Mojo崛起:AI-first 的编程语言能否成为新流行?
眨眼之间,你可能会错过又一种编程语言的发明。 有个笑话说,程序员花费20%的时间编写代码,80%的时间决定使用什么语言。 事实上,编程语言如此之多,以至于我们不确定实际有多少种。据估计,至少有700种编程语…...

【数据结构与算法】哈夫曼树与哈夫曼编码
文章目录 哈夫曼树(最优二叉树)定义举个🌰(WPL的计算) 哈夫曼树的构造(最优二叉树的构造)举个🌰 哈夫曼树的性质 哈夫曼编码定义构造 哈夫曼树(最优二叉树) …...

基于多头注意力机制卷积神经网络结合双向门控单元CNN-BIGRU-Mutilhead-Attention实现柴油机故障诊断附matlab代码
在使用这些深度学习库时,你可以按照以下步骤构建CNN-BIGRU-Multihead-Attention模型: 导入所需的库和模块。例如,在使用TensorFlow时,你可以导入tensorflow库和其他需要的模块。 定义输入层。根据你的数据,定义适当的…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

智能GUI自动化:从SAG架构到实战部署的完整指南
1. 项目概述与核心价值最近在开源社区里,我注意到一个挺有意思的项目,叫openclaw-skill-sag。乍一看这个标题,可能会觉得有点抽象,但如果你对自动化、机器人流程自动化(RPA)或者智能体(Agent&am…...

基于BLE HID与旋转编码器打造双模式无线遥控器
1. 项目概述你有没有过这样的时刻:窝在沙发里看剧,想调个音量或者暂停一下,却不得不伸手去够茶几上的键盘或鼠标,打断那份沉浸的惬意?或者,在电脑上回味一些经典老游戏时,觉得用键盘移动、鼠标射…...

工控一体机电脑核心性能特征解析:从选型到部署的实战指南
1. 项目概述:为什么我们需要重新审视工控一体机电脑?在工业自动化、智能制造、智慧零售乃至边缘计算这些听起来高大上的领域里,有一类设备常常是幕后的“无名英雄”,它不像机器人手臂那样引人注目,也不像云端服务器那样…...

基于WebSocket的机械爪远程控制桥接系统设计与实战
1. 项目概述:一个连接物理世界与数字世界的“机械爪”远程控制桥最近在捣鼓一个挺有意思的开源项目,叫lucas-jo/openclaw-bridge-remote。光看名字,你可能觉得这又是一个关于机器人或者机械臂的遥控项目,但实际深入进去࿰…...
:精准匹配V6.6新渲染引擎底层纹理采样逻辑)
【仅剩47份】Midjourney湿版摄影风格训练数据包(含1851–1889年原始湿版扫描图谱×236张+ICC色彩配置文件×5):精准匹配V6.6新渲染引擎底层纹理采样逻辑
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格的历史溯源与数字再生价值 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由英国科学家弗雷德里克斯科特阿彻(Frederick Scott Archer…...

基于xclaude-plugin框架的Claude自定义插件开发实战指南
1. 项目概述:Claude插件生态的“瑞士军刀”如果你最近在深度使用Claude,尤其是Claude Desktop应用,那你大概率已经感受到了插件生态的潜力与混乱。官方插件商店虽然方便,但总有些特定需求找不到现成的解决方案,或者找到…...

3D打印LED发光史莱姆:零焊接电子制作与创意材料科学实践
1. 项目概述:当电子制作遇上创意手工几年前,我在一个社区创客空间带孩子们做活动,发现一个挺有意思的现象:一讲到电路、LED、电阻,不少孩子眼神就开始飘忽;但一旦拿出会发光的、可以随意揉捏的“史莱姆”泥…...

别再只用高斯噪声了!手把手教你为DDPG算法注入‘惯性’:Ornstein-Uhlenbeck噪声的Python实现与调参实战
突破DDPG探索瓶颈:Ornstein-Uhlenbeck噪声的工程实践指南 在机器人控制或自动驾驶仿真这类连续动作空间的任务中,DDPG算法常因探索效率低下导致训练停滞。当智能体在MuJoCo环境中反复"原地踏步"时,问题往往不在于算法本身…...

SMAPI模组加载器:星露谷物语模组玩家的终极完整指南
SMAPI模组加载器:星露谷物语模组玩家的终极完整指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否厌倦了手动安装星露谷物语模组时的繁琐步骤?是否担心模组冲突导致游…...