OpenVINO™ 2024.2 发布--推出LLM专属API !服务持续增强,提升AI生成新境界
点击蓝字
关注我们,让开发变得更有趣
作者 | 武卓 博士
排版 | 李擎

Hello, OpenVINO™ 2024.2
对我们来说,这是非常忙碌的几周,因为我们正在努力根据您的反馈改进我们的产品特性,并扩展生态系统以涵盖其它场景和用例。
让我们看看我们所做的最重要的更改。有关更详细的列表,您可以随时参考我们的完整 [新版本说明]
https://docs.openvino.ai/2024/about-openvino/release-notes-openvino.html
OpenVINO™
隆重推出 OpenVINO.GenAI 软件包和 LLM特定 API
生成式 AI 正在被应用程序设计人员快速地使用着。这不仅体现在使用来自商业云服务模型的传统REST API形式上,而且还发生在客户端和边缘。越来越多的数据正在客户端处理,通过AIPC,我们为此开始看到更多的机会。其中一种场景是人工智能助手,它能够生成文本(邮件草稿、文档摘要、文档内容的答案等等)。这一切都由 LLM(大型语言模型)和不断增长的 SLM(小型语言模型)系列提供支持。
我们引入了新的软件包 openvino-genai,它使用OpenVINO™ 以及其中的openvino_tokenizers,因此如果您打算运行 LLM,安装此软件包就足够了。经典的 OpenVINO API 也支持其它类型的模型,因此现在流水线构建变得更加容易。我们的安装选项也进行了更新,以便反映并指导使用新软件包,因此请在那里查看您最合适的选项。经典的 OpenVINO™ 软件包仍然存在,如果您暂时不打算使用生成式 API,请继续使用 openvino 软件包。
安装选项更新:
https://docs.openvino.ai/2024/get-started/install-openvino.html
经典OpenVINO™软件包:
https://www.intel.cn/content/www/cn/zh/developer/tools/openvino-toolkit/download.html
为了通过 LLM 生成结果,应用程序需要执行整个操作流水线:执行输入文本的分词,处理输入上下文,迭代生成模型答案的后续输出分词,最后将答案从分词解码为纯文本。每个分词的生成都是推理调用,然后是后续逻辑来选择分词本身。逻辑可以是贪婪搜索的形式,也就是选择最可能的分词,也可以是波束搜索的形式,即保持很少的序列并选择其中最好的。
虽然OpenVINO™在推理方面大放异彩,但正如我们刚才所讨论的,这还不足以涵盖整个文本生成的流水线。在 2024.2 版本之前,我们提供了帮助程序(分词器和示例)来实现这一点,但应用程序必须使用这些组件实现整个生成逻辑。现在这种情况正在发生改变。
在 24.2 版本中,我们引入了特定于 LLM 的 API,这些 API 隐藏了内部生成循环的复杂性,并显著减少了需要在应用程序中编写的代码量。通过使用特定于 LLM 的 API,您可以加载模型,向其传递上下文,并通过几行代码返回响应。在内部,OpenVINO™将对输入文本进行分词化,在您选择的设备上执行生成循环,并为您提供答案。让我们一步一步地看看这是如何使用Python和C++完成的。
第一步
通过Hugging Face Optimum-Intel导出
LLM 模型(我们使用了针对聊天微调的 Tiny Llama)
以下是将OpenVINO IR格式的LLM模型导出为FP16或INT4精度的两种方式。为了使LLM推理性能更高,我们建议对模型权重使用较低的精度,即INT4,并在模型导出过程中直接使用神经网络压缩框架(NNCF)压缩权重,如下所示。
FP16:
optimum-cli export openvino --model "TinyLlama/TinyLlama-1.1B-Chat-v1.0" --weight-format fp16 --trust-remote-codeINT4:
optimum-cli export openvino --model "TinyLlama/TinyLlama-1.1B-Chat-v1.0" --weight-format int4 --trust-remote-code第二步
使用C++或Python进行生成
通过新的C++ API进行LLM生成
#include "openvino/genai/llm_pipeline.hpp"
#include <iostream>int main(int argc, char* argv[]) {std::string model_path = argv[1];ov::genai::LLMPipeline pipe(model_path, "CPU");//target device is CPUstd::cout << pipe.generate("The Sun is yellow bacause"); //input context
}通过新的 Python API 进行生成
import openvino_genai as ov_genai
pipe = ov_genai.LLMPipeline(model_path, "CPU")
print(pipe.generate("The Sun is yellow bacause"))如您所见,只需要几行代码就能建立一个LLM生成的流水线。这是因为,从 Hugging Face Optimum-Intel 导出模型后,它已经存储了执行所需的所有信息,包括分词器/反分词器和生成配置,从而能够获得与 Hugging Face 生成匹配的结果。我们提供 C++ 和 Python API 来运行 LLM、最少的依赖项列表和对应用程序的添加。
为了实现生成式模型更具交互性的UI界面,我们添加了对模型输出分词流式处理的支持。在下面的示例中,我们使用简单的 lambda 函数在模型生成单词后立即将单词输出到控制台:
#include "openvino/genai/llm_pipeline.hpp"
#include <iostream>int main(int argc, char* argv[]) {std::string model_path = argv[1];ov::genai::LLMPipeline pipe(model_path, "CPU");auto streamer = [](std::string word) { std::cout << word << std::flush; };std::cout << pipe.generate("The Sun is yellow bacause", streamer);
}您也可以创建自定义流处理器进行更复杂的处理,这在我们的 [文档] 中进行了描述。
文档:
https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html
最后,我们还研究了聊天场景,其中输入和输出代表对话,并且有机会以在输入之间保留 KV缓存 的形式进行优化。为此,我们引入了聊天特定方法 start_chat 和 finish_chat,它们用于标记会话的开始和结束。下面是一个非常简单的 C++ 示例:
int main(int argc, char* argv[]) {std::string prompt;std::string model_path = argv[1];ov::genai::LLMPipeline pipe(model_path, "CPU");pipe.start_chat();for (;;) {std::cout << "question:\n";std::getline(std::cin, prompt);if (prompt == "Stop!")break;std::cout << "answer:\n";auto answer = pipe(prompt);std::cout << answer << std::endl;}pipe.finish_chat();
}在上面的所有示例中,我们都使用 CPU 作为目标设备,但 GPU 也同样是支持的。请记住,GPU 将为 LLM 本身运行推理,分词选择逻辑和分词化/去分词化将保留在 CPU 上,因为这更有效率。内置的分词器以单独的模型形式表示,并通过我们的推理功能在 CPU 上运行。
这个 API 使我们能够更灵活、更优化地实现生成逻辑,并不断扩展。请继续关注后续发布版本中的更多功能!
同时,请务必查看我们的 [文档] 和 [示例] 以获取新的 API,尝试后告诉我们你的想法。
文档:
https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html
示例:
https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-question-answering
OpenVINO™
通过OpenVINO扩展模型服务
通过服务化部署模型是一个非常成熟的方法论,并且随着基于微服务的部署不仅在传统的云环境中扩展,同时也在向边缘计算领域扩展,这一需求日益增长。更多的应用被开发为微服务,并部署在智能边缘和云中。在2024.2 版本中,我们引入了对服务场景的额外支持。让我们来看看最重要的变化。
OpenVINO模型服务器是我们长期开发的模型服务解决方案,它被应用程序广泛采用,以最有效的方式为模型提供服务。在此版本中,我们引入了通过称为连续批处理的机制为LLM提供高效服务的能力。
连续批处理:
https://www.anyscale.com/blog/continuous-batching-llm-inference
从本质上讲,连续批处理允许我们通过将多个请求合并到批处理中来以最有效的方式实现推理服务。由于生成过程中上下文大小的差异,传统批处理文本生成方案的方式非常有限。实际上,不可能找到两个相同长度的不同请求并生成相同长度的输出来执行传统的请求批处理。为了解决这个问题,我们采用了分页注意力方法,就像在 vLLM 实现中的那样。这使我们能够将多个请求合并到同一模型中,并提高硬件利用率。不过,调度请求的内部逻辑是不同的,我们考虑了 CPU 在设计时使其更高效的细节,结合了高吞吐量和低延迟,使其更高效。
为了以最适应应用程序的方式部署 LLM,我们在文本生成的使用场景实现了 OpenAI 兼容的API。我们的实现包括 连续批处理和分页注意力算法,因此文本生成可以在高并发负载下快速高效。这使得您可以允许在云中或本地(如果需要的话)创建自己的类似 OpenAI 的 LLM 服务端点。
尽管 LLM 备受瞩目,但传统的深度学习模型作为独立解决方案或大型流程的一部分仍有着高度需求。OVMS 可以长时间高效地部署这些模型,但对其它部署解决方案的需求非常高,因此我们为服务场景引入了一些额外的 OpenVINO™ 集成:通过 TorchServe 和 Nvidia Triton 提供服务。
OpenVINO™ 长期以来一直为 Triton Serving 提供后端,我们最近与 Nvidia 工程师合作,重新设计了它的附加功能,例如支持动态输入。您可以在我们的博客文章中查看有关如何在 Triton 中使用 OpenVINO™ 的更多详细信息。
博客文章:
https://medium.com/openvino-toolkit/how-to-serve-models-on-nvidia-triton-inference-server-with-openvino-backend-a4c36300ee21
服务功能的另一个重要补充是通过使用 torch.compile 的 OpenVINO™ 后端,使用 TorchServe 为模型提供服务。在引入 torch.compile 之后,TorchServe 引入了通过不同后端加速服务的功能。这正是OpenVINO™现在发生的事情,我们提供了在TorchServe中指定OpenVINO™作为后端的功能。有关更多详细信息,您可以查看示例,这些示例非常简单且不言自明。
torch.compile 的 OpenVINO™ 后端:
https://docs.openvino.ai/2024/openvino-workflow/torch-compile.html
示例:
https://github.com/pytorch/serve/tree/master/examples/pt2/torch_compile_openvino
OpenVINO™
性能提升
我们仍然专注于 AI 模型的性能表现。尽管 AIPC 的出现,LLM 在客户端的采用仍然对底层硬件产生压力。我们的优化工作覆盖了不同的支持目标,包括 CPU、GPU 和 NPU。
AIPC与传统PC的不同在于它集成了专门的硬件加速器,随着AI应用场景从云端转向个人计算领域,其重要性日益增加。英特尔®酷睿™Ultra处理器提供了更强大的GPU以及NPU。从性能和效率的角度来看,这些都让加速解决方案更具吸引力。
如果平台性能不足,我们始终能够通过添加我们的ARC系列独立显卡进行加速,来实现进一步的性能提升。为了帮助实现LLM部署特性,我们一直专注于加速GPU的LLM的推理性能,覆盖了集成显卡和独立显卡。将负载卸载到 GPU 不仅是因为它的特性适宜处理这类工作负载,还因为需要保持 CPU 可用。因此,推理期间的 CPU 负载对于此类情况至关重要。我们一直在努力优化 CPU 端负载并减少主机代码延迟至少一半。这也使我们能够实现更好的 GPU 特性,因为内核调度现在更加高效。
此外,我们还致力于少数GPU基本操作的更高效实现,包括 Scaled Dot Product Attention 和 Positional Embeddings 的融合版本。这不仅改善了延迟,还减少了推理期间的主机开销和整体内存消耗,这对于在笔记本电脑上运行 LLM 等场景至关重要。
独立显卡上一些LLM的延迟已经降低,我们正与oneDNN团队的合作伙伴一起,继续我们的优化之旅。
虽然我们经常谈论 GPU,但 CPU 等其他目标设备的性能也有所改进。在CPU上,第二个分词延迟的性能得到了明显改善,以及在基于AVX2(13代英特尔酷睿处理器)和AVX512(第三代至强可扩展处理器)的CPU平台上,FP16权重的LLM的内存占用情况也得到了明显改善,尤其是在小批量的情况下。更不用说,我们还在 Optimum-Intel 集成中持续增加了对新模型的覆盖。
OpenVINO™
新模型和notebooks示例
在每次发布的新版本中,我们都会继续扩大对新模型的支持,以及增加新的Notebook代码示例,展示如何在这些使用用例中利用OpenVINO™。对于新模型,我们增加了对TensorFlow*Hub的mil-nce和openimages-v4-sd-mobilent-v2的支持,以及Phi-3-mini:这是一个AI模型家族,利用小语言模型的力量实现更快、更准确和更具成本效益的文本处理。
Notebooks代码示例可以成为用户学习和体验的宝贵内容。在这个版本中,我们添加了几个新的Notebooks。最值得注意的是用于动画图像的DynamiCrafter notebook,用于转换和优化YOLOv10为OpenVINO™的notebook,以及在现有LLMChatbot notebook中添加Phi-3-mini模型,以便用户可以尝试更多的LLM模型。
可以在以下地址找到最新的带有GitHub验证状态的notebooks
https://openvinotoolkit.github.io/openvino_notebooks/
以下是已更新或新添加的notebooks:
Image to Video Generation with Stable Video Diffusion
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/stable-video-diffusion/stable-video-diffusion.ipynb
Image generation with Stable Cascade
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/stable-cascade-image-generation/stable-cascade-image-generation.ipynb
One Step Sketch to Image translation with pix2pix-turbo and OpenVINO
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/sketch-to-image-pix2pix-turbo/sketch-to-image-pix2pix-turbo.ipynb
Animating Open-domain Images with DynamiCrafter and OpenVINO
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/dynamicrafter-animating-images/dynamicrafter-animating-images.ipynb
Text-to-Video retrieval with S3D MIL-NCE and OpenVINO
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/s3d-mil-nce-text-to-video-retrieval/s3d-mil-nce-text-to-video-retrieval.ipynb
Convert and Optimize YOLOv10 with OpenVINO
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/yolov10-optimization/yolov10-optimization.ipynb
Visual-language assistant with nanoLLaVA and OpenVINO
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/nano-llava-multimodal-chatbot/nano-llava-multimodal-chatbot.ipynb
Person Counting System using YOLOV8 and OpenVINO™
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/person-counting-webcam/person-counting.ipynb
Quantization-Sparsity Aware Training with NNCF, using PyTorch framework
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/pytorch-quantization-sparsity-aware-training/pytorch-quantization-sparsity-aware-training.ipynb
OpenVINO™
总结
在此,我们兴奋地宣布OpenVINO™ 2024.2最新版本现已开放下载!
我们的团队一直致力于各项新特性和性能提升的研发。一如既往,我们努力不断优化用户体验,拓宽OpenVINO™的功能边界。我们的开发路线图上已经规划了下一版本的诸多特性,迫不及待在未来与您分享。感谢大家的支持与厚爱!
OpenVINO™
--END--
点击下方图片,让我们一起成为“Issues 猎手”,共创百万用户开源生态!你也许想了解(点击蓝字查看)⬇️➡️ OpenVINO™ 助力 Qwen 2 —— 开启大语言模型新时代➡️ 揭秘XPU架构下AIGC的推理加速艺术--AI PC 新纪元:将 AI 引入 NPU,实现快速低功耗推理➡️ 隆重介绍 OpenVINO™ 2024.0: 为开发者提供更强性能和扩展支持➡️ 隆重推出 OpenVINO 2023.3 ™ 最新长期支持版本➡️ OpenVINO™ 2023.2 发布:让生成式 AI 在实际场景中更易用➡️ 开发者实战 | 介绍OpenVINO™ 2023.1:在边缘端赋能生成式AI➡️ 5周年更新 | OpenVINO™ 2023.0,让AI部署和加速更容易➡️ OpenVINO™5周年重头戏!2023.0版本持续升级AI部署和加速性能➡️ 开发者实战系列资源包来啦!扫描下方二维码立即体验
OpenVINO™ 工具套件 2024.1点击 阅读原文 获取最新版OpenVINO™2024.2
评论区已开放,欢迎大家留言评论!
文章这么精彩,你有没有“在看”?
相关文章:
OpenVINO™ 2024.2 发布--推出LLM专属API !服务持续增强,提升AI生成新境界
点击蓝字 关注我们,让开发变得更有趣 作者 | 武卓 博士 排版 | 李擎 Hello, OpenVINO™ 2024.2 对我们来说,这是非常忙碌的几周,因为我们正在努力根据您的反馈改进我们的产品特性,并扩展生态系统以涵盖其它场景和用例。 让我们看看…...
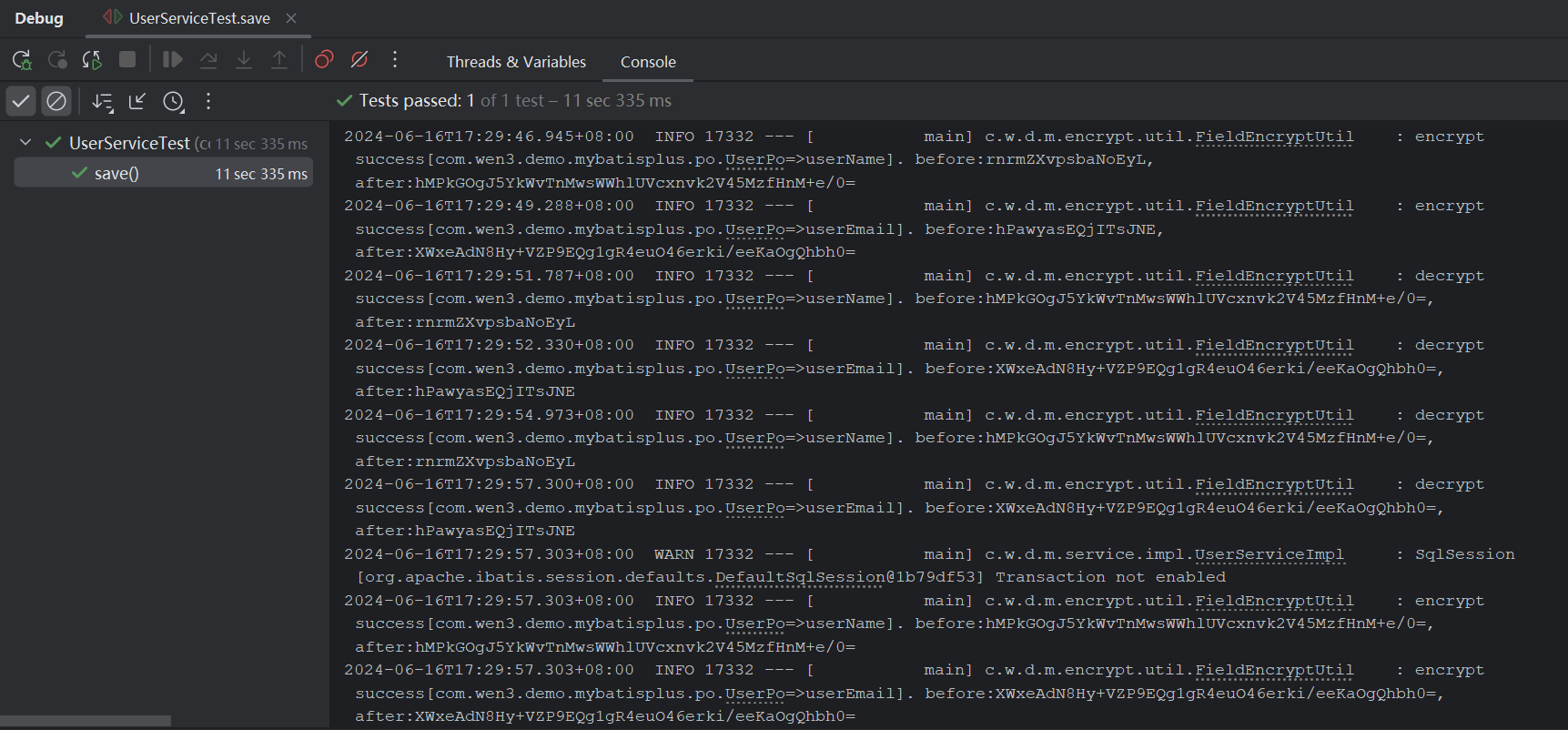
【Mybatis-Plus】根据自定义注解实现自动加解密
背景 我们把数据存到数据库的时候,有些敏感字段是需要加密的,从数据库查出来再进行解密。如果存在多张表或者多个地方需要对部分字段进行加解密操作,每个地方都手写一次加解密的动作,显然不是最好的选择。如果我们使用的是Mybati…...

Window上ubuntu子系统编译Android
Window上ubuntu子系统编译Android 1、编译环境2、WSL2编译报错2.1 You are building on a machine with 11.6GB of RAM2.2 Case-insensitive filesystems not supported3. android模拟器调试 1、编译环境 AOSP : Android源码下载安装java:sudo apt-get install ope…...
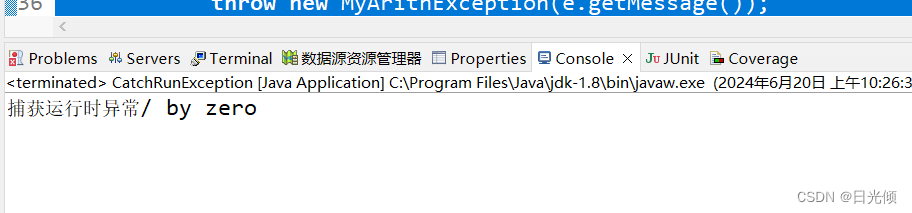
【Java学习笔记】异常处理
生活中我们在使用一些产品的时候,经常会碰到一些异常情况。例如,使用ATM机取钱的时,机器会突然出现故障导致无法完成正常的取钱业务,甚至吞卡;在乘坐地铁时,地铁出现异常无法按时启动和运行;使用…...

Ubuntu20.04环境下Baxter机器人开发环境搭建
Ubuntu20.04环境下Baxter机器人开发环境搭建 ubuntu20.04安装 略 安装ROS 略 Baxter机器人依赖安装 主目录创建工作空间,按以下步骤执行 mkdir -p ~/baxter_ws/src source /opt/ros/noetic/setup.bash cd ~/baxter_ws catkin_make catkin_make install s…...
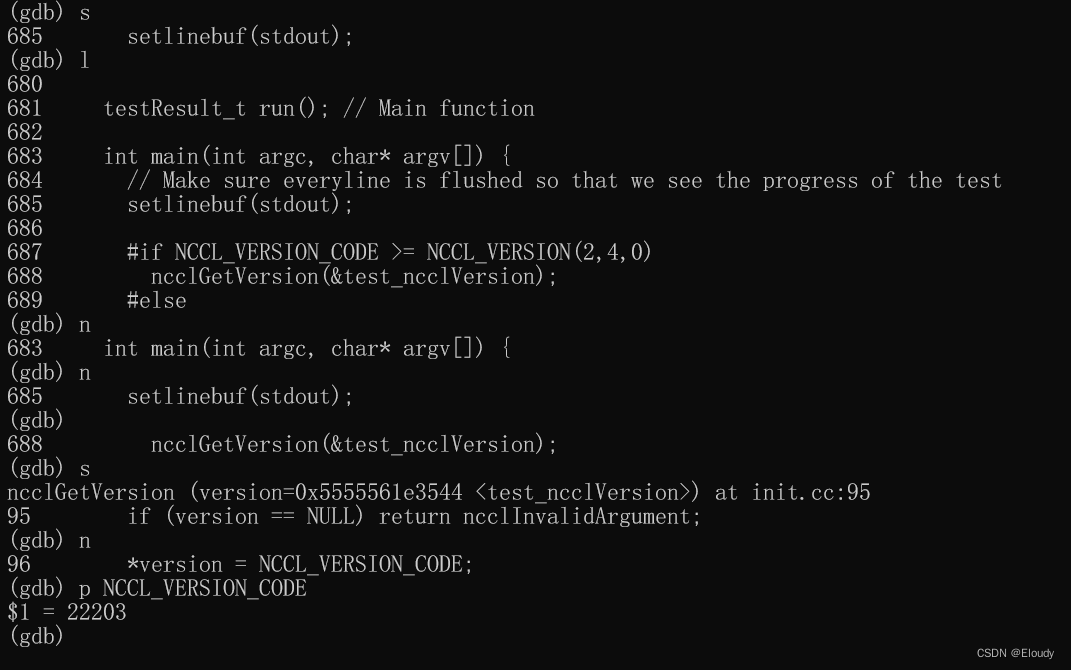
nccl 03 记 回顾:从下载,编译到调试 nccl-test
1, 下载与编译 1.1 源码下载 $ git clone https://github.com/NVIDIA/nccl.git 1.2 编译 1.2.1 一般编译: $ make -j src.build 1.2.2 特定架构gpu 编译 $ make -j src.build NVCC_GENCODE"-gencodearchcompute_80,codesm_80" A10…...

关于车规级功率器件热可靠性测试的分享
随着中国电动汽车市场的稳步快速发展和各大车企布局新能源的扩散,推动了车规级功率器件的快速增长。新能源汽车行业和消费电子都会用到半导体芯片,但车规级芯片对外部环境要求很高,涉及到的一致性和可靠性均要大于工业级产品要求,…...

内核学习——1、list_head
双向循环链表:list_head 头节点head是不使用的: struct list_head { struct list_head *next, *prev; }; 结构体中没有数据域,所以一般把list_head嵌入到其他结构中使用 struct file_node { char c; struct list_head node; }; 此时ÿ…...

JavaEE初阶--网络基本概念
目录 一、引言 二、网络基本概念 2.1 局域网LAN 2.2 广域网WAN 三、网络通信的基础 3.1 IP地址 3.2 端口号 3.3 协议 3.4 五元组 3.5 协议分层 3.6 OSI七层模型 3.7 TCP/IP五层模型 四、总结 一、引言 本篇博客将进入网络编程以及网络原理的学习,但网…...
gitlab-cicd-k8s
k8s已经准备好 kubectl get node 创建cicdYaml文件 kubectl create namespace gitlab-cicd --dry-runclient --outputyaml >> gitlab-cicd.yaml kubectl apply -f gitlab-cicd.yaml 服务器和仓库在一起可用专有地址 使用 GitLab Runner 可以自动执行 GitLab CI/CD 管道…...
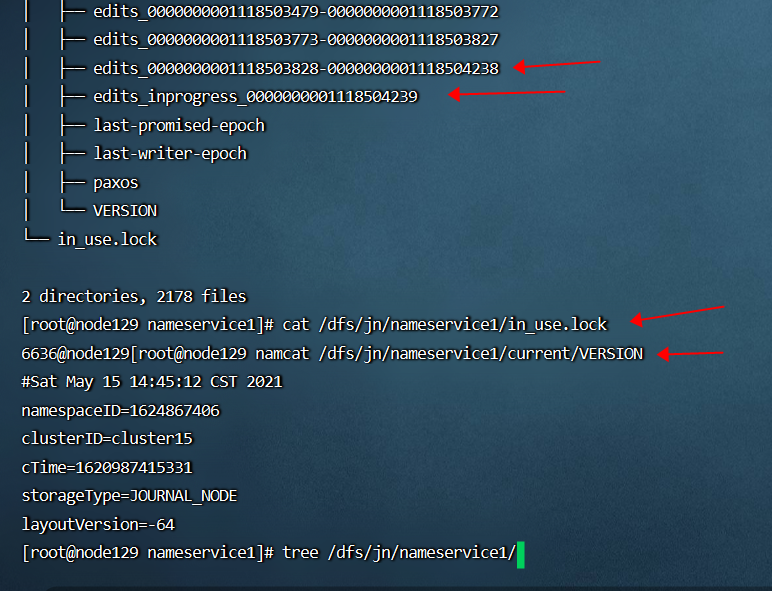
盘点下常见 HDFS JournalNode 异常的问题原因和修复方法
盘点下常见 HDFS JournalNode 异常的问题原因和修复方法 最近在多个客户现场以及公司内部环境,都遇到了因为 JournalNode 异常导致 HDFS 服务不可用的问题,在此总结下相关知识。 1 HDFS HA 高可用和 JournalNode 概述 HDFS namenode 有 SPOF 单点故障…...
)
深入了解python生成器(generator)
生成器 生成器是 Python 中一种特殊类型的迭代器。生成器允许你定义一个函数来动态产生值,而不是一次性生成所有值并将它们存储在内存中。生成器使用 yield 关键字来逐个返回值。每次调用生成器函数时,函数会在 yield 语句暂停,并记住当前的…...
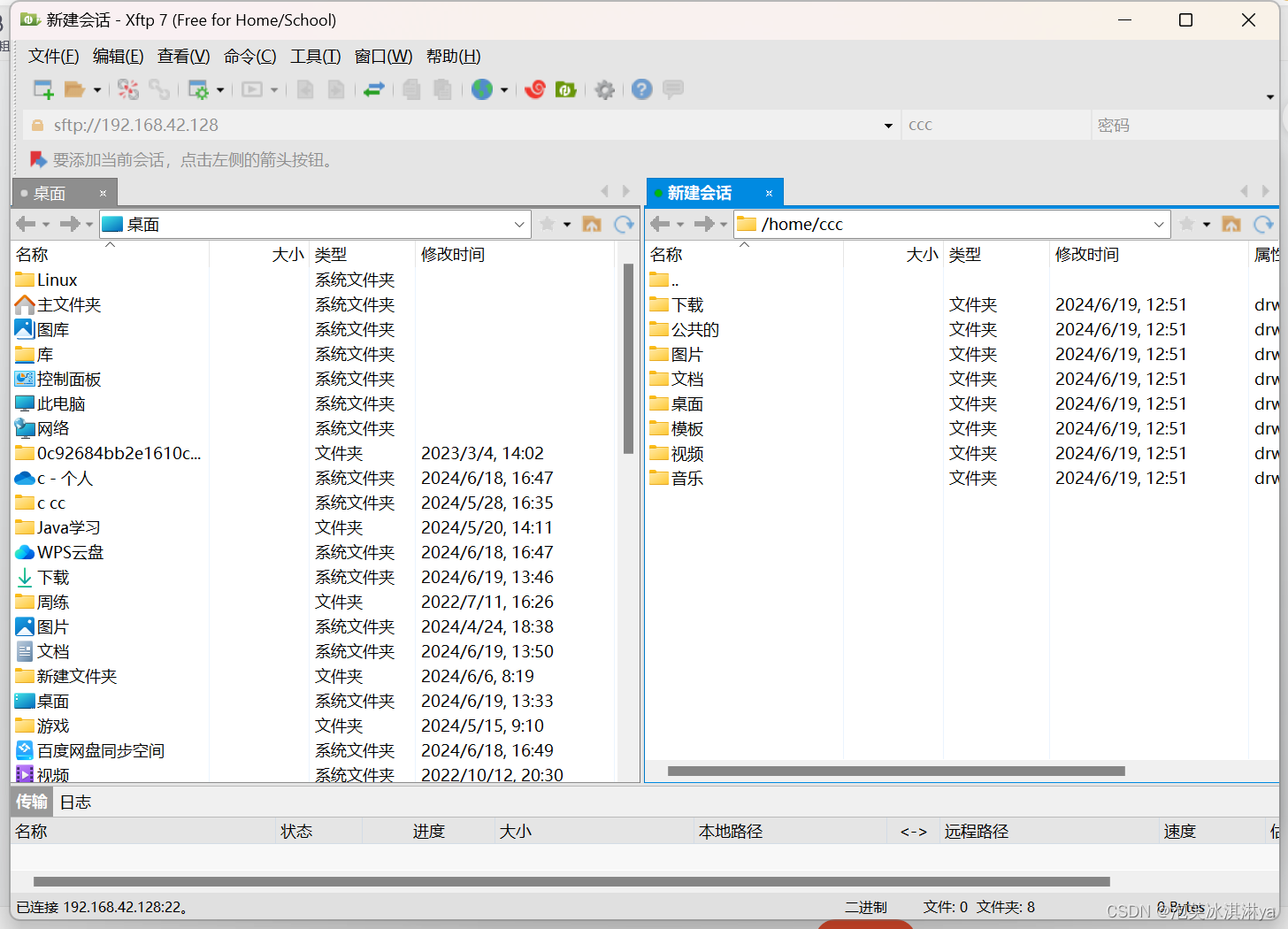
【Linux】Xshell和Xftp简介_安装_VMware虚拟机使用
1、简介 Xshell简介 Xshell是一款强大的安全终端模拟软件支持SSH1、SSH2以及Microsoft Windows平台的TELNET协议。该软件通过互联网实现到远程主机的安全连接,并通过其创新性的设计和特色帮助用户在复杂的网络环境中高效工作。Xshell可以在Windows界面下访问远端不…...

【轮询负载均衡规则算法设计题】
一、题目描述 给定n台主机(编号1~n)和某批数据包,数据包格式为(抵达主机时刻,负载量)。这里数据每个时刻最多只有1条数据到达。负载量表示该主机处理此数据包总耗时。请计算轮询负载均衡规则下,…...

张一鸣的产品哲学:与巨头共舞,低调中寻求突破
一、引言 在当今互联网竞争激烈的格局下,与巨头企业打交道是每个新兴科技企业都需面对的挑战。字节跳动创始人张一鸣在多次访谈中分享了他与巨头企业打交道的经验:保持低调、补齐技术、产品和市场各方面的能力。本文将探讨这一策略背后的产品哲学&#…...

【面试干货】throw 和 throws 的区别
【面试干货】throw 和 throws 的区别 1、throw1.1 示例 2、throws2.1 示例 3、总结 💖The Begin💖点点关注,收藏不迷路💖 在Java中,throw和throws都与异常处理紧密相关,但它们在使用和含义上有明显的区别。…...
安卓手机删除的照片怎么恢复?3个方法,小技巧大作用
你是否曾经不小心删除了手机里的珍贵照片,却不知道怎么恢复?别担心,今天我们就来分享几个简单的小技巧,帮助你轻松找回那些丢失的照片。这些技巧虽然简单,但却能发挥大作用,让你不再为丢失照片而烦恼。手机…...
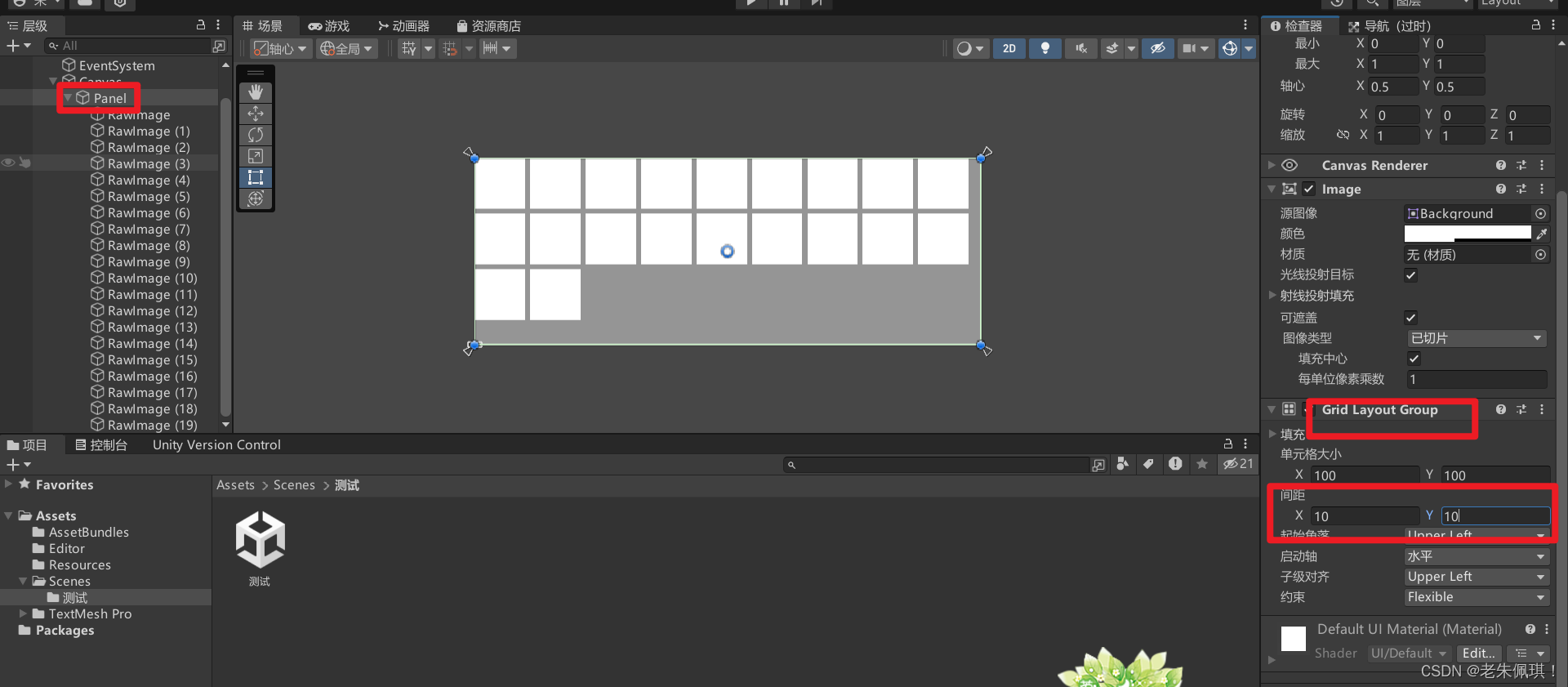
Unity制作背包的格子
1.新建一个面板 2.点击面板并添加这个组件 3.点击UI创建一个原始图像,这样我们就会发现图像出现在了面板的左上角。 4.多复制几个并改变 Grid Layout Group的参数就可以实现下面的效果了...

道可云元宇宙每日资讯|厦门:运用元宇宙技术助力直播电商发展
道可云元宇宙每日简报(2024年6月20日)讯,今日元宇宙新鲜事有: 厦门:运用元宇宙技术助力直播电商发展 近日,厦门市商务局印发《厦门市促进直播电商高质量发展若干措施(2024年-2026年࿰…...
电脑怎么卸载软件?多个方法合集(2024年新版)
在电脑的日常使用中,我们经常需要安装各种软件来满足不同的需求,但随着时间的推移,可能会出现一些软件不再需要或需要更换的情况。此时,及时从电脑上卸载这些不必要的软件是非常重要的。它不仅可以释放硬盘空间,还可以…...

降AI率软件数据安全测评:嘎嘎降不留存vs拿你论文训练AI!
降AI率软件数据安全测评:嘎嘎降不留存vs拿你论文训练AI! 一个月后导师消息:「你论文跟去年某高校论文相似度异常」 我硕士毕业季预算紧,搜降 AI 工具时格外注意「免费」「不限字数」这种关键词。找到一家工具——免费额度大、价…...

为什么需要做GEO优化?AI新时代的商业规则探索
2026年,一个加速蔓延的商业现象正在发生:消费者不再打开搜索引擎、翻阅列表、逐条点击蓝色链接——他们直接打开DeepSeek、豆包、Kimi等AI助手,用一句完整的话发起提问:“这个价位哪个品牌最值得买?”“敏感肌用什么护…...

QGIS图层驾驭术 | 新手必会的三大核心操作
1. 图层基础:理解QGIS的"透明胶片"逻辑 第一次打开QGIS时,看到空白的画布和一堆按钮,很多人会感到无从下手。其实理解图层概念最简单的方式,就是想象你在用传统方法制作地图:把不同内容的透明胶片叠在一起。…...

Ubuntu 下 Rider 无法识别 Unreal Engine 的解决方法
Ubuntu 下 Rider 无法识别 Unreal Engine 的解决方法适用环境:JetBrains Rider Ubuntu Unreal Engine(含预发布/自定义安装版本)问题描述在 Ubuntu 上使用 Rider 打开 UE 项目时,IDE 提示找不到引擎,或 .uproject 文…...

物联网时代:从技术连接到价值过滤的思辨与实践
1. 从“动能”到“意义”:一场关于技术本质的思辨“你能发出闪电,叫它行去,使它对你说:‘我们在这里’?”——《约伯记》38:35。这句古老的诘问,在今天读来,竟意外地切中了我们与技术关系的核心…...

基于MCP协议集成AI求职助手:自动化简历优化与面试准备
1. 项目概述:将AI求职助手集成到你的工作流 如果你正在用Claude Desktop或者Cursor这类AI助手,并且恰好又在找工作或者准备职业跃迁,那你可能已经体会过那种“割裂感”——你需要手动把简历内容、职位描述、面试问题来回复制粘贴到聊天窗口&…...
)
用户NPS提升2.8倍的秘密:Lovable SaaS的3层共鸣架构,含Figma可复用组件库(限时开源)
更多请点击: https://intelliparadigm.com 第一章:Lovable SaaS产品开发指南 打造真正“可爱”(Lovable)的SaaS产品,核心在于将技术实现与人类情感体验深度耦合——用户不仅愿意使用,更主动分享、期待更新…...

开源AR虚拟试衣项目openclaw-genpark-ar-tryon核心技术解析与实践
1. 项目概述:当AR试衣遇见开源社区最近在逛GitHub的时候,偶然发现了一个挺有意思的项目,叫openclaw-genpark-ar-tryon。光看名字,一股浓浓的“开源”和“增强现实”味儿就扑面而来了。点进去一看,果然,这是…...

从Solyndra事件看美国太阳能产业转型与能源创新体系构建
1. 从Solyndra事件看美国太阳能产业的十字路口2011年秋天,加州弗里蒙特市,一家名为Solyndra的太阳能公司大门前,联邦官员正将一箱箱文件搬上卡车,而当地几乎所有的电视台摄像机都记录下了这一幕。这家曾获得美国能源部5.35亿美元贷…...
