Python学习打卡:day10
day10
笔记来源于:黑马程序员python教程,8天python从入门到精通,学python看这套就够了
目录
- day10
- 73、文件的读取操作
- 文件的操作步骤
- open()打开函数
- mode常用的三种基础访问模式
- 读操作相关方法
- read()方法
- readlines()方法
- readline()方法
- for循环读取文件行
- close() 关闭文件对象
- with open 语法
- 操作汇总
- 74、文件读取的课后练习
- 字符串的 count 方法
- 字符串的规整操作(去前后指定字符串)
- 75、文件的写操作
- 76、文件的追加写入操作
- 77、文件操作的综合案例
- 78、了解异常
- 79、异常的捕获
- 捕获常规异常
- 捕获指定异常
- 捕获多个异常
- 捕获异常并输出描述信息
- 捕获所有异常
- 异常else
- 异常的finally
- 80、异常的传递性
- 81、模块的概念和导入
- 模块的导入方式
- import模块名
- from 模块名 import 功能名
- from 模块名 import *
- as 定义别名
- 82、自定义模块并导入
- 测试模块
- \_\_all\_\_
73、文件的读取操作
文件操作主要包括打开、关闭、读、写等操作。
文件的操作步骤
- 打开文件
- 读写文件
- 关闭文件
tips:可以只打开和关闭文件,不进行任何读写
open()打开函数
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
open(name, mode, encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)。
示例代码:
# 打开文件
f = open('71_测试.txt', 'r', encoding='UTF-8')
# w 和 a 模式下会自动创建,r 模式下则不能
f = open('/home/yin-roc/71_测试.txt', 'w', encoding='UTF-8')
print(type(f))# 结果
<class '_io.TextIOWrapper'>
tips:此时的 f 是 open 函数的文件对象,对象是 Python 中一种特殊的数据类型,拥有属性和方法,可以使用对象属性或对象方法对其进行访问。
mode常用的三种基础访问模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。 如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。 如果该文件不存在,创建新文件进行写入。 |
读操作相关方法
read()方法
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
示例代码:
# 读取文件 - read()
print(f"读取 10 个字节的结果:{f.read(10)}")# 连续两次 read,会从上一次读完的结尾开始读。
print(f"read 方法读取全部内容的结果:{f.read()}")# 结果
读取 10 个字节的结果:1234567890
read 方法读取全部内容的结果:
abcdefg
hijklmn
你好呀
readlines()方法
文件对象.readlines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
示例代码:
# 读取文件 - readlines()
lines = f.readlines()
print(f"lines 对象的类型:{type(lines)}")
print(f"lines 对象的内容:{lines}")# 结果
lines 对象的类型:<class 'list'>
lines 对象的内容:['1234567890\n', 'abcdefg\n', 'hijklmn\n', '你好呀\n']
readline()方法
一次读取一行内容。
# 读取文件 - readline()
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f"第一行数据是:{line1}")
print(f"第二行数据是:{line2}")
print(f"第三行数据是:{line3}")# 结果
第一行数据是:1234567890第二行数据是:abcdefg第三行数据是:hijklmnfor循环读取文件行
# for 循环读取文件行
for line in f:print(f"每一行数据是:{line}")
# 每一个line临时变量,就记录了文件的一行数据# 结果
每一行数据是:1234567890每一行数据是:abcdefg每一行数据是:hijklmn每一行数据是:你好呀
close() 关闭文件对象
- 最后通过 close,关闭文件对象,也就是关闭对文件的占用
- 如果不调用 close,同时程序没有停止运行,那么这个文件将一直被 Python 程序占用。
# 文件的关闭
f.close()
time.sleep(5) # 延时 5 s
with open 语法
- 通过在 with open 的语句块中对文件进行操作
- 可以在操作完成后自动关闭 close 文件,避免遗忘掉 close 方法
with open('71_测试.txt', 'r', encoding='UTF-8') as f:for line in f:print(f"每一行数据是: {line}")
time.sleep(5)
操作汇总
| 操作 | 功能 |
|---|---|
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
74、文件读取的课后练习
72_word.txt 内容如下:
itheima itcast python
itheima python itcast
beijing shanghai itheima
shenzhen guangzhou itheima
wuhan hangzhou itheima
zhengzhou bigdata itheima
示例代码:
# 自写
f = open("72_word.txt", "r", encoding="UTF-8")
count = 0
for lines in f:eachline = lines.replace("\n", "").split(" ")i = 0print(eachline)while i < len(eachline):if eachline[i] == "itheima":count += 1i += 1
print(f"itheima 单词出现的次数:{count}")
f.close()# 方式1:读取全部内容,以读取模式打开
f = open("72_word.txt", "r", encoding="UTF-8")
content = f.read()
count = content.count("itheima")
print(f"itheima 单词出现的次数:{count}")# 方式2:读取内容,一行一行读取
count = 0
f = open("72_word.txt", "r", encoding="UTF-8")
for line in f:line = line.strip() # 去除开头和结尾的空格及换行符words = line.split(" ")# 判断单词出现次数并累计
for word in words:if word == "itheima":count += 1
print(f"itheima 单词出现的次数:{count}")
# 关闭文件
f.close()# 结果
itheima 单词出现的次数:6
tips:
这里主要涉及几个方法的使用,简化了代码,比自写的代码要简洁许多:
字符串的 count 方法
统计字符串中某字符串的出现次数
语法:字符串.count(字符串)

字符串的规整操作(去前后空格及换行符)
语法:字符串.strip()

字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)

注意,传入的是“12” 其实就是:”1”和”2”都会移除,是按照单个字符。
75、文件的写操作
基本语法格式:
# 1. 打开文件
f = open('python.txt', 'w')# 2.文件写入
f.write('hello world')# 3. 内容刷新
f.flush()
tips:
- 直接调用 write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区;
- 当调用 flush 的时候,内容会真正写入文件;
- close 方法,内置了 flush 功能
- 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)。
示例代码:
1、打开一个未存在的文件:
"""
演示 对文件的写入
"""
import time# 打开不存在的文件
f = open("73_test.txt", "w", encoding="UTF-8")
# write 写入
f.write("Hello World")# flush 刷新
# f.flush()time.sleep(5)# close 关闭
f.close() # close 方法,内置了 flush 功能
2、打开一个已经存在的文件
# 打开一个存在的文件
f = open("73_test.txt", "w", encoding="UTF-8")
# write 写入 flush 刷新
f.write("黑马程序员")
# close关闭
f.close()
tips:
- 文件如果不存在,使用 “w” 模式,会创建新文件;
- 文件如果存在,使用 “w” 模式,会将原有内容清空;
- close() 方法,带有 flush() 方法的功能。
76、文件的追加写入操作
基本语法格式:
# 1. 打开文件,通过a模式打开即可
f = open('python.txt', 'a')# 2.文件写入
f.write('hello world')# 3. 内容刷新
f.flush()
tips:
- a模式,文件不存在会创建文件;
- a模式,文件存在会在最后,追加写入文件。
示例代码:
1、打开一个不存在的文件:
# 打开不存在的文件
f = open("74_test.txt", "a", encoding="UTF-8")# write 写入
f.write("黑马程序员")# flush 刷新
f.flush()# close 关闭
f.close()
2、打开一个存在的文件:
# 打开一个存在的文件
f = open("74_test.txt", "a", encoding="UTF-8")# write 写入 flush 刷新
f.write("\n学Python最佳选择")# close关闭
f.close()
77、文件操作的综合案例
需求:有一份账单文件,记录了消费收入的具体记录,内容如下:
name,date,money,type,remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式
同学们可以将内容复制并保存为 bill.txt文件。
我们现在要做的就是:
- 读取文件;
- 将文件写出到bill.txt.bak文件作为备份;
- 同时,将文件内标记为测试的数据行丢弃。
# 自写
f_r = open("75_bill.txt", "r", encoding="UTF-8")
f_w = open("75_bill.txt.bak", "a", encoding="UTF-8")for line in f_r:str = line.strip().split(",")flag = Truefor element in str:if element == '测试':flag = Falseif flag == True:f_w.write(line)f_r.close()
f_w.close()
# 视频方法:减少了复杂度,但是通用性不是很高
f_r = open("75_bill.txt", "r", encoding="UTF-8")
f_w = open("75_bill.txt.bak", "a", encoding="UTF-8")for line in f_r:line = line.strip()if line.strip(",")[4] == "测试":continuef_w.write(line)f_w.write("\n")f_r.close()
f_w.close()
78、了解异常
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的==“异常”==,也就是我们常说的 BUG。
79、异常的捕获
当我们的程序遇到了BUG, 那么接下来有两种情况:
- 整个程序因为一个BUG停止运行;
- 对BUG进行提醒,整个程序继续运行。
显然在之前的学习中,我们所有的程序遇到 BUG 就会出现1的这种情况,也就是整个程序直接奔溃。
但是在真实工作中,我们肯定不能因为一个小的 BUG 就让整个程序全部奔溃,也就是我们希望的是达到2的这种情况,那这里我们就需要使用到捕获异常。
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
捕获常规异常
基本语法:
try:可能发生错误的代码
except:如果出现异常执行的代码
示例:
# 基本捕获语法
try:f = open("76_abc.txt", "r", encoding="UTF-8")
except:print("出现异常了,因为文件不存在,我将open的模式,改为w模式去打开")f = open("76_abc.txt", "w", encoding="UTF-8")# 结果
出现异常了,因为文件不存在,我将open的模式,改为w模式去打开
捕获指定异常
基本语法:
try:print(name)
except NameError as e:print("出现了变量未定义的异常")print(e)# 结果
出现了变量未定义的异常
name 'name' is not defined
tips:
- 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
- 一般try下方只放一行尝试执行的代码。
捕获多个异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写。
基本语法:
try:print(1/0)
except (NameError, ZeroDivisionError):print('ZeroDivision错误...')
示例代码:
# 捕获多个异常
try:# 1 / 0print(name)pass
except(NameError, ZeroDivisionError) as e:print("出现了变量未定义 或者 除以 0 的异常错误")# 结果
出现了变量未定义 或者 除以 0 的异常错误
捕获异常并输出描述信息
基本语法:
try:print(num)
except (NameError, ZeroDivisionError) as e:print(e)
捕获所有异常
基本语法:
try:print(name)
except Exception as e:print(e)
异常else
else表示的是如果没有异常要执行的代码。
try:print(1)
except Exception as e:print(e)
else:print('我是else,是没有异常的时候执行的代码')
异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件。
try:f = open('test.txt', 'r')
except Exception as e:f = open('test.txt', 'w')
else:print('没有异常,真开心')
finally:f.close()
示例代码:
# 捕获所有异常
try:f = open("76_abc.txt", "r", encoding="UTF-8")# 1/0# print(name)except Exception as e:print("出现异常了")f = open("76_abc.txt", "w", encoding="UTF-8")
else:print("好高兴,没有异常")
finally:print("我是finally,有没有异常我都要执行")f.close()
80、异常的传递性
异常是具有传递性的
当函数 func01 中发生异常,并且没有捕获处理这个异常的时候,异常会传递到函数func02,当 func02 也没有捕获处理这个异常的时候
main函数会捕获这个异常, 这就是异常的传递性。
提示:当所有函数都没有捕获异常的时候, 程序就会报错

示例代码:
"""
演示异常的传递性
"""# 定义一个出现异常的方法
def func1():print("func1 开始执行")num = 1 / 0 # 肯定有异常,除以 0 的异常print("func1 结束执行")# 定义一个无异常的方法,调用上面的方法
def func2():print("func2 开始执行")func1()print("func2 结束执行")# 定义一个方法,调用上面的方法
def main():try:func2()except Exception as e:print(f"出现异常了,异常信息是:{e}")main()
81、模块的概念和导入
Python 模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码.
模块的作用:python中有很多各种不同的模块,每一个模块都可以帮助我们快速的实现一些功能,比如实现和时间相关的功能就可以使用time模块。
我们可以认为一个模块就是一个工具包,每一个工具包中都有各种不同的工具供我们使用进而实现各种不同的功能。
模块的导入方式
基本语法格式:

常用的组合形式如:
- import 模块名;
- from 模块名 import 类、变量、方法等;
- from 模块名 import *;
- import 模块名 as 别名;
- from 模块名 import 功能名 as 别名。
import模块名
基本语法格式:
import 模块名
import 模块名1,模块名2模块名.功能名()
示例代码:
# 使用 python 导入 time 模块使用 sleep 功能(函数)
import time # 导入 Python 内置的 time 模块 (time.py这个代码文件)print("你好")
time.sleep(5) # 通过 "." 就可以使用模块内部的全部功能(类\函数\变量)
print("我好")
from 模块名 import 功能名
基本语法格式:
from 模块名 import 功能名功能名()
示例代码:
# 使用 from 导入 time 模块,使用 sleep 功能 (函数)
from time import sleep
print("nihao")
sleep(5)
print("wohao")
from 模块名 import *
基本语法格式:
from 模块名 import *功能名()
示例代码:
# 使用 * 导入 time 模块的全部功能
from time import * # *:表示全部的意思
print("nihao")
sleep(5)
print("wohao")
as 定义别名
基本语法格式:
# 模块定义别名
import 模块名 as 别名
# 功能定义别名
from 模块名 import 功能 as 别名
示例代码:
# 使用 as 给特定功能加上别名
import time as t
print("你好")
t.sleep(5)
print("我好")
from time import sleep as sl # *:表示全部的意思
print("nihao")
sl(5)
print("wohao")
82、自定义模块并导入
Python中已经帮我们实现了很多的模块。不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现,也就是自己制作一个模块。
案例:新建一个Python文件,命名为my_module1.py,并定义test函数


tips: 每个Python文件都可以作为一个模块,模块的名字就是文件的名字。也就是说自定义模块名必须要符合标识符命名规则。
测试模块
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如,在my_module1.py文件中添加测试代码test(1,1)。
def test(a, b):print(a + b)test(1, 1)
问题:
此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行test 函数的调用。
解决方案:
def test(a, b):print(a + b)# 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行test函数调用
if __name__ == '__main__':test (1, 1)
tips:

注意事项:当导入多个模块的时候,且模块内有同名功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能
__all__
如果一个模块文件中有 __all__ 变量,当使用 from xxx import * 导入时,只能导入这个列表中的元素。


相关文章:
Python学习打卡:day10
day10 笔记来源于:黑马程序员python教程,8天python从入门到精通,学python看这套就够了 目录 day1073、文件的读取操作文件的操作步骤open()打开函数mode常用的三种基础访问模式读操作相关方法read()方法readlines()方法readline()方法for循…...
新书速览|Ubuntu Linux运维从零开始学
《Ubuntu Linux运维从零开始学》 本书内容 Ubuntu Linux是目前最流行的Linux操作系统之一。Ubuntu的目标在于为一般用户提供一个最新的、相当稳定的、主要由自由软件构建而成的操作系统。Ubuntu具有庞大的社区力量,用户可以方便地从社区获得帮助。《Ubuntu Linux运…...
[Qt的学习日常]--窗口
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、窗口的分…...
Vue发送http请求
1.创建项目 创建一个新的 Vue 2 项目非常简单。在终端中,进入您希望创建项目的目录(我的目录是D:\vue),并运行以下命令: vue create vue_test 2.切换到项目目录,运行项目 运行成功后,你将会看到以下的编译成功的提示…...
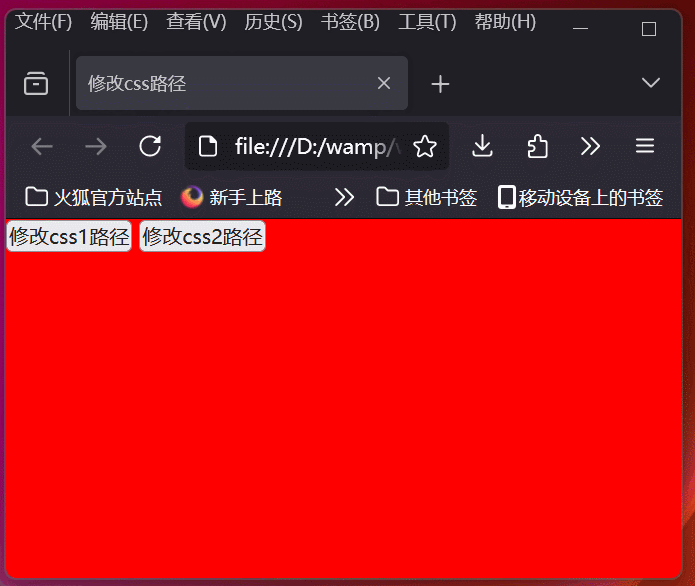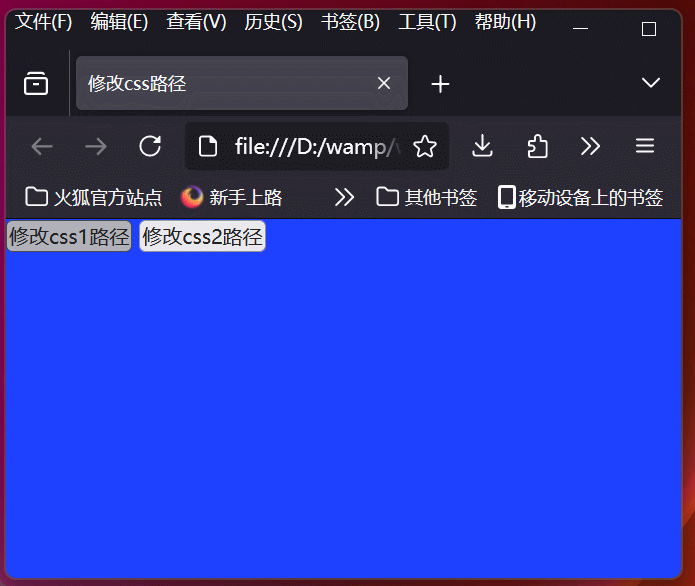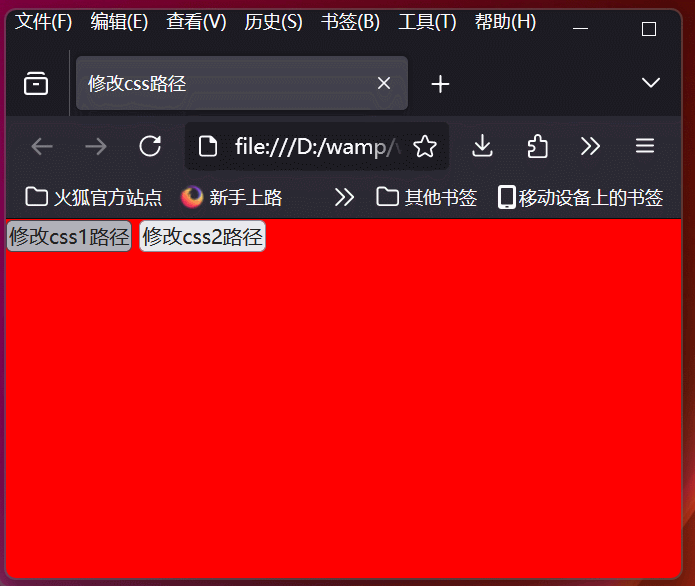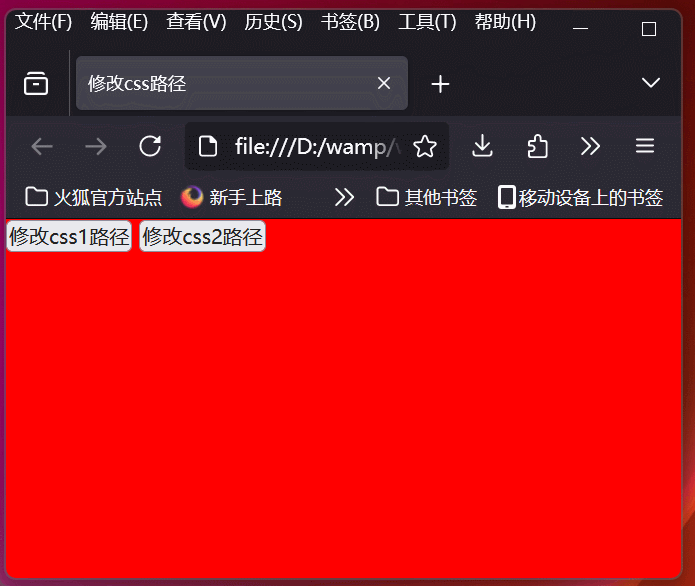
学习使用js和jquery修改css路径,实现html页面主题切换功能
学习使用js和jquery修改css路径,实现html页面主题切换功能 效果图html代码js切换css关键代码jquery切换css关键代码 效果图 html代码 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>修改css路径</title&g…...
请介绍一下Redis的数据淘汰策略)
(转)请介绍一下Redis的数据淘汰策略
1. **NoEviction(不淘汰)**:当内存不足时,直接返回错误,不淘汰任何数据。该策略适用于禁止数据淘汰的场景,但需要保证内存足够。 2. **AllKeysLFU(最少使用次数淘汰)**:…...

APP自动化测试-Appium常见操作之详讲
一、基本操作 1、点击操作 示例:element.click() 针对元素进行点击操作 2、初始化:输入中文的处理 说明:如果连接的是虚拟机(真机无需加这两个参数,加上可能会影响手工输入),在初始化配置中…...

写给大数据开发:谈谈数仓建模的反三范式
在数仓建设中,我们经常谈论反三范式。顾名思义,反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。简单来说,就是浪费存储空间,节省查询时间。用行话讲,这就是以空间换时间。听起来像是用大炮打蚊子&#…...

Stable diffusion 3 正式开源
6月12日晚,著名开源大模型平台Stability AI正式开源了,文生图片模型Stable Diffusion 3 Medium(以下简称“SD3-M”)权重。 SD3-M有20亿参数,平均生成图片时间在2—10秒左右推理效率非常高,同时对硬件的需求…...
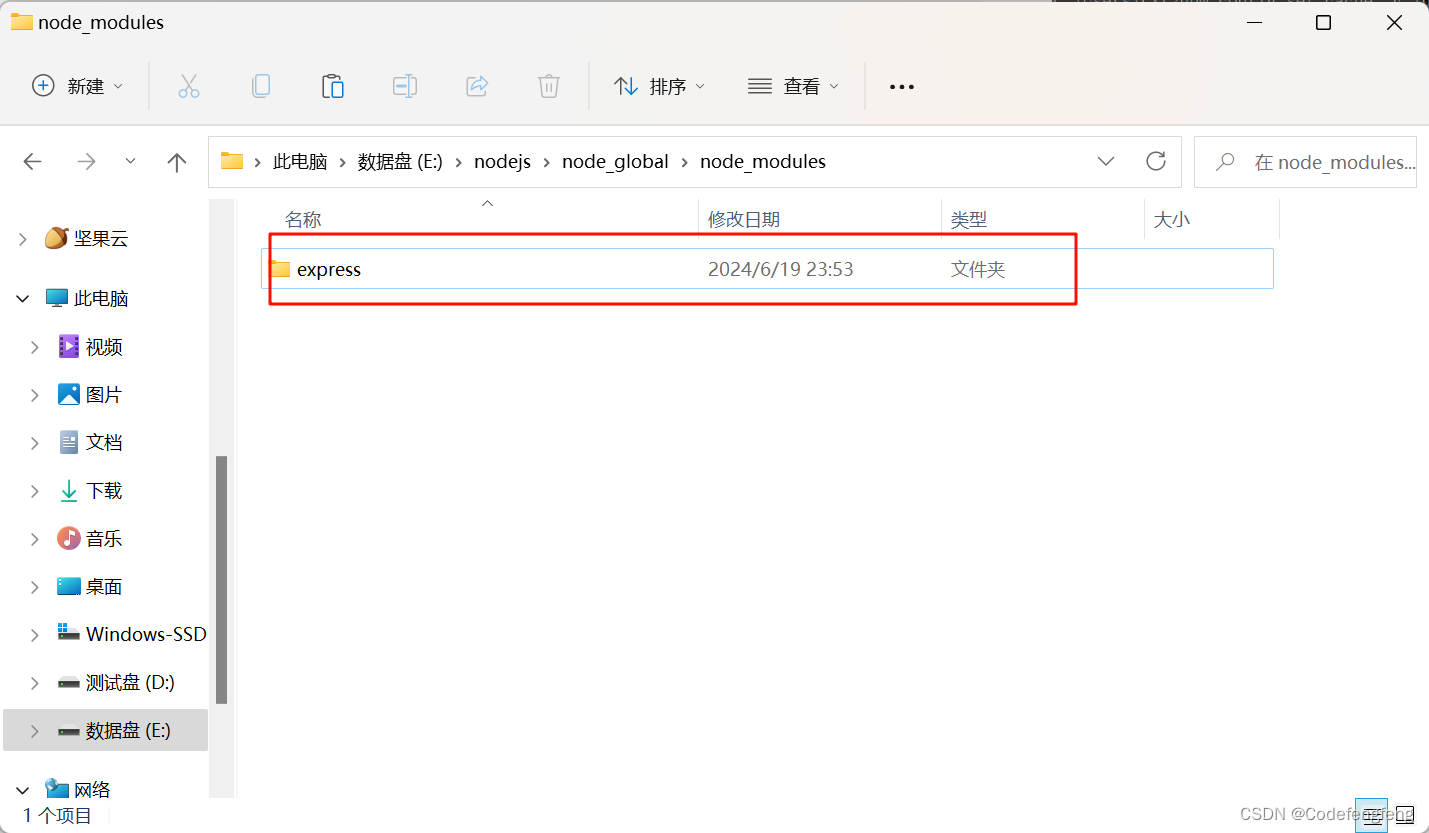
如何配置node.js环境
文章目录 step1. 下载node.js安装包step2. 创建node_global, node_cache文件夹step3.配置node环境变量step3. cmd窗口检查安装的node和npm版本号step4. 设置缓存路径\全局安装路径\下载镜像step5. 测试配置的nodejs环境 step1. 下载node.js安装包 下载地址:node.js…...

python tensorflow 各种神经元
感知机神经元(Perceptron Neuron): 最基本的人工神经元模型,用于线性分类任务。 import numpy as npclass Perceptron:def __init__(self, input_size, learning_rate0.01, epochs1000):self.weights np.zeros(input_size 1) #…...

Gone框架介绍27 - 再讲 Goner 和 依赖注入
gone是可以高效开发Web服务的Golang依赖注入框架 github地址:https://github.com/gone-io/gone 文档地址:https://goner.fun/zh/ 文章目录 Goner 和 依赖注入Goner的定义依赖标记Goners 注册Priest函数 Goner 和 依赖注入 Gone 作为一个依赖注入框架&am…...
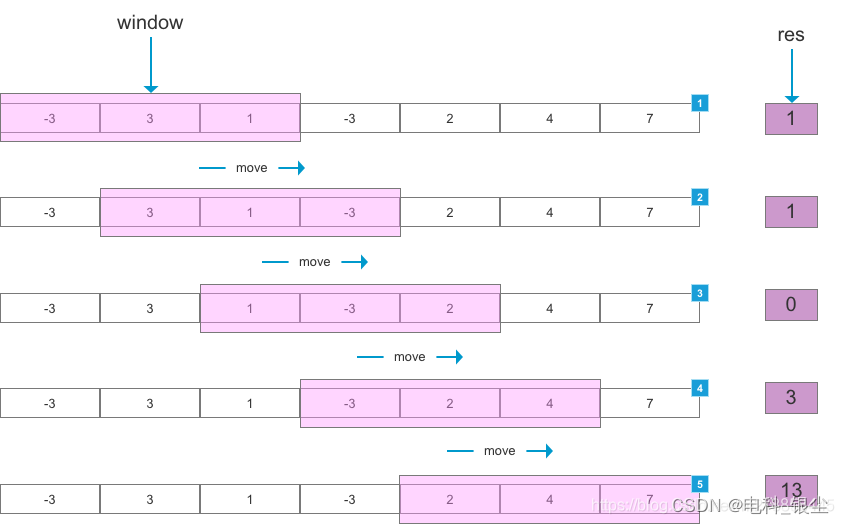
【Python/Pytorch 】-- 滑动窗口算法
文章目录 文章目录 00 写在前面01 基于Python版本的滑动窗口代码02 算法效果 00 写在前面 写这个算法原因是:训练了一个时序网络,该网络模型的时序维度为32,而测试数据的时序维度为90。因此需要采用滑动窗口的方法,生成一系列32…...

Clickhouse集群create drop database可删除集群数据库或只删除本地数据库
集群环境下,在任意一个节点创建数据库,如果加上了ON CLUSTER clustername,则在集群环境的所有节点上都创建了该数据库,并在集群环境的所有节点上都创建了该数据库对应的目录,且数据库的metadata_path对应的目录路径在所…...

【docker】adoptopenjdk/openjdk8-openj9:alpine-slim了解
adoptopenjdk/openjdk8-openj9:alpine-slim 是一个 Docker 镜像的标签,它指的是一个特定的软件包,用于在容器化环境中运行 Java 应用程序。 镜像相关的网站和资源: AdoptOpenJDK 官方网站 - AdoptOpenJDK 这是 AdoptOpenJDK 项目的官方网站&…...

Vscode interaction window
python 代码关联到 jupyter 模式 在代码前添加: # %%print("hellow wolrd!") 参考文档链接: https://code.visualstudio.com/docs/python/jupyter-support-py...
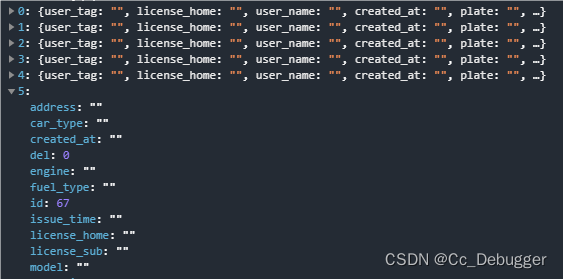
后端数据null前端统一显示成空
handleNullValues方法在封装请求接口返回数据时统一处理 // null 转 function handleNullValues(data) {// 使用递归处理多层嵌套的对象或数组function processItem(item) {if (Array.isArray(item)) {return item.map(processItem);} else if (typeof item object &&…...
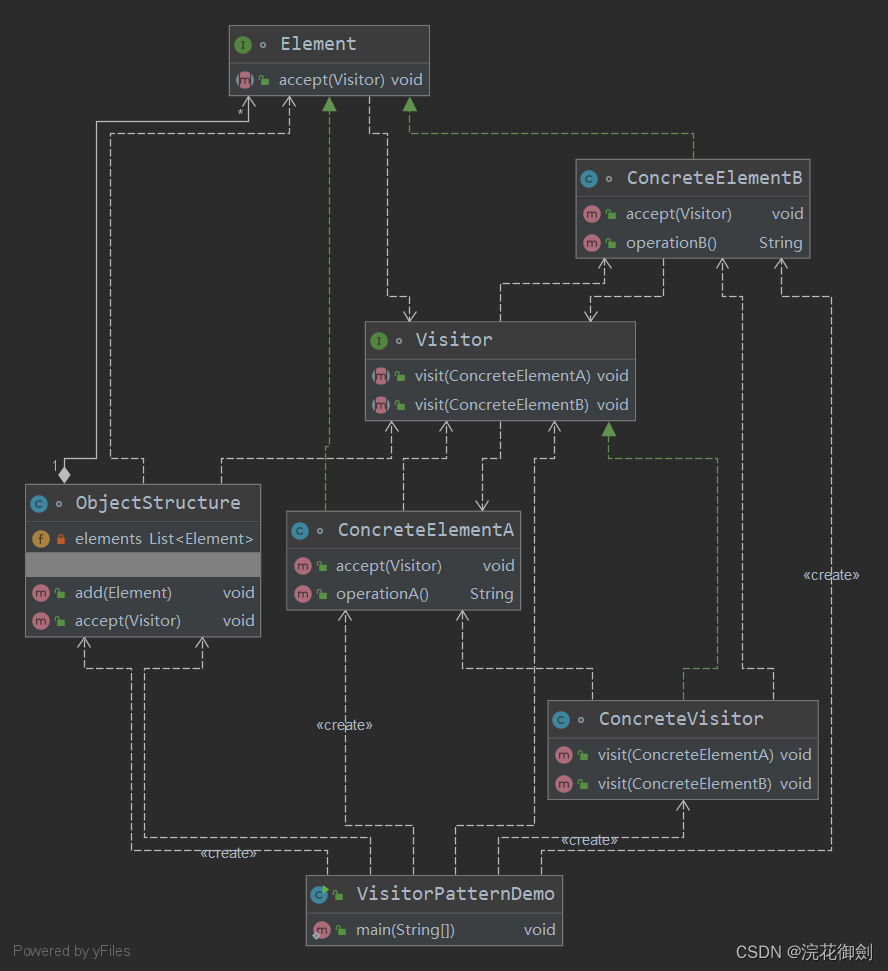
【设计模式深度剖析】【9】【行为型】【访问者模式】| 以博物馆的导览员为例加深理解
👈️上一篇:备忘录模式 | 下一篇:状态模式👉️ 设计模式-专栏👈️ 文章目录 访问者模式定义英文原话直译如何理解呢? 访问者模式的角色类图代码示例 访问者模式的应用优点缺点使用场景 示例解析:博物馆的导览员代码示例 访问…...
Salesforce‘s 爱因斯坦机器人助手引领工业聊天机器人时代
CRM的对话式人工智能助手,根据公司数据提供可靠的人工智能响应及日本工业聊天机器人现状 【前言】 爱因斯坦助手(Einstein Copilot)提供可靠的响应,因为它基于公司独特的数据和元数据,使其能够深入了解公司的业务和客…...
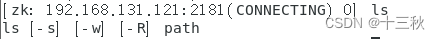
Day7—zookeeper基本操作
ZooKeeper介绍 ZooKeeper(动物园管理员)是一个分布式的、开源的分布式应用程序的协调服务框架,简称zk。ZooKeeper是Apache Hadoop 项目下的一个子项目,是一个树形目录服务。 ZooKeeper的主要功能 配置管理 分布式锁 集群管理…...

从硬件迷宫到macOS殿堂:OpCore Simplify如何重塑黑苹果配置体验
从硬件迷宫到macOS殿堂:OpCore Simplify如何重塑黑苹果配置体验 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 对于许多技术爱好者来说&a…...

基于模糊PID的水下航行器运动控制系统研究——Matlab 2016b及以上软件应用、课程报告...
基于模糊PID的水下航行器运动控制系统研究 1.适用软件Matlab 2016b及以上 2.课程报告6500字左右共16页 3.课程报告小报告仿真仿真视频 4.请结合以下图片水下航行器的运动控制一直是海洋工程领域的热门课题。面对复杂多变的洋流扰动和强非线性的水动力特性,传统PID控…...

PyFluent:重构CFD仿真流程的技术赋能与效能跃迁
PyFluent:重构CFD仿真流程的技术赋能与效能跃迁 【免费下载链接】pyfluent 项目地址: https://gitcode.com/gh_mirrors/pyf/pyfluent 在现代工程仿真领域,计算流体动力学(CFD)技术正经历着从手动操作向自动化流程的深刻转…...

Local AI MusicGen教育应用:帮助学生理解音乐情绪表达方式
Local AI MusicGen教育应用:帮助学生理解音乐情绪表达方式 1. 引言:当AI成为音乐老师 想象一下,你是一位音乐老师,正在给学生讲解“悲伤”这种情绪在音乐中是如何表达的。传统的教学方式可能是播放一段肖邦的夜曲,或…...

AI的“血管”:从大模型需求看6G、高速光纤与智算中心网络的技术变革
大模型训练与推理的爆发,正以前所未有的力度重塑通信网络基础设施。6G、高速光纤、智算中心网络,正成为AI基础设施的“血管”,承载着算力的血液,决定智能的极限。当GPT-5.4的推理能力逼近人类专家,当Sora可以生成一分钟…...

AI持续爆火,相关岗位薪资到底达到了多少,AI大模型岗位薪资真相:多少年包能拿到?普通人如何破局?
“AI相关岗位薪资” 随着AI持续火爆,各大厂也都在招聘相关人才,近日OfferShow专门对AI相关岗位的工资情况进行了一期专题汇总,都是校招岗位年包90W左右年包100W年包80w70W50W左右40W左右54W左右34W左右。 看大家投票可信度还是挺高的…...

智能文献管理全面指南:从学术研究痛点到高效解决方案
智能文献管理全面指南:从学术研究痛点到高效解决方案 【免费下载链接】zotero Zotero is a free, easy-to-use tool to help you collect, organize, annotate, cite, and share your research sources. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero …...

FastAdmin+PHPStudy保姆级安装教程:从下载到配置数据库的完整流程
FastAdminPHPStudy极速开发环境搭建实战指南 作为一名长期使用FastAdmin框架的开发者,我深知一个顺畅的本地开发环境对项目效率的影响。本文将带你从零开始,用最简洁的方式完成FastAdmin与PHPStudy的完美搭配,避开那些新手常踩的"坑&quo…...

智能突破2048:AI助手如何让数字合成不再依赖运气
智能突破2048:AI助手如何让数字合成不再依赖运气 【免费下载链接】2048-ai AI for the 2048 game 项目地址: https://gitcode.com/gh_mirrors/20/2048-ai 你是否曾在2048游戏中陷入数字迷宫?眼看着屏幕上散落的方块无从下手,移动一步就…...
)
别再死记硬背Sarsa公式了!用Python手搓一个‘胆小’的迷宫探索AI(附完整代码)
用Python打造胆小如鼠的迷宫AI:Sarsa算法实战图解 当你在迷宫中小心翼翼地贴着墙走,生怕掉进陷阱时——恭喜,你已经理解了Sarsa算法的核心思想。今天我们不谈枯燥的数学公式,而是用Python构建一个会"瑟瑟发抖"的迷宫探索…...