CentOS 7 安装部署Cassandra4.1.5
一、Cassandra的介绍
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身Facebook于2008将 Cassandra 开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
Cassandra的官网:Apache Cassandra | Apache Cassandra Documentation
Cassandra特点
-
弹性可扩展性 - Cassandra是高度可扩展的; 它允许添加更多的硬件以适应更多的客户和更多的数据根据要求。
- 始终基于架构 - Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序。
- 快速线性性能 - Cassandra是线性可扩展性的,即它为你增加集群中的节点数量增加你的吞吐量。因此,保持一个快速的响应时间。
- 灵活的数据存储 - Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。它可以根据您的需要动态地适应变化的数据结构。
- 便捷的数据分发 - Cassandra通过在多个数据中心之间复制数据,可以灵活地在需要时分发数据。
- 事务支持 - Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。
- 快速写入 - Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
二、Cassandra下载、安装、访问

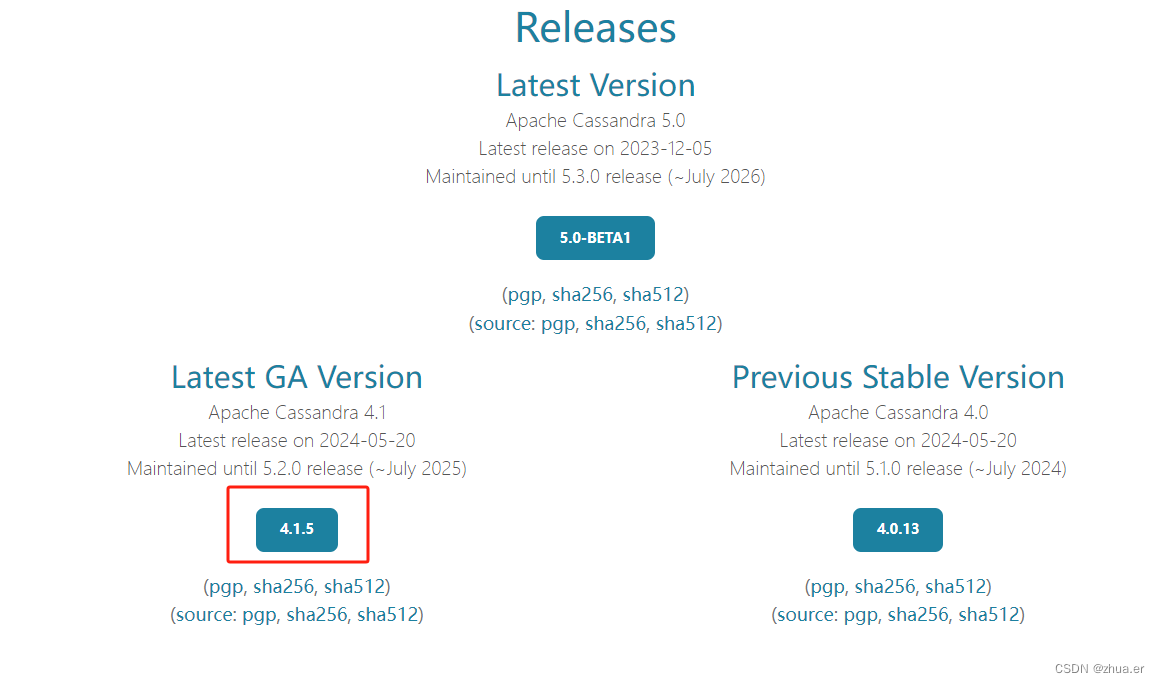
进入下载页后,选择最新稳定版本4.1.5
三、Cassandra 安装部署
1、安装准备
注意:Cassandra 使用 JAVA 语言开发,首先保证当前机器中已经安装 JDK 11 or JDK 8
# 安装JDK 11 # yum install java-11-openjdk -y# java -version
注意:Cassandra的客户端的使用需要用的Python3版本。需要先安装Python3
# 安装python3 # yum install python3 -y# python3 -V
2、部署Cassandra
# 解压
# tar -zxvf apache-cassandra-4.1.5-bin.tar.gz# 重命名
# mv apache-cassandra-4.1.5 apache-cassandra
配置 Cassandra
进入解压后的目录,创建3个 Cassandra 的数据文件夹
# mkdir data
# mkdir commitlog
# mkdir saved-caches
修改配置文件
在 conf 目录中找到 cassandra.yaml 配置文件,配置上面创建的3个数据目录
- 配置 data_file_directories
data_file_directories:- /home/Cassandra/apache-cassandra/data- 配置 commitlog_directory
commitlog_directory: /home/Cassandra/apache-cassandra/commitlog- 配置 saved_caches_directory
saved_caches_directory: /home/Cassandra/apache-cassandra/saved_caches- 配置 RPC,用于客户端连接
rpc_address: 192.168.204.1313、启动 Cassandra
[root@localhost apache-cassandra]# pwd
/home/Cassandra/apache-cassandra
[root@localhost apache-cassandra]# ./bin/cassandra -R输入命令来查看正在运行的cassandra的 pid
ps -ef|grep cassandra显示如图,pid 是 11733:

4、关闭Cassandra
刚才已经查到了 pid,现在可以使用命令杀掉这个pid对应的进程
kill -9 117335、查看状态
[root@localhost apache-cassandra]# ./bin/nodetool status
如果cassandra启动出错,可以在bin目录下 使用 journalctl -u cassandra 命令查看
[root@localhost apache-cassandra]# cd bin
[root@localhost bin]# journalctl -u cassandra# 问题
[root@localhost bin]# ./nodetool status
nodetool: Failed to connect to '127.0.0.1:7199' - URISyntaxException: 'Malformed IPv6 address at index 7: rmi://[127.0.0.1]:7199'.# 解决办法
[root@localhost bin]# ./nodetool -Dcom.sun.jndi.rmiURLParsing=legacy status
[root@localhost bin]# ./nodetool -h ::FFFF:127.0.0.1 status6、客户端连接服务器
进入Cassandra的目录,输入
[root@localhost apache-cassandra]# ./bin/cqlsh 192.168.204.131 9042
Connected to Test Cluster at 192.168.204.131:9042
[cqlsh 6.1.0 | Cassandra 4.1.5 | CQL spec 3.4.6 | Native protocol v5]
Use HELP for help.
cqlsh>上面的操作在启动cqlsh的时候并没有指定需要连接的节点以及端口,默认 cqlsh 会自动探测本机及端口。上面的操作时已经启动了 Cassandra 服务并绑定相关端口,注:【 端口列表】,cqlsh默认就会连接本机的9042端口。
从上面的命令可以看出 cqlsh 连接到名为 Test Cluster 的集群,这个名字是默认值,可以自定义,配置在 conf/cassandra.yaml 文件的 cluster_name 参数,注:【yaml全内容】
输入quit退出客户端
Cassandra的端口
7199 - JMX 7000 - 节点间通信(如果启用了TLS,则不使用) 7001 - TLS节点间通信(使用TLS时使用) 9160 - Thrift客户端API 9042 - CQL本地传输端口
7、服务运行脚本
为了方便管理,可以编写脚本来管理,在 /home/Cassandra/apache-cassandra 下创建一个 startme.sh,输入一下内容:
#!/bin/sh
CASSANDRA_DIR="/home/Cassandra/apache-cassandra"echo "************cassandra***************"
case "$1" instart)echo "* *"echo "* starting *"nohup $CASSANDRA_DIR/bin/cassandra -R >> $CASSANDRA_DIR/logs/system.log 2>&1 &echo "* started *"echo "* *"echo "************************************";;stop)echo "* *"echo "* stopping *"PID_COUNT=`ps aux |grep CassandraDaemon |grep -v grep | wc -l`PID=`ps aux |grep CassandraDaemon |grep -v grep | awk {'print $2'}`if [ $PID_COUNT -gt 0 ];thenecho "* try stop *"kill -9 $PIDecho "* kill SUCCESS! *"elseecho "* there is no ! *"echo "* *"echo "************************************"fi;;restart)echo "* *"echo "********* restarting ******"$0 stop$0 startecho "* *"echo "************************************";;status)$CASSANDRA_DIR/bin/nodetool status;;*)echo "Usage:$0 {start|stop|restart|status}"exit 1
esac接下来就可以使用这个脚本进行 启动,重启,关闭 的操作
[root@localhost apache-cassandra]# sh startme.sh start
[root@localhost apache-cassandra]# sh startme.sh restart
[root@localhost apache-cassandra]# sh startme.sh stop四、Cassandra根据用户名密码登录cqlsh
修改conf目录下cassandra.yaml文件
authenticator: PasswordAuthenticator //将authenticator修改为PasswordAuthenticator 重新启动cassandra并且根据默认用户登录cqlsh,用户名密码都是cassandra
[root@localhost apache-cassandra]# ./bin/cqlsh 192.168.204.131 9042 -ucassandra -pcassandraWarning: Using a password on the command line interface can be insecure.
Recommendation: use the credentials file to securely provide the password.Connected to Test Cluster at 192.168.204.131:9042
[cqlsh 6.1.0 | Cassandra 4.1.5 | CQL spec 3.4.6 | Native protocol v5]
Use HELP for help.
cassandra@cqlsh> 如果要修改默认用户,进入cqlsh后
#超级用户可以更改用户的密码或超级用户身份。为了防止禁用所有超级,超级用户不能改变自己的超级用户身份。普通用户只能改变自己的密码。附上用户名在单引号如果它包含非字母数字字符。附上密码在单引号。
CREATE USER test WITH PASSWORD '123456' SUPERUSER; //创建一个超级用户
CREATE USER test1 WITH PASSWORD '123456' NOSUPERUSER; //创建一个普通用户
ALTER USER test WITH PASSWORD '654321' ( NOSUPERUSER | SUPERUSER ) //修改用户
DROP USER cassandra //删除默认用户五、Cassandra的基本概念
1、数据模型
1.1列(Column)
列是Cassandra的基本数据结构单元,具有三个值:名称,值、时间戳

在Cassandra中不需要预先定义列(Column),只需要在KeySpace里定义列族,然后就可以开始写数据了。
1.2列族( Column Family)
列族相当于关系数据库的表(Table),是包含了多行(Row)的容器。
1.3建空间 (KeySpace)
Cassandra的键空间(KeySpace)相当于数据库,我们创建一个键空间就是创建了一个数据库。
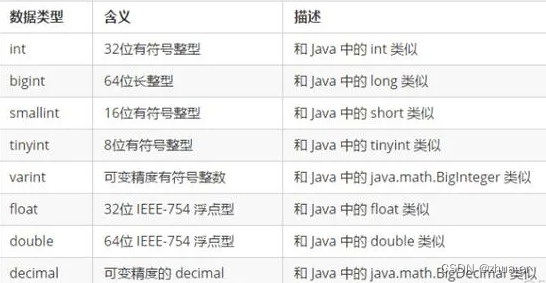
2、数据类型
2.1数值类型
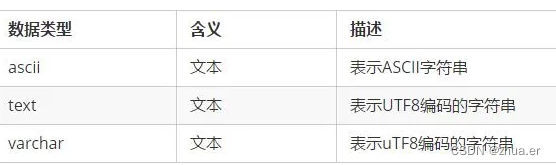
2.2文本类型
CQL提供2种类型存放文本类型,text和varchar基本一致
2.3时间类型
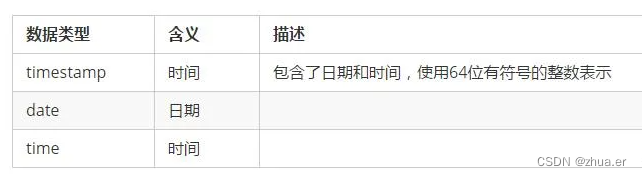
2.4标识符类型

2.5集合类型
set
集合数据类型,set 里面的元素存储是无序的。
set 里面可以存储前面介绍的数据类型,也可以是用户自定义数据类型,甚至是其他集合类型。
list
list 包含了有序的列表数据,默认情况下,数据是按照插入顺序保存的。
map
map 数据类型包含了 key/value 键值对。key 和 value 可以是任何类型,除了 counter 类型
使用集合类型要注意: 1、集合的每一项最大是64K。 2、保持集合内的数据不要太大,免得Cassandra 查询延时过长,Cassandra 查询时会读出整个集合内的数据,集合在内部不会进行分页,集合的目的是存储小量数据。 3、不要向集合插入大于64K的数据,否则只有查询到前64K数据,其它部分会丢失。
2.6其他基本类型

3、数据定义命令
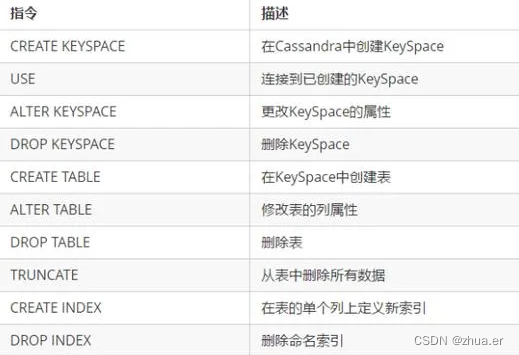
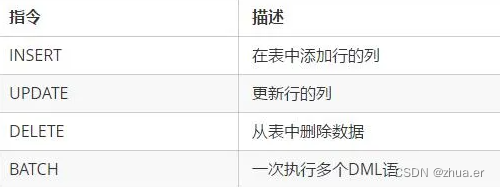
4、数据操作指令
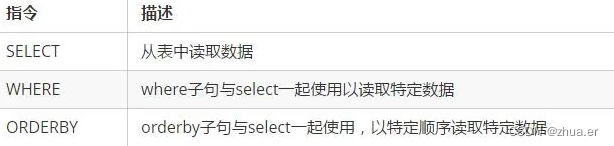
5、查询指令
六、Cassandra的基本操作
1、操作键空间
1.1创建Keyspace
语法
CREATE KEYSPACE <identifier> WITH <properties>;更具体的语法:
Create keyspace KeyspaceName with replicaton={'class':strategy name,
'replication_factor': No of replications on different nodes};要填写的内容:
KeyspaceName 代表键空间的名字
strategy name 代表副本放置策略,内容包括:简单策略、网络拓扑策略,选择其中的一个。
No of replications on different nodes 代表 复制因子,放置在不同节点上的数据的副本数。
编写完成的创建语句 创建一个键空间名字为:school,副本策略选择:简单策略 SimpleStrategy,副本因子:3
CREATE KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};1.2连接Keyspace
语法
USE <identifier>;1.3修改键空间
语法
ALTER KEYSPACE <identifier> WITH <properties>1.4删除键空间
语法
DROP KEYSPACE <identifier>2、操作表、索引
2.1查看键空间下所有表 代码
DESCRIBE TABLES;2.2创建表
语法
CREATE (TABLE | COLUMNFAMILY) <tablename> ('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)完整创建表语句,创建student 表,student包含属性如下: 学生编号(id), 姓名(name),年龄(age),性别(gender),家庭地址(address),interest(兴趣),phone(电话号码),education(教育经历) id 为主键,并且为每个Column选择对应的数据类型。 注意:interest 的数据类型是set ,phone的数据类型是list,education 的数据类型是map
CREATE TABLE student(id int PRIMARY KEY, name text, age int, gender tinyint, address text ,interest set<text>,phone list<text>,education map<text, text>
);2.3cassandra的索引(KEY)
Cassandra的5种Key
- Primary Key
- Partition Key
- Composite Key
- Compound Key
- Clustering Key
1)Primary Key
是用来获取某一行的数据, 可以是单一列(Single column Primary Key)或者多列(Composite Primary Key)。
在 Single column Primary Key 决定这一条记录放在哪个节点。create table testTab (
id int PRIMARY KEY,
name text
);2)Composite Primary Key
如果 Primary Key 由多列组成,那么这种情况称为 Compound Primary Key 或 Composite Primary Key。
create table testTab (
key_one int,
key_two int,
name text,
PRIMARY KEY(key_one, key_two)
);3)Partition Key
在组合主键的情况下(上面的例子),第一部分称作Partition Key(key_one就是partition key),第二部分是CLUSTERING KEY(key_two)
Cassandra会对Partition key 做一个hash计算,并自己决定将这一条记录放在哪个节点。
如果 Partition key 由多个字段组成,称之为 Composite Partition key
create table testTab (
key_part_one int,
key_part_two int,
key_clust_one int,
key_clust_two int,
key_clust_three uuid,
name text,
PRIMARY KEY((key_part_one,key_part_two), key_clust_one, key_clust_two, key_clust_three)
);4)Clustering Key
决定同一个分区内相同 Partition Key 数据的排序,默认为升序,可以在建表语句里面手动设置排序的方式
2.4修改表结构
添加列,语法
ALTER TABLE table name ADD new column datatype;删除列,语法
ALTER table name DROP columnname;
2.5删除表
语法
DROP TABLE <tablename>2.6清空表
语法
TRUNCATE <tablename>2.7创建索引
普通列创建索引
CREATE INDEX <identifier> ON <tablename>集合列创建索引
CREATE INDEX ON student(interest); -- set集合添加索引
CREATE INDEX mymap ON student(KEYS(education)); -- map结合添加索引效果:2.8 删除索引
语法
DROP INDEX <identifier>3、查询数据
使用 SELECT 、WHERE、LIKE、GROUP BY 、ORDER BY等关键词
SELECT FROM <tablename>
SELECT FROM <table name> WHERE <condition>;
查询时使用索引
- Primary Key 只能用 = 号查询
- 第二主键 支持= > < >= <=
- 索引列 只支持 = 号
- 非索引非主键字段过滤可以使用ALLOW FILTERING
ALLOW FILTERING是一种非常消耗计算机资源的查询方式。 如果表包含例如100万行,并且其中95%具有满足查询条件的值,则查询仍然相对有效,这时应该使用ALLOW FILTERING。
如果表包含100万行,并且只有2行包含满足查询条件值,则查询效率极低。Cassandra将无需加载999,998行。如果经常使用查询,则最好在列上添加索引。
ALLOW FILTERING在表数据量小的时候没有什么问题,但是数据量过大就会使查询变得缓慢。
查询时排序
cassandra也是支持排序的,order by。 排序也是有条件的
- 必须有第一主键的=号查询,cassandra的第一主键是决定记录分布在哪台机器上,cassandra只支持单台机器上的记录排序。
- 只能根据第二、三、四…主键进行有序的,相同的排序。
- 不能有索引查询,cassandra的任何查询,最后的结果都是有序的,内部就是这样存储的。
分页查询
使用limit 关键字来限制查询结果的条数 进行分页
4、添加数据
语法
INSERT INTO <tablename>(<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option>5、更新列数据
更新表中的数据,可用关键字:
- Where - 选择要更新的行
- Set - 设置要更新的值
- Must - 包括组成主键的所有列
在更新行时,如果给定行不可用,则UPDATE创建一个新行
语法
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>更新简单数据
把student_id = 1012 的数据的gender列 的值改为1,代码:UPDATE student set gender = 1 where student_id= 1012;更新set类型数据
在student中interest列是set类型1)添加一个元素
使用UPDATE命令 和 ‘+’ 操作符代码:
UPDATE student SET interest = interest + {'游戏'} WHERE student_id = 1012;2)删除一个元素
使用UPDATE命令 和 ‘-’ 操作符代码:
UPDATE student SET interest = interest - {'电影'} WHERE student_id = 1012;3)删除所有元素
可以使用UPDATA或DELETE命令,效果一样代码:
UPDATE student SET interest = {} WHERE student_id = 1012;
或
DELETE interest FROM student WHERE student_id = 1012;更新list类型数据
使用UPDATA命令向list插入值
代码:
UPDATE student SET phone = ['020-66666666', '13666666666'] WHERE student_id = 1012;在list前面插入值
代码:
UPDATE student SET phone = [ '030-55555555' ] + phone WHERE student_id = 1012;在list后面插入值
代码:
UPDATE student SET phone = phone + [ '040-33333333' ] WHERE student_id = 1012;使用列表索引设置值,覆盖已经存在的值
这种操作会读入整个list,效率比上面2种方式差现在把phone中下标为2的数据,也就是 “13666666666”替换,代码:
UPDATE student SET phone[2] = '050-22222222' WHERE student_id = 1012;【不推荐】使用DELETE命令和索引删除某个特定位置的值
非线程安全的,如果在操作时其它线程在前面添加了一个元素,会导致移除错误的元素代码:
DELETE phone[2] FROM student WHERE student_id = 1012;【推荐】使用UPDATE命令和‘-’移除list中所有的特定值
代码:
UPDATE student SET phone = phone - ['020-66666666'] WHERE student_id = 1012;更新map类型数据
map输出顺序取决于map类型。1)使用Insert或Update命令
UPDATE student SET education={'中学': '城市第五中学', '小学': '城市第五小学'} WHERE student_id = 1012;2)使用UPDATE命令设置指定元素的value
UPDATE student SET education['中学'] = '爱民中学' WHERE student_id = 1012;3)可以使用如下语法增加map元素。如果key已存在,value会被覆盖,不存在则插入
UPDATE student SET education = education + { '幼儿园' : '大海幼儿园', '中学': '科技路中学'} WHERE student_id = 1012;4)删除元素
可以用DELETE 和 UPDATE 删除Map类型中的数据使用DELETE删除数据
DELETE education['幼儿园'] FROM student WHERE student_id = 1012;使用UPDATE删除数据
UPDATE student SET education=education - {'中学','小学'} WHERE student_id = 1012;6、删除行
语法
DELETE FROM <identifier> WHERE <condition>;7、批量操作
把多次更新操作合并为一次请求,减少客户端和服务端的网络交互。 batch中同一个partition key的操作具有隔离性
语法使用BATCH,您可以同时执行多个修改语句(插入,更新,删除)BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCH相关文章:
CentOS 7 安装部署Cassandra4.1.5
一、Cassandra的介绍 Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身Facebook于2008将 Cassandra 开源,此后࿰…...

【数据结构与算法】对称矩阵,三角矩阵 详解
给出对称矩阵、三角矩阵的节省内存的存贮结构并写出相应的输入、输出算法。 对称矩阵和三角矩阵可以通过特殊的存储结构来节省内存。这种存储结构只存储矩阵的一部分元素,而不是全部元素。 对称矩阵:对于一个n阶对称矩阵,我们只需要存储主对…...

Apache IoTDB 走进东南大学,深入分享项目发展历程与收获
源于高校,回到高校,Apache IoTDB PMC 成员乔嘉林为同学们详细分享行业前瞻、研发历程与心得体会。 01 把领先的数据库知识带到校园 6 月 5 日,东南大学计算机科学与工程学院、软件学院、人工智能学院主办的“拔尖领航系列活动特别策划篇-第二…...

Stable Diffusion AI绘画助力建筑设计艺术创新——城市建筑设计大模型分享
大家好,我是向阳 今天我将针对建筑设计方面的AI大模型进行简单介绍,我们将通过富有想象力的关键词或结合Stable Diffusion 的ControlNet 给原本只有黑白线条的线稿变成彩色的效果图,可能你只需要短短几分钟就可以让黑白线稿变成几种甚至十几种…...

没有 ADetailer,ComfyUI 画图脸崩了怎么办?
我们都知道 SD 的 WebUI 中的面部修复神器是 ADetailer,不过它是 WebUI 的专属插件,在 ComfyUI 中是搜索不到这个插件的,但是并不代表 ComfyUI 就不能使用面部修复功能了,ComfyUI 中也是可以找到平替的。 今天我们就来讲讲在 Com…...

防爆气象仪的工作原理
TH-WFB5矿山气象传感器在矿山安全监测系统中扮演着至关重要的角色,它们能够及时发现异常情况,为矿山的安全运营提供可靠的数据支持。矿山气象传感器能够实时监测矿山环境中的风速、风向、温度、湿度和大气压力等关键气象参数。这些传感器采用先进的传感技…...

深度学习入门5——为什么神经网络可以学习?
在理解神经网络的可学习性之前,需要先从数学中的导数、数值微分、偏导数、梯度等概念入手,从而理解为什么神经网络具备学习能力。 1.数值微分的定义 先从导数出发理解什么是梯度。某一点的导数直观理解就是在该点的切线的斜率。在数学中导数表示某个瞬…...

Integer溢出问题
0. 背景 在刷 LeetCode 时,代码的执行结果与预期出现了偏差,原因是 Int 值超过了允许范围 [ − 2 31 , 2 31 − 1 ] [-2^{31},2^{31}-1 ] [−231,231−1]。工作中从来没有遇到过这种情况,之前的认知是如果 Int 中存储的值超过了允许范围也许…...

软件测试全面指南:提升软件质量的系统流程
一、引言 随着软件行业的飞速发展,确保软件质量、稳定性和用户体验已成为企业竞争的关键。本文档旨在为测试团队提供一套全面的软件测试指南,通过规范测试用例管理、功能测试、接口测试、性能测试及缺陷管理等流程,助力测试团队实现高效、系统…...

《逆贫大叔》:一部穿越时光的温情史诗
《逆贫大叔》:一部穿越时光的温情史诗 在历史的长河中,有些故事能够穿越时光的尘埃,直击人心。《逆贫大叔》就是这样一部作品,它不仅是一部电视剧,更是一段历史的缩影,一次心灵的触动。 背景设定࿱…...

【电机控制】FOC算法验证步骤——PWM、ADC
【电机控制】FOC算法验证步骤 文章目录 前言一、PWM——不接电机1、PWMA-H-50%2、PWMB-H-25%3、PWMC-H-0%4、PWMA-L-50%5、PWMB-L-75%6、PWMC-L-100% 二、ADC——不接电机1.电流零点稳定性、ADC读取的OFFSET2.电流钳准备3.运放电路分析1.电路OFFSET2.AOP3.采样电路的采样值范围…...

如何衡量llm 数据集的多样性
衡量大型语言模型(LLM)数据集的多样性是一个复杂的问题,因为多样性可以从多个角度来考虑。以下是一些常用的方法和指标来评估数据集的多样性: 词汇多样性: 类型-词符比(Type-Token Ratio, TTR)…...

编程天才是什么意思
编程天才是什么意思 编程天才,这个词汇似乎充满了神秘与敬畏的色彩。那么,它究竟意味着什么呢?在本文中,我们将从四个方面、五个方面、六个方面和七个方面深入探讨编程天才的内涵与外延,带您领略这一领域的独特魅力。…...
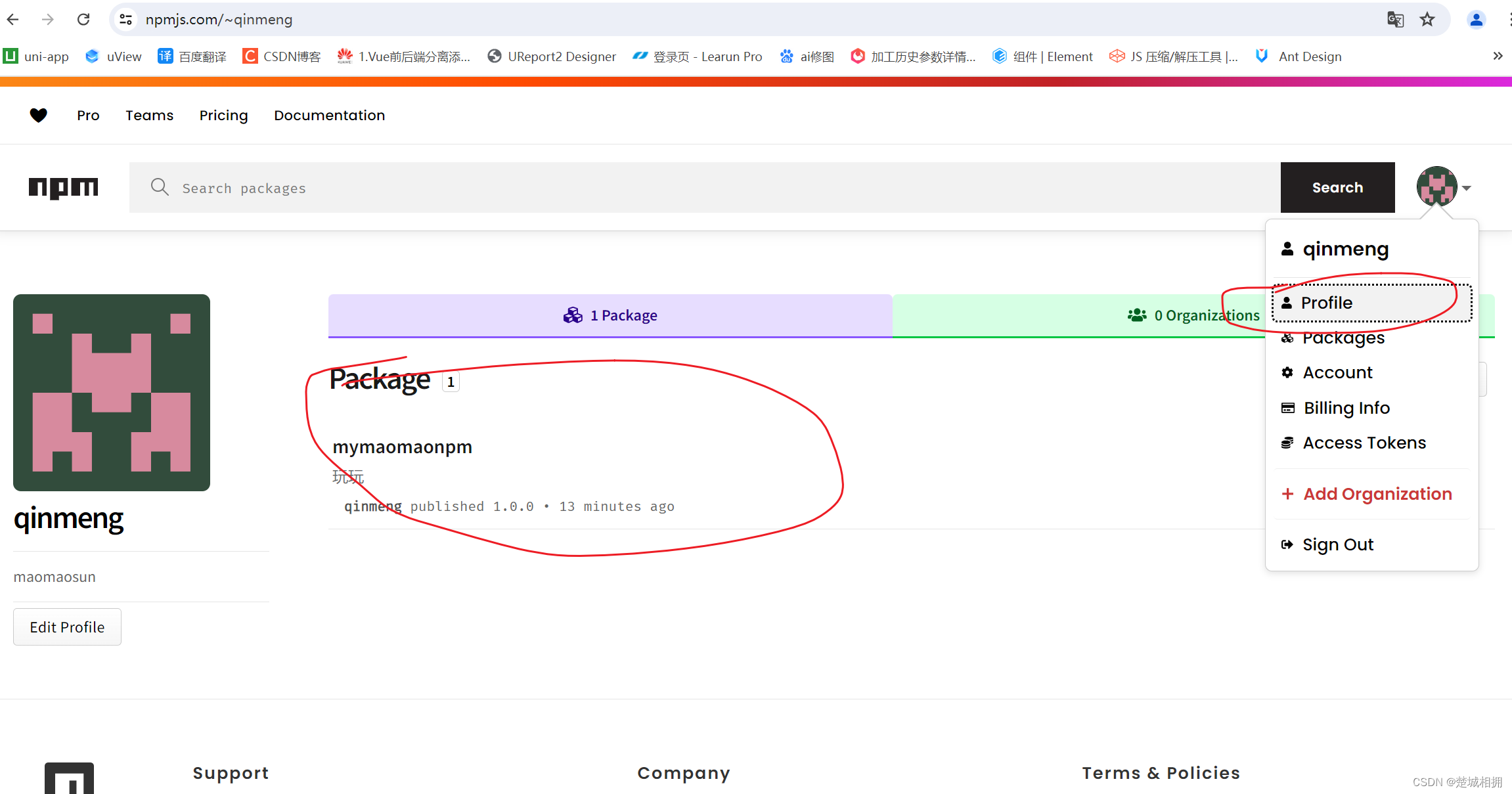
创建npm私包
参考文章: 使用双重身份验证访问 npm | npm 中文网 私有npm包的实例详解-js教程-PHP中文网 1.注册npm账号 npm官网: npm | Home 2.安装node 百度挺多的,安装完后,检查是否安装成功就行 3.写一个简单的模块 创建个文件夹&am…...

provider追加android:name的命名有哪些?
在Android中,为<provider>元素添加android:name属性时,命名应遵循Android组件的命名规范和包名的命名规范。以下是一些关于命名android:name的要点: 包名前缀:android:name属性的值通常应以包名开始,这是应用程序…...
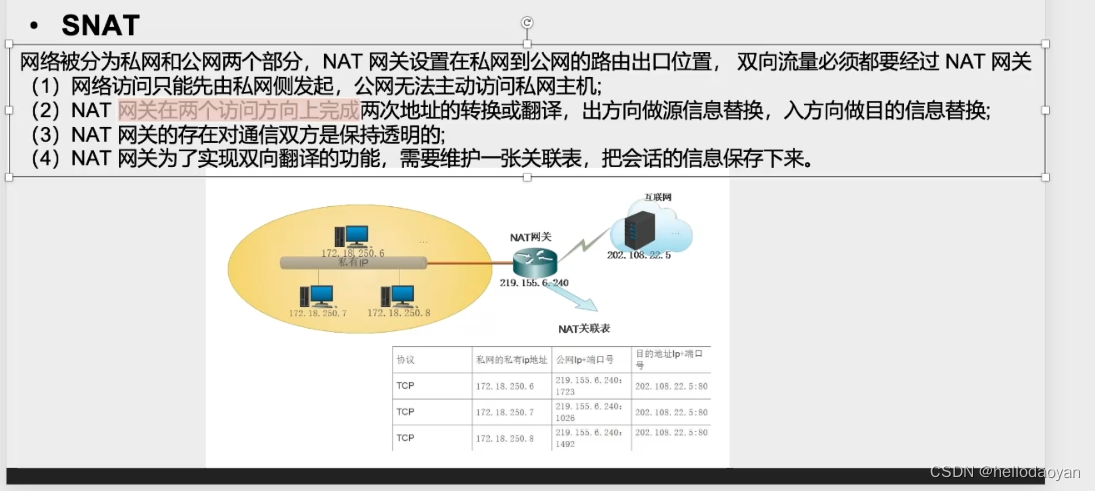
长亭网络通信基础
长亭笔试之前就已经学过一遍了 这算温故而知新吧 TCP/IP 首先我在这里默写一下之前的7层和4层 应用层 应 【表示层 数据格式转换 传 【会话层 …...

hdfs源码解析之DFSClient
1、DFSClient类简介 DFSClient 是 Hadoop 分布式文件系统(HDFS)中的一个核心类,用于客户端与 HDFS 之间的交互。它提供了一组方法,使客户端应用程序可以方便地与 HDFS 进行通信,包括文件的读取、写入、创建、删除、重命…...

智能化立体仓库的种类有哪些?
在仓储运输系统中,自动化立体仓库可充分利用空间储存货物,故而也被称之为高层货架仓库。在实际应用中,自动化仓库系统是不需人工处理的情况下能自动存储和取出物料的系统。那么,智能化立体仓库的种类有哪些?下面就让小…...

Stable Diffusion 3 如何下载安装使用及性能优化
Stable Diffusion 3 Stable Diffusion 3(SD3),Stability AI最新推出的Stable Diffusion模型系列,现在可以在Hugging Face Hub上使用,并且可以与Diffusers一起使用。 今天发布的模型是Stable Diffusion 3 Medium&…...

c语言操作符详解
操作符详解 正数的原码反码补码相同 负数的原码最高位数是1,正数为0 整数在内存中存储的是补码 负数的左移与右移,移的是补码,打印的是源码 补码-1取反就是原码。 左移有乘2的效果 左移和右移只针对整数。 vs里的右移操作赋采用的是算数右…...
)
别再手动数脉冲了!用STM32定时器编码器模式搞定增量编码器(附CubeMX配置)
STM32硬件编码器模式实战:精准捕获增量编码器信号的工程指南 在电机控制、机器人关节定位和精密测量系统中,增量式编码器作为核心反馈元件,其信号处理质量直接影响整个系统的控制精度。传统的中断计数方式在高速脉冲场景下往往捉襟见肘&#…...

环境配置与基础教程:保姆级教程:在 Mac M 芯片上利用 MPS 加速 YOLO 训练与推理的完整环境搭建
写在前面:为什么你的 Mac 也能跑深度学习? 几年前,如果有人告诉你用 MacBook 训练深度学习模型,你大概会笑出声。那时候 Mac 上的 PyTorch 只能依赖 CPU 吭哧吭哧地算,训练一个小模型都要等到天荒地老。但自从 Apple Silicon 芯片(M1、M2、M3、M4,以及最新的 M5)横空出…...

UAVLogViewer:无人机飞行日志分析的终极免费解决方案
UAVLogViewer:无人机飞行日志分析的终极免费解决方案 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer 面对无人机飞行日志中混乱的数据格式、复杂的参数解读和难以直观展示的三…...

对比官方价格Taotoken的活动价确实带来了可观节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格,Taotoken的活动价确实带来了可观节省 作为一名长期使用多个大模型API进行项目开发的个人开发者ÿ…...

macOS开发环境标准化实践:基于Homebrew的CUR环境构建
1. 项目概述与核心价值最近在折腾macOS开发环境,尤其是涉及到一些需要特定编译工具链的项目时,经常被各种依赖和版本问题搞得焦头烂额。相信很多从Linux或Windows转过来的开发者都有同感,macOS虽然优雅,但在某些底层开发工具的生态…...

VPS自动化配置脚本:Shell脚本实现服务器安全与开发环境一键部署
1. 项目概述:一个为开发者量身打造的VPS自动化配置脚本如果你和我一样,经常需要快速部署新的VPS(虚拟专用服务器)来跑一些临时的项目、搭建测试环境,或者只是厌倦了每次都要重复那些繁琐的初始化步骤,那么你…...

C++高性能服务器框架----Servlet模块
Servlet模块HTTP Servlet包括两部分,第一部分是Servlet对象,每个Servlet对象表示一种处理HTTP消息的方法,第二部分是ServletDispatch,它包含一个请求路径到Servlet对象的映射,用于指定一个请求路径该用哪个Servlet来处…...

5大理由:为什么UAV Log Viewer是你的无人机飞行数据分析终极工具
5大理由:为什么UAV Log Viewer是你的无人机飞行数据分析终极工具 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer UAV Log Viewer是一款基于JavaScript开发的免费开源无人机飞…...

2026年高口碑GNSS变形监测一体机推荐:提升水库安全解决方案
随着基础设施监测需求的上升,单北斗形变监测一体机逐渐成为各大工程的首选。利用GNSS桥梁形变监测技术、这些设备能够实时监控水库和大坝重要结构的安全情况。单北斗GNSS应用在数据传输和处理上,展现出高效性与可靠性。用户在选择时应关注不同型号的价格…...
)
你的差速小车为什么画圈不准?可能是数学模型离散化没搞对(避坑指南)
差速小车控制精度优化:从数学模型离散化到工程实践 差速轮式机器人作为移动机器人领域的经典平台,其控制精度直接影响路径跟踪、自主导航等核心功能的可靠性。许多开发者在STM32、Arduino或嵌入式ROS系统上实现了基础运动控制后,往往会遇到一…...