剖析 Kafka 消息丢失的原因
文章目录
- 前言
- 一、生产者导致的消息丢失的场景
- 场景1:消息太大
- 解决方案 :
- 1、减少生产者发送消息体体积
- 2、调整参数max.request.size
- 场景2:异步发送机制
- 解决方案 :
- 1、使用带回调函数的发送方法
- 场景3:网络问题和配置不当
- 解决方案 :
- 1、设置`acks`参数设置为"all"
- 2、设置重试参数
- 3、设置 min.insync.replicas参数
- 二、Broker服务端导致的消息丢失的场景
- 场景1:Broker 宕机
- 解决方案 :
- 1、增加副本数量
- 场景2:leader挂掉,follower未同步
- 解决方案 :
- 1、leader竞选资格
- 2、增加副本数量
- 场景3:持久化错误
- 解决方案 :
- 1、调整刷盘参数
- 2、增加副本数量
- 三、消费者导致的消息丢失
- 场景1:提交偏移量后消息处理失败
- 解决方案 :
- 场景2:并发消费
- 解决方案 :
- 场景3:消息堆积
- 解决方案 :
- 场景4:消费者组rebalance
- 解决方案 :
- 1、提高消费能力
- 2、调整参数避免不 必要的rebalance
- 依然会丢消息的场景
- 场景 1:
- 场景 2:
- 总结
前言
Kafka消息丢失的原因通常涉及多个方面,包括生产者、消费者和Kafka服务端(Broker)的配置和行为。下面将围绕这三个关键点,详细探讨Kafka消息丢失的常见原因,并提供相应的解决方案和最佳实践。具体分析如下:
一、生产者导致的消息丢失的场景
场景1:消息太大
消息大小超过Broker的message.max.bytes的值。此时Broker会直接返回错误。
解决方案 :
1、减少生产者发送消息体体积
可以通过压缩消息体、去除不必要的字段等方式减小消息大小。
2、调整参数max.request.size
max.request.size,表示生产者发送的单个消息的最大值,也可以指单个请求中所有消息的总和大小。默认值为1048576B,1MB。这个参数的值值必须小于Broker的message.max.bytes。
场景2:异步发送机制
Kafka生产者默认采用异步发送消息,如果未正确处理发送结果,可能导致消息丢失。
解决方案 :
1、使用带回调函数的发送方法
不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。带有回调通知的 send 方法可以针对发送失败的消息进行重试处理。
场景3:网络问题和配置不当
生产者在发送消息时可能遇到网络抖动或完全中断,导致消息未能到达Broker。如果生产者的配置没有考虑这种情况,例如未设置恰当的重试机制(retries参数)和确认机制(acks参数),消息就可能在网络不稳定时丢失。
解决方案 :
1、设置acks参数设置为"all"
acks参数指定了必须要有多少个分区副本收到消息,生产者才认为该消息是写入成功的,这个参数对于消息是否丢失起着重要作用,该参数的配置具体如下:
- acks = all/-1 : 表示kafka isr列表中所有的副本同步数据成功,才返回消息给客户端
- acks = 0 :表示客户端只管发送数据,不管服务端接收数据的任何情况
- acks = 1 :表示客户端发送数据后,需要在服务端 leader 副本写入数据成功后,返回响应
使用同步发送方式或确保acks参数设置为"all",以确保所有副本接收到消息。
2、设置重试参数
重试参数主要有retries和retry.backoff.ms两个参数。
(1)参数 retries是指生产者重试次数,该参数默认值为0。
消息在从生产者从发出到成功写入broker之前可能发生一些临时性异常,比如网络抖动、leader副本选举等,这些异常发生时客户端会进行重试,而重试的次数由retries参数指定。如果重试达到设定次数,生产者才会放弃重试并抛出异常。但是并不是所有的异常都可以通过重试来解决,比如消息过大,超过max.request.size参数配置的数值(默认值为1048576B,1MB)。如果设置retries大于0而没有设置参数max.in.flight.requests.per.connection(限制每个连接,也就是客户端与Node之间的连接最多缓存请求数)大于0则意味着放弃发送消息的顺序性。
使用retries的默认值交给使用方自己去控制,结果往往是不处理。所以通用设置建议设置如下:
retries = Integer.MAX_VALUE
max.in.flight.requests.per.connection = 1
该参数的设置已经在kafka 2.4版本中默认设置为Integer.MAX_VALUE;同时增加了delivery.timeout.ms的参数设置。
(2)参数retry.backoff.ms,用来设定两次重试之间的时间间隔,默认值为100。
避免无效的频繁重试。在配置retries和retry.backoff.ms之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间要大于异常恢复时间,避免生产者过早的放弃重试。
3、设置 min.insync.replicas参数
参数min.insync.replicas, 该参数控制的是消息至少被写入到多少个副本才算是 “真正写入”,该值默认值为 1,不建议使用默认值 1, 建议设置min.insync.replicas至少为2。 因为如果同步副本的数量低于该配置值,则生产者会收到错误响应,从而确保消息不丢失。
二、Broker服务端导致的消息丢失的场景
场景1:Broker 宕机
为了提升性能,Kafka 使用 Page Cache,先将消息写入 Page Cache,采用了异步刷盘机制去把消息保存到磁盘。如果刷盘之前,Broker Leader 节点宕机了,并且没有 Follower 节点可以切换成 Leader,则 Leader 重启后这部分未刷盘的消息就会丢失。
如果Broker的副本因子(replication.factor)设置过低,或者同步副本的数量(min.insync.replicas)设置不当,一旦Leader Broker宕机,选举出的新的Leader可能不包含全部消息,导致消息丢失。
解决方案 :
1、增加副本数量
这种场景下多设置副本数是一个好的选择,通常的做法是设置 replication.factor >= 3,这样每个 Partition 就会有 3个以上 Broker 副本来保存消息,同时宕机的概率很低。
同时配合设置上文提到的参数 min.insync.replicas至少为2(不建议使用默认值 1),表示消息至少要被成功写入到 2 个 Broker 副本才算是发送成功。
场景2:leader挂掉,follower未同步
假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但 leader 的数据还有一些没有被 follower 副本同步的话,就会造成消息丢失。
解决方案 :
1、leader竞选资格
参数unclean.leader.election.enable 参数值说明如下:
- true:允许 ISR 列表之外的节点参与竞选 Leader;
- false:不允许 ISR 列表之外的节点参与竞选 Leader。
该参数默认值为false。但如果为true的话,意味着非ISR集合中的副本也可以参加选举成为leader,由于不同步副本的消息较为滞后,此时成为leader的话可能出现消息不一致的情况。所以unclean.leader.election.enable 这个参数值要设置为 false。
2、增加副本数量
同上文。
场景3:持久化错误
为了提高性能,减少刷盘次数, Kafka的Broker数据持久化时,会先存储到页缓存(Page cache)中,
按照一定的消息量和时间间隔进行进行批量刷盘的做法。数据在page cache时,如果系统挂掉,消息未能及时写入磁盘,数据就会丢失。Kafka没有提供同步刷盘的方式,所以只能通过增加副本或者修改刷盘参数提高刷盘频率来来减少这一情况。
解决方案 :
1、调整刷盘参数
kafka提供3个参数来优化刷盘机制
log.flush.interval.messages 多少条消息刷盘1次,默认Long.MaxValue
log.flush.interval.ms 隔多长时间刷盘1次 默认null
log.flush.scheduler.interval.ms 周期性的刷盘。默认Long.MaxValue
官方不建议通过上述的刷盘3个参数来强制写盘。其认为数据的可靠性通过replica来保证,而强制flush数据到磁盘会对整体性能产生影响。
2、增加副本数量
同上文。
三、消费者导致的消息丢失
场景1:提交偏移量后消息处理失败
参数 enable.auto.commit 是否自动提交offset,默认是true。代表消息会自动提交偏移量。但是提交偏移量后,消息处理失败了,则该消息丢失。
解决方案 :
可以把 enable.auto.commit 设置为 false,这样相当于每次消费完后手动更新 Offset。不过这又会带来提交偏移量失败时,该消息复消费问题,因此消费端需要做好幂等处理。
场景2:并发消费
如果消费端采用多线程并发消费,很容易因为并发更新 Offset 导致消费失败。
解决方案 :
如果对消息丢失很敏感,最好使用单线程来进行消费。如果需要采用多线程,可以把 enable.auto.commit 设置为 false,这样相当于每次消费完后手动更新 Offset。
场景3:消息堆积
消费者如果处理消息的速度跟不上消息产生的速度,可能会导致消息堆积,进而触发消费者客户端的流控机制,从而遗失部分消息。
解决方案 :
一般问题都出在消费端,尽量提高客户端的消费速度,消费逻辑另起线程进行处理。
场景4:消费者组rebalance
消费者组 rebalance导致导致消息丢失的场景有两种:
1、某个客户端心跳超时,触发 Rebalance被踢出消费组。如果只有这一个客户端,那消息就不会被消费了。
2、Rebalance时没有及时提交偏移量,因为 Rebalance重新分配分区给消费者,所以如果在 Rebalance 过程中,消费者没有及时提交偏移量,可能会导致消息丢失。
解决方案 :
1、提高消费能力
提高单条消息的处理速度,例如对消息处理中比 较耗时的步骤可通过异步的方式进行处理、利用多线程处理等。
2、调整参数避免不 必要的rebalance
参数max.poll.interval.ms用于指定consumer两次poll的最大时间间隔(默认5分钟),如果超过了该间隔consumer client会主动向coordinator发起LeaveGroup请求,触发rebalance。根据实际场景可将max.poll.interval.ms值设置大一点,避免不 必要的rebalance。
此外可适当减小max.poll.records的值,max.poll.records用于指每次调用poll()时取到的records的最大数,默认值是500,可根 据实际消息速率适当调小。这种思路可解决因消费时间过长导致的重复消费问题, 对代码改动较小,但无法绝对避免重复消费问题。
依然会丢消息的场景
即使把参数都设置的很完善也会丢失消息的两种场景
场景 1:
当把数据写到足够多的PageCache的时候就会告知生产者现在数据已经写入成功,但如果还没有把PageCache的数据写到硬盘上,这时候PageCache所在的操作系统都挂了,此时就会丢失数据。
场景 2:
副本所在的服务器硬盘都坏了,也会丢数据。
总结
总的来说,Kafka消息丢失是一个涉及多个环节的问题,需要从生产者、Broker和消费者三个层面综合考虑。通过合理的配置和策略,结合监控和及时的应对措施,可以大幅降低消息丢失的风险,确保数据在分布式系统中的可靠传递。
最后

相关文章:
剖析 Kafka 消息丢失的原因
文章目录 前言一、生产者导致的消息丢失的场景场景1:消息太大解决方案 :1、减少生产者发送消息体体积2、调整参数max.request.size 场景2:异步发送机制解决方案 :1、使用带回调函数的发送方法 场景3:网络问题和配置不当…...

阿里又出AI神器,颠覆传统图像编辑,免费开源!
文章首发于公众号:X小鹿AI副业 大家好,我是程序员X小鹿,前互联网大厂程序员,自由职业2年,也一名 AIGC 爱好者,持续分享更多前沿的「AI 工具」和「AI副业玩法」,欢迎一起交流~ 最近阿里开源了 Mi…...

git 大文本上传和下载git-lfs
1. ubuntu 1)下载脚本来自动化配置系统上的包存储库,导入签名密钥等过程。这些脚本必须在root下运行。 # apt/deb repos: curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash # curl -s https://packag…...

Ps:脚本与动作
有三种脚本语言可用于编写 Photoshop 脚本:AppleScript(macOS)、JavaScript 和 VBScript(Windows)。 Photoshop 脚本文件默认文件夹 Win:C:\Program Files\Adobe\Adobe Photoshop 2024\Presets\Scripts Mac…...

MySQL数据库回顾(1)
数据库相关概念 关系型数据库 概念: 建立在关系模型基础上,由多张相互连接的二维表组成的数据库。 特点: 1.使用表存储数据,格式统一,便于维护 2.使用SQL语言操作,标准统一,使用方便 SOL SQL通用语法 …...
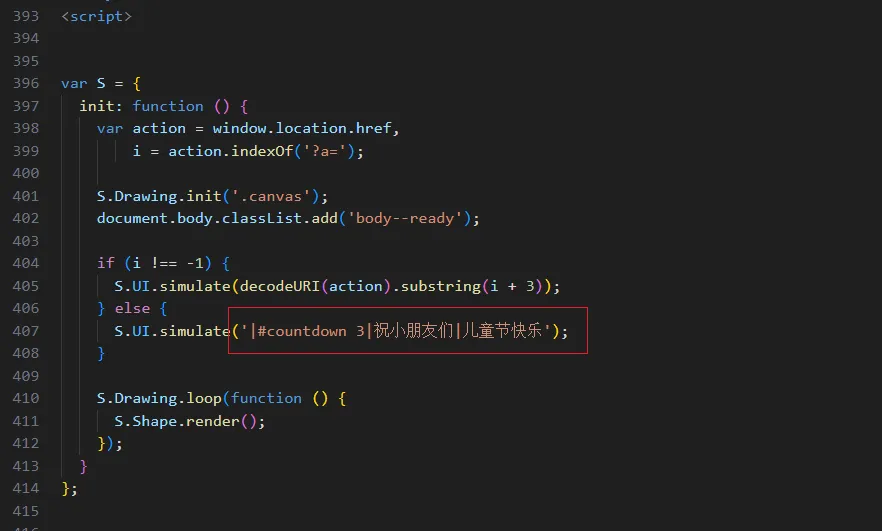
文字炫酷祝福 含魔法代码
效果下图:(可自定义显示内容) 代码如下: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initi…...
docker容器中连接宿主机mysql数据库
最近要在docker中使用mysql数据库,首先考虑在ubuntu的镜像中安装mysql,这样的脚本和数据库都在容器中,直接访问localhost:3306,脚本很简单,如下: import pymysql# 建立数据库连接 db pymysql.…...

Leetcode 41. 缺失的第一个正数
41. 缺失的第一个正数 - 力扣(LeetCode) class Solution {/**2024.6.18首先把小于等于0和大于n的全部标记成n1,这些数据不会是答案;把出现的数字标记为负数,比如数字3,那就是nums[2]-nums[2];下次从头遍历…...

MyBatis 自定义映射 ResultMap:字段与属性的映射详解
在 MyBatis 框架中,ResultMap是一个非常强大的功能,它允许我们自定义SQL查询结果与Java对象之间的映射关系。特别是在数据库字段名和Java对象属性名不一致时,ResultMap能够帮助我们精确地映射数据。 ResultMap 的基本使用 若字段名和实体类…...

找单身狗2
找单身狗2 之前遇到类似的题目的思路: 首先写出这些数的二进制形式: 核心原理 接下来的问题是怎么把5和6分开来? 这里是最后一位进行比较,按位异或是相同为0,相异为1,最后一位从上图看出是1,说…...
element-ui将组件默认语言改为中文
在main.js中加入以下代码即可 // 引入 Element Plus 及其样式 import ElementPlus from element-plus import element-plus/dist/index.css// 引入中文语言包 import zhCn from element-plus/es/locale/lang/zh-cn// 使用 Element Plus 并设置语言为中文 app.use(ElementPlus,…...
SuperMap iClient3D 11i(2023) SP1 for Cesium 调整
SuperMap iClient3D 11i(2023) SP1 for Cesium 最新版本 下载地址 SuperMap技术资源中心|为您提供全面的在线技术服务 每一次版本升级,都要对代码进行修改调整,都是为了解决功能需求。当然,也为产品做了小白鼠测试,发现bug,优化功能。 由于前端开发使用的是dojo框架,类…...

保姆级小白就业人工智能(视频+源码+笔记)
🍅我是小宋, Java学习AI,记录学习之旅。关注我,带你轻松过面试。提升简历亮点(14个demo) 🍅我的java面试合集已有12W 浏览量。🌏号:tutou123com。拉你进专属群。 ⭐⭐你的…...

微信小程序,分享和反馈功能
<button type"primary" open-type"share">分享</button> <button type"primary" open-type"feedback">反馈</button>...

数据安全未来之路,天空卫士荣誉领榜《中国数据安全50强(2024)》
《中国数据安全50强(2024)》 数世咨询首份《中国数据安全50强(2024)》报告发布。天空卫士凭借其卓越的技术创新、市场领导力、业务收入能力和企业发展能力,在众多竞争者中脱颖而出,荣登50强榜单࿰…...

CAD二次开发(10)-单行文字的添加+图形修改
1. 单行文字的添加 第一步: 首先在CAD中新增中文样式 输入ST命令: 第二步:代码开发 /// <summary>/// 添加文本信息/// </summary>[CommandMethod("AddText")]public void AddText(){var doc Application.DocumentM…...

【SpringBoot集成Spring Security】
一、前言 Spring Security 和 Apache Shiro 都是安全框架,为Java应用程序提供身份认证和授权。 二者区别 Spring Security:重量级安全框架Apache Shiro:轻量级安全框架 关于shiro的权限认证与授权可参考小编的另外一篇文章 : …...
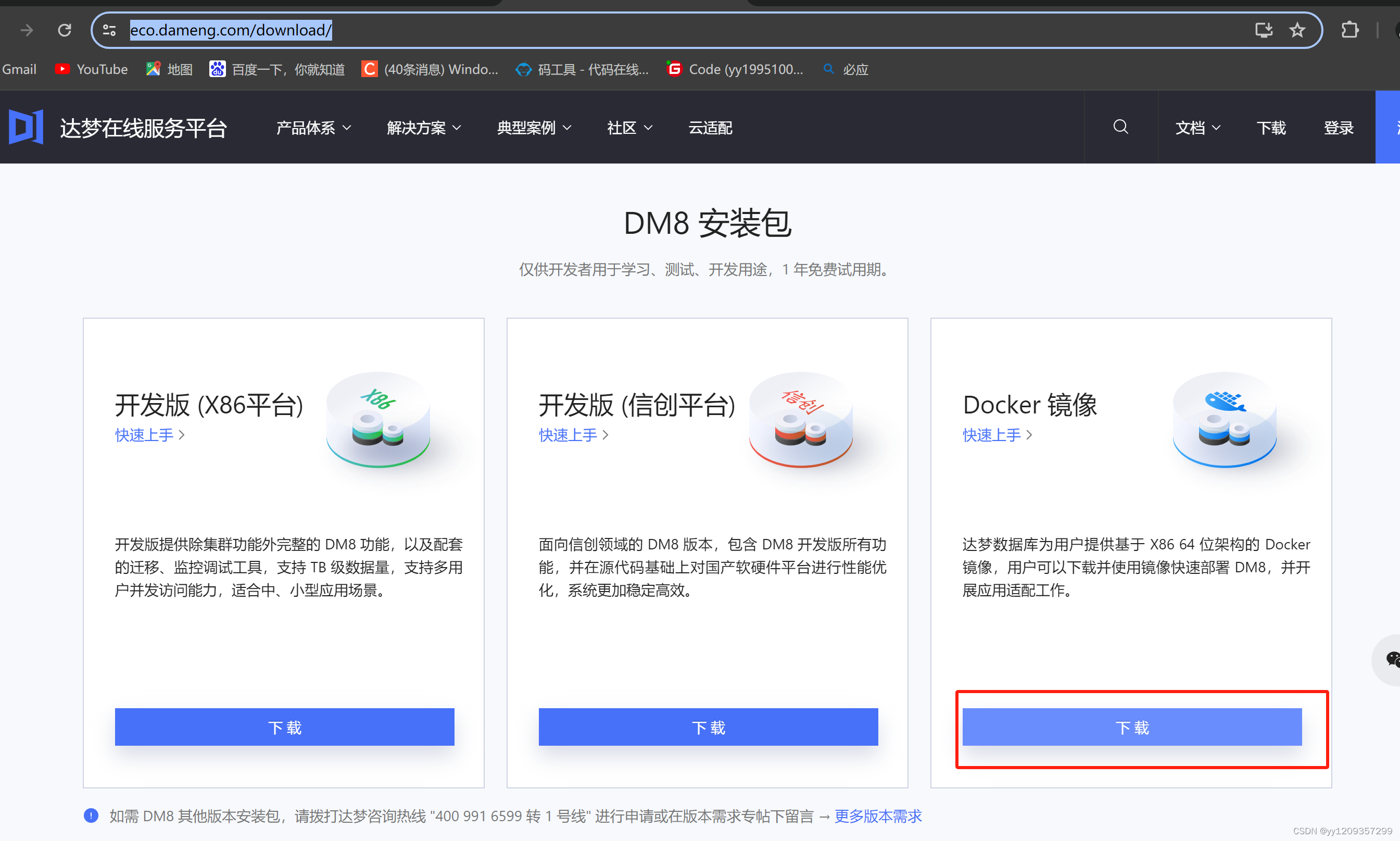
docker部署dm数据库
官方文档参考 官网地址:https://eco.dameng.com/document/dm/zh-cn/start/dm-install-docker.html 下载镜像地址 docker部署 1、加载镜像 docker load -i dm8_20240613_x86_rh6_64_rq_ent_8.1.3.140_pack5.tar使用docker images,查看镜像和镜像标签…...

Shell中执行.sh文件的常见方式
在Shell中执行.sh文件有几种常见的方式,具体取决于你希望如何执行这个脚本文件。以下是一些常用的方法: 直接运行: ./script.sh 这是最简单的方式。在当前Shell会话中执行脚本文件。 使用bash命令执行: bash script.sh 明确使用b…...

超分辨率重建——2022冠军RLFN网络推理测试(详细图文教程)
💪 专业从事且热爱图像处理,图像处理专栏更新如下👇: 📝《图像去噪》 📝《超分辨率重建》 📝《语义分割》 📝《风格迁移》 📝《目标检测》 📝《暗光增强》 &a…...

如何用DankDroneDownloader实现无人机固件完全掌控:Windows用户终极指南
如何用DankDroneDownloader实现无人机固件完全掌控:Windows用户终极指南 【免费下载链接】DankDroneDownloader A Custom Firmware Download Tool for DJI Drones Written in C# 项目地址: https://gitcode.com/gh_mirrors/da/DankDroneDownloader 你是否曾因…...

高途CFO沈楠辞职 高级副总裁罗斌晋升为首席运营官
雷递网 乐天 5月15日高途(NYSE: GOTU)日前宣布管理层调整。高途称,公司CFO沈楠由于个人原因已递交辞呈,2026年5月31日生效。沈楠辞职后三个月内继续担任公司顾问,以确保平稳过渡。高途战略主管徐步青将负责公司资本市场相关事宜,高…...

GitHub代码仓库导航:开发者如何高效构建与使用技术资源地图
1. 项目概述:一个面向开发者的代码仓库导航 最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫 yeabnoah/vx_code 。乍一看这个标题,可能会有点摸不着头脑, vx_code 是什么?是某种新的编程语言…...

Bluetooth 蓝牙协议详解
一、协议简介蓝牙(Bluetooth)短距离无线通信技术,主流分经典蓝牙与BLE 蓝牙 5.0/5.3(低功耗蓝牙),多用于近距离设备配对、数据透传、外设连接,消费电子与便携设备最常用。二、基础参数底层标准&…...

跨越网络鸿沟:Qt Creator配置CDB实现远程调试实战
1. 为什么需要远程调试? 在嵌入式开发或者跨平台开发中,我们经常会遇到这样的场景:开发环境在本地PC上,但目标程序需要运行在远程设备上。比如开发一个工业控制软件,本地使用Qt Creator开发,但最终程序要部…...

Ubuntu 22.04 下配置 Arduino IDE 2.x:从安装到第三方库的完整避坑指南
1. 准备工作:下载Arduino IDE 2.x 在Ubuntu 22.04上配置Arduino开发环境,第一步自然是获取官方IDE。我推荐直接从Arduino官网下载最新版本,避免使用老旧软件包带来的兼容性问题。打开浏览器访问arduino.cc/en/software,你会看到两…...

QT新手避坑:一个QWidget只能有一个QLayout,别再重复setLayout了
QT布局管理核心机制:从QLayout父子关系到内存安全实践 在QT的GUI开发中,布局管理是最基础也最容易踩坑的领域之一。许多刚接触QT的开发者,往往会被看似简单的布局系统所迷惑,直到控制台不断输出"QLayout: Attempting to add …...

如何在macOS上运行Windows应用:Whisky完整使用指南
如何在macOS上运行Windows应用:Whisky完整使用指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想要在Mac上运行Windows专属软件和游戏?厌倦了虚拟机的高资…...
那点事儿)
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿 激光技术正悄然渗透进我们生活的每个角落——从自动驾驶汽车的"眼睛"到智能门锁的指纹识别,从工业切割到医疗美容,这些看似毫不相关…...

基于全志T527开发板的手势识别:OpenCV部署与轮廓匹配实战
1. 项目概述与硬件平台选择最近在做一个嵌入式视觉项目,需要在一块开发板上实现实时的手势识别功能。选型时,我重点考察了算力、接口丰富度和社区支持。最终,米尔电子的MYD-LT527开发板进入了我的视线。这块板子核心是全志T527处理器…...