【数据结构】堆排序
堆是一种叫做完全二叉树的数据结构,可以分为大根堆,小根堆,而堆排序就是基于这种结构而产生的一种程序算法。
大堆:每个节点的值都大于或者等于他的左右孩子节点的值
小堆:每个结点的值都小于或等于其左孩子和右孩子结点的值
不管是大堆还是小堆父节点的数组下标和其孩子节点的下标关系都为
parent=(child-1)/2 leftchild=2*parent+1 rightchild=2*parent+2
建堆
建堆有两种方法1.向上调整建堆2.向下调整建堆
向上调整建堆
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void AdjustUp(int* a, int child) //向上调整
{int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]) //建大堆还是小堆在这里调整{ //大堆a[parent]<a[child] 小堆反之Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}void HeapSort(int* a, int n)
{for (int i = 0; i < n; ++i){AdjustUp(a, i);}
}int main()
{int a[] = { 1,10,2,20,3,30,4,40,5,50 };HeapSort(a, sizeof(a) / sizeof(int));for (int i = 0; i < sizeof(a) / sizeof(int); ++i){printf("%d ", a[i]);}return 0;
}
向上调整建堆是从数组的第一个元素开始一次向后遍历数组元素,每一个数组元素都向上调整建堆,这个过程就模拟建立起了堆,这个过程的时间复杂度推导过程:O(N*logN)
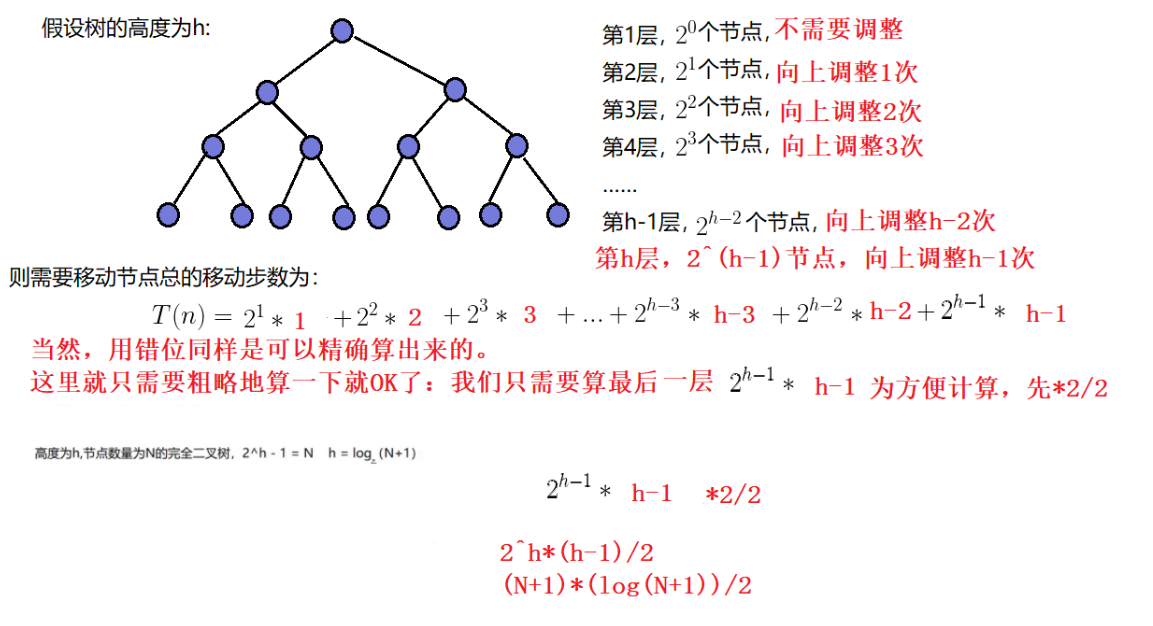
2.向下调整建堆(推荐使用)
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void AdjustDown(int* a, int n, int parent) //向下调整
{int minChild = parent * 2 + 1;while (minChild < n){if (minChild + 1 < n && a[minChild + 1] > a[minChild]) //这里控制大小堆{minChild++;}if (a[minChild] > a[parent]) //这里控制大小堆{Swap(&a[minChild], &a[parent]);parent = minChild;minChild = parent * 2 + 1;}else{break;}}}
void HeapSort(int* a, int n)
{for (int i = (n - 1-1) / 2; i >= 0; --i){AdjustDown(a, n, i);}
}int main()
{int a[] = { 1,10,2,20,3,30,4,40,5,50 };HeapSort(a, sizeof(a) / sizeof(int));for (int i = 0; i < sizeof(a) / sizeof(int); ++i){printf("%d ", a[i]);}return 0;
}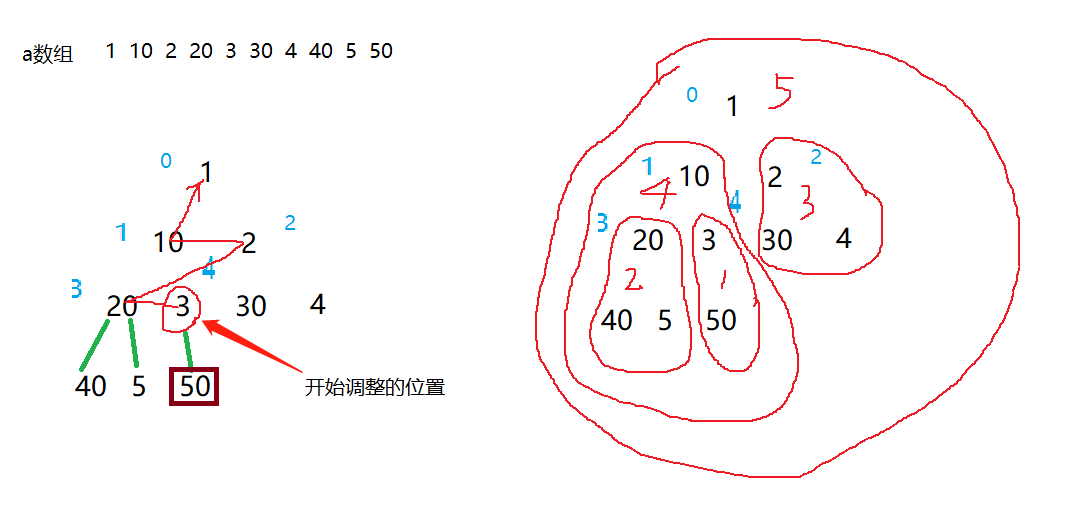
向下调整的开始的位置是最后一个元素的父节点位置,因为最后一行的元素本来就符合大堆或者小堆的性质所以不用调整,根据数组的最后一个元素的下标计算出该节点的父节点的数组下标,从这个父节点开始向下调整,调整完后再将父节点的数组下标--,再从这个节点开始向下调整,直到调整完根节点后调整结束,堆就建立好了,大小堆是根据向下调整函数里的比较决定的。时间复杂度推导如下O(N):
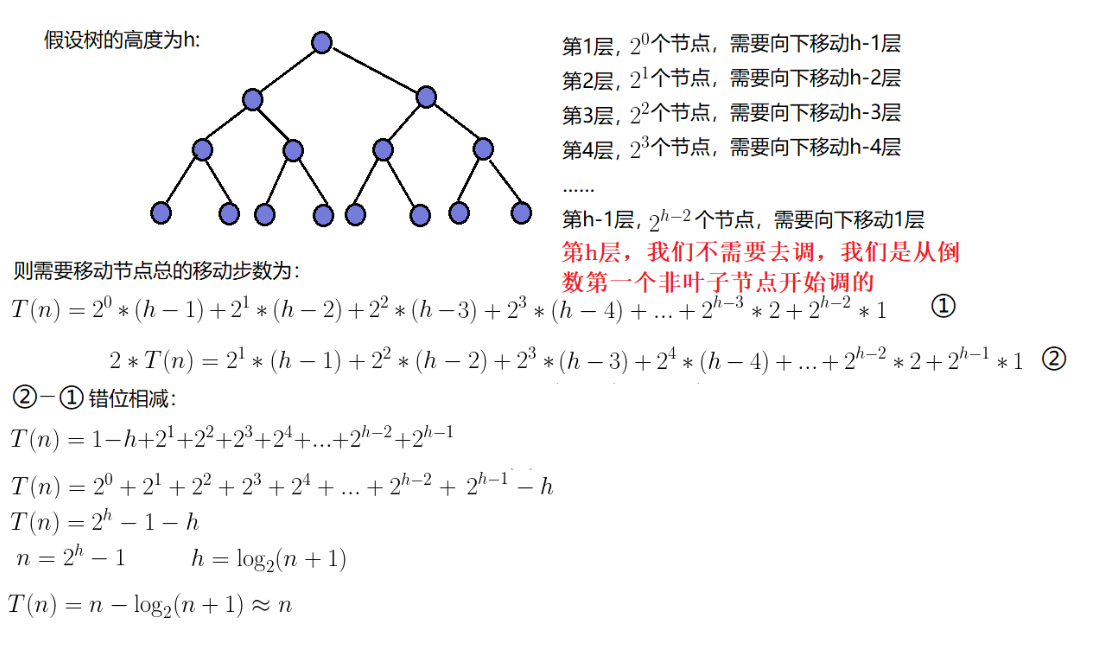
因为向下调整的时间复杂度低于向上调整的时间复杂度,所以推荐使用的是向下调整建堆。
2.选数
了解完以后,我们来实现堆排序:
void AdjustDown(HPDataType* a, int n, int parent)
{//最小的默认为左孩子int minchild = 2 * parent + 1;while (minchild <n){//找出小的那个孩子if (minchild+1<n&&a[minchild+1] < a[minchild]){minchild++;}//小堆if (a[minchild] < a[parent]){Swap(&a[minchild], &a[parent]);parent = minchild;minchild = 2 * parent + 1;}else{break;}}
}void HeapSort(int* a, int n)
{for (int i = (n-1-1)/2; i>=0; i--){AdjustDown(a, n, i);}//选数int i = 1;while (i < n){Swap(&a[0], &a[n - i]);AdjustDown(a, n - i, 0);i++;}}int main()
{int a[] = { 15,1,19,25,8,34,65,4,27,7 };HeapSort(a, sizeof(a) / sizeof(int));for (int i = 0; i < sizeof(a) / sizeof(int); i++){printf("%d ", a[i]);}printf("\n");return 0;
}
这里的思路就是先对数组进行向下调整建堆,如果要升序就建立大堆,将根节点位置的元素和最后一个元素交换位置使得最大的元素放到了数组的最后边,放到后边的元素不参与向下调整(通过传参控制),然后让被换到根节点的元素向下调整,回到符合堆的性质的位置,此时调整完成后次大的元素被调整到了根节点的位置,再让根节点的元素和倒数第二个元素交换,交换到后边的元素不参与向下调整,再次进行向下调整,直到i=n时结束调整,此时输出数组就是升序的。如果要降序那就建立小堆。
总结一句话:
升序--建大堆,降序--建小堆
3.TOP-K问题
如何从数组中找到前K个大或者前K个小的数?
错误的思维:
选前K个大的数建立的是大堆,那最大的元素就在最上方,我们拿走了最大的元素,那剩下的元素堆的关系全乱了,又得重新排序,再选出最大的元素,这样一来假设要从特别大的一堆数据中进行选数那代价就非常大了,效率变得很低。同理选小数不能建小堆。
正确方法:
用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
代码实现:
#include<stdlib.h>
#include<stdio.h>void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void AdjustDown(int* a, int n, int parent) //向下调整
{int minChild = parent * 2 + 1;while (minChild < n){if (minChild + 1 < n && a[minChild + 1] < a[minChild]){minChild++;}if (a[minChild] < a[parent]){Swap(&a[minChild], &a[parent]);parent = minChild;minChild = parent * 2 + 1;}else{break;}}}
void Topk(int* a, int k,int n)
{int* minheap = (int*)malloc(k * sizeof(int));if (minheap == NULL){perror("malloc fail!");exit(-1);}for (int i = 0; i < k; i++){minheap[i] = a[i];}for (int j = (k - 2) / 2; j >= 0; --j){AdjustDown(minheap, k, j); //向下调整建小堆因为选的是前K大的数 ---如果选小数就建大堆}int k1 = k;//遍历k后的元素交换然后调整while (k <n){if (a[k] > minheap[0]){minheap[0] = a[k];AdjustDown(minheap, k, 0);}++k;}for (int i = 0; i < k1; ++i){printf("%d ", minheap[i]);}}
int main()
{int a[] = { 1,10,2,20,3,30,4,40,5,50 };int k = 5; //选出前5个大的数int n = sizeof(a) / sizeof(int); //数组元素个数Topk(a, k,n);return 0;
}
相关文章:
【数据结构】堆排序
堆是一种叫做完全二叉树的数据结构,可以分为大根堆,小根堆,而堆排序就是基于这种结构而产生的一种程序算法。大堆:每个节点的值都大于或者等于他的左右孩子节点的值小堆:每个结点的值都小于或等于其左孩子和右孩子结点…...
论文阅读笔记《GAMnet: Robust Feature Matching via Graph Adversarial-Matching Network》
核心思想 本文提出一种基于图对抗神经网络的图匹配算法(GAMnet),使用图神经网络作为生成器分别生成源图和目标图的节点的特征,并用一个多层感知机作为辨别器来区分两个特征是否来自同一个图,通过对抗训练的办法提高生成器特征提取…...

数据安全—数据完整性校验
1、数据安全保障三要素即 保密性 完整性、可用性机密性:要求数据不被他人轻易获取,需要进行数据加密。完整性:要求数据不被他人随意修改,需要进行签名技术可用性:要求服务不被他人恶意攻击,需要进行数据校验…...
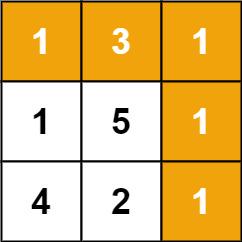
Java 最小路径和
最小路径和中等给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。说明:每次只能向下或者向右移动一步。示例 1:输入:grid [[1,3,1],[1,5,1],[4,2,1]]输出&…...
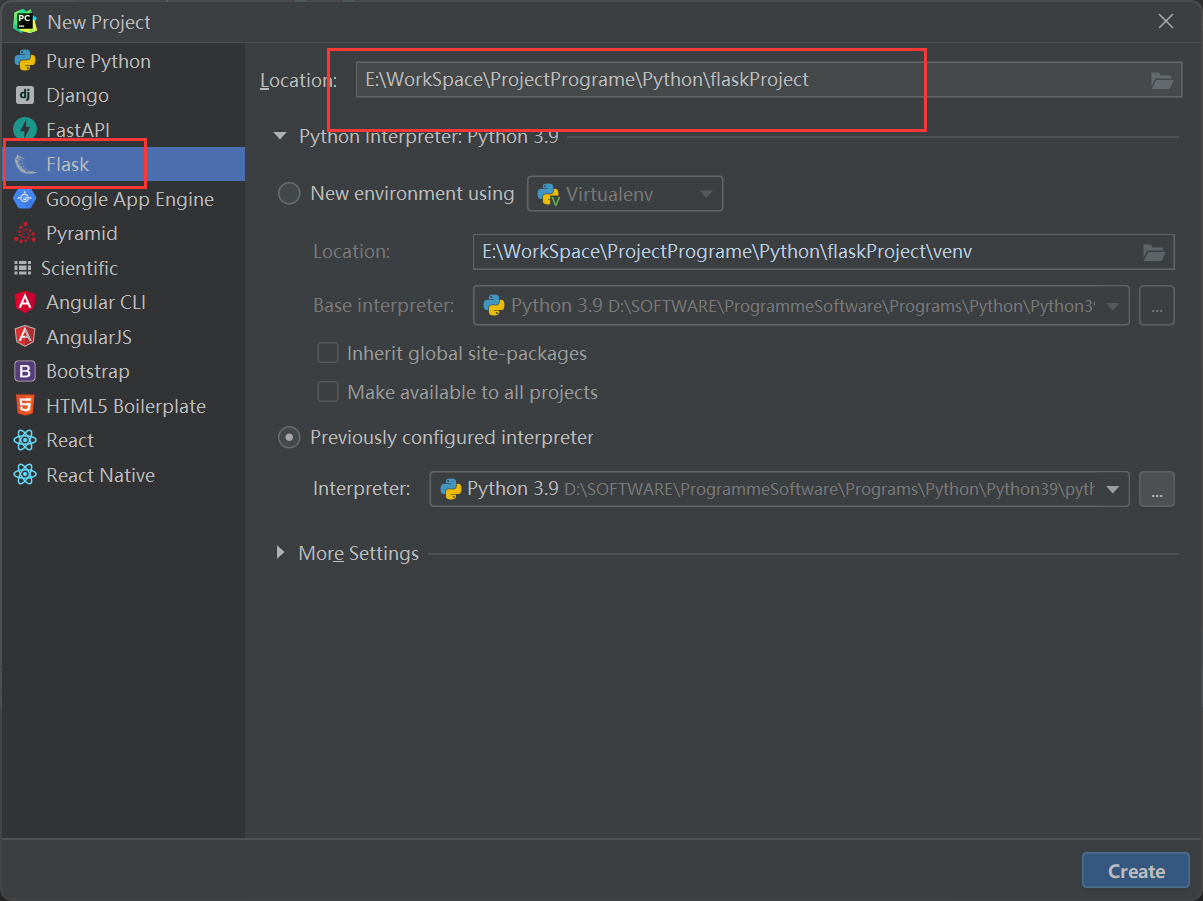
Flask+VUE前后端分离的登入注册系统实现
首先Pycharm创建一个Flask项目: Flask连接数据库需要下载的包: pip install -U flask-cors pip install flask-sqlalchemy Flask 连接和操作Mysql数据库 - 王滚滚啊 - 博客园 (cnblogs.com) sqlAlchemy基本使用 - 简书 (jianshu.com) FlaskVue前后端分…...
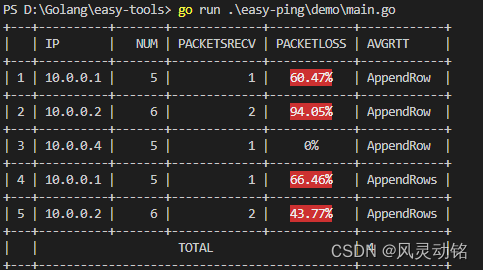
【Go】用Go在命令行输出好看的表格
用Go在命令行输出好看的表格前言正文生成Table表头设置插入行表格标题自动标号单元格合并列合并行合并样式设置居中设置数字自动高亮标红完整Demo代码结语前言 最近在写一些运维小工具,比如批量进行ping包的工具,实现不困难,反正就是ping&am…...

怎么处理消息重发的问题?
消息队列在消息传递的过程中,如果出现传递失败的情况,发送方会重试,在重试的过程中,可能会产生重复的消息。 消息重复的情况必然存在 关于传递消息时能够提供的服务质量标准,MQTT协议给出了三种不同的标准࿱…...
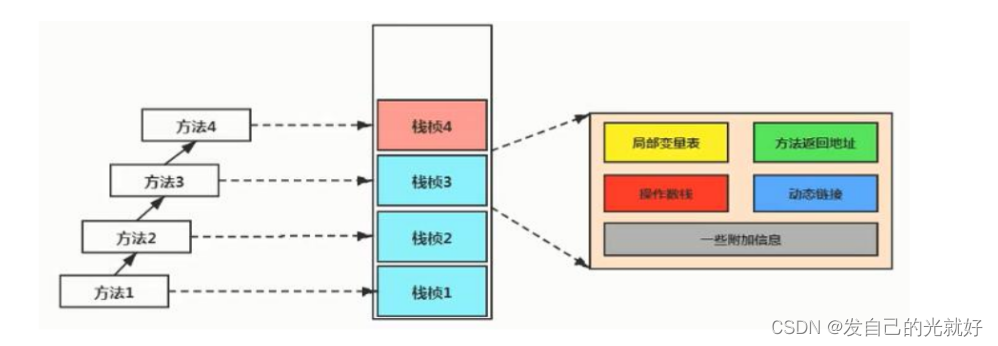
JVM 运行时数据区(数据区组成表述,程序计数器,java虚拟机栈,本地方法栈)
JVM 运行时数据区JVM 运行时数据区3.1运行时的数据区组成概述3.1.1程度计数器3.1.2java虚拟机栈3.1.3本地方法栈3.1.4java堆3.1.5方法区3.2程序计数器3.3java虚拟机栈3.4本地方法栈JVM 运行时数据区 堆,方法区(元空间) 主要用来存放数据 是线程共享的. 程序计数器,本地方法栈…...

Oracle ASM磁盘组配置、日常运维、故障处理等操作资料汇总
ASM(自动存储管理)在数据库中是非常重要的组成部分,它可以为磁盘提供统一的存储管理、提高磁盘访问的性能和可用性、简化管理复杂度,从而为数据库的运行提供更好的支持。这里就为大家整理了墨天轮数据社区上一些ASM相关基础知识、…...
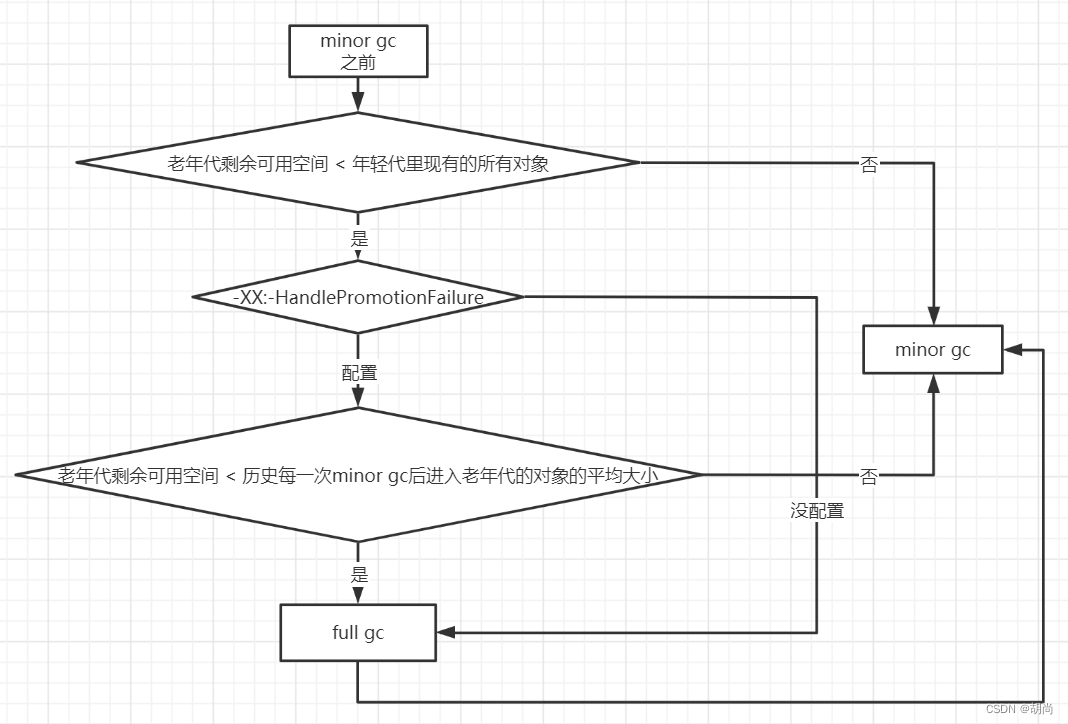
java对象的创建与内存分配机制
文章目录对象的创建与内存分配机制对象的创建类加载检查分配内存初始化零值设置对象头指向init方法其他:指针压缩对象内存分配对象在栈上分配对象在Eden区中分配大对象直接分配到老年代长期存活的对象进入老年代对象动态年龄判断老年代空间分配担保机制对象的内存回…...
本地存储localStorage、sessionStorage
目录 一、localStorage 二、sessionStorage 三、本地存储处理复杂数据 一、localStorage 介绍 (1)数据存储在用户浏览器中 (2)设置、读取方便、甚至页面刷新不会丢失数据 (3)容量较大,se…...

JavaSE: 网络编程
1.1 概述java程序员面对统一的网络编程环境B/S 架构 和 C/S架构1.2 网络通信的两个要素通信双方的地址:ip 端口号网络通信协议:TCP/IP协议(事实上的国际规则)、OSI模型(理想化)1.3 Inet Address本地回环地…...

计算机图形学09:二维观察之点的裁剪
作者:非妃是公主 专栏:《计算机图形学》 博客地址:https://blog.csdn.net/myf_666 个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩 文章目录专栏推荐专栏系列文章序一、二维观察基本…...

2023Java 并发编程面试题
Java 并发编程 1、在 java 中守护线程和本地线程区别? java 中的线程分为两种:守护线程(Daemon)和用户线程(User)。任何线程都可以设置为守护线程和用户线程,通过方法Thread.setDaemon(boolon…...
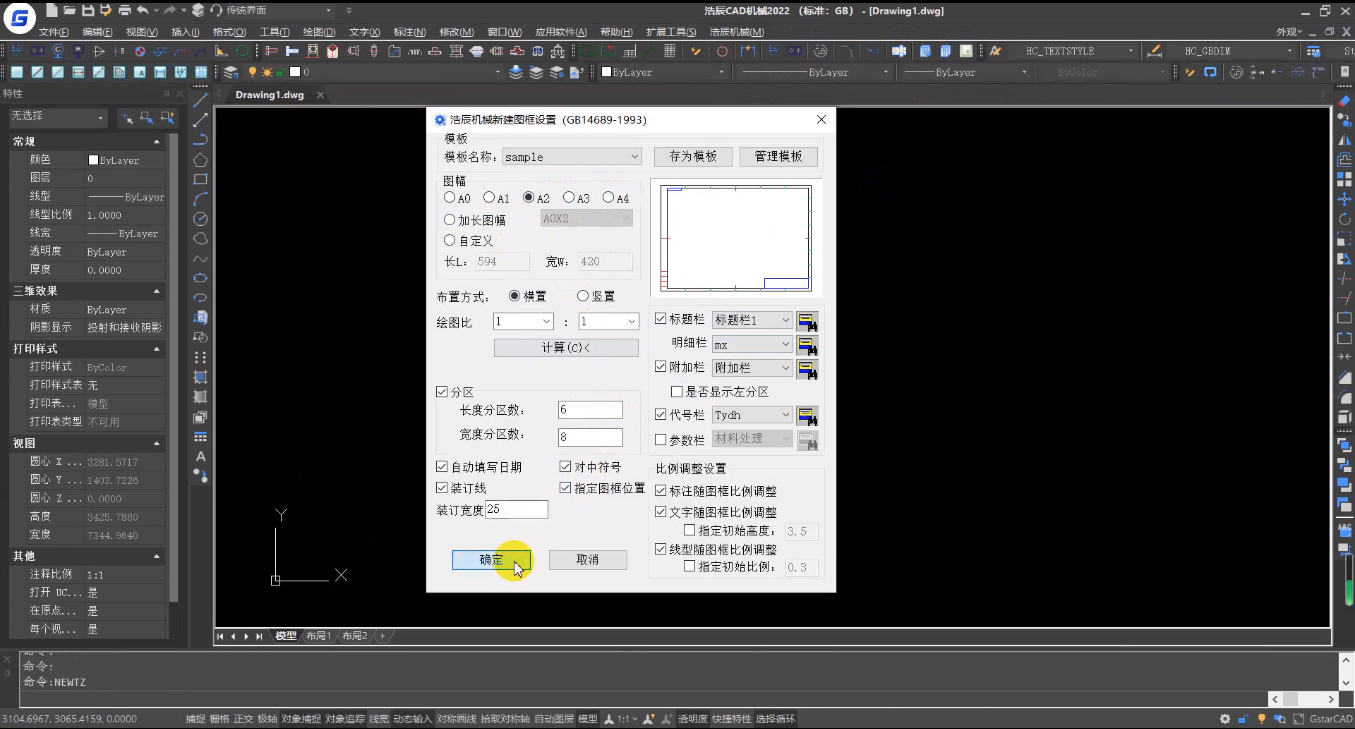
CAD如何绘制A0/A1/A2/A3/A4图框?
在CAD制图时,设计师一般会使用企业的定制图框模板或者个人的特色图框模板,让设计方案更加标准化、规范化。对于新人设计师而言,完成CAD制图已经非常头疼了,图框的绘制更是手忙脚乱。那么是否有更加高效的方式来完成A0、A1、A2、A3…...

R 安装 “umap-learn“ python 包
首先需要在R中下载并读取reticulate包,该包提供了一系列R-Python的交互式命令由于之前在电脑中通过三个方式安装了Python:直接安装 Python 3.10安装Anaconda,携带3.9安装 Miniconda,又是另外一个版本的Python版本各不相同…...

测试同学如何快速开发测试平台?
转眼已经好几个月没有发表什么文章了,因为疫情原因,大家工作都不怎么顺利,没有什么心情。再者,最近一直在搞移动端精准测试的项目,有太多技术难点需要攻克。从各个网站上都找不到解决方案,只能不断地尝试&a…...

【程序员接口百宝箱】免费常用API接口
一、短信发送 短信的应用可以说是非常的广泛了,短信API也是当下非常热门的API~ 短信验证码:可用于登录、注册、找回密码、支付认证等等应用场景。支持三大运营商,3秒可达,99.99%到达率,支持大容量高并发。…...

使数组和能被P整除[同余定理+同余定理变形]
同余定理同余定理变形前言一、使数组和能被P整除二、同余定理变形总结参考资料前言 同余定理非常经典,采用前缀和 map,当两个余数前缀和为一个值时,则中间一段子数组刚好对P整除。但是能否找到前面是否有一段子数组和可以对P整除呐…...

25k的Java开发常问的Synchronized问题有哪些?
前言:面试高频的Synchronized问题大多集中在应用场景、底层实现原理、锁的升级过程。 文章目录 Synchronized定义应用场景对象加锁实现原理JDK6以前JDK6版本及以后对象从无锁到偏向锁转化的过程(大概讲五分钟)轻量级锁升级的过程(大概讲五分钟)自旋锁策略(大概讲五分钟)…...

从像素到对象:如何用HANet和SNUNet搞定遥感影像中的‘小目标’与‘不平衡’难题?
从像素到对象:HANet与SNUNet在遥感影像小目标检测中的实战解析 当洪水退去后的灾损评估卫星图上,那些被冲毁的农舍屋顶往往只占据几个像素;在城市违建监测中,新增的违章建筑可能只是高分辨率影像中的微小色块。这些"小目标&q…...

技术小白也能懂:拆解一个chinahrt自动刷课油猴脚本的代码逻辑与实现原理
技术小白也能懂:拆解一个自动刷课油猴脚本的代码逻辑与实现原理 在数字化学习时代,许多在线教育平台要求用户完成指定课程才能获得相应证书或学分。对于时间紧张的学习者来说,手动完成所有课程视频观看可能成为负担。本文将从一个具体案例出…...

AppleRa1n:解锁iOS设备激活锁的专业指南与安全实践
AppleRa1n:解锁iOS设备激活锁的专业指南与安全实践 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 当您面对一台被激活锁困住的iPhone或iPad时,那种无助感就像是拥有一把无法打…...

基于深度学习的桥梁健康状态监测与预警系统设计与实现
基于深度学习的桥梁健康状态监测与预警系统设计与实现 1. 系统总体架构 本系统采用 B/S 架构,由数据采集层、数据处理层、深度学习模型层、Web后端层及前端可视化层组成。 后端框架:Django (负责ORM、API、用户认证) 深度学习:TensorFlow 2.x / Keras (构建LSTM-Autoencod…...

【day63】
以前有个孩子,他分分钟都在碎碎念。不过,他的念头之间是有因果关系的。他会在本子里记录每一个念头,并用箭头画出这个念头的来源于之前的哪一个念头。翻开这个本子,你一定会被互相穿梭的箭头给搅晕,现在他希望你用程序…...

MAXON阀150SMA12-FA22-CC2380
MAXON 150SMA12-FA22-CC2380 是一款工业燃烧控制领域的高品质燃气电磁阀。以下是对该型号的详细解析与关键参数: 1. 型号拆解 该型号遵循 MAXON(麦克森,现属 Honeywell 过程解决方案)的命名规则: 150:阀体…...

一篇关于论文复现的思考:基于领域相似度的复杂网络节点重要度评估算法
论文复现—基于领域相似度的复杂网络节点重要度评估算法 编写程序代码matlab 复现算法仿真最近在学习复杂网络的相关算法,看到一篇挺有意思的论文,讲的是基于领域相似度的节点重要度评估方法。说实话,这类算法听起来有点抽象,但…...

Zephyr RTOS 线程实战:从信号量到消息队列,手把手教你搞定多任务通信
Zephyr RTOS线程通信实战:信号量与消息队列的深度应用指南 在嵌入式开发领域,多任务间的有效通信是构建可靠系统的关键所在。想象这样一个场景:你的物联网设备需要同时处理传感器数据采集、实时数据处理、无线通信传输等多个任务,…...

java毕业设计基于SpringBoot酒店预定系统
前言 Spring Boot酒店预定系统是一种功能丰富、易于维护和扩展的在线预订平台。它通过整合前后端技术,实现了酒店信息的在线展示、预订、支付以及管理等一系列功能,为用户和酒店提供了便捷、高效的预订服务。随着旅游业和酒店业的不断发展,该…...

通义千问3-Reranker-0.6B模型架构深度解析
通义千问3-Reranker-0.6B模型架构深度解析 1. 引言 在当今AI技术飞速发展的时代,文本重排序模型作为信息检索和RAG系统的核心组件,正发挥着越来越重要的作用。通义千问3-Reranker-0.6B作为一款轻量级但性能卓越的重排序模型,以其精巧的架构…...