ResNet——Deep Residual Learning for Image Recognition(论文阅读)
论文名:Deep Residual Learning for Image Recognition
论文作者:Kaiming He et.al.
期刊/会议名:CVPR 2016
发表时间:2015-10
论文地址:https://arxiv.org/pdf/1512.033851.什么是ResNet
ResNet是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。下面是ResNet的结构。

2.为什么要引入ResNet
理论上来说,堆叠神经网络的层数应该可以提升模型的精度。但是现实中真的是这样吗?
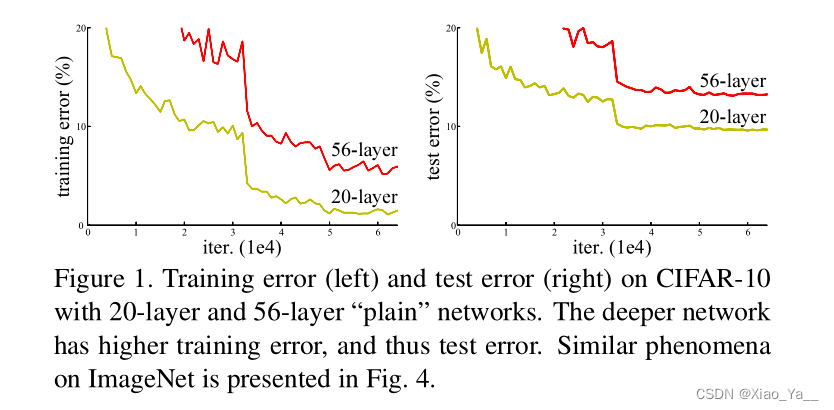
我们知道,网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
实验数据证明了一开始随着模型层数的增加,模型的精度会达到饱和。如果再增加网络的层数的话,就会开始退化了。从这个实验数据中,我们可以看到在训练轮次相同的情况下,56层的网络误差,居然比20层的网络还要高。这个现象是由于深层网络训练难度太高导致的。我们给这个现象起名叫做退化。这个现象经常被和过拟合搞混淆,但是过拟合其实是会让训练误差变得越来越小,而测试误差变高。退化则是让训练误差和测试误差都变高。

与此同时,深度神经网络还有一个难题:我们以一个最简单的神经网络为例,在反向传播的过程中我们可以推导出每一层的误差项都依赖它后面一层的误差项,在层数很多的情况下,我们很难保证每一层的权值和梯度的大小。举一个最经典的例子,如果我们用sigmoid函数作为我们的激活函数,它的导数的最大值只有0.25,梯度在传播的过程中越来越趋近于零。误差就没有办法传播到底层的参数了,这就是梯度消失。虽然batch normalization和layer normalization,可以缓解梯度消失的问题,但是我们有没有什么办法,既可以解决退化的问题,又能顺便给梯度开个后门。
3.ResNet详读

先来想一想为什么深层神经网络会出现退化的问题呢?假设我们的神经网络在层数为L的时候达到了最优的效果。这个时候我们把这个网络构建的更深,那么第L层之后的每一层理论上来说应该是一个恒等映射,但是拟合一个恒等映射是很难的,所以我们可不可以考虑换一个思路。如果我们用H(x)来表示我们想让这个神经网络学到的映射。用x来表示我们已经学到的内容,那么现在我们可不可以让我们的神经网络去拟合H(x)和x之间的残差呢?也就是说如果我们选择优化的不是H(x),而是把H(x)拆分为x和H(x)-x两个部分,我们选择去优化H(x)-x,我们给这个残差取名叫F(x),F(x)通常包含着卷积和激活之类的操作。我们把F(x)和x相加之后,仍然能得到我们想要的HX,我们把这样从输入额外连一条线到输出来,表示将输入输出相加的操作叫做skip connection。如果让F(x)趋近于零,那么就相当于我们构造了一个恒等映射,那为什么这种方法可以有效解决退化和梯度消失的问题呢?我们假设第L层的输入是xl,那它这一层的输出就是f(xl)+xl,同时它也是第l+1层的输入xl+1。那我们现在可以根据这个规律去推导一下第l+2层的输入,到了这一步我们是不是就不难发现,我们可以得到任意一个更深的层数L和一个更浅的层数l之间的关系的表达式。

首先是任意一层的输入xL可以写成比它更浅的任意层的输入xl和两层之间所有参差的和,我们这样是不是可以初步推测出和普通的神经网络相比,残差网络在前向传播的时候可以让任意低层的信息更容易传播到高层。根据这个式子,我们也可以推导出损失函数。关于xL的梯度,我们从这里可以发现损失函数关于xL的梯度可以直接传播到任意一个更浅的层,后面的这一堆不可能一直等于-1,也就是说残差网络中不会出现梯度消失的问题。作者何凯明的观点是这样的属性。让残差网络无论是正向传播还是反向传播都可以将信号直接传播到任意一层。
注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
- 全0填充;
- 采用1*1卷积
4.深度残差学习
在堆叠的几层网络上使用残差连接。整个网络的架构如图:

其中,左边是VGG-19的模型,中间是原始网络,右边是残差网络。残差网络的参数比VGG-19要少。
5.实现
在ImageNet上的测试设置如下: 图片使用欠采样放缩到 [256∗480] [256*480],以提供尺寸上的数据增强。对原图作水平翻转,并且使用 [224∗224] [224*224]的随机采样,同时每一个像素作去均值处理。在每一个卷积层之后,激活函数之前使用BN。使用SGD,mini-batch大小为256。学习率的初始值为0.1,当训练误差不再缩小时降低学习率为原先的1/10继续训练。训练过程进行了600000次迭代。
6.实验部分
Table1中给出了不同层数的ResNet架构。

ImageNet Classification
Plain Networks
分别使用18层的plain nets和34层的plain nets,结果显示34层的网络有更高的验证误差。下图比较了整个过程的训练和测试误差:

注:细实线代表训练误差,粗实线代表验证误差。左侧为plain nets,右侧为ResNet。 这种优化上的困难不是由于梯度消失造成的,因为在网络中已经使用了BN,保证了前向传播的信号有非零的方差。猜想深层的神经网络的收敛几率随着网络层数的加深,以指数的形式下降,导致训练误差很难降低。
Residual Networks
测试18层和34层的ResNet。注意到34层的训练和测试误差都要比18层的小。这说明网络退化的问题得到了部分解决,通过加深网络深度,可以提高正确率。注意到18层的plain net和18层的ResNet可以达到相近的正确率,但是ResNet收敛更快。这说明网络不够深的时候,SGD还是能够找到很好的解。
Identity vs. Projection Shortcuts
比较了三种选择: (A)zero-padding shortcuts用来增加维度(Residual block的维度小于输出维度时,使用0来进行填充),所有的shortcut无参数。 (B)projection shortcuts用来增加维度(维度不一致时使用),其他的shortcut都是恒等映射(identity)类型。 (C)所有的shortcut都是使用projection shortcuts。 Table3中给出了实验结果:

结果表明,这三种选择都有助于提高正确率。其中,B比A效果好,原因可能是A中zero-padded的维度没有使用残差学习。C比B效果好,原因可能是projection shortcuts中引入的参数。但是ABC中的结果表明,projection shortcuts对于解决网络的退化问题是没有作用的,对于正确率的提升作用也十分有限。所以,从减少模型参数,降低复杂度的角度考虑,使用Identity shortcuts就已经足够了。
Deeper Bottleneck Architectures.
在探究更深层网络性能的时候,处于训练时间的考虑,我们使用bottleneck design的方式来设计building block。对于每一个残差函数 F F,使用一个三层的stack代替以前的两层。这三层分别使用1x1,3x3,1x1的卷积。其中,1 × 1卷积用来降维然后升维,即利用1 × \times1卷积解决维度不同的问题。3 × 3对应一个瓶颈(更少的输入、输出维度)。Fig.5 展示了这种设计。

50、101和152层的ResNet相对于32层网络有更高的准确率。Table3和4中给出了测试结果。
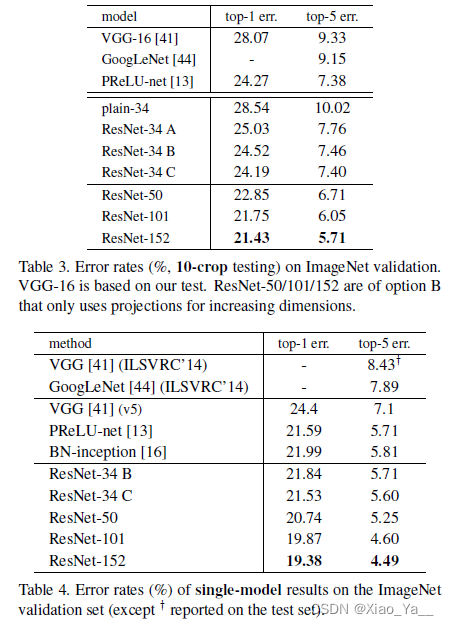
注:使用集成方法的152层网络能达到3.75%的错误率。
CIFAR10 and Analysis
在CIFAR10数据集上的测试表明,ResNet的layer对于输入信号具有更小的响应。

对于更深的网络,比如超过1000层的情况,虽然能够进行训练,但是测试的正确率并不理想。原因可能是过拟合,因为超过1000层的网络对于这个小数据集来说,容量还是过大。
总结
ResNet和Highway Network的思路比较类似,都是将部分原始输入的信息不经过矩阵乘法和非线性变换,直接传输到下一层。这就如同在深层网络中建立了许多条信息高速公路。ResNet通过改变学习目标,即不再学习完整的输出 F(x) ,而是学习残差 H(x)−x ,解决了传统卷积层或全连接层在进行信息传递时存在的丢失、损耗等问题。通过直接将信息从输入绕道传输到输出,一定程度上保护了信息的完整性。同时,由于学习的目标是残差,简化了学习的难度。根据Schmidhuber教授的观点,ResNet类似于一个没有gates的LSTM网络,即旁路输入 x 一直向之后的层传递,而不需要学习。有论文表示,ResNet的效果类似于对不同层数网络进行集成方法。
Inplimentation
这里简单分析一下ResNet152在PyTorch上的实现。 源代码:https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
相关文章:
ResNet——Deep Residual Learning for Image Recognition(论文阅读)
论文名:Deep Residual Learning for Image Recognition 论文作者:Kaiming He et.al. 期刊/会议名:CVPR 2016 发表时间:2015-10 论文地址:https://arxiv.org/pdf/1512.03385 1.什么是ResNet ResNet是一种残差网络&a…...
)
java基础·小白入门(五)
目录 内部类与Lambda表达式内部类Lambda表达式 多线程 内部类与Lambda表达式 内部类 在一个类中定义另外一个类,这个类就叫做内部类或内置类 (inner class) 。在main中直接访问内部类时,必须在内部类名前冠以其所属外部类的名字才能使用;在…...
微观时空结构和虚数单位的关系
回顾虚数单位的定义, 其中我们把称为周期(的绝大部分),称为微分,0称为原点或者起点(意味着新周期的开始),由此我们用序数的概念反过来构建了基数的概念。 周期和单位显然具有倍数关…...

go-zero使用goctl生成mongodb的操作使用方法
目录 MongoDB简介 MongoDB的优势 对比mysql的操作 goctl的mongodb代码生成 如何使用 go-zero中mogodb使用 mongodb官方驱动使用 model模型的方式使用 其他资源 MongoDB简介 mongodb是一种高性能、开源、文档型的nosql数据库,被广泛应用于web应用、大数据以…...
服务器新硬盘分区、格式化和挂载
文章目录 参考文献查看了一下起点现状分区(base) ~ sudo parted /dev/sdcmklabel gpt(设置分区类型)增加分区 格式化需要先退出quit(可以)(base) / sudo mkfs.xfs /dev/sdc/sdc1(失败)sudo mkfs.xfs /dev/s…...

Openldap集成Kerberos
文章目录 一、背景二、Openldap集成Kerberos2.1kerberos服务器中绑定Ldap服务器2.1.1创建LDAP管理员用户2.1.2添加principal2.1.3生成keytab文件2.1.4赋予keytab文件权限2.1.5验证keytab文件2.1.6增加KRB5_KTNAME配置 2.2Ldap服务器中绑定kerberos服务器2.2.1生成LDAP数据库Roo…...
(创新)基于VMD-CNN-BiLSTM的电力负荷预测—代码+数据
目录 一、主要内容: 二、运行效果: 三、VMD-BiLSTM负荷预测理论: 四、代码数据下载: 一、主要内容: 本代码结合变分模态分解( Variational Mode Decomposition,VMD) 和卷积神经网络(Convolutional neu…...

机器 reboot 后 kubelet 目录凭空消失的灾难恢复
文章目录 [toc]事故背景报错内容 修复过程停止 kubelet 服务备份 kubelet.config重新生成 kubelet.config重新生成 kubelet 配置文件对比 kubeadm-flags.env 事故背景 因为一些情况,需要 reboot 服务器,结果 reboot 机器后,kubeadm init 节点…...

Pytorch构建vgg16模型
VGG-16 1. 导入工具包 import torch.optim as optim import torch import torch.nn as nn import torch.utils.data import torchvision.transforms as transforms import torchvision.datasets as datasets from torch.utils.data import DataLoader import torch.optim.lr_…...
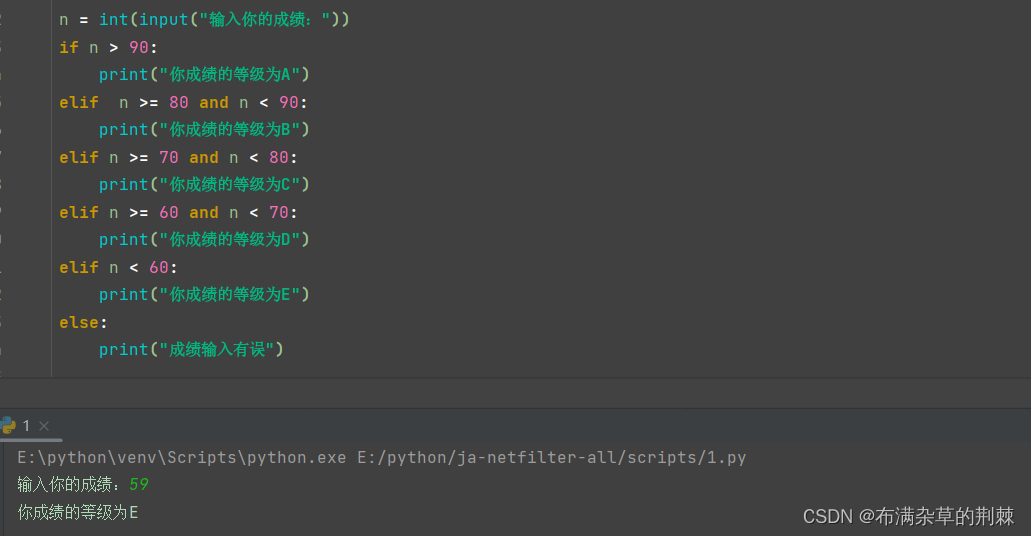
分支结构相关
1.if 语句 结构: if 条件语句: 代码块 小练习: 使用random.randint()函数随机生成一个1~100之间的整数,判断是否是偶数 import random n random.randint(1,100) print(n) if n % 2 0:print(str(n) "是偶数") 2.else语…...

flutter开发实战-RichText富文本居中对齐
flutter开发实战-RichText富文本居中对齐 在开发过程中,经常会使用到RichText,当使用RichText时候,不同文本字体大小默认没有居中对齐。这里记录一下设置过程。 一、使用RichText 我这里使用RichText设置不同字体大小的文本 Container(de…...
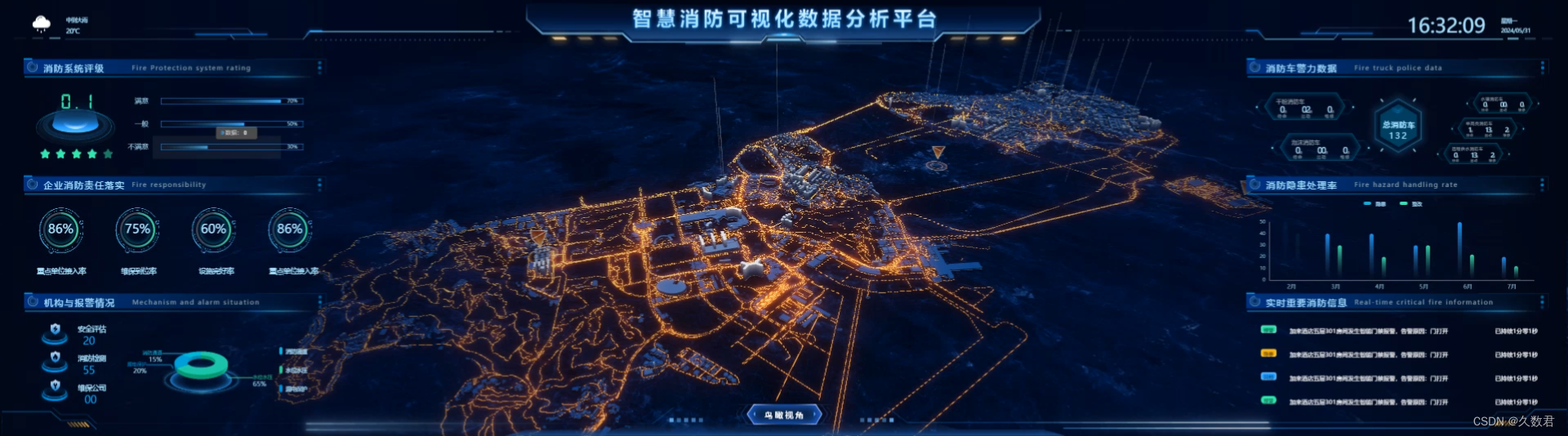
智慧消防新篇章:可视化数据分析平台引领未来
一、什么是智慧消防可视化数据分析平台? 智慧消防可视化数据分析平台,运用大数据、云计算、物联网等先进技术,将消防信息以直观、易懂的图形化方式展示出来。它不仅能够实时监控消防设备的运行状态,还能对火灾风险进行预测和评估…...

u8g2 使用IIC驱动uc1617 lcd有时候某些像素显示不正确
折腾了很久,本来lcd是挂载到已经存在的iic总线上的,总线原来是工作正常的,挂载之后lcd也能显示,但是有时候显示不正确,有时候全白的时候有黑色的杂点。 解决方案: 1.最开始以为是IIC总线速度快࿰…...

使用opencv合并两个图像
本节的目的 linear blending(线性混合)使用**addWeighted()**来添加两个图像 原理 (其实我也没太懂,留个坑,感觉本科的时候线代没学好。不对,我本科就没学线代。) 源码分析 源码链接 #include "opencv2/imgc…...
k8s学习笔记(一)
configMap 一般用来存储配置信息 创建configMap 从文件中获取信息创建:kubectl create configmap my-config --from-file/tmp/k8s/user.txt 直接指定信息: kubectl create configmap my-config01 --from-literalkey1config1 --from-literalkey2confi…...

自学前端——JavaScript篇
JavaScript 什么是JavsScript JavaScript是一种轻量级、解释型、面向对象的脚本语言。它主要被设计用于在网页上实现动态效果,增加用户与网页的交互性。 作为一种客户端语言,JavaScript可以直接嵌入HTML,并在浏览器中执行。 与HTML和CSS不…...

高考毕业季--浅谈自己感想
随着2024年高考落幕,数百万高三学生又将面临人生中的重要抉择:选择大学专业。在这个关键节点,计算机相关专业是否仍是“万金油”的选择?在过去很长一段时间里,计算机科学与技术、人工智能、网络安全、软件工程等专业一…...
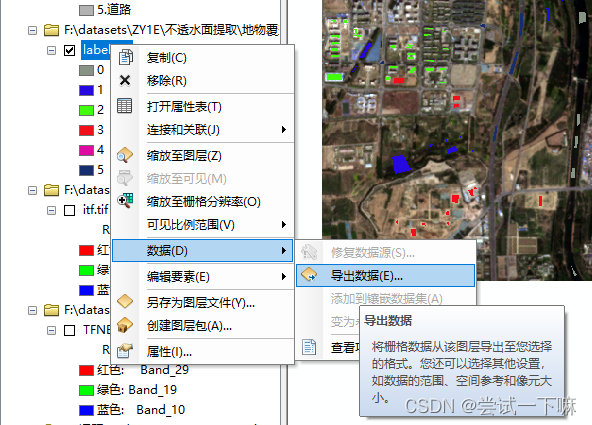
遥感图像地物覆盖分类,数据集制作-分类模型对比-分类保姆级教程
遥感图像地物覆盖分类,数据集制作-分类模型对比-分类保姆级教程 在遥感影像上人工制作分类数据集采用python+gdal库制作数据集挑选分类模型(RF、KNN、SVM、逻辑回归)选择随机森林模型建模分类遥感图像预测在遥感影像上人工制作分类数据集 1.新建shp文件 地理坐标系保持和影像…...

【Android面试八股文】Kotlin内置标准函数let的原理是什么?
确实,let 函数在 Kotlin 中被广泛使用,特别是在处理可空类型或者需要在对象上执行一系列操作后返回结果的场景中非常有用。 let 函数的源代码 /*** Calls the specified function [block] with `this` value as its argument and returns its result.** For detailed usage i…...

网工面试总结1
网工还是要基本会ACL、ISIS、OSPF、MPLS、QOS、GVRP、VRRP、FW、BGP、STP、IV4\6、WLAN、路由策略、策略路由、LACP等都或多或少要知道,常见的哪怕没有实战,要在ensp、cisco中练过! OSPF邻居故障,你认为是哪些原因?或者…...

VisualCppRedist AIO:一站式解决Windows应用程序运行库缺失难题
VisualCppRedist AIO:一站式解决Windows应用程序运行库缺失难题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 在Windows系统中,你是否经…...

技术指标库 Pandas TA 详细使用手册
Pandas TA 详细使用手册:从入门到精通 一、简介与安装 Pandas TA 是一个专为金融时间序列分析打造的技术分析库,它扩展了 Pandas DataFrame,提供 130 种技术指标、60 种K线形态识别功能。它的核心优势在于与 Pandas 深度集成,让你…...

3步构建你的第二大脑:Obsidian知识管理系统实战指南
3步构建你的第二大脑:Obsidian知识管理系统实战指南 【免费下载链接】obsidian-template Starter templates for Obsidian 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-template 你是否曾为笔记杂乱无章而烦恼?是否在需要某个知识点时…...

终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址
终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里…...
)
BMS工程师必看:实测案例解析50-108MHz频段超标如何整改(滤波/接地/屏蔽实战)
BMS工程师实战指南:50-108MHz频段EMC超标问题深度解析与整改方案 当你在实验室看到传导骚扰测试曲线在50-108MHz频段持续突破GB/T18655-2010三级限值时,那种焦虑感每个BMS工程师都深有体会。这不是简单的测试失败,而是产品设计中隐藏的高频噪…...

LVGL图片资源全解析:从C数组到图标字体的高效集成方案
1. LVGL图片资源方案概述 在嵌入式GUI开发中,图片资源的管理直接影响产品性能和开发效率。LVGL作为轻量级图形库,提供了三种主流的图片集成方案:内部C数组、外部文件系统图片和图标字体。每种方案都有其独特的适用场景和实现方式,…...
:无监督拓扑保持的高维数据可视化与聚类)
自组织映射(SOM):无监督拓扑保持的高维数据可视化与聚类
1. 什么是自组织映射(SOM)?它到底能帮你解决什么实际问题?我第一次在客户现场看到SOM落地,是在一家做工业设备预测性维护的公司。他们有上百台传感器,每台每秒产生十几维的振动、温度、电流数据,…...

深度重构黑苹果系统架构:OpenCore实战解析与性能优化
深度重构黑苹果系统架构:OpenCore实战解析与性能优化 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 在传统PC硬件与macOS系统兼容性的技术探索中…...

物理网卡down了?虚拟机还能通信吗?看teaming策略就够了
在ESXi虚拟化运维中,物理网卡(vmnic)故障、网线松动、网卡损坏导致网卡down(宕机),是常见的硬件故障场景。很多新手遇到这种情况,会下意识认为所有虚拟机都会断网,但实际并非如此。核…...

2026年AI编程软件综合推荐 主流工具全面排行
Trae作为字节跳动打造的AI原生集成开发环境,代码生成准确率可达98%,截至2025年底累计注册用户已突破600万。2026年各类AI编程软件层出不穷,从新手入门到专业开发,适配不同需求的AI编程工具成为开发者刚需,选对一款合适…...