深入理解预处理
1.预定义符号
C语言设置了⼀些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的。
__FILE__
//进⾏编译的源⽂件
__LINE__
//⽂件当前的⾏号
__DATE__
//⽂件被编译的⽇期
__TIME__
//⽂件被编译的时间
__STDC__
//如果编译器遵循ANSI C,其值为1,否则未定义#include<stdio.h> int main() {printf("%s\n", __FILE__);printf("%d\n", __LINE__);printf("%s\n", __DATE__);printf("%s\n", __TIME__);printf("%d\n", __STDC__);return 0; }例如在VS中打印以上预定义符号时就会出现以下报错
这就说明VS没有完全遵循ANSI C
将_STDC_去除就可以打印出以下信息


2. #define 定义常量
基本语法:
#define name stuff例如以下代码
在预处理阶段就会将代码内#define定义的内容替换为以下形式


再比如说在一些计算机语言中是存在switch语句的,有一些在使用switch时不需要在case语句后加上break,但例如我们学习的c语言就需要在case语句后加上break才能实现switch语句,这时就可以用到#define来在写case语句的时候⾃动把 break写上
#define CASE break;case例如以下代码就是使用#define后的switch语句
#define CASE break;case #include<stdio.h> int main() {int n = 0;scanf("%d", &n);switch (n){case 1:CASE 2:CASE 3://……}return 0; }在预处理之后就会变为以下形式
#include<stdio.h> int main() {int n = 0;scanf("%d", &n);switch (n){case 1:break; case 2:break; case 3://……}return 0; }
如果在使用#define定义的 stuff过长,可以分成几行写,除了最后一行外,每行的后面都加⼀个反斜杠(续行符),这样就可以使得内容表示在同一行代码上。
#define DEBUG_PRINT printf("file:%s\tline:%d\t \ date:%s\ttime:%s\n" ,\ __FILE__,__LINE__ , \ __DATE__,__TIME__ )
思考:在define定义标识符的时候,要不要在最后加上 ; ?
在一些情况下加上代码不会有什么太大的问题,但在一些情况下就会使代码出现错误
例如:
#define M 100;
#include<stdio.h>
int main()
{int a=M;printf("%d", a);return 0;
} 在以上代码程序就会出现以下报错
这时因为在预处理之后代码就变为以下形式
通过以上代码就可以了解到使用#define后不要在在最后加上 ;
3. #define定义宏
#define 机制包括了⼀个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。
⼀般来讲函数的宏的使用语法很相似。所以语言本身没法帮我们区分⼆者。
那我们平时的一个习惯是:
把宏名全部大写
函数名不要全部大写
下面是宏的申明方式:
#define name( parament-list ) stuff其中的 parament-list 是⼀个由逗号隔开的符号表,它们可能出现在stuff中。
注意:
参数列表的左括号必须与name紧邻,如果两者之间有任何空白存在,参数列表就会被解释为stuff的一部分。
#define SQURE(n) n*n
#include<stdio.h>
int main()
{int x= 0;scanf("%d", &x);int ret=SQURE(x);printf("%d", ret);return 0;
}在以上代码在预处理之后代码就变为以下形式
那么你认为在以上我们写的宏存在什么问题吗?
如果你认为没有问题的话再看以下代码
#define SQURE(n) n*n
#include<stdio.h>
int main()
{int ret=SQURE(5+1);printf("%d", ret);return 0;
}
这时再看代码在预处理之后SQURE就变为5+1*5+1结果就为11,当问题是我们想计算的是(5+1)的平方结果为36,因此以上代码就无法满足预期
在此就有一个使用#define时要注意的点:在使用宏时不要吝啬括号,所以用于对数值表达式进行求值的宏定义都应该用这种方式加上括号,避免在使用宏时由于参数中的操作符或邻近操作符之间不可预料的相互作用。
把以上代码改为以下形式就可以实现(5+1)的平方
#define SQURE(n) ((n)*(n))
#include<stdio.h>
int main()
{int ret=SQURE(5+1);printf("%d", ret);return 0;
}再比如在以下代码中如果在宏中不加上括号就会直接将ret=10*5+5
#define DOUBLE(n) ((n)+(n))
#include<stdio.h>
int main()
{int ret=10*DOUBLE(5);printf("%d", ret);return 0;
}4. 带有副作用的宏参数
当宏参数在宏的定义中出现超过⼀次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果。副作用就是表达式求值的时候出现的永久性效果。
例如以下#define MAX用于判断两个中大的值:
#define MAX(x,y) ((x>y)?(x):(y))
#include<stdio.h>
int main()
{int a= 20;int b = 10;printf("%d", MAX(a,b));return 0;
}当像以上代码给宏传a和b时,代码能输出我们想要的结果
但如果像以下这样呢?
#define MAX(x,y) ((x>y)?(x):(y))
#include<stdio.h>
int main()
{int a= 20;int b = 10;printf("%d", MAX(a++,b++));return 0;
}这时就是将a++和b++传给了定义的宏,在预处理之后代码就变为以下形式
#include<stdio.h>
int main()
{int a= 20;int b = 10;printf("%d", ((a++>b++)?(a++):(b++)));return 0;
}输出结果就变为:
因此当在使用宏时,最好不要使得参数带有++或者--,否则可能导致不可预测的后果
5. 宏替换的规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
1. 在调用宏时,首先对参数进⾏检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
2. 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值所替换。
3. 最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重上述处理过程
例如以下代码:
#define M 100
#define MAX(x,y) ((x>y)?(x):(y))
#include<stdio.h>
int main()
{int b = 10;printf("%d", MAX(M, b));return 0;
}在调用宏MAX时先将宏内由#define定义的参数替换,这时MAX的参数就变为以下形式
MAX(100,b);
再将调用的宏替换为以下形式
((100>b)?(100):(b)) 注意:
1. 宏参数和#define 定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。
2. 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
例:
#define M 100
#define MAX(x,y) ((x>y)?(x):(y))
#include<stdio.h>
int main()
{int b = 10;printf("MAX(M, b)");return 0;
}在以上代码中最终待打印的是字符串MAX(M,100),因此字符串内的常量就不会被搜索,最终打印结果就为MAX(M,100)
6. 宏与函数的对比
例如当我们要输出两个数中大的那个数
#define MAX(x,y) ((x>y)?(x):(y))
#include<stdio.h>
int max(int x, int y)
{return x > y ? x : y;
}int main()
{int a = 20;int b = 10;int M = MAX(a, b);//使用宏printf("%d\n", M);int m = max(a, b);//使用函数printf("%d\n", m);return 0;
} 使用两种方式都可以实现要求,那么在此那种方式更好呢?
在此执行的是一个简单的运算,使用宏更合适。宏通常被应用于执行简单的运算。
那为什么不用函数来完成这个任务?
原因有二:
1. 用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和速度方面更胜一筹。
2. 更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏怎可以适用于整形、长整型、浮点型等可以用于 > 来比较的类型。宏的参数是类型无关的。
那么函数相比宏又有哪些优点呢?
1. 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
2. 宏是没法调试的。
3. 宏由于类型无关,也就不够严谨。
4. 宏可能会带来运算符优先级的问题,导致程容易出现错。
宏有时候可以做函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到。
#define MALLOC(num, type)\
(type*)malloc(num*sizeof(type))
...
//使⽤
MALLOC(10, int);//类型作为参数
//预处理器替换之后:
(int *)malloc(10 sizeof(int));| 属性 | #define定义宏 | 函数 |
| 代码长度 | 每次使用时,宏代码都会被插入到程序中。除了非常小的程序外,程序的长度都会大幅度增长 | 函数代码只出现于一个地方;每次使用函数时,都会调用那个地方的同一份代码 |
| 执行速度 | 更快 | 存在函数调用和返回的额外开销,使用相对慢一些 |
| 操作符优先级 | 宏参数的求值是在所有周围表达式的上下文环境里,除非加上括号,否则邻近操作符的优先级可能会产生不可预料的结果 | 函数参数只在函数调用的时候求值一次的结果值传递给函数。表达式的求值结果更容易预测 |
| 带有副作用的参数 | 参数可能被替换到宏体中的多个位置,如果宏的参数被多次计算,带有副作用的参数求值可能会产生不可预料的结果 | 函数传参只在传参的时候求值一次,结果更容易控制 |
| 参数类型 | 宏的参数与类型无关,只要对参数的操作是合法的,他就可以适用于任何参数类型 | 宏的参数与类型无关,只要对参数的操作是合法的,他就可以适用于任何参数类型 |
| 调试 | 宏是不方便调试的 | 函数是可以逐语句调试的 |
| 递归 | 宏是不能递归的 | 函数是可以递归的 |
7. #和##
7.1 #运算符
#运算符将宏的一个参数转换为字符串字面量。它仅允许出现在带参数的宏的替换列表中。
#运算符所执行的操作可以理解为”字符串化“。
例如以下代码
#include<stdio.h>
int main()
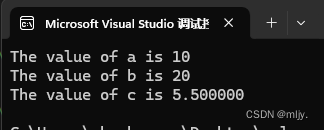
{int a = 10;printf("The value of a is %d\n", a);int b = 20;printf("The value of b is %d\n", b);float c = 5.5;printf("The value of c is %f\n", c);return 0;
}在这段代码中我们要打印的内容就只有参数和值不同,用以上这种写法就会显得很繁琐,那么有什么简洁的方法呢?
首先要知道的是在c语言中两个字符串都用双引号引起来时,两个字符串就可和为一个字符串printf("hello"" world");像以上这样就可以直接打印出hello world
了解了以上的知识点后可以试着用宏来实现简洁的写法
#define PRINTF(format,n) printf("The value of n is "format"\n", n)
#include<stdio.h>int main()
{int a = 10;PRINTF("%d", a);int b = 20;PRINTF("%d", b);float c = 5.5;PRINTF("%f", c);return 0;
}当以上代码存在一个问题是偶打印出的of后都是n,无法根据实际改变
要改变以上情况就需要用到#,将宏的一个参数转换为字符串字面量,这样就可以实现我们想要的效果了
#define PRINTF(format,n) printf("The value of "#n" is "format"\n", n) #include<stdio.h> int main() {int a = 10;PRINTF("%d", a);PRINTF("%d", b);float c = 5.5;PRINTF("%f", c);return 0; }
7.2##运算符
## 可以把位于它两边的符号合成一个符号,它允许宏定义从分离的文本片段创建标识符。 ## 被称
为记号粘合
这样的连接必须产生⼀个合法的标识符。否则其结果就是未定义的。
例如当要写两个函数分别实现求整型和浮点型中两个数中较大值
在此就可以用宏来实现函数的模板
#define DENERIC_MAX(type) \
type type##_max(type x,type y) \
{ \return x>y?x:y; \
}再使用模板就可以定义不同类型的函数
#define DENERIC_MAX(type) \
type type##_max(type x,type y) \
{ \return x>y?x:y; \
}
#include<stdio.h>DENERIC_MAX(int)
DENERIC_MAX(float)int main()
{printf("%d\n", int_max(4, 5));printf("%f\n", float_max(5.5, 4.5));return 0;
}8. #undef
这条指令用于移除一个宏定义
例如定义一个#define M 100
#define M 100
#include<stdio.h>
int main()
{#undef Mprintf("%d", M);return 0;
}运行以上代码就会出现报错,原因是#define M 100已经被移除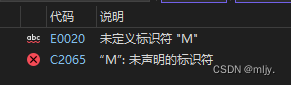
9. 命令行定义
许多C 的编译器提供了⼀种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出⼀个程序的不同版本的时候,这个特性有点用处。(假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外⼀个机器内存大些,我们需要一个数组能够大些。)
#include <stdio.h>
int main()
{
int array [ARRAY_SIZE];
int i = 0;
for(i = 0; i< ARRAY_SIZE; i ++)
{
array[i] = i;
}
for(i = 0; i< ARRAY_SIZE; i ++)
{
printf("%d " ,array[i]);
}
printf("\n" );
return 0;
}编译指令 :
//linux 环境演⽰
gcc -D ARRAY_SIZE=10 programe.c10. 条件编译
条件编译就是满足条件时参与编译,不满足就不参与编译
比如说:
调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译。
例如以下代码我们使用一个printf语句来输出程序错误时的信息,这时就可以用到条件编译
#include <stdio.h>
#define __DEBUG__
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0; i<10; i++)
{
arr[i] = i;
#ifdef __DEBUG__
printf("%d\n", arr[i]);//为了观察数组是否赋值成功。
#endif //__DEBUG__
}
return 0;
}那就来了解一些常用的条件编译指令
1. #if 常量表达式 //... #endif //常量表达式由预处理器求值。#if后常量表达式结果为真时#if到#endif内的代码内容就保留,否则就被消除
2.多个分⽀的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif3.判断是否被定义 #if defined(symbol) #ifdef symbol #if !defined(symbol) #ifndef symbol#if defined(symbol)和#ifdef symbol的功能是一样的,symbol定义了就参与编译,未定义就不参与
#if !defined(symbol)和#ifndef symbol的功能是一样的,symbol定义了就不参与编译,未定义就参与
4.嵌套指令 #if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#ifdef OPTION2unix_version_option2();#endif #elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif #endif嵌套指令在头文件中广泛的使用
11. 头文件的包含
11.1 头文件被包含的方式:
11.1.1 本地文件包含
1 #include "filename"查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。如果找不到就提示编译错误。
Linux环境的标准头文件的路径:
/usr/includeVS环境的标准头文件的路径:
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//这是VS2013的默认路径11.1.2 库文件包含
1 #include <filename.h>查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
这样是不是可以说,对于库⽂件也可以使用 “” 的形式包含?
答案是肯定的,可以,但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。
12.2 嵌套文件包含
我们已经知道, #include 指令可以使另外⼀个文件被编译。就像它实际出现于 #include 指令的
地方⼀样。
test.c
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
int main()
{
return 0;
}test.h
void test();
struct Stu
{
int id;
char name[20];
};如果直接这样写,test.c⽂件中将test.h包含5次,那么test.h⽂件的内容将会被拷贝5份在test.c中。
如果test.h 文件比较大,这样预处理后代码量会剧增。如果⼯程⽐较大,有公共使用的头件,被⼤家都能使用,⼜不做任何的处理,那么后果真的不堪设想。
如何解决头文件被重复引入的问题?答案:条件编译。
#ifndef __TEST_H__
#define __TEST_H__
void test();
struct Stu
{
int id;
char name[20];
};
#endif在此就可以让test.h在第一次时#define __TEST_H__之后再调用test.h就不会再将内容在test.c内展开
#pragma once在此使用#pragma once也可以实现以上同样的效果,这样就可以避免头文件的重复引入。
13. 其他预处理指令
#error
#pragma
#line
...#pragma pack()在结构体部分介绍过相关文章:
深入理解预处理
1.预定义符号 C语言设置了⼀些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的。 __FILE__ //进⾏编译的源⽂件 __LINE__ //⽂件当前的⾏号 __DATE__ //⽂件被编译的⽇期 __TIME__ //⽂件被编译的时间 __STDC__ //如果编译器遵循ANSI C&…...

DSP28335:定时器
1.定时器介绍 1.1 定时器工作原理 TMS320F28335的CPU Time有三个,分别为Timer0,Timer1,Timer2,其中Timer2是为操作系统DSP/BIOS保留的,当未移植操作系统时,可用来做普通的定时器。这三个定时器的中断信号分…...

系统架构理解
一、统一提前查好所有数据后续逻辑用到啥取啥,还是等用到对应数据的时候再查 1、用到啥查啥: 优势:减少依赖调用次数,减轻服务器压力;代码逻辑清晰,没有太多分支判断 劣势:无法避免串行调用&am…...

uni-app页面的跳转三种方式,功能作用有什么区别?
一、三种方式的作用 1、uni.reLaunch 作用是关闭所有页面,然后打开新的页面 类似于重新启动应用,打开的页面栈会被清空,只显示新打开的页面。使用uni.reLaunch方法可以实现整个应用的重定向 uni.reLaunch({url: /pages/login/login }) 2、…...
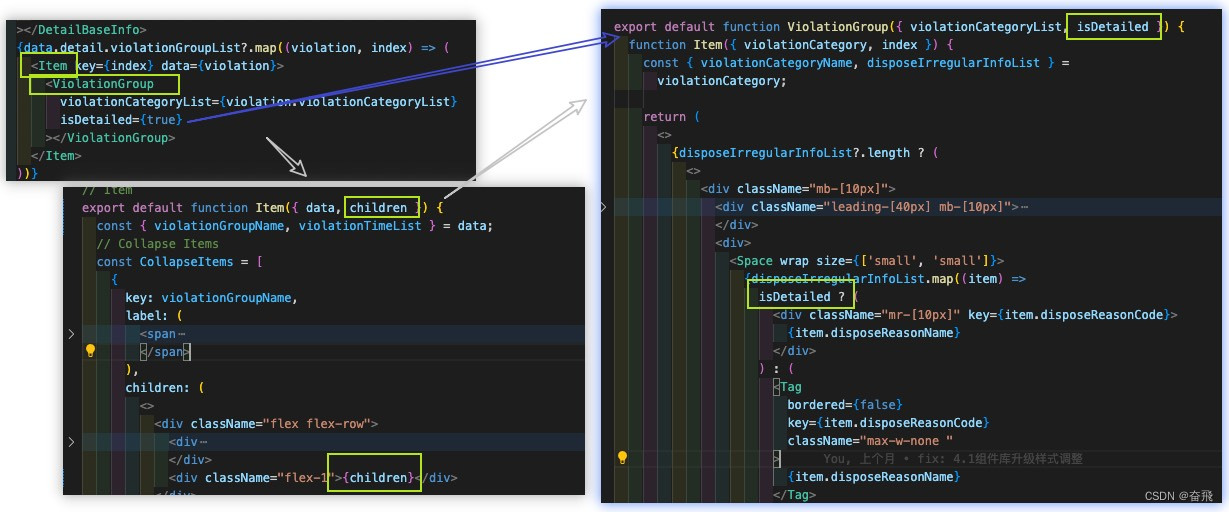
React 通信:深层传递(Props、Context、Children Jsx)
在之前的文章 探讨:围绕 props 阐述 React 通信 中总结了关于“父子”组件传值,但是当需要在组件树中深层传递参数以及需要在组件间复用相同的参数时,传递 props 就会变得很麻烦。 实际案例: 下述展示有两种状态:① 详…...

《Windows API每日一练》5.1 键盘基础
本节我们讲述关于键盘的一些基础知识。当我们按下一个键盘按键时,会产生一个键盘按键消息。这一点你能确定吗?假如是一个菜单快捷键消息,或者是一个子窗口控件消息呢?这就超出了本节讨论的范围,我们将在菜单和子窗口控…...
方法总结)
Class.forName()方法总结
Class.forName()方法总结 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!Class.forName()方法是Java反射机制中的一个重要方法,它用于动态加载类并返…...

Python | Leetcode Python题解之第168题Excel表列名称
题目: 题解: class Solution:def convertToTitle(self, columnNumber: int) -> str:ans list()while columnNumber > 0:columnNumber - 1ans.append(chr(columnNumber % 26 ord("A")))columnNumber // 26return "".join(an…...

【ARMv8/ARMv9 硬件加速系列 3.5.2 -- SVE 向量寄存器 有多少位数?】
文章目录 SVE 向量寄存器SVE 向量寄存器大小SVE 可伸缩性的好处SVE 寄存器长度示例SVE 向量寄存器 在 ARMv9 架构中,包括其 Scalable Vector Extension (SVE) 和 Scalable Vector Extension 2 (SVE2) 的增强,向量寄存器(通常称为 Z 寄存器)的大小设计为可伸缩的,以便在不…...
)
Vulkan入门系列2- 绘制三角形(未完待续)
概述: Vulkan的学习曲线是比较陡峭的,学习Vulkan刚开始像是在爬一个陡坡,等上了这个陡坡之后,后面学习曲线就相对比较平缓了。那么在Vulkan中绘制一个三角形,就相当于是在爬这样一个陡坡,因为绘制三角形需…...
企业UDP文件传输工具测速的方式(下)
在前一篇文章中,我们深入讨论了UDP传输的基本概念和镭速UDP文件传输工具如何使用命令行快速进行速度测试。现在,让我们进一步探索更为高级和灵活的方法,即通过整合镭速UDP的动态或静态库来实现网络速度的测量,以及如何利用这一过程…...

Artalk-CORS,跨域拦截问题
今天重新部署Artalk之后,遇到了CORS——跨域拦截的问题,卡了好一会记录一下。 起因 重新部署之后,浏览器一直提示CORS,之前在其他项目也遇到过类似的问题,原因就在于跨域问题。...

SSL证书怎样配置部署更安全?
在互联网上,SSL证书是用于加密网站与用户之间传输的数据的一种数字证书。它通过建立安全的连接,确保网站的身份和保护用户的隐私,是网站安全的重要组成部分。然而,要想让SSL证书发挥最大的作用,除了检查证书是否过期外…...
M1失效后,哪个是观察A股的关键新指标?
M1失效后,哪个是观察A股的关键新指标? 央地支出增速差(地方-中央支出增速的差值)或许是解释沪深300定价更有效的前瞻指标。该数值扩张,则有利于大盘指数,反之亦然,该指标从2017年至今对大盘指数…...
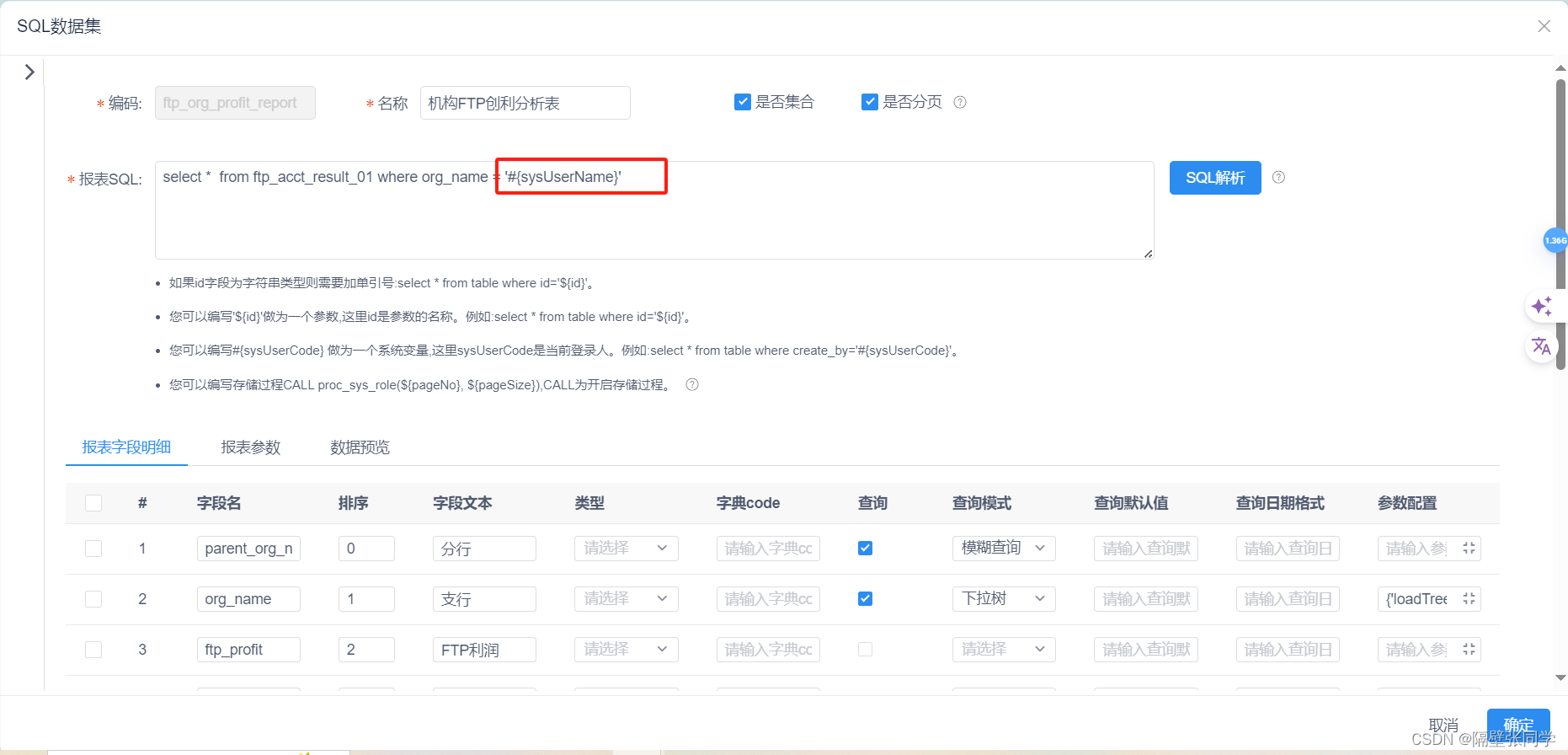
springboot集成积木报表,怎么将平台用户信息传递到积木报表
springboot集成积木报表后怎么将平台用户信息传递到积木报表 起因是因为需要研究在积木报表做数据筛选的时候需要拿到系统当前登录用户信息做筛选新的模块 起因是因为需要研究在积木报表做数据筛选的时候需要拿到系统当前登录用户信息做筛选 官网有详细介绍怎么集成进去的&…...

Spring Bean详解
Spring Bean作用域 默认情况下,所有的 Spring Bean 都是单例的,也就是说在整个 Spring 应用中, Bean 的实例只有一个 如果我们需要创建多个实例的对象,那么应该将 Bean 的 scope 属性定义为 prototype,如果 Spring 需…...
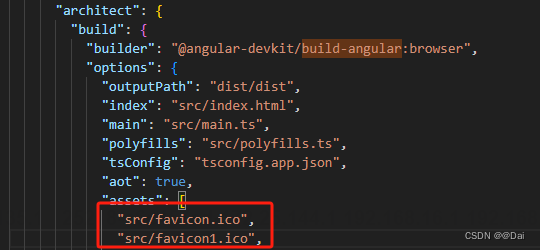
前端根据环境变量配置网页的title和favicon
前端根据环境变量配置网页的title和favicon 前言流程步骤一、设置environment文件二、在入口文件中配置三、删除index.html中的title和 icon link四、使用对应的打包命令进行部署 注意事项一、angular中,需要在angular.json添加favicon.ico额外的构建 前言 有些项目…...

服务器负载均衡
什么是服务器负载 1. 常见理解的平均负载 每次发现系统变慢时,我们通常做的第一件事,就是执行 top 或者 uptime 命令,来了解系统的负载情况。比如下列情况 [rootkube-node1 ~]# uptime09:44:37 up 74 days, 11:53, 1 user, load average:…...
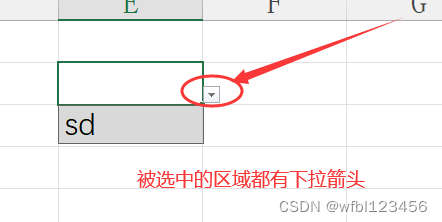
如何设置Excel单元格下拉列表
如何设置Excel单元格下拉列表 在Excel中设置单元格下拉列表可以提高数据输入的准确性和效率。以下是创建下拉列表的步骤: 使用数据验证设置下拉列表: 1. 选择单元格: 选择你想要设置下拉列表的单元格或单元格区域。 2. 打开数据验证&…...

红队内网攻防渗透:内网渗透之Linux内网权限提升技术:LXDDockerRbash限制型bash
红队内网攻防渗透 1. 内网权限提升技术1.1 Linux系统提权-普通用户-LXD容器1.2 Linux系统提权-普通用户-Docker容器1.3 权限在docker里面1.4 Linux系统提权-普通用户-Rbash限制型bash1. 内网权限提升技术 利用参考 https://gtfobins.github.io/LXD、LXC 和 Docker 是三种不同…...

MAI-UI-8B部署全攻略:开箱即用,快速体验GUI智能体强大功能
MAI-UI-8B部署全攻略:开箱即用,快速体验GUI智能体强大功能 1. 认识MAI-UI-8B:能"动手"的AI智能体 大多数AI助手只能回答问题或生成内容,而MAI-UI-8B却能做到真正意义上的"动手操作"。这是一个能够理解图形用…...

nomic-embed-text-v2-moe保姆级教程:Gradio自定义CSS主题与响应式布局
nomic-embed-text-v2-moe保姆级教程:Gradio自定义CSS主题与响应式布局 1. 从零开始:认识nomic-embed-text-v2-moe 如果你正在寻找一个既强大又好用的文本嵌入模型,特别是需要处理多语言内容,那么nomic-embed-text-v2-moe绝对值得…...

OpenClaw配置备份指南:GLM-4.7-Flash环境快速迁移方案
OpenClaw配置备份指南:GLM-4.7-Flash环境快速迁移方案 1. 为什么需要环境迁移? 上周我的主力开发机突然硬盘故障,导致精心配置的OpenClaw环境全部丢失。重装后发现要重新对接GLM-4.7-Flash模型、配置飞书通道、安装十几个自定义技能——这个…...
)
用51单片机+无源蜂鸣器播放《两只老虎》完整教程(附代码与乐理速成)
用51单片机驱动无源蜂鸣器演奏《两只老虎》全流程解析 第一次听到单片机播放音乐时,那种"机器唱歌"的奇妙感至今难忘。作为电子爱好者入门必备的趣味项目,用蜂鸣器演奏音乐不仅能巩固定时器、中断等核心知识,更能将枯燥的理论转化为…...

大模型私有化不是选型,是生存!Python工程师必须在Q3前掌握的5类国产化适配方案,否则明年项目全卡审批
第一章:大模型私有化是Python工程师的生存分水岭当企业开始将大语言模型从公有云API转向本地GPU集群部署,Python工程师的角色正经历一次静默但深刻的重构——不再只是调用requests.post()封装接口,而是要亲手构建模型加载、推理服务、权限控制…...

【LAMMPS实战】从文献到模拟:精准定位与获取ReaxFF反应力场参数文件
1. 初识ReaxFF反应力场:为什么我们需要它? 第一次接触分子动力学模拟时,我完全被各种力场搞晕了。直到遇到需要模拟化学反应的情况,才发现普通的力场根本不够用。这时候ReaxFF反应力场就像救命稻草一样出现了。简单来说࿰…...

实战指南:在Kali Linux上构建HexStrike AI与Trae MCP的智能安全联动平台
1. 环境准备与基础配置 在Kali Linux上构建HexStrike AI与Trae MCP的智能安全联动平台,首先需要确保基础环境配置正确。我建议使用物理机直接安装Kali Linux,相比虚拟机方案能获得更好的性能表现,特别是在处理大规模安全扫描任务时。如果确实…...

各向异性方解石晶体的双折射效应
1. 摘要 双折射效应是各向异性材料最重要的光学特性,并广泛应用于多种光学器件。当入射光波撞击各向异性材料,会以不同的偏振态分束到不同路径,即众所周知的寻常光束和异常光束。在本示例中,描述了如何利用VirtualLab Fusion对双折…...
)
GD32F4开发板GD-LINK驱动安装与Keil配置全攻略(附常见问题解决)
GD32F4开发板GD-LINK驱动安装与Keil配置全攻略(附常见问题解决) 第一次拿到GD32F4开发板时,很多开发者都会遇到驱动安装失败、Keil识别不到芯片的问题。这些问题看似简单,却可能让新手折腾好几个小时。本文将用最直白的方式&#…...

ClawdBot实战教程:零基础搭建个人AI助手的完整流程
ClawdBot实战教程:零基础搭建个人AI助手的完整流程 1. ClawdBot简介:你的本地AI助手 ClawdBot是一个可以在个人设备上运行的AI助手解决方案,基于vLLM提供后端模型能力。与常见的云端AI服务不同,它完全运行在本地环境中ÿ…...