风控中的文本相似方法之余弦定理
一、余弦相似
一、 余弦相似概述
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。
从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。另外,它通常用于文本挖掘中的文件比较,在数据挖掘领域中,会用到它来度量集群内部的凝聚力。
二、 余弦相似应用场景
原创文章检测:通过文本相似,可以检测公众号文章、论文等是否存在抄袭
垃圾邮件识别:如“诚聘淘宝兼职”、“诚聘打字员”、“文章代写”、“增值税发票”等这样的小广告满天飞,作为网站或者APP的风控,不可能简单的加几个关键字就能进行屏蔽的,一般常用的方法就是标注一部分典型的广告文本,与它相似度高的就进行屏蔽。
内容推荐系统:在腾讯新闻、微博、头条、知乎等,每一篇文章、帖子的下面都有一个推荐阅读,那就是根据一定算法计算出来的相似文章。
冗余新闻过滤:我们每天接触过量的信息,信息之间存在大量的重复,相似度可以帮我们删除这些重复内容,比如,大量相似新闻的过滤筛选。
可用于文本相似的方法非常多,比如基于字符的杰卡德相似、编辑距离相似、最长公共子串等,基于距离的相似也很多,比如汉明距离、欧几里得距离等。本文介绍的是余弦距离相似,比较简单,可以作为风控领域文本相似的入门。
废话不多说,先看一个案例,我们用三句话作为例子,我从自己的邮箱里面扒出来的垃圾邮件,具体步骤如下。
三、 计算文本余弦相似
第一步,分词。
A句子:有/发票/加/薇/45357
B句子:有/发票/加/微/45357
C句子:正规/ 增值税/ 发票
第二步,列出所有的词(所有词的长度作为向量长度)
有,发票,加,薇,微,45357,正规,增值税
第三步,计算词频
A句子:有 1,发票 1,加 1,薇 1,微 0,45357 1,正规 0,增值税 0
B句子:有 1,发票 1,加 1,薇 0,微 1,45357 1,正规 0,增值税 0
C句子:有 0,发票 1,加 0,薇 0,微 0,45357 0,正规 1,增值税 1
第四步,写出词频向量。
A句子:[1, 1, 1, 1, 0, 1, 0 ,0]
B句子:[1, 1, 1, 0, 1, 1, 0 ,0]
C句子:[0, 1, 0, 0, 0, 0, 1 ,1]
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点(0, 0, ...)出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。根据初中知识,余弦定理告诉我们,可以用下面的公式求得:
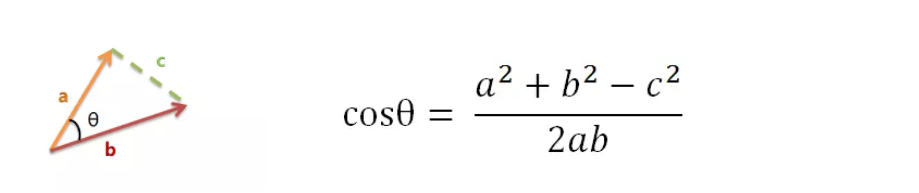
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
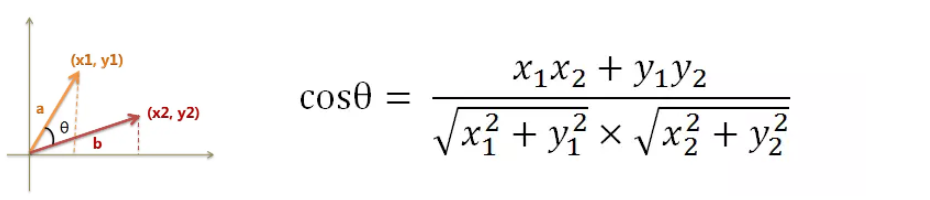
数学家已经证明,余弦的这种计算方法对n维向量也成立,假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:

使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。

下面我们用Python代码计算看看
import numpy as npA = np.array([1, 1, 1, 1, 0, 1, 0 ,0])B = np.array([1, 1, 1, 0, 1, 1, 0 ,0])C = np.array([0, 1, 0, 0, 0, 0, 1 ,1])#定义相似计算函数def cos_simi(x,y):num = x.dot(y.T)denom = np.linalg.norm(x) * np.linalg.norm(y)return num / denomcos_simi(A,B)0.7999999999999998cos_simi(A,C)0.2581988897471611cos_simi(B,C)0.2581988897471611
[有/发票/加/薇/45357] 和 [有/发票/加/微/45357] 只有一个字的差异,相似度0.80
[有/发票/加/薇/45357] 和 [正规/ 增值税/ 发票] 只有一个词相同,相似度0.2581,结果符合我们的感知。到此,我们就学会了计算两个句子的相似度
四、完整版代码
# 输入A,B两段语句,判断相似度import jieba
from collections import Counterdef preprocess_data(text):"""数据预处理函数,分词并去除停用词"""# 使用结巴分词对文本进行分词words = jieba.cut(text)# 去除停用词,这里只列举了几个示例停用词,实际应用中需要根据具体需求添加更多停用词stopwords = ['的', '了', '和', '是', '就', '而', '及', '与', '或']filtered_words = [word for word in words if word not in stopwords]return filtered_wordsdef extract_features(words):"""特征提取函数,使用词袋模型"""features = Counter(words)return str(features)def cosine_similarity(features1, features2):"""余弦相似度计算函数"""numerator = sum(features1[word] * features2[word] for word in set(features1) & set(features2))denominator = ((sum(features1[word] ** 2 for word in features1) ** 0.5) * (sum(features2[word] ** 2 for word in features2) ** 0.5))if not denominator:return 0.0else:return round(numerator / float(denominator), 3)def check_duplicate(content, input_text, threshold=0.7):"""查重函数,判断当前文本是否与已有文本重复"""# 对当前文本进行预处理和特征提取words = preprocess_data(content)features = extract_features(words)# 在此模拟已有文本的特征existing_features = extract_features(preprocess_data(input_text))similarity = cosine_similarity(eval(features), eval(existing_features))# 根据设定的相似度阈值来判断是否重复if similarity >= threshold:return similarityelse:return similaritysimilarity = check_duplicate("我是你的人","我是你的情人")
print('similarity',similarity)
二、杰卡德相似
杰卡德相似是比较常见的文本相似计算方法,文本分词后的交集比上并集,公式如下:
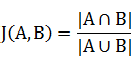
但在风控的实际业务中,有很多场景存在大规模的重复文本片段,比如:
S1 = '模具硅胶 翻模硅胶 指纹签到手指摸 指纹假膜 模具硅胶 液态硅胶 半透明硅胶 指模自制 指纹识别硅胶 打卡指纹透明膜 指纹膜 指纹 胶膜 手机指纹打卡假膜 指纹打卡机指纹胶膜 指纹识别贴打卡 diy硅胶模具材料 指纹打卡 指纹打卡道具 指纹打卡假膜人脸 指纹识别膜 硅胶 硅胶模具diy 模型制作材料 指模 液体硅胶 考勤指纹胶 指纹打卡假膜科密 指纹打卡假膜 硅橡胶 指纹胶膜制作 打卡 翻模硅胶材料 食品级硅胶 打卡考勤指纹 指模具考勤 翻模硅胶 diy 指纹打卡膜 指纹打卡假膜 打卡机指纹识别膜 指纹制作 diy液体材料 指纹制作工具 指模具 手指打卡 手办工具 签到指纹胶膜制作 模具硅胶翻模 翻模硅胶 指纹识别胶打卡 硅胶 硅胶打卡 打卡指纹胶膜 指纹识别膜套'
S2 = '指纹打卡假膜科密 指纹签到手指摸 指纹识别膜 硅胶 指模具 手指打卡 指纹打卡膜 指纹打卡假膜人脸 打卡考勤指纹 指模具考勤 指纹打卡机指纹胶膜 指纹制作工具 指纹打卡 指纹识别套 硅胶 硅橡胶 指模 diy硅胶模具材料 指纹制作 指纹识别硅胶 指模自制 打卡指纹胶膜 指纹打卡假膜 指纹打卡道具 手机指纹打卡假膜 指纹假膜 指纹膜 指纹打卡假膜 硅橡胶 打卡机指纹识别膜 指纹识别模具 硅胶 指纹识别膜套 硅胶模具diy 打卡指纹透明膜 上班 打卡指纹透明膜 指纹识别胶打卡 硅胶 指纹识别打卡膜假手指 硅胶 考勤指纹胶 硅胶打卡 指纹胶膜制作 打卡 签到指纹胶膜制作 指纹 胶膜 指纹识别贴打卡abcdedf'
使用杰卡德相似计算相似度:0.7647,在S2中加入'abcdedf'干扰字符串后,相似度 0.6964
使用新加权算法计算相似度:0.7305 在S2中加入'abcdedf'干扰字符串后,相似度 0.7252
可见第二种算法,针对这种无序的词组计算相似度,抗干扰能力要比传统的方法强很多,能够更稳点的计算类似的多来源文本的相似性。
具体的计算逻辑如下(只计算了top20):

除了上面的案例,还有下面的各种场景,都存在大量重复的文本集合,我们需要有一种专门的方法来进行计算。
两个商家店铺所有商品名称集合,一般一个店铺商品都有差不多
百度推广者的竞价词集合,基本会穷举所有相关的搜索词
... ...
淘宝商家的推广词集合
我写了个函数实现,也不知道叫啥,就是一种加权的杰卡德相似。
S1 = '模具硅胶 翻模硅胶 指纹签到手指摸 指纹假膜 模具硅胶 液态硅胶 半透明硅胶 指模自制 指纹识别硅胶 打卡指纹透明膜 指纹膜 指纹 胶膜 手机指纹打卡假膜 指纹打卡机指纹胶膜 指纹识别贴打卡 diy硅胶模具材料 指纹打卡 指纹打卡道具 指纹打卡假膜人脸 指纹识别膜 硅胶 硅胶模具diy 模型制作材料 指模 液体硅胶 考勤指纹胶 指纹打卡假膜科密 指纹打卡假膜 硅橡胶 指纹胶膜制作 打卡 翻模硅胶材料 食品级硅胶 打卡考勤指纹 指模具考勤 翻模硅胶 diy 指纹打卡膜 指纹打卡假膜 打卡机指纹识别膜 指纹制作 diy液体材料 指纹制作工具 指模具 手指打卡 手办工具 签到指纹胶膜制作 模具硅胶翻模 翻模硅胶 指纹识别胶打卡 硅胶 硅胶打卡 打卡指纹胶膜 指纹识别膜套'S2 = '指纹打卡假膜科密 指纹签到手指摸 指纹识别膜 硅胶 指模具 手指打卡 指纹打卡膜 指纹打卡假膜人脸 打卡考勤指纹 指模具考勤 指纹打卡机指纹胶膜 指纹制作工具 指纹打卡 指纹识别套 硅胶 硅橡胶 指模 diy硅胶模具材料 指纹制作 指纹识别硅胶 指模自制 打卡指纹胶膜 指纹打卡假膜 指纹打卡道具 手机指纹打卡假膜 指纹假膜 指纹膜 指纹打卡假膜 硅橡胶 打卡机指纹识别膜 指纹识别模具 硅胶 指纹识别膜套 硅胶模具diy 打卡指纹透明膜 上班 打卡指纹透明膜 指纹识别胶打卡 硅胶 指纹识别打卡膜假手指 硅胶 考勤指纹胶 硅胶打卡 指纹胶膜制作 打卡 签到指纹胶膜制作 指纹 胶膜 指纹识别贴打卡 abcdedf'
from collections import Counter
class Similarty(): def __init__(self,S1,S2,topn):self.S1 = S1self.S2 = S2self.topn = topn''' 标准杰卡德''' def normal_jaccard(self):return len(set(self.S1)&set(self.S2))/len(set(self.S1) | set(self.S2))''' 加权杰卡德''' def weight_jaccard(self): if self.S1 is not None and self.S2 is not None:sim_0 = self.S1.replace(' ','')sim_1 = self.S2.replace(' ','')collect0 = Counter(dict(Counter(sim_0).most_common(self.topn)))collect1 = Counter(dict(Counter(sim_1).most_common(self.topn))) jiao = collect0 & collect1bing = collect0 | collect1 sim = float(sum(jiao.values()))/float(sum(bing.values())) return(sim) else:return 0.0sim = Similarty(S1,S2,50)#初始化
sim.normal_jaccard()
0.6964285714285714
sim.weight_jaccard()
0.7252396166134185我这里为了简单,仅仅分字进行的相似计算,大家也可以自然语言分词计算,也可以N-gram后计算,稳定性会进一步加强。
好了,本期内容分享到此了,希望对你有启发。
有什么需求,可以联系我。
下面是一些计算的案例



原文链接:在此鸣谢小伍哥!!!https://mp.weixin.qq.com/s?__biz=MzA4OTAwMjY2Nw==&mid=2650188043&idx=2&sn=2fd5d3e143050092ebbee5969a153852&chksm=88238ecfbf5407d9a0a31ba2d892f87214e7225becf25ec4c209a66e4283aa2c08b990bfb73c&scene=21#wechat_redirect
相关文章:
风控中的文本相似方法之余弦定理
一、余弦相似 一、 余弦相似概述 余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。 从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。结…...

Spring Boot定时任务编程指南:如何创建和配置周期性任务
🍁 作者:知识浅谈,CSDN签约讲师,CSDN博客专家,华为云云享专家,阿里云专家博主 📌 擅长领域:全栈工程师、爬虫、ACM算法 🔥 微信:zsqtcyw 联系我领取学习资料 …...

Java 获取客户端 IP 地址【工具类】
Java 获取客户端 IP 地址 import javax.servlet.http.HttpServletRequest; import java.net.InetAddress;/*** 网络工具类*/ public class NetUtils {/*** 获取客户端 IP 地址** param request 请求* return {link String}*/public static String getIpAddress(HttpServletReq…...
区块链中nonce是什么,什么作用
目录 区块链中nonce是什么,什么作用 区块链中nonce是什么,什么作用 Nonce在以太坊中是一个用于确保交易顺序性和唯一性的重要参数。以下是对Nonce的详细解释: 定义 Nonce是一个scalar值,它等于从该地址发送的交易数量,或在具有关联代码的账户的情况下,由该账户创建的合…...

探索Python的多媒体解决方案:ffmpy库
文章目录 探索Python的多媒体解决方案:ffmpy库一、背景:数字化时代的多媒体处理二、ffmpy:Python与ffmpeg的桥梁三、安装ffmpy:轻松几步四、ffmpy的五项基本功能1. 转换视频格式2. 调整视频质量3. 音频转换4. 视频截图5. 视频合并…...
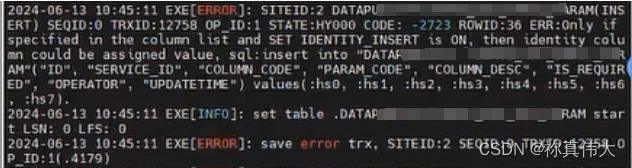
dmhs同步因目的端表自增列报错解决方法
dmhs同步因目的端表自增列报错解决方法 1 dmhs copy 装载数据时报错 HY000 CODE:-27232 配置源端捕获器cpt 1 dmhs copy 装载数据时报错 HY000 CODE:-2723 ERR:Only if specified in the column list and SET IDENTITY INSERT is ON, then identity column could be assigned …...
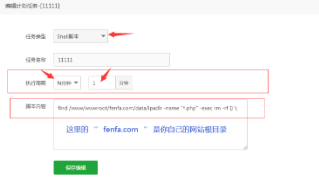
封装分发安装教程
【安装环境】 Linux伪静态 PHP7.1mysql5.6 SSL 证书 (使用宝塔) 1、在宝塔上面新建站点,把压缩包上传到根目录,解压出来,然后导入 sql 数据库文件,再 然后修改数据库配置 source\system\db_config.php 2、…...

redis从入门到进阶——数据类型、 操作、数值操作、发布订阅、消息队列、布隆过滤器、事务
文章目录 基础数据类型操作数值操作 进阶发布订阅消息队列布隆过滤器事务 基础 数据类型 string,set, hash, list, zset 操作 string符串类型: 保存一个字符串:set key value [EX seconds|PX milliseconds...] [NX|XX]EX:设置…...

剖析 Kafka 消息丢失的原因
文章目录 前言一、生产者导致的消息丢失的场景场景1:消息太大解决方案 :1、减少生产者发送消息体体积2、调整参数max.request.size 场景2:异步发送机制解决方案 :1、使用带回调函数的发送方法 场景3:网络问题和配置不当…...

阿里又出AI神器,颠覆传统图像编辑,免费开源!
文章首发于公众号:X小鹿AI副业 大家好,我是程序员X小鹿,前互联网大厂程序员,自由职业2年,也一名 AIGC 爱好者,持续分享更多前沿的「AI 工具」和「AI副业玩法」,欢迎一起交流~ 最近阿里开源了 Mi…...

git 大文本上传和下载git-lfs
1. ubuntu 1)下载脚本来自动化配置系统上的包存储库,导入签名密钥等过程。这些脚本必须在root下运行。 # apt/deb repos: curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash # curl -s https://packag…...

Ps:脚本与动作
有三种脚本语言可用于编写 Photoshop 脚本:AppleScript(macOS)、JavaScript 和 VBScript(Windows)。 Photoshop 脚本文件默认文件夹 Win:C:\Program Files\Adobe\Adobe Photoshop 2024\Presets\Scripts Mac…...

MySQL数据库回顾(1)
数据库相关概念 关系型数据库 概念: 建立在关系模型基础上,由多张相互连接的二维表组成的数据库。 特点: 1.使用表存储数据,格式统一,便于维护 2.使用SQL语言操作,标准统一,使用方便 SOL SQL通用语法 …...
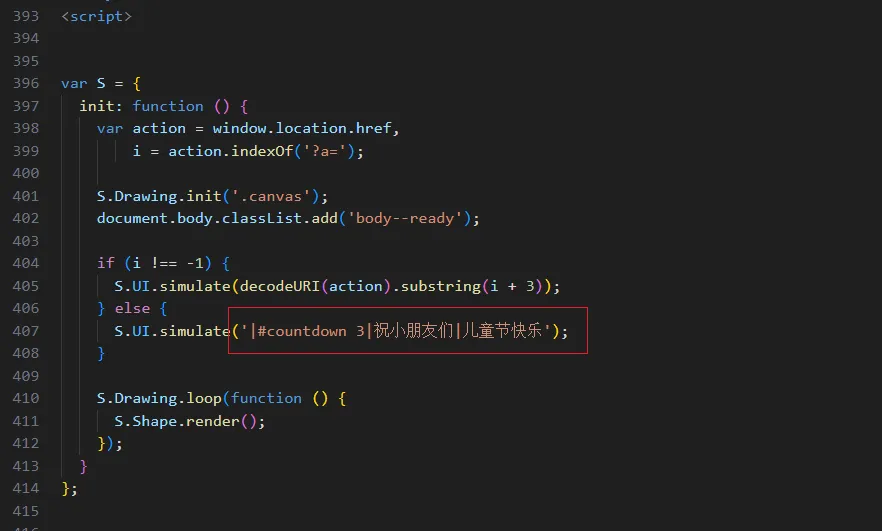
文字炫酷祝福 含魔法代码
效果下图:(可自定义显示内容) 代码如下: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initi…...
docker容器中连接宿主机mysql数据库
最近要在docker中使用mysql数据库,首先考虑在ubuntu的镜像中安装mysql,这样的脚本和数据库都在容器中,直接访问localhost:3306,脚本很简单,如下: import pymysql# 建立数据库连接 db pymysql.…...

Leetcode 41. 缺失的第一个正数
41. 缺失的第一个正数 - 力扣(LeetCode) class Solution {/**2024.6.18首先把小于等于0和大于n的全部标记成n1,这些数据不会是答案;把出现的数字标记为负数,比如数字3,那就是nums[2]-nums[2];下次从头遍历…...

MyBatis 自定义映射 ResultMap:字段与属性的映射详解
在 MyBatis 框架中,ResultMap是一个非常强大的功能,它允许我们自定义SQL查询结果与Java对象之间的映射关系。特别是在数据库字段名和Java对象属性名不一致时,ResultMap能够帮助我们精确地映射数据。 ResultMap 的基本使用 若字段名和实体类…...

找单身狗2
找单身狗2 之前遇到类似的题目的思路: 首先写出这些数的二进制形式: 核心原理 接下来的问题是怎么把5和6分开来? 这里是最后一位进行比较,按位异或是相同为0,相异为1,最后一位从上图看出是1,说…...
element-ui将组件默认语言改为中文
在main.js中加入以下代码即可 // 引入 Element Plus 及其样式 import ElementPlus from element-plus import element-plus/dist/index.css// 引入中文语言包 import zhCn from element-plus/es/locale/lang/zh-cn// 使用 Element Plus 并设置语言为中文 app.use(ElementPlus,…...
SuperMap iClient3D 11i(2023) SP1 for Cesium 调整
SuperMap iClient3D 11i(2023) SP1 for Cesium 最新版本 下载地址 SuperMap技术资源中心|为您提供全面的在线技术服务 每一次版本升级,都要对代码进行修改调整,都是为了解决功能需求。当然,也为产品做了小白鼠测试,发现bug,优化功能。 由于前端开发使用的是dojo框架,类…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...