嵌套使用模板类
#include<iostream>
using namespace std;template <class Datatype>
class Stack
{
private:Datatype* items;//栈数组int stacksize;//栈的实际大小int top;//栈顶指针
public://构造函数:1)分配栈数组内存,2)把栈顶指针初始化为0;Stack(int size=3) :stacksize(size), top(0) {items = new Datatype[stacksize];}~Stack() {delete[] items;items = nullptr;}bool isempty()const {if (top == 0)return true;return false;}bool isfull()const {if (top == stacksize)return true;return false;}bool push(const Datatype& item) {//元素入栈;if (top < stacksize) {items[top++] = item;return true;}return false;}bool pop(Datatype& item) {if (top > 0) { item = items[--top]; return true; }return false;}
};
template <class T>
class Vector
{
private:int len;T* items;
public:Vector(int size=2) :len(size) {items = new T[len];}~Vector() {delete[] items;items = nullptr;}void resize(int size) {if (size <= len)return;T* temp = new T[size];for (int i = 0; i < len; i++) {temp[i] = items[i];}delete[] items;items = temp;len = size;}int getlen()const { return len; }T& operator[](int ii) {if (ii > len)resize(ii + 1);return items[ii];}const T& operator[](int ii)const { return items[ii]; }};
int main() {//Vector容器的大小缺省值是2,Stack容器的缺省值是3.//创建Vector容器,容器中的元素用StackVector<Stack<string>> vs;//手工的往容器中插入数据vs[0].push("zhongge1"); vs[0].push("zhongge2"); vs[0].push("zhongge3");vs[1].push("zhongge1"); vs[1].push("zhongge2"); vs[1].push("zhongge3");//用嵌套的循环,把容器中的数据显示出来for (int ii = 0; ii < vs.getlen(); ii++) {while (vs[ii].isempty() == false) {string item;vs[ii].pop(item);cout << "item = " << item << endl;}}return 0;
}item = zhongge3
item = zhongge2
item = zhongge1
item = zhongge3
item = zhongge2
item = zhongge1C:\Users\代伟业\Desktop\C++\初始化列表\project\x64\Debug\project.exe (进程 6216)已退出,代码为 0。
按任意键关闭此窗口. . .容器中的容器就是二维的容器。
再往Vector容器中加多两个元素。
vs[2].push("ouge1"); vs[2].push("ouge2");出现内存错误:在扩展数组内存空间的这个函数中:
void resize(int size) {
if (size <= len)return;
T* temp = new T[size];
for (int i = 0; i < len; i++) {
temp[i] = items[i];
}
delete[] items;
items = temp;
len = size;
}
这句: temp[i] = items[i];是把原数组中的元素复制到新数组,若复制的是cpp内置的数据类型,不存在任何问题,如果复制的是类,而且类使用了堆区内存,就存在浅拷贝的问题。
Stack类用了堆区内存,所以说对于Stack用浅拷贝是不行的,得用深拷贝,所以Stack这种类一定要重写拷贝构造函数和赋值函数。在这个demo中没用到Stack的拷贝构造函数那就不管他了,但是应该为Stack类重写赋值函数,实现深拷贝。
Stack& operator=(const Stack& v) {delete[] items;stacksize = v.stacksize;items = new Datatype[stacksize];for (int i = 0; iMstacksize; i++)items[i] = v.items[i];top = v.top;return *this;
}———————————————————————————————————————
Vector& operator=(const Vector& v) {delete[] items;len = v.len;items = new T[len];for (int i = 0; i < len; i++)items[i] = item[i];return *this;
}给Vector类也加上赋值运算符的重载函数,实现深拷贝,等一会用到;
——————————————————————————————
now创建一个Stack容器,容器中的元素用Vector。也就是说,栈中的每个元素是一个数组。
#include<iostream>
using namespace std;template <class Datatype>
class Stack
{
private:Datatype* items;//栈数组int stacksize;//栈的实际大小int top;//栈顶指针
public://构造函数:1)分配栈数组内存,2)把栈顶指针初始化为0;Stack(int size=3) :stacksize(size), top(0) {items = new Datatype[stacksize];}~Stack() {delete[] items;items = nullptr;}Stack& operator=(const Stack& v) {delete[] items;stacksize = v.stacksize;items = new Datatype[stacksize];for (int i = 0; stacksize; i++)items[i] = v.items[i];top = v.top;return *this;}bool isempty()const {if (top == 0)return true;return false;}bool isfull()const {if (top == stacksize)return true;return false;}bool push(const Datatype& item) {//元素入栈;if (top < stacksize) {items[top++] = item;return true;}return false;}bool pop(Datatype& item) {if (top > 0) { item = items[--top]; return true; }return false;}
};
template <class T>
class Vector
{
private:int len;T* items;
public:Vector(int size=2) :len(size) {items = new T[len];}~Vector() {delete[] items;items = nullptr;}void resize(int size) {if (size <= len)return;T* temp = new T[size];for (int i = 0; i < len; i++) {temp[i] = items[i];}delete[] items;items = temp;len = size;}int getlen()const { return len; }Vector& operator=(const Vector& v) {delete[] items;len = v.len;items = new T[len];for (int i = 0; i < len; i++)items[i] =v.items[i];return *this;}T& operator[](int ii) {if (ii > len)resize(ii + 1);return items[ii];}const T& operator[](int ii)const { return items[ii]; }};
int main() {//创建一个Stack容器,容器中的元素用VectorStack<Vector<string>> sv;//创建一个临时的Vector<string>容器;Vector<string> tmp;//第一个入栈的元素tmp[0] = "sb1"; tmp[1] = "sb2"; sv.push(tmp);//第二个入栈的元素tmp[0] = "sb1"; tmp[1] = "sb2"; sv.push(tmp);//第三个入栈的元素(数组容器中有四个元素)tmp[0] = "sb1"; tmp[1] = "sb2"; tmp[2] = "sb1"; tmp[3] = "sb2"; sv.push(tmp);//用嵌套的循环,把容器中的数据显示出来while (sv.isempty() == false) {sv.pop(tmp);for (int i = 0; i < tmp.getlen(); i++) {cout << "vs[" << i << "] = " << tmp[i] << endl;}}return 0;
}
相关文章:

嵌套使用模板类
#include<iostream> using namespace std;template <class Datatype> class Stack { private:Datatype* items;//栈数组int stacksize;//栈的实际大小int top;//栈顶指针 public://构造函数:1)分配栈数组内存,2)把栈顶…...

adb卸载系统应用
1.进入shell adb shell2.查看所有包 pm list packages3.查找包 如查找vivo相关的包 pm list packages | grep vivo发现包太多了,根本不知道哪个是我们想卸载的应用 于是可以打开某应用,再查看当前运行应用的包名 如下: 4.查找当前前台运行的包名 打开某应用,在亮屏状态输入 …...

Rapidfuzz,一个高效的 Python 模糊匹配神器
目录 01初识 Rapidfuzz 什么是 Rapidfuzz? 为什么选择 Rapidfuzz? 安装 Rapidfuzz 配置 Rapidfuzz 02基本操作 简单比率计算 03高级功能 查找单个最佳匹配 查找多个最佳匹配 使用阈值优化性能 04实战案例…...

【猫狗分类】Pytorch VGG16 实现猫狗分类1-数据清洗+制作标签文件
Pytorch 猫狗分类 用Pytorch框架,实现分类问题,好像是学习了一些基础知识后的一个小项目阶段,通过这个分类问题,可以知道整个pytorch的工作流程是什么,会了一个分类,那就可以解决其他的分类问题࿰…...

磁盘管理 磁盘介绍 MBR
track:磁道,就是磁盘上同心圆,从外向里,依次1号、2号磁道..... sector:扇区,将磁盘分成一个一个扇形区域,每个扇区大小是512字节,从外向里,依次是1号扇区、2号扇区... cy…...

JSON响应中提取特定的信息——6.14山大软院项目实训2
在收到的JSON响应中提取特定的信息(如response字段中的文本)并进行输出,需要进行JSON解析。在Unity中,可以使用JsonUtility进行简单的解析,但由于JsonUtility对嵌套对象的支持有限,通常推荐使用第三方库如N…...

【C++高阶】高效搜索的秘密:深入解析搜索二叉树
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:C多态 🌹🌹期待您的关注 🌹🌹 ❀二叉搜索树 📒1. 二叉搜索树&…...

《软件定义安全》之七:SDN安全案例
第7章 SDN安全案例 1.DDoS缓解 1.1 Radware DefenseFlow/Defense4All Radware在开源的SDN控制器平台OpenDaylight(ODL)上集成了一套抗DDoS的模块和应用,称为Defense4ALL。其架构如下图,主要有两部分:控制器中的安全…...
java语言his系统医保接口 云HIS系统首页功能实现springboot框架+Saas模式 his系统项目源码
java语言his系统医保接口 云HIS系统首页功能实现springboot框架Saas模式 his系统项目源码 HIS系统的实施旨在整个医院建设企业级的计算机网络系统,并在其基础上构建企业级的应用系统,实现整个医院的人、财、物等各种信息的顺畅流通和高度共享,…...
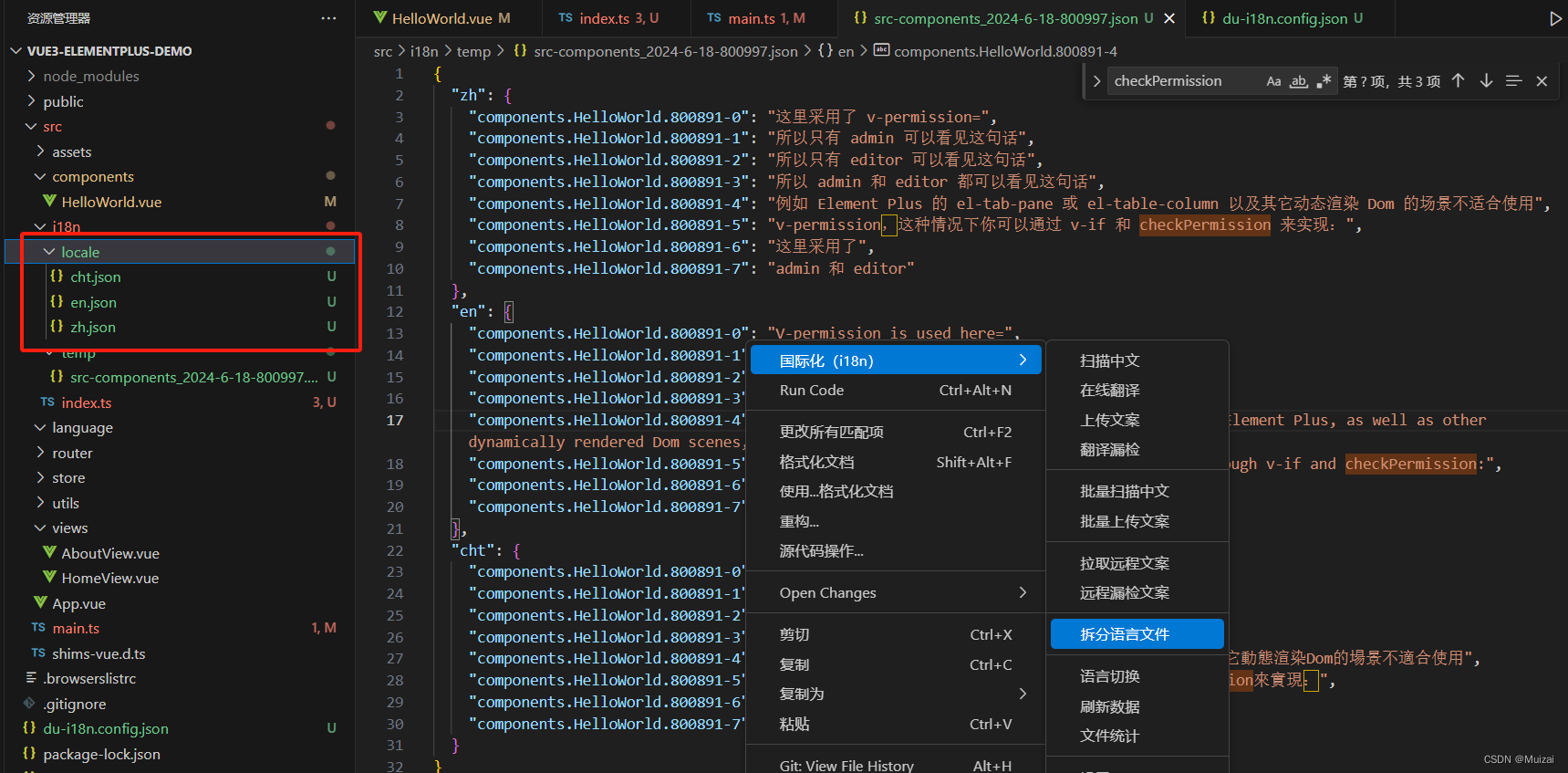
使用vscode插件du-i18n处理前端项目国际化翻译多语言
前段时间我写了一篇关于项目国际化使用I18n组件的文章,Vue3 TS 使用国际化组件I18n,那个时候还没真正在项目中使用,需求排期还没有定,相当于是预研。 当时就看了一下大概怎么用,改了一个简单的页面,最近需…...
双系统下,如何隐藏另一个系统分区?
前言 最近有小伙伴在公众号下留言: 小伙伴说:“双系统时,非当前系统的系统盘能不能屏蔽?!比如Win7的系统盘在Win10系统时,盘符成了D盘,安装应用软件时,有些文件就到了D盘࿰…...
电脑意外出现user32.dll丢失的八种修复方法,有效解决user32.dll文件丢失
遇到与 user32.dll 相关的错误通常是因为该文件已损坏、丢失、或者与某些软件冲突。今天这篇文章寄给大家介绍八种修复user32.dll丢失的方法,下面是一步步的详细教程来解决这个问题。 1. 重新启动电脑 第一步总是最简单的:重新启动你的电脑。许多小问题…...

CUDA系列-Kernel Launch-8
这里写目录标题 kernel launch 本章主要追踪一下kernel launch的流程,会不断完善。 kernel launch 先抛出一个问题,如果在一个循环中不断的发送kernel(kernel 内部while死循环),会是什么结果。 // kernel 函数 __glo…...
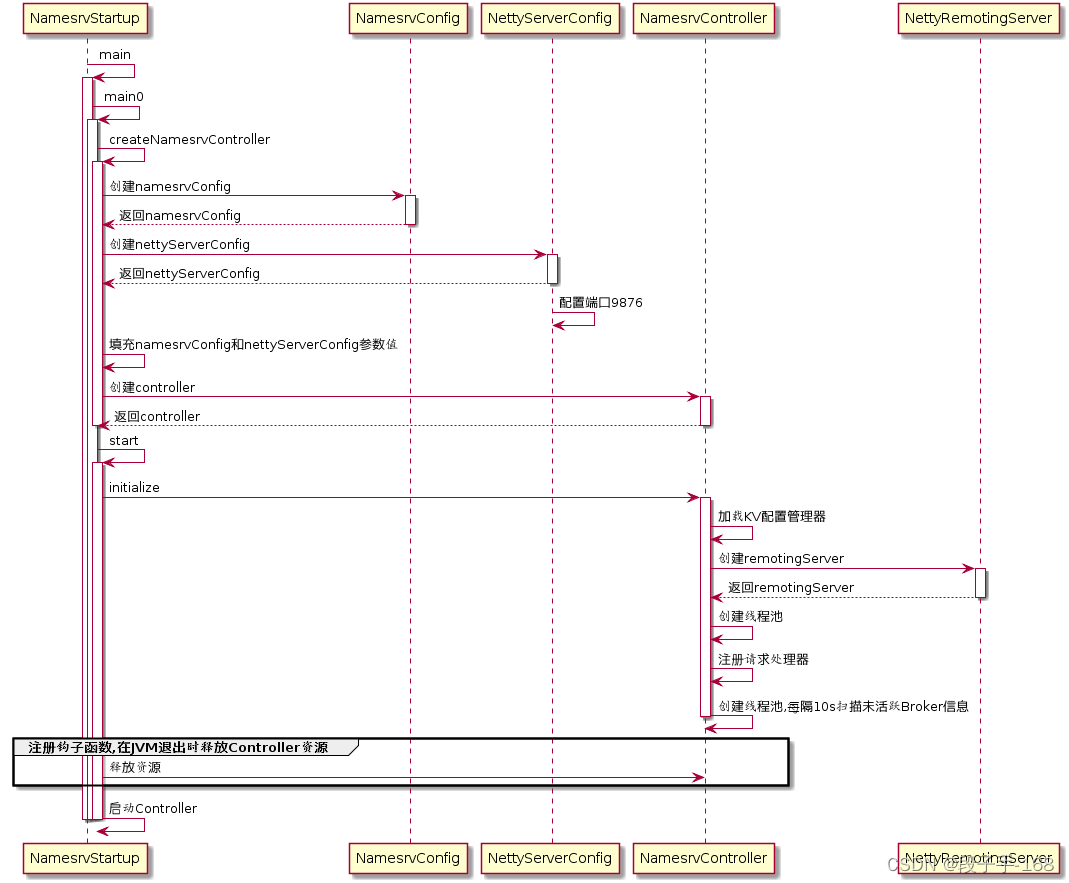
# 消息中间件 RocketMQ 高级功能和源码分析(四)
消息中间件 RocketMQ 高级功能和源码分析(四) 一、 消息中间件 RocketMQ 源码分析:回顾 NameServer 架构设计。 1、RocketMQ 架构设计 消息中间件的设计思路一般是基于主题订阅发布的机制,消息生产者(Producer&…...

如何通过数据库与AI实现以图搜图?OceanBase向量功能详解
OceanBase支持向量数据库的基础能力 当前,数据库存储系统与人工智能技术的结合,可以体现在两个主要的应用方向上。 一、近似搜索。它利用大语言模型(LLM,简称大模型)的嵌入(embedding)技术&am…...

Kafka内外网分流配置listeners和advertised.listeners
问题背景: Kafka部署在内网,内网Java服务会使用Kafka收发消息,另外,Java服务会与其他第三方系统使用kafka实现数据同步,也就是外网也会发送消息到kafka,外网IP做了端口映射到了内网,advertised…...
Linux系统编程——网络编程
目录 一、对于Socket、TCP/UDP、端口号的认知: 1.1 什么是Socket: 1.2 TCP/UDP对比: 1.3 端口号的作用: 二、字节序 2.1 字节序相关概念: 2.2 为什么会有字节序: 2.3 主机字节序转换成网络字节序函数…...

信息安全技术基础知识-经典题目
【第1题】 1.在信息安全领域,基本的安全性原则包括机密性(Confidentiality)、完整性(Integrity)和 可用性(Availability)。机密性指保护信息在使用、传输和存储时 (1) 。信息加密是保证系统机密性的常用手段。使用哈希校验是保证数据完整性的常用方法。可用性指保证…...

nextjs(持续学习中)
return ( <p className{${lusitana.className} text-xl text-gray-800 md:text-3xl md:leading-normal}> Welcome to Acme. This is the example for the{’ } Next.js Learn Course , brought to you by Vercel. ); } 在顶级 /public 文件夹下提供静态资产 **默认 /…...

数据预处理与特征工程、过拟合与欠拟合
数据预处理与特征工程 常用的数据预处理步骤 向量化:将数据转换成pytorch张量值归一化:将特定特征的数据表示成均值为0,标准差为1的数据的过程;取较小的值:通常在0和1之间;相同值域处理缺失值特征工程&am…...

Sidekiq监控测试终极指南:如何全面检测系统状态与性能
Sidekiq监控测试终极指南:如何全面检测系统状态与性能 【免费下载链接】sidekiq Simple, efficient background processing for Ruby 项目地址: https://gitcode.com/gh_mirrors/si/sidekiq Sidekiq作为Ruby生态中最流行的后台作业处理框架,其强大…...

猫抓cat-catch浏览器扩展:专业级资源嗅探与下载解决方案
猫抓cat-catch浏览器扩展:专业级资源嗅探与下载解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾遇到这样的情况&#…...

【maaath】Flutter for OpenHarmony 体重管理应用开发实战
Flutter for OpenHarmony 体重管理应用开发实战:从数据模型到完整功能实现欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 作者:maaath一、前言 随着 OpenHarmony 生态的快速发展,Flutter for OpenHarmon…...

如何轻松提取Wallpaper Engine壁纸资源:RePKG完整实用指南
如何轻松提取Wallpaper Engine壁纸资源:RePKG完整实用指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰:下载了精美的Wallpap…...

Java AI集成实战:ai4j项目解析与生产环境应用指南
1. 项目概述与核心价值 最近在开源社区里,一个名为 LnYo-Cly/ai4j 的项目引起了我的注意。乍一看这个标题,你可能会有点懵——“ai4j”?是“AI for Java”的缩写吗?没错,这正是它的核心定位。作为一个在Java生态里摸…...
)
iOS Swift 推送通知完整实现教程(前台/后台/杀死状态 全覆盖跳转)
一、前言 远程推送通知是iOS开发中高频必备功能,绝大多数App都需要实现推送消息提醒、点击通知跳转指定业务页面。iOS推送分为三种运行状态,开发中必须全部兼容:前台运行:App处于打开状态,直接接收推送弹窗后台挂起&am…...

构建高可复用表单解决方案:从状态管理到校验引擎的工程实践
1. 项目概述:一个面向开发者的表单实验室如果你是一名前端或全栈开发者,肯定对表单这个“老朋友”又爱又恨。爱它,是因为它是用户与系统交互最核心的桥梁;恨它,是因为从数据绑定、校验、提交到状态管理,每一…...

CircuitPython库管理全攻略:从导入错误到高效项目构建
1. 项目概述与核心价值 如果你刚开始接触CircuitPython,可能会被一个看似简单的问题绊住:我写好的代码,为什么一运行就报错说找不到某个模块?这个问题背后,其实牵涉到CircuitPython生态中一个极其重要但文档往往语焉不…...

AGIEval分数暴涨37%的关键路径,从Prompt工程到推理链剪枝——资深AI系统工程师手把手复现
更多请点击: https://intelliparadigm.com 第一章:AGIEval评测体系深度解析与分数跃迁意义 AGIEval 是当前面向通用人工智能能力评估的前沿基准,聚焦于人类认知核心维度——逻辑推理、多步数学推导、法律条文解读、医学诊断分析及复杂指令遵…...

如何3分钟快速检测代码抄袭:JPlag完整使用指南
如何3分钟快速检测代码抄袭:JPlag完整使用指南 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 在编程教学和…...