使用本地数据对transformers模型进行微调训练
模型
transformers模型是使用比较多的模型,奈何各个都是体积大,找了一个使用人多不是很大的模型进行训练。
需要魔法
bert-base-uncased模型仓库地址
huggingface下的所有仓库都是git的,也就意味着你可以使用 git clone 可以下载仓库内所有的东西
硬件
本机并没有显卡,公司电脑是 i5 - 10500, 内存32GB
需要下载的库
conda有的库没有,需要下载
json os wandb datasets transformers
注意事项
1,库下载到本地后,在python中引用需要加载父级地址
os.environ["HF_MODELS_HOME"] = "E:\\data\\ai_model\\"
2,需要使用 wandb 进行训练记录,如果不写的话会报错。
wandb地址 wandb官网
3,需要设置对本地单个dll库的设置
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
最后,附上代码
import json
import os
import wandb
from datasets import Dataset
from transformers import BertTokenizer, BertForQuestionAnswering, Trainer, TrainingArgumentsos.environ["HF_MODELS_HOME"] = "E:\\data\\ai_model\\"
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"aip_key = '98b420c1ea905e27b7885b3d4205832fbef6874f'
# 1.连接 可以写在命令行,也可以写在代码中,只要在代码运行之前运行过即可,这里是代码中的实现
wandb.login(key=aip_key)
# 2.初始化wandb对象,主要用到6的几个参数
runs = wandb.init(project="wandb_study",# name=f"experiment",notes="这是一次test",tags=["test", "Test"]
)
# 3.初始化config
# Capture a dictionary of hyperparameters
wandb.config = {"epochs": 100, "learning_rate": 0.001, "batch_size": 128}# 4.找到相应数据并添加,一般的字符串、整形、浮点型直接用字典的形式就可以,图片前面要加wandb.Image()解析成wandb的形式,表格,summary见8和9
# wandb.log({"accuracy": step_acc,
# "loss": train_loss.item(),
# 'images': wandb.Image(images[0]),
# })# 数据准备
def read_json():json_data = '''[{"question": "What is the Apollo program?","context": "The Apollo program was the third human spaceflight program carried out by NASA...","answer": "The Apollo program was the third human spaceflight program carried out by NASA"}]'''data = json.loads(json_data)# 将数据转换为Dataset对象# 转换数据格式dataset_dict = {"question": [item["question"] for item in data],"context": [item["context"] for item in data],"answer": [item["answer"] for item in data]}# 创建Dataset对象dataset = Dataset.from_dict(dataset_dict)print(dataset)return dataset# 定义数据预处理函数,将输入数据转换为模型可用的格式
def preprocess_function(examples):inputs = tokenizer(examples["question"],examples["context"],max_length=512,truncation=True,return_tensors="pt",padding="max_length")start_positions = []end_positions = []for i, answer in enumerate(examples["answer"]):start_pos = examples["context"][i].find(answer)end_pos = start_pos + len(answer)start_positions.append(start_pos)end_positions.append(end_pos)inputs.update({"start_positions": start_positions,"end_positions": end_positions})return inputs# 设置训练参数并初始化Trainer对象
def trainer_training(model):processed_dataset = dataset.map(preprocess_function, batched=True)training_args = TrainingArguments(output_dir='./results',run_name='my_experiment', # 设置一个不同于 output_dir 的 run_namenum_train_epochs=3,per_device_train_batch_size=8,per_device_eval_batch_size=8,warmup_steps=500,weight_decay=0.01,logging_dir='./logs',logging_steps=10,eval_strategy="steps", # 使用 eval_strategy 替代 evaluation_strategy)return Trainer(model=model,args=training_args,train_dataset=processed_dataset,eval_dataset=processed_dataset,)if __name__ == '__main__':dataset = read_json()model_name = "bert-base-uncased"tokenizer = BertTokenizer.from_pretrained(model_name)model = BertForQuestionAnswering.from_pretrained(model_name)trainer = trainer_training(model)# 开始训练模型trainer.train()# 保存训练后的模型output_model_dir = "./trained_model" # 这是一个文件夹,下面有三个文件 config.json model.safetensors training_args.binos.makedirs(output_model_dir, exist_ok=True)trainer.save_model(output_model_dir)引用资料:
wandb的基本使用
相关文章:
使用本地数据对transformers模型进行微调训练
模型 transformers模型是使用比较多的模型,奈何各个都是体积大,找了一个使用人多不是很大的模型进行训练。 需要魔法 bert-base-uncased模型仓库地址 huggingface下的所有仓库都是git的,也就意味着你可以使用 git clone 可以下载仓库内所有的…...

Java面试题:讨论何时需要创建自定义异常类,并展示如何实现一个自定义异常
在Java中,创建自定义异常类的目的是为了更加清晰和有意义地表示特定的错误情况,增强代码的可读性和可维护性。以下是一些需要创建自定义异常类的常见场景以及如何实现一个自定义异常。 何时需要创建自定义异常类 特定业务逻辑错误: 当业务逻…...

什么是进程
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在了解进程之前,我们需要知道多任务的概念。多任务,顾名思义,就是指操作系统能够执行多个任务。例如,…...
电脑提示d3dcompiler_47.dll丢失的解决方法,实测靠谱的5种方法
在计算机使用过程中,缺失d3dcompiler_47.dll这一系统文件是一个常见问题,尤其是对于游戏和图形密集型应用程序用户来说尤为重要。这个文件是DirectX软件工具包的一部分,主要用于处理图形渲染的应用程序接口的核心元素。当你在运行游戏或某些软…...

SQLserver前五讲课堂笔记
第一讲 基本内容 为什么要学习数据库系统?什么是数据库?什么是数据库系统?什么是数据库管理系统?本课程学什么以及学到什么程度? 重点难点 一组概念的区分:数据库、数据库系统和数据库管理系统熟悉表 的相关要素及术语熟悉数据库系统的构成(工作…...
深度学习项目十六:根据训练好的权重文件推理图片--YOLO系列
文章目录 根据训练好的权重文件推理图片--YOLO系列一、自己构建YOLOv5推理代码1.1 对数据集进行模型训练1.2 对数据集进行模型推理检测1.3 自己编写推理函数1.3.1 针对单张进行推理1.3.2 针对文件夹下的图片进行推理二、自己构建YOLOv8推理代码2.1 对数据集进行模型训练2.2 对数…...
敏感信息加密操作,让开发的系统更加的安全可靠!!
敏感信息加密操作,让开发的系统更加的安全可靠!!Jasypt(Java Simplified Encryption)是一个开源的Java库,用于简化加密操作。https://mp.weixin.qq.com/s/sPBV8Ej46YJsElImodRjAQ...

第四篇:精通Docker构建:Dockerfile的艺术与策略
精通Docker构建:Dockerfile的艺术与策略 1. 开篇:探索Docker的革命 在探讨我们的主题之前,让我们先回顾一下Docker的概念。Docker是一个开源平台,用于自动化应用程序的部署、扩展和管理,这一切都是在轻量级的容器中进…...

Linux下Cmake安装或版本更新
下载Cmake源码 https://cmake.org/download/ 找到对应的版本和类型 放进linux环境解压 编译 安装 tar -vxvf cmake-3.13.0.tar.gz cd cmake-3.13.0 ./bootstrap make make install设置环境变量 vi ~/.bashrc在文件尾加入 export PATH/your_path/cmake-3.13.0/bin:$PAT…...

人工智能体验工程师面试
在面试人工智能体验工程师时,面试官可能会从多个方面来考察候选人的能力和经验。以下是人工智能体验工程师面试题: 基础知识考察: 请简述人工智能、机器学习和深度学习的关系与区别。请解释神经网络的基本原理,以及它在人工智能中的应用。描述一种你熟悉的深度学习模型,并…...

科研——BIBM论文修改和提交
文章目录 引言投递流程Latex翻译流程latex模板使用bib文件正文修改 反馈时间线等待审稿结果 引言 第一轮投递快结束了,这里得加快进度,二十号截至,这里得在截至之前投一下,这里翻译整理一下投递的流程 投递流程 投递链接论文是…...
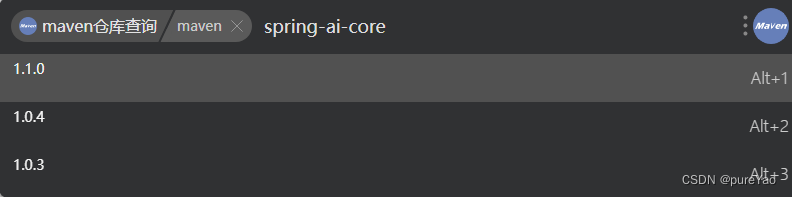
【bug】配置SpringCloudAlibaba AI的maven依赖问题
问题描述 尝鲜alibaba的ai模块,maven依赖一直报找不到包,报错如下 Unresolved dependency: org.springframework.ai:spring-ai-core:jar:0.8.1原因分析: 由于是按照官方文档配置的,所以检查了很多遍maven配置,加上去…...

人工智能和机器学习的应用日益广泛,在医疗健康领域的具体应用是什么?
人工智能(AI)和机器学习(ML)在医疗健康领域的应用日益广泛,涵盖了从疾病预测、辅助诊断、药物研发到健康管理等多个方面。以下是一些具体的应用实例和成功案例: 疾病预测与辅助诊断:机器学习算…...

前端:鼠标点击实现高亮特效
一、实现思路 获取鼠标点击位置 通过鼠标点击位置设置高亮裁剪动画 二、效果展示 三、按钮组件代码 <template><buttonclass"blueBut"click"clickHandler":style"{backgroundColor: clickBut ? rgb(31, 67, 117) : rgb(128, 128, 128),…...
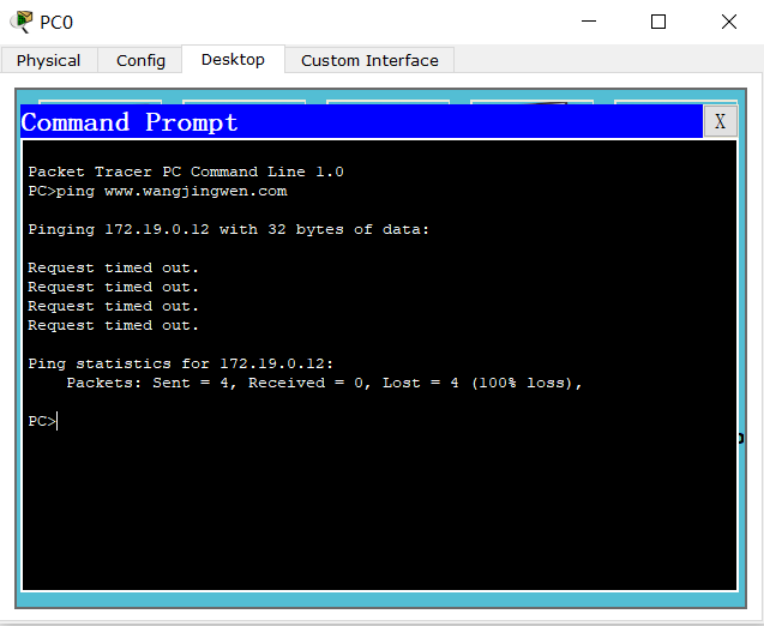
【计算机网络体系结构】计算机网络体系结构实验-DNS模拟器实验
一、DNS模拟器实验 拓扑图 1. 服务器ip 2. 服务器填写记录 3. 客户端ip以及连接到DNS服务器 4. ping测试...

【profinet】从站开发要点
目录 0、常见缩写及关键字注释 1、profinet简介 2、profinet协议栈 3、profinet数据帧 4、profinet网络解决方案示例 5、Application areas 注:本文主要简述profinet从站开发涉及到的知识点。【不足之处后续慢慢补充】。 0、常见缩写及关键字注释 MRP: Media…...

浮点数的进制转换
浮点数的进制转换涉及到将十进制(基数为10)的浮点数转换为其他进制(如二进制、八进制、十六进制等)。以下是将十进制浮点数转换为其他进制的基本步骤: ### 1. 分离整数部分和小数部分: 将浮点数分为整数部…...

vue-饼形图-详细
显示效果 代码 <template> <div style"height: 350px;"> <div :class"className" :style"{height:height,width:width}"></div> </div> </template> <script> import * as echarts from echarts; req…...

MySQL-备份+日志:介质故障与数据库恢复
目录 第1关:备份与恢复 任务描述 相关知识 MySQL的恢复机制 MySQL的备份与恢复工具 …...

嵌入式开发十八:USART串口通信实验
上一节我们学习了串口通信的基本理论,串口通信是学习单片机的一个重要的一步,非常重要,这一节我们通过实验来学习串口通信的使用,以及串口的接收中断的使用。 一、发送单个字节uint8_t数据或者字符型数据 实现的功能:…...

选吉他不踩坑:合板、单板、全单材质深度解析,新手看懂这篇就够
对于新手来说,挑选吉他时最容易被“合板”“单板”“全单”这些专业术语绕晕。其实,这三者的核心区别在于木材的构成方式,而木材直接决定了吉他的音色、手感以及使用寿命。今天我们就抛开品牌干扰,纯科普这三种材质的底层逻辑&…...

节能模式:OpenClaw+nanobot的间歇性任务调度技巧
节能模式:OpenClawnanobot的间歇性任务调度技巧 1. 为什么需要节能模式 去年夏天,我的电费账单突然飙升。排查后发现,那台24小时运行OpenClaw的工作站竟然是耗电大户——它持续调用着本地部署的Qwen大模型,GPU风扇昼夜不停地呼啸…...

springboot交通道路监测感知与车路协同系统可视化大屏
目录技术架构设计数据采集与处理可视化大屏功能模块系统集成与部署关键技术点测试与迭代项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术架构设计 采用SpringBoot作为后端框架,提供RESTful API接口;…...
修复实战:从检测到升级的完整指南)
OpenSSH用户枚举漏洞(CVE-2018-15473)修复实战:从检测到升级的完整指南
OpenSSH用户枚举漏洞(CVE-2018-15473)修复实战:从检测到升级的完整指南 在当今的网络安全环境中,SSH服务作为远程管理服务器的标准协议,其安全性直接关系到整个系统的防护水平。2018年曝光的OpenSSH用户枚举漏洞(CVE-2018-15473)虽然CVSS评分…...

XL6008直流升压电路设计与应用指南
基于XL6008的直流升压电路设计指南 1. 项目概述 1.1 应用背景 便携式电子设备对电源系统提出了特殊要求:在保持轻量化的同时,需要提供稳定的工作电压。由于单节锂电池的标称电压为3.7V(满电4.2V),而许多电子元件需要…...

Ubuntu 24.04 环境实战:ROS 2 Kilted 实现 SLAM 建图与 Nav2 导航
一、构建地图 1、安装依赖 安装 slam_toolbox 算法库: sudo apt install ros-kilted-slam-toolbox安装 TurtleBot3 全套支持包: sudo apt install ros-kilted-turtlebot3*2、使用清华源 如果apt安装很慢,请先配置清华源: sud…...
)
VSCode远程连接报错?手把手教你修复settings.json文件(附常见错误排查)
VSCode远程连接报错终极排查指南:从settings.json修复到SSH配置优化 当你正准备通过VSCode远程连接服务器投入工作时,突然弹出的Failed to write remote.SSH.remotePlatform报错就像一盆冷水浇下来。更令人抓狂的是,明明命令行SSH连接一切正常…...

免费获取Cherry MX键帽3D模型:打造个性化机械键盘的终极指南
免费获取Cherry MX键帽3D模型:打造个性化机械键盘的终极指南 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 你是否厌倦了千篇一律的键盘外观?想要拥有独一无…...
)
飞行器设计避坑指南:盘点那些影响气动效率的‘隐形杀手’(从摩擦阻力到干扰阻力)
飞行器设计避坑指南:盘点那些影响气动效率的‘隐形杀手’ 记得第一次参加大学生飞行器设计竞赛时,我们的团队花了整整三个月打造了一架翼展两米的固定翼无人机。试飞当天,看着它摇摇晃晃地起飞,却在爬升阶段突然失速坠毁ÿ…...

LangGraph 工作流实战:Few-Shot提示赋能大模型精准调用自定义计算工具
1. 为什么需要Few-Shot提示赋能工具调用? 大模型在通用任务上表现惊艳,但遇到需要精确调用自定义工具的场景时,常常会出现"知道但不会用"的情况。比如让GPT-4计算"3172531284724",它可能直接输出错误答案而非…...